1. Introduction
In the last few years, social media have played an increasingly-important role as information sources for many categories of people (such as travelers, researchers, public administrators, company managers, and so on). In particular, the exploitation of information concerning public places (also called points of interests (POIs)) is continuously increasing: posts written by other people concerning public places (such as reviews) are becoming more and more important for decision making (for example, to decide whether to visit a museum).
Currently, several players own very large corpora of information concerning public places. Google has the corpus built for Google Maps; its service called Google Places is a valid tool to get lists of descriptors of public places in a given area. Facebook has a large corpus of pages concerning public places; pages are created by owners of places to promote their business (for example, restaurants, pubs, museums, and so on). Trip Advisor collects reviews about public places looked for by travelers (typically, restaurants, hotels, and so on). Other famous social media that collect information about public places are Yelp and FourSquares.
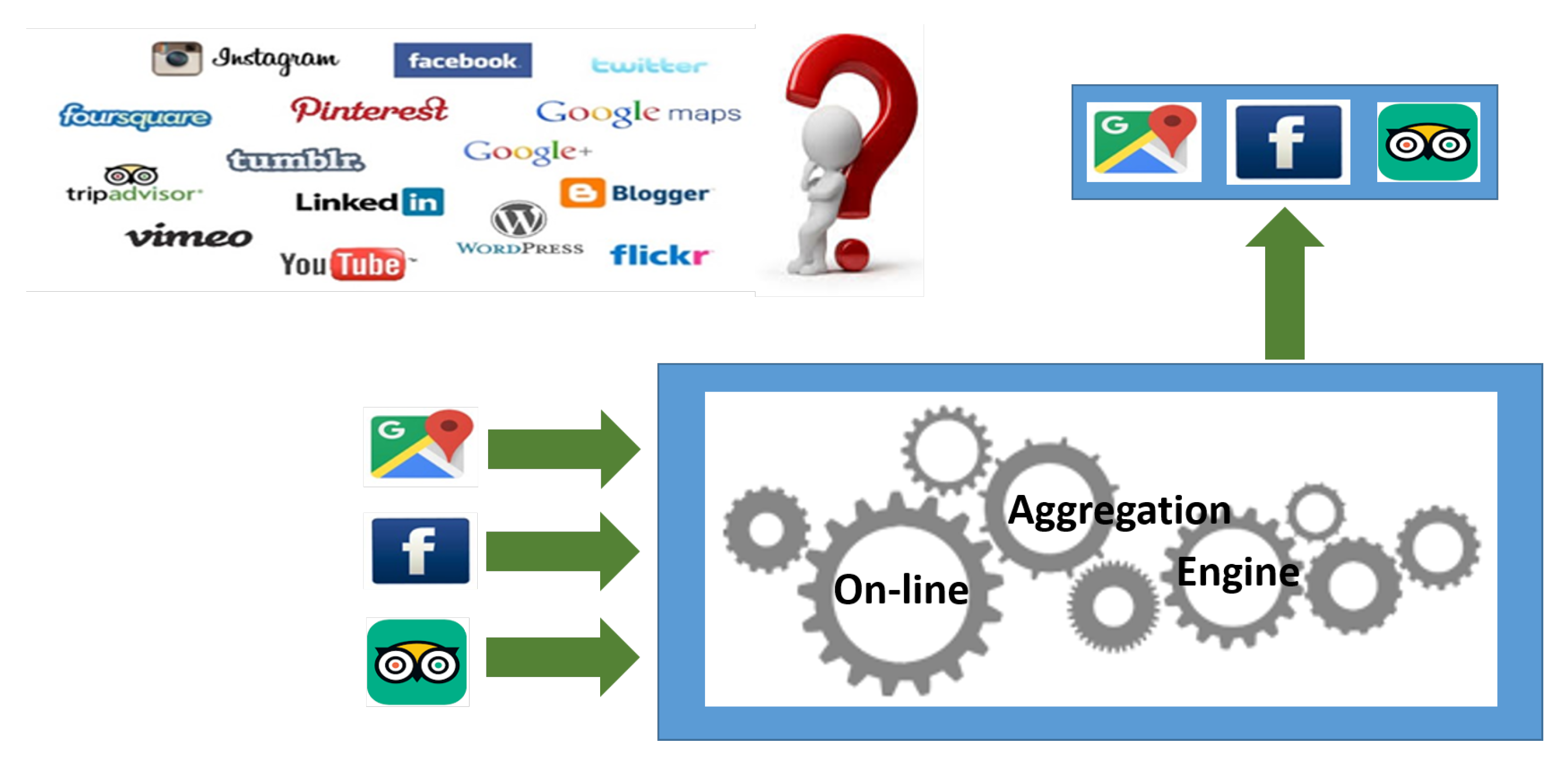
Usually, social media users who wish to get information concerning a given public place, start by exploiting one source of information (for example, Google Places) and one or two other social media (for example, Facebook and/or Trip Advisor). This activity is very tedious to carry on, in particular when a complete panorama about places in a given area is wished; in fact, at present, it can be performed only by aggregating information concerning the same place that comes from multiple sources by hand, by interacting with each single source. Clearly, an on-line aggregation engine for information describing public places would help people greatly.
Figure 1 illustrates the scenario. A user seeks for a public place in a given city, by getting a list of places provided by a system, for example Google Places; he/she chooses the desired one and asks the aggregation engine to provide all pieces of information concerning that place together (like news, events, reviews, and so on) from several sources (such as Facebook, Trip Advisor, and so on).
The on-line approach is necessary because on-line social media are not stable sources; as far as public places are concerned, information is continuously added, updated, and removed; therefore, the best way to aggregate up-to-date information is performing the aggregation on demand.
However, the social nature of social media requires dealing with an important issue: the same place could have a different name, address, and coordinates in the different sources. As an example, consider the following case taken from the area of Manchester (UK): the place with Facebook name “Al-Jumeirah”, in Google Places is named as “Al Jumeirah Restaurant”; to a human eye, they clearly appear to be the same, but this is not obvious for an automated algorithm.
In literature, this problem is usually called “geo-spatial data conflation” and it has been widely studied for off-line contexts, i.e., when lists of places are available in advance and can be analyzed and processed with time-consuming techniques. For example, [
1,
2,
3] adopt some kind of learning technique to overcome the limitations of applying string-similarity measures. Even those works that propose methods based on string-similarity metrics evaluated on names and/or addresses, such as [
4], do not consider coordinates of places, and some works [
5,
6] use complex geometries that are not available in our context. In general, the problem of on-line conflation of geographical data has not been considered.
Section 2 provides an extensive analysis of the literature, that could help readers understand the research context.
The contribution of this paper is the definition and evaluation of a technique for on-line aggregating descriptors of public places coming from two different social media, without prior knowledge and off-line activities. We follow an approach based on fuzzy logic and possibility theory [
7]: we propose a binary fuzzy relation, named
, to compare two place descriptors; the membership degree of this relation describes the degree of likelihood that the two descriptors actually describe the same place. Note that, in literature, to the best of our knowledge fuzzy approaches for on-line conflation of geographical data have not been proposed; the only work based on a fuzzy technique that addresses a similar problem is [
8], in which the authors consider data sets of generic objects (neither public places nor generic geographical objects).
In order to evaluate the goodness of the approach, the technique has been implemented within a prototype library. Then, we downloaded three data sets describing places in three different cities, such as Manchester (UK), Genoa (Italy), and Stuttgart (Germany): descriptors were downloaded from Google Places and paired with descriptors of Facebook pages. As a baseline for the evaluation, we considered our preliminary version of the binary fuzzy relation introduced in [
9], showing that the new definition (proposed in this paper) significantly improves the effectiveness of the technique. Then, we make a comparison with a machine-learning technique, named “random forest”: it is a well known classification technique, to be executed off-line. We will show that our technique obtains comparable results, even though it can be applied on-line, without a preliminary download of the data sets.
The paper is organized as follows.
Section 2 discusses related works.
Section 3 presents the problem and the technique we propose.
Section 4 introduces the formal fuzzy framework exploited in
Section 5 to define the binary fuzzy relation named
.
Section 6 presents how we evaluated the technique, in particular how we built the data sets and the comparison with the baseline and with random forest classifiers. Finally,
Section 7 draws the conclusions and future developments.
2. Related Works
Social media have become very important tools for people, not only for exchanging messages concerning their private life, but also for finding information concerning public places. In fact, both owners and visitors of public places can post messages either promoting events or disseminating opinions somehow concerning the place. Contemporary citizens rely on social media to experience the city. The work [
10] is an interesting study, that helps to understand how people live their cities, in particular how they live public places by exploiting location-based services. The paper points out limitations to flexibly and effectively use them by citizens.
Clearly, the need to aggregate information concerning public places is not new and several works were published on the topic. However, we observed that previous works usually do not exploit coordinates (latitude and longitude) to conflate descriptors of the same public place; at the best of our knowledge, only the technique proposed by [
11] considers coordinates and distance. Moreover, all of them adopt an off-line approach: corpora containing data describing public places must be previously downloaded and then aggregated. This approach is suitable for stable and verified data sets. For instance, digital gazetteers are examples of stable and verified data sets describing places [
5]. This work jointly adopts three metrics that evaluate shape similarity (because it is argued that place markers are not enough), type similarity (or category of places) and names, trying to reproduce the cognitive approach performed by people. Our work approaches the problem in a similar way; however, we can rely neither on shapes of places (social media provide markers only) nor on reliable categories (social media adopt specific and not comparable categories).
Nevertheless, the topic of aggregating information about public places or POIs coming from social media is current; in fact, many researchers are working on this topic. For example, the work [
12] addresses semantic aligning of heterogeneous geo-spatial data sets (GDs) produced by various organizations, in order to find an efficient similarity matching technique. This work seems to be related to our work; in fact, to solve the aligning problem, the authors presented a holistic approach to adapt the geo-spatial entities (concepts, properties and instances) together. In particular, they faced the problem of aligning the instances of various category systems by simultaneously matching unbalanced schema of data composed by multi-dimensional information.
The work [
4] evaluates the DAS technique: it is based on an interesting word similarity measure, that is exploited in a three step process. Specifically, given the strings reporting names of two public places, they are compared (after removing blanks) as a whole (this is the word-similarity measure) and, after tokenization, as sentences (this is called the sentence-similarity measure); finally, if the two above-mentioned similarity measures are greater than a given threshold, a final comparison is made, where all characters in the strings are compared (this is called name-similarity measure). Although it is effective, the technique considers only names of public places, without considering coordinates.
The work by Santos et al. [
1] is closely related to our work. The authors applied different string similarity metrics, as well as various machine learning methods, to solve the problem of toponym matching, in order to perform a comparative performance study. They show that machine learning methods outperform similarity metrics: in particular, classifiers based on the random forest method outperform other machine learning techniques. In our work, we show that it is possible to perform similarly to random forest classifiers, by combining similarity between names, addresses, and locations.
The work [
3] addresses the problem of urban neighborhood identification. In particular, neighborhoods are regions (or areas) that own similar characteristics, whose names are often given by people that inhabit them. These names are important for people that live in these urban neighborhoods, because they constitute the socio-demographic identity of people; therefore, often they are not listed in official data sets. The source of information considered in [
3] is the Craigslist platform (
https://www.craigslist.org): specifically, ads concerning house rentals are of interest, because they are geo-tagged and contain neighborhood names. The methodology proposed by the authors extracts all n-grams from ads text and geo-tags them with coordinates associated with ads; then, a pool of statistical measures, possibly denoting spatial correlation, are associated to n-grams; these are labeled based on the capability of identifying neighbourhoods; finally, a random-forest classifier is built, in order to identify novel neighbourhoods. Interestingly, the paper shows that a classification model built on n-grams collected for Washington D.C. (USA), is able to discover n-grams denoting unknown neighborhoods in ads for Seattle, WA (USA) and Montreal, QC (CA), by using spatial statistical correlation measures associated with n-grams.
The authors of [
13] address the problem of geo-spatial data conflation as well; in particular, they consider POIs, because they convey important information about spatial entities and territories. They propose a method to match objects (describing POIs) coming from different sources, by means of an entropy-based technique organized in four steps. (1) A normalized similarity formula is developed, that helps to simplify the computation of spatial attribute similarity; in particular, the authors specified the rule of attribution selection, then study POI matching for spatial, name, and category attribution and indicated a way for weighted multi-attribute matching of POIs. (2) They used phonetic and word segmentation methods in order to remove linguistic ambiguity. (3) They established category mapping in order to address heterogeneity among various classifications. (4) They calculated attribute weights by computing the entropy of attributes, in order to manage non-linearity of attribute similarity. Experiments demonstrated that this technique obtains good results in terms of precision and recall for matching instances from various POI data sets.
In another work [
2] the authors face the problem of toponym matching by using a deep neural network. The focus is pairing strings that represent the same POI location. The authors noted that techniques based on string similarity metrics are either dedicated for matching POI names or combined with other metrics. But these techniques, that establish similarity by detecting common sub-strings, do not always detect the character substitutions involved in toponym changes caused by changes in language. Therefore, the authors present a matching approach based on a deep neural network in order to classify pairs of toponyms as “same POI” (matching) or “different POIs” (non matching). In particular, their network architecture exploits recurrent nodes in order to create representations from the sequences of bytes that are the strings to match. In a second step, the above representations are combined and passed to feed-forward nodes in order to achieve the classification decision. The authors used a data set of the GeoNames gazetteer. The final results show that their technique can do better than individual similarity metrics and methods based on supervised machine learning methods.
In [
8], Bunke et al. do not focus on conflation of public places, but on conflation of objects from generic data sets. Specifically, they propose an approach based on fuzzy sets and fuzzy rules. In details, objects are seen as vectors of features; fuzzy sets are used to characterize the distance of each single pair of homogeneous features; fuzzy rules combine fuzzy sets evaluated on single feature pairs and determine the distance between two objects. At the best of our knowledge, this is the closest proposal to our work, since it adopts a fuzzy approach, although it does not consider coordinates.
A side problem is addressed in [
6]: Jung et al. faced the problem of conflating geographical objects from different catalogues coming from different portal APIs (Application Programming Interfaces). Although apparently it is similar to the problem addressed in this paper, the problem they addressed is quite different, because they consider the shape of objects and the neighborhoods of them on the map; in contrast, we consider punctual coordinates of public places, for which the shape of buildings is not available.
Fuzzy approaches and soft computing are of interest in many contexts, in particular to manage web data and geographical information. To cite some work related to our experience, in [
14,
15,
16] fuzzy techniques to perform location-based spatial queries are presented; fuzzy logic helps in dealing with uncertainty about both user position and places of interest. The methodology presented in these papers is also the long-term result of research in flexible querying in relational databases: in fact, an extension to SQL, called SoftSQL, was proposed to provide users of relational databases with a powerful tool to express queries based on linguistic predicates and soft aggregators on relational tables [
17,
18].
To conclude, soft approaches can be applied to post-process web searches; in [
19,
20,
21] we studied the evolution of a framework for clustering web-search results; clusters could be manipulated, in order to find out the pool of search results that fit user needs. The soft approach was essential to deal with imprecision of search results.
6. Experimental Evaluation
In order to evaluate the effectiveness of our technique, we built three test data sets—specifically, by exploiting the algorithm to download place descriptors proposed in [
9]. We downloaded place descriptors from Google Places; for each of them, we looked for up to two descriptors of Facebook pages, possibly corresponding to the place described by the Google Places descriptor.
We decided to consider three cities to build our data sets: Manchester (UK), Genoa (Italy), and Stuttgart (Germany). This way, we could test our technique with place descriptors written in three different languages, i.e., English, Italian, and German. The main difference between these languages are related to addresses: in fact, in Italian the urban designations (like “via” and “piazza”, that stand for “street” and “square”, respectively) are positioned at the beginning of the address, while in the other two languages urban designations are positioned at the end. Recall that in the definition of the and relations (Definitions 10 and 12) we introduced the function, that removes urban designations and civic numbers from addresses.
We chose these cities because they are comparable with respect to the number of inhabitants; they are not small cities, but they are not even big cities; furthermore, they have a large variety of public places. From Google Places API, we obtained 5214 descriptors for Manchester, 4895 descriptors for Genoa, and 5596 descriptors for Stuttgart. From Facebook API, we obtained 5738 descriptors for Manchester, 4086 descriptors for Genoa, and 2724 descriptors for Stuttgart. We composed 2310 pairs for Manchester, 1644 pairs for Genoa, and 1280 pairs for Stuttgart.
At the end, we selected randomly 400 pairs for each city. By hand, we labeled each pair either with “Yes” or with “No” (i.e., the two paired descriptors do or do not represent the same public place, respectively).
At this point, we randomly divided each pool of 400 pairs into a training set of 300 pairs and a test set of 100 pairs. We denote these data sets as
Manchester training set, Manchester test set, Genoa training set, Genoa test set, Stuttgart training set, and
Stuttgart test set (training sets will be used to train the random forest classifier, as described in
Section 6.2).
6.1. Evaluation
First of all, we studied the behavior of the
relation with 15 different settings. Recall that we have two parameters:
and α.
is the contribution of the geographical relation
to the membership degree of the
relation. α is the threshold to de-fuzzify and label a pair: if the membership degree of the
relation is no less than α, the assigned label is “Good”, otherwise it is “Bad”.
Table 1 reports the 15 chosen settings.
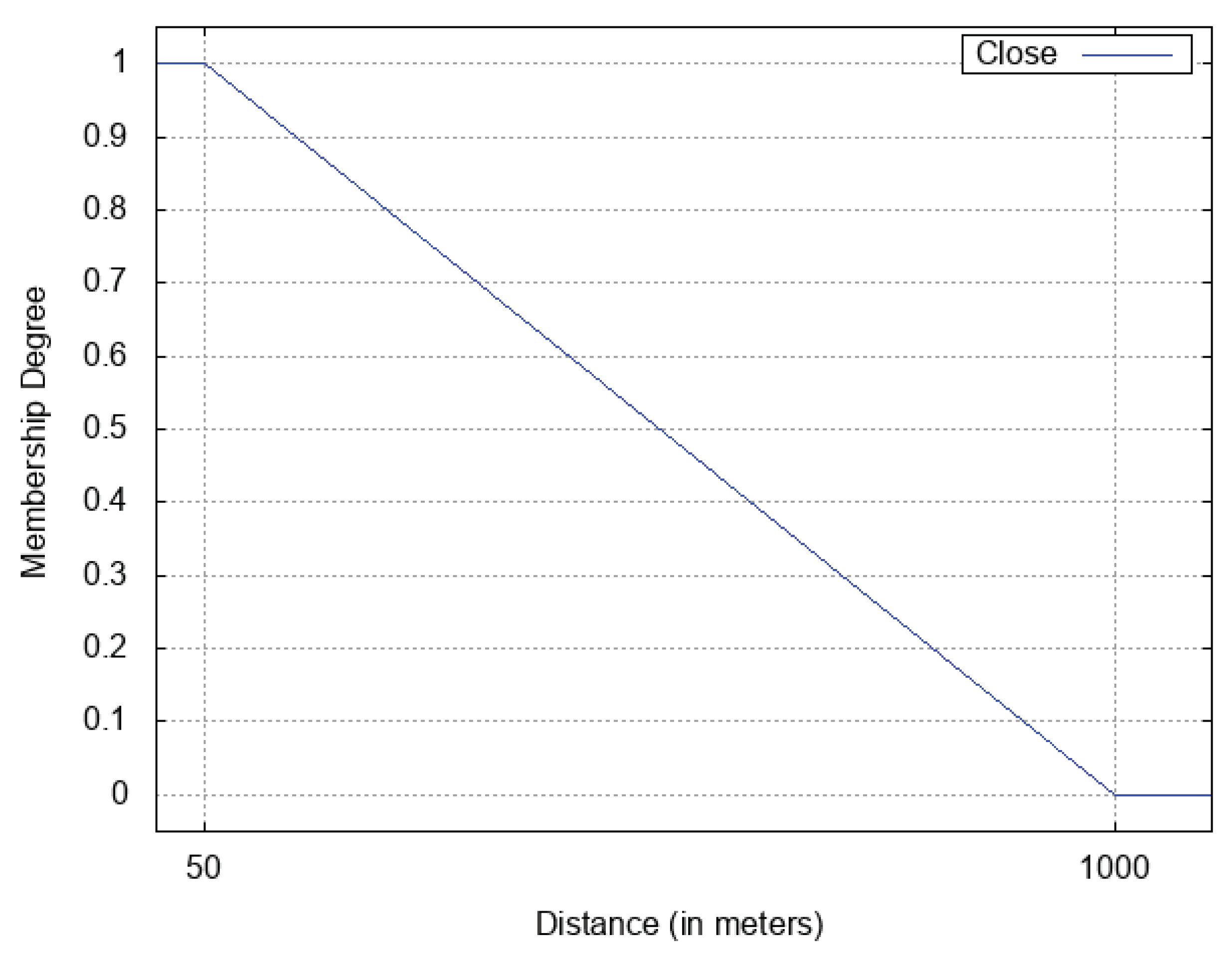
We considered five different values for the parameter (0.15; 0.30; 0.50; 0.70; 0.85) so as to evaluate the effect of the geographical contribution, by varying its weight from a very small weight to a very high weight. We also considered three different values for the α parameter (0.65; 0.75; 0.85), in order to evaluate the effect of increasing the threshold (the greater the threshold, the stronger the membership degree necessary to classify a pair as “Good”). As far as the relation is concerned, we ran all the experiments with m and 1000 m.
We evaluated recall, precision, and F1-score. Remember that recall represents the ratio between the number of descriptor pairs labeled as “Good” by the technique that were labeled with “Yes” by hand (the true positive pairs) and the total number of descriptor pairs labeled with “Yes” by hand (formally, , where stands for “true positive” and stands for “false negative”). Then, remember that precision represents the ratio between the number of descriptor pairs labeled as “Good” by the technique which were labeled with “Yes” by hand and the total number of descriptor pairs labeled as “Good” by the technique (formally, , where stands for “false positive”). Finally, remember that F1-score (or F1) represents a combined/synthetic metric of recall and precision: it is defined as F1-score .
Table 2 reports the results of our experiments performed on
Manchester test set;
Table 3 reports the results of our experiments performed on
Genoa test set;
Table 4 reports the results of our experiments performed on
Stuttgart test set.
In order to easily conduct the sensitivity analysis, results in
Table 2,
Table 3 and
Table 4 are plotted, respectively, in
Figure 3,
Figure 4 and
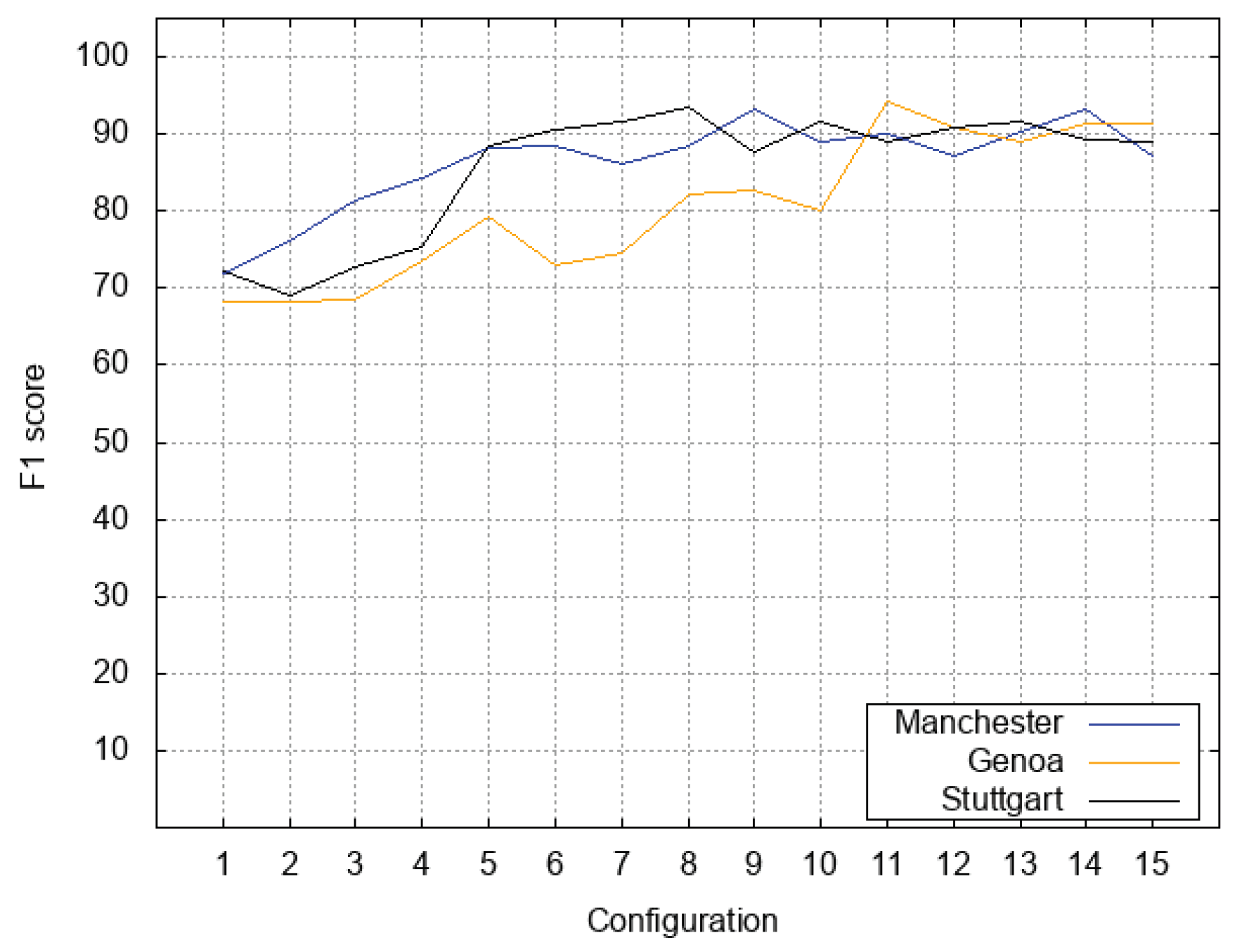
Figure 5. In particular,
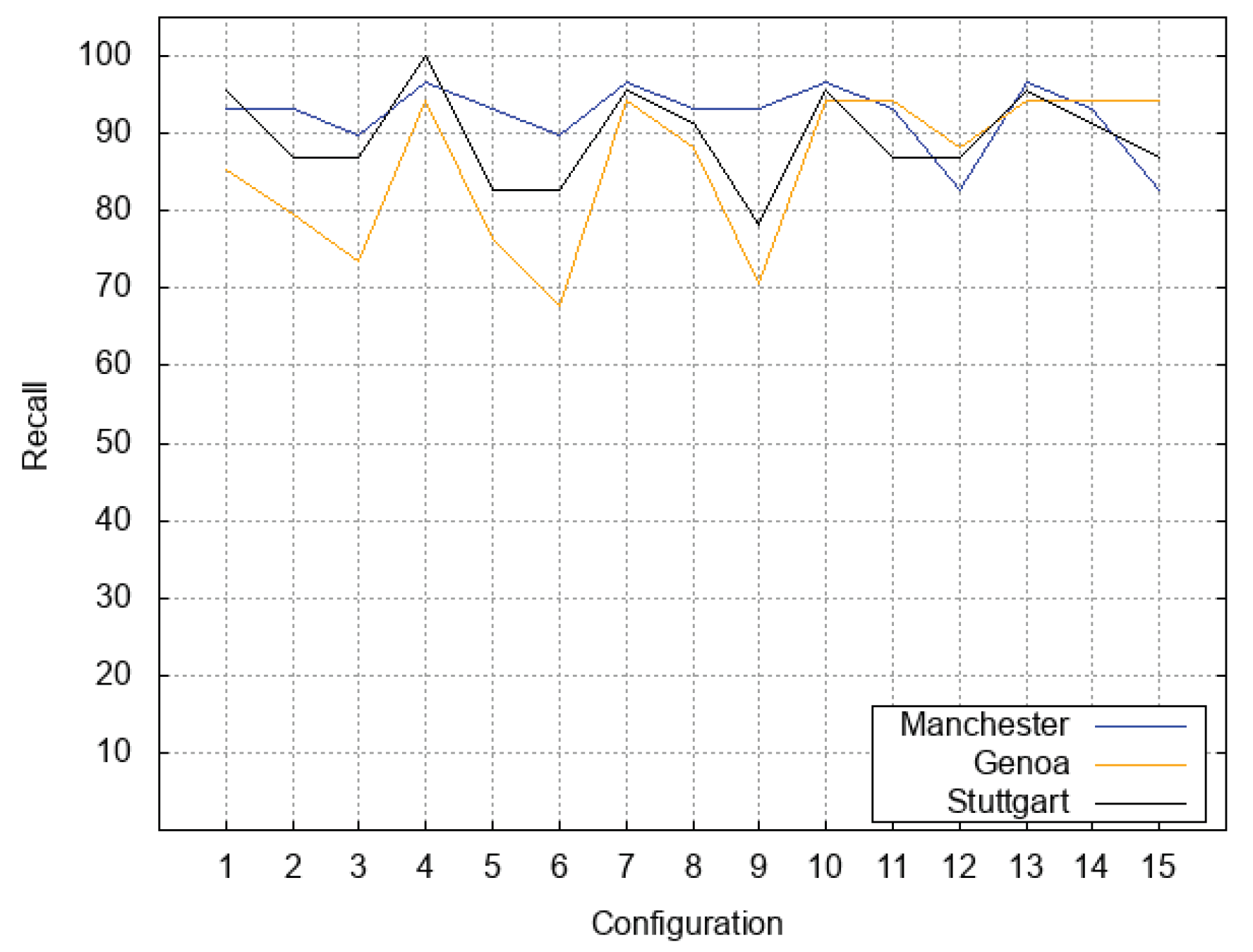
Figure 3 plots how recall varies depending on the variation of configuration settings; the blue line plots results obtained with the
Manchester test set, the orange line plots how recall varies for the
Genoa test set, and the black line plots how recall varies for the
Stuttgart test set. We can notice that
Genoa test set was quite sensitive to variations of the
parameter; we observe that the orange line becomes stable for configurations
,
, and
. The other two test sets were more stable; nevertheless, all three lines reached a good stability for the last three configurations.
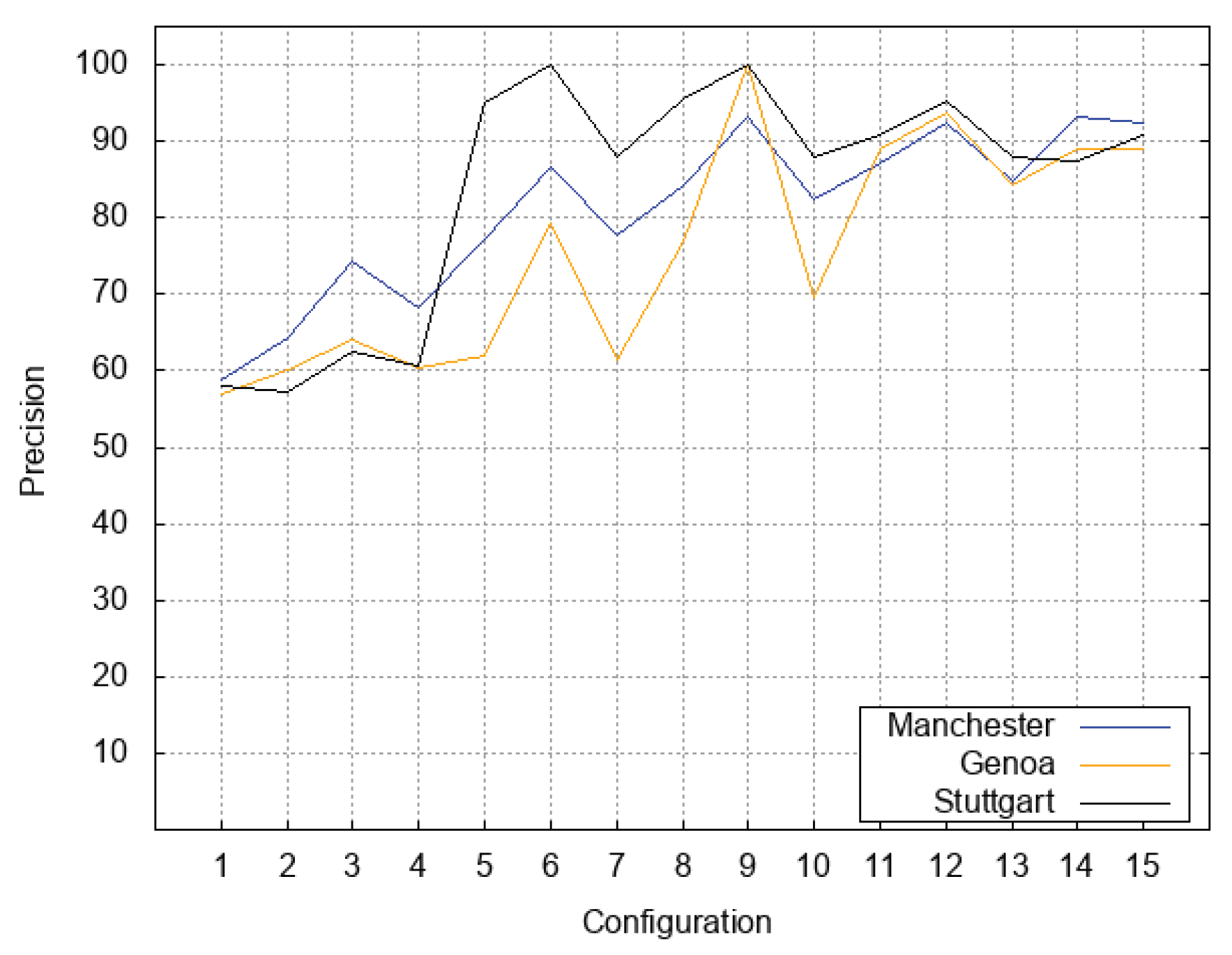
Figure 4 plots precision obtained for the three test sets for all the 15 configurations. Note how increasing values of the
parameter strongly influence precision, which substantially increases. Even though for
Genoa test set (orange line) we obtain the best precision with
and for
Stuttgart test set (black line) we obtain the best precision also with
; all three curves become stable for configurations
,
and
, confirming what emerged by analyzing plots for recall (
Figure 3).
Figure 5 plots the behavior of F1-score, for the three test sets with all the 15 configurations. The F1-score is quite useful to analyze the behavior in an aggregated way. We can see that the three lines all converge to show stable and good results for configurations from
to
. This confirms that high values of the
parameter obtained the best results, while changes in the α parameter usually got little effects for high values of the
parameter.
After this analysis, it is possible to see that configuration can be chosen as the reference configuration for our technique, because it obtained the best combination of recall, precision, and F1-score for the three test sets.
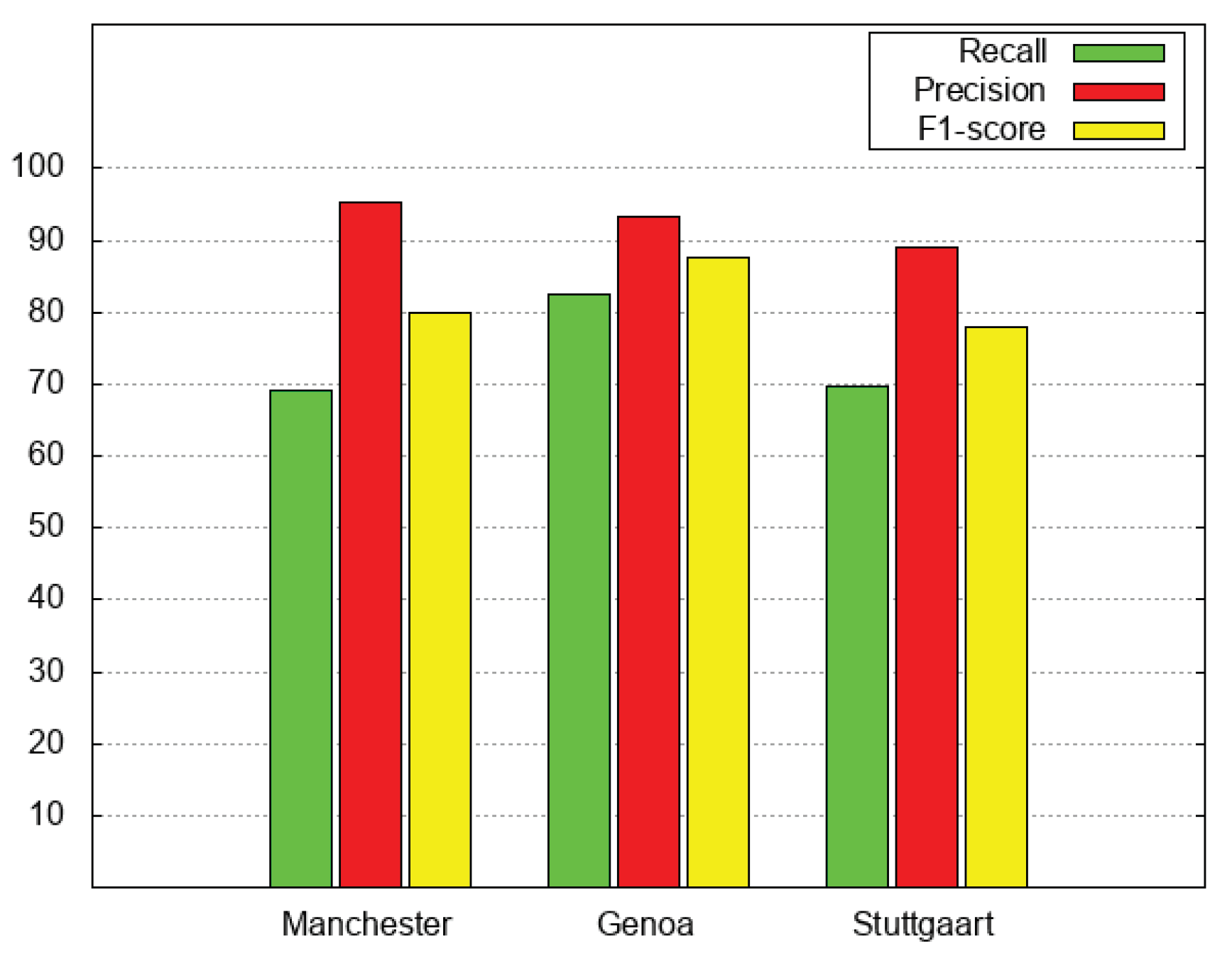
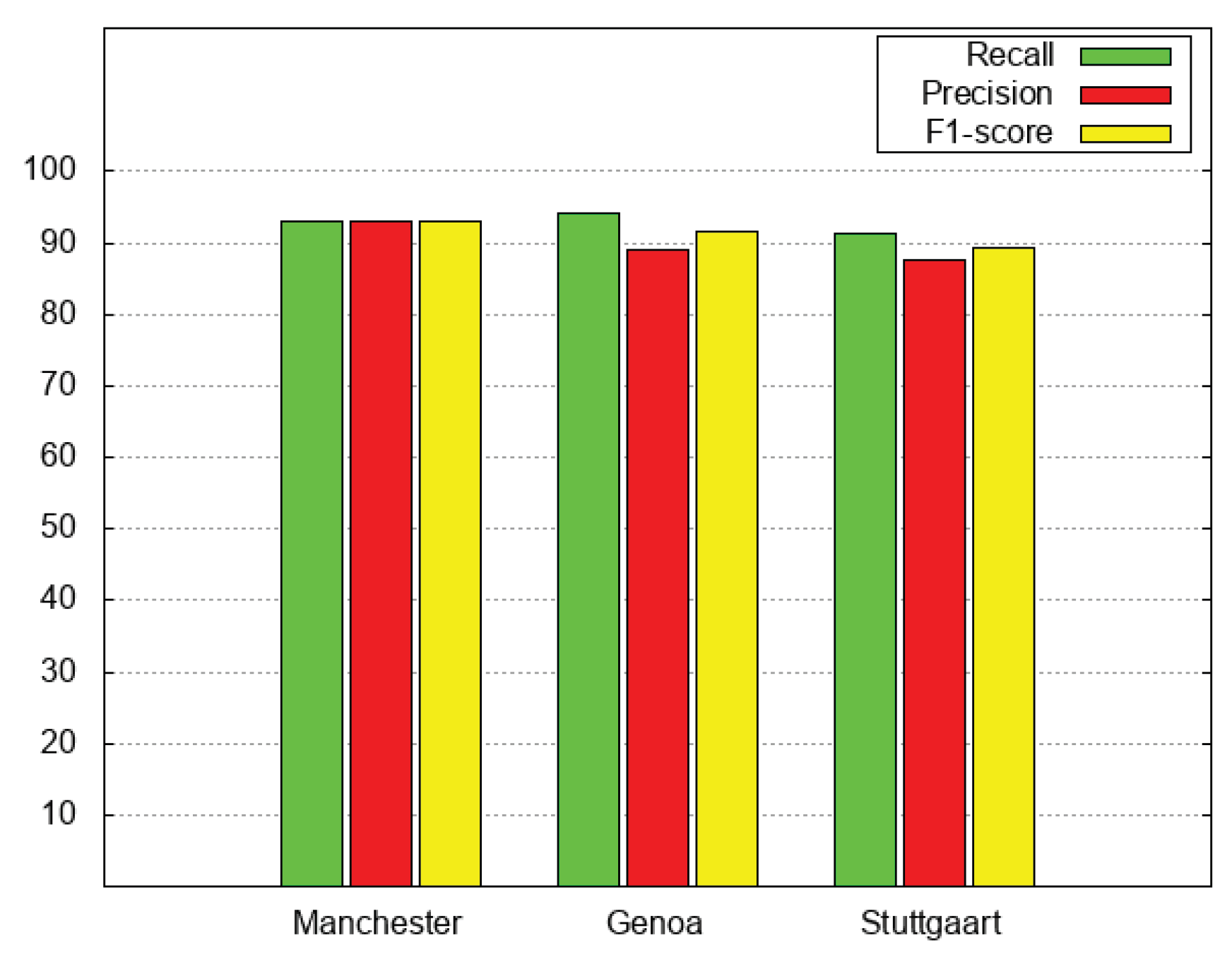
Table 5 reports, in the upper part, the results obtained by applying the
relation (see Definition 6), that is the baseline definition of the
relation; in the middle, the table reports the results obtained for the
relation with
as reference configuration. Recall (from
Section 5.2) that, as far as the
relation is concerned, we run experiments for the
relation with settings
m and
2000 m, as in [
9]; furthermore, the minimum threshold to defuzzify is
.
The table clearly shows that the novel formulation of the relation (denoted as ) always outperforms the baseline version (denoted as ) as far as recall and F1-score are concerned.
In particular, notice that we obtained for F1-score, recall and precision for the Manchester test set.
Figure 6 and
Figure 7 depict the results reported in the upper and middle parts of
Table 5. Specifically, green bars denote recall, red bars denote precision and yellow bars denote F1-score.
It is possible to notice that the baseline has good performance with Italian language, while it does not perform so well with English and German languages. This is due to the fact that the Manchester test set and Stuttgart test set have a significant number of missing fields. This confirms that the novel formulation of the relation is actually effective in dealing with such missing fields.
6.2. Comparison with Random-Forest Classifiers
We now compare our technique with the machine-learning technique known as “random forest”. It is a known supervised ensemble learning method for classification devised by Ho [
29]. In a supervised learning method, there are two types of variables: many features that are the input independent variables; and one target that is the output dependent variable (individual classes into which the input variables maybe mapped). The name of the technique is motivated by the fact that, during the training phase, many classification trees are generated (i.e., a forest of classification trees). During the test phase, all the classification trees are exploited and the class assigned by the majority of them is taken.
We chose the random-forest technique because it was used by Santos et al. [
1] to compare the performances of different string similarity metrics in the task known as toponym matching.
We performed experiments by adopting the Python library named ML provided within the sklearn module; specifically, we exploited the method named RandomForestClassifier. In particular, we configured its parameters as follows:
, out of 3 (instead of );
(default value);
(default value).
Hereafter, we discuss the choices. We chose three out of three features (instead of , where is the total number of features in the data set) in order to compare it with our technique. These features are: the membership degree of the relation evaluated on names; the membership degree of the relation evaluated on addresses; the distance (in meters) between locations. Finally, for each tree of the random forest, the Gini impurity criterion serves to split the sample in each node.
For each training set, we generated three distinct classifiers. So, we have a random forest for Manchester training set, one for Genoa training set and one for Stuttgart training set. Recall that each training set contains 300 pairs of descriptors, while each test set contains 100 pairs of descriptors.
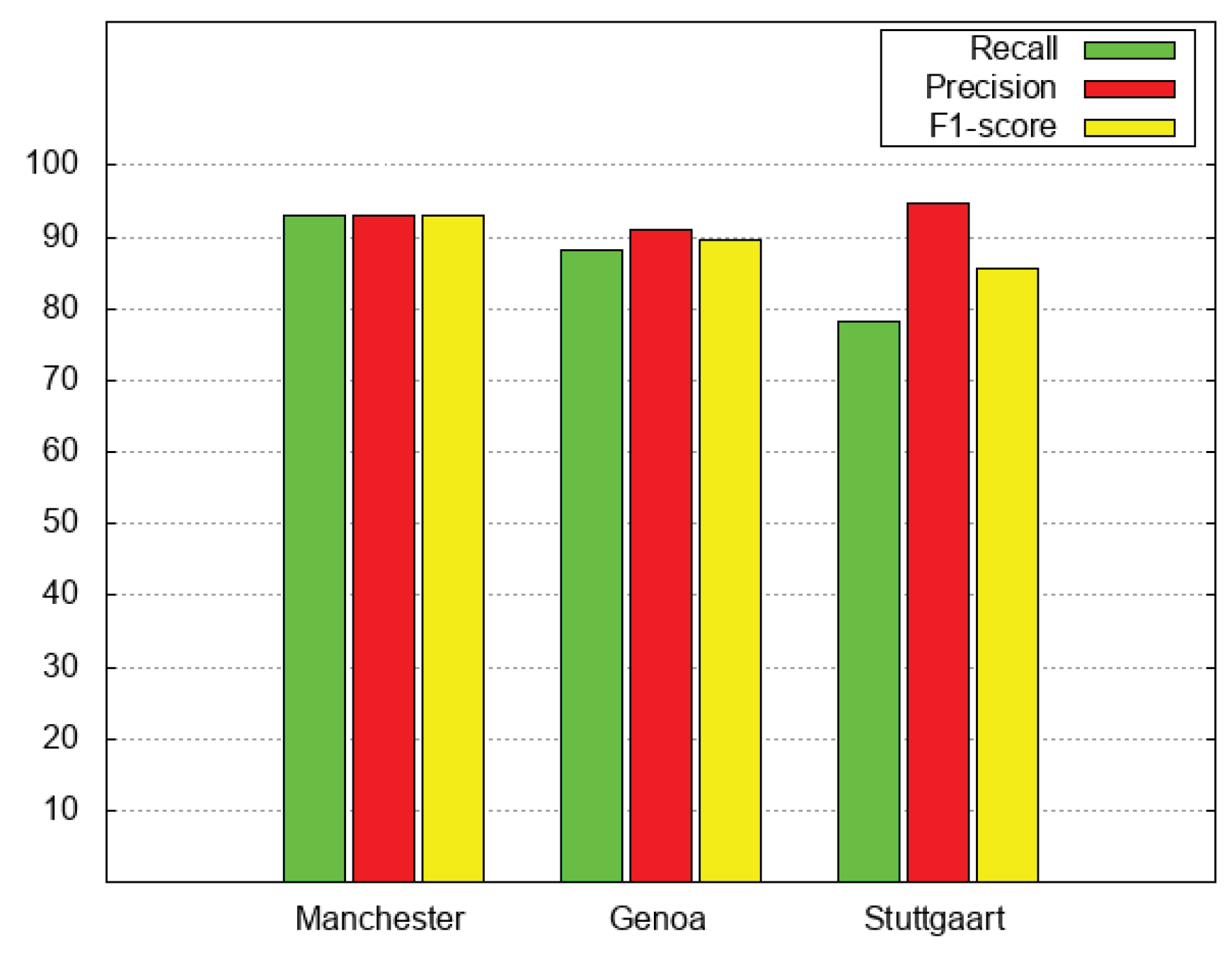
Table 5 compares performances shown by the random-forest technique (bottom part) with performances obtained by our technique (middle part of the table), with configuration Conf14, that is the configuration that provided the best average performance. Furthermore,
Figure 8 compares recall (green bars), precision (red bars), and F1-score (yellow bar) obtained by applying the random-forest technique to the three test sets (denoted as Manchester, Genoa, and Stuttgart), as opposed to
Figure 7, that compares performances obtained by the
relation with configuration
.
We can notice that as far as recall and F1-score are concerned, our technique always outperformed (even slightly) the random-forest technique. In particular, while with the Manchester test set the results were the same, our technique behaveed better with Genoa test set and Stuttgart test set.
In contrast, the random forest technique behaved better in terms of precision with Genoa test set and Stuttgart test sets. This means that the classifier based on random forests retrieved fewer false positive pairs of descriptors. In any case, the higher recall shown by our technique significantly compensates the slightly lower precision of our technique, as shown by the F1-score.
Consequently, we can conclude that our technique is effective as much as random-forest classifiers, and sometimes it is slightly better. This confirms that our approach is good for performing the on-line aggregation of place descriptors coming from different social media, in that it does not require any preliminary training phase and behaves as random-forest classifiers that, in contrast, require a preliminary training phase.
7. Conclusions
In this paper, we addressed the problem of on-line aggregating information concerning public places and points of interest gathered and published by social media. The goal is to develop a tool able to provide users with a unique and aggregated view of all pieces of information concerning the same public place.
We proposed a fuzzy technique based on a binary fuzzy relation named
: by relying on possibility theory; the proposed relation allows us to make a hypothesis about the fact that two place descriptors actually describe the same place, without prior knowledge. In order to validate the approach, we tested it on three real-life data sets, concerning Manchester (UK), Genoa (Italy), and Stuttgart (Germany), downloaded from Google Places and Facebook. We compared the new technique with the preliminary version proposed in [
9], that we used as baseline: experiments show that the new version significantly outperforms the baseline, meaning that it deals with anomalies better than the baseline. Furthermore, we compared it to the well known off-line classification technique called random forest: we could see that the two techniques obtained comparable results; however, to build a random-forest classifier, a preliminary download and a training phase preceded by hand-made labeling of data were necessary; our technique can be directly applied on-line, when querying social-media APIs.
The reader could wish to understand if the proposed approach, based on the adoption of fuzzy relations, could be applied to different application contexts, always related to social media but not concerning public places. If this question is intended as “is it possible to apply the same complex MatchingPlaces relation as it is to conflate lists of triples (name, address, location) not describing public places?”, the answer is “yes, it can be applied as it is”. In this case, we would obtain two advantages: (i) no preliminary training phase on data would be necessary, because our relation does not require training; (ii) the reason why two items are aggregated is clearly explained by the definition of the MatchingPlaces relation. In contrast, if the problem to address could not be formulated as we said, we could expect that other complex fuzzy relations should be defined, possibly reusing basic fuzzy relations concerned with string similarity or closeness; in fact, the fuzzy approach is general and can be applied when imprecision and uncertainty must be addressed, but relations must be specifically designed for the specific problem.
In the future, we will further refine our technique, by designing new fuzzy relations that exploit different fuzzy aggregation operators; moreover, we will compare our method with other machine-learning methods. Finally, we think that the relation should be parameterized with respect to the size of the geographical area of interest and number of inhabitants in cities, in order to tailor the aggregation technique to the specific context. Notice that this is a different kind of prior knowledge, if compared with the knowledge provided by labeling training sets for off-line classifiers; in fact, this knowledge describes the geo-political context in which public places are, and can l be acquired on-line, by querying specific web services.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}