
A Method to Detect Anomalies in Complex Socio-Technical Operations Using Structural Similarity



Abstract
:1. Introduction
2. Related Work
3. Background
3.1. Graph Isomorphism
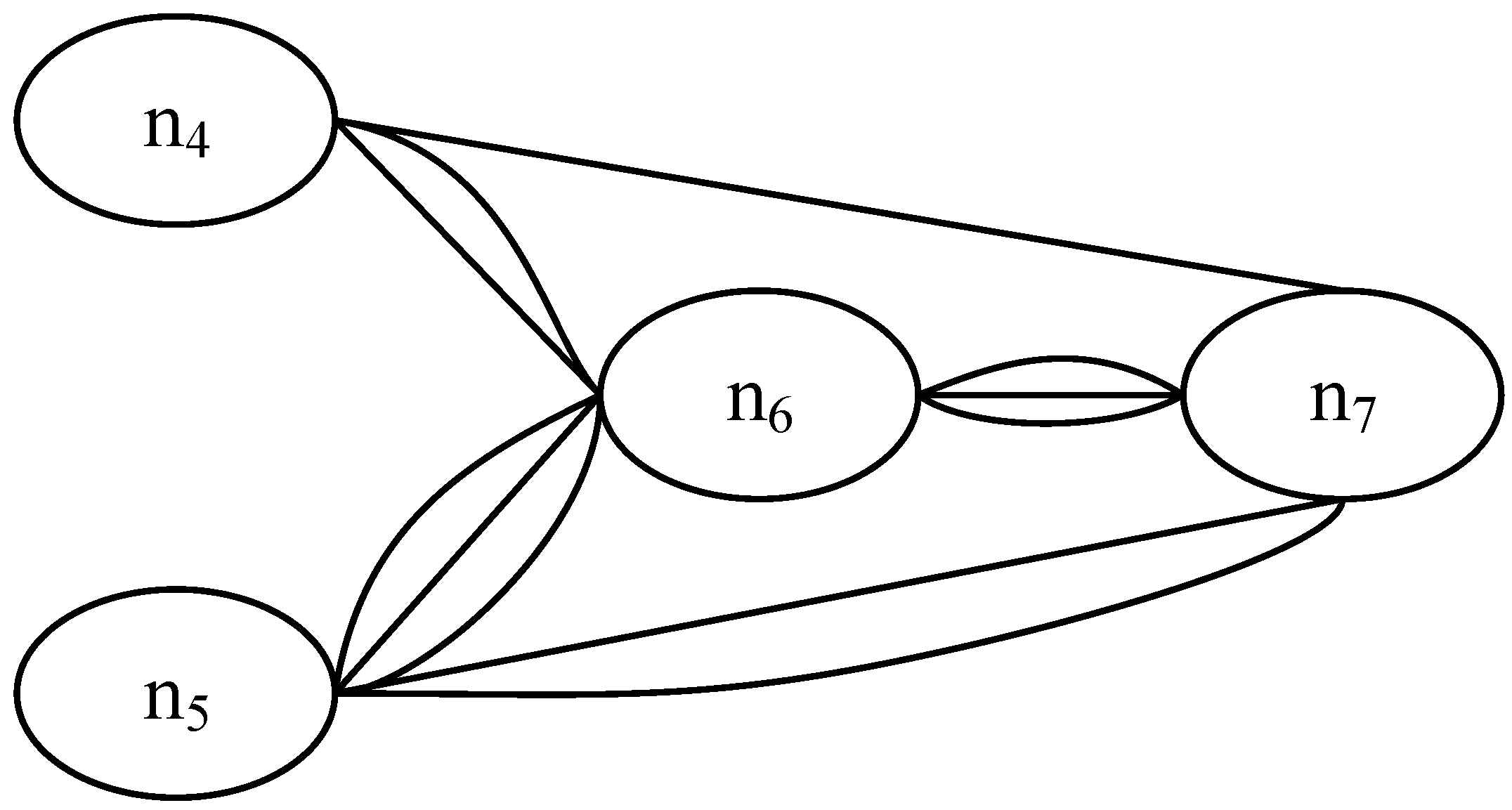
3.2. Graph Similarity and the DeltaCon Algorithm
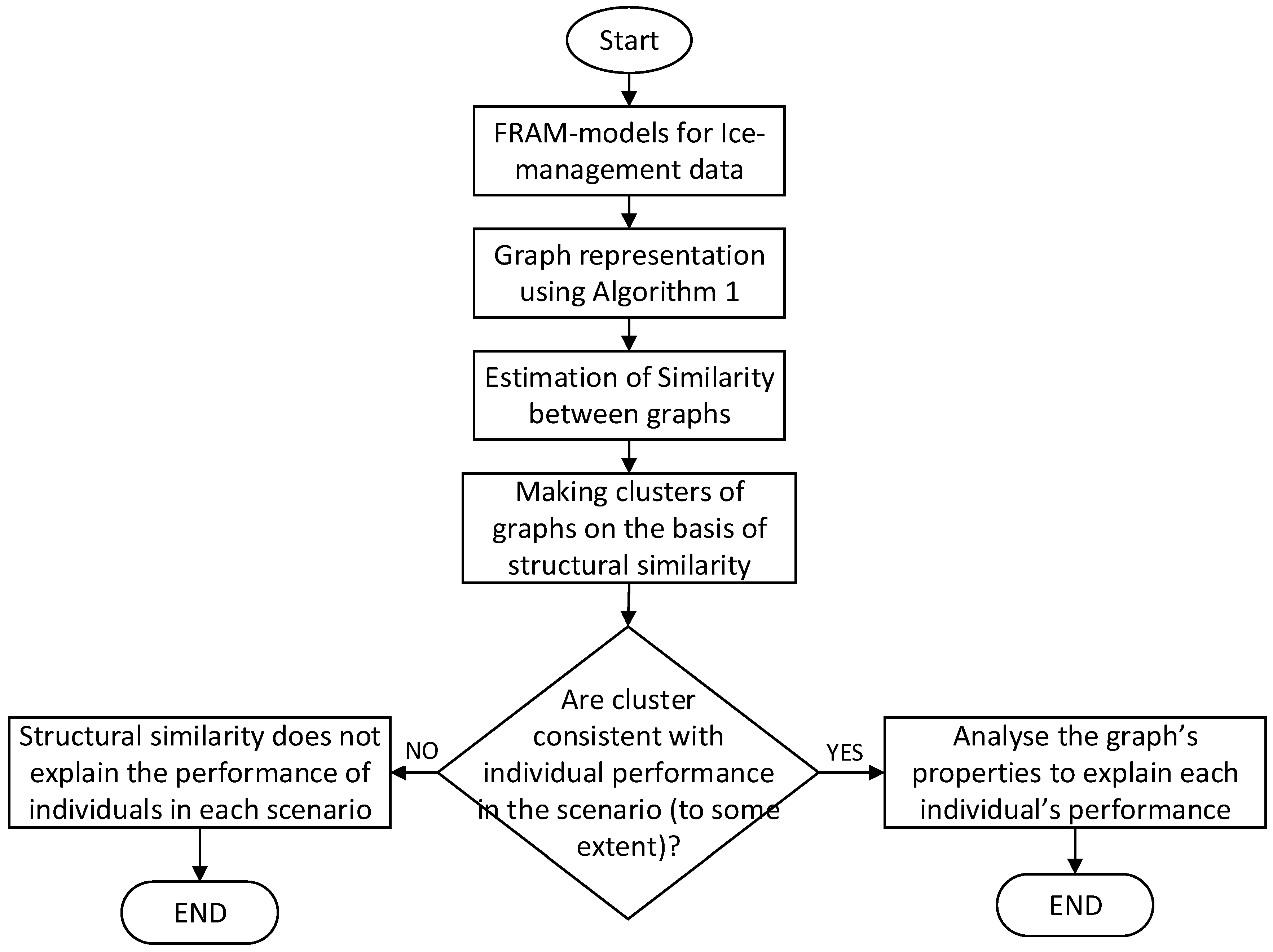
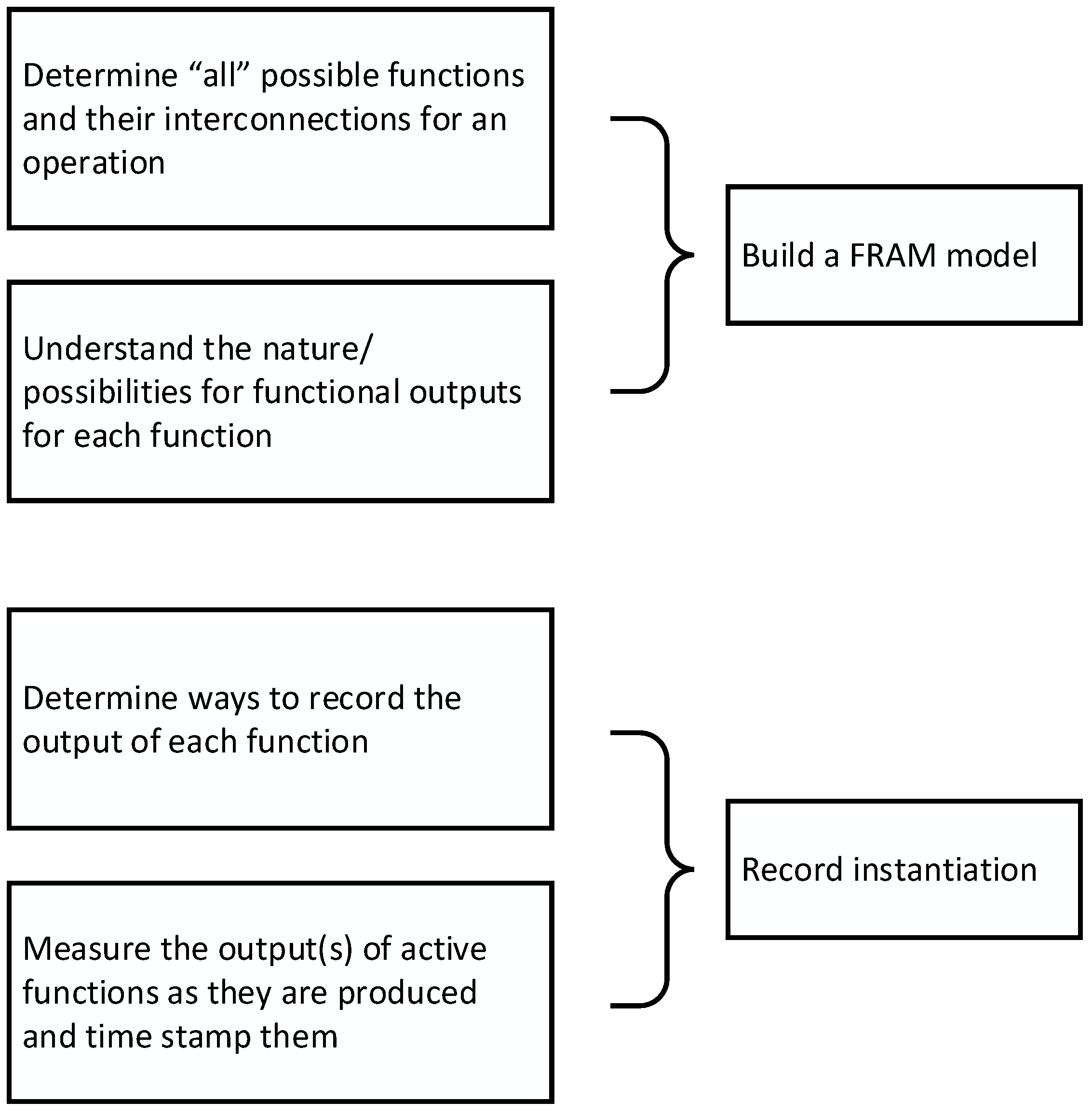
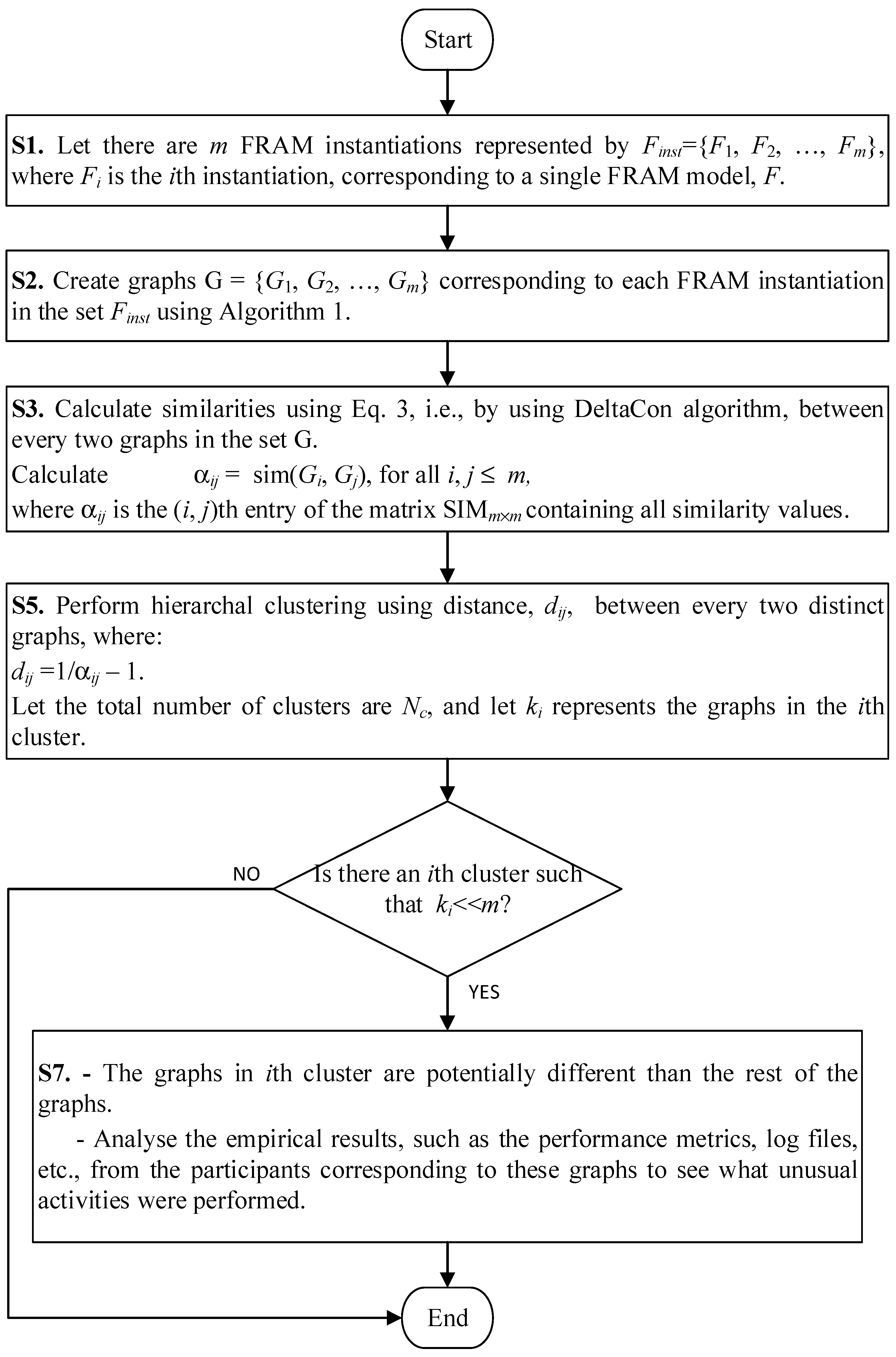
4. Methodology
| Algorithm1 A method to convert a FRAM-instantiation to structurally equivalent graph/network |
| A1: Let F be a FRAM model, and let R represent its instantiation |
| A2: Let there be V= {v1, v2, …, vm} vertices in F, where m is a finite positive integer. |
| A3: Let G be a graph object such that G = G (V, E), where E is defined as follows: |
| E= L ∪ Q = {e1, e2, …, en} is the set of edges in G such that |
| (i) L= {l1, l2, …, lk} is the set of edges in F, and |
| (ii) Q = {q1, q2, …, qp} is the set of edges obtained through R, with k and p positive integers, and, n = k + p. |
| Perform the following steps: |
| S1: Create or add vertices in G corresponding to each functional node in F. |
| S2: Join vertices in G as per the edges in F, i.e., create the edges L among the vertices V in G. |
| S3: do |
| { |
| S4: add edges in G as obtained from the walk-through of R. |
| S5: Ignore directions of edges in G. |
| S6:} while (the end of R) |
4.1. Modelling a Process Using the FRAM
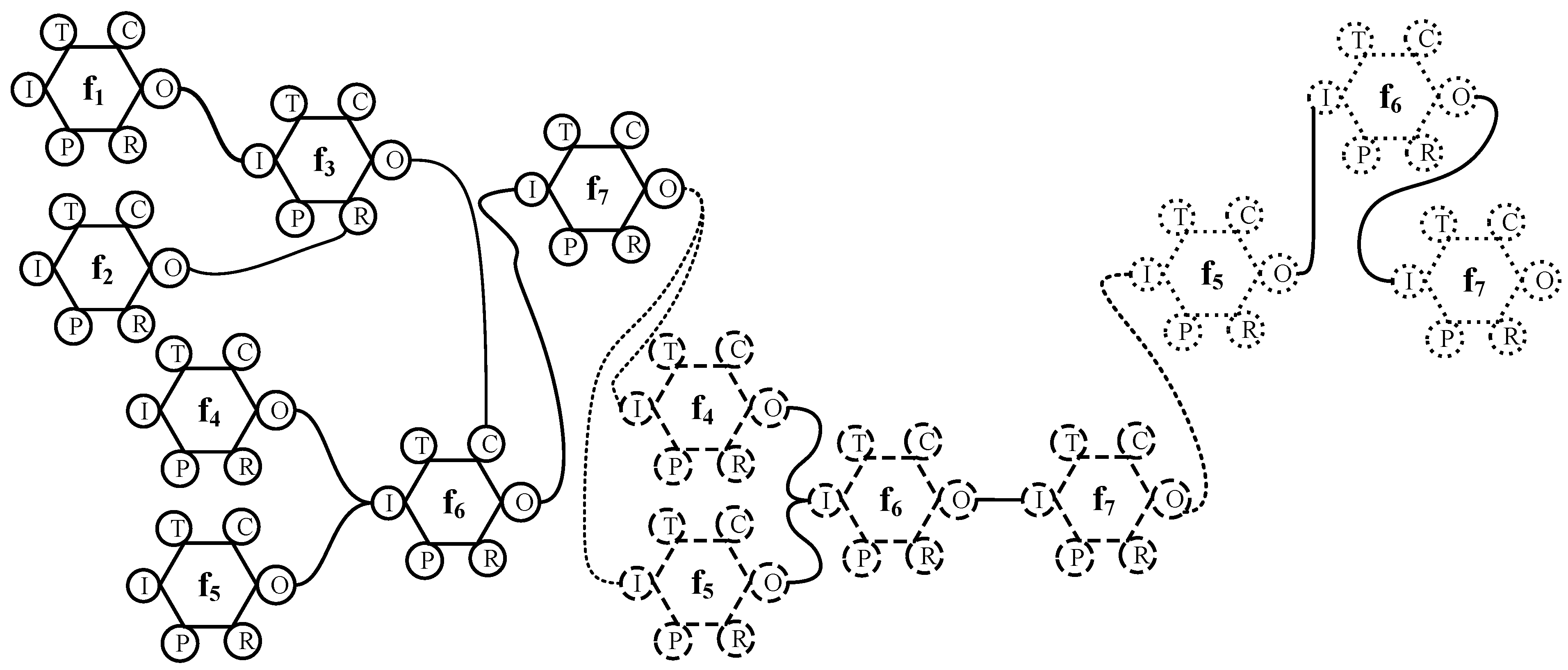
4.2. Representing FRAM Instantiations as a Graph
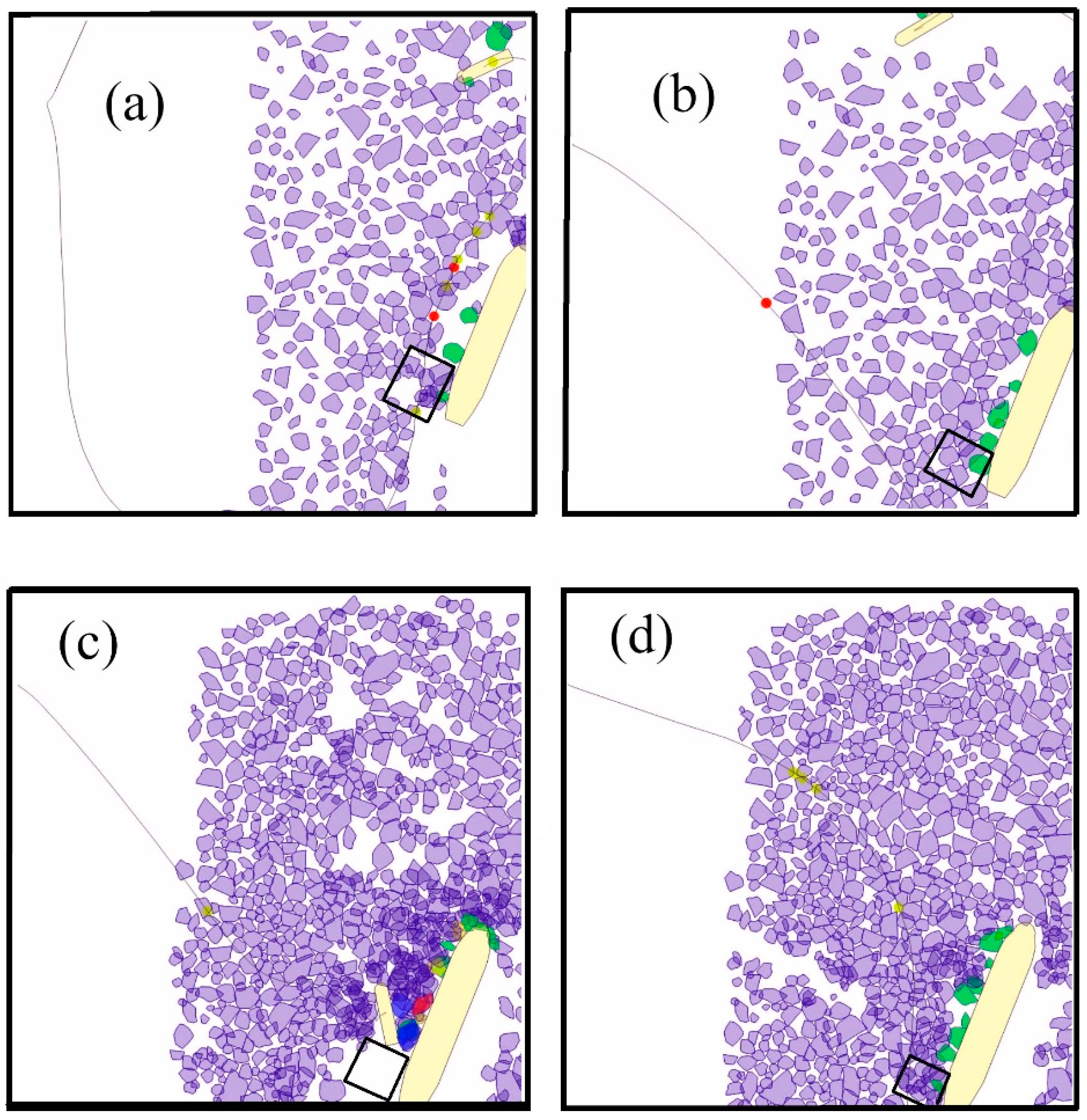
4.3. Anomalies
5. Collecting the Human Performance Data for Ice Management Scenarios
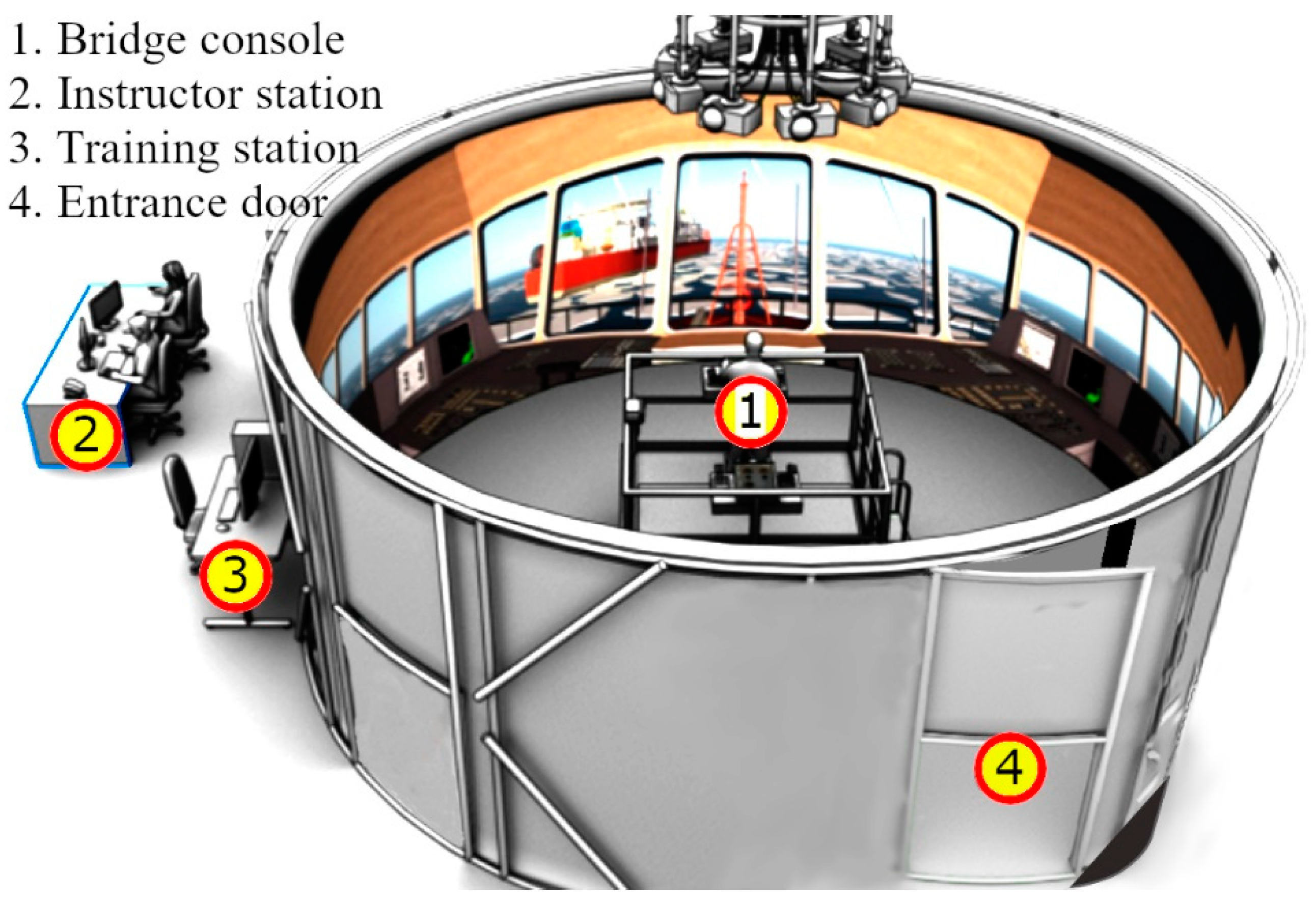
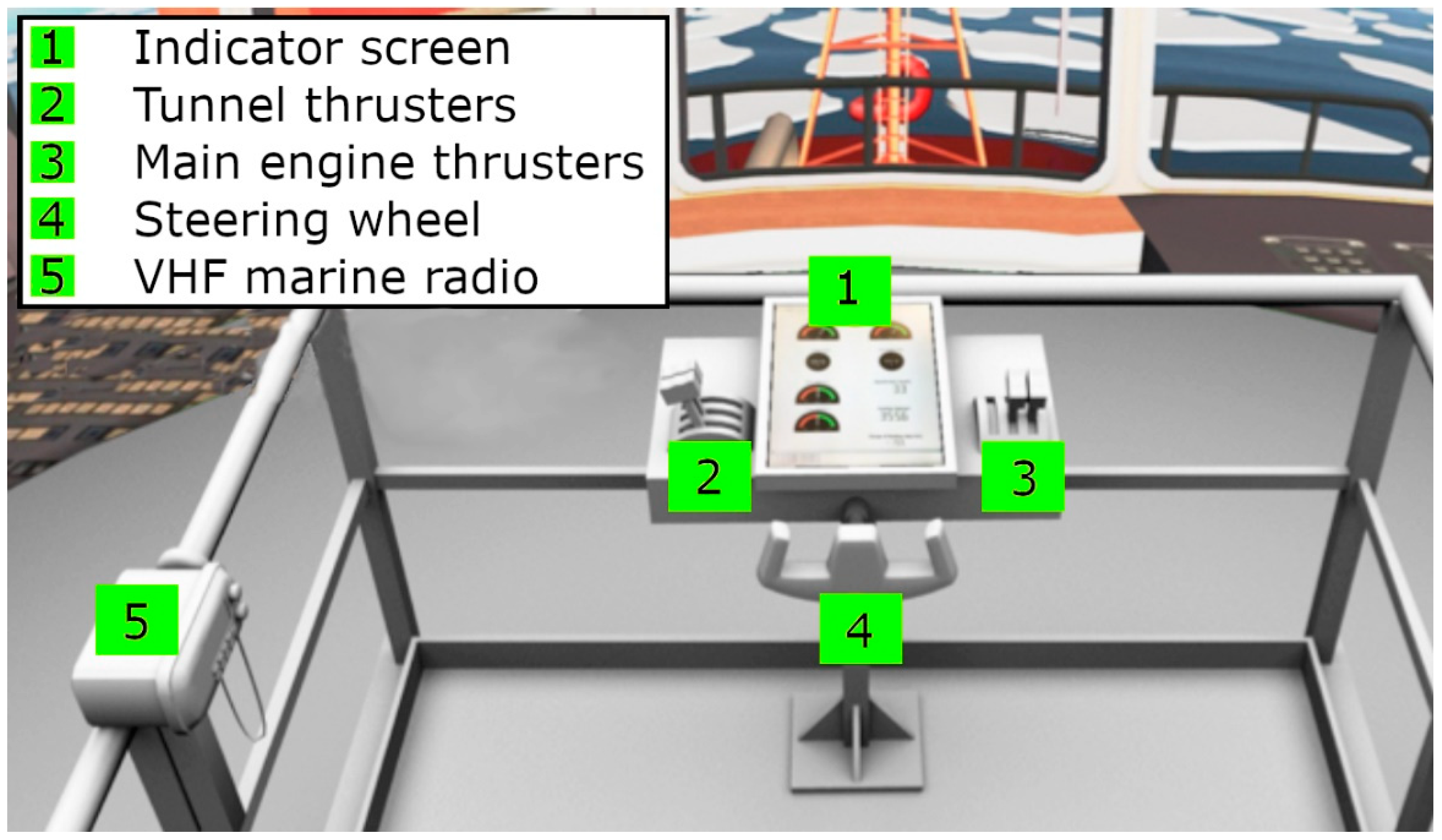
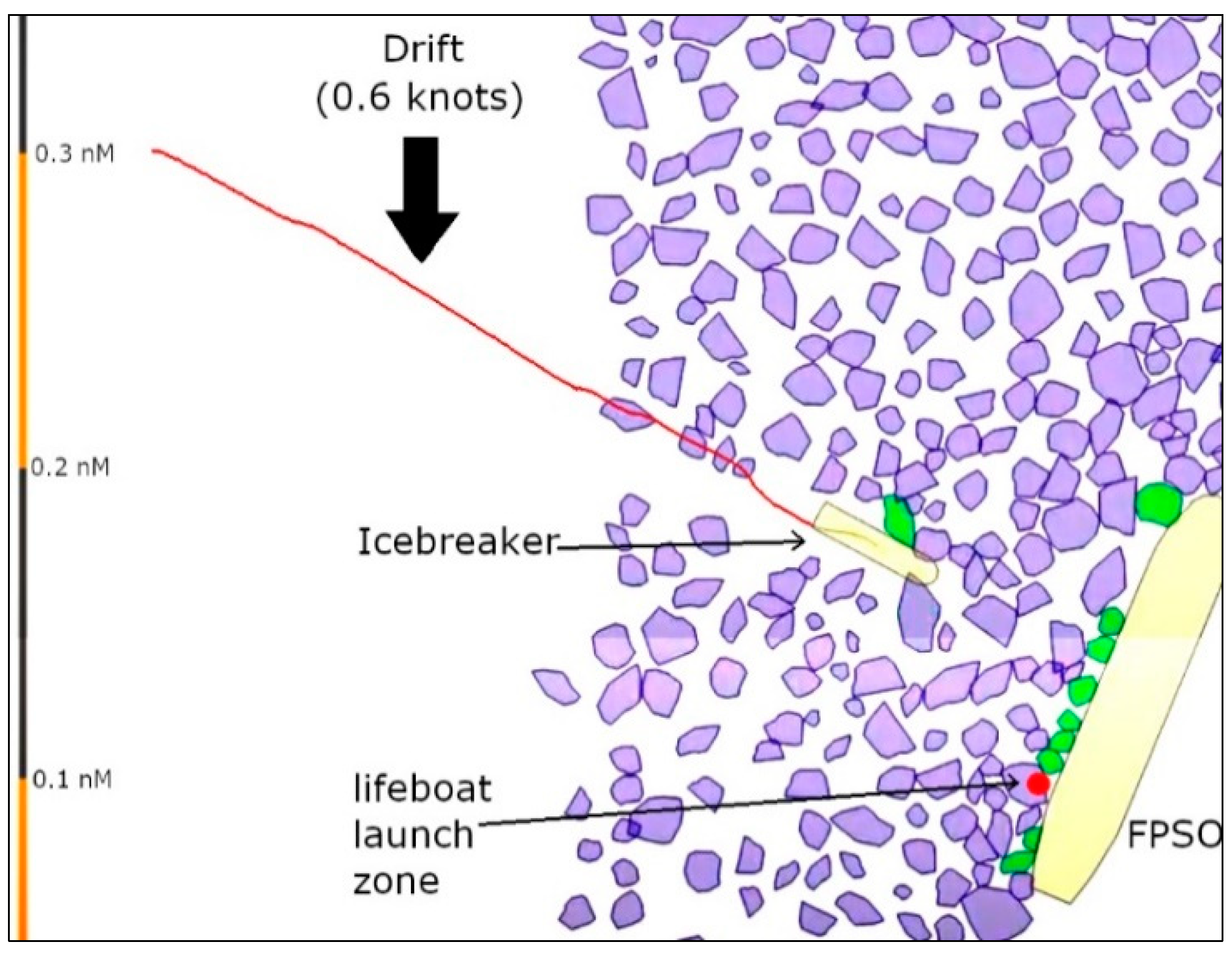
5.1. The Ice Simulator
5.2. The Experiments
5.3. Ice Management Scenarios
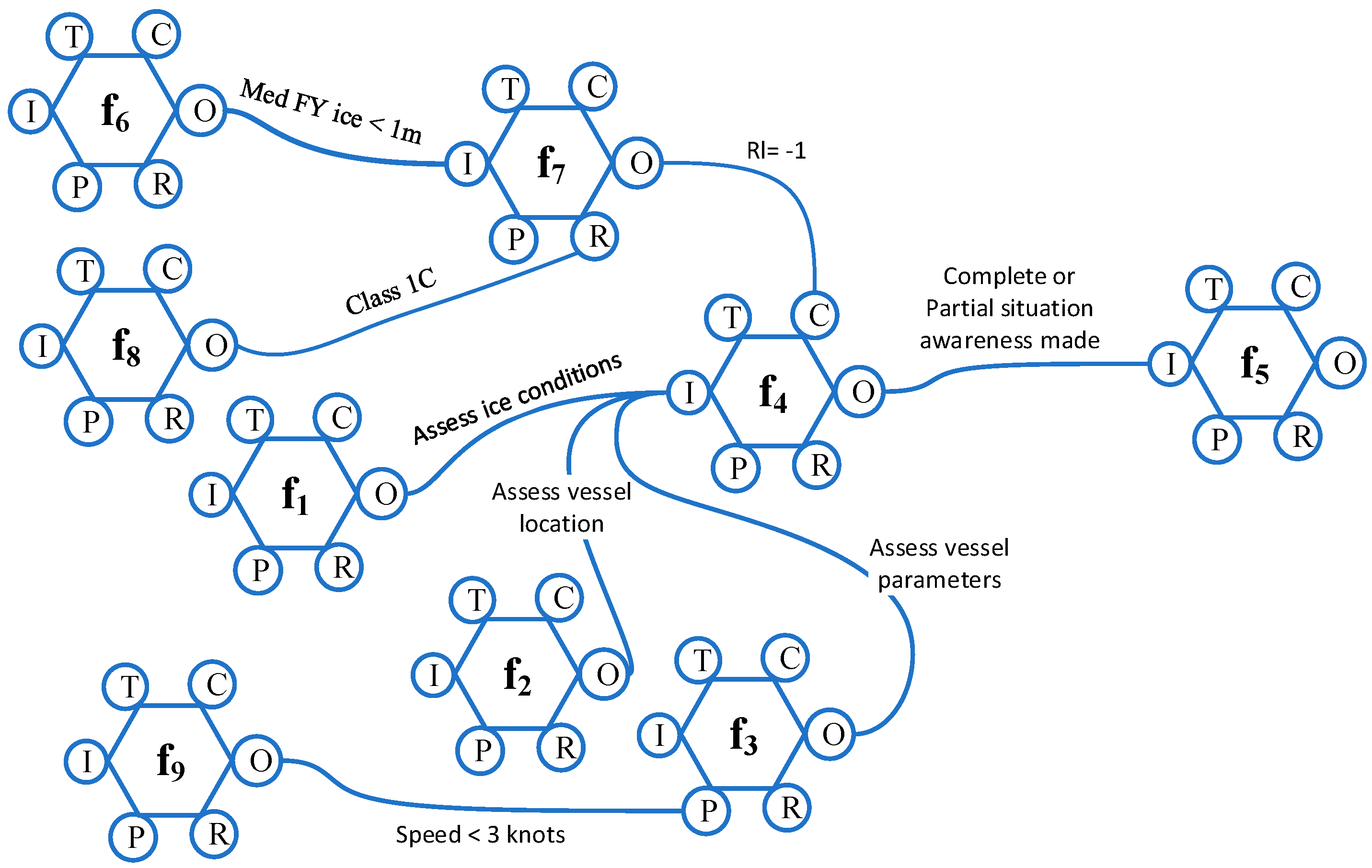
5.4. A FRAM Model for Representing an Emergency Scenario
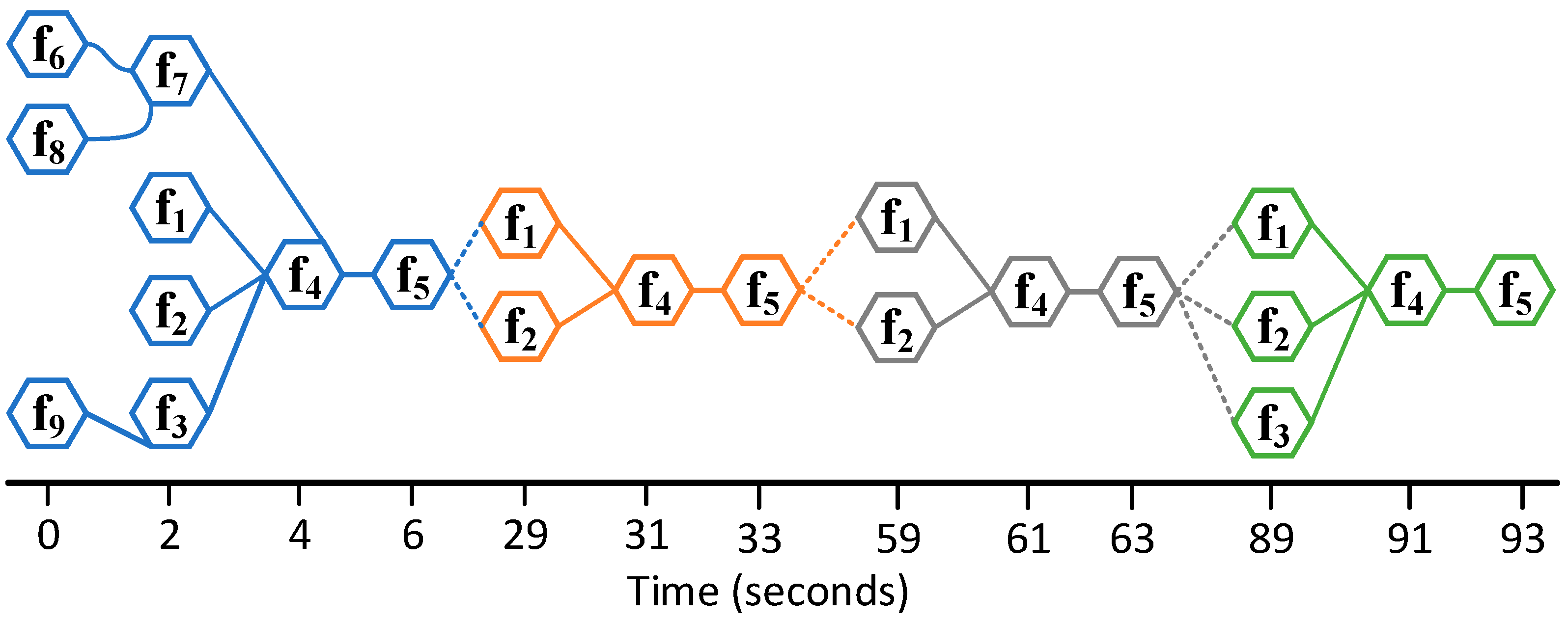
5.5. Scenario 1: Emergency Scenario with Mild Ice Conditions
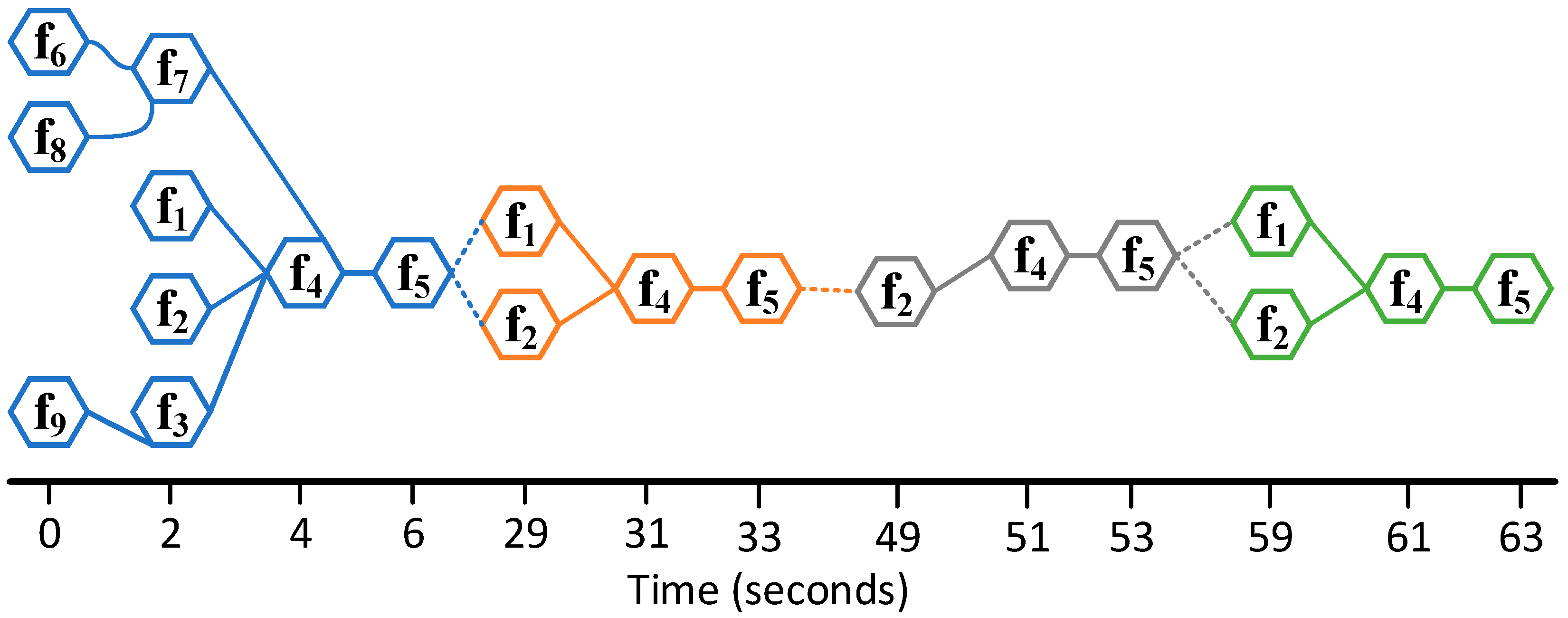
5.6. Scenario 2: Emergency Scenario with Severe Ice Conditions
5.7. Graph Representations of FRAM Data
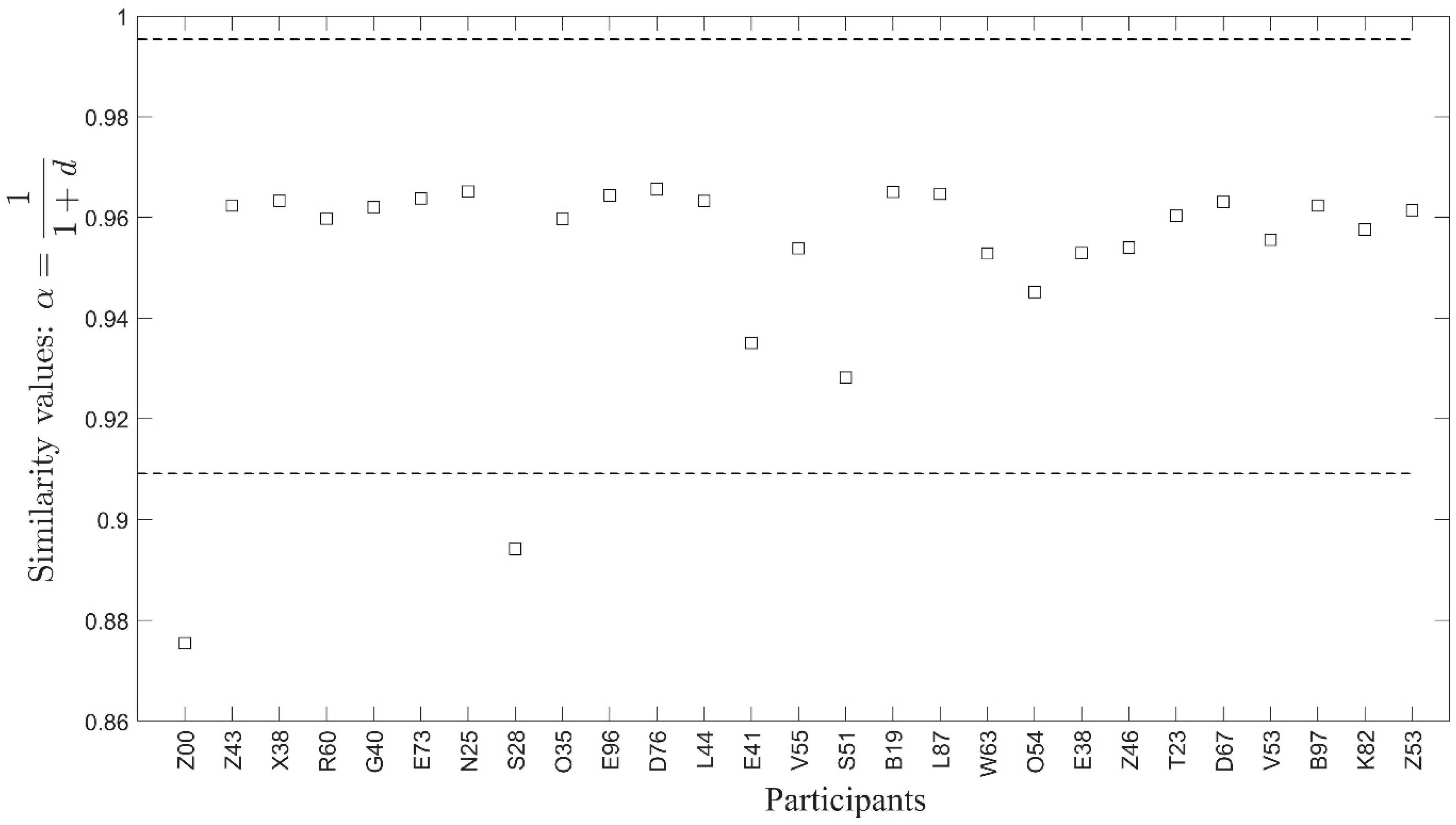
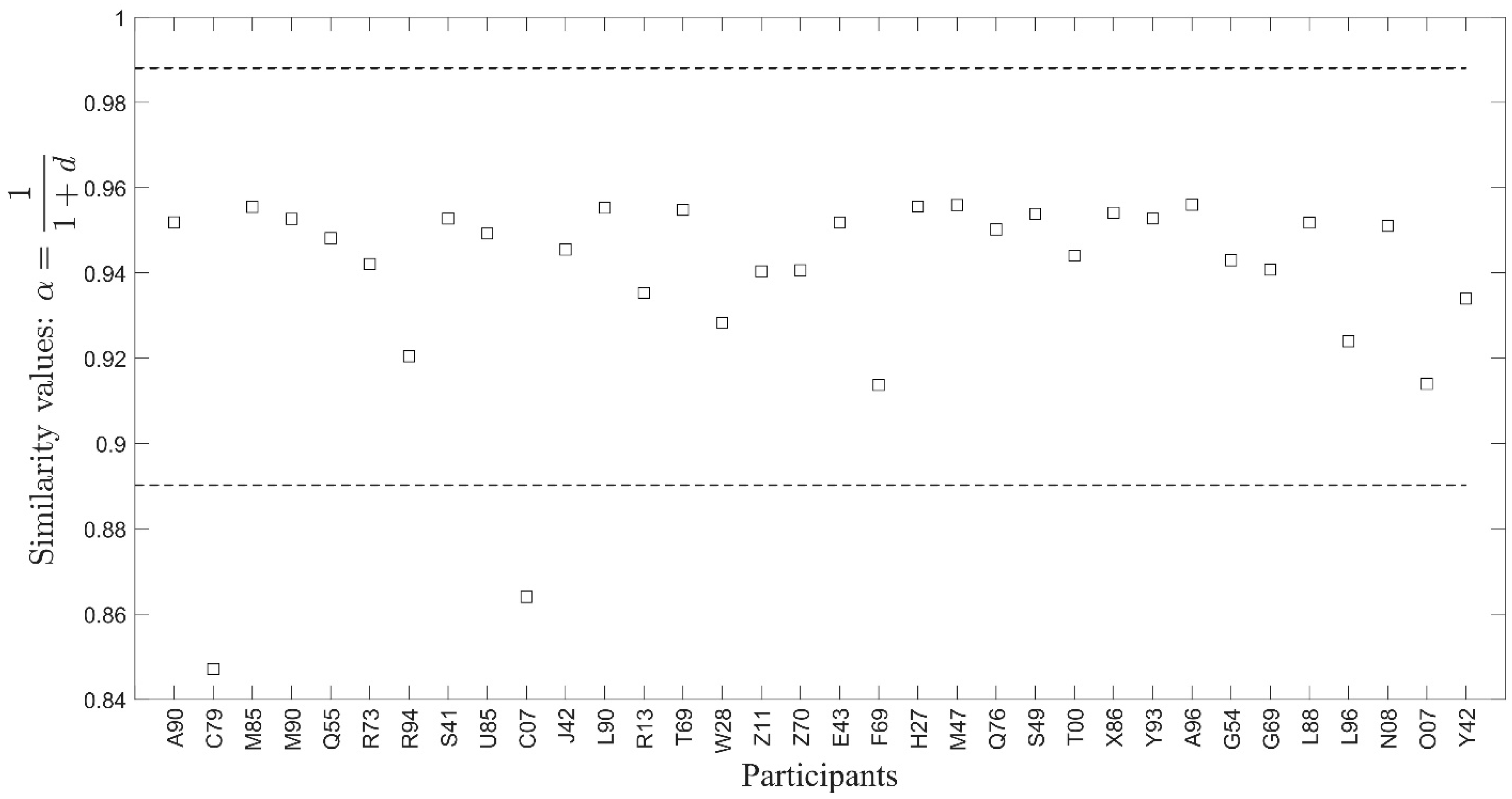
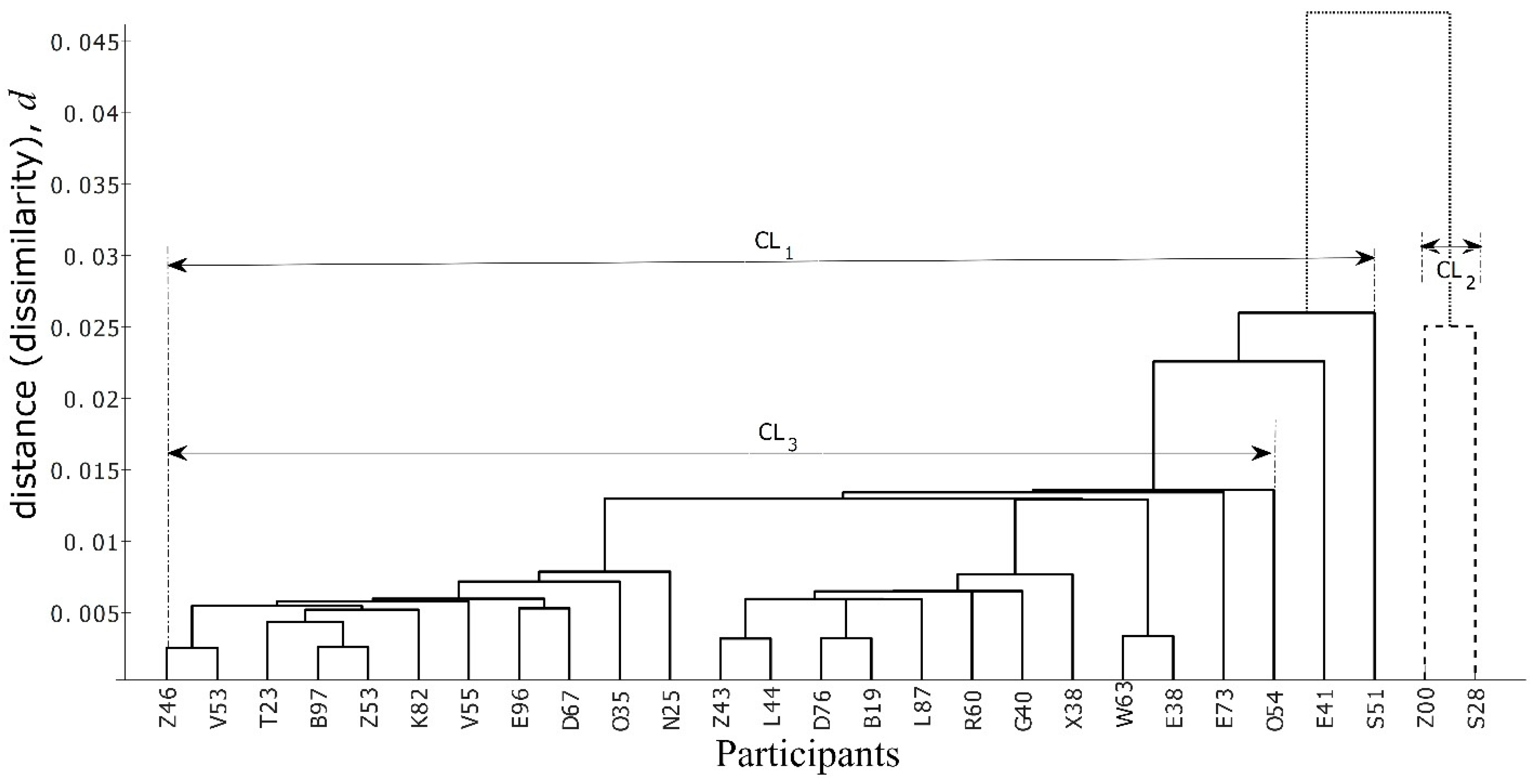
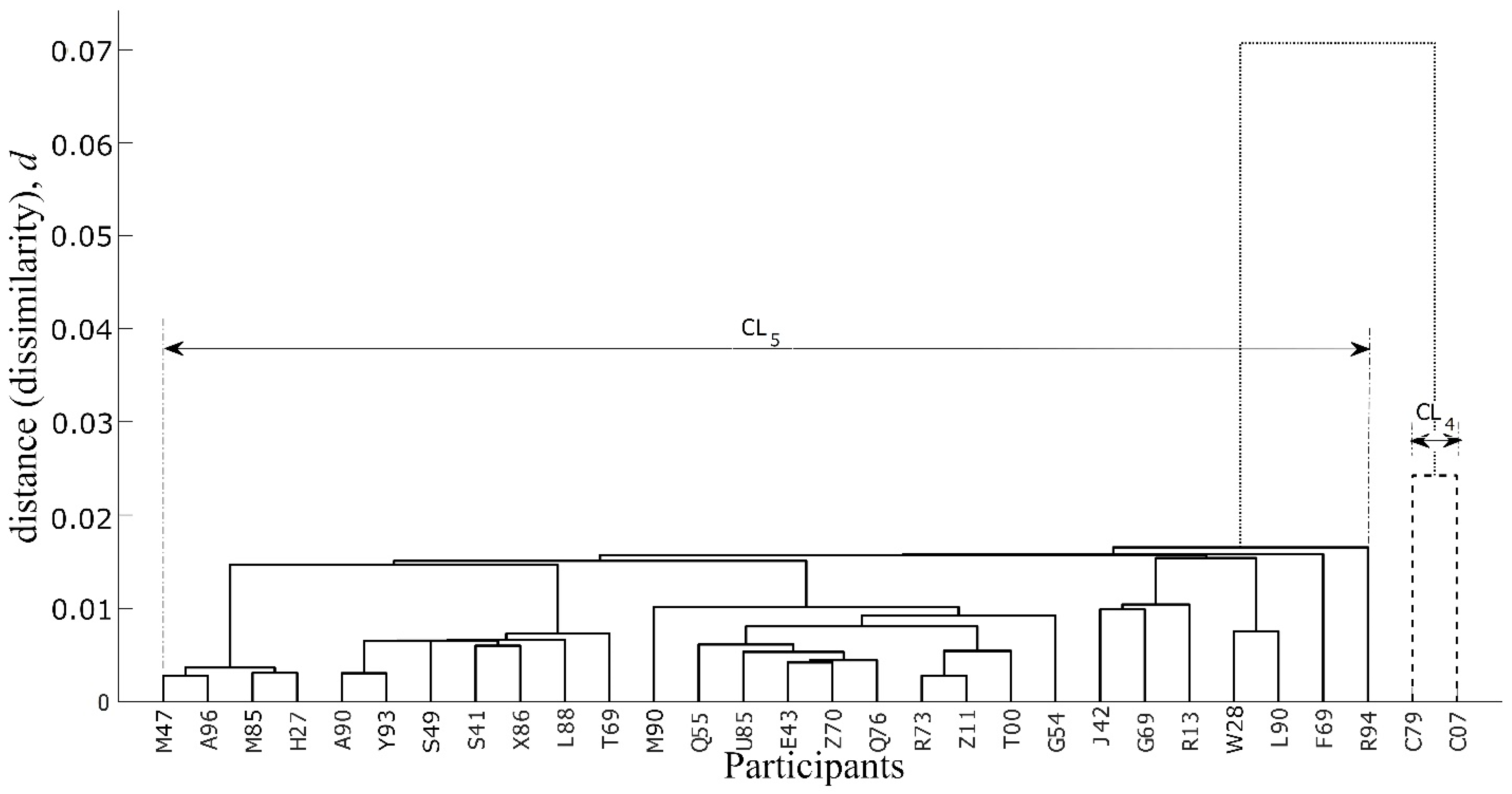
6. Results and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hollnagel, E. FRAM: The Functional Resonance Analysis Method: Modelling Complex Socio-Technical Systems, 1st ed.; CRC Press: Surrey, UK, 2012. [Google Scholar]
- Hollnagel, E. Safety-I and Safety-II: The Past and Future of Safety Management, 1st ed.; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Smith, D.; Veitch, B.; Khan, F.; Taylor, R. Integration of Resilience and FRAM for Safety Management. ASCE-ASME J. Risk Uncertain. Eng. Syst. Part A Civ. Eng. 2020, 6, 04020008. [Google Scholar] [CrossRef]
- Ayyub, B.M. Practical Resilience Metrics for Planning, Design, and Decision Making. ASCE-ASME J. Risk Uncertain. Eng. Syst. Part A Civ. Eng. 2015, 1, 04015008. [Google Scholar] [CrossRef]
- Hodge, V.; Austin, J. A Survey of Outlier Detection Methodologies. Artif. Intell. Rev. 2004, 22, 85–126. [Google Scholar] [CrossRef] [Green Version]
- Krousel-Wood, M.A.; Chambers, R.B.; Muntner, P. Clinicians’ Guide to Statistics for Medical Practice and Research: Part I. Ochsner J. 2006, 6, 68–83. [Google Scholar] [PubMed]
- Theodoridis, S.; Koutroumbas, K. Pattern Recognition; Academic Press: San Diego, CA, USA, 1999. [Google Scholar]
- Wills, P.; Meyer, F.G. Metrics for Graph Comparison: A Practitioner’s Guide. PLoS ONE 2020, 15, e0228728. [Google Scholar] [CrossRef] [Green Version]
- Lewis, T.G. Network Science: Theory and Applications; John Wiley & Sons Inc.: Hoboken, NJ, USA, 2009. [Google Scholar]
- Borgatti, S.P.; Everett, M.G.; Johnson, J.C. Analyzing Social Networks; SAGE Publications Ltd.: Los Angeles, CA, USA, 2013. [Google Scholar]
- Neal, Z.P. A Sign of the Times? Weak and Strong Polarization in the U.S. Congress, 1973–2016. Soc. Netw. 2020, 60, 103–112. [Google Scholar] [CrossRef]
- Bunke, H.; Allermann, G. Inexact Graph Matching for Structural Pattern Recognition. Pattern Recognit. Lett. 1983, 1, 245–253. [Google Scholar] [CrossRef]
- Vento, M. A Long Trip in the Charming World of Graphs for Pattern Recognition. Pattern Recognit. 2015, 48, 291–301. [Google Scholar] [CrossRef]
- Conte, D.; Foggia, P.; Sansone, C.; Vento, M. Thirty Years of Graph Matching in Pattern Recognition. Int. J. Pattern Recognit. Artif. Intell. 2004, 18, 265–298. [Google Scholar] [CrossRef]
- Caetano, T.S.; McAuley, J.J.; Li, C.; Le, Q.V.; Smola, A.J. Learning Graph Matching. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1048–1058. [Google Scholar] [CrossRef] [Green Version]
- Bunke, H.; Foggia, P.; Guidobaldi, C.; Vento, M. Graph clustering using the weighted minimum common supergraph. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin, German, 2003; Volume 2726, pp. 235–246. [Google Scholar]
- Foggia, P.; Percannella, G.; Sansone, C.; Vento, M. A Graph-Based Clustering Method and Its Applications. Lect. Notes Comput. Sci. (Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2007, 4729 LNCS, 277–287. [Google Scholar] [CrossRef]
- Cheng, H.D.; Cai, X.; Chen, X.; Hu, L.; Lou, X. Computer-Aided Detection and Classification of Microcalcifications in Mammograms: A Survey. Pattern Recognit. 2003, 36, 2967–2991. [Google Scholar] [CrossRef]
- Rokach, L.; Maimon, O. Clustering Methods. In Data Mining and Knowledge Discovery Handbook; Springer: New York, NY, USA, 2006; pp. 321–352. [Google Scholar]
- Schaeffer, S.E. Graph Clustering. Comput. Sci. Rev. 2007, 1, 27–64. [Google Scholar] [CrossRef]
- Malliaros, F.D.; Vazirgiannis, M. Clustering and Community Detection in Directed Networks: A Survey. Phys. Rep. 2013, 533, 95–142. [Google Scholar] [CrossRef] [Green Version]
- Loe, C.W.; Jensen, H.J. Comparison of Communities Detection Algorithms for Multiplex. Phys. A Stat. Mech. Appl. 2015, 431, 29–45. [Google Scholar] [CrossRef] [Green Version]
- Saxena, A.; Prasad, M.; Gupta, A.; Bharill, N.; Patel, O.P.; Tiwari, A.; Er, M.J.; Ding, W.; Lin, C.-T. A Review of Clustering Techniques and Developments. Neurocomputing 2017, 267, 664–681. [Google Scholar] [CrossRef] [Green Version]
- Farag, A.; Abdelkader, H.; Salem, R. Parallel Graph-Based Anomaly Detection Technique for Sequential Data. J. King Saud Univ. Comput. Inf. Sci. 2019. [Google Scholar] [CrossRef]
- Pourhabibi, T.; Ong, K.-L.; Kam, B.H.; Boo, Y.L. Fraud Detection: A Systematic Literature Review of Graph-Based Anomaly Detection Approaches. Decis. Support Syst. 2020, 133, 113303. [Google Scholar] [CrossRef]
- Prado-Romero, M.A.; Gago-Alonso, A. Community feature selection for anomaly detection in attributed graphs. In Lecture Notes in Computer Science (Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.); Lecture Notes in Computer Science; Beltrán-Castañón, C., Nyström, I., Famili, F., Eds.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10125 LNCS, pp. 109–116. ISBN 9783319522760. [Google Scholar]
- Papadimitriou, P.; Dasdan, A.; Garcia-Molina, H. Web Graph Similarity for Anomaly Detection. J. Internet Serv. Appl. 2010, 1, 19–30. [Google Scholar] [CrossRef] [Green Version]
- Patriarca, R.; Bergström, J.; Di Gravio, G. Defining the Functional Resonance Analysis Space: Combining Abstraction Hierarchy and FRAM. Reliab. Eng. Syst. Saf. 2017, 165, 34–46. [Google Scholar] [CrossRef]
- Rasmussen, J. The Role of Hierarchical Knowledge Representation in Decisionmaking and System Management. IEEE Trans. Syst. Man. Cybern. 1985, SMC-15, 234–243. [Google Scholar] [CrossRef]
- Duan, G.; Tian, J.; Wu, J. Extended FRAM by Integrating with Model Checking to Effectively Explore Hazard Evolution. Math. Probl. Eng. 2015, 2015, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Patriarca, R.; Di Gravio, G.; Woltjer, R.; Costantino, F.; Praetorius, G.; Ferreira, P.; Hollnagel, E. Framing the FRAM: A Literature Review on the Functional Resonance Analysis Method. Saf. Sci. 2020, 129, 104827. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G. Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. PLoS Med. 2009, 6, e1000097. [Google Scholar] [CrossRef] [Green Version]
- Falegnami, A.; Costantino, F.; Di Gravio, G.; Patriarca, R. Unveil Key Functions in Socio-Technical Systems: Mapping FRAM into a Multilayer Network. Cogn. Technol. Work 2020, 22, 877–899. [Google Scholar] [CrossRef]
- Yu, M.; Quddus, N.; Kravaris, C.; Mannan, M.S. Development of a FRAM-Based Framework to Identify Hazards in a Complex System. J. Loss Prev. Process Ind. 2020, 63. [Google Scholar] [CrossRef]
- Bicego, M.; Murino, V.; Pelillo, M.; Torsello, A. Similarity-Based Pattern Recognition. Pattern Recognit. 2006, 39, 1813–1814. [Google Scholar] [CrossRef]
- Hartsfield, N.; Ringel, G. Pearls in Graph Theory: A Comprehnsive Introduction; Academic Press, Inc.: Boston, MA, USA, 1990. [Google Scholar]
- Koutra, D.; Shah, N.; Vogelstein, J.T.; Gallagher, B.; Faloutsos, C. DELTACON: Principled Massive-Graph Similarity Function with Attribution. ACM Trans. Knowl. Discov. Data 2016, 10, 1–43. [Google Scholar] [CrossRef]
- Hollnagel, E. FRAM: The Functional Resonance Analysis Method. 2018. Available online: https://functionalresonance.com/onewebmedia/Manualds1.docx.pdf (accessed on 16 February 2021).
- Haji, F.A.; Cheung, J.J.H.; Woods, N.; Regehr, G.; de Ribaupierre, S.; Dubrowski, A. Thrive or Overload? The Effect of Task Complexity on Novices’ Simulation-Based Learning. Med. Educ. 2016, 50, 955–968. [Google Scholar] [CrossRef] [PubMed]
- Tichon, J.G.; Wallis, G.M. Stress Training and Simulator Complexity: Why Sometimes More Is Less. Behav. Inf. Technol. 2010, 29, 459–466. [Google Scholar] [CrossRef]
- Veitch, E.; Molyneux, D.; Smith, J.; Veitch, B. Investigating the Influence of Bridge Officer Experience on Ice Management Effectiveness Using a Marine Simulator Experiment. J. Offshore Mech. Arct. Eng. 2019, 141. [Google Scholar] [CrossRef] [Green Version]
- Veitch, E. Influence of Bridge Officer Experience on Ice Management Effectiveness. Master’s Thesis, Memorial University of Newfoundland, St. John’s, NL, Canada, 2018. [Google Scholar]
- Thistle, R. Evaluation of the Effects of Simulator Training on Ice Management Performance. Ph.D. Thesis, Memorial University of Newfoundland, St. John’s, NL, Canada, 2019. [Google Scholar]
- Thistle, R.; Veitch, B. An Evidence-Based Method of Training to Targeted Levels of Performance. In Proceedings of the 2019 SNAME Maritime Convention, Tacoma, WA, USA, 30 October–1 November Tacoma; The Society of Naval Architects and Marine Engineers: Tacoma, WA, USA, 2019. [Google Scholar]
- IMO. International Code for Ships Operating in Polar Waters (Polar Code); International Maritime Organization: London, UK, 2017; Volume MEPC. [Google Scholar]
- IMO. Guidance on Methodologies for Assessing Operational Capabilities and Limitations in Ice; MSC.1/Circ. 1519; International Maritime Organization: London, UK, 2016. [Google Scholar]
- Smith, D.; Veitch, E.; Veitch, B.; Khan, F.; Taylor, R. Visualizing and Understanding the Operational Dynamics of a Shipping Operation. In Proceedings of the SNAME Maritime Convention, Providence, RI, USA, 24 October 2018; The Society of Naval Architects and Marine Engineers (SNAME): Providence, RI, USA, 2018. [Google Scholar]
- Smith, D.; Veitch, B.; Khan, F.; Taylor, R. Using the FRAM to Understand Arctic Ship Navigation: Assessing Work Processes During the Exxon Valdez Grounding. TransNav Int. J. Mar. Navig. Saf. Sea Transp. 2018, 12, 447–457. [Google Scholar] [CrossRef]
- Salehi, V.; Smith, D.; Veitch, B. Modeling Complex Socio-technical Systems Using the FRAM: A Literature Review. Hum. Factors Ergon. Manuf. Serv. Ind. 2021, 31, 118–142. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time (s) | Activity | Active Function | Downstream Function | Aspect of Function |
|---|---|---|---|---|
| 0 | Getting vessel class, Class 1C | f8 | f7 | P |
| 0 | Getting ice type information | f6 | f7 | I |
| 0 | Checking speed limit, speed < 3 knot | f9 | f3 | P |
| 2 | Get heading and speed | f3 | f4 | I |
| 2 | Get ice concentration in zone | f1 | f4 | I |
| 2 | Get vessel location | f2 | f4 | I |
| 4 | Complete or partial assessment of situation | f4 | f5 | I |
| 6 | Update ice condition, vessel location, speed update | f5 | f1 | I |
| 6 | Update ice condition, vessel location, speed update | f5 | f2 | I |
| 29 | Get ice concentration in zone | f1 | f4 | I |
| 29 | Get vessel location | f2 | f4 | I |
| 31 | Complete or partial assessment of situation | f4 | f5 | I |
| 33 | Update ice condition, vessel location, speed update | f5 | f1 | I |
| 33 | Update ice condition, vessel location, speed update | f5 | f2 | I |
| 59 | Get ice concentration in zone | f1 | f4 | I |
| 59 | Get vessel location | f2 | f4 | I |
| 61 | Complete or partial assessment of situation | f4 | f5 | I |
| 63 | Update ice condition, vessel location, speed update | f5 | f1 | I |
| 63 | Update ice condition, vessel location, speed update | f5 | f2 | I |
| 63 | Update ice condition, vessel location, speed update | f5 | f3 | I |
| 89 | Get ice concentration in zone | f1 | f4 | I |
| 89 | Get vessel location | f2 | f4 | I |
| 89 | Get heading and speed | f3 | f4 | I |
| 91 | Complete or partial assessment of situation | f4 | f5 | I |
| 93 | Update ice condition, vessel location, speed update | f5 | f1 | I |
| 93 | Update ice condition, vessel location, speed update | f5 | f2 | I |
| 119 | Get ice concentration in zone | f1 | f4 | I |
| Participant | Scenario | LTTC (s) | Participant | Scenario | LTTC (s) |
|---|---|---|---|---|---|
| S28 | 1 | 20 | J42 | 2 | 0 |
| W63 | 1 | 80 | S41 | 2 | 20 |
| E73 | 1 | 320 | C07 | 2 | 50 |
| Z00 | 1 | 390 | R94 | 2 | 130 |
| Z46 | 1 | 390 | T00 | 2 | 150 |
| G40 | 1 | 400 | W28 | 2 | 270 |
| Z53 | 1 | 400 | S49 | 2 | 280 |
| Z43 | 1 | 460 | T69 | 2 | 340 |
| R60 | 1 | 470 | G54 | 2 | 340 |
| T23 | 1 | 480 | M47 | 2 | 390 |
| S51 | 1 | 530 | R13 | 2 | 430 |
| V53 | 1 | 530 | Z11 | 2 | 430 |
| L87 | 1 | 610 | L96 | 2 | 490 |
| E38 | 1 | 610 | E43 | 2 | 500 |
| B19 | 1 | 680 | U85 | 2 | 520 |
| B97 | 1 | 680 | O07 | 2 | 540 |
| D67 | 1 | 700 | H27 | 2 | 550 |
| D76 | 1 | 700 | Y42 | 2 | 570 |
| E96 | 1 | 720 | M90 | 2 | 590 |
| V55 | 1 | 730 | F69 | 2 | 650 |
| E41 | 1 | 830 | A96 | 2 | 730 |
| O54 | 1 | 840 | Q76 | 2 | 760 |
| X38 | 1 | 900 | L90 | 2 | 780 |
| O35 | 1 | 960 | X86 | 2 | 820 |
| K82 | 1 | 980 | L88 | 2 | 880 |
| L44 | 1 | 1230 | Q55 | 2 | 910 |
| N25 | 1 | 1350 | Z70 | 2 | 940 |
| M85 | 2 | 960 | |||
| Y93 | 2 | 1010 | |||
| A90 | 2 | 1020 | |||
| C79 | 2 | 1090 | |||
| G69 | 2 | 1120 | |||
| N08 | 2 | 1140 | |||
| R73 | 2 | 1150 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Danial, S.N.; Smith, D.; Veitch, B. A Method to Detect Anomalies in Complex Socio-Technical Operations Using Structural Similarity. J. Mar. Sci. Eng. 2021, 9, 212. https://doi.org/10.3390/jmse9020212
Danial SN, Smith D, Veitch B. A Method to Detect Anomalies in Complex Socio-Technical Operations Using Structural Similarity. Journal of Marine Science and Engineering. 2021; 9(2):212. https://doi.org/10.3390/jmse9020212
Chicago/Turabian StyleDanial, Syed Nasir, Doug Smith, and Brian Veitch. 2021. "A Method to Detect Anomalies in Complex Socio-Technical Operations Using Structural Similarity" Journal of Marine Science and Engineering 9, no. 2: 212. https://doi.org/10.3390/jmse9020212
APA StyleDanial, S. N., Smith, D., & Veitch, B. (2021). A Method to Detect Anomalies in Complex Socio-Technical Operations Using Structural Similarity. Journal of Marine Science and Engineering, 9(2), 212. https://doi.org/10.3390/jmse9020212