2. Related Work
The most critical component of a botnet is the so-called command-and-control infrastructure (C&C), consisting of the bots and a control entity that can be either centralized or decentralized. The C&C infrastructure typically serves as the only way to control bots within the botnet and is necessary for maintaining a stable connection within this infrastructure to operate efficiently. In general, botnets may be classified as centralized or decentralized [
8,
9,
10,
11].
The centralized command was employed by early botnets while control (C&C) has been applied for the distribution of commands and has been updated to individual bots, generally by HTTP or IRC protocols [
12]. Even though it is easy and simple to manage a centralized structure, it suffers from a single failure point and shoulders the susceptibility to the conventional defenses, for example blacklisting, DNS redirection, domain revocation, etc. Thus, P2P architecture has been started to be used by the botmasters for the C&C channels. For the P2P botnets, every bot is applied as both a client and a server, permitting botmasters for the publishing of the commands and the updating of the botnet’s any point [
13,
14].
Beigi et al. [
15] conducted a selection of the characteristics for the detection of the botnets through C4.5 machine learning algorithm and a greedy algorithm, which is called a stepwise algorithm. The datasets being applied actually have been collected from three various agencies: the Malware Capture Facility Project, ISCX, and ISOT. Various experiments have been performed by them, where the characteristics have been divided into 4 categories, based on their behavior, time, package, and bytes. The outcomes of the final set of characteristics demonstrated the detection rate larger 90% in a dataset with a limited number of botnets. According to another experiment containing some botnets for the phase training a greater diversity of the botnets’ test, there was 75% detection rate. According to the study of Huseynov et al. [
16], a comparison is made between the ant colony system algorithm K-means algorithm for detection decentralized botnets.
All the schemes above have been designed for the detection of either the particular botnet, which they have been trained for the centralized botnets.
Generally, the network’s P2P bots’ detection is difficult. There are some methods for the detection of botnets and bots, though there are some traditional techniques being comparatively effective botnets, even though many conventional skills have been comparatively less effective being botnets with centralized C&C mechanism is replaced by peer-to-peer (P2P) botnets, which pose difficulty for detection.
Su el al. [
17] offered a comprehensively great survey of DDoS and SDNA attacks being included SDN technology for management of network, even though the mechanism of P2P botnet identification was not applied as the concentration of the study. According to [
18], Gu et al. figured out the BotSniffer for the detection of the bots based on the spatio-temporal relationships between commands’ bot responses. Meanwhile, according to [
19], Narang et al. established PeerShark, through which the hosts were clustered via the network by protocol-oblivious and port-oblivious characteristics. To conclude, the disadvantage of the approach is that members of various botnets generally fall into the same cluster.
A lot of work has been conducted via machine learning for the identification of P2P botnets by researchers. According to paper [
20], a novel hybrid mechanism for the identification of P2P botnets has been implemented and proposed by the authors through the integration of the Bayesian Regularization and Bayesian. By Bayesian Regulation, it is helpful for the network traffic through the integration of Bayesian Regularization and Neural Networks. A better generalization of the dataset has been achieved with the assistance of Bayesian Regularization and thus empowering the botnet activity detection even of those bots, which have been never used for the Neural Network training. Therefore, a framework such as this is deemed suitable for the identification of the unseen and newer botnets in the network’s live traffic.
According to paper [
21], a two-tier detection scheme has been presented for the identification of the P2P botnets. The botnets have been detected through our method during the waiting phase. The search requests have been sent out to those neighboring peers very often in the network. The fact that the nodes have been connected indirectly has not been considered. According to research [
22], the effectiveness of the algorithms of community detection for the detection of P2P botnets have been analyzed, particularly through partial information. They demonstrate that only around half of the nodes can use this approach, with only a slight increase of the detection errors. According to the research [
23], various clustering algorithms have been experimented and tested while their accuracy has been recorded through the prepared datasets. Experiments have been implemented over multiple unsupervised machine learning approaches and it has been noticed that it has not proposed the best detection effect yet.
The Mahalanobis distance method mentioned in literature [
24] is a direct application of features between points and is only used as an introduction for anomaly detection. References [
24,
25] all use Mahalanobis distance to measure the correlation between features and filter the data, but there is no specific application analysis on the characteristics of P2P botnet, which has reference significance for the detection of botnet. In reference [
26], Mahalanobis distance is used for anomaly detection, which uses the distance from the point to the center to estimate whether the point belongs to the center cluster. This method can be used in the detection of botnet anomalies, but they are different from the detection background in this paper and the problems solved are different.
Few techniques have been proposed that are able to detect local P2P bots, assuming that P2P bots exhibit similar malicious activities and similar connection patterns, and there is no application of Mahalanobis distance to detect P2P botnet using the P2P botnet communication characteristics. Returning to our problem, assuming that botnet reduces direct contact, how to use the bot node finding other nodes with the same attribute, our work is innovative and necessary.
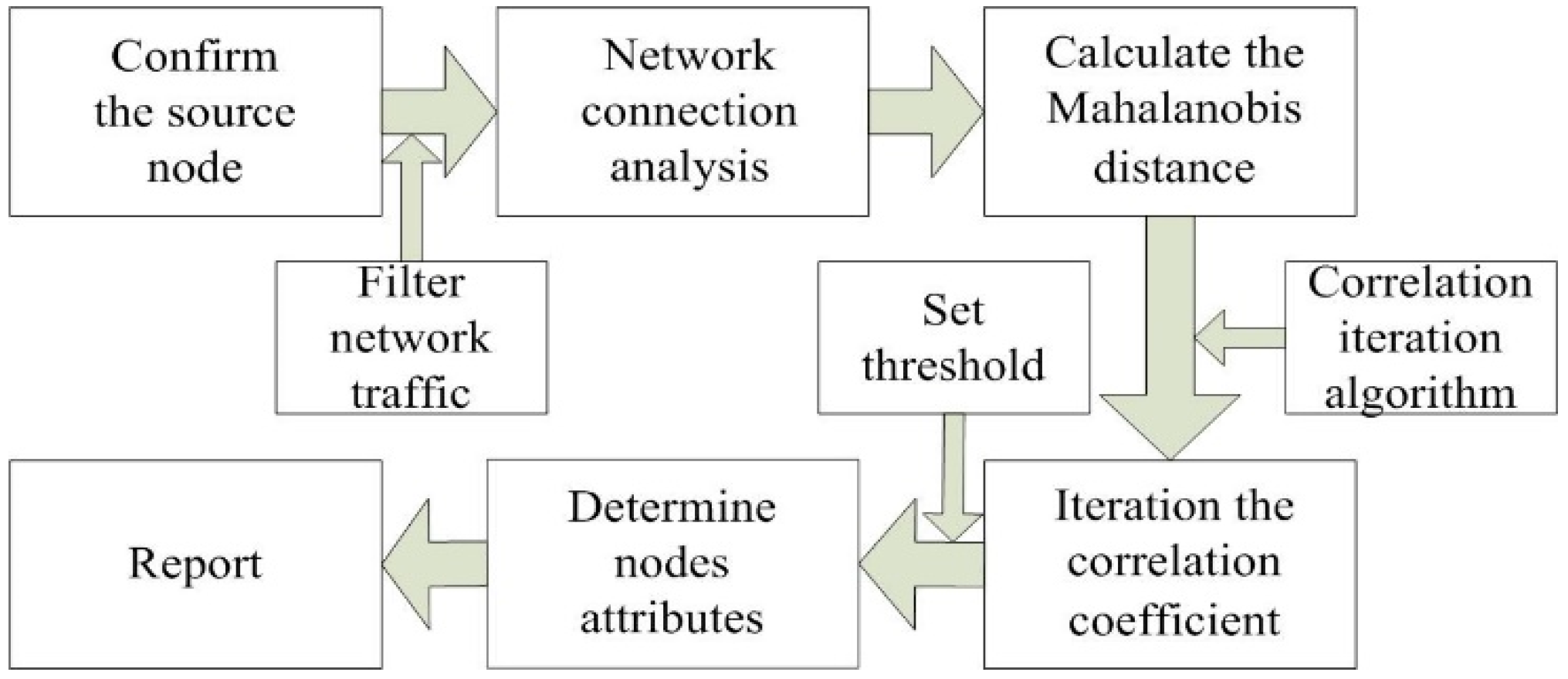
3. Theoretical Analysis
In this paper, aiming at the characteristics of P2P botnet connection, Mahalanobis distance is used to distance the connection between nodes, and an iterative algorithm is introduced to analyze the dynamic propagation of infected nodes, to expand the range of indirect connection between nodes. By determining the attributes of one node, the attributes of other nodes can be determined.
Paper [
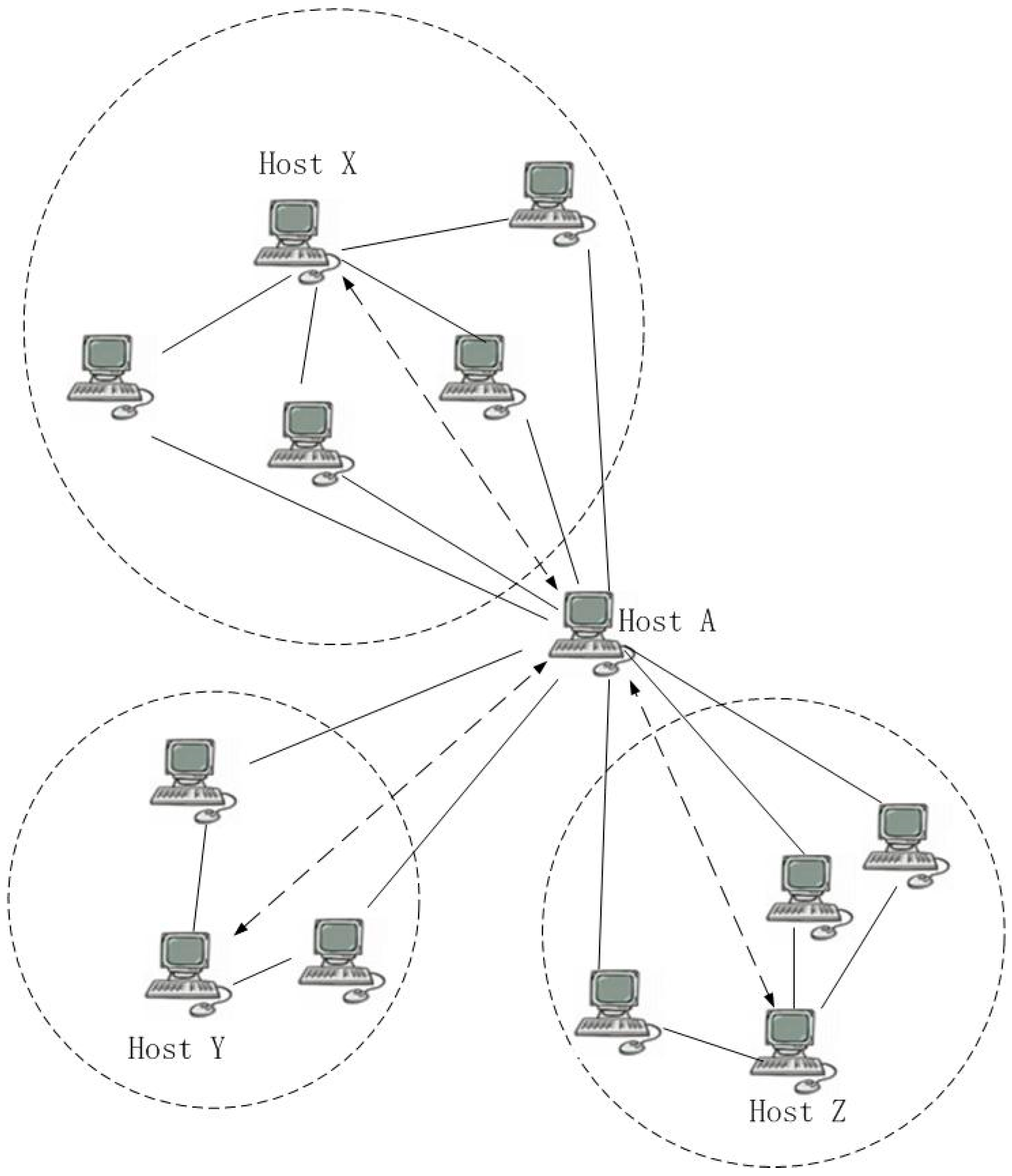
7] determined the correlation coefficient between nodes through the connected number to find the infected nodes (we called that ‘connected nodes method’)—the greater the number of commonly connected nodes, the more similar two nodes are. As shown in
Figure 1, when Host A and Host B are not directly connected, but are indirectly connected through the commonly connected Host X, Host A is assumed to be a bot, and Host B may also be a bot. Other hosts are connected to Host X might also be bots. Therefore, the connection model can be assumed using the commonly connected nodes between hosts. When a host is bot, the possibility that the other host is also a bot is greater.
The most obvious feature of P2P botnets is that each node in the network is a peer and can receive the same instructions and information. When a node receives instructions, this information is connected to other nodes and cannot easily be perceived. Therefore, there are commonly connected nodes which can convey information between nodes.
The number of commonly connected nodes excludes the non-structural connection nodes of nodes and the public connected nodes related to the software. If a source node is infected, the commonly connected nodes are used to determine the correlation to find other inflected nodes. The correlations between the nodes in a bot are complex. If we analyze the connections of all the related nodes, there are many errors between nodes of the same type. The correlation coefficient can be used to identify the correlation that is most relevant to the commonly connected nodes based on the object being detecting to find the next node by connection iteration after the model is realized and to determine whether the connected nodes are infected.
When a P2P botnet deliberately reduces the commonly connected nodes in a botnet, the correlation between the hosts can be used to indicate whether the hosts have the same attributes. Thus, we needed to identify a value to express the correlations between indirectly connected nodes.
The Mahalanobis distance calculates the distance between the two variables by obtaining their degree of correlation. The data object considers the measurement by calculating the dependence on scale [
27]. It is not affected by dimension, and the Mahalanobis distance between two nodes is not related to the measurement unit of the original data. The Mahalanobis distance between two nodes calculated using standardized and centralized data (i.e., the difference between the original data and the mean value) is the same.
To compute the Mahalanobis distance (MD), the variance–covariance matrix
Cx is first constructed:
where
X is the data matrix containing
n objects in the rows measured for
p variables; and
Xc is the column-centered data matrix
. In the case of two variables,
x1 and
x2, the variance–covariance matrix is
where
and
are the variances of the values of, respectively, the first and second variables, and
is the covariance between the two variables.
The MD for each object
xi is then
with
where
is the determinant of the variance–covariance matrix.
For an object
xi measured in two variables,
x1 and
x2,
can be rewritten, since
and
so that
Through this experiment, second variable’s section has already been demonstrated through the first subtracted variable. That is to say the MD corrects for the correlations within the data.
Each cluster in the MD is a multi-dimensional Gaussian distribution with a central position and a covariance matrix describing the local data distribution. It can present the distance between the data in the following form:
This paper attempts to represent the correlation between hosts using the MD. When Host A is a bot, and the distance to Host B is used to calculate the correlation coefficient, Host B is considered to be an infected host if the correlation coefficient after the iteration is greater than the set threshold. Based on the advantages of the MD for classification, P2P botnet detection can be achieved when there are fewer commonly connected nodes.
5. Experiment and Analysis of the Results
Unstructured botnet is more suitable for this detection structure, because unstructured botnet needs botmaster to convey information and is easier to detect. A structured P2P topology can be used by botmaster for the decrease of the chance of the possible mutual contacts through peer-connection with the same network for the communication with various sets of peers. To realize this, it requires the peers in the same mechanism to coordinate with each other and hence they will not have communication with the peer list of each other. From a specific perspective, peers with the same network are required to have their own tiny botnet and they show up as a single node for the rest of the P2P botnet. Even though a mutual-contact-fee P2P is deployed by botmaster, at least two networks have the choices of sharing the flow records and hence to get the mutual contacts among the P2P bots exploited in various networks, which cannot be avoided given that it would be impossible for the botmaster to acknowledge which network has the collaboration at the beginning. In this paper, structured botnet is used to evaluate the reliability of detection because there are few common connection nodes of P2P botnet.
5.2. Model Parameter Setting
Common connection nodes are few, and the number of infected nodes in a network range is also small. When the number of infected nodes obtained by threshold judgment is large, the threshold value needs to be adjusted.
The iteration number setting
The correlation coefficient between the corresponding nodes was calculated using the size of the first packet of the commonly connected nodes as a characteristic sample of different correlations.
However, according to the actual data, most hosts do not share, or rarely share, connected nodes with other nodes. To reduce the computation time, it is not necessary to calculate the MD of all hosts with the indirect connected nodes. Therefore, the number of iterations associated with iterative algorithm should not be greater than five. According to the Erdös–Renyi model [
30], a P2P botnet can never find infected nodes beyond three hops, so the iteration number was set as five.
The commonly connected nodes number setting
Considering that the botnet will deliberately reduce the number of commonly connected nodes, the smallest number of commonly connected nodes was set to k = 2 in the experiment.
The threshold setting
After obtaining the result of sequential analysis, reasonable threshold is in demand to distinguish botnet nodes. Assuming initial threshold is
, its value is set as:
where
is the normalization based on
e(
x,
t).
Assuming the time cycle is
Tth, the detailed coordinated strategy is:
where
is the amount of sample data within
,
is the factor to control the percentage of attack behaviors.
The THR represents the threshold of the correlation coefficient. To do a comparative experiment, according to the calculation results of the coefficient, the numerical magnitude was , and the correlation coefficient results are normalized, the order of magnitude of different methods remains unchanged. So, we set the three specified thresholds were , and for the comparative experiment.
After the correlation coefficient threshold of node data had been obtained, a known bot was selected to be the source node, and the iteration number was set as five. Moreover, new infected nodes in the data set were detected through the correlation iteration algorithm.
5.3. Comparison of the Results
The average accuracy rate and recall ratio were calculated to measure the performance of the proposed algorithm. After model detection, the accuracy rate was defined as the ratio of the number of the actually detected storm-detected nodes to the number of storm-detected nodes in the data set. The recall ratio was defined as the ratio of the number of detected storm-detected nodes to the number of the detected nodes in the data set list.
In accordance with the numerical interval of the correlation coefficient threshold, to compare the results, we set the experimental threshold to be the same as the previous method, which were set as
,
and
. The numbers of commonly connected hosts were 2, 4, and 6. The detection results are shown in
Table 1.
The accuracy rates and recall ratios of the test data were compared under different settings, and the results are shown below.
As shown in
Figure 5 and
Figure 6, as the threshold increased, the detection accuracy rate increased, while as the threshold decreased, the recall ratio decreased. It was demonstrated that the presence of a k value caused the recall ratio to decrease with an increasing number of commonly connected nodes, while the accuracy rate was less affected by the k value. Moreover, in cases with only two commonly connected nodes, the accuracy rate and the recall ratio were maintained at 89.3% and 85.4%, respectively, when the threshold was
.
We write in the Related Work section that many methods work in the P2P botnet detection. However, the articles use different data sets, and the premise of our method is that an infected node is known, which is different from the detection environment of other articles, so the results of this paper are compared with paper [
7] under the same detection background. When the THR was the same, the detection results of the previously connected nodes method in paper [
7] were as shown in
Table 2, and we made the accuracy comparison with the MD detection method.
As shown in
Figure 7, when k = 4, the accuracy rate of the MD detection method was shown to be higher than that of the connected nodes method. According to the comparison results with different k values, when k = 2, the detection accuracy rate decreased obviously as the THR value reduced.
Each point on the ROC curve corresponds to a threshold, and for different threshold settings there will be a true positive rate (TPR) and false positive rate (FPR). For example, when the threshold value of the classifier is at its maximum, TP = FP = 0, corresponding to the origin. The minimum threshold value, TN = FN = 0, corresponds to point (1,1) in the upper right corner. As the threshold value of classifier increased, the TP and FP decreased, the TPR and FPR decreased, and the ROC point moved down to the left.
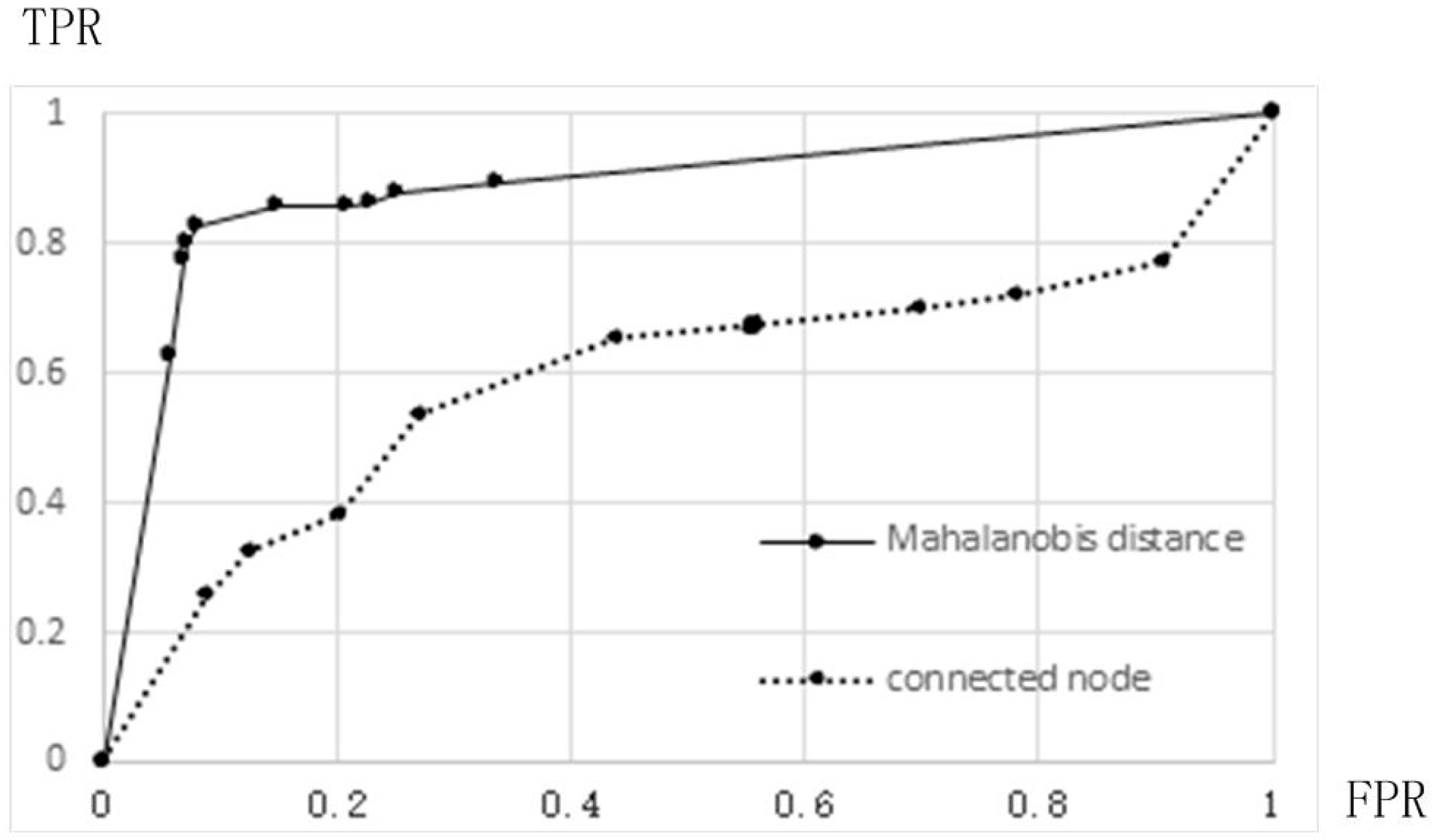
To determine the accuracy of the ROC curve, the selected threshold increased in the experiment, and the TPR and FPR were plotted (
Figure 8). The area under the curve (AUC) was determined using the coordinates. In general, the AUC was greater than 0.5, and the closer the AUC was to 1, the better the detection effect was. It can be seen from the figure that the MD detection method had higher accuracy than the previous method. In the figure, under the setting k = 2, when the FPR was 5%, the TPR was higher than 75%, and after that, it was close to the final accuracy level of the method. As can be seen from
Figure 9, when the connected number method was used, a TPR of 75% was associated with an FPR as high as 65%. In addition, as the threshold changed throughout the test, the TPR gradually increased, indicating that the method was unstable. The stable performance of the MD method under multiple detection settings created a larger AUC area and a better detection effect.
The experimental results showed that the application of the MD detection method can improve the accuracy rate and recall ratio of the detection. Moreover, when there are fewer commonly connected nodes, both the accuracy rate and the recall ratio will be greater than 85%, which addresses the limitations of the connected nodes method. Above all, we can conclude that the expression of correlations between the data by the MD is useful for the description of P2P botnet node relationships. Different correlation coefficient thresholds and k values have their advantages in terms of the accuracy rate and recall ratio. In practical applications, their values should be determined according to the specific arrangement demands of a network.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}