1. Introduction
Among the plethora of choices for communication at a professional or social level, online social networks stand ahead as an option that allows individuals to connect, communicate and interact within a virtual online environment. Social networks aim to facilitate individuals to connect through social relations (e.g., friendship, follower, colleague links, etc.) and communicate with each other either privately or publicly [
1,
2].
Product review sites (e.g., Epinions, Yelp, Amazon, etc.) have emerged as a new type of social network that aims to support consumers in making buying decisions for products. In such networks, consumers write reviews and provide ratings for products they have bought, form their opinion by reading product reviews written by other users, or form trust bonds with other users whose opinions they trust.
Graph representations and graph based algorithms have been very popular among researchers that perform analysis of social networks [
3]. In the graph representation of a typical social network, users are represented as vertices and the relations that connect them are represented as edges, forming the social graph, which is then used by algorithms to extract useful knowledge (influencers, cliques, communities, etc.). In the simplest form of product reviewing social networks, a new type of vertices is introduced to represent product items and a new type of weighted directed edge is added to represent ratings assigned by users to products. Bipartite graphs are ideal for this representation, since they define two disjoint sets of nodes (i.e., users, items) and directed edges that connect nodes from different sets (a user with an item).
Since the introduction of Recommender Systems in the users’ daily activities, the evolution both in the way users interact with the web and with each other has been exceptional. The link between these two domains is currently very tight and this is the result of approaches that applied knowledge from one domain to improve user experience in the other. From one side, recommender systems benefitted early from the content that users share in social networks, which has been used to create a richer user profile [
4]. From the other side, social networks took advantage of recommender systems to filter the abundance of information available to their users and create a personalised experience. Several research works attempted to combine both worlds, recommender systems and social networks, in ways that aim to change how people connect with each other, how they interact and what content items they share [
5].
Lately, the field of application of recommender systems has expanded in a wide area of domains such as creating movie or music recommendations, suggesting related news, finding useful scientific research papers, recommending possible social connections or potential product users could be interested in buying. However, the type of domains’ recommender systems are used for are not limited to the above. There have been developed many domain-specific recommender systems such as for finding experts based on a query string and the domain characteristics [
6], or potential researchers for collaborating with [
7], even for supporting suggestions on loans, etc. [
8], or just simply suggesting pages of interest in Twitter [
9]. In general, RSs aim to solve the information overload problem for the users of a social network by recommending items, which can either be content, products, services or even other users.
In the case of product review or product rating sites, the analysis of the bipartite graphs and the information they carry has attracted the interest of researchers in recommender systems, and gave rise to new solutions and algorithms. Recommender systems have become very popular on sites such as IMDB, MovieLens and Netflix, where users rate the films they have seen and receive recommendations for more films of potential interest to them.
It was back in October 2006 when Netflix launched an open contest, which challenged research teams across the world to beat (in terms of the Root Mean Square Error of predicted ratings’ metrics) their ratings prediction algorithm. The competition aimed to find the best algorithm that predicts user ratings for films, based on their previous ratings and the ratings of other users. The winning algorithm by the Bell and Koren’s team (BellKor Pragmatic Chaos) bested Netflix’s own algorithm by 10.06% and was a Collaborative Filtering (CF) algorithm that gave rise to Matrix Factorisation approaches in recommender systems [
10,
11].
Collaborative Filtering (CF) is one of the most well examined and primarily used techniques in recommender systems to create personalized content that will be provided as recommendations to the targeted users, tailored to each user’s preferences. The premise in CF is to use the information from the preferences (typically expressed as ratings) of the user’s closest neighbors to generate recommendations. The neighbors of a user can be found based on: (a) the similarity between users’ profile features such as demographics, etc., (b) the items that users have reviewed in common and the ratings they have provided for them, and (c) the proximity of a user with other users in the social graph.
When used in the context of social networks, recommender systems suggest users, content, or both and this is based on the explicit or implicit preferences of the user. Explicit preferences are expressed with likes and follows and implicit with views and other actions that denote interest.
Some of the most well-known social networks, such as Facebook or Twitter, have millions of users, which means that the respective graph size is huge. In addition, the expansion rate of such networks is also impressive, since thousands of new users are added daily, and this pushes the limits of the recommendation algorithms, which must be able to scale up to billions of users and trillions of items and implicit or explicit edges [
12]. The maintenance of high performance and low latency of the social network services is unquestionable, no matter how many new users are connecting or how many new content items have been added.
Using bipartite graphs to represent the user-item rating matrix is a straightforward option, especially in social networks, where trust or friendship information is also available in the form of a graph [
13,
14]. Deep learning and matrix factorization methods are gaining the hype in the recommendation systems research. Although they operate differently than graph-based methods, they are still based on the rating matrix information, but either process the whole matrix information in a single node or randomly partition the matrix in (usually overlapping) sub-matrices for scalability [
15]. In this work, we mainly use the bipartite graph representation as a means for partitioning the rating matrix using a less random and more meaningful method. Our partitioning method can take advantage of the social network structure or any other similarity information between users or items. Building on this concept, we examine various methods that build on a better partition overlap and try for a better collaborative filtering performance both in time and quality performance.
The diversity in the size and characteristics of the information created in social networks and applications in many cases push the current state-of-the-art recommender systems algorithms to their limits. The scalability of processing algorithms is further challenged by additional nodes and edges added to the user graph, which may correspond to content items and user interactions with them [
16].
The two main alternatives for scaling to large graphs (or large rating matrices in general) are to either upgrade the infrastructure in order to cover the increasing processing requirements, or to partition the graph (or the rating matrix) into smaller sub-graphs, which can be processed in parallel, thus increasing performance without losing quality of the produced results.
Our previous work in the field showed the potential of graph partitioning solutions, which can benefit from by the social graph formed in social networks [
17]. People usually consider the opinions of their friends more than the opinions of any random user, so the partitioning of the bipartite (ratings) graph can be based on a pre-partitioning of the social graph. However, this partitioning has a limit, due to the sparsity of the resulting bipartite partitions [
18]. As a result, it is important to consider the sparsity of the partitions of the bipartite graph and, if possible, to reduce this sparsity by replicating edges (ratings) across partitions.
In our last work [
18], we split the initial problem into sub-problems that can be solved more efficiently using parallel and distributed algorithms, without loss of the effectiveness of the provided solutions (measured by the quality of the generated recommendations). In this work, we study the scalability and the efficiency of this approach in generating user-to-item recommendations using the Collaborative Filtering algorithms of Apache Spark. More specifically, we experiment only with Singular Value Decomposition (SVD++) algorithm [
19] and its implementation in Apache Spark, which is a state-of-the-art collaborative filtering algorithm [
20]. The proposed approach is based on an initial partitioning of the bipartite graph. For the sake of generality, we do not assume a social graph behind the bipartite graph as we did in previous works. The partitioning of the bipartite graph is done at random and only some of the ratings are replicated across partitions. We evaluate different edge replication strategies across partitions, which aim to increase the performance of the CF algorithm in each partition, and report on their performance.
The contributions of this manuscript focus on introducing an architecture for parallel collaborative filtering addressing the problem of collaborative filtering parallelization in the case of sparse graphs and proposing approaches for improving CF’s prediction performance.
The rest of the paper is organized as follows: in
Section 2, we summarize related work on distributed and parallel collaborative filtering solutions. In
Section 3, we present our proposed method for optimizing Collaborative Filtering in distributed or parallel environments, which is based on the replication of selected edges (ratings) across partitions. In
Section 4, we evaluate the various strategies for selecting which edges to copy across partitions, using a dataset from Epinions for our experiments, and discuss the results. Finally, in
Section 5, we provide the conclusions and the next steps of our work.
2. Related Work
Collaborative Filtering algorithms have been the state-of-the-art solution for the generation of recommendations in various social network applications. Two of the main problems that CF algorithms have to confront [
21] are the
information sparsity and the
lack of scalability in huge datasets. Recent advances in CF algorithms capitalize on the use of deep neural network architectures for adding implicit feedback [
22] to the original rating matrix, thus creating a latent space with reduced sparsity. Implicit information is either collected from textual reviews or images that accompany user ratings, thus creating a multi-modal [
23] and multi-aspect model [
24] for handling item ratings, amd increasing the complexity of the problem and -in some cases- the sparsity of the space. The concept of mapping the original high-dimensional space to a latent low-dimensional semantic space [
25] is a common practice for reducing sparsity. A completely different approach to CF on the low-dimensional matrix has been introduced in [
26], where a smoothing technique is applied to the user–item bipartite graph using the target user’s known preference as a query vector. The technique in [
26] is based on the main principle that common ratings (co-citations) denote item similarity and uses this principle to rank items to be recommended instead of predicting a specific rating for each item.
The undeniable progress in the field of recommender systems has led to a great research interest towards parallel and distributed implementations of collaborative filtering algorithms. The majority of today’s online shops and applications demand lots of high processing units to support their functionality. With current loads of information in these applications, traditional state-of-the-art implementations of CF algorithms could not cope with these needs. A first direction in addressing the efficiency problem of Collaborative Filtering (CF) comprises methods that hash users and items as latent vectors in the form of binary codes, so that user-item affinity can be efficiently calculated in a Hamming space [
27]. In a similar direction, low-dimensional item embeddings that incorporate both graph structure and feature information have been used in [
13] to reduce the space complexity and thus increase scalability. The approach involved the use of Graph Convolutional Networks to combine random walks and graph convolutions on the bipartite graph. The second direction focuses on the distribution and parallel execution of the CF algorithm in multiple machines. The tendency of using computer clusters to combine processing power and distribute the processing load has affected the implementation of various CF algorithms to deal with the scalability issues over the last years. Based on this, Java Threads, Pthreads, OpenMP frameworks for parallel programming and Mahout, Apache Spark for data processing have been utilized to implement collaborative filtering [
21,
28].
One of the first distributed approaches for generating recommendations was presented by [
29] that proposed a peer-to-peer SVD model for aggregating user profile information and creating recommendations. Another distributed approach of matrix factorization (SGD) algorithm was implemented in [
30], where authors proposed a model of a system for distributed sharing of user-generated content streams. In the same context of recommender systems in decentralized environments like P2P, PipeCF algorithm [
31,
32] has also been proposed. PipeCF algorithm first divides the original user database into buckets which are stored in different peers and each is assigned an identifier in order to use this as a key when needed. Then, PipeCF uses the information from all users in the same bucket with the active user to compute the predictions. The algorithm increases the weights for the contributions of the most similar users (unanimous amplification) and decreases the weights for users that have rated many items (significance refinement) in a process that is similar to the Term Frequency and Inverse Document Frequency (TF/IDF) weighting of terms in a text collection.
Wang and Pouwelse [
33] introduced a predictive model for user-item score prediction, using buddy-tables, which are used to store the top-N most relevant to the user items and are shared across a P2P network users. Recently, leveraging the benefits of distributed processing, authors in [
34] proposed a hybrid model called Distributed Partitioned Merge (DPM) model, for processing large social graphs. Using a combination of Fork-Join programming and Pregel framework authors stated that based on their evaluation DPM outperforms both Fork–Join and Pregel’s recommendation time.
A television show collaborative recommendation system that uses item-to-item collaborative filtering and delegates most of the work to the numerous network clients rather than centralizing process to the server is presented in [
35]. User reviews and comments are common sources for extracting user preferences and creating item recommendations. In this context, researchers in [
36] used short review texts to create recommendations based on word vector representations. They used word vector representations for users and items; then, they created a set of training data with the rating scores that users give to items based on these representations and finally used a regression model that was trained to predict the unknown user-item ratings. Furthermore, Ref. [
37] introduces two methods for modeling users’ review texts, one based on Bag-of-Words Paragraph Vectors [
38] and another using recurrent neural networks (RNNs) respectively, in order to produce representations of products used in Collaborative Filtering.
Since Hadoop is one of the most widely used frameworks for distributed processing, Ref. [
39] proposed a hybrid approach for recommending movies combining user-based collaborative filtering and content-based filtering and using Hadoop and Hive to create SQL queries. Another interesting hybrid approach for creating recommendations was developed in [
40]. Authors used Apache Spark for parallel implementation of a hybrid collaborative filtering algorithm, whereas, in order to deal with the collaborative filtering limitations, they used dimensionality reduction and clustering techniques.
Scalability is one of the biggest issues for modern collaborative filtering approaches [
18]. Dealing with this problem, Lee and Hong [
41] proposed an Adaptive Collaborative Filtering algorithm Based on Scalable Clustering (ACFSC), which first creates a cluster model for users/items that is based on their feature vectors and then uses the users’ neighborhood only to get recommendations based on CF. As already mentioned before, partitioning and clustering are very promising methods for dealing with scalability. Consequently, researchers in [
42] combine user and item similarities, multi-dimensional clustering to cluster metadata information and cluster pruning to measure the predicted weighted average score of the user ratings. In addition, N-cut graph clustering can be used to group similar user in the same cluster to increase Collaborative Filtering performance [
43].
The main limitation on using clustering incorporated with CF in large sparse graphs is the higher demands on processing power for the clustering process and the increasing probability of prediction errors due to higher sparsity. The proven usability of frameworks like Apache Spark for distributed processing and the scalability limitations of collaborative filtering is the motivation that drives our proposed approach. Based on our evaluation results, the idea of using graph partitioning with partition refinement seems to be a feasible and promising approach.
3. System Architecture
The concept behind collaborative filtering algorithms is that users with very similar profiles are more likely to be interested in the same items or inversely when a user is interested in an item then he/she is more likely to be interested in more items with similar features. Based on this concept, the performance of collaborative filtering algorithms depends on the information we have for users and items. When collaborative filtering algorithms rely only to the bipartite graph of user ratings for items, then the user-to-user similarity is defined on the number of items they rated in common or on the agreement of their ratings for these item (e.g., using cosine similarity). When a new user enters the social network, there is no information about his/her ratings so the similarity to all other users cannot be defined, leading to the cold-start problem. Even for existing users, when the total number of ratings is very low compared to the number of users and items in the social network (i.e., sparse network), it is very likely that users may have rated completely different items, so the user similarity, which is measured on commonly rated items, cannot be defined or is not properly measured. Using information from other sources, such as the social connections between users [
44] or user and item context is a promising solution, but is not always applicable.
The distributed processing of a sparse ratings’ graph will result in even more sparse partitions and thus affect the performance of collaborative filtering algorithms. In our previous work [
18], we applied graph partitioning to the large ratings’ graph in order to tackle the problem of scalability of collaborative filtering algorithms, but restricted the number of partitions in order to avoid high sparsity. In this work, we extend the previous approach, which also took advantage of distributed architectures (like Apache Spark) and algorithms (like SVD or SVD++), by adding some new refinements in the initial methodology of graph partitioning on the bipartite graph. Our extension begins with the partitions of the bipartite graph, which could be created with any graph partitioning technique, and replicate selected ratings in all partitions in order to increase the density in each partition and boost the performance of the SVD++ algorithm, even for partitions with only one rating.
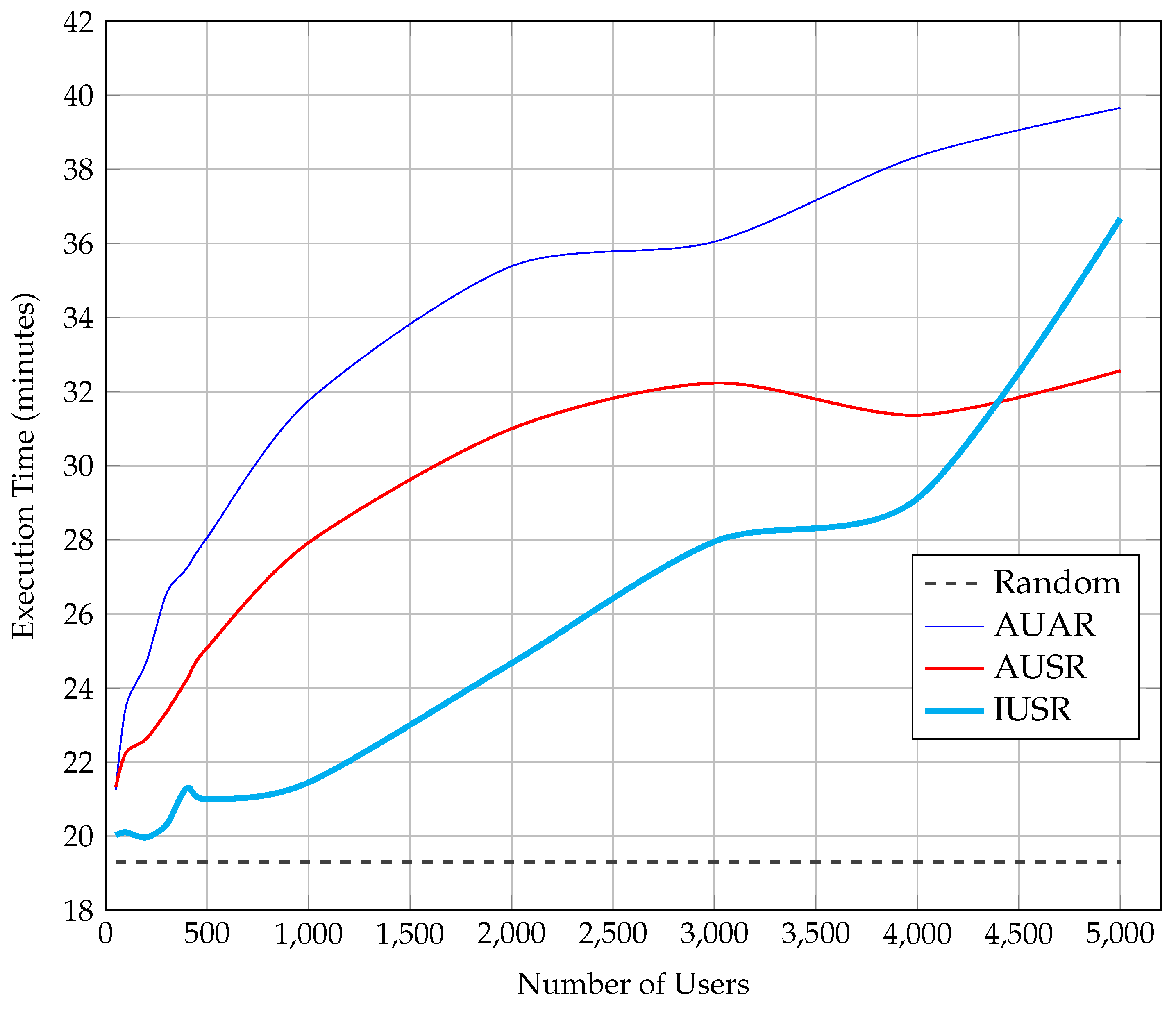
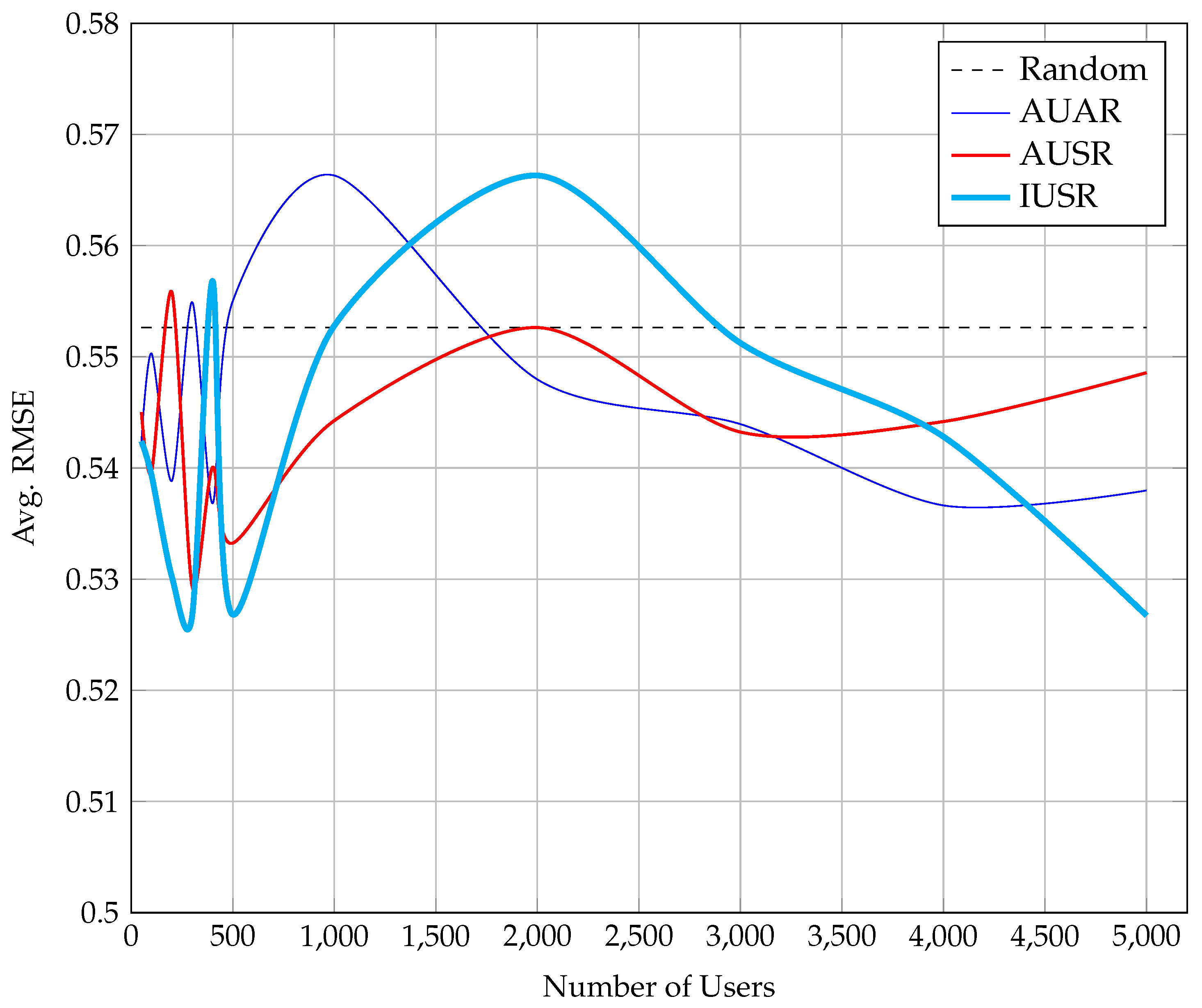
We develop two strategies for choosing the ratings that will be replicated across partitions. The first strategy aims at identifying the most active users inside each partition, where active users are the users that contribute the majority of ratings in the partition. Then, it replicates the ratings of the active users to all partitions in order to increase the total number of ratings per partition. This strategy has been implemented in two different scenarios. In the first scenario (Active Users All Ratings—AUAR), all the ratings provided by an active user in partition , where , are replicated to all the other partitions. This scenario improves the collaborative filtering algorithm since it introduces more users to the partitions and thus allows finding more similar users to a selected user. Its main drawback is that it can probably introduce new items to the partition and thus may increase the sparsity () of the partition and consequently the prediction error.
The second scenario (Active Users Selected Ratings—AUSR) also replicates the ratings of active users across partitions, but tackles the main drawback of the AUAR scenario. This is done by finding the active users of a partition (e.g., ), but replicating only the ratings for items that already exist in each target partition. For example, if an active user in has rated items from which only exists in partition , then only the rating for is replicated to . This tactic is very promising for bipartite graphs with a high number of items compared to users since it does not affect the item set of the target partitions, but only adds rating information, thus reducing sparsity and the average error for the predicted scores.
A similar issue to cold-start users in Collaborative Filtering are the items that have none or very few ratings. For these items, the algorithm can hardly find similarities since it has very little information. Our second strategy aims to support these least rated items (LRIs) by adding ratings from other partitions. In its first step, it identifies the least rated items across all partitions (e.g., the items that have received only one rating in their partition). In the second step, it uses this list of (LRIs) and repeats the steps of the first strategy for these items only. Thus, it first redefines the concept of Active Users in a partition to be the most Informative Users that have rated the majority of LRIs. Then, it replicates the ratings of these Informative Users across partitions. Only the selected ratings scenario is evaluated Informative Users Selected Ratings—IUSR, since the all ratings scenario suffers from increased sparsity.
As described so far, our approach (depicted in
Figure 1) is based on a three-stages architecture: (i) Graph partitioning, (ii) Partition refinement, and (iii) Distributed execution of the CF algorithm in Spark nodes, which also includes the evaluation of results. The starting point of our model is a bipartite graph with a set of Users
U, a set of Items
I and the respective edges of ratings
R among these sets. The first stage in our approach involves the random split of the initial graph into partitions, whereas the only premise is the equality in terms of size (number of ratings) among the different sub-graphs. The partition refinement stage that follows the two strategies (three scenarios) described above is followed, in order to improve the overall density of the partitions and consequently reduce the prediction error. The final stage of our approach consists of the execution of a distributed Collaborative Filtering algorithm over the refined partitions produced in stage two and the evaluation of the results using a 10-fold cross validation approach. In order to evaluate the contribution of the various strategies, we measure the number of ratings that are replicated across partitions, the resulting sparsity of partitions, the time complexity and the prediction error of each method.
Algorithm 1 describes the graph partitioning with edge replication (GPwER) approach.
| Algorithm 1 Graph partitioning with edge replication across partitions |
![Information 10 00155 i001]() |
The procedure begins with the partitioning of the bipartite graph (), which comprises user () and item () vertices and rating edges (R), into a set of n not overlapping partitions () (i.e., and ). It then continues with any of the three scenarios proposed in this work: AUAR, AUSR () and IUSR () that add edges to each bipartite graph partition and result in a set of enhanced partitions () that are given as input to the CF algorithm.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}