DGA CapsNet: 1D Application of Capsule Networks to DGA Detection

Abstract
:1. Introduction
- A 1D version of Capsule Networks (CapsNet), a new CNN architecture that eliminates maximum pooling layers in favor of new capsule layers
- A 1D CNN that contains multiple layers, including maximum pooling layers
2. Background
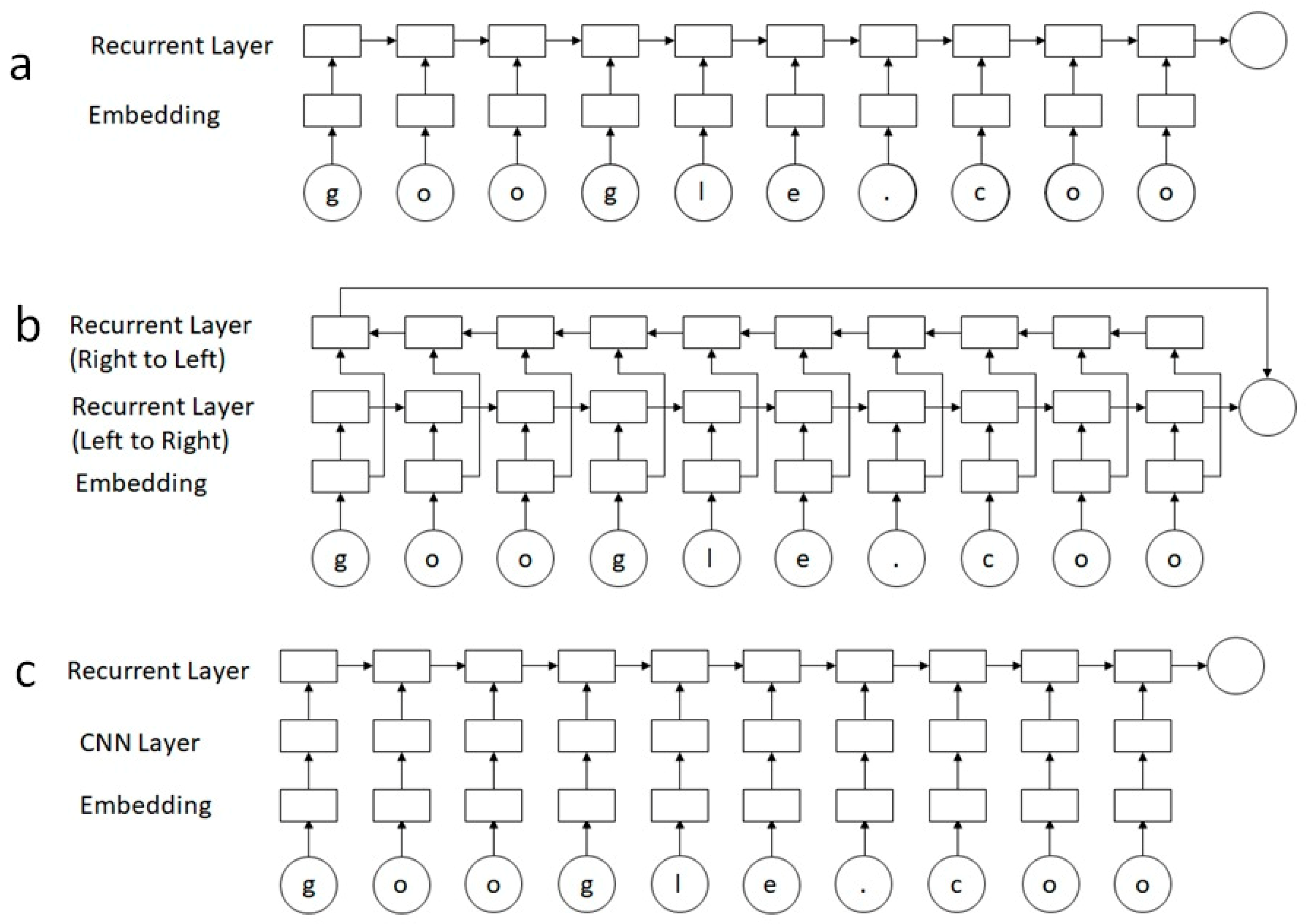
2.1. Embedding
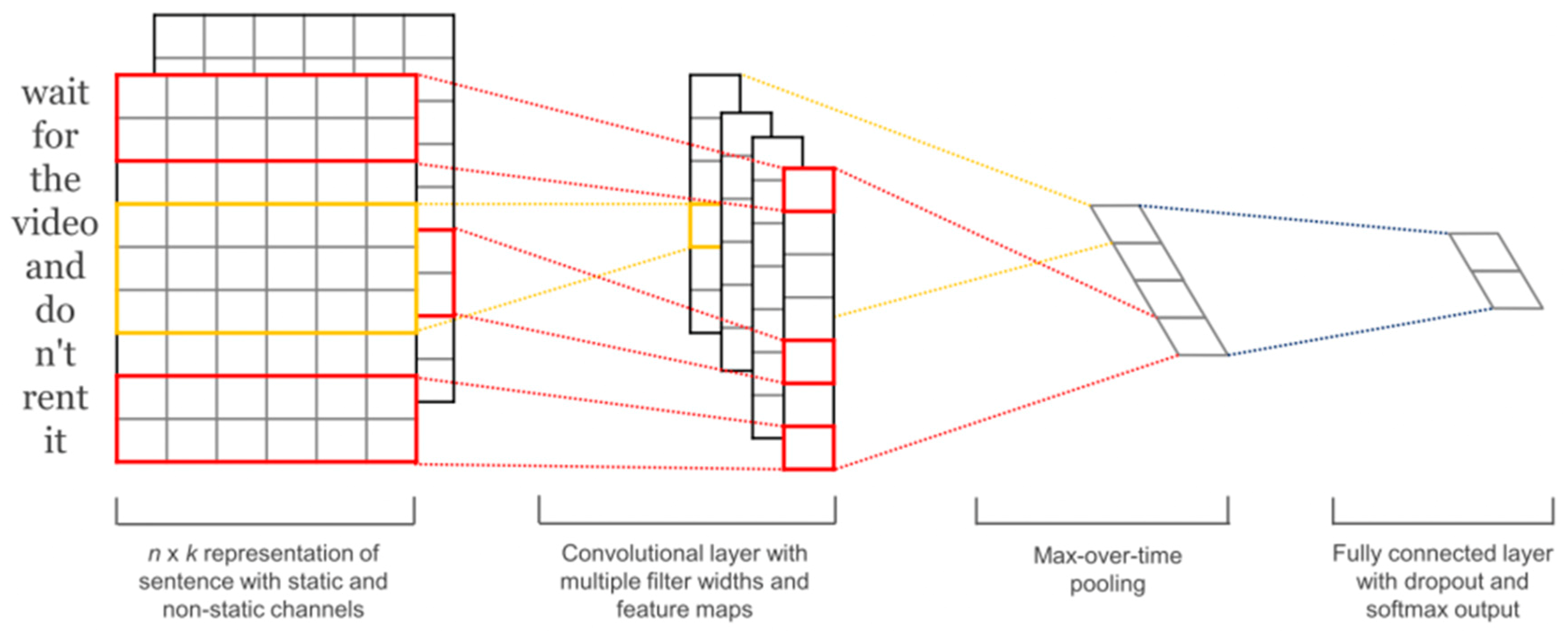
2.2. Convolutional Neural Networks
- Reduces the number of parameters for the model,
- Reduces the memory required to perform computations, and
- Reduces overfitting.
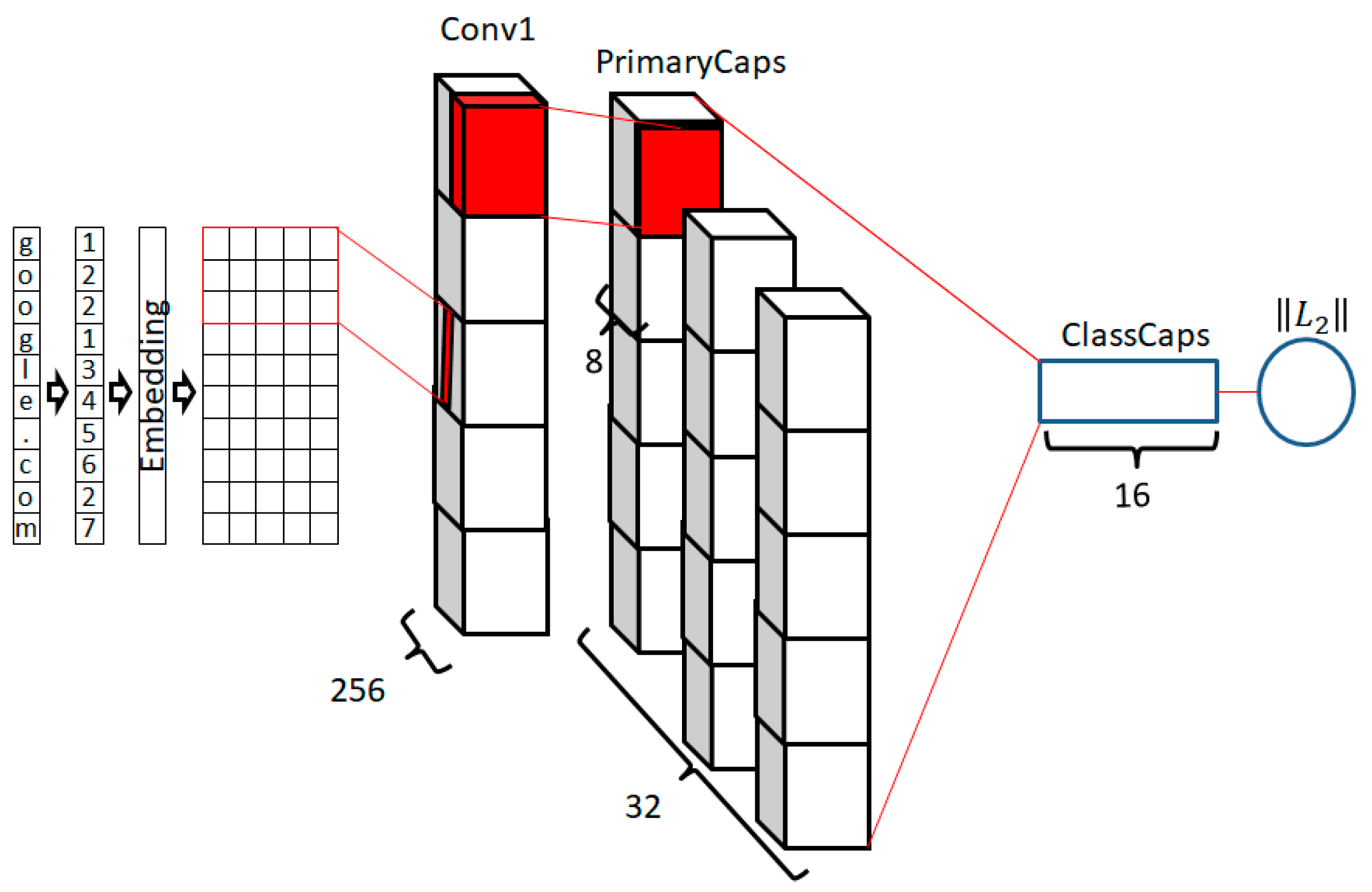
2.3. Capsule Networks
2.4. LSTMs
3. Model Implementation
4. Datasets
- The Alexa top one million domains, which formed the list of benign domain names [30].
- The Open-Source Intelligence (OSINT) DGA feed from Bambenek Consulting, which provided the malicious domain names [31]. This data feed was based on 50 DGA algorithms that together contained 852,116 malicious domain names. The dataset was downloaded on May 23, 2018 and DGAs were generated on that day. Also, on April 18, 2019, an additional dataset of 855,197 DGA generated domains was downloaded from OSINT for testing differences in model performance based on time and is regarded as a separate test dataset.
5. Evaluation Metrics
6. Results
7. Conclusions
Funding
Conflicts of Interest
References
- Domain Generation Algorithm (DGA). Available online: https://searchsecurity.techtarget.com/definition/domain-generation-algorithm-DGA (accessed on 23 April 2019).
- McGrath, D.K.; Gupta, M. Behind Phishing: An Examination of Phisher Modi Operandi. In Proceedings of the First USENIX Workshop on Large-Scale Exploits and Emergent Threats, LEET ‘08, San Francisco, CA, USA, 15 April 2008. [Google Scholar]
- Bilge, L.; Kirda, E.; Kruegel, C.; Balduzzi, M. EXPOSURE: Finding Malicious Domains Using Passive DNS Analysis. In Proceedings of the Network and Distributed System Security Symposium, NDSS 2011, San Diego, CA, USA, 6–9 February 2011. [Google Scholar]
- Ma, J.; Saul, L.K.; Savage, S.; Voelker, G.M. Beyond blacklists: Learning to detect malicious web sites from suspicious URLs. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 1245–1254. [Google Scholar]
- Yadav, S.; Reddy, A.K.K.; Reddy, A.L.N.; Ranjan, S. Detecting algorithmically generated domain-flux attacks with DNS traffic analysis. IEEE/ACM Trans. Netw. 2012, 20, 1663–1677. [Google Scholar] [CrossRef]
- Antonakakis, M.; Perdisci, R.; Nadji, Y.; Vasiloglou, N.; Abu-Nimeh, S.; Lee, W.; Dagon, D. From Throw-Away Traffic to Bots: Detecting the Rise of DGA-Based Malware. In Proceedings of the 21st USENIX Security Symposium, Bellevue, WA, USA, 8–10 August 2012. [Google Scholar]
- Nhauo, D.; Sung-Ryul, K. Classification of malicious domain names using support vector machine and bi-gram method. J. Secur. Appl. 2013, 7, 51–58. [Google Scholar]
- Demertzis, K.; Iliadis, L. Evolving smart URL filter in a zone-based policy firewall for detecting algorithmically generated malicious domains. In International Symposium on Statistical Learning and Data Sciences; Springer: Cham, Switzerland, 2015; pp. 223–233. [Google Scholar]
- Shibahara, T.; Yamanishi, K.; Takata, Y.; Chiba, D.; Akiyama, M.; Yagi, T.; Ohsita, Y.; Murata, M. Malicious URL sequence detection using event de-noising convolutional neural network. In Proceedings of the 2017 IEEE International Conference on Communications, Paris, France, 21–25 May 2017; pp. 1–7. [Google Scholar]
- Woodbridge, J.; Anderson, H.S.; Ahuja, A.; Grant, D. Predicting domain generation algorithms with long short-term memory networks. arXiv preprint 2016, arXiv:1611.00791. [Google Scholar]
- Mac, H.; Tran, D.; Tong, V.; Nguyen, L.G.; Tran, H.A. DGA Botnet Detection Using Supervised Learning Methods. In Proceedings of the Eighth Symposium on Information and Communication Technology (SoICT 2017), Nha Trang, Vietnam, 7–8 December 2017; pp. 211–218. [Google Scholar]
- Lison, P.; Mavroeidis, V. Automatic Detection of Malware-Generated Domains with Recurrent Neural Models. arXiv preprint 2017, arXiv:1709.07102. [Google Scholar]
- Yu, B.; Gray, D.L.; Pan, J.; De Cock, M.; Nascimento, A.C.A. Inline DGA detection with deep networks. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 683–692. [Google Scholar]
- Zeng, F.; Chang, S.; Wan, X. Classification for DGA-Based Malicious Domain Names with Deep Learning Architectures. Int. J. Intell. Inf. Syst. 2017, 6, 67–71. [Google Scholar] [CrossRef]
- Saxe, J.; Berlin, K. eXpose: A character-level convolutional neural network with embeddings for detecting malicious URLs, file paths and registry keys. arXiv preprint 2017, arXiv:1702.08568. [Google Scholar]
- Tran, D.; Mac, H.; Tong, V.; Tran, H.A.; Nguyen, L.G. A LSTM based framework for handling multiclass imbalance in DGA botnet detection. Neurocomputing 2018, 275, 2401–2413. [Google Scholar] [CrossRef]
- Yu, B.; Pan, J.; Hu, J.; Nascimento, A.; De Cock, M. Character level based detection of DGA domain names. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Zhao, W.; Ye, J.; Yang, M.; Lei, Z.; Zhang, S.; Zhao, Z. Investigating capsule networks with dynamic routing for text classification. arXiv preprint 2018, arXiv:1804.00538. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- LeCun, Y.; Boser, B.E.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.E.; Jackel, L.D. Handwritten digit recognition with a back-propagation network. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 26–29 November 1990; pp. 396–404. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using convolutional networks. In Proceedings of the 28th IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 648–656. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 3856–3866. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- CapsNet-Keras. Available online: https://github.com/XifengGuo/CapsNet-Keras (accessed on 24 April 2019).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv preprint 2014, arXiv:1412.6980. [Google Scholar]
- Does Alexa have a list of its top-ranked websites? Available online: https://support.alexa.com/hc/en-us/articles/200449834-Does-Alexa-have-a-list-of-its-top-ranked-websites (accessed on 25 May 2018).
- Bambenek Consulting—Master Feeds. Available online: http://osint.bambenekconsulting.com/feeds/ (accessed on 22 May 2018).
- Berman, D.S.; Buczak, A.L.; Chavis, J.S.; Corbett, C.L. A survey of Deep Learning Methods for Cyber Security. Information 2019, 10, 122. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Model | Batch Size | Model Parameters and Layers |
|---|---|---|
| 1D Shallow CNN | 256 | Embedding(128) Conv2D(filters=1000, kernel_size=2, padding=’same’, kernel_initializer =’glorot_normal’) Dropout(0.5) Flatten() Dense(100, kernel_initializer= ‘glorot_normal’) Dense(1, kernel_initializer=’glorot_normal’) |
| 1D CNN with MaxPooling | 32 | Embedding(50) Dropout(0.25) Conv1D(filters=250, kernel_size=4, padding=’same’) MaxPooling1D(pool_size=3) Conv1D(filters=300, kernel_size=3, padding=’same’) Flatten() BatchNormalization() Dense(300) Dropout(0.2) BatchNormalization() Dense(1) |
| Long Short-Term Memory (LSTM) | 256 | Embedding(128) LSTM(128) Dropout(0.5) Dense(1) |
| Bidirectional LSTM | 256 | Embedding(50) Bidirectional(LSTM(128, dropout=0.2, recurrent_dropout=0.2)) Dropout(0.5) Dense(1) |
| CNN+LSTM | 256 | Embedding(128) Conv1D(filters=250, kernel_size=4, padding=’same’) LSTM(128) Dropout(0.5) Dense(1) |
| Parallel CNNs | 256 | def conv1DLayer(filter, kernel_size):
[conv1DLayer(2,256), conv1DLayer(3,256), conv1DLayer(4,256), conv1DLayer(5,256)] Dense(1024, activation=’relu’) Dropout(0.5) Dense(1024, activation=’relu’) Dropout(0.5) Dense(1, activation=’sigmoid’) |
| Capsule Network (CapsNet) | 318 | Embedding(128) Conv1D(filters=256, kernel_size=8, padding=’valid’) SpatialDropout1D(0.2) Conv1D(filters=512, kernel_size=4, padding=’valid’) Dropout(0.7) Conv1D(filters=256, kernel_size=4, padding=’valid’) PrimaryCaps(dim_capsule=8, n_channels=32, kernel_size=4, strides=2, padding=’valid’) CapsuleLayer(num_capsule=1, dim_capsule=16, routing=7) Length(0.85, 0.15) |
| Predicted Class | |||
|---|---|---|---|
| Malicious | Benign | ||
| Actual Class (Ground Truth): | Malicious | True Positive (TP) | False Negative (FN) |
| Benign | False Positive (FP) | True Negative (TN) | |
| Model | Accuracy | Recall | Precision | FPR | F1-Score | Partial AUC |
|---|---|---|---|---|---|---|
| Shallow CNN | 0.9927 | 0.9901 | 0.9940 | 0.0051 | 0.9920 | 0.9556 |
| 1D CNN | 0.9936 | 0.9924 | 0.9937 | 0.0054 | 0.9931 | 0.9577 |
| LSTM (128 embedding) | 0.9932 | 0.9917 | 0.9935 | 0.0055 | 0.9926 | 0.9659 |
| Bidirectional LSTM (embedding) | 0.9919 | 0.9893 | 0.9930 | 0.0060 | 0.9912 | 0.9670 |
| Parallel CNNs | 0.9884 | 0.9836 | 0.9913 | 0.0074 | 0.9874 | 0.9341 |
| CNN+LSTM | 0.9942 | 0.9930 | 0.9945 | 0.0047 | 0.9937 | 0.9626 |
| CapsNet | 0.9938 | 0.9916 | 0.9950 | 0.0042 | 0.9933 | 0.9481 |
| Model | Accuracy | Recall | Precision | FPR | F1-Score | Partial AUC |
|---|---|---|---|---|---|---|
| Shallow CNN | 0.9613 | 0.8695 | 0.9875 | 0.0042 | 0.9247 | 0.8119 |
| 1D CNN | 0.9684 | 0.8964 | 0.9868 | 0.0045 | 0.9394 | 0.8226 |
| LSTM (128 embedding) | 0.9689 | 0.8949 | 0.9904 | 0.0033 | 0.9402 | 0.8214 |
| Bidirectional LSTM (embedding) | 0.9689 | 0.8990 | 0.9862 | 0.0047 | 0.9406 | 0.8298 |
| Parallel CNNs | 0.9585 | 0.8655 | 0.9806 | 0.0065 | 0.9194 | 0.7972 |
| CNN+LSTM | 0.9710 | 0.9013 | 0.9917 | 0.0028 | 0.9444 | 0.8535 |
| CapsNet | 0.9714 | 0.9044 | 0.9900 | 0.0034 | 0.9453 | 0.8403 |
| Type of Data | CNN+LSTM | 1D CNN | Shallow CNN | CapsNet | LSTM | Bidirectional LSTM | Parallel CNNs |
|---|---|---|---|---|---|---|---|
| Benign | 0.9953 | 0.9946 | 0.9949 | 0.9958 | 0.9949 | 0.9940 | 0.9926 |
| Cryptolocker | 0.9917 | 0.9917 | 0.9875 | 0.9900 | 0.9883 | 0.9933 | 0.9817 |
| P2P Gameover Zeus | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Post Tovar GOZ | 0.9999 | 1.0000 | 0.9999 | 1.0000 | 0.9998 | 0.9999 | 0.9999 |
| Volatile Cedar/Explosive | 0.9848 | 0.9747 | 0.9848 | 1.0000 | 0.9899 | 0.9848 | 0.9343 |
| bamital | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| banjori | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| bedep | 1.0000 | 0.9394 | 1.0000 | 1.0000 | 0.9697 | 0.9697 | 0.9394 |
| beebone | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| chinad | 0.9966 | 1.0000 | 0.9761 | 0.9966 | 1.0000 | 1.0000 | 0.9795 |
| corebot | 1.0000 | 1.0000 | 0.9851 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| cryptowall | 0.2727 | 0.2727 | 0.2273 | 0.2727 | 0.3182 | 0.2273 | 0.2273 |
| dircrypt | 0.9792 | 0.9792 | 0.9583 | 0.9722 | 0.9792 | 0.9792 | 0.9722 |
| dyre | 0.9994 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| fobber | 0.9779 | 0.9779 | 0.9853 | 0.9779 | 0.9779 | 0.9853 | 0.9632 |
| geodo | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| gozi | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| hesperbot | 0.9487 | 0.9487 | 0.9487 | 0.9231 | 0.8974 | 0.9231 | 0.8718 |
| kraken | 0.9854 | 0.9769 | 0.9679 | 0.9831 | 0.9730 | 0.9730 | 0.9651 |
| locky | 0.9815 | 0.9760 | 0.9766 | 0.9834 | 0.9699 | 0.9656 | 0.9477 |
| madmax | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| matsnu | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| murofet | 0.9988 | 0.9974 | 0.9976 | 0.9985 | 0.9974 | 0.9979 | 0.9954 |
| necurs | 0.9818 | 0.9810 | 0.9715 | 0.9736 | 0.9756 | 0.9729 | 0.9539 |
| nymaim | 0.8998 | 0.8875 | 0.8662 | 0.8818 | 0.8621 | 0.8612 | 0.8342 |
| padcrypt | 0.9658 | 0.9487 | 0.9402 | 0.9658 | 0.9316 | 0.9658 | 0.8632 |
| pandabanker | 0.8750 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.8750 | 0.5000 |
| pizd | 0.9464 | 0.9196 | 0.8214 | 0.9196 | 0.8482 | 0.4821 | 0.0804 |
| proslikefan | 0.8980 | 0.8912 | 0.8707 | 0.8912 | 0.8299 | 0.8299 | 0.7823 |
| pushdo | 0.9178 | 0.9348 | 0.9207 | 0.8980 | 0.9008 | 0.8924 | 0.8499 |
| pykspa | 0.9613 | 0.9592 | 0.9462 | 0.9547 | 0.9469 | 0.9431 | 0.9290 |
| qakbot | 0.9892 | 0.9884 | 0.9834 | 0.9863 | 0.9850 | 0.9868 | 0.9813 |
| ramdo | 0.9974 | 0.9922 | 0.9974 | 0.9897 | 0.9974 | 0.9948 | 0.9716 |
| ramnit | 0.9804 | 0.9736 | 0.9699 | 0.9728 | 0.9719 | 0.9726 | 0.9571 |
| ranbyus | 0.9981 | 0.9981 | 0.9983 | 0.9971 | 0.9985 | 0.9981 | 0.9967 |
| shifu | 0.9533 | 0.9618 | 0.9278 | 0.9469 | 0.9384 | 0.9554 | 0.9618 |
| shiotob/urlzone/bebloh | 0.9861 | 0.9921 | 0.9905 | 0.9885 | 0.9869 | 0.9881 | 0.9711 |
| simda | 0.9895 | 0.9959 | 0.9817 | 0.9804 | 0.9841 | 0.9878 | 0.9414 |
| sisron | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Sphinx | 0.9938 | 0.9938 | 0.9875 | 0.9938 | 0.9938 | 0.9875 | 0.9813 |
| Suppobox | 0.9188 | 0.9086 | 0.6142 | 0.8782 | 0.6193 | 0.1980 | 0.0609 |
| symmi | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.9896 |
| tempedreve | 0.8696 | 0.8478 | 0.8043 | 0.8478 | 0.8478 | 0.8478 | 0.8478 |
| tinba | 0.9936 | 0.9940 | 0.9948 | 0.9914 | 0.9916 | 0.9914 | 0.9877 |
| unknowndropper | 0.9167 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| unknownjs | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.9231 | 0.9487 | 0.8718 |
| vawtrak | 0.8517 | 0.8485 | 0.8006 | 0.9075 | 0.8517 | 0.7703 | 0.5550 |
| Vidro | 0.9767 | 0.9535 | 0.9535 | 0.9302 | 0.9070 | 0.9302 | 0.9535 |
| virut | 0.3248 | 0.3419 | 0.2393 | 0.3419 | 0.1624 | 0.1368 | 0.1709 |
| Micro Average | 0.9040 | 0.9049 | 0.8892 | 0.9047 | 0.8880 | 0.8676 | 0.8319 |
| Type of Data | CNN+LSTM | 1D CNN | Shallow CNN | CapsNet | LSTM | Bidirectional LSTM | Parallel CNNs |
|---|---|---|---|---|---|---|---|
| Benign | 0.9912 | 0.9878 | 0.9868 | 0.9878 | 0.9860 | 0.9903 | 0.9797 |
| Cryptolocker | 0.9995 | 0.9995 | 0.9975 | 1.0000 | 0.9990 | 1.0000 | 0.9990 |
| P2P Gameover Zeus | 0.9999 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.9998 |
| Post Tovar GOZ | 0.9950 | 0.9859 | 0.9950 | 0.9990 | 0.9940 | 0.9869 | 0.9789 |
| Volatile Cedar/Explosive | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Bamital | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Banjori | 0.9857 | 0.9857 | 0.9714 | 0.9943 | 0.9800 | 0.9886 | 0.9629 |
| Bedep | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Beebone | 0.9889 | 0.9941 | 0.9915 | 0.9967 | 0.9941 | 0.9954 | 0.9759 |
| Chinad | 1.0000 | 0.9964 | 1.0000 | 0.9964 | 0.9964 | 0.9964 | 0.9893 |
| corebot | 0.2447 | 0.2021 | 0.3085 | 0.2660 | 0.2234 | 0.1915 | 0.1809 |
| cryptowall | 0.9875 | 0.9806 | 0.9806 | 0.9889 | 0.9764 | 0.9722 | 0.9528 |
| Dircrypt | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.9999 |
| dyre | 0.9950 | 0.9833 | 0.9900 | 0.9917 | 0.9900 | 0.9833 | 0.9700 |
| Fobber | 0.9965 | 1.0000 | 1.0000 | 1.0000 | 0.9983 | 0.9965 | 0.9983 |
| geodo | 0.0833 | 0.0417 | 0.0417 | 0.0000 | 0.0833 | 0.0417 | 0.0417 |
| Gozi | 0.9479 | 0.9479 | 0.9479 | 0.9531 | 0.9271 | 0.9271 | 0.8750 |
| hesperbot | 0.9933 | 0.9851 | 0.9818 | 0.9923 | 0.9831 | 0.9817 | 0.9676 |
| Kraken | 0.9636 | 0.9644 | 0.9512 | 0.9619 | 0.9651 | 0.9621 | 0.9392 |
| locky | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Madmax | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| matsnu | 0.9983 | 0.9969 | 0.9959 | 0.9975 | 0.9974 | 0.9975 | 0.9954 |
| Murofet | 0.9818 | 0.9837 | 0.9774 | 0.9761 | 0.9754 | 0.9739 | 0.9499 |
| Necurs | 0.8930 | 0.8758 | 0.8590 | 0.8762 | 0.8615 | 0.8625 | 0.8097 |
| nymaim | 0.9670 | 0.9479 | 0.9427 | 0.9444 | 0.9514 | 0.9462 | 0.8490 |
| padcrypt | 0.9091 | 0.9697 | 0.9697 | 0.8788 | 1.0000 | 0.9394 | 0.8485 |
| pandabanker | 0.4686 | 0.5784 | 0.4451 | 0.4471 | 0.4490 | 0.1882 | 0.0745 |
| Pizd | 0.8808 | 0.8577 | 0.8269 | 0.8423 | 0.8513 | 0.8372 | 0.7449 |
| proslikefan | 0.9208 | 0.9256 | 0.9060 | 0.8815 | 0.8869 | 0.8869 | 0.8655 |
| pushdo | 0.9635 | 0.9577 | 0.9490 | 0.9610 | 0.9514 | 0.9430 | 0.9063 |
| Pykspa | 0.9893 | 0.9876 | 0.9831 | 0.9861 | 0.9855 | 0.9874 | 0.9767 |
| Qakbot | 0.9985 | 0.9965 | 0.9995 | 0.9970 | 0.9995 | 0.9955 | 0.9910 |
| Ramdo | 0.9861 | 0.9792 | 0.9815 | 0.9874 | 0.9769 | 0.9742 | 0.9521 |
| Ramnit | 0.9982 | 0.9979 | 0.9983 | 0.9977 | 0.9977 | 0.9980 | 0.9958 |
| ranbyus | 0.9717 | 0.9743 | 0.9648 | 0.9773 | 0.9605 | 0.9515 | 0.9369 |
| shifu | 0.9929 | 0.9944 | 0.9950 | 0.9955 | 0.9916 | 0.9867 | 0.9703 |
| shiotob/urlzone/bebloh | 0.9942 | 0.9973 | 0.9861 | 0.9919 | 0.9857 | 0.9836 | 0.9364 |
| Simda | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Sisron | 0.9869 | 0.9804 | 0.9869 | 0.9869 | 0.9896 | 0.9856 | 0.9817 |
| Sphinx | 0.0483 | 0.1016 | 0.0375 | 0.0582 | 0.0621 | 0.0325 | 0.0276 |
| Suppobox | 0.9375 | 0.9688 | 0.8750 | 0.9375 | 0.9375 | 0.9844 | 0.8594 |
| symmi | 0.9277 | 0.8795 | 0.8795 | 0.9317 | 0.8675 | 0.8554 | 0.8153 |
| tempedreve | 0.9964 | 0.9953 | 0.9974 | 0.9961 | 0.9940 | 0.9926 | 0.9880 |
| tinba | 0.9167 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| unknowndropper | 0.8944 | 0.8611 | 0.8444 | 0.8333 | 0.9056 | 0.8333 | 0.7556 |
| unknownjs | 0.8962 | 0.8730 | 0.8606 | 0.9508 | 0.8711 | 0.7511 | 0.5667 |
| Vawtrak | 0.9100 | 0.9200 | 0.9200 | 0.9100 | 0.9100 | 0.9000 | 0.8600 |
| Vidro | 0.3633 | 0.3083 | 0.2217 | 0.3100 | 0.1767 | 0.1433 | 0.1150 |
| virut | 0.8742 | 0.8742 | 0.8656 | 0.8704 | 0.8673 | 0.8530 | 0.8246 |
| Micro Average | 0.9912 | 0.9878 | 0.9868 | 0.9878 | 0.9860 | 0.9903 | 0.9797 |
| Type of Data | CNN+LSTM | 1D CNN | Shallow CNN | CapsNet | LSTM | Bidirectional LSTM | Parallel CNNs |
|---|---|---|---|---|---|---|---|
| Benign | 0.9972 | 0.9955 | 0.9958 | 0.9966 | 0.9958 | 0.9955 | 0.9935 |
| dircrypt | 0.9653 | 0.9458 | 0.9347 | 0.9569 | 0.9486 | 0.9597 | 0.9236 |
| hesperbot | 0.8698 | 0.8594 | 0.8333 | 0.8906 | 0.8594 | 0.8385 | 0.7500 |
| pandabanker | 0.5455 | 0.8485 | 0.7879 | 1.0000 | 0.5455 | 0.6667 | 0.5455 |
| proslikefan | 0.8141 | 0.8103 | 0.7590 | 0.7923 | 0.7987 | 0.8167 | 0.7269 |
| pykspa | 0.8127 | 0.8074 | 0.7695 | 0.8303 | 0.8167 | 0.8028 | 0.8015 |
| ramnit | 0.9548 | 0.9492 | 0.9276 | 0.9525 | 0.9508 | 0.9536 | 0.9135 |
| sisron | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| unknowndropper | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| vawtrak | 0.3756 | 0.3848 | 0.3152 | 0.4137 | 0.3994 | 0.3857 | 0.3448 |
| Micro Average | 0.7335 | 0.7601 | 0.7323 | 0.7833 | 0.7315 | 0.7419 | 0.7000 |
| Model | Evaluation Time |
|---|---|
| Shallow CNN | 1.95 |
| 1D CNN | 1.82 |
| LSTM (128 embedding) | 21.58 |
| Bidirectional LSTM (embedding) | 60.16 |
| Parallel CNNs | 4.06 |
| CNN+LSTM | 25.88 |
| CapsNet | 2.86 |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Berman, D.S. DGA CapsNet: 1D Application of Capsule Networks to DGA Detection. Information 2019, 10, 157. https://doi.org/10.3390/info10050157
Berman DS. DGA CapsNet: 1D Application of Capsule Networks to DGA Detection. Information. 2019; 10(5):157. https://doi.org/10.3390/info10050157
Chicago/Turabian StyleBerman, Daniel S. 2019. "DGA CapsNet: 1D Application of Capsule Networks to DGA Detection" Information 10, no. 5: 157. https://doi.org/10.3390/info10050157
APA StyleBerman, D. S. (2019). DGA CapsNet: 1D Application of Capsule Networks to DGA Detection. Information, 10(5), 157. https://doi.org/10.3390/info10050157