1. Introduction
Nowadays, computer programming proves to be a crucial domain not only in university education, but also in younger education. This trend is related to the fact that programming is considered one of the best ways to stimulate articulated and logical reasoning in problem solving, which we have to constantly face in our daily lives. Despite its importance, teaching in programming courses continues to be problematic due to several issues: (1) it is a complex domain that requires the student to master a panoply of concepts; (2) classroom methodologies are still composed of theoretical presentations of language syntax that do not enhance programming practice, which is crucial for learning in this domain; (3) courses have an extensive curriculum, typically with large classes, which makes it difficult for teachers to give rich and consistent feedback to all students.
Learning computer programming can be a lonely, complex, and demotivating process [
1,
2,
3]. These issues have been addressed in the last years, with the appearance of several online learning environments trying to leverage coding education and make it accessible to everyone, even those with absolutely no coding experience or knowledge [
4,
5]. These environments come in various formats ranging from non-interactive approaches (e.g., YouTube channels, blogs, books) to integrated and interactive solutions (e.g., intelligent tutors, online coding providers, Massive Open Online Courses (MOOCs)) [
6].
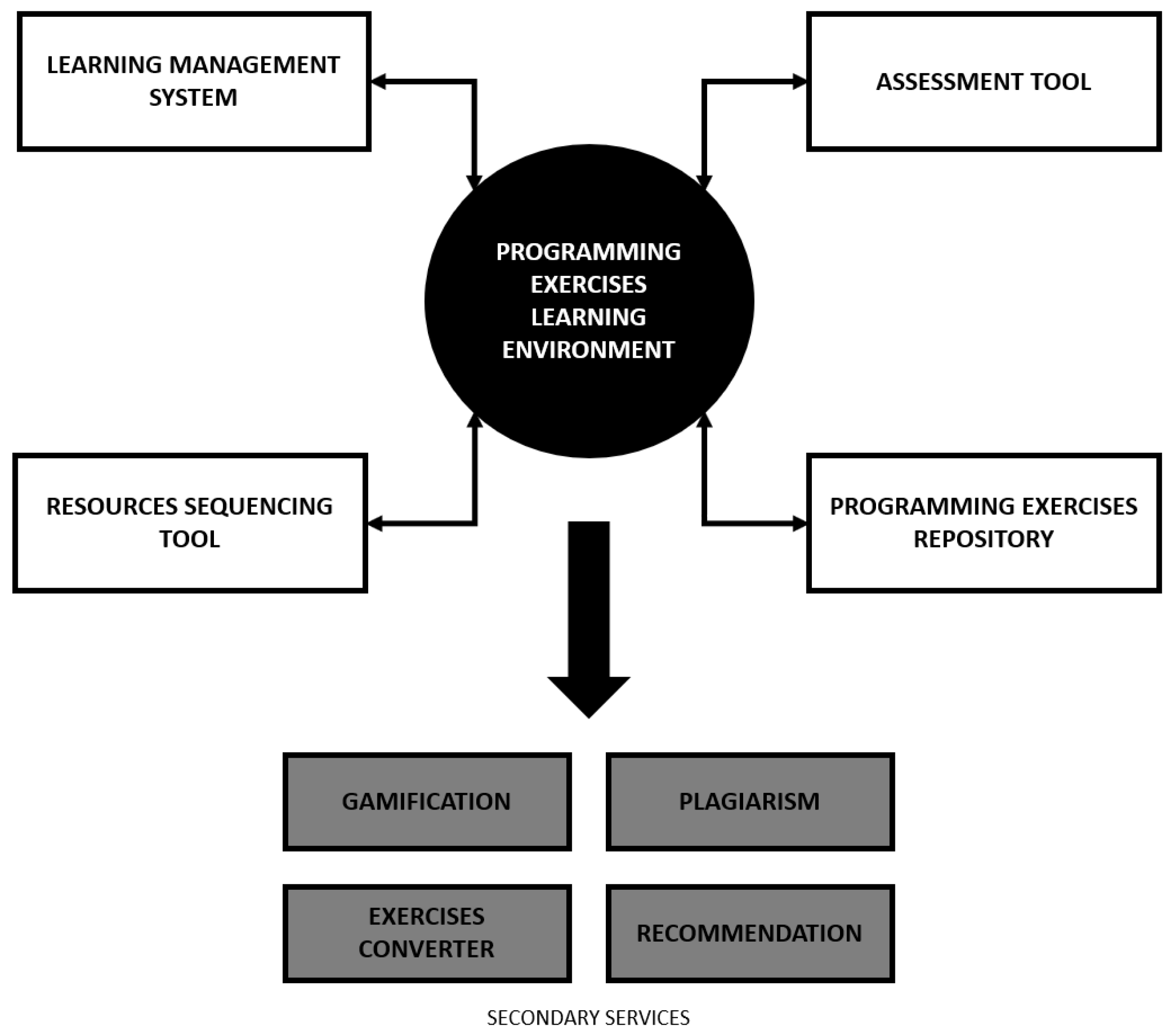
In order to overcome these issues, several systems have emerged in recent years to automate the teaching–learning process of computer programming [
7]. These systems were given various names: interactive learning environments, online playgrounds, learning management systems, MOOCs, and intelligent tutors among others. Regardless of their names, their main goal is to make available interactive 24x7 environments where students have at their disposal a set of programming exercises to solve. After their resolution and submission, students receive automatic feedback sent through an online assessment system. With this approach, the teacher relieves their manual evaluation work and focuses on other important aspects of the teaching process, such as the creation of new programming exercises. Despite their partial success, these systems present several problems related to evaluation, interoperability, user experience, and adaptability among others [
8]. Regarding evaluation, existing systems are limited to give concise feedback on students’ performances; they do not go into details about the code, such as the use of certain keywords, the code style used, or the implemented algorithm. These systems also have poor interoperability features, for instance, not allowing a flexible integration with the existing learning management systems. The user experience is often neglected causing latencies in page loading or remote requests. This is often due to the fact that online environments try to mimic traditional integrated development environments, making interaction more complex and time consuming. In terms of adaptability, most systems present a rigid sequence of exercises to be solved, with unsuitable content sequencing and a great inability to adapt to the learner’s profile.
One of the great trends of the last decade is the use of gamification in several types of environments [
9,
10], including online programming learning environments [
11]. The goal is simple: keep students motivated and encourage more practice in order to gain programming skills. Although it is a legitimate goal, the gamification used is limited to a set of badges that are earned when the student completes a particular module or a set of rankings, to compare the students’ performance in the course. Despite being a step forward in the gamification of these environments, there is still much more to explore in order to stimulate the students’ competitiveness [
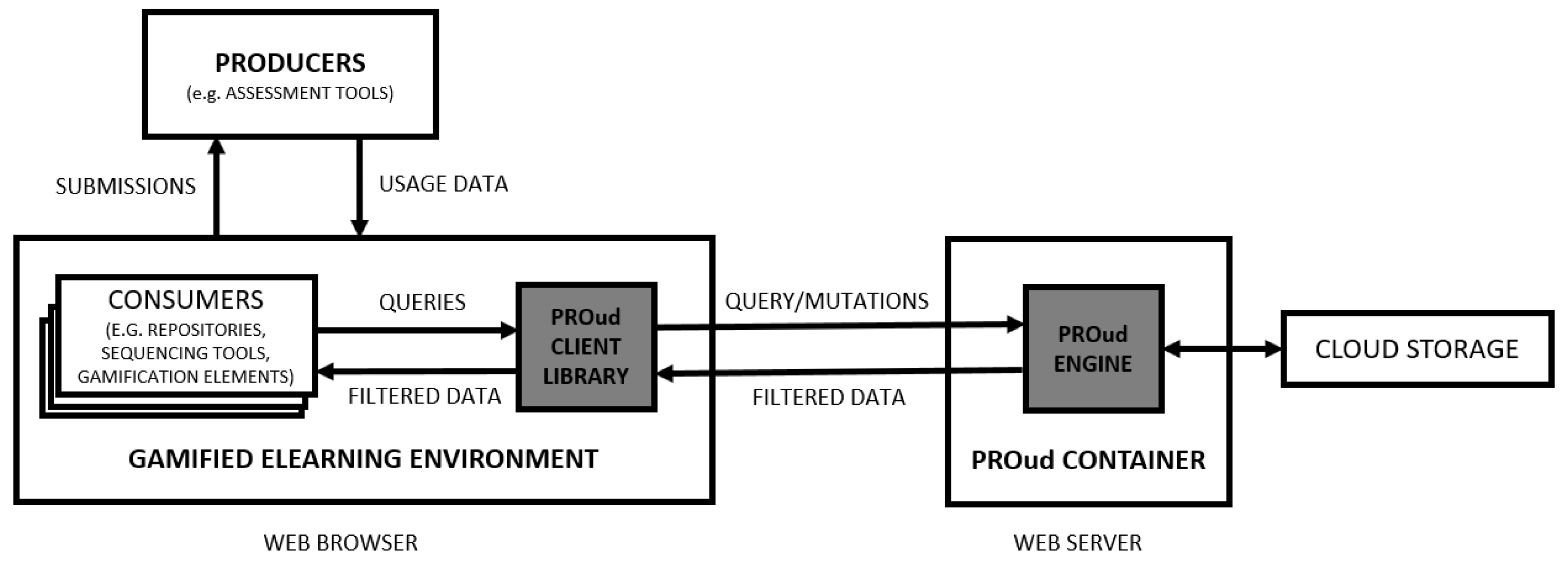
12]. In order to do this, our proposal is to gather information about the usage data of the programming exercises. Such information can then be stored in a central storage and, through a programming interface, can be used in a flexible way, as input to various components of the learning system or in the construction of specific gamification assets (e.g., leaderboards, achievements, statistical panels).
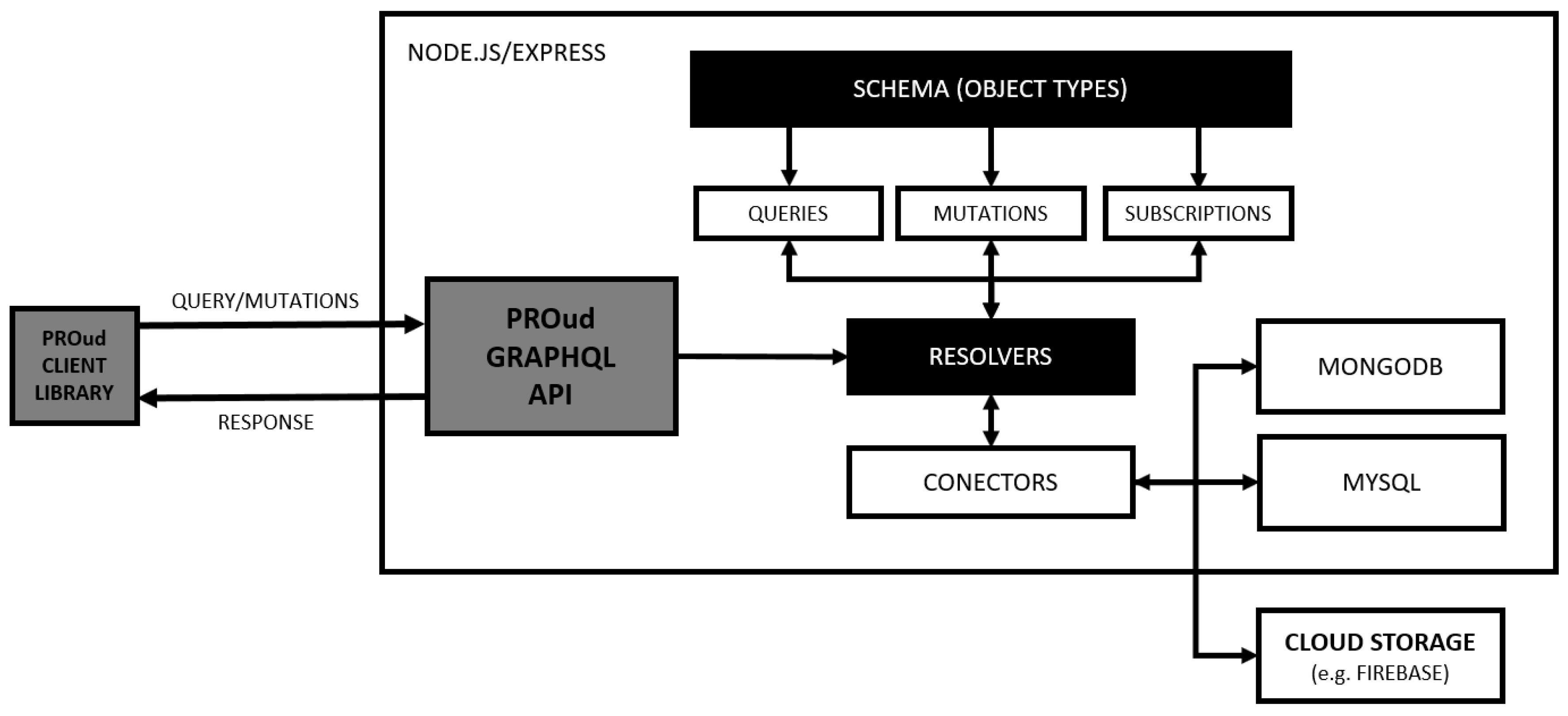
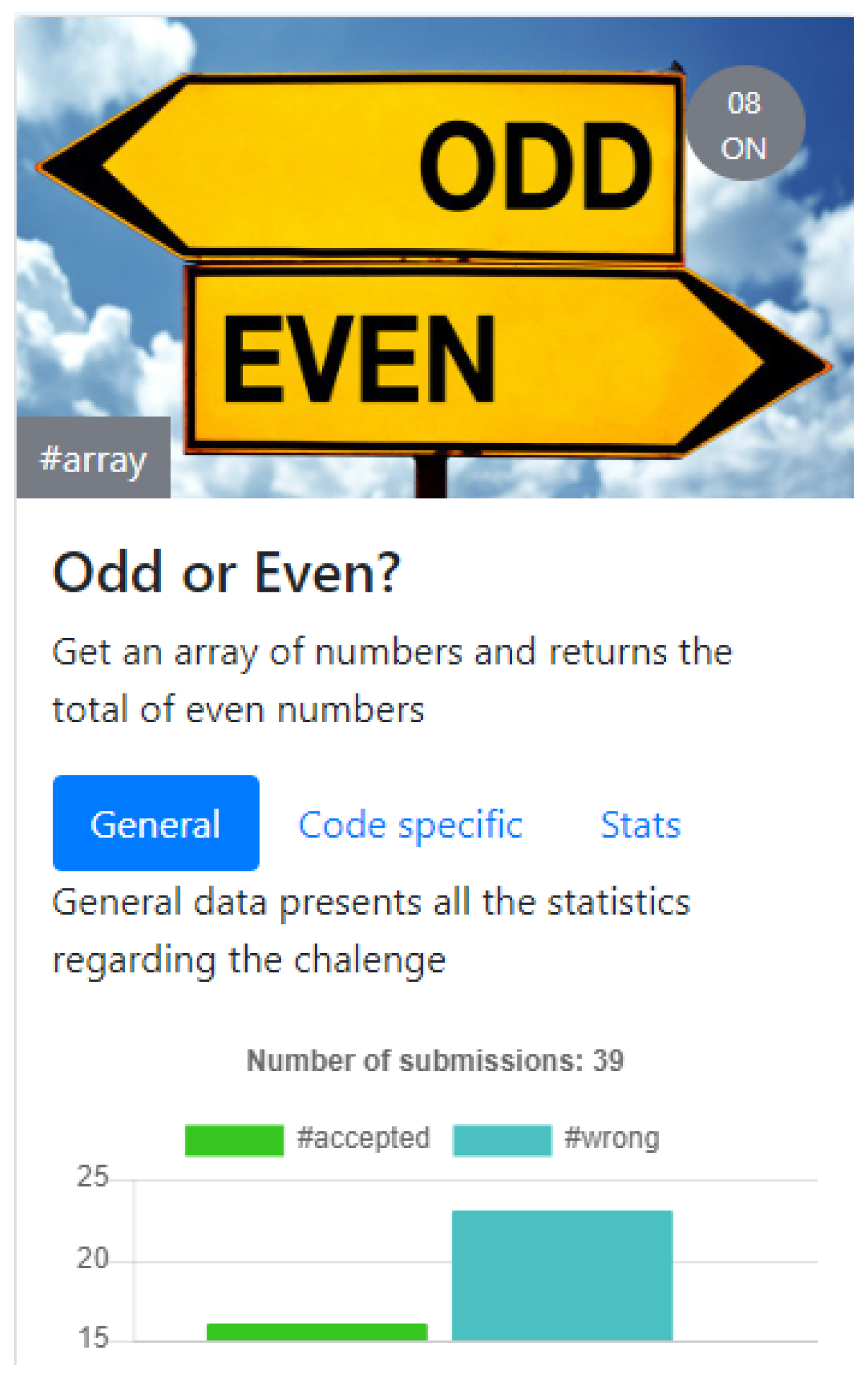
This paper presents PROud—a framework to foster gamification features in learning environments based on the usage data of programming exercises. The framework is composed of several components: a storage where all usage data is stored; an API to expose filtered usage data; and a client library that will allow any web developers to rapidly inject multiple gamification features and integrate them seamlessly into a computer programming teaching–learning environment. In order to evaluate PROud, we used it for the construction of a gamification asset to present programming exercises statistics.
The article is structured as follows:
Section 2 presents the various tools that typically arise in a teaching–learning computer programming ecosystem. Afterwards, PROud is presented as a framework to facilitate the creation of gamification elements based on the the usage data from programming exercises. Then, one case study is presented where the framework can be used, more precisely, in the creation of a statistics panel related to a given programming exercise. Finally, conclusions are presented regarding this work and a set of improvements to be made in the short term are discussed.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}