Considerations for Comparing Video Game AI Agents with Humans


{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
Camera view. Humans play StarCraft through a screen that displays only part of the map along with a high-level view of the entire map (to avoid information overload, for example). The agent interacts with the game through a similar camera-like interface, which naturally imposes an economy of attention, so that the agent chooses which area it fully sees and interacts with. The agent can move the camera as an action. […]
Indeed, it was generally agreed that “forcing AlphaStar to use a camera helped level the playing field” [16]. As such, even with the camera limitations later added to AlphaStar [8], the agent is able to click on objects on the screen that are not actually visible to human experts (i.e., objects at the end of the screen with only a few viewable pixels) ([17] confirmed as replay “AlphaStarMid_053_TvZ”). Even with these constraints, it can be debated whether the limitations imposed on AlphaStar are sufficient given that humans have considerable limitations in their sensory and motor abilities, for instance: (1) the inability to actively attend to all of the presented visual information simultaneously; and (2) less targeting control of the temporal and spatial precision of their actions. In human experts, declines in performance can emerge as early as at 24 years old [18]. For instance, even though humans and AlphaStar could be matched to the same APM distribution characteristics, human actions are not all efficiently made—unlike AlphaStar. In a preliminary show-match [19,20], AlphaStar was able to demonstrate superhuman control, “it could attack with a big group of Stalkers, have the front row of stalkers take some damage, and then blink them to the rear of the army before they got killed” [16] (watch the demonstration with commentary [20] from 1:30:15). Humans have previously used this strategy as well, but are unable to have the spatial and temporal precision to execute it as well as AlphaStar is able. In another example, AlphaStar can exhibit precision control of multiple groups of units beyond human capabilities (e.g., see 1:41:35 and 1:43:30 in the previous video [20]). Clearly, human performance, even that of skilled humans, is not a suitable benchmark for modern AI agents; they simply are not matched in the sensorimotor processing and precision necessary for comparable real-time performance. Note, however, I am not critiquing the differences in the amount of experience between humans and AI agents, e.g., “During training, each agent experienced up to 200 years of real-time StarCraft play”. While AI agents often are provided with orders of magnitude more experience than human agents in the tested scenario, humans benefit from a biological architecture that makes this relative difference hard to evaluate directly (e.g., genetic and physiological optimisation; see Zador [21] and LeDoux [22]). Moreover, I suggest that the principle measure of interest is not how quickly an agent reaches its current level of performance (e.g., number of matches or years of play), but the decision-making strategies that were present at the point of evaluation. Notably, these highlighted issues do not apply to turn-based strategy games, such as chess or Go, only to real-time strategy games. Moreover, it is also important to acknowledge that these concerns about AlphaStar’s lack of limitations (e.g., camera view and APM limits) were not as relevant to previous StarCraft AI agents, which were not nearly as able to defeat human players [23].APM limits. Humans are physically limited in the number of actions per minute (APM) they can execute. Our agent has a monitoring layer that enforces APM limitations. This introduces an action economy that requires actions to be prioritized. […] [A]gent actions are hard to compare with human actions (computers can precisely execute different actions from step to step).
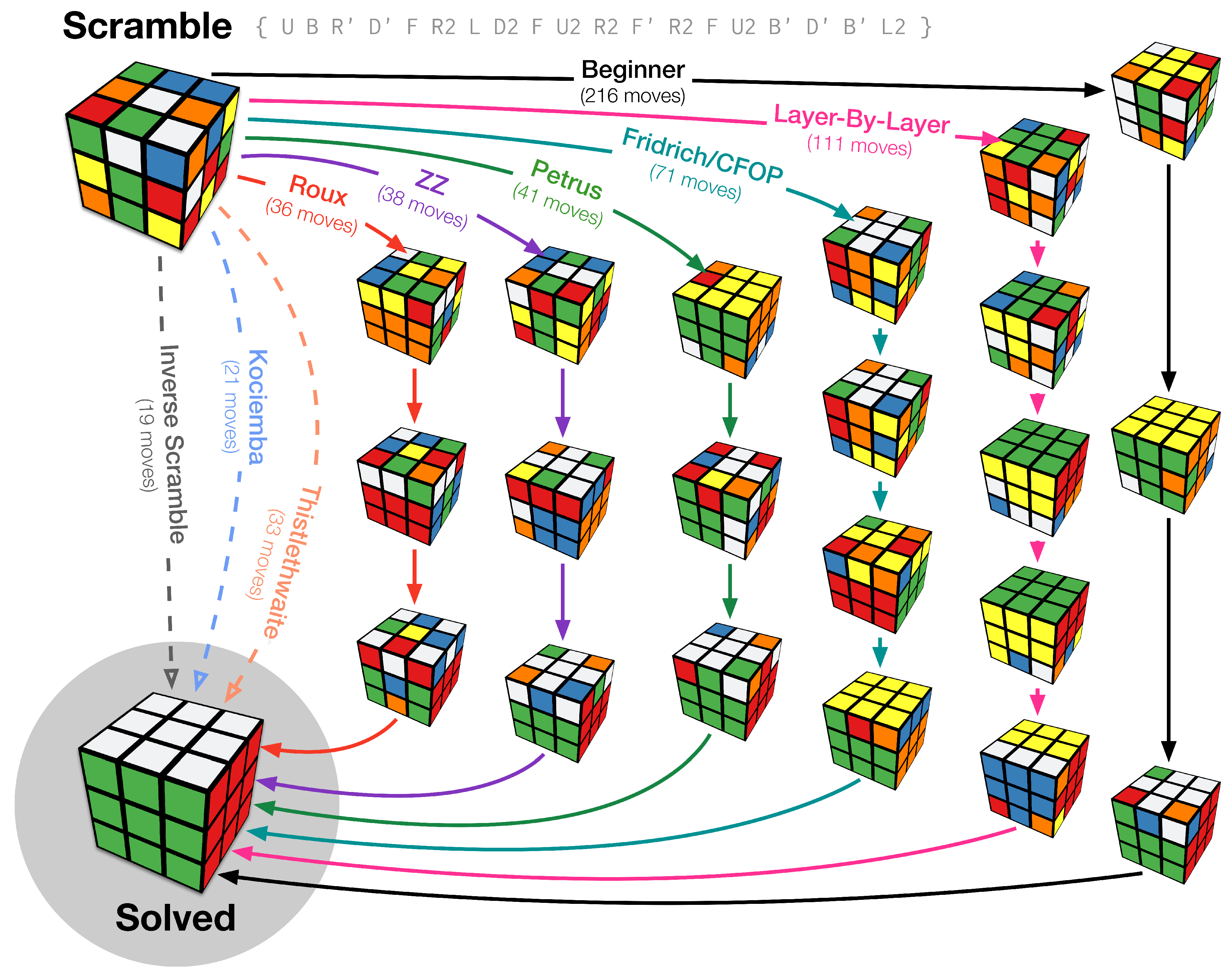
2. Learning from the Cube
3. Developing Better Benchmarks for AI Agents
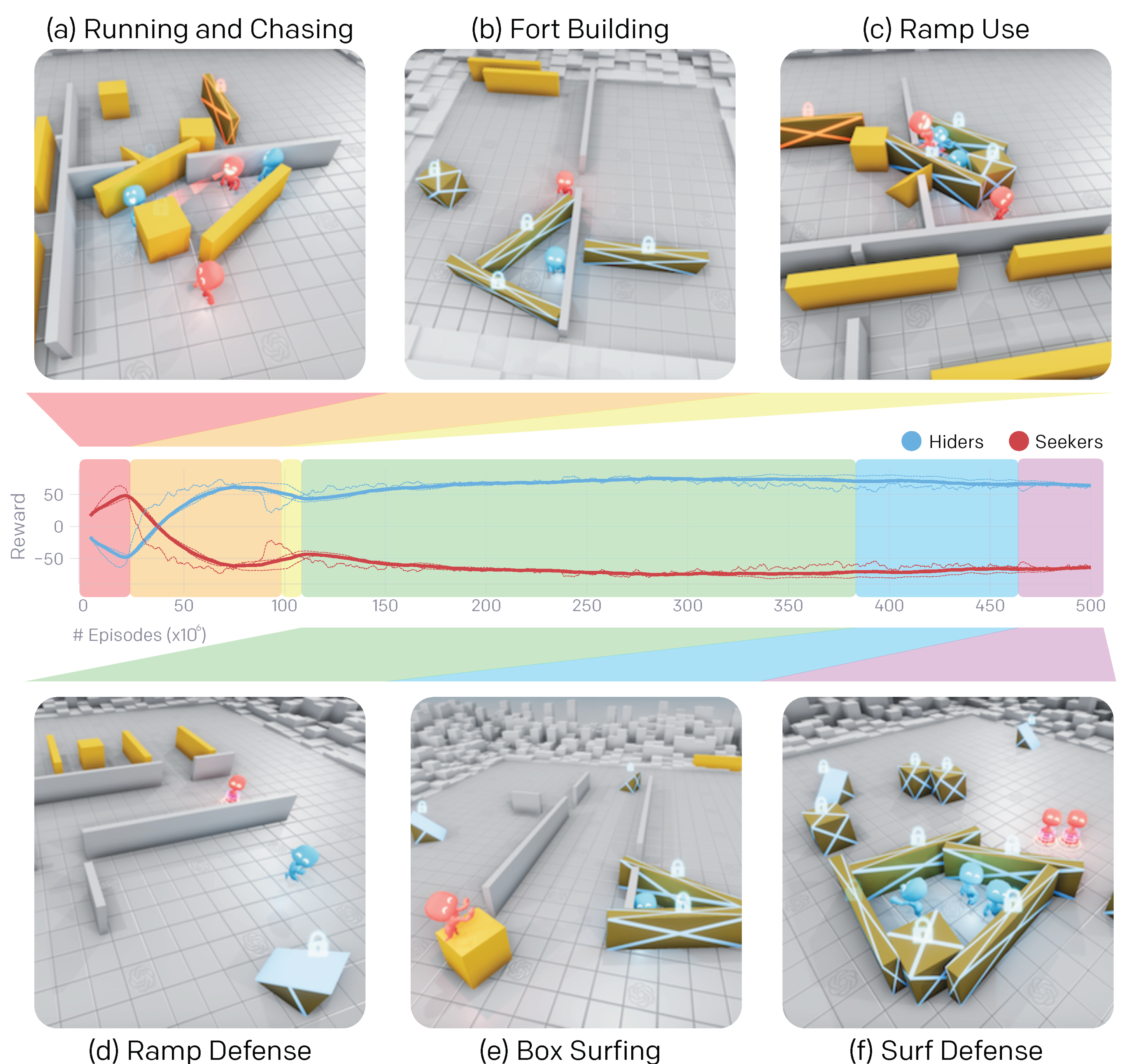
4. AI Agents Performing beyond Human Capabilities
5. Conclusions
Funding
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| APM | Actions per minute |
| CFOP | Cross, F2L (first two layers), OLL (orient last layer), PLL (permute last layer); Rubik’s Cube solving method |
| RTS | Real-time strategy |
| TAS | Tool-assisted speed-run |
References
- Whiteson, S.; Tanner, B.; White, A. Report on the 2008 Reinforcement Learning Competition. AI Mag. 2010, 31, 81–94. [Google Scholar] [CrossRef] [Green Version]
- Togelius, J.; Karakovskiy, S.; Koutnik, J.; Schmidhuber, J. Super Mario evolution. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence and Games, Milano, Italy, 7–10 September 2009; pp. 156–161. [Google Scholar] [CrossRef]
- Karakovskiy, S.; Togelius, J. The Mario AI Benchmark and Competitions. IEEE Trans. Comput. Intell. AI Games 2012, 4, 55–67. [Google Scholar] [CrossRef] [Green Version]
- Bellemare, M.G.; Naddaf, Y.; Veness, J.; Bowling, M. The Arcade Learning Environment: An evaluation platform for general agents. J. Artif. Intell. Res. 2013, 47, 253–279. [Google Scholar] [CrossRef]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Rocki, K.M. Nintendo Learning Environment. 2019. Available online: https://github.com/krocki/gb (accessed on 9 May 2020). [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef] [PubMed]
- Dann, M.; Zambetta, F.; Thangarajah, J. Deriving subgoals autonomously to accelerate learning in sparse reward domains. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 881–889. [Google Scholar] [CrossRef] [Green Version]
- Ecoffet, A.; Huizinga, J.; Lehman, J.; Stanley, K.O.; Clune, J. Go-Explore: A new approach for hard-exploration problems. arXiv 2019, arXiv:1901.10995. [Google Scholar]
- Lewis, J.; Trinh, P.; Kirsh, D. A corpus analysis of strategy video game play in Starcraft: Brood War. In Proceedings of the Annual Meeting of the Cognitive Science Society, Boston, MA, USA, 20–23 July 2011; Volume 33, pp. 687–692. [Google Scholar]
- Ontanon, S.; Synnaeve, G.; Uriarte, A.; Richoux, F.; Churchill, D.; Preuss, M. A Survey of Real-Time Strategy Game AI Research and Competition in StarCraft. IEEE Trans. Comput. Intell. AI Games 2013, 5, 293–311. [Google Scholar] [CrossRef] [Green Version]
- Robertson, G.; Watson, I. A review of real-time strategy game AI. AI Mag. 2014, 35, 75. [Google Scholar] [CrossRef] [Green Version]
- Baumgarten, R. Infinite Mario AI. 2009. Available online: https://www.youtube.com/watch?v=0s3d1LfjWCI (accessed on 25 July 2019).
- Jaderberg, M. AlphaStar Agent Visualisation. 2019. Available online: https://www.youtube.com/watch?v=HcZ48JDamyk (accessed on 25 July 2019).
- Lee, T.B. An AI Crushed Two Human Pros at StarCraft—But It Wasn’t a Fair Fight. Ars Technica. 2019. Available online: https://arstechnica.com/gaming/2019/01/an-ai-crushed-two-human-pros-at-starcraft-but-it-wasnt-a-fair-fight (accessed on 30 January 2019).
- Heijnen, S. StarCraft 2: Lowko vs AlphaStar. 2019. Available online: https://www.youtube.com/watch?v=3HqwCrDBdTE (accessed on 22 November 2019).
- Thompson, J.J.; Blair, M.R.; Henrey, A.J. Over the Hill at 24: Persistent Age-Related cognitive-motor decline in reaction times in an ecologically valid video game task begins in early adulthood. PLoS ONE 2014, 9, e94215. [Google Scholar] [CrossRef]
- Vinyals, O.; Babuschkin, I.; Chung, J.; Mathieu, M.; Jaderberg, M.; Czarnecki, W.M.; Dudzik, A.; Huang, A.; Georgiev, P.; Powell, R.; et al. AlphaStar: Mastering the Real-Time Strategy Game StarCraft II. 2019. Available online: https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/ (accessed on 24 January 2019).
- DeepMind. StarCraft II Demonstration. 2019. Available online: https://www.youtube.com/watch?v=cUTMhmVh1qs (accessed on 25 January 2019).
- Zador, A.M. A critique of pure learning and what artificial neural networks can learn from animal brains. Nat. Commun. 2019, 10, 3770. [Google Scholar] [CrossRef] [Green Version]
- LeDoux, J. The Deep History of Ourselves: The Four-Billion-Year Story of How We Got Conscious Brains; Viking: New York, NY, USA, 2019. [Google Scholar]
- Risi, S.; Preuss, M. Behind DeepMind’s AlphaStar AI that reached grandmaster level in StarCraft II: Interview with Tom Schaul, Google DeepMind. Kunstl. Intell. 2020, 34, 85–86. [Google Scholar] [CrossRef]
- High Score. Seaquest (Atari 2600 Expert/A) High Score: 276,510 Curtferrell (Camarillo, United States). Available online: http://highscore.com/games/Atari2600/Seaquest/578 (accessed on 29 May 2019).
- TASVideos. [2599] A2600 Seaquest (USA) “Fastest 999999” by Morningpee in 01:39.8. Available online: http://tasvideos.org/2599M.html (accessed on 29 May 2019).
- High Score. Kangaroo (Atari 2600) High Score: 55,600 BabofetH (Corregidora, Mexico). Available online: http://highscore.com/games/Atari2600/Kangaroo/652 (accessed on 29 May 2019).
- Toromanoff, M.; Wirbel, E.; Moutarde, F. Is deep reinforcement learning really superhuman on Atari? Leveling the playing field. arXiv 2019, arXiv:1908.04683. [Google Scholar]
- Hessel, M.; Modayil, J.; Hasselt, V.H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, G.M.; Silver, D. Rainbow: Combining improvements in deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32, pp. 3215–3222. [Google Scholar]
- Kapturowski, S.; Ostrovski, G.; Dabney, W.; Quan, J.; Munos, R. Recurrent experience replay in distributed reinforcement learning. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Schrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S.; Guez, A.; Lockhart, E.; Hassabis, D.; Graepel, T.; et al. Mastering Atari, Go, chess and shogi by planning with a learned model. arXiv 2020, arXiv:1911.08265. [Google Scholar]
- Korf, R.E. Sliding-tile puzzles and Rubik’s Cube in AI research. IEEE Intell. Syst. 1999, 14, 8–12. [Google Scholar]
- El-Sourani, N.; Hauke, S.; Borschbach, M. An evolutionary approach for solving the Rubik’s Cube incorporating exact methods. Lect. Notes Comput. Sci. 2010, 6024, 80–89. [Google Scholar] [CrossRef] [Green Version]
- Agostinelli, F.; McAleer, S.; Shmakov, A.; Baldi, P. Solving the Rubik’s Cube with deep reinforcement learning and search. Nat. Mach. Intell. 2019, 1, 356–363. [Google Scholar] [CrossRef] [Green Version]
- Rubik’s Cube You Can Do the Rubik’s Cube. 2020. Available online: https://www.youcandothecube.com/solve-the-cube/ (accessed on 5 April 2020).
- Ruwix. Different Rubik’s Cube Solving Methods. Available online: https://ruwix.com/the-rubiks-cube/different-rubiks-cube-solving-methods/ (accessed on 16 April 2020).
- Thistlewaite, M.B. 45–52 Move Strategy for Solving the Rubik’s Cube. Technical Report, University of Tennessee in Knoxville. 1981. Available online: https://www.jaapsch.net/puzzles/thistle.htm (accessed on 25 April 2020).
- Rokicki, T.; Kociemba, H.; Davidson, M.; Dethridge, J. God’s Number Is 20. 2010. Available online: http://cube20.org (accessed on 25 April 2020).
- Yang, B.; Lancaster, P.E.; Srinivasa, S.S.; Smith, J.R. Benchmarking robot manipulation With the Rubik’s Cube. IEEE Robot. Autom. Lett. 2020, 5, 2094–2099. [Google Scholar] [CrossRef]
- OpenAI; Akkaya, I.; Andrychowicz, M.; Chociej, M.; Litwin, M.; McGrew, B.; Petron, A.; Paino, A.; Plappert, M.; Powell, G.; et al. Solving Rubik’s Cube with a Robot Hand. arXiv 2019, arXiv:1910.07113. [Google Scholar]
- TASVideos. Tool-Assisted Game Movies: When Human Skills Are Just Not Enough. Available online: http://tasvideos.org (accessed on 29 May 2019).
- Madan, C.R. Augmented memory: A survey of the approaches to remembering more. Front. Syst. Neurosci. 2014, 8, 30. [Google Scholar] [CrossRef] [Green Version]
- LiMieux, P. From NES-4021 to moSMB3.wmv: Speedrunning the serial interface. Eludamos 2014, 8, 7–31. [Google Scholar]
- Potter, P. Saving Milliseconds and Wasting Hours: A Survey of Tool-Assisted Speedrunning. Electromagn. Field 2016. Available online: https://www.youtube.com/watch?v=6uzWxLuXg7Y (accessed on 16 May 2019).
- Chrabąszcz, P.; Loshchilov, I.; Hutter, F. Back to basics: Benchmarking canonical evolution strategies for playing Atari. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence. International Joint Conferences on Artificial Intelligence Organization, Stockholm, Sweden, 13–19 July 2018; pp. 1419–1426. Available online: https://www.youtube.com/watch?v=meE5aaRJ0Zs (accessed on 2 March 2018). [CrossRef] [Green Version]
- Sampson, G. Q*bert Scoring Glitch on Console. 2018. Available online: https://www.youtube.com/watch?v=VGyeUuysyqg (accessed on 22 July 2020).
- Murphy, T. The first level of Super Mario Bros. is easy with lexicographic orderings and time travel…after that it gets a little tricky. In Proceedings of the 2013 SIGBOVIK Conference, Kaohsiung, Taiwan, 1 April 2013; pp. 112–133. Available online: http://tom7.org/mario/ (accessed on 22 July 2020).
- Lehman, J.; Clune, J.; Misevic, D.; Adami, C.; Altenberg, L.; Beaulieu, J.; Bentley, P.J.; Bernard, S.; Beslon, G.; Bryson, D.M.; et al. The surprising creativity of digital evolution: A collection of anecdotes from the evolutionary computation and artificial life research communities. arXiv 2019, arXiv:1803.03453. [Google Scholar]
- Baker, B.; Kanitscheider, I.; Markov, T.; Wu, Y.; Powell, G.; McGrew, B.; Mordatch, I. Emergent tool use from multi-agent autocurricula. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26 April–1 May 2020; Available online: https://iclr.cc/virtual_2020/poster_SkxpxJBKwS.html (accessed on 5 May 2020).
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- DeepMind. AlphaGo: The Movie. 2017. Available online: https://www.youtube.com/watch?v=WXuK6gekU1Y (accessed on 14 August 2020).
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Yonhap News Agency. Go Master Lee Says He Quits Unable to Win over AI Go Players. 2019. Available online: https://en.yna.co.kr/view/AEN20191127004800315 (accessed on 15 August 2020).
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [Green Version]
- Dreyfus, H.L. What Computers Can’t Do; Harper & Row: New York, NY, USA, 1972. [Google Scholar]
- Marcus, G.; Davis, E. Rebooting AI; Pantheon: Roman, Italy, 2019. [Google Scholar]
- Miller, T.; Howe, P.; Sonenberg, L. Explainable AI: Beware of Inmates Running the Asylum. In Proceedings of the IJCAI 2017 Workshop on Explainable Artificial Intelligence (XAI), Melbourne, Australia, 20 August 2017; Available online: https://people.eng.unimelb.edu.au/tmiller/pubs/explanation-inmates.pdf (accessed on 12 May 2020).
- Goebel, R.; Chander, A.; Holzinger, K.; Lecue, F.; Akata, Z.; Stumpf, S.; Kieseberg, P.; Holzinger, A. Explainable AI: The New 42? Lect. Notes Comput. Sci. 2018, 11015, 295–303. [Google Scholar] [CrossRef] [Green Version]
- Holzinger, A. From Machine Learning to Explainable AI. In Proceedings of the IEEE 2018 World Symposium on Digital Intelligence for Systems and Machines (DISA), Kosice, Slovakia, 23–25 August 2018. [Google Scholar] [CrossRef]
- Peters, D.; Robinson, K.V.D.; Calvo, R.A. Responsible AI–Two Frameworks for Ethical Design Practice. IEEE Trans. Technol. Soc. 2020, 1, 34–47. [Google Scholar] [CrossRef]
- Asimov, I. I, Robot; Gnome Press: New York, NY, USA, 1950. [Google Scholar]
- Gerrold, D. When HARLIE Was One; Ballantine Books: New York, NY, USA, 1972. [Google Scholar]
- Čapek, K. R.U.R.: Rossum’s Universal Robots; Project Gutenberg: Salt Lake City, UT, USA, 1921; Available online: http://www.gutenberg.org/files/59112/59112-h/59112-h.htm (accessed on 28 October 2019).
- Gold, K. Choice of Robots; Choice of Games: San Franciscio, CA, USA, 2014; Available online: https://www.choiceofgames.com/robots/ (accessed on 31 August 2015).
- Olah, C.; Mordvintsev, A.; Schubert, L. Feature Visualization. Distill 2017. [Google Scholar] [CrossRef]
- Olah, C.; Satyanarayan, A.; Johnson, I.; Carter, S.; Schubert, L.; Ye, K.; Mordvintsev, A. The Building Blocks of Interpretability. Distill 2018. [Google Scholar] [CrossRef]
- Carter, S.; Armstrong, Z.; Schubert, L.; Johnson, I.; Olah, C. Exploring Neural Networks with Activation Atlases. Distill 2019. [Google Scholar] [CrossRef]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Ding, Y.; Hu, S.X.; Niemier, M.; Cong, J.; Hu, Y.; Shi, Y. Scaling for edge inference of deep neural networks. Nat. Electron. 2018, 1, 216–222. [Google Scholar] [CrossRef]



© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Madan, C.R. Considerations for Comparing Video Game AI Agents with Humans. Challenges 2020, 11, 18. https://doi.org/10.3390/challe11020018
Madan CR. Considerations for Comparing Video Game AI Agents with Humans. Challenges. 2020; 11(2):18. https://doi.org/10.3390/challe11020018
Chicago/Turabian StyleMadan, Christopher R. 2020. "Considerations for Comparing Video Game AI Agents with Humans" Challenges 11, no. 2: 18. https://doi.org/10.3390/challe11020018
APA StyleMadan, C. R. (2020). Considerations for Comparing Video Game AI Agents with Humans. Challenges, 11(2), 18. https://doi.org/10.3390/challe11020018