1. Introduction
Named-entity recognition refers to the identification of entities with a specific meaning. This includes the name and place associated with a person or the name of an organization from a large amount of unstructured or structured text. This research involves knowledge graphs, machine translation technology, entity relation extraction [
1], and automatic question answering. To obtain a more effective translation with machine translation technology, large enterprises often extract the entities in sentences for customized processing, which increases the use of keywords and improves the quality of sentence translation. However, traditional named-entity recognition methods rely heavily on linguistic knowledge and feature engineering. These ignore the hidden information of the entities in the text, thus increasing the difficulty of named-entity recognition in the text. Therefore, using the effective features and neural network technology to improve the accuracy of the named-entity recognition in the text is a hot research topic. With the improvement in human living standards, sports have become an indispensable part of our lives. Extracting the content of sporting events is of interest since there is a significant amount of sports information that appears on the Internet every day; hence, this is an urgent problem that needs to be solved. The identification of named entities in the sports field is an important part of information extracted from sports events, which is also the topic of this paper.
In recent years, with the development of deep learning technology, numerous deep learning methods have been applied to extract and recognize named entities. For example, Gu et al. [
2] accurately recognized the complex sports events named entities in Chinese text. Gu et al. proposed a method of named-entity recognition based on the cascaded conditional random fields. Feng et al. [
3] used word vector features and bidirectional long-short-term memory (Bi-LSTM) networks to obtain the correlation of text sequence tags, as well as the context semantic information of named entities. This improved the recognition accuracy of the named entities. Habibi et al. [
4] used word embedding technology to extract the word vector features of the named entities in biomedical text, which replaced the manual features. Subsequently, they identified and classified automatically extracted features via deep learning technology.
To improve the recognition accuracy of named entities in Vietnamese texts, Pham et al. [
5] introduced conditional random fields (CRF) and convolutional neural networks (CNNs) based on Bi-LSTM networks. Pham et al. used word and sentence vector features as input to increase the discriminability of named entities in Vietnamese text. Augenstein et al. [
6] combined feature sparse representation with deep learning technology to extract and recognize user-named entities from Web text, and they explained the feasibility of this method. Unanue et al. [
7] extracted the word vector features of named entities in medical text using word embedding techniques such as Word2vec. Unanue et al. further extracted the context semantic information of text with recurrent neural networks (RNNs), which achieved the accurate recognition of named entities in the text. In the process of extracting named entities from patient reports, the scarcity of their text labels poses a great challenge. To solve the problem, Lee et al. [
8] introduced transfer learning in entity extraction. Lee et al. transferred the data trained on the artificial neural network model to other case reports, which achieved good test results. To dispense with manual features completely, Wang et al. [
9] used the gated CNN to extract the global and local semantic information of the text. To verify the feasibility of this method further, three named-entity datasets were tested and satisfactory results were obtained. To extract the relevant named entities from unstructured texts of drug compounds, Pei et al. [
10] added models with an attention mechanism to the combined framework of bidirectional short and long memory networks and CRF to enhance the weights of key features in a text. This was validated using the CHEMDNER corpus. To capture the correlation between the named entities in the text further, Cetoli et al. [
11] introduced the graph CNN into the traditional framework of named-entity recognition to depict the influence of the sentence syntax for named-entity recognition.
Song et al. [
12] proposed a joint learning method of Chinese vocabulary and its components based on a ladder structure network. As a result, Yan Song et al. achieved the joint learning of different features and achieved good results.
The deep learning algorithms used by the researchers cited above eliminates the errors caused by artificial participation in setting features to improve the accuracy of named-entity recognition. However, most of these algorithms are based on simple word embedding technologies such as Word2vec or Word Embedding for extracting the word vector features of the text. This not only loses the semantic information of the named entities in the text but also ignores the hierarchical information between them. To solve these problems, this paper proposes a character-level graph convolutional self-attention network (CGCN-SAN) based on the Chinese sports text named-entity recognition method. The character-level graph convolutional network (GCN) is used to extract the character features and the internal structural information of the named entities in text. The self-attention mechanism is used to capture the global semantic information of the text and to describe the hierarchical structure of the named entities in the text.
The main contributions of this paper are as follows:
The character features of the named entities in sports text are obtained using the character-level GCN. The internal structural information of the named entities in the text is further characterized using graph convolution nodes.
The self-attention mechanism model is used to capture the global semantic information of sports text to enhance the correlation between the named entities in the text and to achieve an accurate named entities recognition.
2. Feature Learning
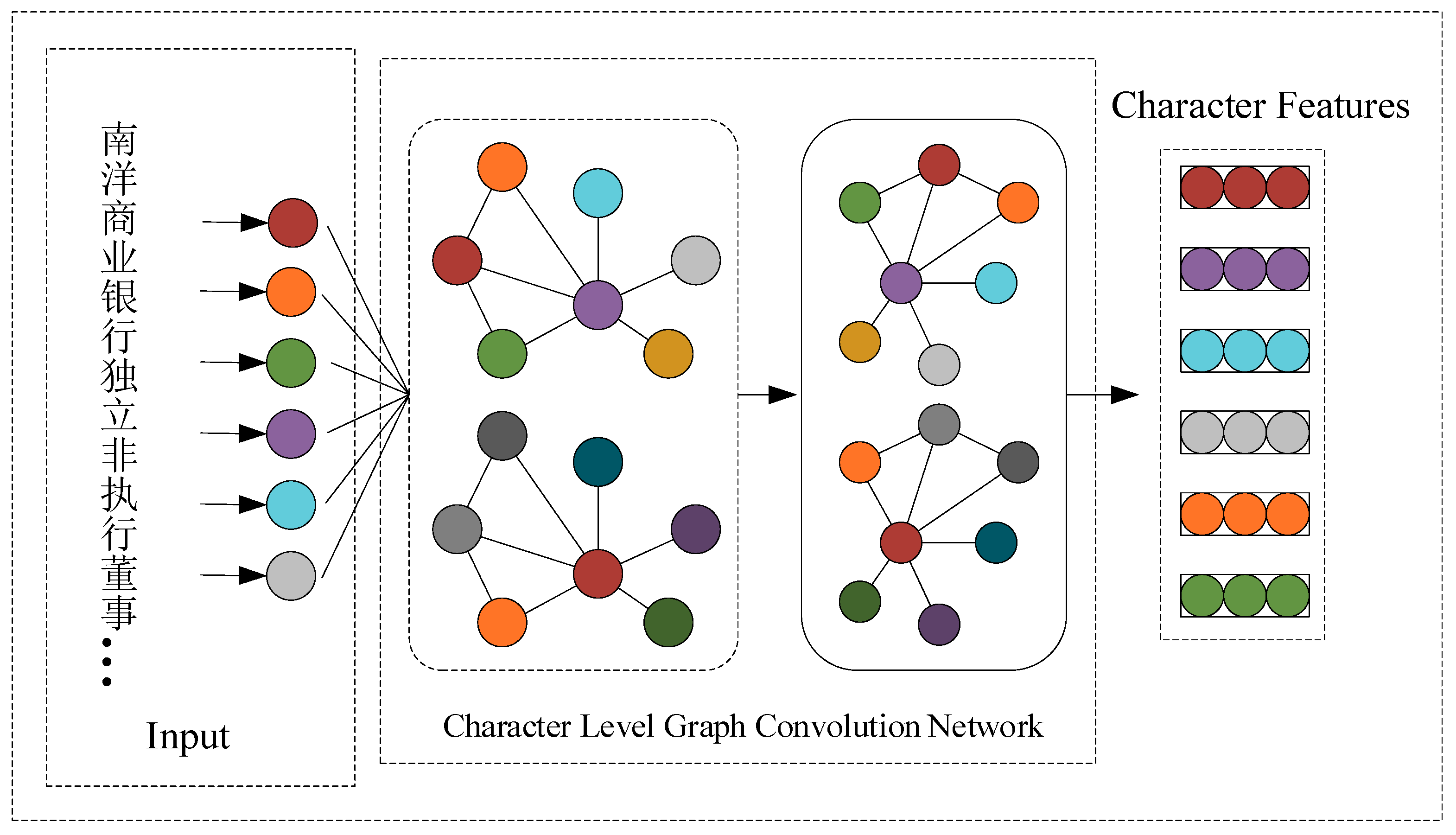
Effective features play a vital role in the correct recognition of named entities in sports text. That is, the more effective information the extracted features contain, the stronger the representation ability and vice versa. Based on simple word vector techniques such as Glove and Word2vec, traditional features of character, word vector, and sentence generation correspond to low-dimensional space vectors, which are used to represent text. These methods can effectively map sports texts into low-dimensional space to increase the use of potential information in sports text. However, they not only ignore the related information existing between the named entities in sports text, but also lose the global semantic information and details. The text information is filtered when the word vector is mapped. As a result, the unimportant information is deleted and only the important information is retained. This method seems to capture significant information about the sports text; however, the information that is often lost also has a certain value. Therefore, to better capture the correlation between named entities in sports text, as well as the global semantic information of sports text and to avoid the loss of detailed information, a character-level GCN is constructed in this study. The GCN extracts the character feature information of sports text and semantically models it to improve the character representation ability. The characters in the Chinese text can also be understood as a single word. This is the basic unit of the text sentence; the character features that are captured can also be understood as syntactic information of the sports text. When extracting character features, the adjacent nodes in the GCN, as well as the individual words that make up the entity, are connected. Therefore, when the character structure of the sports text is extracted by the character-level GCN, the internal structural information of the named-entity is further captured. In the two-layer GCN used in the paper, when the information is exchanged between the layers, the upper layer information is transferred to the next layer. This forms the hierarchical relationship, namely the hierarchical structure information, between the named entities in the sports text. The specific character feature-extraction network structure is shown in
Figure 1.
In
Figure 1, each node in the GCN represents a character. A total of 2545 characters are used in this paper, which contains the commonly used 2,500 basic Chinese characters, 10 numeric characters (0123456789) and 35 special symbols, such as ~! @#¥%......&*()——+-=? ““,./‘;:“,|·~[]. One-hot is used to encode each character in the sports text. This is the input to character-level GCNs for learning how to obtain the character feature information of the sports text. The “character features” in the figure represents the character features that we have learned through the character-level GCN.
Since characters are the basic building blocks of words, and words compose texts, there is a close relationship between characters, words, and text. The traditional CNN [
13] prioritizes the local characteristics of the text when capturing the character information of the text; thus, a lot of information is lost. While the long short-term memory network [
14] considers the global semantic information of the text from the character information, it only expands in time; thus, it cannot effectively capture the deeper level abstract features. Each node in the character-level convolutional layer [
15,
16,
17], when extracting the character features of the named-entity, transmits the feature information obtained by itself to the next adjacent node after nonlinear variation. This is then passed onto multiple nodes nearby to achieve the accumulation of character information. The node itself can self-loop; thus, the internal structural information can be captured further through the node itself. The hierarchical structural information between the entity and the non-entity in the text can be acquired from the transfer between the convolutional layers. Finally, through the above methods, the accurate acquisition of character information, internal structural information, and hierarchical structural information in the sports text can be realized. The specific calculation steps are as follows:
(1) To capture the character information of the named-entity and the association between the characters in the text, character similarity
is used to construct the edge between the character nodes. If the value of
is greater than 0, an edge is added to the character nodes
and
, then the weight of the edge is 1. If the value of
is less than or equal to 0, the character nodes
and
are not edge-connected. The calculation is presented in Equation (1):
In Equation (1), represents an adjacency matrix of the character nodes and .
(2) The character vectors of nodes
and
are captured by Word2vec and are denoted as
and
, respectively. The similarity between nodes
and
is calculated by using the cosine similarity equation. The specific equation
is depicted in Equation (2):
In Equation (2), represents the angle between the vectors and .
(3) From the above steps (1) and (2), a character graph structure is obtained, and the form satisfies , where and respectively represent a set of character nodes and a set of edges between nodes. The matrix input into the character-level GCNs is , where N represents the number of character nodes and M represents the feature vector dimension of the node.
The input and training process of the text in the graph convolution layer is demonstrated as follows:
where
represents the hidden layers, and
signifies the number of hidden layers.
The optimization process of the node matrix and the adjacency matrix of the graph convolution layer is provided as follows:
where
σ and
ω represent the weight of the activation function and the upper hidden layer, respectively.
Considering that not all of the named entities in the dataset of sports text are labeled—that is, the classification label can only be used for a part of the nodes—the Laplacian regularization loss function [
18] is introduced into the graph convolution layer. In this way, the label information of the node can be transmitted to the adjacent node, the feature information of the adjacent node can be pooled, and the internal structure information of the node can be captured. The Laplace regularization function is calculated as follows:
where
represents the supervision loss of some classification labels,
represents the differentiable function of the GCN,
is a weighted factor of a loss function, and
is the eigenvector matrix of the nodes of the graph.
Finally, the hierarchical relationship between the named entities and non-entities is obtained. This further enhances the feature information representation ability.
(4) Finally, through the character-level GCN, we can capture the character information of the named-entity in the text, which is denoted as .
3. Methodology
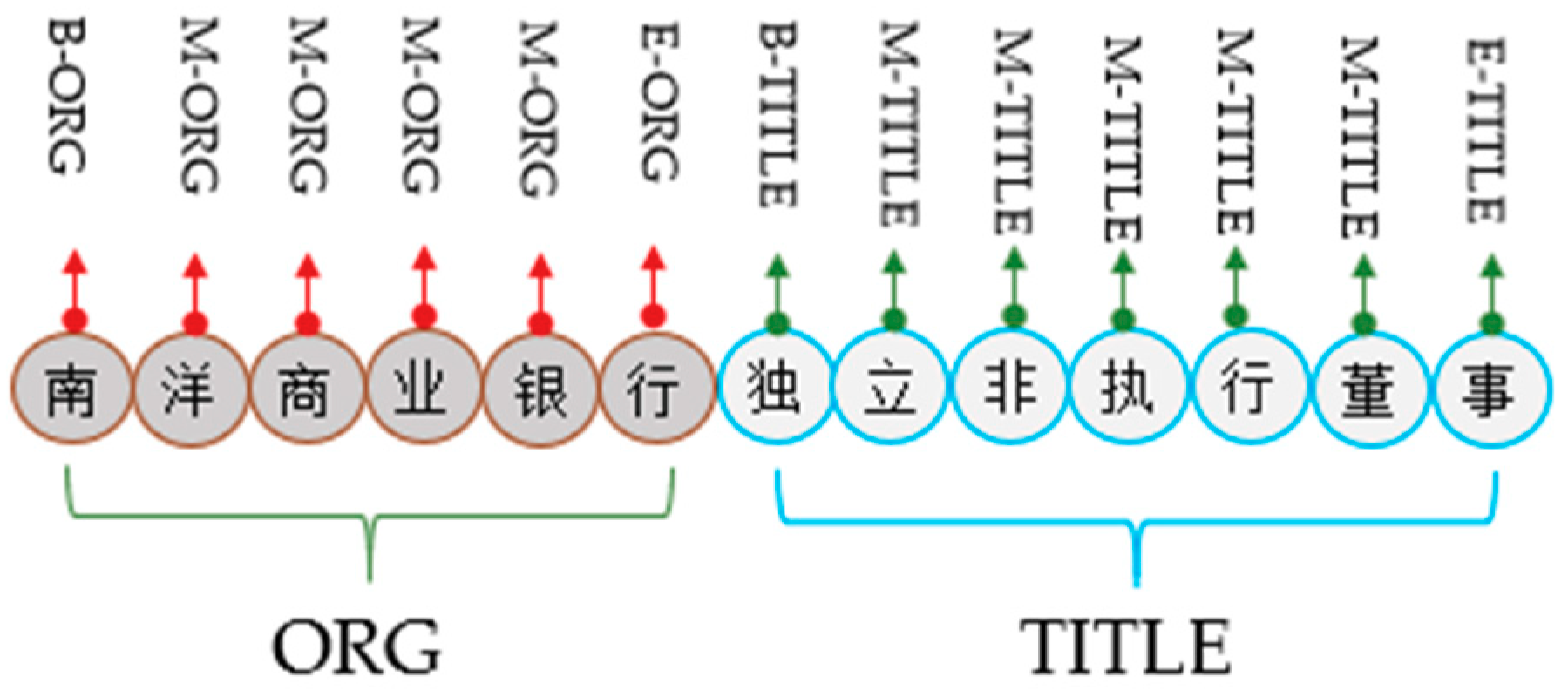
In the joint extraction of entity relations, the sequence labeling method is generally used to jointly extract and identify the entity relationships in the text. Therefore, to compensate for the deficiency of the description of the text semantic information by the features, this paper transforms the problem of named-entity recognition into a problem of sequence annotation. Consider the following classifications: the initial entity unit is labeled as B; the internal entity unit is I; other non-entity words are designated as O; the name of an athlete is SPER; a team is referred to as Steam; and an organization is referred to as Sport organization (SORG). For instance, Yao Ming is B-I-SPER, the organizer of the event is B-I-SORG, which represents the Chinese Basketball Association, and the team name is B-I-S, which is the Chinese Basketball Team. Taking ResumeNER as an experimental sample, the annotation result of named-entity of ResumeNER is given, as shown in
Figure 2.
In
Figure 2, “B” represents the start unit of the named-entity; “M” represents the middle unit of the named-entity; “E” represents the end unit of the named-entity; “ORG” represents the organization; “TITLE” represents the name class entity.
To further reduce the accumulated errors in the transmission of semantic information between layers, this paper adopts the self-attention model [
19,
20] to capture the spatial relationship between long-distance named entities in sports text. Because of the use of the transformer framework in encoding and decoding conversions, the self-attention mechanism model not only effectively solves the long-distance dependency problem of cyclic neural networks (RNN) [
21,
22], but also improves the overall operation efficiency of the model. However, the correlation between the adjacent named entities is independent of each location when extracting the semantic information of the text is ignored. Therefore, a gated bidirectional long-term and short-term memory network is used based on the model of the self-attention mechanism. The detailed network structure is shown in
Figure 3. The character features in the figure are the character information extracted by the character-level GCN. Word features are the word vector information captured by Word2vec, that is,
.
In
Figure 3, the network framework is divided into three parts. These include the feature representation layer (character feature and word vector feature), the Bi-LSTM layer of self-attention, and the output layer of the CRF. The example “南洋商业银行独立非执行董事 (means: nanyang commercial bank independent non-executive director)” in the figure is from the ResumeNER benchmark data set; “-ORG” represents the named-entity related to the organization. For the character entities in “-ORG,” we can respectively represent “B-ORG,” “M-ORG,” and “E-ORG,” where “B” represents the initial unit of the entity, “M” represents the intermediate unit of the entity, and “E” represents the end unit of the entity. “-TITLE” represents the named-entity associated with a TITLE.
The feature presentation layer combines the character information with the word vector information as
. The specific calculation is shown in Equation (6):
In Equation (6),
represents the series operation. For the Bi-LSTM layer of self-attention, the character and word vector features
of the named entities are inputted into a bidirectional long short-term memory network. This can characterize the dependencies between the long-term named entities in the text further; the relevant encoding and decoding operations are performed. The transformer framework [
23,
24], with the self-attention mechanism, is used in the process of the coding-decoding conversion. This can improve the overall operation efficiency of the model while avoiding the loss of the location information of the named entities. The specific calculation of the input Bi-LSTM layer is described with Equation (7):
where:
represents the hidden layer of the bidirectional long-term and short-term memory network at time
t;
represents a bidirectional network of the long short-term memory; and
represents the feature vector input at time
t. When
,
.
in Equation (7) consists of a plurality of gate structures and memory cells [
25,
26]. The equations of each gate and memory unit are given as follows:
where the input gate, forget gate, output gate, offset, and the memory unit are represented as
i, ƒ,
o,
b, and
c, respectively.
In order to further capture the correlations between the characters in the text, between the characters and the named entities, and between the entity character locations, a multi-head self-attention mechanism was developed in the Bi-LSTM layer [
27,
28]. This was done to enforce the dependency between the characters and the words. First, for the single-head self-attention mechanism, the expression form of the time series
of t is shown in Equation (9):
where
Q,
K, and
V represent the query, key, and value vectors. The calculation of the multi-head self-attention is shown in Equation (10):
where
represent the relevant weight matrix.
CRF layer: Considering the dependency between the adjacent tags, we used the CRF to predict the probability of the tags [
29]. The probability prediction value of the tag sequence
in the sentence is shown in Equation (11):
where
represents the possible value of a tag
in a sequence of sentences;
represents the score of
and
.
In order to reduce the over-fitting phenomenon in the learning process of the model and to confirm the tag sequence
with the highest score in the text sentences, the regularized loss function was applied [
30]. The specific calculation for this is shown in Equation (12):
where we used the regularized loss function,
.
In summary, the proposed framework can encode and decode the named entities in the text according to the contextual semantic information. It can also further capture the relationship between the long-distance named entities in sports text. Finally, complete accurate identification of the named entities was obtained.






{kind=link}
{kind=link}
{kind=link}
{kind=link}