Visual Saliency Prediction Based on Deep Learning


Abstract
:1. Introduction
- (1)
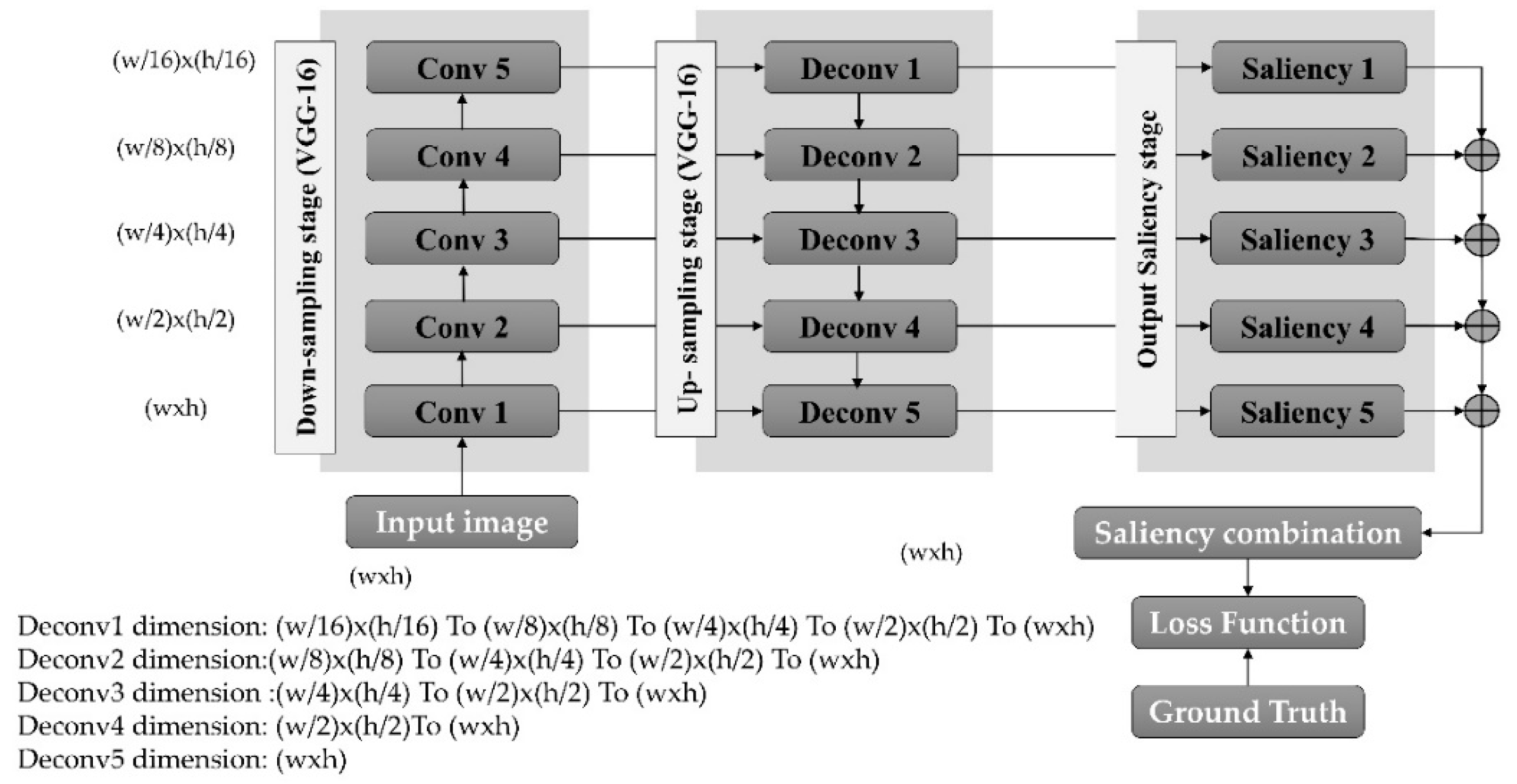
- A deep learning architecture based on the VGG-16 network that is able to predict visual saliency is proposed. As opposed to the current state-of-the-art technique that uses three stages in the encoder/decoder architecture [26], the proposed network uses five encoder and decoder stages to produce a useful saliency map (e.g., visual saliency). This makes the proposed architecture more powerful for extracting more specific deep features;
- (2)
- The proposed model is the first to use a semantic segmentation technique within the encoder-decoder architecture to classify all image pixels into the appropriate class (foreground or background), where the foreground is most likely a salient object;
- (3)
- The proposed model is evaluated using four well-known datasets, including TORONTO, MIT300, MIT1003, and DUT-OMRON. The proposed model achieves a reasonable result, with a global accuracy of 96.22%.
2. The Proposed Method
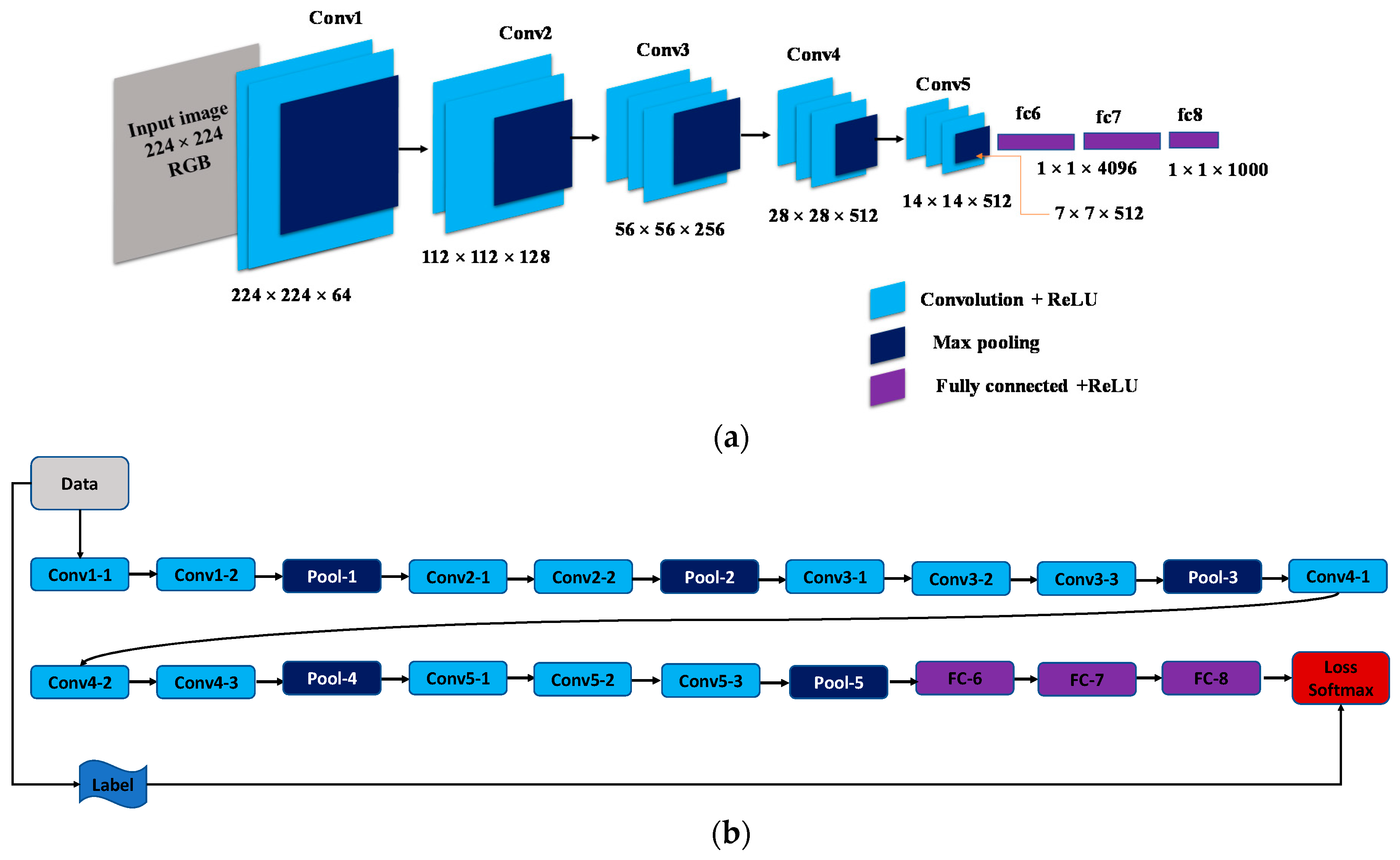
2.1. The VGG-16 Netwok Architecture
2.2. Visual Saliency Prediction Model
3. Materials and Methods
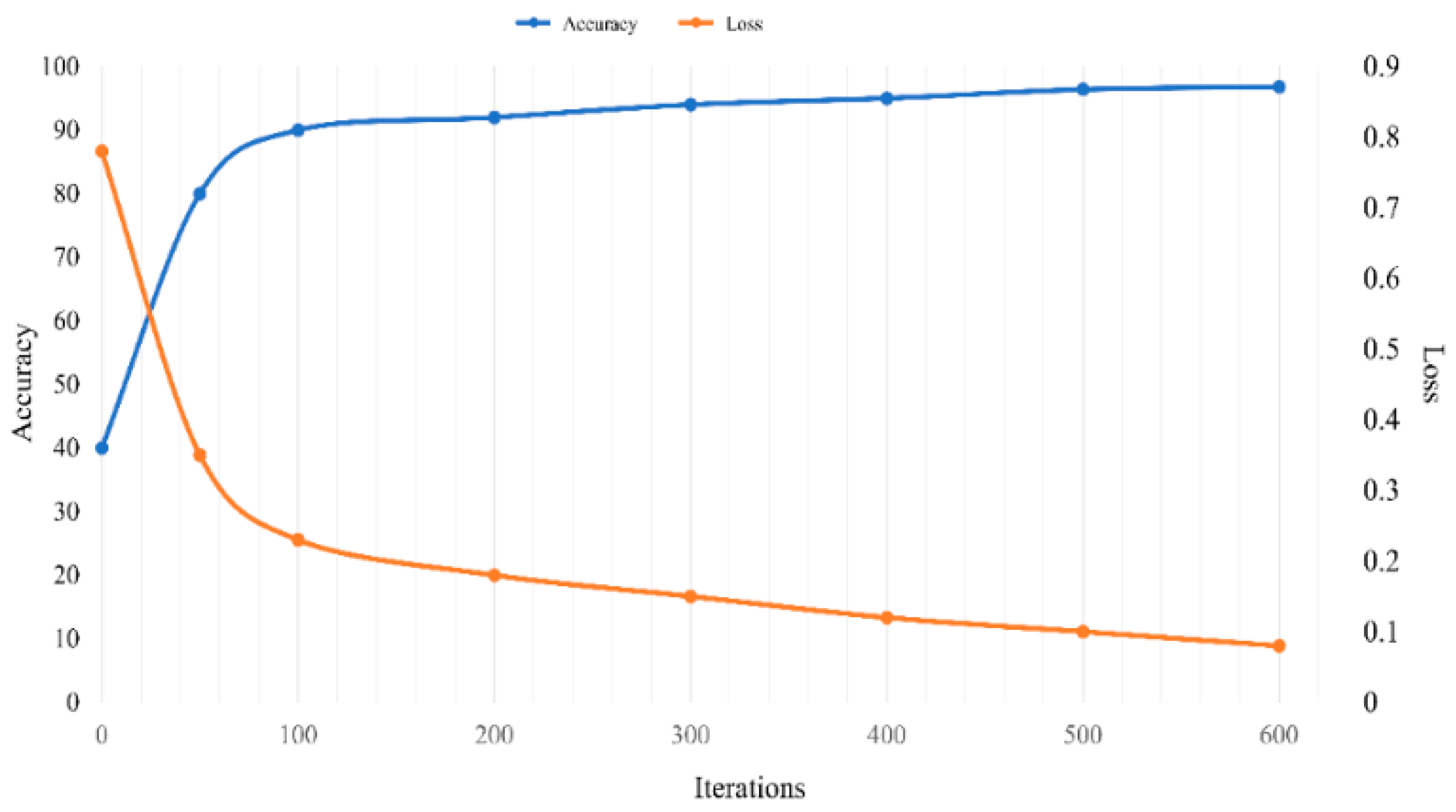
3.1. Model Training
3.2. Model Testing
3.3. Datasets
3.3.1. SALICON
3.3.2. TORONTO
3.3.3. MIT300
3.3.4. MIT1003
3.3.5. DUT-OMRON
3.4. Evaluation Metrics
3.4.1. Normalized Scanpath Saliency (NSS)
3.4.2. Similarity Metric (SIM)
3.4.3. Judd Implementation (AUC-Judd)
3.4.4. Borji Implementation (AUC-Borji)
3.4.5. Semantic Segmentation Metrices
4. Experimental Results
4.1. Quantitative Comparison of the Proposed Model with other State-of-the-Art Models
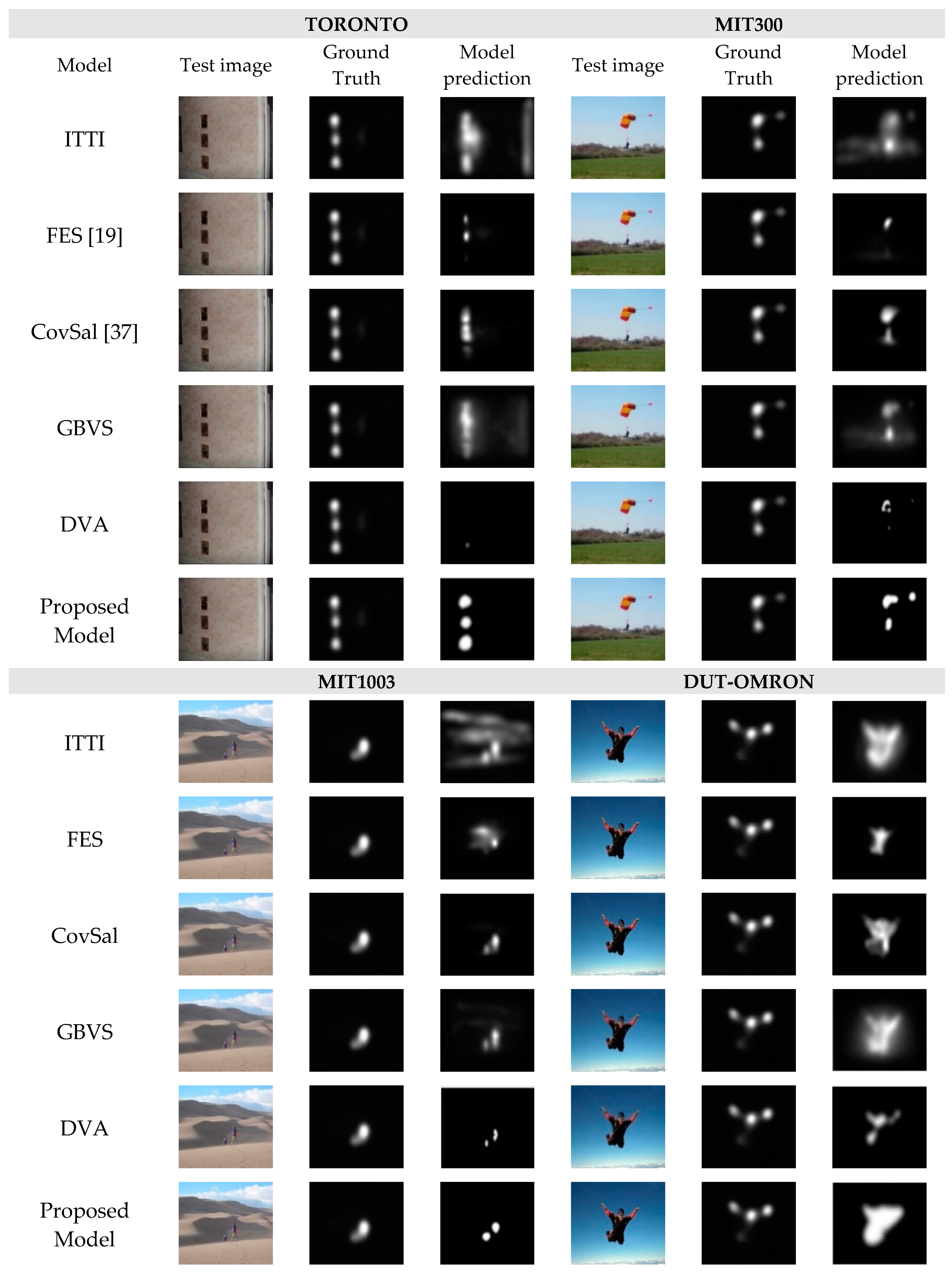
4.2. Qualitative Comparison of the Proposed Model with Other State-of-the-Art Models
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Sun, Y.; Fisher, R. Object-based visual attention for computer vision. Artif. Intell. 2003, 146, 77–123. [Google Scholar] [CrossRef] [Green Version]
- Koch, C.; Ullman, S. Shifts in selective visual attention: Towards the underlying neural circuitry. In Matters of Intelligence; Springer: Dordrecht, The Netherlands, 1987; pp. 115–141. [Google Scholar]
- Wang, K.; Wang, S.; Ji, Q. Deep eye fixation map learning for calibration-free eye gaze tracking. In Proceedings of the Ninth Biennial ACM Symposium on Eye Tracking Research & Applications, Charleston, SC, USA, 14–17 March 2016; pp. 47–55. [Google Scholar]
- Borji, A. Boosting bottom-up and top-down visual features for saliency estimation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 438–445. [Google Scholar]
- Zhu, W.; Deng, H. Monocular free-head 3D gaze tracking with deep learning and geometry constraints. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3143–3152. [Google Scholar]
- Kanan, C.; Tong, M.H.; Zhang, L.; Cottrell, G.W. SUN: Top-down saliency using natural statistics. Vis. Cogn. 2009, 17, 979–1003. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hickson, S.; Dufour, N.; Sud, A.; Kwatra, V.; Essa, I. Eyemotion: Classifying facial expressions in VR using eye-tracking cameras. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1626–1635. [Google Scholar]
- Zhao, R.; Ouyang, W.; Li, H.; Wang, X. Saliency detection by multi-context deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1265–1274. [Google Scholar]
- Recasens, A.; Vondrick, C.; Khosla, A.; Torralba, A. Following gaze in video. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1435–1443. [Google Scholar]
- Wang, C.; Shi, F.; Xia, S.; Chai, J. Realtime 3D eye gaze animation using a single RGB camera. ACM Trans. Graph. 2016, 35, 118. [Google Scholar] [CrossRef]
- Cornia, M.; Baraldi, L.; Serra, G.; Cucchiara, R. Paying more attention to saliency: Image captioning with saliency and context attention. ACM Trans. Multimed. Comput. Commun. Appl. 2018, 14, 48. [Google Scholar] [CrossRef]
- Naqvi, R.; Arsalan, M.; Batchuluun, G.; Yoon, H.; Park, K. Deep learning-based gaze detection system for automobile drivers using a NIR camera sensor. Sensors 2018, 18, 456. [Google Scholar] [CrossRef] [PubMed]
- Rezaee, M.; Mahdianpari, M.; Zhang, Y.; Salehi, B. Deep Convolutional Neural Network for Complex Wetland Classification Using Optical Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3030–3039. [Google Scholar] [CrossRef]
- Krafka, K.; Khosla, A.; Kellnhofer, P.; Kannan, H.; Bhandarkar, S.; Matusik, W.; Torralba, A. Eye tracking for everyone. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2176–2184. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Kruthiventi, S.S.S.; Gudisa, V.; Dholakiya, J.H.; Venkatesh Babu, R. Saliency unified: A deep architecture for simultaneous eye fixation prediction and salient object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5781–5790. [Google Scholar]
- Pan, J.; Sayrol, E.; Giro-i-Nieto, X.; McGuinness, K.; O’Connor, N.E. Shallow and deep convolutional networks for saliency prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 598–606. [Google Scholar]
- Mahdianpari, M.; Salehi, B.; Mohammadimanesh, F.; Motagh, M. Random forest wetland classification using ALOS-2 L-band, RADARSAT-2 C-band, and TerraSAR-X imagery. ISPRS J. Photogramm. Remote Sens. 2017, 130, 13–31. [Google Scholar] [CrossRef]
- Liu, N.; Han, J.; Liu, T.; Li, X. Learning to predict eye fixations via multiresolution convolutional neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2016, 29, 392–404. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Mahdianpari, M.; Salehi, B.; Rezaee, M.; Mohammadimanesh, F.; Zhang, Y. Very deep convolutional neural networks for complex land cover mapping using multispectral remote sensing imagery. Remote Sens. 2018, 10, 1119. [Google Scholar] [CrossRef]
- Jiang, M.; Huang, S.; Duan, J.; Zhao, Q. Salicon: Saliency in context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1072–1080. [Google Scholar]
- Judd, T.; Ehinger, K.; Durand, F.; Torralba, A. Learning to predict where humans look. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2106–2113. [Google Scholar]
- Bruce, N.; Tsotsos, J. Saliency based on information maximization. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; pp. 155–162. [Google Scholar]
- Li, Y.; Hou, X.; Koch, C.; Rehg, J.M.; Yuille, A.L. The secrets of salient object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 280–287. [Google Scholar]
- Wang, W.; Shen, J. Deep visual attention prediction. IEEE Trans. Image Process. 2017, 27, 2368–2378. [Google Scholar] [CrossRef] [PubMed]
- Mohammadimanesh, F.; Salehi, B.; Mahdianpari, M.; Gill, E.; Molinier, M. A new fully convolutional neural network for semantic segmentation of polarimetric SAR imagery in complex land cover ecosystem. ISPRS J. Photogramm. Remote Sens. 2019, 151, 223–236. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Qian, N. On the momentum term in gradient descent learning algorithms. Neural Netw. 1999, 12, 145–151. [Google Scholar] [CrossRef]
- Judd, T.; Durand, F.; Torralba, A. A Benchmark of Computational Models of Saliency to Predict Human Fixations. 2012. Available online: http://hdl.handle.net/1721.1/68590 (accessed on 9 August 2019).
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.-H. Saliency detection via graph-based manifold ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3166–3173. [Google Scholar]
- Wang, W.; Shen, J.; Yang, R.; Porikli, F. Saliency-aware video object segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 20–33. [Google Scholar] [CrossRef] [PubMed]
- Harel, J.; Koch, C.; Perona, P. Graph-based visual saliency. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 545–552. [Google Scholar]
- Borji, A.; Tavakoli, H.R.; Sihite, D.N.; Itti, L. Analysis of scores, datasets, and models in visual saliency prediction. In Proceedings of the IEEE international Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 921–928. [Google Scholar]
- Tavakoli, H.R.; Rahtu, E.; Heikkilä, J. Fast and efficient saliency detection using sparse sampling and kernel density estimation. In Proceedings of the Scandinavian Conference on Image Analysis, Ystad, Sweden, 23–25 May 2011; pp. 666–675. [Google Scholar]
- Erdem, E.; Erdem, A. Visual saliency estimation by nonlinearly integrating features using region covariances. J. Vis. 2013, 13, 11. [Google Scholar] [CrossRef] [PubMed]
- Bruce, N.D.B.; Tsotsos, J.K. Saliency, attention, and visual search: An information theoretic approach. J. Vis. 2009, 9, 5. [Google Scholar] [CrossRef] [PubMed]
- Csurka, G.; Larlus, D.; Perronnin, F.; Meylan, F. What is a good evaluation measure for semantic segmentation? In Proceedings of the 24th British Machine Vision Conference (BMVC), Bristol, UK, 9–13 September 2013; Volume 27, p. 2013. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | NSS | SIM | AUC-Judd | AUC-Borji |
|---|---|---|---|---|
| ITTI [38] | 1.30 | 0.45 | 0.80 | 0.80 |
| AIM [23] | 0.84 | 0.36 | 0.76 | 0.75 |
| Judd Model [34] | 1.15 | 0.40 | 0.78 | 0.77 |
| GBVS [31] | 1.52 | 0.49 | 0.83 | 0.83 |
| Mr-CNN [39] | 1.41 | 0.47 | 0.80 | 0.79 |
| DVA [26] | 2.12 | 0.58 | 0.86 | 0.86 |
| Proposed Model | 3.00 | 0.42 | 0.91 | 0.87 |
| Model | NSS | SIM | AUC-Judd | AUC-Borji |
|---|---|---|---|---|
| ITTI | 0.97 | 0.44 | 0.75 | 0.74 |
| AIM | 0.79 | 0.40 | 0.77 | 0.75 |
| Judd Model | 1.18 | 0.42 | 0.81 | 0.80 |
| GBVS | 1.24 | 0.48 | 0.81 | 0.80 |
| Mr-CNN | 1.13 | 0.45 | 0.77 | 0.76 |
| DVA | 1.98 | 0.58 | 0.85 | 0.78 |
| Proposed Model | 2.43 | 0.51 | 0.87 | 0.80 |
| Model | NSS | SIM | AUC-Judd | AUC-Borji |
|---|---|---|---|---|
| ITTI | 1.10 | 0.32 | 0.77 | 0.76 |
| AIM | 0.82 | 0.27 | 0.79 | 0.76 |
| Judd Model | 1.18 | 0.42 | 0.81 | 0.80 |
| GBVS | 1.38 | 0.36 | 0.83 | 0.81 |
| Mr-CNN | 1.36 | 0.35 | 0.80 | 0.77 |
| DVA | 2.38 | 0.50 | 0.87 | 0.85 |
| Proposed Model | 2.39 | 0.42 | 0.87 | 0.80 |
| Model | NSS | SIM | AUC-Judd | AUC-Borji |
|---|---|---|---|---|
| ITTI | 3.09 | 0.53 | 0.83 | 0.83 |
| AIM | 1.05 | 0.32 | 0.77 | 0.75 |
| GBVS | 1.71 | 0.43 | 0.87 | 0.85 |
| DVA | 3.09 | 0.53 | 0.91 | 0.86 |
| Proposed Model | 2.50 | 0.49 | 0.91 | 0.84 |
| Datasets | Global Accuracy | WeightedIoU |
|---|---|---|
| TORONTO | 0.96227 | 0.94375 |
| MIT300 | 0.94131 | 0.91924 |
| MIT1003 | 0.94862 | 0.92638 |
| DUT-OMRON | 0.94484 | 0.92605 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghariba, B.; Shehata, M.S.; McGuire, P. Visual Saliency Prediction Based on Deep Learning. Information 2019, 10, 257. https://doi.org/10.3390/info10080257
Ghariba B, Shehata MS, McGuire P. Visual Saliency Prediction Based on Deep Learning. Information. 2019; 10(8):257. https://doi.org/10.3390/info10080257
Chicago/Turabian StyleGhariba, Bashir, Mohamed S. Shehata, and Peter McGuire. 2019. "Visual Saliency Prediction Based on Deep Learning" Information 10, no. 8: 257. https://doi.org/10.3390/info10080257
APA StyleGhariba, B., Shehata, M. S., & McGuire, P. (2019). Visual Saliency Prediction Based on Deep Learning. Information, 10(8), 257. https://doi.org/10.3390/info10080257