A Method for Road Extraction from High-Resolution Remote Sensing Images Based on Multi-Kernel Learning

Abstract
:1. Introduction
- (1)
- Pixel-spectral classification (PSC) [21] is widely used in early road extraction; this method classifies an image into the road group and the non-road group according to the pixel spectral information of the image.
- (2)
- Spectral-spatial classification (SSC) [9] is a two-step method for extracting road skeleton from HRRS images. In the first step, a feature vector is constructed by integrating spectral–spatial classification and shape features. The SVM classifier is used to segment the imagery into two classes: The road class and the non-road class. In the second step, the road class is refined by utilizing homogenous and shape features.
- (3)
- Region-based classification (RBC) [22] is a semi-automatic approach that first segments the image and combines adjacent segments by Full Lambda Schedule. The SVM classifier is then used to classify the segmented region by spatial, spectral, and textural features of the image, and the initial road skeleton is obtained. Finally, the quality of the detected road skeleton is improved by using morphological operators.
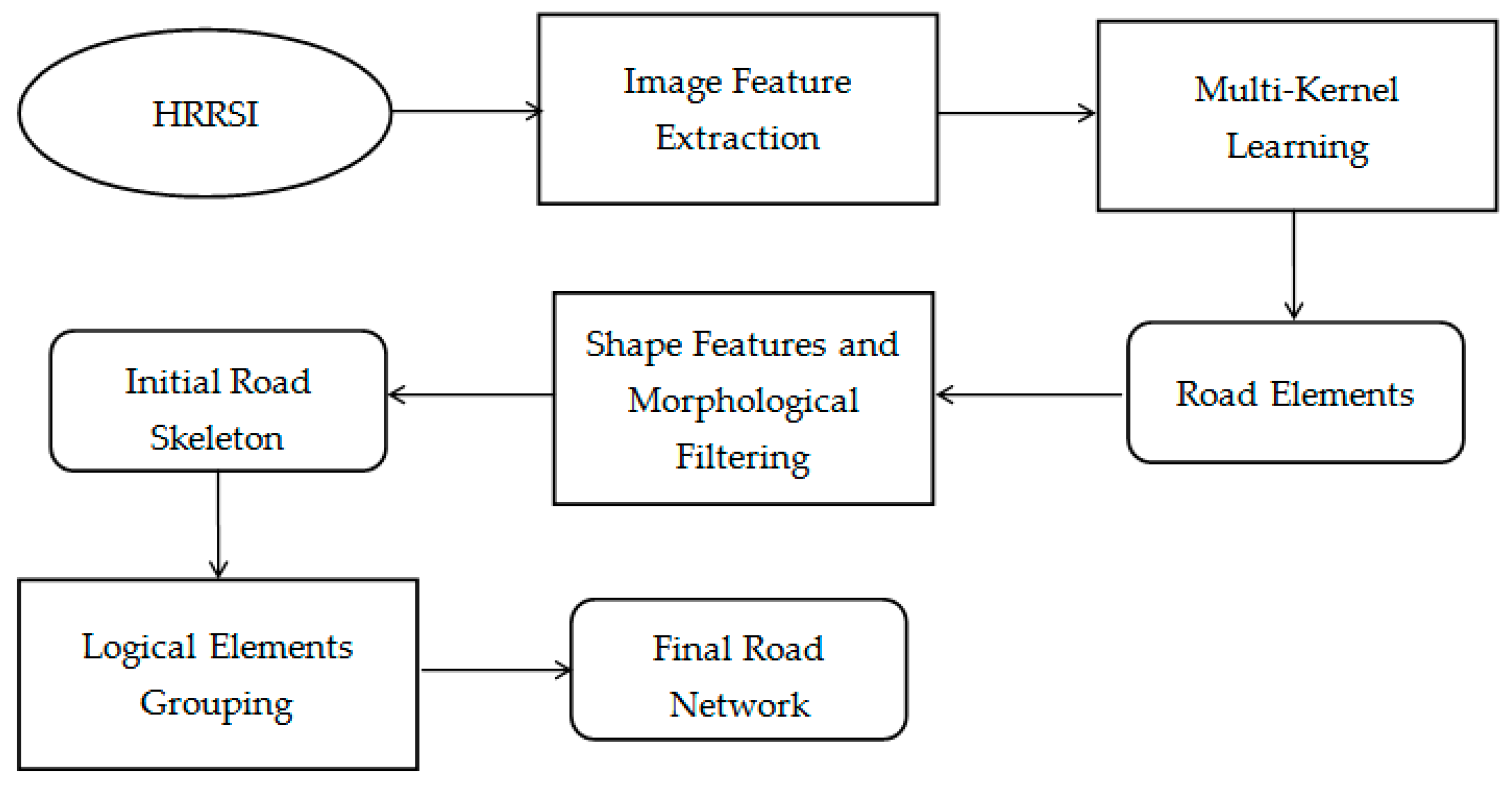
2. Proposed Methodology
- (1)
- The features of the road in HRRS images and extract image features suitable for describing road are analyzed. Multi-scale and multi-direction non-subsampled contourlet transform (NSCT) is used to describe the texture features and linear features of the road. A color moment matrix is used to describe the spectral feature.
- (2)
- Road elements are roughly extracted by multi-kernel learning and multi-feature fusing (MKL). About 8% of the road samples and 10% of the non-road samples are taken for classification learning, and the MKL-SVM classifier is obtained to divide the image into two categories: Road and non-road. This step provides candidate road elements.
- (3)
- Road elements are precisely extracted by road shape features and morphological filtering. This step combines such features as the slenderness of the road’s shape, the compactness of ground objects, and the area of surroundings to build road shape indexes for automatically filtering out the interference of non-road noises. A series of morphological operations are also carried out to regulate the incomplete structures of the road elements. This step provides the initial road skeleton.
- (4)
- Road elements are grouped by the road element connection penalty factor, which is constructed based on the prior knowledge and topological features of the road. This step obtains the connected and complete road network.
2.1. Image Features Extraction
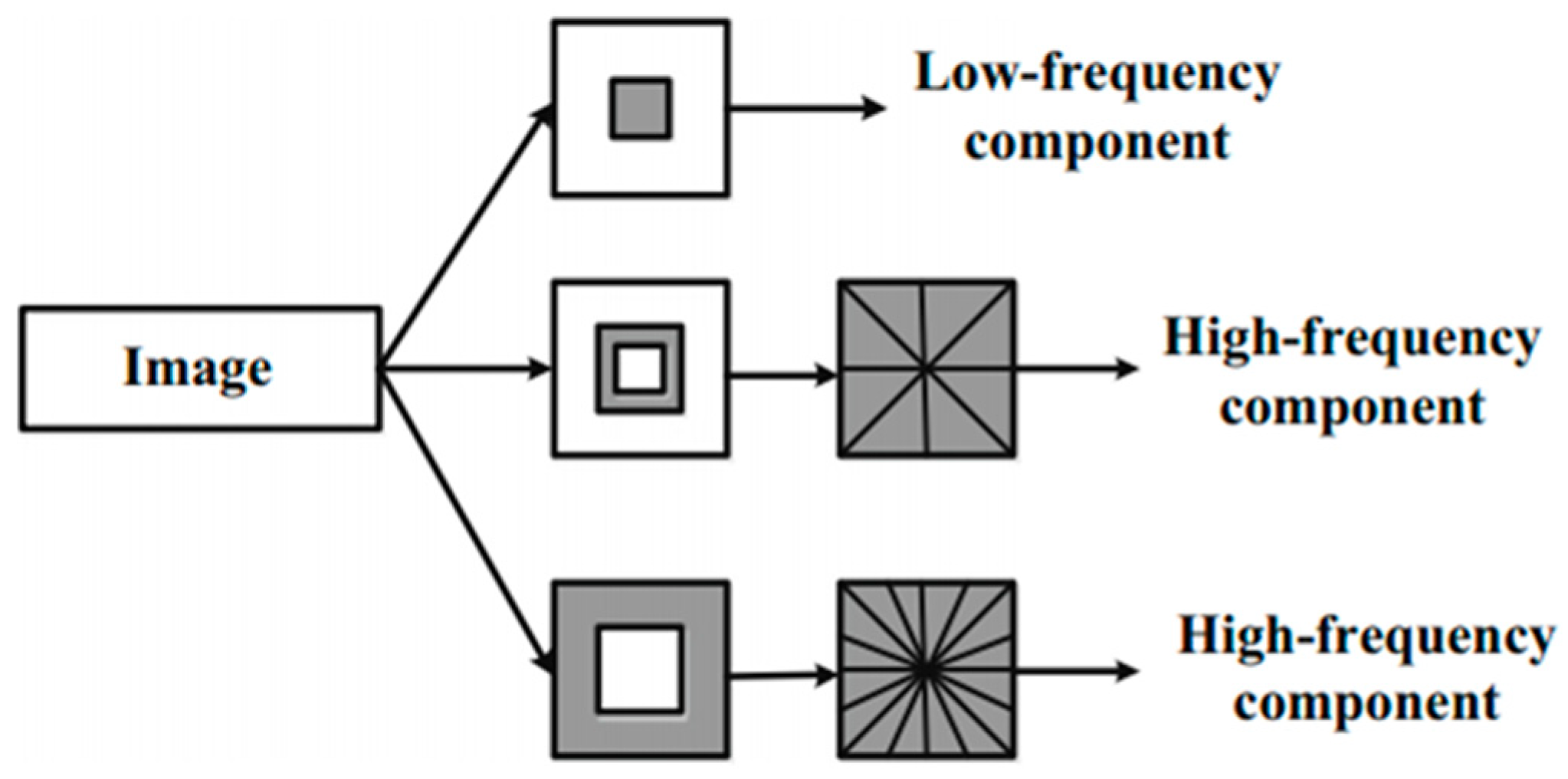
2.1.1. Non-Subsampled Contourlet Transform
- Features of low frequency sub-band.
- (1)
- MeanIn Equation (1), ILow(x,y) denotes the matrix of low frequency sub-band coefficients, M, N denotes the number of rows and columns of coefficients in the sub-band respectively, M, and N is the dimension of the coefficient matrix.
- (2)
- Variance
- (3)
- HomogeneityThe low frequency sub-band reflects the information of the image’s basic features. The texture feature vector constructed by the mean (μLow), the variance (δLow), and the homogeneity (hLow) can be expressed as:
- Features of high frequency sub-band.After the image is transformed by NSCT, multi-directional high frequency sub-bands of different scales are obtained. The coefficient magnitude sequence of these sub-bands is calculated as the features of high frequency sub-bands.
- (1)
- Gradient energy
- (2)
- Variancewhere μH is the mean value of the high frequency sub-bands.
2.1.2. Spectral Feature Extraction
2.2. Image Classification Based on Multi-Kernel Learning
2.3. Road Skeleton Extraction Based on Shape Feature and Morphology
- (1)
- Roads do not have small areas and regions with small areas can be regarded as noise and should be removed.
- (2)
- Compactness is defined as 4 .π. A/P2, where P is the perimeter of the region and A is the area of the region. Compactness is in the range of (0, 1].
- (3)
- Roads are narrow and long. Length–width ratio is the aspect ratio of the minimum-enclosing rectangle.
2.4. Road Elements Grouping
- (1)
- Distance, including absolute distance and vertical distance. The absolute distance is the distance between the two nearest end points of the two road elements. The vertical distance is the distance from the two nearest endpoints in the vertical direction between the two road elements. Both the absolute and the vertical distance should be lower than a threshold.
- (2)
- Width difference. The difference of average width between two adjacent elements should be lower than a threshold.
- (3)
- Direction difference. The direction of a road section is defined as the vector connecting the two end points of its center-line. The direction difference, that is, the angle between the direction vectors of the two road sections, should be lower than a threshold for the two road sections to be connected.
- (4)
- Homogeneity. The road has strong homogeneity. Considering the similar spectral characteristics of adjacent road elements, this paper defines homogeneity as the color mean of each element. Homogeneity difference of the adjacent elements should be lower than a threshold.
3. Experimental Results and Discussions
3.1. Tests of Different Study Areas
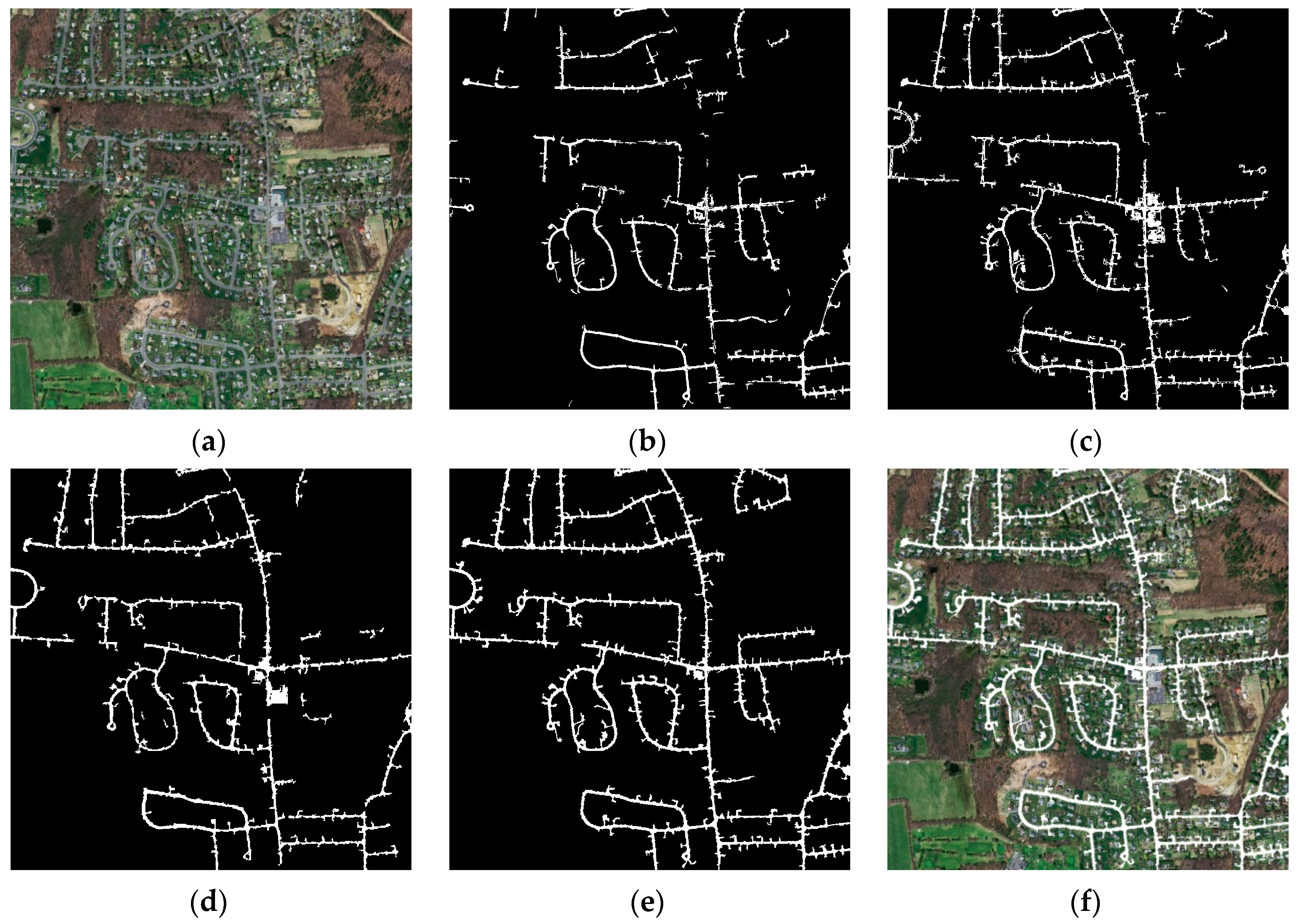
3.1.1. Study Area I
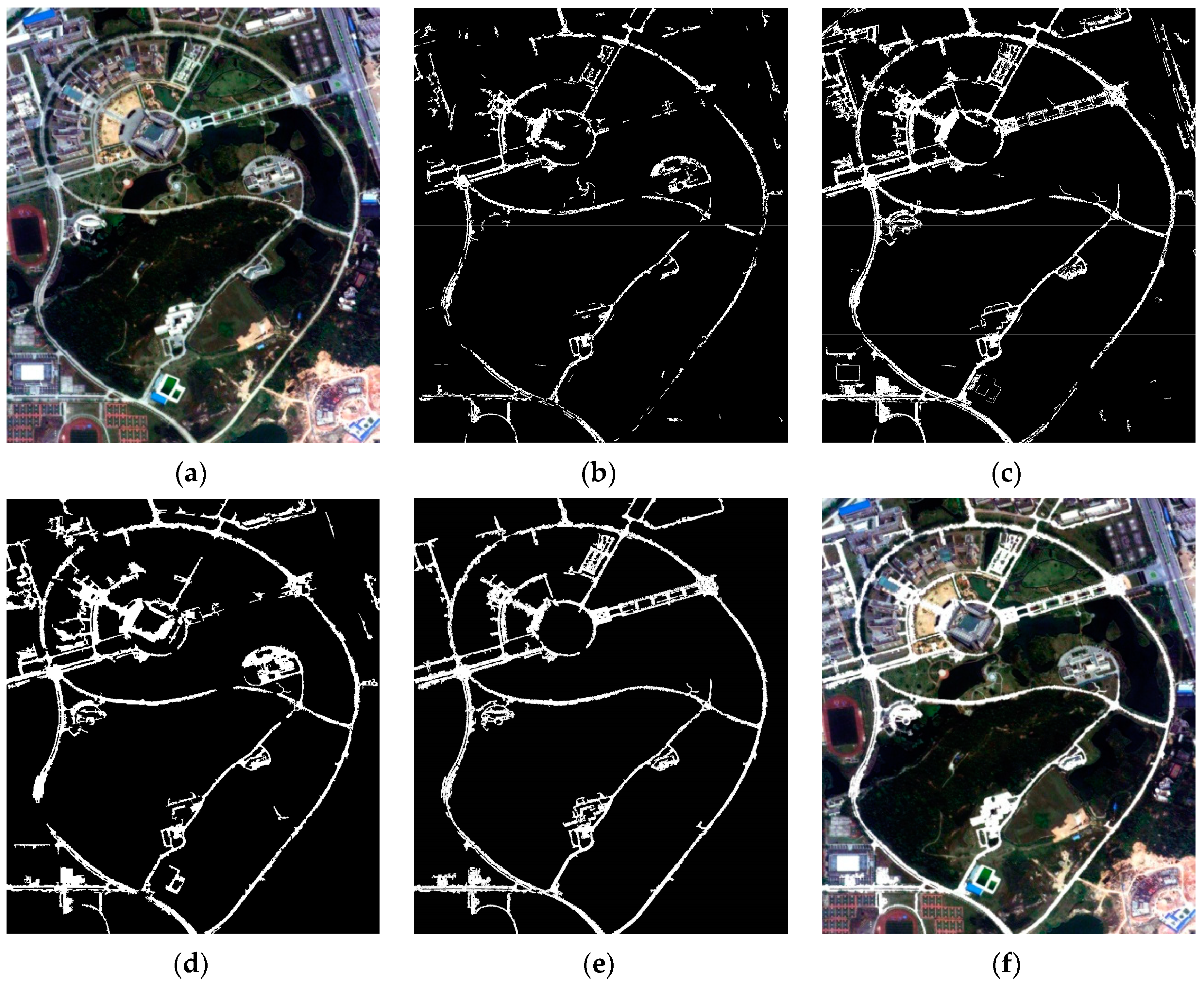
3.1.2. Study Area II
3.1.3. Study Area III
3.1.4. Study Area IV
3.2. Experiment Results
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bonnefon, R.; Dhérété, P.; Desachy, J. Geographic information system updating using remote sensing images. Pattern Recognit. Lett. 2002, 23, 1073–1083. [Google Scholar] [CrossRef]
- Li, Q.; Chen, L.; Li, M.; Shaw, S.L. A Sensor-Fusion Drivable-Region and Lane-Detection System for Autonomous Vehicle Navigation in Challenging Road Scenarios. IEEE Trans. Veh. Technol. 2014, 63, 540–555. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Bruzzone, L.; Carlin, L. A Multilevel Context-Based System for Classification of Very High Spatial Resolution Images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2587–2600. [Google Scholar] [CrossRef] [Green Version]
- Sghaier, M.O.; Lepage, R. Road Extraction from Very High Resolution Remote Sensing Optical Images Based on Texture Analysis and Beamlet Transform. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 9, 1946–1958. [Google Scholar] [CrossRef]
- Das, S.; Mirnalinee, T.T.; Varghese, K. Use of Salient Features for the Design of a Multistage Framework to Extract Roads from High-Resolution Multispectral Satellite Images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3906–3931. [Google Scholar] [CrossRef]
- Wang, W.; Yang, N.; Zhang, Y.; Wang, F.; Cao, T.; Eklund, P. A review of road extraction from remote sensing images. J. Traffic Transp. Eng. 2016, 3, 271–282. [Google Scholar] [CrossRef] [Green Version]
- Yager, N.; Sowmya, A. Support vector machines for road extraction from remotely sensed images. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Groningen, The Netherlands, 25–27 August 2003; pp. 285–292. [Google Scholar]
- Shi, W.; Miao, Z.; Wang, Q.; Zhang, H. Spectral-spatial classification and shape features for urban road centerline extraction. IEEE Geosci. Remote Sens. Lett. 2014, 11, 788–792. [Google Scholar]
- Yuan, J.; Wang, D.; Wu, B.; Yan, L. LEGION-based automatic road extraction from satellite imagery. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4528–4538. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R. Hierarchical graph-based segmentation for extracting road networks from high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2017, 126, 245–260. [Google Scholar] [CrossRef]
- Li, M.; Stein, A.; Bijker, W.; Zhan, Q. Region-based urban road extraction from VHR satellite images using Binary Partition Tree. Int. J. Appl. Earth Obs. Geoinf. 2016, 44, 217–225. [Google Scholar] [CrossRef]
- Berlemont, S.; Olivo-Marin, J.C. Combining Local Filtering and Multiscale Analysis for Edge, Ridge, and Curvilinear Objects Detection. IEEE Trans. Image Process. 2010, 19, 74–84. [Google Scholar] [CrossRef] [PubMed]
- Silva, C.R.D.; Silva Centeno, J.A.; Henriques, M.J. Automatic road extraction in rural areas, based on the Radon transform using digital images. Can. J. Remote Sens. 2010, 36, 737–749. [Google Scholar] [CrossRef]
- Zang, Y.; Wang, C.; Yu, Y.; Luo, L. Joint Enhancing Filtering for Road Network Extraction. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1511–1525. [Google Scholar] [CrossRef]
- Vosselman, G.; Knecht, J. Road tracing by profile matching and Kalman filtering. In Automatic Extraction of Man-Made Objects from Aerial and Space Images; Birkhäuser Basel: Basel, Switzerland, 1995; pp. 265–274. [Google Scholar]
- Koutaki, G.; Uchimura, K. Automatic road extraction based on cross detection in suburb. In Proceedings of the International Society for Optics and Photonics, San Jose, CA, USA, 21 May 2004; pp. 337–344. [Google Scholar]
- Hu, J.; Razdan, A.; Femiani, J.C.; Cui, M.; Wonka, P. Road Network Extraction and Intersection Detection from Aerial Images by Tracking Road Footprints. IEEE Trans. Geosci. Remote Sens. 2007, 45, 4144–4157. [Google Scholar] [CrossRef]
- Burges, C.J.C. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Miao, Z.; Shi, W.; Samat, A.; Lisini, G. Information Fusion for Urban Road Extraction from VHR Optical Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 9, 1817–1829. [Google Scholar] [CrossRef]
- Song, M.; Civco, D. Road extraction using SVM and image segmentation. Photogramm. Eng. Remote Sens. 2004, 70, 1365–1371. [Google Scholar] [CrossRef] [Green Version]
- Bakhtiari, H.R.R.; Abdollahi, A.; Rezaeian, H. Semi automatic road extraction from digital images. Egypt. J. Remote Sens. Space Sci. 2017, 20, 117–121. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zhang, Z.; Wang, Y. JointNet: A Common Neural Network for Road and Building Extraction. Remote Sens. 2019, 11, 696. [Google Scholar] [CrossRef] [Green Version]
- Gao, L.; Song, W.; Dai, J.; Chen, Y. Road Extraction from High-Resolution Remote Sensing Imagery Using Refined Deep Residual Convolutional Neural Network. Remote Sens. 2019, 11, 552. [Google Scholar] [CrossRef] [Green Version]
- Cheng, M.; Hou, Q.; Zhang, S.; Rosin, P.L. Intelligent visual media processing: When graphics meets vision. J. Comput. Sci. Technol. 2017, 32, 110–121. [Google Scholar] [CrossRef]
- Cheng, M.; Liu, Y.; Hou, Q.; Bian, J.; Torr, P.; Hu, S.; Tu, Z. HFS: Hierarchical feature selection for efficient image segmentation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 867–882. [Google Scholar]
- Cheng, G.; Wu, C.; Huang, Q.; Meng, Y.; Shi, J.; Chen, J.; Yan, D. Recognizing road from satellite images by structured neural network. Neurocomputing 2019, 356, 131–141. [Google Scholar] [CrossRef]
- Cunha, A.L.D.; Zhou, J.; Do, M.N. The Nonsubsampled Contourlet Transform: Theory, Design, and Applications. IEEE Trans. Image Process. 2006, 15, 3089–3101. [Google Scholar] [CrossRef] [Green Version]
- Michael, J.S.; Dana, H.B. Color Indexing. Int. J. Comput. Vis. 1991, 7, 11–32. [Google Scholar]
- Stricker, M.A.; Orengo, M. Similarity of Color Images. In Proceedings of the SPIE-The International Society for Optical Engineering, San Jose, CA, USA, 23 March 1995; pp. 381–392. [Google Scholar]
- Song, H.; Triguero, I.; Özcan, E. A review on the self and dual interactions between machine learning and optimisation. Prog. Artif. Intell. 2019, 8, 143–165. [Google Scholar] [CrossRef] [Green Version]
- Zhao, X.; Wang, C.; Su, J.; Wang, J. Research and application based on the swarm intelligence algorithm and artificial intelligence for wind farm decision system. Renew. Energy 2019, 134, 681–697. [Google Scholar] [CrossRef]
- Anandakumar, H.; Umamaheswari, K. A bio-inspired swarm intelligence technique for social aware cognitive radio handovers. Comput. Electr. Eng. 2018, 71, 925–937. [Google Scholar] [CrossRef]
- Dulebenets, M.A. A Comprehensive Evaluation of Weak and Strong Mutation Mechanisms in Evolutionary Algorithms for Truck Scheduling at Cross-Docking Terminals. IEEE Access 2018, 6, 65635–65650. [Google Scholar] [CrossRef]
- Dulebenets, M.A. A Delayed Start Parallel Evolutionary Algorithm for Just-in-Time Truck Scheduling at a Cross-Docking Facility. Int. J. Prod. Econ. 2019, 212, 236–258. [Google Scholar] [CrossRef]
- Govindan, K.; Jafarian, A.; Nourbakhsh, V. Designing a sustainable supply chain network integrated with vehicle routing: A comparison of hybrid swarm intelligence metaheuristics. Comput. Oper. Res. 2019, 110, 220–235. [Google Scholar] [CrossRef]
- Vishwanathan, S.V.N.; Sun, Z.; Ampornpunt, N. Multiple Kernel Learning and the SMO Algorithm. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; pp. 2361–2369. [Google Scholar]
- Bao, J.; Chen, Y.; Yu, L.; Chen, C. A multi-scale kernel learning method and its application in image classification. Neurocomputing 2017, 257, 16–23. [Google Scholar] [CrossRef]
- Luo, F.; Guo, W.; Yu, Y.; Chen, G. A multi-label classification algorithm based on kernel extreme learning machine. Neurocomputing 2017, 260, 313–320. [Google Scholar] [CrossRef]
- Singh, P.P.; Garg, R.D. A two-stage framework for road extraction from high-resolution satellite images by using prominent features of impervious surfaces. Int. J. Remote Sens. 2014, 35, 8074–8107. [Google Scholar] [CrossRef]
- VPLab. Available online: http://www.cse.iitm.ac.in/~sdas/vplab/satellite.html (accessed on 13 June 2014).
- Department of Computer Science University of Toronto. Available online: https://www.cs.toronto.edu/~vmnih/data/mass_roads/train/sat/index.html (accessed on 5 December 2019).
- Wiedemann, C.; Heipke, C.; Mayer, H.; Jamet, O. Empirical evaluation of automatically extracted road axes. In Empirical Evaluation Techniques in Computer Vision; IEEE Computer Society Press: Los Alamitos, CA, USA, 1998; pp. 172–187. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | #1 Image | #2 Image | #3 Image | #4 Image | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NTP | NFN | NFP | NTP | NFN | NFP | NTP | NFN | NFP | NTP | NFN | NFP | |
| PSC | 31,882 | 7871 | 1725 | 144,099 | 49,873 | 9425 | 405,093 | 105,743 | 46,055 | 24,9564 | 115,830 | 22,286 |
| SSC | 35,221 | 4532 | 3295 | 175,934 | 18,038 | 17,772 | 461,796 | 49,040 | 31,249 | 324,756 | 40,638 | 44,410 |
| RBC | 35,897 | 3856 | 3726 | 167,010 | 26,962 | 13,050 | 468,947 | 41,889 | 97,682 | 296,700 | 68,694 | 57,448 |
| Ours | 38,760 | 993 | 3399 | 184,468 | 9504 | 10,878 | 479,150 | 31,686 | 5213 | 333,230 | 32,164 | 35,374 |
| Method | #1 Image | #2 Image | #3 Image | #4 Image | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| E1 (%) | E2 (%) | E3 (%) | E1 (%) | E2 (%) | E3 (%) | E1 (%) | E2 (%) | E3 (%) | E1 (%) | E2 (%) | E3 (%) | |
| PSC | 80.2 | 94.9 | 76.9 | 74.3 | 93.9 | 70.8 | 79.3 | 89.8 | 72.7 | 68.3 | 91.8 | 64.4 |
| SSC | 88.6 | 91.4 | 81.8 | 90.7 | 90.8 | 83.1 | 90.4 | 93.7 | 85.2 | 88.9 | 88.0 | 79.2 |
| RBC | 90.3 | 90.6 | 82.6 | 86.1 | 92.8 | 80.7 | 91.8 | 82.8 | 77.1 | 81.2 | 83.8 | 70.2 |
| Ours | 97.5 | 91.9 | 89.8 | 95.1 | 94.4 | 90.1 | 93.8 | 98.9 | 92.8 | 91.2 | 90.4 | 83.1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, R.; Zeng, Y. A Method for Road Extraction from High-Resolution Remote Sensing Images Based on Multi-Kernel Learning. Information 2019, 10, 385. https://doi.org/10.3390/info10120385
Xu R, Zeng Y. A Method for Road Extraction from High-Resolution Remote Sensing Images Based on Multi-Kernel Learning. Information. 2019; 10(12):385. https://doi.org/10.3390/info10120385
Chicago/Turabian StyleXu, Rui, and Yanfang Zeng. 2019. "A Method for Road Extraction from High-Resolution Remote Sensing Images Based on Multi-Kernel Learning" Information 10, no. 12: 385. https://doi.org/10.3390/info10120385
APA StyleXu, R., & Zeng, Y. (2019). A Method for Road Extraction from High-Resolution Remote Sensing Images Based on Multi-Kernel Learning. Information, 10(12), 385. https://doi.org/10.3390/info10120385