Link Prediction Based on Deep Convolutional Neural Network


Abstract
:1. Introduction
- To solve the link prediction problem, we transform it into a binary classification problem and construct a deep convolution neural network model to solve the problem.
- In view of the fact that heuristic methods can only utilize the network’s topological structure and represent learning methods can only utilize the potential features of the network, such as DeepWalk, LINE, node2vec, we propose a sub-graph extraction algorithm, which can better contain the information needed by the link prediction algorithm. On this basis, a residual attention model is proposed, which can effectively learn from graph structure features to link structure features.
- Through further research, we find that the residual attention mechanism may impede the information flow in the whole network. Therefore, a dense convolutional neural network model is proposed to improve the effect of link prediction.
2. Related Work
3. Preliminaries
3.1. Network Representation Learning
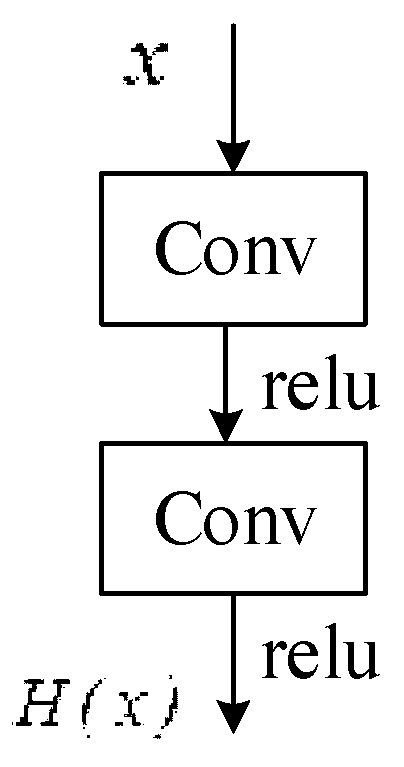
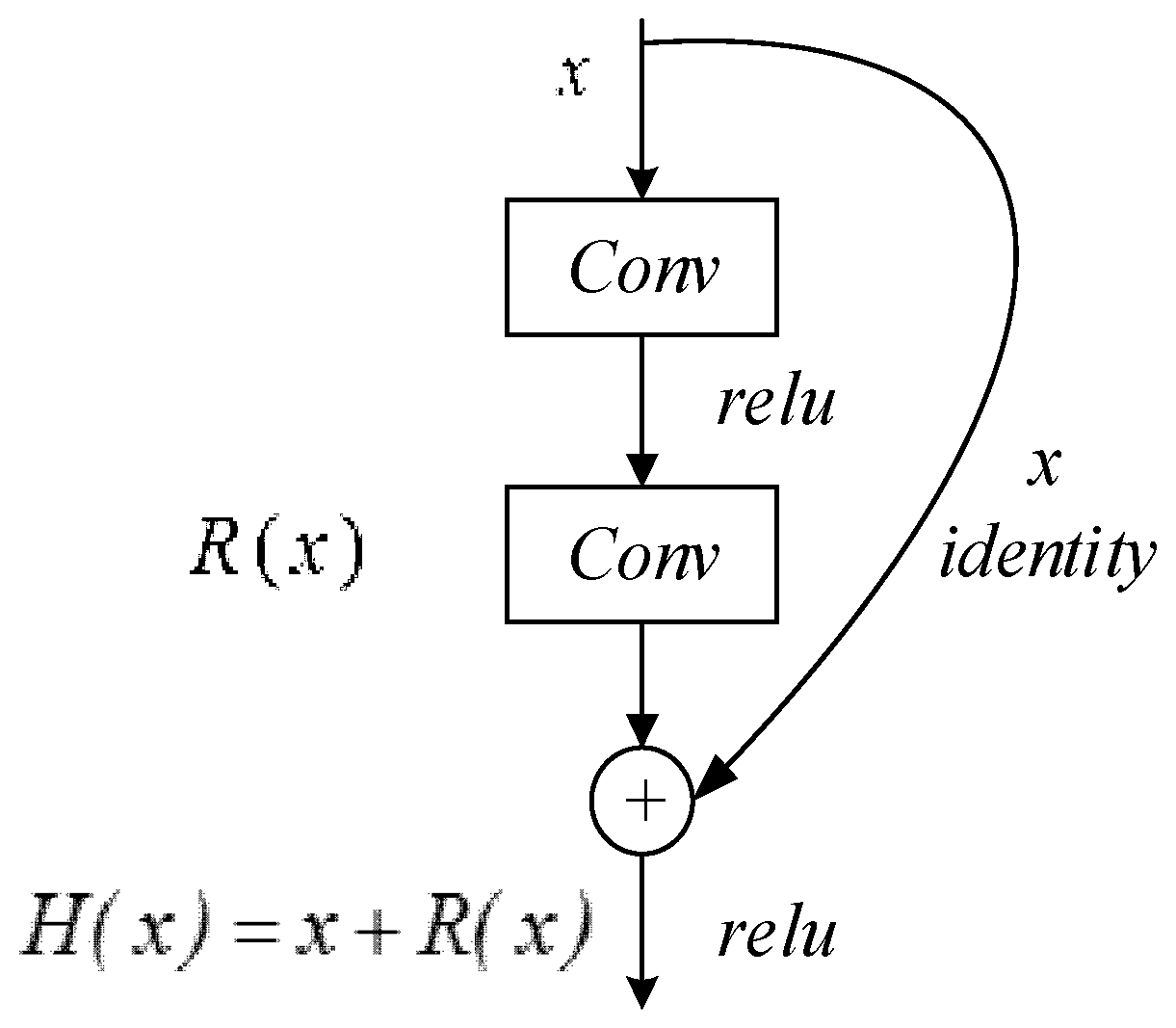
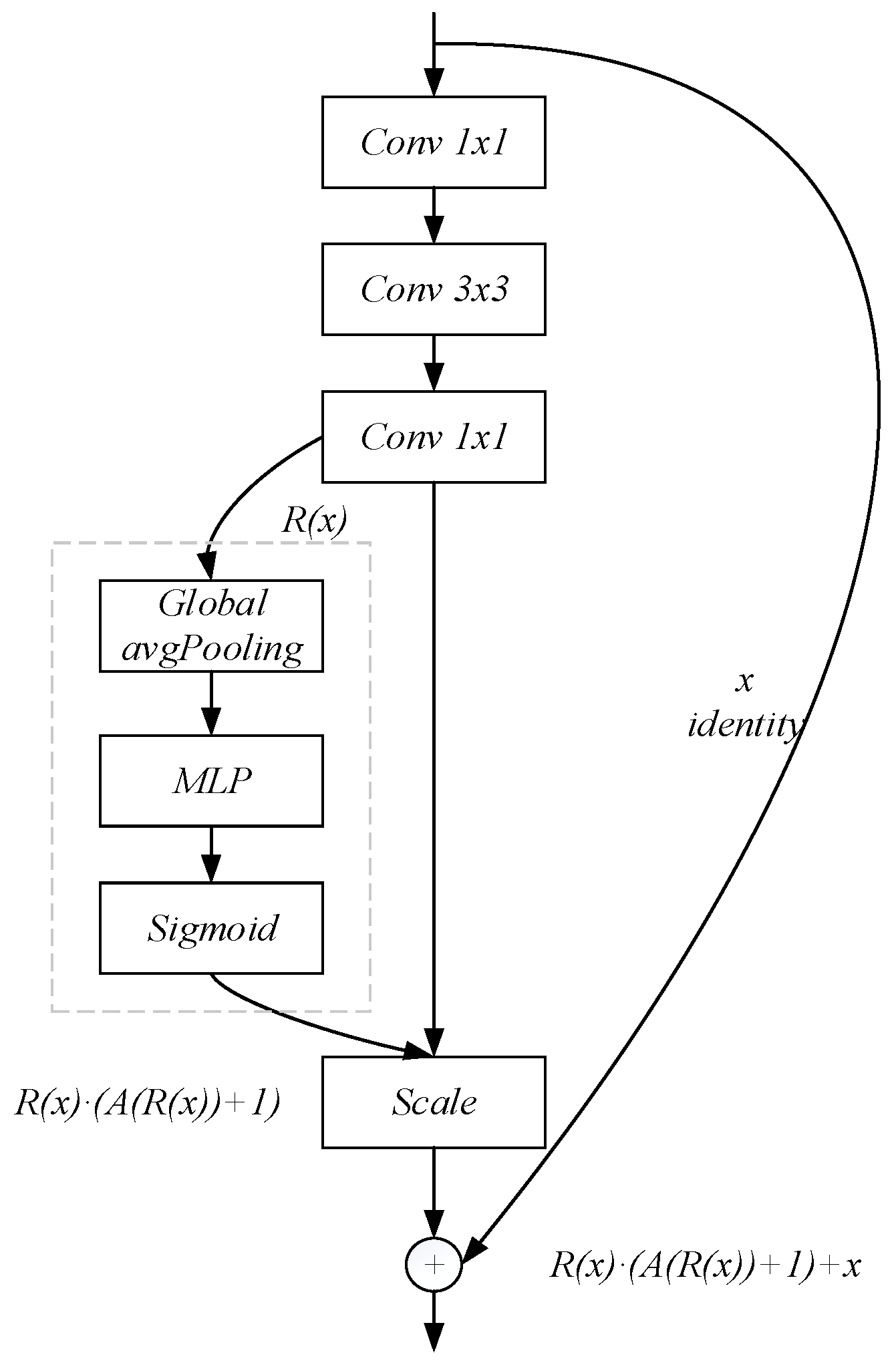
3.2. Residual Attention Mechanism
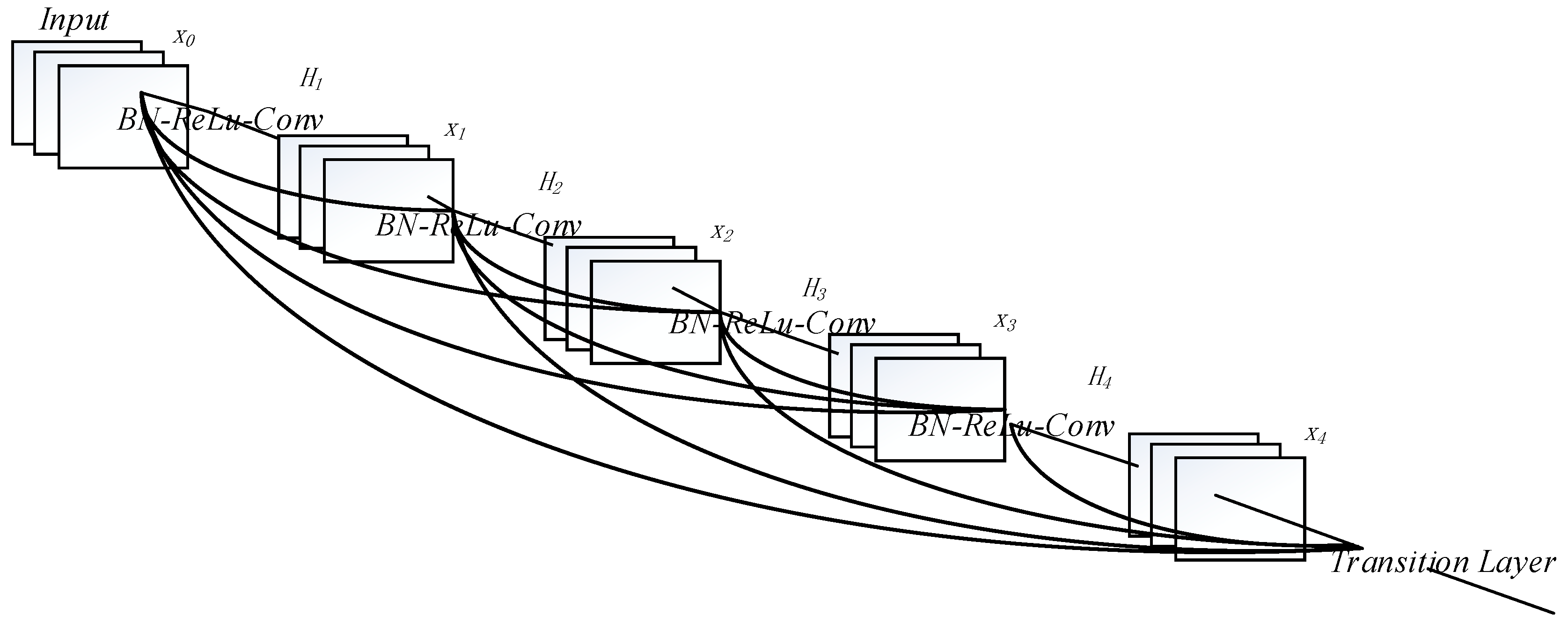
3.3. Densely Connected Convolutional Neural Network
4. Methodology
4.1. Problem Formulation
4.2. Method Overview
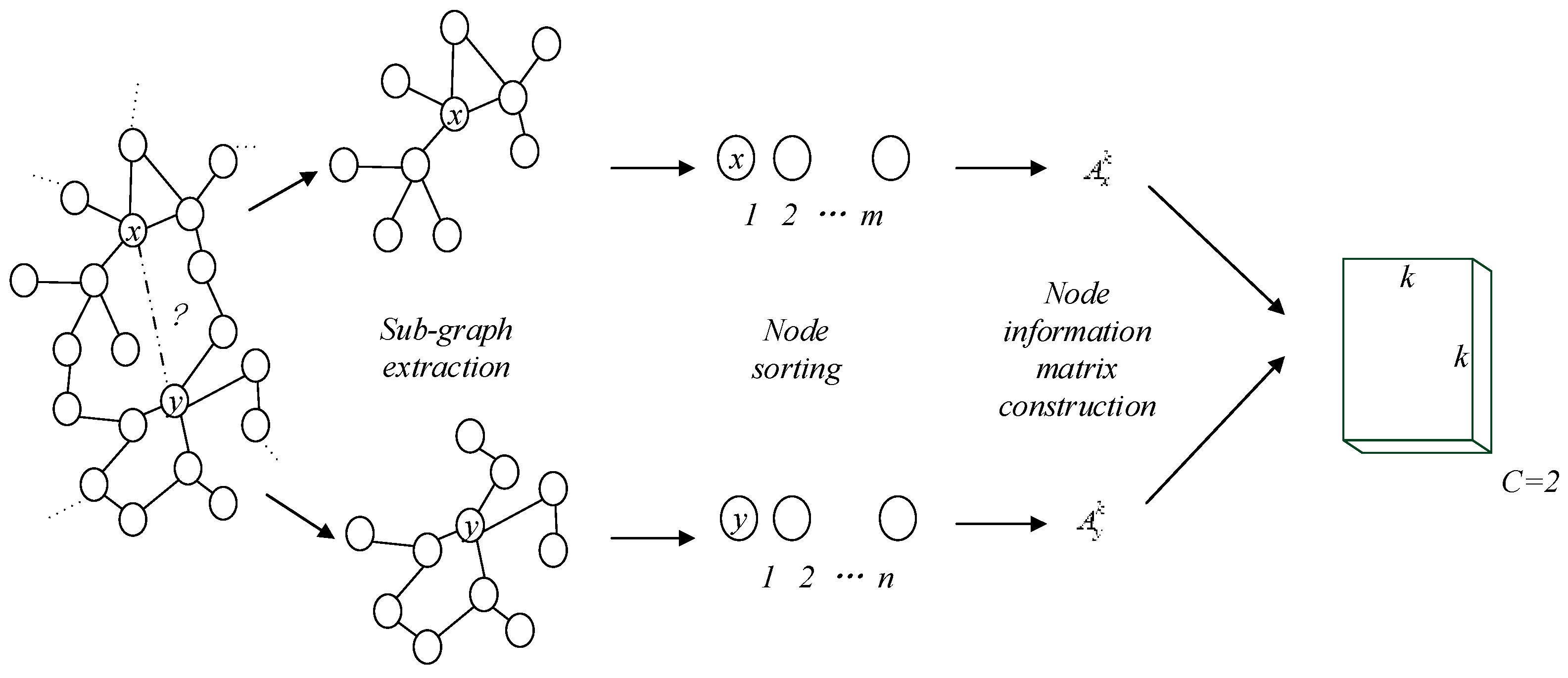
4.3. Sub-Graph Extraction
| Algorithm 1 Sub-graph extraction algorithm |
| input: Objective node x, network G, integer h |
| output:x corresponding sub-graph |
| 1. |
| 2. |
| 3. for in range(h) |
| 4. if || == 0 then break |
| 5. |
| 6. |
| 7. end for |
| 8. return |
4.4. Node Sorting
| Algorithm 2 Node sorting algorithm |
| input:nbb[n], node_vec[N][M] |
| output:x |
| 1. node_vec_dist[][]; |
| 2. for to n do node_vec_dist[nbb[0]][nbb[i]]=cos(node_vec[nbb[0]],node_vec[nbb[i]]); |
| 3. end for |
| 4. seq = Sorted(node_vec_dist, Reverse = True) |
| 5. return seq |
4.5. Node Information Matrix Construction
- (1)
- For a given graph , corresponding h-hop sub-graph for each node shall be generated according to Algorithm 1 Sub-graph extraction algorithm;
- (2)
- The nodes in each sub-graph shall be sorted, and the order between sub-graphs does not affect each other;
- (3)
- If the number of nodes in the sub-graph is greater than or equal to , the first nodes are selected from the ordered sequence nodes, and the k-ordered sequence nodes is mapped to the adjacency matrix , ; If the number of nodes is less than , the element 0 shall be filled as complementary element;
- (4)
- and are integrated into data with the size of . If the node pair (x, y) has a link in the original network, it is labeled as 1; otherwise, it is labeled 0.
4.6. Residual Attention Mechanism
4.7. Densely Connected Convolutional Network Model
5. Experimental Results
5.1. Data Sets
- (1)
- USAir line (USAir): The air transportation network of USA that consists of 332 nodes and 2126 links. The nodes of the network are airports. If there is a direct route between two airports, then there is a link between the two airports.
- (2)
- Politicablogs (PB): The network of American political blog website that consists of 1222 nodes and 19,021 links. The nodes of the network are log pages, and each link represents the hyperlinks between the blog pages.
- (3)
- Metabolic: A metabolic network of nematode that consists of 453 nodes and 2025 links. The node of the network is metabolite and each link represents a biochemical reaction.
- (4)
- King James: A vocabulary co-occurrence network that consists of 1773 nodes and 9391 links. The nodes of the network represent nouns and the links indicate that two nouns appear in the same sentence.
5.2. Experiment Setup
5.2.1. Parameter Settings
- (1)
- To quantify the performance of the link prediction, the presented links from each data set were partitioned into a training set (90%) and test set (10%) randomly and independently. At the same time, the network connectivity of the training set and the test set was guaranteed.
- (2)
- To compare the results with other learning methods, the same parameter settings were adopted. Please refer to [20] for details. In addition, the node representation vectors generated by the two models were computed according to Equation (8), and the link eigenvectors were computed by the Hadamard [20] operation mentioned. The calculation formula is as follows:where denotes the representation vector of the node ; denotes the value of the -dimension of the representation. Binary regression classifier is used to predict unknown links.
- (3)
- Sub-graph extraction algorithm: it is usually set as . Since achieved good results in the experiment, we set .
- (4)
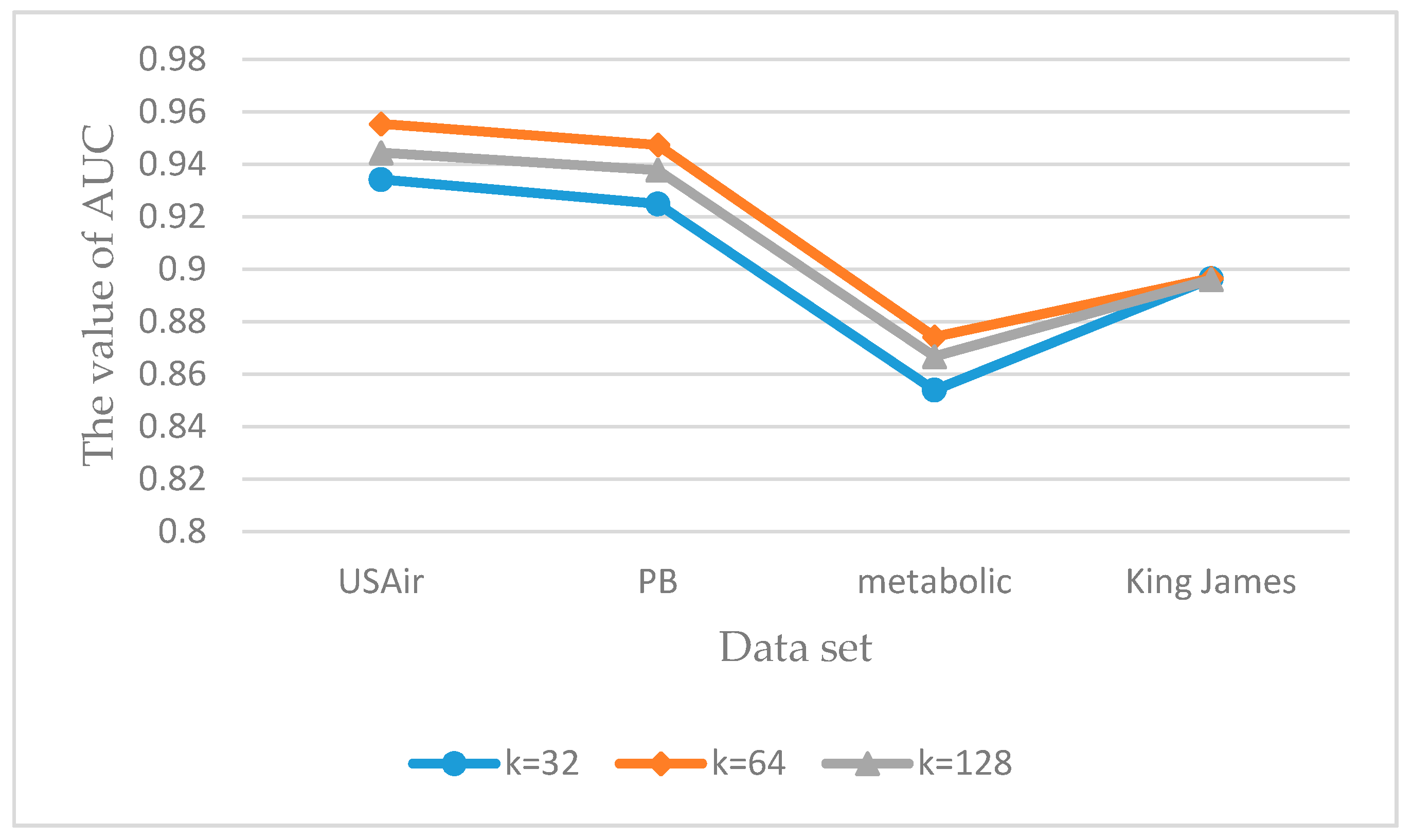
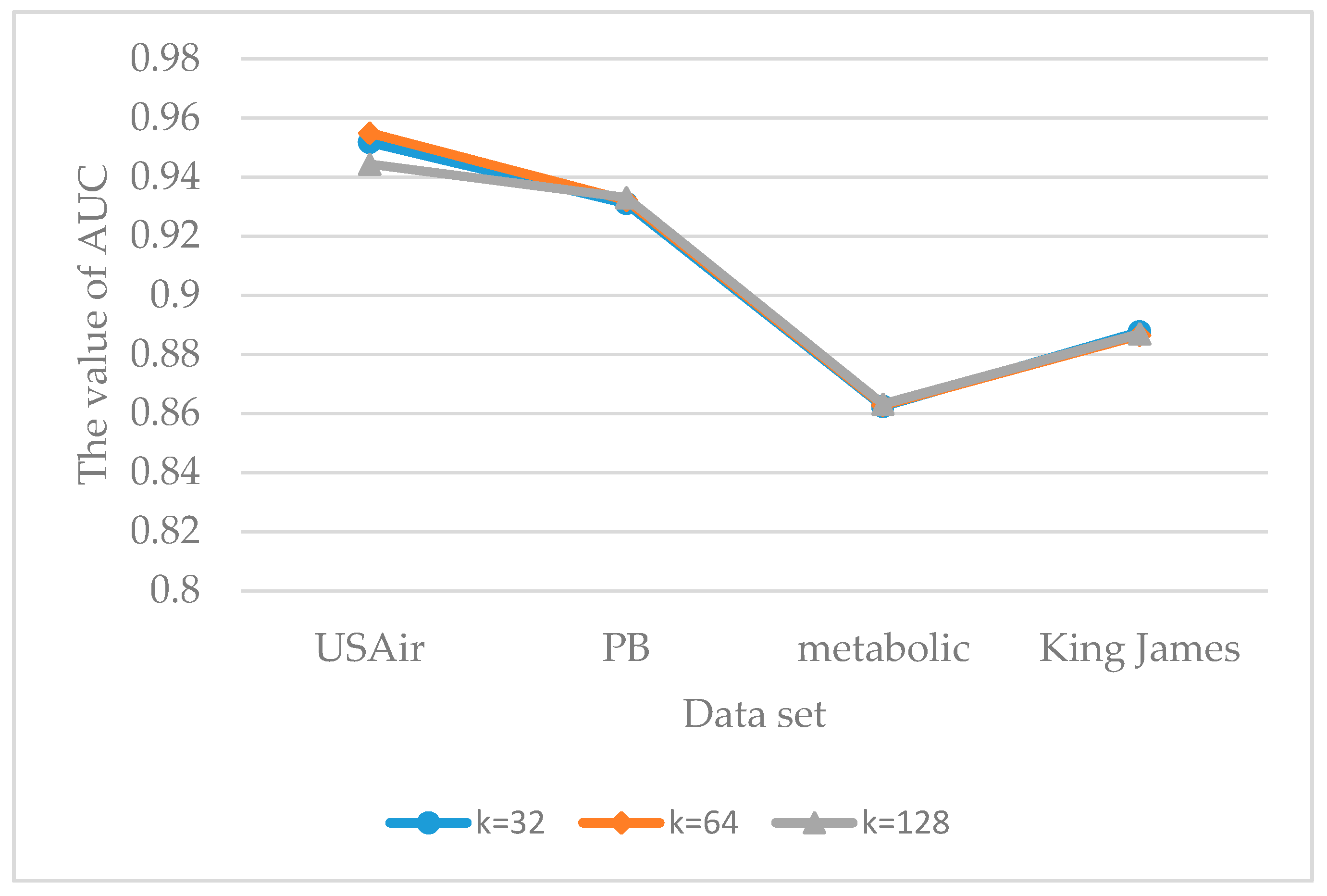
- Node information matrix construction: the experiment sets . Through the experiment contrast, when , the prediction accuracy of AUC is relatively good, so we chose the size of , as shown in Figure 6.
5.2.2. Baseline Algorithms
5.3. Experiment Results and Analysis
5.3.1. Comparison with CN-Based Methods
5.3.2. Comparison with Representation Learning Methods
5.3.3. Parameter Sensitivity
6. Conclusions
- (1)
- We considered the pure structure of the network for link prediction in this paper, although it can achieve better prediction results on most networks, but this is obviously not enough. Therefore, in the future, other information will be added to the network for modeling, in order to achieve better prediction results.
- (2)
- Modeling with deep convolution neural network can improve the effect of link prediction, but it is well known that the computational complexity will also increase. Therefore, the use of the in-depth learning model for large-scale network data is bound to be constrained by efficiency, so how to improve the efficiency of the model is also a challenge at present.
- (3)
- Network adaptability. In this paper, we adopted some common data sets, which cannot be tested on large-scale networks, so we will consider this research step by step.
Author Contributions
Funding
Conflicts of Interest
References
- Liben-Nowell, D.; Kleinberg, J. The link-prediction problem for social networks. JASIST 2007, 58, 1019–1031. [Google Scholar] [CrossRef] [Green Version]
- Aiello, L.M.; Barrat, A.; Schifanella, R.; Cattuto, C.; Markines, B.; Menczer, F. Friendship prediction and homophily in social media. ACM Trans. Web 2012, 6, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Tang, J.; Wu, S.; Sun, J.M.; Su, H. Cross-Domain Collaboration Recommendation. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 1285–1293. [Google Scholar]
- Akcora, C.G.; Carminati, B.; Ferrari, E. Network and Profile Based Measures for User Similarities on Social Networks. In Proceedings of the 2011 IEEE International Conference on Information Reuse& Integration, Las Vegas, NV, USA, 2–5 August 2011; pp. 292–298. [Google Scholar]
- Turki, T.; Wei, Z. A link prediction approach to cancer drug sensitivity prediction. J. BMC Syst. Biol. 2017, 11, 13–26. [Google Scholar] [CrossRef] [PubMed]
- Nickel, M.; Murphy, K.; Tresp, V.; Gabrilovich, E. A Review of Relational Machine Learning for Knowledge Graphs; IEEE: New York, NY, USA, 2016; pp. 11–33. [Google Scholar]
- Ahn, M.W.; Jung, W.S. Accuracy test for link prediction in terms of similarity index: The case of WS and BA models. J. Phys. A 2015, 429, 3992–3997. [Google Scholar] [CrossRef]
- Hoffman, M.; Steinley, D.; Brusco, M.J. A note on using the adjusted Rand index for link prediction in networks. J. Soc. Netw. 2015, 42, 72–79. [Google Scholar] [CrossRef] [PubMed]
- Lv, L.; Zhou, T. Link prediction in complex networks: A survey. J. Phys. A 2011, 390, 1150–1170. [Google Scholar] [Green Version]
- Newman, M.E.J. Clustering and preferential attachment in growing networks. J. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 2001, 64, 025102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, H.-H.; Liang, G.; Zhang, X.L.; Giles, C.L. Discovering Missing Links in Networks Using Vertex Similarity Measures. In Proceedings of the 27th Annual ACM Symposium on Applied Computing, Trento, Italy, 26–30 March 2012; pp. 138–143. [Google Scholar]
- Lichtenwalter, R.N.; Chawla, N.V. Vertex Collocation Profiles: Subgraph Counting for Link Analysis and Prediction. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 1019–1028. [Google Scholar]
- Li, R.-H.; Jeffrey, X.Y.; Liu, J. Link Prediction: The Power of Maximal Entropy Random Walk. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Glasgow, UK, 24–28 October 2011; pp. 1147–1156. [Google Scholar]
- Shang, Y. Distinct Clusterings and Characteristic Path Lengths in Dynamic Small-World Networks with Indentical Limit Degree Distribution. J. Stat. Phys. 2012, 149, 505–518. [Google Scholar] [CrossRef]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deep Walk: Online Learning of Social Representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Grover, A.; Leskovec, J. Node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.Z.; Zhang, M.; Yan, J.; Mei, Q.Z. Line: Large-Scale Information Network Embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Wang, D.X.; Cui, P.; Zhu, W.W. Structural Deep Network Embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1225–1234. [Google Scholar]
- Zhang, M.; Chen, Y. Link prediction Based on Graph Neural Networks. In Proceedings of the Thirty-Second Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 2–8 December 2018. [Google Scholar]
- Hou, J.H.; Deng, Y.; Cheng, S.M.; Xiang, J. Visual Object Tracking Based on Deep Features and Correlation Filter. J. South Cent. Univ. Nat. 2018, 37, 67–73. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual Attention Network for Image Classification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6450–6458. [Google Scholar]
- Tu, C.; Yang, C.; Liu, Z.; Sun, M. Network representation learning: An overview. J. Sci. Sin. 2017, 47, 980–996. [Google Scholar] [CrossRef]
- Qi, J.S.; Liang, X.; Li, Z.Y.; Chen, Y.F.; Xu, Y. Representation learning of large-scale complex information network: Concepts, methods and challenges. Chin. J. Comput. 2018, 41, 2394–2420. [Google Scholar]
- Shang, Y. Subgraph Robustness of Complex Networks under Attacks. J. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 821–833. [Google Scholar] [CrossRef]
- Lada, A.A.; Eytan, A. Friends and neighbors on the web. J. Soc. Netw. 2003, 25, 211–230. [Google Scholar]
- Barabási, A.L.; Albert, A. Emergence of scaling in random networks. J. Sci. 1999, 286, 509–512. [Google Scholar]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution on χ–Transformed Points. Available online: https://arxiv.org/abs/1801.07791 (accessed on 10 October 2018).
- Li, Y.; Shang, Y.; Yang, Y. Clustering coefficients of large networks. J. Inf. Sci. 2017, 382–383, 350–358. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Meanings |
|---|---|
| n | Number of nodes in sub-graph |
| N | Number of nodes in network G |
| M | Represents the dimension of feature |
| Nbb[] | x corresponding ordered node sequence seq[n] |
| node_vec[][] | All nodes in the network represent vector |
| node_vec_dist[][] | A temporary variable that holds the cosine distance |
| Dataset | |V| | |E| | <k> | <CC> | r |
|---|---|---|---|---|---|
| USAir | 332 | 2126 | 12.810 | 0.749 | −0.208 |
| PB | 1222 | 16,714 | 27.360 | 0.360 | −0.221 |
| Metabolic | 453 | 2025 | 8.940 | 0.647 | 0.226 |
| King James | 1773 | 9131 | 18.501 | 0.163 | −0.0489 |
| Data Set | CN | AA | Jac | PA | AM-ResNet-LP | DenseNet-LP |
|---|---|---|---|---|---|---|
| USAir | 0.9368 | 0.9507 | 0.9072 | 0.8876 | 0.9550 | 0.9554 |
| Metabolic | 0.8448 | 0.8540 | 0.8050 | 0.8229 | 0.8632 | 0.8742 |
| PB | 0.9218 | 0.9250 | 0.8760 | 0.9022 | 0.9322 | 0.9474 |
| King James | 0.6543 | 0.6690 | 0.6621 | 0.5195 | 0.8877 | 0.8966 |
| Data Set | LINE | DeepWalk | node2vec | AM-ResNet-LP | DenseNet-LP |
|---|---|---|---|---|---|
| USAir | 0.8066 | 0.7665 | 0.8349 | 0.9550 | 0.9554 |
| Metabolic | 0.7733 | 0.7871 | 0.7970 | 0.8632 | 0.8742 |
| PB | 0.7779 | 0.7783 | 0.7911 | 0.9322 | 0.9474 |
| King James | 0.8634 | 0.8602 | 0.8895 | 0.8877 | 0.8966 |
| Model | Dataset | Simple Size | AUC | Interval (c1,c2) |
|---|---|---|---|---|
| DenseNet-LP | USAir | 424 | 0.9554 | 0.935~0.975 |
| Metabolic | 404 | 0.8742 | 0.836~0.902 | |
| PB | 3342 | 0.9474 | 0.940~0.955 | |
| King James | 1810 | 0.8966 | 0.882~0.910 | |
| AM-ResNet-LP | USAir | 424 | 0.9550 | 0.935~0.975 |
| Metabolic | 404 | 0.8632 | 0.828~0.895 | |
| PB | 3342 | 0.9322 | 0.924~0.941 | |
| King James | 1810 | 0.8877 | 0.873~0.902 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Wu, L.; Huang, Y.; Wang, H.; Zhu, R. Link Prediction Based on Deep Convolutional Neural Network. Information 2019, 10, 172. https://doi.org/10.3390/info10050172
Wang W, Wu L, Huang Y, Wang H, Zhu R. Link Prediction Based on Deep Convolutional Neural Network. Information. 2019; 10(5):172. https://doi.org/10.3390/info10050172
Chicago/Turabian StyleWang, Wentao, Lintao Wu, Ye Huang, Hao Wang, and Rongbo Zhu. 2019. "Link Prediction Based on Deep Convolutional Neural Network" Information 10, no. 5: 172. https://doi.org/10.3390/info10050172
APA StyleWang, W., Wu, L., Huang, Y., Wang, H., & Zhu, R. (2019). Link Prediction Based on Deep Convolutional Neural Network. Information, 10(5), 172. https://doi.org/10.3390/info10050172