Information Evolution and Organisations

Abstract
:1. Introduction
2. Information Evolution Overview
- The use of symbols separates information from the physical world;
- Ecosystem conventions separate symbols from types of representation (so words can be written or spoken, for example);
- Ecosystem conventions separate processing (and the making of connections) from types of IE (so computers can automate some human activities, for example);
- Communication separates information from a physical location (so information can be duplicated at a distance).
- Level 1 (narrow fitness): Associated with a single interaction;
- Level 2 (broad fitness): Associated with multiple interactions (of the same or different types) and the consequent need to manage and prioritise resources between the different types. This is the type of fitness linked to specialisation, for example;
- Level 3 (adaptiveness): Associated with environment change and the consequent need to adapt.
3. Viewpoints and Information Processing
- With the same evidence, different political parties reach very different conclusions about the right course of action;
- In legal cases, the prosecution and defence represent different viewpoints in response to the same evidence;
- Business processes and applications encapsulate an organisational response to certain circumstances;
- Even in science, there are divisive debates about the merit of hypotheses (this is represented, for example, in Kuhn’s paradigm shifts [25]).
- The overall outcome(s) desired;
- Any interim outcomes to be achieved;
- Actions and interactions required to deliver the outcomes;
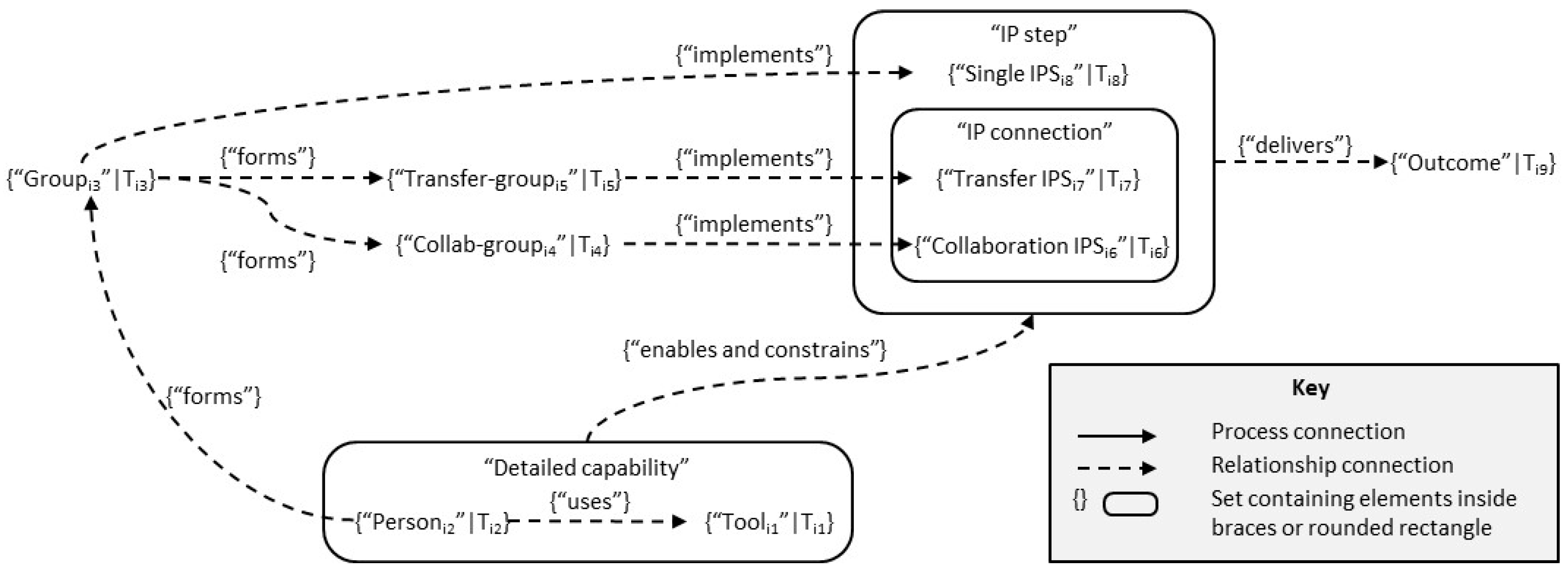
- The groups of IEs involved and what they will do (a group may include one IE or more);
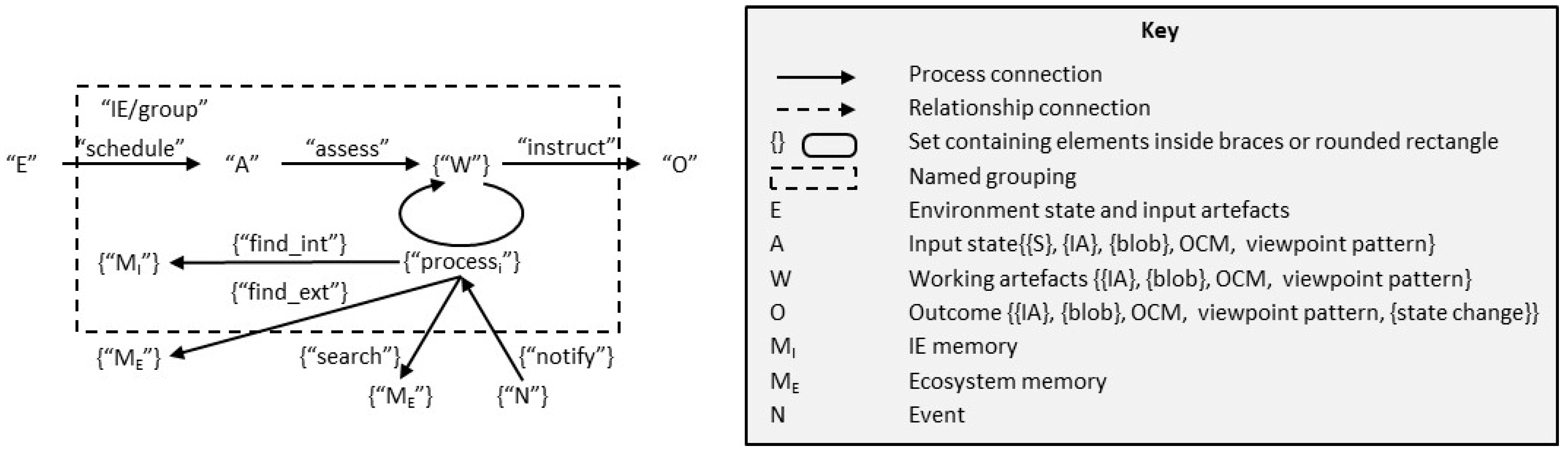
- The individual information processing steps (IP steps) carried out by each group, how the steps relate to each other, how groups collaborate, and how information is transferred between them.
- Achieves the desired interim outcome;
- Engages in an interaction with one or more other groups;
- Transfers information to another group;
- Is unable to complete the processing for some reason.
- Scheduling the processing for the IP step. Here, the IE may well be engaged in other IP steps or have higher priority IP steps to consider first and only then will it be ready to process the information;
- Assessing the inputs to decide what information to collate and what information processing models to apply (i.e., how to process the information to achieve the desired IP step outcome);
- Apply the relevant models;
- Testing whether the result meets the selection pressures and, if not, deciding whether to continue processing, transfer the processing to another IP step, look for more information or wait for more inputs;
- Reacting to external events during the processing;
- Generating IAs as instructions to create the outputs, notifications, and state changes required to deliver the desired outcome.
4. Information Measures
- Pace: How fast IAs are produced. This is important because the environment may demand a response in a given time or may prioritise early responses;
- Friction: How many resources are used. This is important because any IE has limited resources;
- Quality: How well the IAs meet the requirements of the environment.
- Alignment: This measures the degree to which the outcomes that different IEs are aiming to achieve are the same.
4.1. Information Evolution and Measures
4.2. Information Conversion
- Information transferred from one IE to another;
- Translated information;
- Information that describes how an entity of some kind has changed (as is the case with organisational change);
- Information that describes when the same thing is described from different viewpoints (as is the case with software development) and information has to be converted between them.
- Structure similarity: How closely different information structures map to each other within the same or different ecosystems;
- Content similarity: How closely the content chunks in one ecosystem relate to the other (for example, do they relate to the same properties in the same way?);
- Interpretation similarity: How closely interpretations in the different ecosystems can map to each other (for example, interpretations in physics, relating theory to experiment, need to be very rigorous, whereas political debate does not meet the same criteria).
- Performing information conversion within an IE;
- Using collaboration between groups to improve connectivity where the connection memory is not strong enough to maintain the required information measures;
- Reducing the number of conversions required.
4.3. Viewpoint Information Measures
- Ensuring high-quality input to the viewpoint and each IP step;
- Applying selection pressures continuously through each IP step;
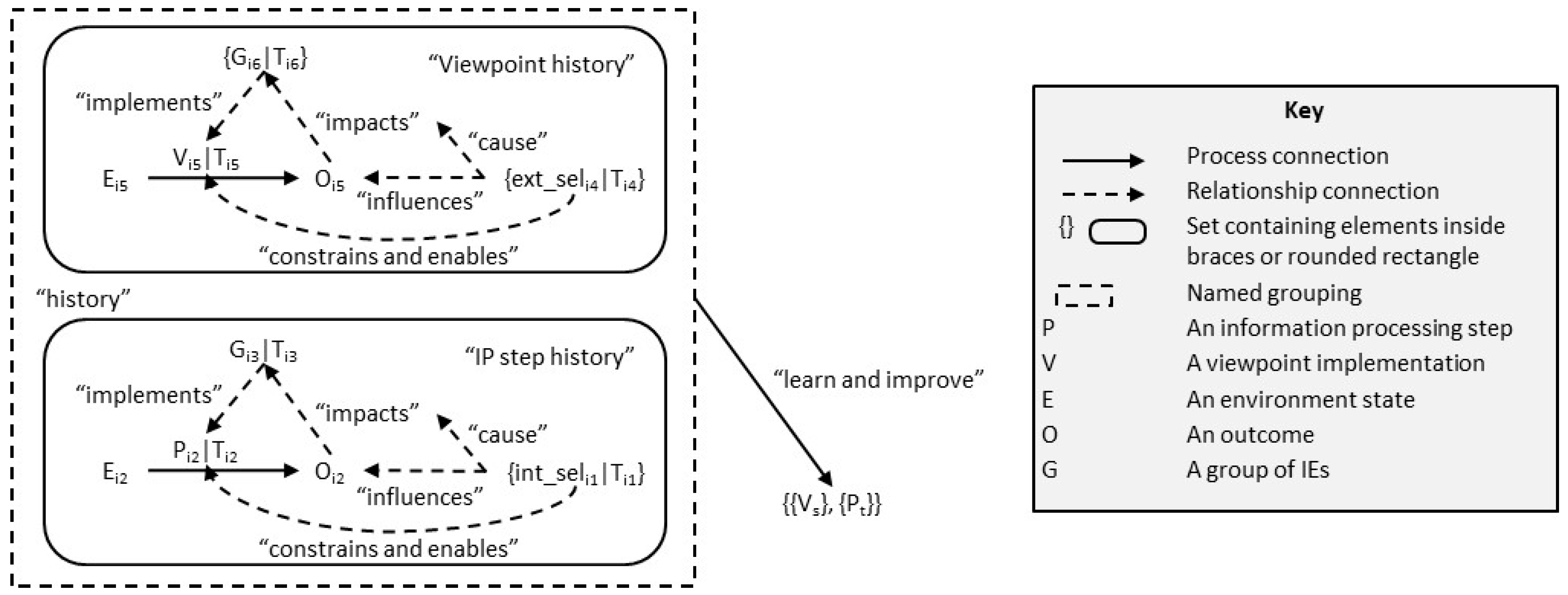
- Learning and improving;
- Minimising interruptions to the viewpoint and each IP step;
- Implementing conversion quality strategies, as described in the conversion quality principle.
5. Information Evolution and Organisations
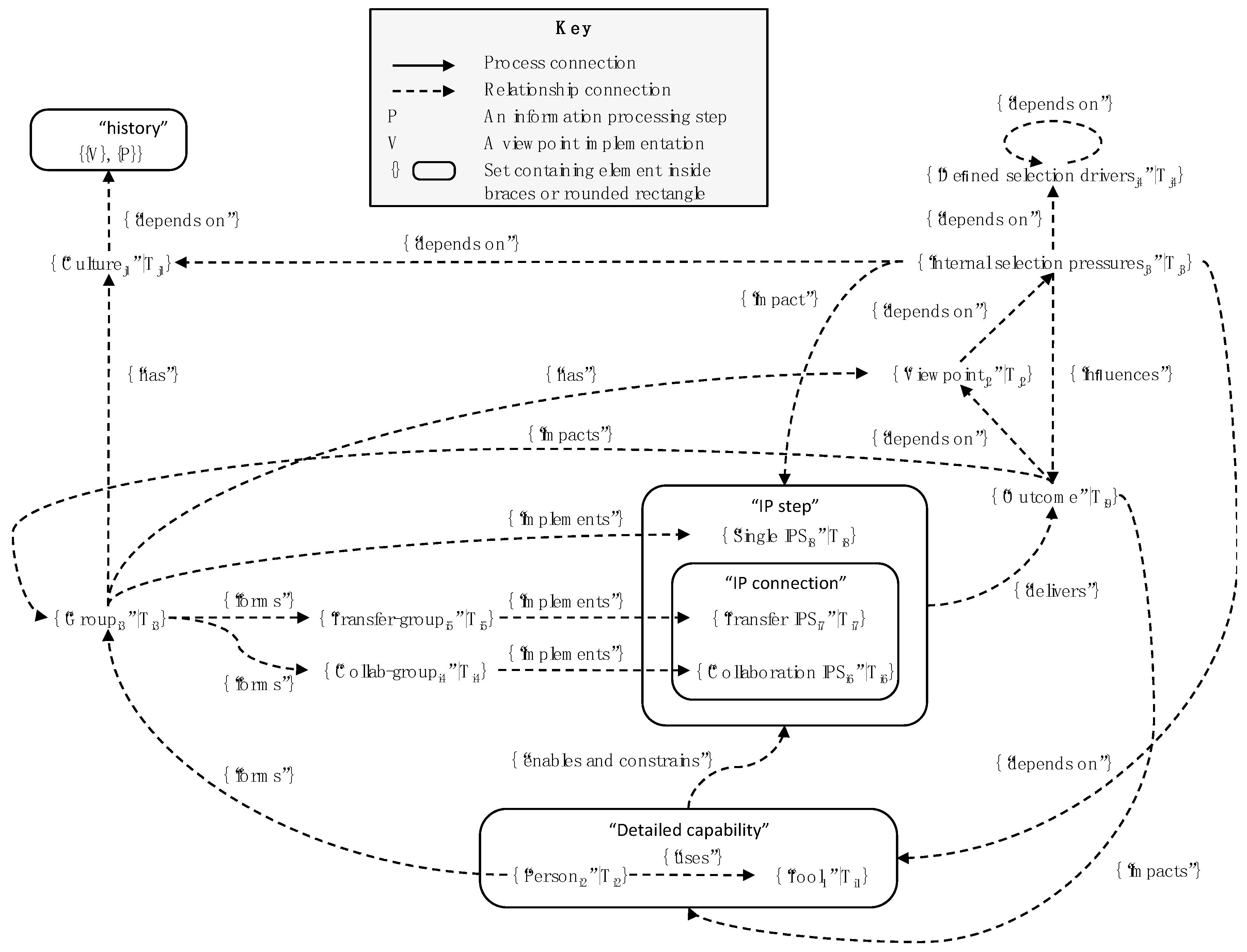
5.1. Internal Selection Pressures
- Too broad: For combinatorial reasons, defined selection drivers divide the potential outcomes into a relatively small set of categories, each of which include various outcomes that external selection pressures would differentiate between;
- Limited: They only apply to some of the outcome and, especially, may not consider level 3 fitness at all;
- Untimely: They may be subject to annual (or less frequent) updates which are out of step with the environment;
- Unintegrated: They may not be designed as a coherent whole or integrate effectively, and so the outcomes they support may contradict each other;
- Gamed: Womack and Jones [40] quote the case study of a Texan builder who “got rid of individual sales commissions (‘which destroy quality consciousness’) and eliminated the traditional ‘builder bonus’ for his construction superintendents (who were qualifying for the ‘on-time completion’ bonus by making side deals with customers on a ‘to-be-done-later’ list)”;
- Subject to surrogation: Surrogation is a human failing, in which people get metrics confused with what is being measured. This is discussed in [41], in which the authors include the following example: “A company selects ‘delighting the customer’ as a strategic objective and decides to track progress on it using customer survey scores. […] But somehow, employees start thinking the strategy is to maximize survey scores, rather than to deliver a great customer experience.” Surrogation is an example of the development of ecosystem conventions;
- Inadequate with respect to culture: Culture acts in the minutiae of daily activities and the powerful connection memory it induces is difficult to overcome [15].
5.2. Ecosystems and Silos
5.3. Information Processing Trends
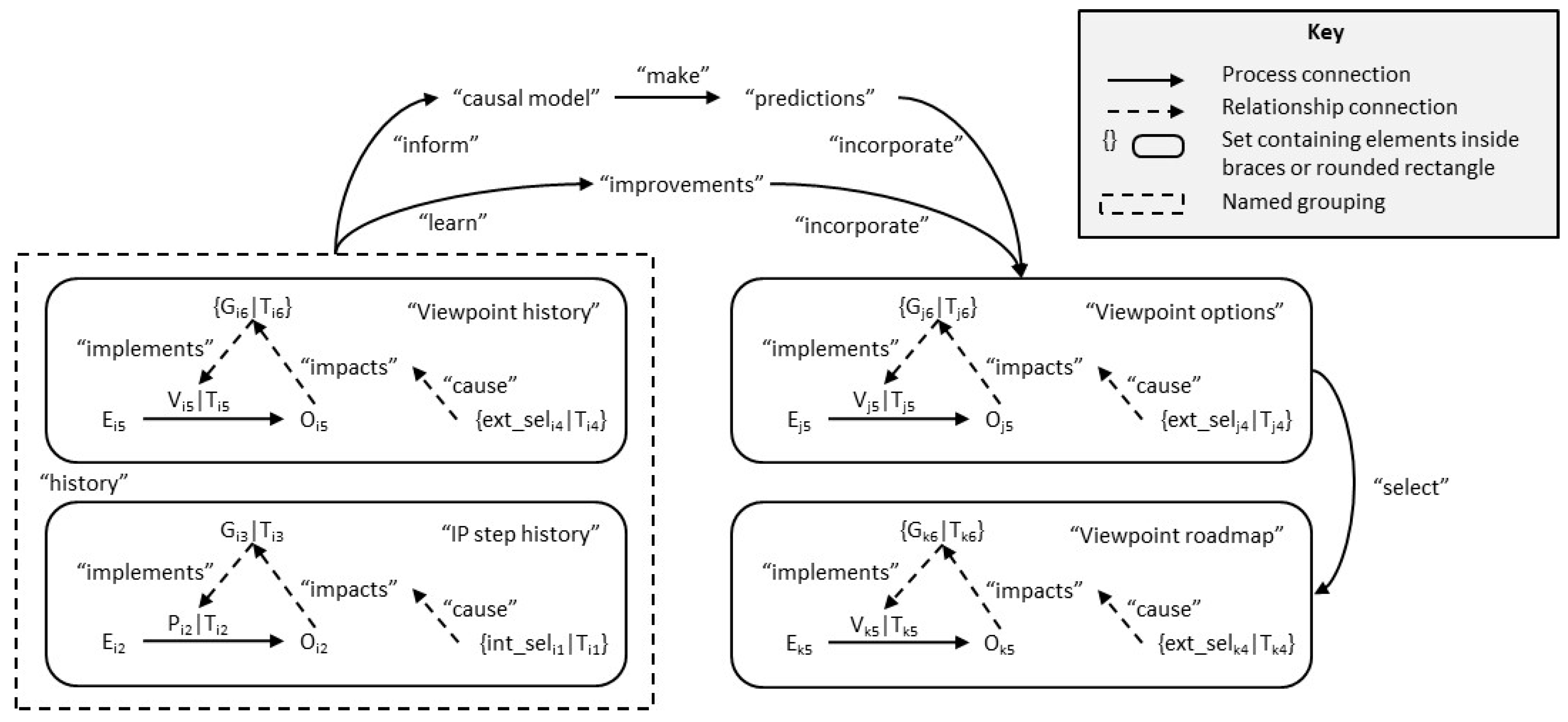
5.4. Viewpoint Patterns and Business Architecture
6. Organisational Change
6.1. Ecosystem Inertia
- Kuhn’s discussion of paradigm shifts in science [25];
- “Change resistance” in organisations, for example [46]: “One of the most baffling and recalcitrant problems which business executives face is employee resistance to change”;
- “The natural state of companies as they grow and mature is always towards more disorder” [13], and this disorder makes change harder;
- The “digital divide” [49], as some people find it difficult to keep up with changing digital technology.
6.2. Flexibility
- The environment state that triggers the IP step;
- The domain of the IP step;
- The triggering of process connections for inputs that cannot be processed within the ecosystem conventions.
6.3. Dependencies and Decoupling
- Definition dependency: When one IA is defined in terms of another (e.g., when performance management is defined according to organisation structure);
- Connection memory: When strong connection memory creates a dependency (this is the effect of culture, for example, in which the culture of groups, and therefore their performance, depends on history);
- Viewpoint pattern: When a viewpoint requires group activities to act in concert (this is the use of the term “dependency” in project management terms and applies to the relationship between IP steps in a viewpoint pattern).
6.4. Organisational Change and Information Evolution
- What are the impacts of selection pressures on the change itself?
- What is the impact of silos on the change process?
- What is the quality of the change and how does it relate to the scope of the change?
- What are appropriate patterns for the change viewpoint?
- How can the difficulty of change be reduced?
- The improvement of the change ecosystem;
- Improved connections between groups (to improve overall fitness and reduce constraints and friction).
7. Conclusions
- Organisations are information processing entities that require the right balance between level 1, 2, and 3 fitness in response to external selection pressures;
- In a rapidly changing environment, organisations need to develop a change ecosystem throughout the organisation (with the associated culture, internal selection pressures, and enablers) to support the required rate of change;
- In a rapidly changing environment, organisations need a business architecture with the following ingredients:
- Long-term groups conforming to pattern D in Table 2;
- Stable activities that do not require pattern D;
- One-off initiatives;
- Continuous connection orchestration.
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Information Evolution and Information Connection
- What information is and what we mean by information connection;
- Conventions for drawing information connection diagrams (in the form used in the main paper);
- Measures of information.
Appendix A.1. Information and Information Connections
- The physical world, properties, and values;
- Ecosystem content, including the symbolic representation of information;
- Different types of content, including chunks (to express the constraints under consideration, nouns, adjectives, and verbs are all examples in the case of human language) and assertions about the relationships between chunks (like sentences);
- How content is interpreted in terms of the physical world;
- Different types of connection.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modelling Tool | Example Chunks | Example Assertions |
|---|---|---|
| English Language | “John”, “lives in Rome” | “John lives in Rome” |
| Mathematics | “planar graphs”, “four-colourable” | “Planar graphs are four-colourable” |
- The slice representing the content itself;
- C-interpretation: The set of slices corresponding to the chunk under the standard ecosystem interpretation (c stands for chunk); this may not be trivial, for example, “i” references specific content when it is about the square root of minus one and the c-interpretation, and, in that case, will only relate to the relevant mathematical slices;
- R-interpretation: The set of slices that the chunk references under an interpretation (r stands for reference). Where just the term “interpretation” is used, it means r-interpretation.
- Process connection: There is a process, recognised within the ecosystem, that produces one outcome when acting on another outcome;
- Relationship connection: There is a process, recognised within the ecosystem, that establishes whether or not a set of slices satisfies a relationship with a particular value;
- Property connection: There is a process, recognised within the ecosystem, that establishes the value that a set of slices has for a particular property.
- l is a label: Lab (c);
- S is a set which is the set of all possible values of the pointer: Cont (c);
- v is the value (a member of S or ∅).
- An unrooted linnet C is a tuple (V, E, N) which satisfies the following conditions:
- There is a set of pointers P with unique labels LP;
- V ⊆ LP is a finite set that we call vertices;
- E ⊆ LP is a finite set that we call connectors;
- V and E are disjoint;
- N is the set of connections of D where N ⊆ {(a, e, b): a, b ∈ V ∪ E, e ∈ E};
- If e ∈ E and (a, e, b), (a’, e, b’) ∈ N, then a = a’ and b = b’.
Appendix A.2. Information Connection Diagrams



Appendix A.3. Information Measures
- Pace: How fast outcomes are produced. This is important because the environment may demand a response in a given time or may prioritise early responses;
- Friction: How many resources are used. This is important because any IE has limited resources;
- Quality: How well the outcomes meet the requirements of the environment. This is an important factor in determining the favourability of the outcome.
- Accuracy: This measures how closely the interpretation of any chunk matches the ecosystem interpretation (defined by the ecosystem conventions);
- Precision: This measures the extent to which interpretations of the chunk are the same in different circumstances (where they are intended to be the same);
- Resolution: This measures whether one interpretation can discriminate more finely than another;
- Coverage: This measures the number of properties of slices that are incorporated in a chunk and how tightly each value constrains the property (this is a measure of the modelling tool rather than the interpretation);
- Timeliness: This measures the difference between the time of measurement of the slice properties under consideration and the time of interpretation.
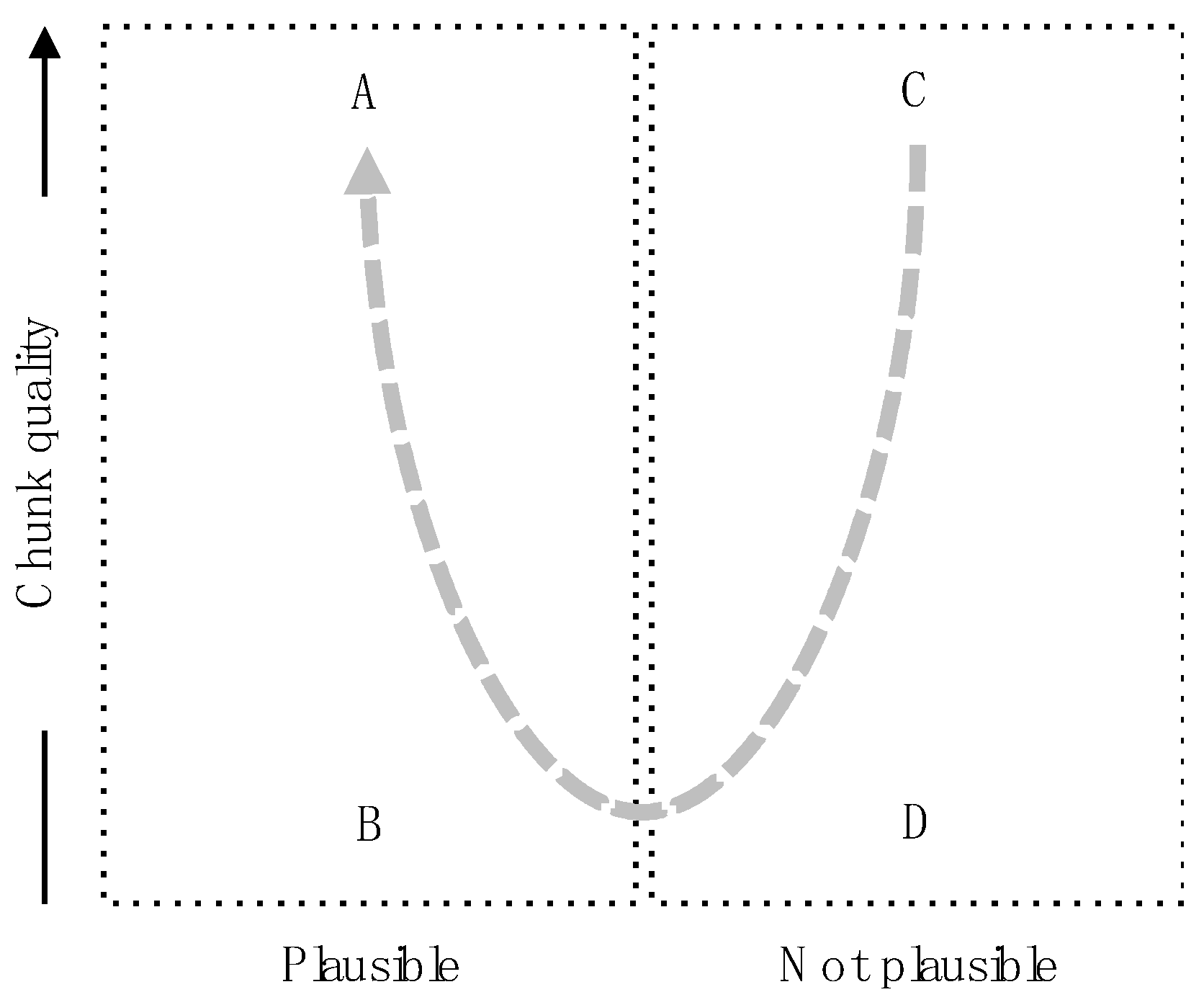
- Plausibility: This measures the extent to which the set theoretical relation associated with the assertion corresponds to the actual set relationship of the interpreted chunks.

- Alignment: This measures the degree to which outcomes with different IEs are aiming to achieve are the same thing.
References
- Westerman, G.; Bonnet, D.; McAfee, A. Leading Digital: Turning Technology into Business Transformation; Harvard Business Review Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Buvat, J.; Puttur, R.K.; Bonnet, D.; Slatter, M.; Westerman, G.; Crummenert, C. Understanding Digital Mastery Today; Capgemini Digital Transformation Institute, 2018; Available online: https://www.capgemini.com/wp-content/uploads/2018/07/Digital-Mastery-DTI-report_20180704_web.pdf (accessed on 10 December 2019).
- Davenport, T.H.; Spanyi, A. Digital Transformation Should Start with Customers. MIT Sloan Review. October 2019. Available online: https://sloanreview.mit.edu/article/digital-transformation-should-start-with-customers/ (accessed on 10 December 2019).
- Barnard, M.; Stoll, N. Organisational Change Management: A Rapid Literature Review; Centre for Understanding Behaviour Change: Bristol, UK, 2010; Available online: http://www.bristol.ac.uk/media-library/sites/cubec/migrated/documents/pr1.pdf (accessed on 10 December 2019).
- Rosenbaum, D.; More, E.; Steane, P. Planned organisational change management: Forward to the past? An exploratory literature review. J. Organ. Chang. Manag. 2018, 31, 286–303. [Google Scholar] [CrossRef]
- Walton, P. A Model for Information. Information 2014, 5, 479–507. [Google Scholar] [CrossRef] [Green Version]
- Walton, P. Measures of Information. Information 2015, 6, 23–48. [Google Scholar] [CrossRef] [Green Version]
- Walton, P. Information and Meaning. Information 2016, 7, 41. [Google Scholar] [CrossRef] [Green Version]
- Walton, P. Information and Inference. Information 2017, 8, 61. [Google Scholar] [CrossRef] [Green Version]
- Walton, P. Artificial Intelligence and the Limitations of Information. Information 2018, 9, 332. [Google Scholar] [CrossRef] [Green Version]
- Kahneman, D. Thinking, Fast and Slow; Macmillan: London, UK, 2011. [Google Scholar]
- Granovetter, M.S. The Strength of Weak Ties. Am. J. Sociol. 1973, 78, 1360–1380. [Google Scholar] [CrossRef] [Green Version]
- Wade, M.; Noronha, A.; Macaulay, J.; Barber, J. Orchestrating Transformation: How to Deliver Winning Performance with a Connected Approach to Change; DBT Center Press: Lausanne, Switzerland, 2019. [Google Scholar]
- Darwin, C. On the Origin of Species by Means of Natural Selection, or the Preservation of Favoured Races in the Struggle for Life; John Murray: London, UK, 1859. [Google Scholar]
- Schein, E.H.; Schein, P. Organizational culture and leadership; John Wiley and Sons, Inc.: Hoboken, NJ, USA, 2017. [Google Scholar]
- Quine, W.V.O. Two Dogmas of Empiricism, Reprinted in from a Logical Point of View, 2nd ed.; Harvard University Press: Cambridge, MA, USA, 1951; pp. 20–46. [Google Scholar]
- Christian, D. Origin Story: A Big History of Everything; Little, Brown and Company: New York, NY, USA, 2018. [Google Scholar]
- Simon, H. Bounded Rationality and Organizational Learning. Organ. Sci. 1991, 2, 125–134. [Google Scholar] [CrossRef]
- Ferrero, G. L’inertie mentale et la loi du moindre effort. Revue Philosophique de la France et de l’Étranger 1894, 37, 169–182. [Google Scholar]
- Zipf, G.K. Human Behavior and the Principle of Least Effort; Addison-Wesley Press: Boston, MA, USA, 1949. [Google Scholar]
- Sommerville, I. Software Engineering; Addison-Wesley: Harlow, UK, 2010. [Google Scholar]
- Walton, P. Digital Information and Value. Information 2015, 6, 733–749. [Google Scholar] [CrossRef] [Green Version]
- Dwivedi, Y.K.; Hughes, L.; Ismagilova, E.; Aarts, G.; Coombs, C.; Crick, T.; Duan, Y.; Dwivedi, R.; Edwards, J.; Eirug, A.; et al. Artificial Intelligence (AI): Multidisciplinary Perspectives on Emerging Challenges, Opportunities, and Agenda for Research, Practice and Policy. Int. J. Inf. Manag. 2019. [Google Scholar] [CrossRef]
- Avgeriou, P.; Uwe, Z. Architectural patterns revisited: A pattern language. In Proceedings of the 10th European Conference on Pattern Languages of Programs (EuroPlop 2005), Bavaria, Germany, 6–10 July 2005. [Google Scholar]
- Kuhn, T.S. The Structure of Scientific Revolutions, 2nd ed.; University of Chicago Press: Chicago, IL, USA, 1970. [Google Scholar]
- DeBrusk, C. The Risk of Machine-Learning Bias (And How to Prevent It). MIT Sloan Manag. Rev. March 2018. Available online: https://sloanreview.mit.edu/article/the-risk-of-machine-learning-bias-and-how-to-prevent-it/ (accessed on 10 December 2019).
- Miller, A. Want Less-Biased Decision? Use Algorithms. Harv. Bus. Rev. July 2018. Available online: https://hbr.org/2018/07/want-less-biased-decisions-use-algorithms (accessed on 10 December 2019).
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423, 623–656. [Google Scholar] [CrossRef] [Green Version]
- Rosenfeld, L.; Morville, P. Information Architecture for the World Wide Web; O’Reilly & Associates: Sebastopol, CA, USA, 1998. [Google Scholar]
- Casciaro, T.; Edmondson, A.C.; Jang, S. Cross-Silo Leadership. HBR. May-June 2019. Available online: https://hbr.org/2019/05/cross-silo-leadership (accessed on 10 December 2019).
- Beck, K.; Beedle, M.; van Bennekum, A.; Cockburn, A.; Cunningham, W.; Fowler, M.; Grenning, J.; Highsmith, J.; Hunt, A.; Jeffries, R.; et al. Manifesto for Agile Software Development. Available online: http://www.agilemanifesto.org (accessed on 10 December 2019).
- Bossert, O.; Desmet, D. The Platform Play: How to Operate Like a Tech Company. McKinsey Digital. February 2019. Available online: https://www.mckinsey.com/business-functions/mckinsey-digital/our-insights/the-platform-play-how-to-operate-like-a-tech-company (accessed on 10 December 2019).
- Deming, W.E. Out of the Crisis; Massachusetts Institute of Technology, Center for Advanced Engineering Study; Cambridge University Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Conway, M.E. How Do Committees Invent? Datamation; Thompson Publications: Chicago, IL, USA, 1988. [Google Scholar]
- Scott, W.R. Organizations: Rational, Natural, and Open Systems; Englewood Cliffs: Bergen County, NJ, USA; Prentice Hall Inc.: Upper Saddle River, NJ, USA, 1981. [Google Scholar]
- Cox, J.; Goldratt, E.M. The Goal: A Process of Ongoing Improvement; North River Press: Croton-on-Hudson, NY, USA, 1986. [Google Scholar]
- Performance Management: An Introduction. Available online: https://www.cipd.co.uk/knowledge/fundamentals/people/performance/factsheet (accessed on 10 December 2019).
- International Standard on Social Responsibility. Available online: https://asq.org/quality-resources/iso-26000 (accessed on 10 December 2019).
- Dwivedi, Y.K.; Wastell, D.; Laumer, S.; Henriksen, H.Z.; Myers, M.D.; Bunker, D.; Elbanna, A.; Ravishankar, M.N.; Srivastava, S.C. Research on information systems failures and successes: Status update and future directions. Inf. Syst. Front. 2015, 17, 143–157. [Google Scholar] [CrossRef] [Green Version]
- Womack, J.P.; Jones, D.T. Lean Thinking—Banish Waste and Create Wealth in your Corporation; Simon & Schuster: New York, NY, USA, 1996. [Google Scholar]
- Harris, M.; Tayler, B. Don’t Let Metrics Undermine Your Business. Harvard Business Review. 2019. Available online: https://hbr.org/2019/09/dont-let-metrics-undermine-your-business (accessed on 10 December 2019).
- Isaacson, W. Steve Jobs; Simon & Schuster: New York, NJ, USA; Toronto, ON, Canada, 2011. [Google Scholar]
- Capgemini Report. TechnoVision 2018: The Impact of AI. Available online: https://www.capgemini.com/technovision-2018-the-impact-of-ai/ (accessed on 10 December 2019).
- Thompson, J.D. Organisations in Action. Social Science Bases of Administrative Theory; McGraw Hill: New York, NY, USA, 1967. [Google Scholar]
- Kim, G.; Debois, P.; Willis, J.; Humble, J. The Devops Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations; IT Revolution Press: Portland, OR, USA, 2016. [Google Scholar]
- Lawrence, P.R. How to Deal with Resistance to Change. Harv. Bus. Rev. 1954, 32, 49–57. [Google Scholar] [CrossRef]
- Kotter, J.P. Leading Change: Why Transformation Efforts Fail. Harv. Bus. Rev. January 2007. Available online: https://hbr.org/2007/01/leading-change-why-transformation-efforts-fail (accessed on 10 December 2019).
- Pearl, J.; MacKenzie, D. The Book of Why: The New Science of Cause and Effect; Basic Books: New York, NY, USA, 2018. [Google Scholar]
- Norris, P. Digital Divide: Civic Engagement, Information Poverty and the Internet Worldwide; Cambridge University Press: New York, NY, USA, 2001. [Google Scholar]
- Lewin, K. Field Theory in Social Science; Harper and Row: Manhattan, NY, USA, 1951. [Google Scholar]
- Moss Kanter, R. Ten Reasons People Resist Change. Harv. Bus. Rev. September 2012. Available online: https://hbr.org/2012/09/ten-reasons-people-resist-chang (accessed on 10 December 2019).
- Allman, E. Managing Technical Debt. Commun. ACM 2012, 55, 50–55. [Google Scholar] [CrossRef]
- Ford, N.; Parsons, R.; Kua, K. Building Evolutionary Architectures: Support Constant Change; O’Reilly Media: Sebastopol, CA, USA, 2017. [Google Scholar]
- Weick, K.E. Educational Organizations as Loosely Coupled Systems. Adm. Sci. Q. 1976, 21, 1–19. [Google Scholar] [CrossRef]
- Orton, J.D.; Weick, K.E. Loosely coupled systems: A reconceptualization. Acad. Manag. Rev. 1990, 15, 203–223. [Google Scholar] [CrossRef] [Green Version]
- Ashkenas, R. Change Management Needs to Change. Harv. Bus. Rev. April 2013. Available online: https://hbr.org/2013/04/change-management-needs-to-cha (accessed on 10 December 2019).
- Luna, T.; Cohen, J. To Get People to Change, Make Change Easy. Harv. Bus. Rev. December 2017. Available online: https://hbr.org/2017/12/to-get-people-to-change-make-change-easy (accessed on 10 December 2019).
- Keller, S.; Schaninger, B. Getting Personal about Change. McKinsey Quarterly. August 2019. Available online: https://www.mckinsey.com/business-functions/organization/our-insights/getting-personal-about-change (accessed on 10 December 2019).





| No Change Intended | Change Intended | |
|---|---|---|
| Same Ecosystem | Transfer | Transform |
| Different Ecosystem | Translate | Transform |
| No Integration | Joint Ecosystem | |
|---|---|---|
| High External Interaction | B Requires an iterative approach. Requires high levels of collaboration between groups. | D Requires an iterative approach. Requires the overhead of establishing a joint ecosystem. |
| Low External Interaction | A Separate groups can operate in series or parallel. | C Requires the overhead of establishing a joint ecosystem. |
| Figure 4 Reference | Decoupling Approaches |
|---|---|
| Defined Selection Drivers | Defining selection drivers independently of each other. Incorporating selection drivers that focus on connections as well as silos. |
| Culture | Making change part of the culture. |
| TransferIPS CollaborationIPS (these are shown in Figure 4) | Designing groups and viewpoint patterns to reduce the need for information conversion. Designing groups and viewpoint patterns to reduce the need for information transfer. Creating a collaborative culture. |
| CoreIPS | These can either be treated as atomic or expanded out, and the same overall analysis is applied at the next level down. |
| Groups | Decoupling people from groups has an inbuilt difficulty, namely, the continuity of knowledge, but there are several approaches to be used with care because of the potential impact on quality:
|
| Tools | Enabling the separation of information from its generation (see Section 2). Reducing the need for extensive training for tools by incorporating good user research and user experience design. Making access to training straightforward (e.g., computer-based training). |
| Kotter Stage | Information Evolution Relationship |
|---|---|
| Establish a Sense of Urgency | Understand selection pressures, trends, and opportunities. Align leaders with desired outcomes. |
| Form a Powerful Guiding Coalition | Ensure alignment to desired outcomes. Collaborate to avoid the effects of silos. |
| Create a Vision | Define the outcomes and viewpoint for the change. |
| Communicate the Vision | Communicate the change viewpoint to ensure alignment more widely. Use the leadership to start to change dependencies (including culture). |
| Empower Others to Act on the Vision | Implement selection pressures aligned with the change. Encourage the implementation of the required dependencies (including culture). |
| Plan for and Create Short-Term Wins | Implement the change viewpoint pattern. Implement selection pressures aligned with the change. Improve change connection memory. Encourage the implementation of the required dependencies (including culture). |
| Consolidate Improvements and Produce More Change | Reinforce selection pressures aligned with the change. Implement the change viewpoint pattern and update the change viewpoint pattern. Improve change connection memory. Encourage the implementation of the required dependencies (including culture). |
| Institutionalize New Approaches | Reinforce selection pressures aligned with the change. Improve change connection memory. Encourage the implementation of the required dependencies (including culture). |
| Principle | Commentary |
|---|---|
| Align Internal Selection Pressures with External Selection Pressures |
|
| Create a Change Ecosystem |
|
| Create an Adaptive Business Architecture |
|
| Manage One-Off Change Adaptively |
|
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Walton, P. Information Evolution and Organisations. Information 2019, 10, 393. https://doi.org/10.3390/info10120393
Walton P. Information Evolution and Organisations. Information. 2019; 10(12):393. https://doi.org/10.3390/info10120393
Chicago/Turabian StyleWalton, Paul. 2019. "Information Evolution and Organisations" Information 10, no. 12: 393. https://doi.org/10.3390/info10120393
APA StyleWalton, P. (2019). Information Evolution and Organisations. Information, 10(12), 393. https://doi.org/10.3390/info10120393