Dramatically Reducing Search for High Utility Sequential Patterns by Maintaining Candidate Lists †

Abstract
:1. Introduction
- The maintenance of an item candidate list through out the search, which significantly reduces the time and space required to search. This reduction is due to the fact that items not in the list for a given candidate pattern are provably never required to be considered as possible extensions for that pattern, or for that pattern’s extensions.
- A method for computing an upper bound on the utility of all future extensions of a sequential pattern involving a particular item, referred to as the Reduced Concatenation Utility (RCU). Given a sequential pattern and item i, the RCU gives an upper bound on the possible utility of any other sequential pattern that is an extension of (i.e., that has as prefix) that includes i. If the RCU is found to be below the minimum utility, then i can be removed from the search. By capitalizing on the knowledge of candidate list of eligible items, this bound is proven to be tighter than the best existing bound from the literature, the Reduced Sequence Utility (RSU). This tighter upper bound results in earlier pruning and, thus, faster search.
- The introduction of a slightly more loose upper bound, referred to as the Pivot-Centered Prefix Extension Utility (PPEU) that is significantly less expensive computationally to compute than RCU, allowing it to more fully exploit the removed candidates and dramatically reduce the required search space. Experiments show that search time is reduced significantly for some datasets.
- The CRUSP (Candidate Reduced Utility-boundedness for Sequential Patterns) and CRUSPPivot algorithms, designed to implement search using the RCU and PPEU bound computation methods, respectively.
2. Background
2.1. Literature Review
2.2. Sequential Pattern Mining
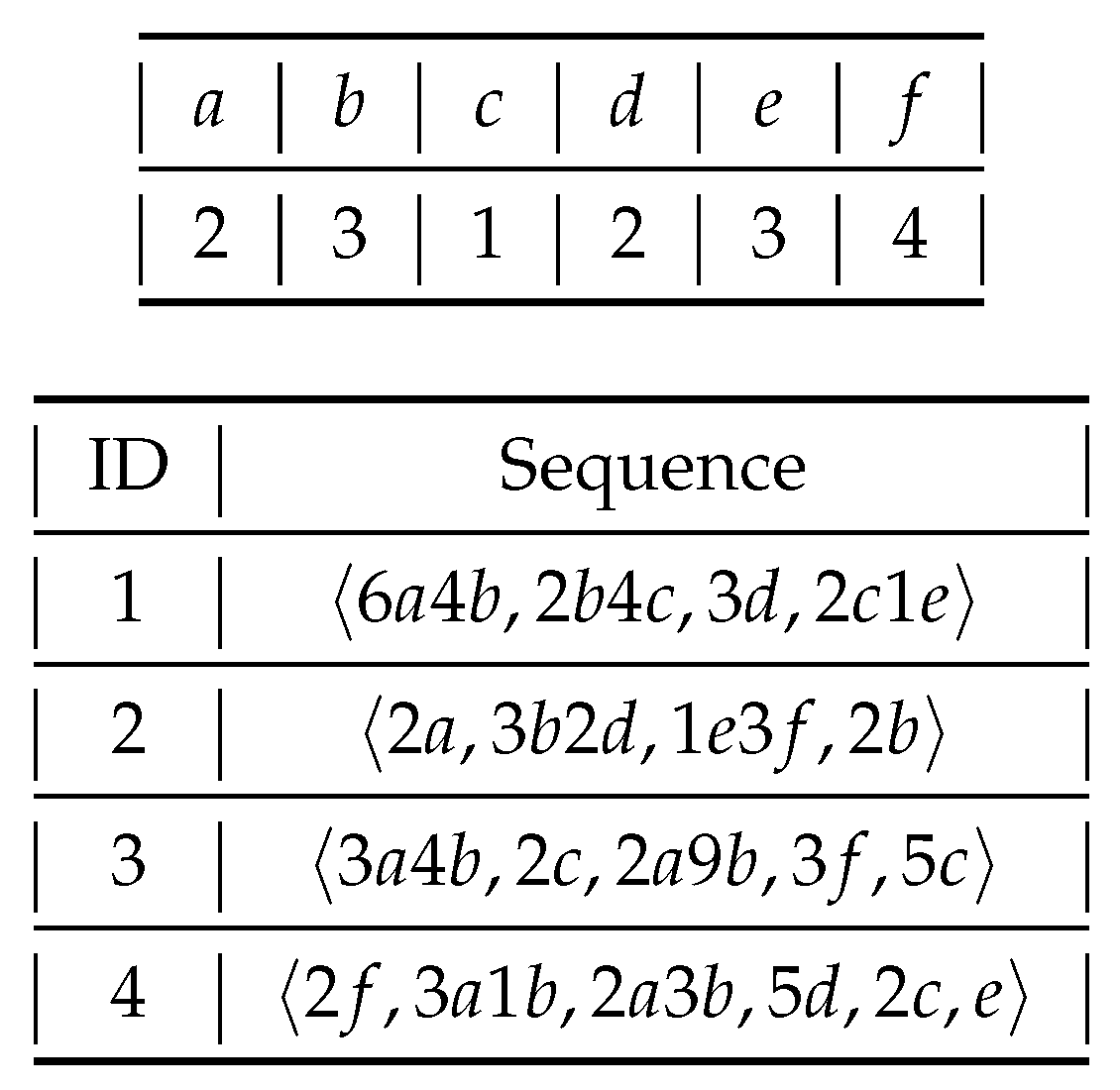
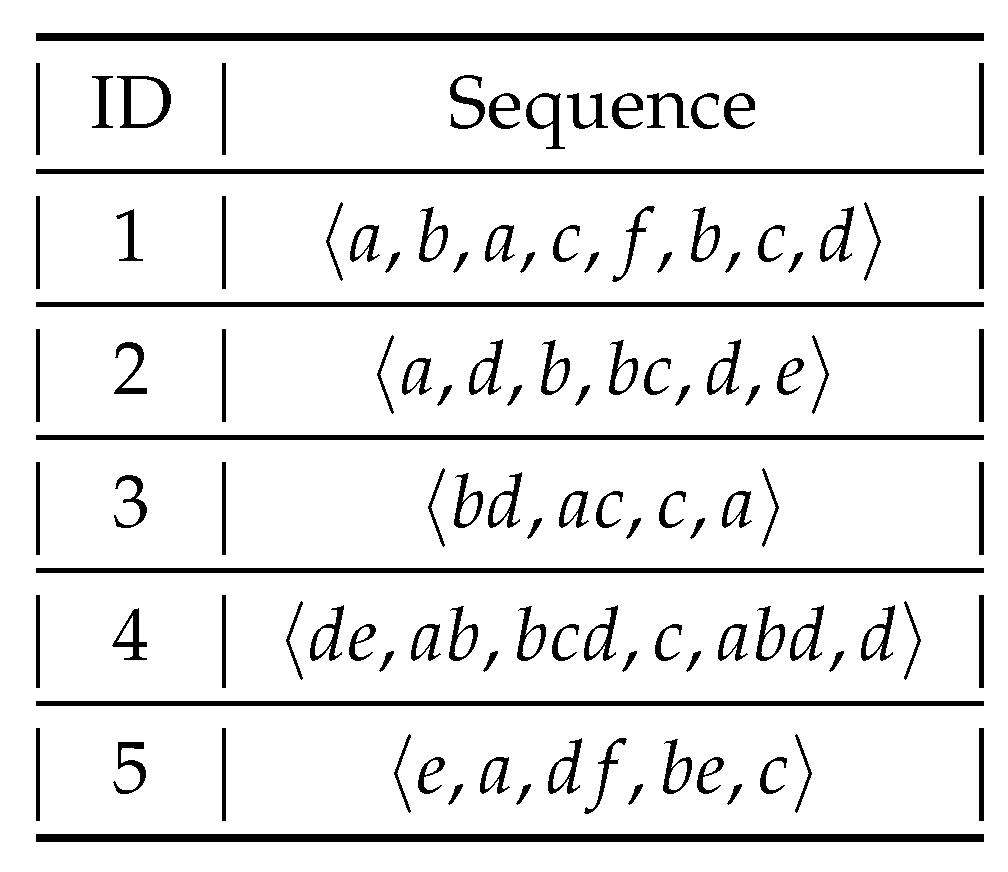
2.3. High Utility Sequential Pattern Mining
- has two matches in sequence 1, and , which have utilities and , respectively. Thus, the utility set for in sequence 1 is .
- has no match in sequence 2.
- has three matches in sequence 3: , and , yielding the utility set
- has two matches in sequence 4: and , yielding the utility set
3. Existing Bounding and Search Space Pruning Strategies
3.1. Lexicographic Tree Search
- i-extensions: an item is added to the final itemset of the pattern,
- s-extensions: an item is added to a newly added itemset appended to the end of the pattern.
3.2. Existing Pruning Strategies for HUSPM
- for : , , and ,
- for : , , and .
4. Candidate Generate-and-Test vs. Pattern Growth Methods
- First, instance of prefix:
- Projected sequence:
5. Concatenation Candidate List Maintenance
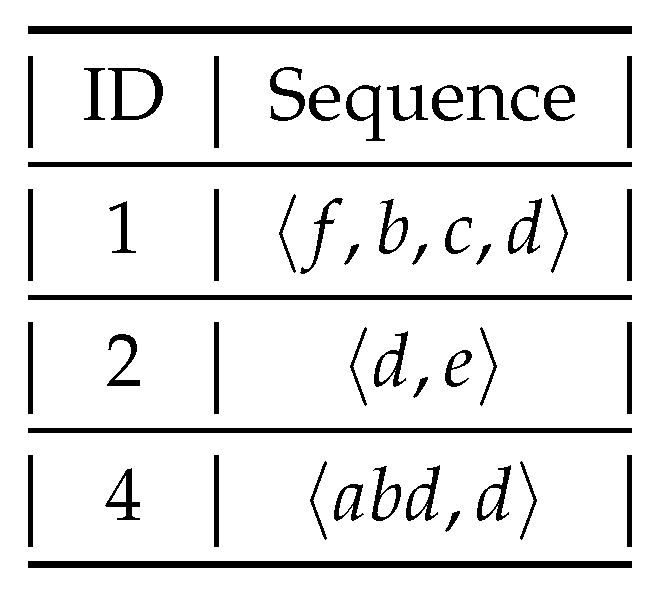
5.1. PEU-Based Candidate Maintenance
- Assume is false. Since contains , s will not contain and thus .
- Assume is false. Since is a result of i-concatenation with i and thus contains i, s will not contain and thus .
- Assume . Then, the first ending position of appears after the last position of i, so cannot be contained in s, and thus .
5.2. The CRUSP Algorithm
6. Candidate List Maintenance with Repeated Item Traversal
6.1. Pivot-Centered PEU-Based Candidate Maintenance
6.2. The CRUSPPivot Algorithm
7. Results
7.1. Objectives and Hypotheses
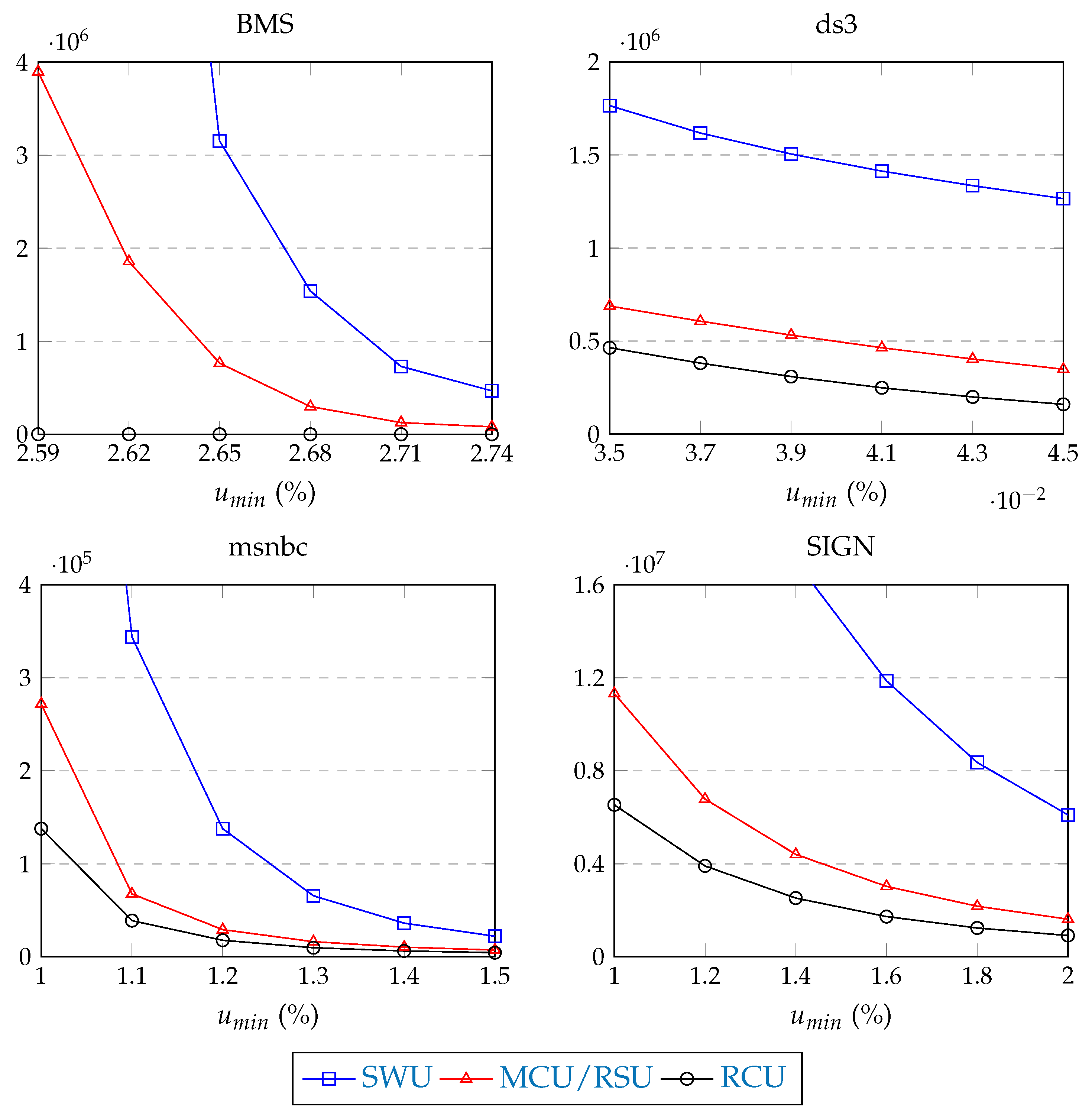
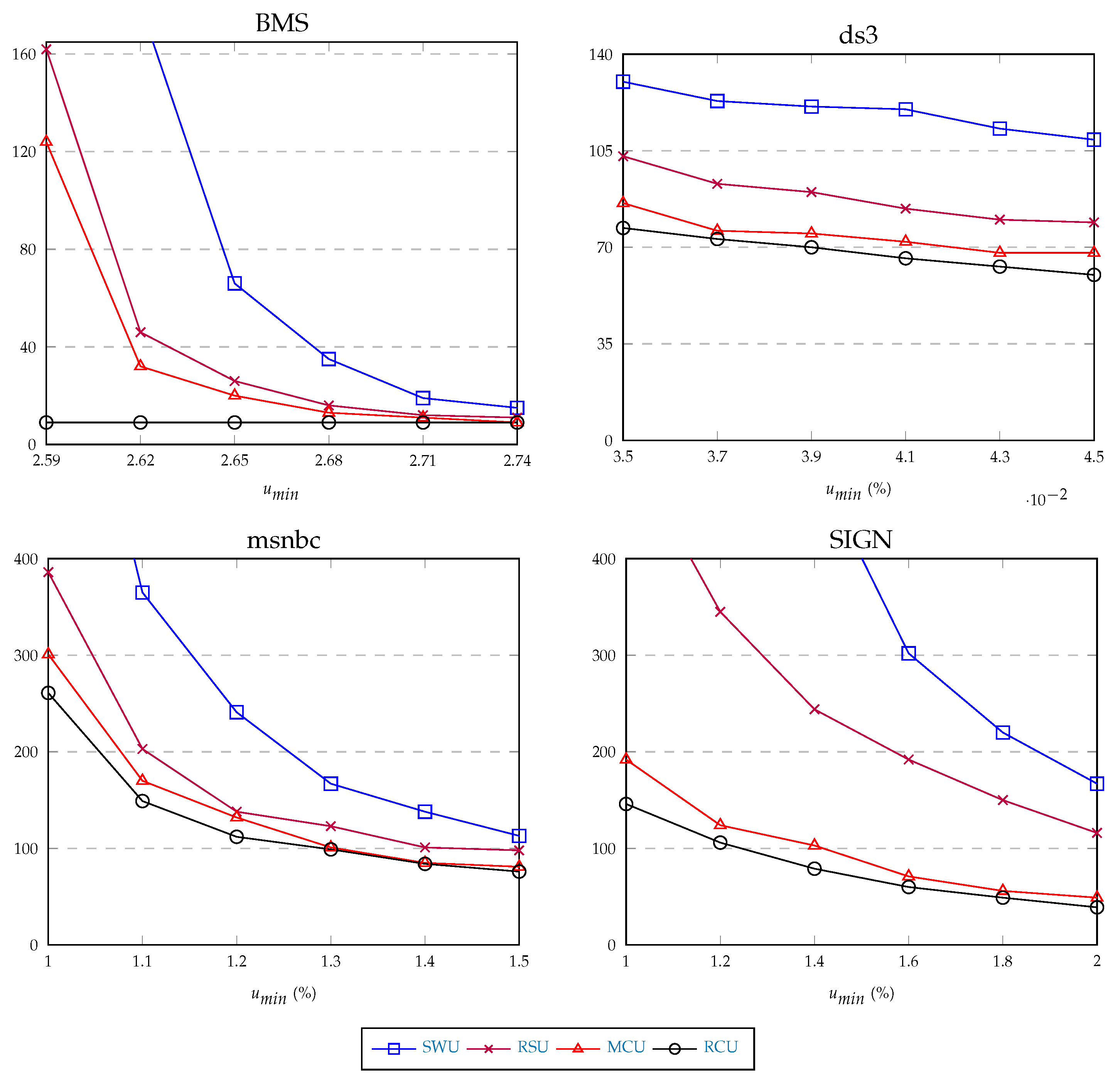
7.2. Experiment #1: CRUSP Performance Validation
- BMS: e-commerce website (click-stream data),
- ds3: e-commerce website (data on customer transactions),
- msnbc: data on website page visits (msnbc.com, 28 September 1999),
- SIGN: sign language data.
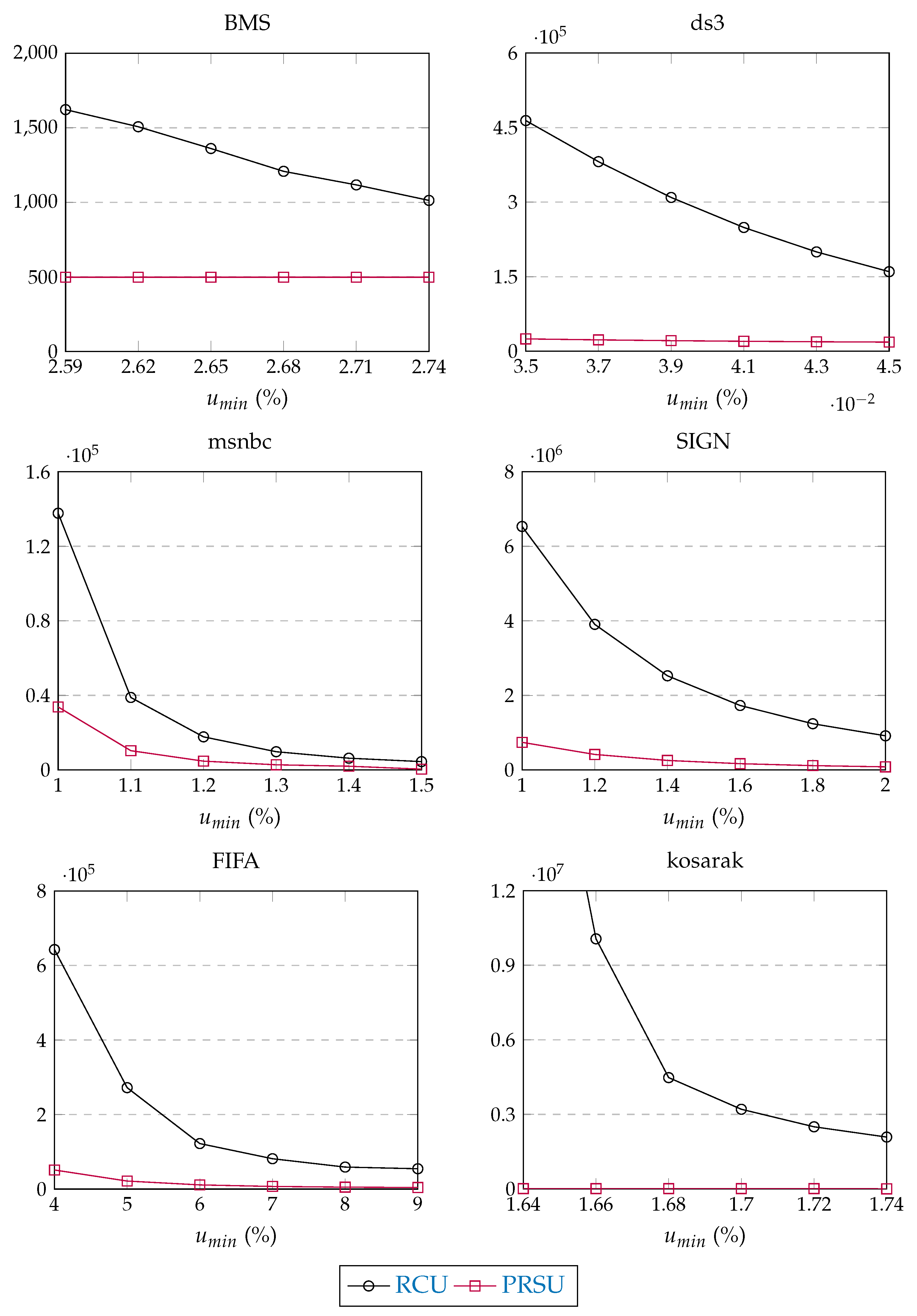
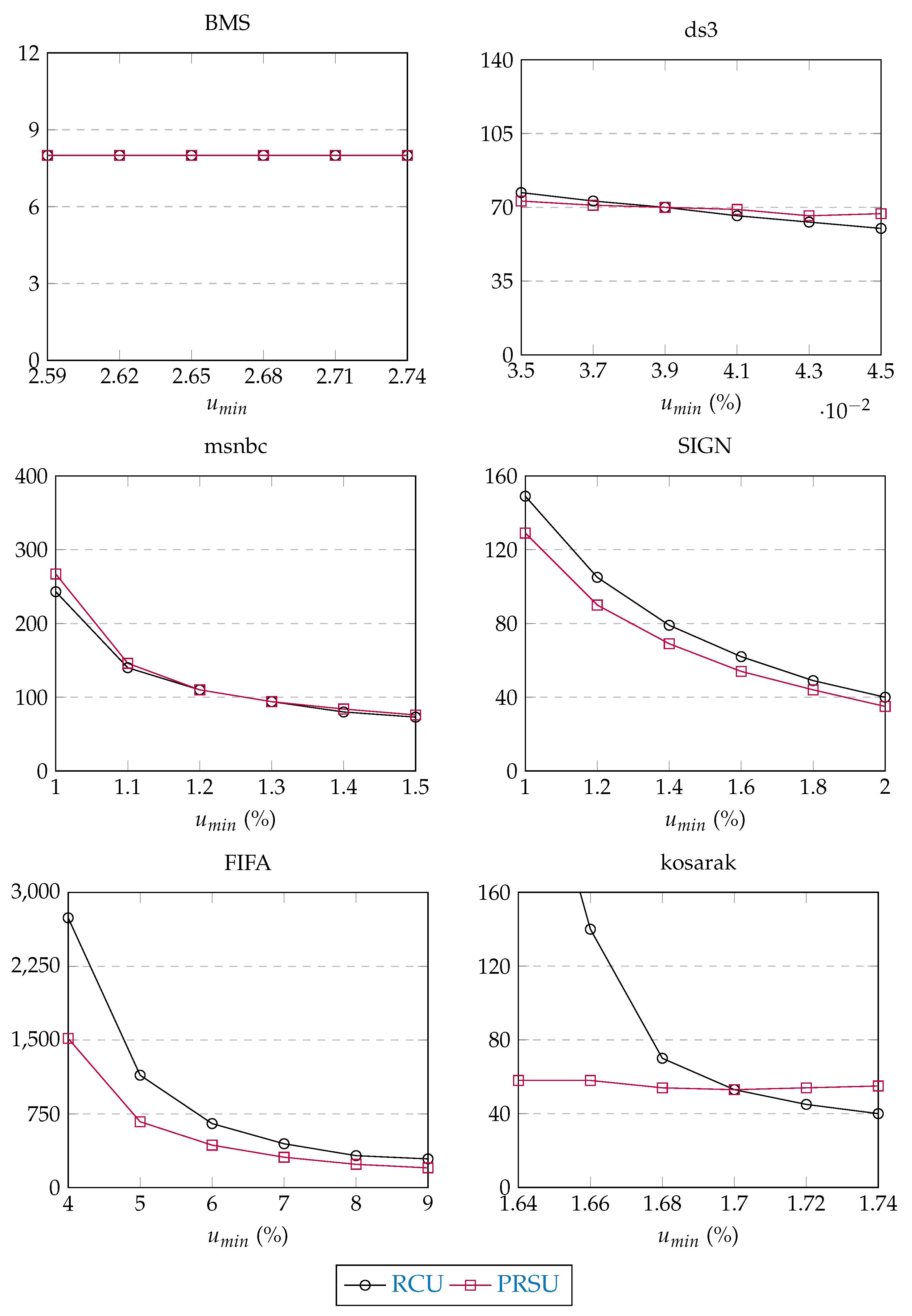
7.3. Experiment #2: CRUSPPivot Performance Validation
8. Conclusions
Funding
Conflicts of Interest
References
- Ahmed, C.F.; Tanbeer, S.K.; Jeong, B.S. A novel approach for mining high-utility sequential patterns in sequence databases. ETRI J. 2010, 32, 676–686. [Google Scholar] [CrossRef]
- Yin, J.; Zheng, Z.; Cao, L. USpan: An efficient algorithm for mining high utility sequential patterns. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 660–668. [Google Scholar]
- Aggarwal, C.C.; Han, J. Frequent Pattern Mining; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Fournier-Viger, P.; Lin, J.C.W.; Vo, B.; Chi, T.T.; Zhang, J.; Le, H.B. A survey of itemset mining. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2017, 7, e1207. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th Int. Conf. Very Large Data Bases, VLDB, Santiago de Chile, Chile, 12–15 September 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Agrawal, R.; Srikant, R. Mining sequential patterns. In Proceedings of the Eleventh International Conference on Data Engineering, Taipei, Taiwan, 6–10 March 1995; pp. 3–14. [Google Scholar]
- Wang, J.Z.; Huang, J.L.; Chen, Y.C. On efficiently mining high utility sequential patterns. Knowl. Inf. Syst. 2016, 49, 597–627. [Google Scholar] [CrossRef]
- BUFFETT, S. Candidate List Maintenance in High Utility Sequential Pattern Mining. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), IEEE, Seattle, WA, USA, 10–13 December 2018; pp. 644–652. [Google Scholar]
- Hájek, P.; Havel, I.; Chytil, M. The GUHA method of automatic hypotheses determination. Computing 1966, 1, 293–308. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Yin, Y.; Mao, R. Mining frequent patterns without candidate generation: A frequent-pattern tree approach. Data Min. Knowl. Discov. 2004, 8, 53–87. [Google Scholar] [CrossRef]
- Zaki, M.J. Scalable algorithms for association mining. IEEE Trans. Knowl. Data Eng. 2000, 12, 372–390. [Google Scholar] [CrossRef] [Green Version]
- Srikant, R.; Agrawal, R. Mining Sequential Patterns: Generalizations and Performance Improvements; Springer: Berlin/Heidelberg, Germany, 1996. [Google Scholar]
- Zaki, M.J. SPADE: An efficient algorithm for mining frequent sequences. Mach. Learn. 2001, 42, 31–60. [Google Scholar] [CrossRef] [Green Version]
- Ayres, J.; Flannick, J.; Gehrke, J.; Yiu, T. Sequential pattern mining using a bitmap representation. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 429–435. [Google Scholar]
- Pei, J.; Han, J.; Mortazavi-Asl, B.; Pinto, H.; Chen, Q.; Dayal, U.; Hsu, M.C. Prefixspan: Mining sequential patterns efficiently by prefix-projected pattern growth. In Proceedings of the 2013 IEEE 29th International Conference on Data Engineering (ICDE), Heidelberg, Germany, 2–6 April 2001; p. 0215. [Google Scholar]
- Yao, H.; Hamilton, H.J.; Butz, C.J. A foundational approach to mining itemset utilities from databases. In Proceedings of the 2004 SIAM International Conference on Data Mining, Lake Buena Vista, FL, USA, 22–24 April 2004; pp. 482–486. [Google Scholar]
- Liu, Y.; Liao, W.K.; Choudhary, A.N. A Two-Phase Algorithm for Fast Discovery of High Utility Itemsets. In PAKDD; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3518, pp. 689–695. [Google Scholar]
- Fournier-Viger, P.; Wu, C.W.; Zida, S.; Tseng, V.S. FHM: Faster high-utility itemset mining using estimated utility co-occurrence pruning. In International Symposium on Methodologies for Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2014; pp. 83–92. [Google Scholar]
- Fournier-Viger, P.; Wu, C.W.; Tseng, V.S. Novel concise representations of high utility itemsets using generator patterns. In International Conference on Advanced Data Mining and Applications; Springer: Berlin/Heidelberg, Germany, 2014; pp. 30–43. [Google Scholar]
- Tseng, V.S.; Wu, C.W.; Fournier-Viger, P.; Philip, S.Y. Efficient algorithms for mining top-k high utility itemsets. IEEE Trans. Knowl. Data Eng. 2015, 28, 54–67. [Google Scholar] [CrossRef]
- Lin, J.C.W.; Li, T.; Fournier-Viger, P.; Hong, T.P.; Zhan, J.; Voznak, M. An efficient algorithm to mine high average-utility itemsets. Adv. Eng. Inform. 2016, 30, 233–243. [Google Scholar] [CrossRef]
- Lin, J.C.W.; Zhang, J.; Fournier-Viger, P. High-Utility Sequential Pattern Mining with Multiple Minimum Utility Thresholds. In Asia-Pacific Web (APWeb) and Web-Age Information Management (WAIM) Joint Conference on Web and Big Data; Springer: Berlin/Heidelberg, Germany, 2017; pp. 215–229. [Google Scholar]
- Liu, B.; Hsu, W.; Ma, Y. Mining association rules with multiple minimum supports. In Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; Volume 99, pp. 337–341. [Google Scholar]
- Zhang, B.; Lin, J.C.W.; Fournier-Viger, P.; Li, T. Mining of high utility-probability sequential patterns from uncertain databases. PLoS ONE 2017, 12, e0180931. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zihayat, M.; Wu, C.W.; An, A.; Tseng, V.S. Mining high utility sequential patterns from evolving data streams. In Proceedings of the ASE BigData & SocialInformatics 2015, Kaohsiung, Taiwan, 7–9 October 2015; p. 52. [Google Scholar]
- Xu, T.; Dong, X.; Xu, J.; Dong, X. Mining High Utility Sequential Patterns with Negative Item Values. Int. J. Pattern Recognit. Artif. Intell. 2017, 31, 1750035. [Google Scholar] [CrossRef]
- Zida, S.; Fournier-Viger, P.; Wu, C.W.; Lin, J.C.W.; Tseng, V.S. Efficient mining of high-utility sequential rules. In International Workshop on Machine Learning and Data Mining in Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2015; pp. 157–171. [Google Scholar]
- Jiang, Y.; Yin, S.; Kaynak, O. Data-driven monitoring and safety control of industrial cyber-physical systems: Basics and beyond. IEEE Access 2018, 6, 47374–47384. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, K.; Yin, S. Cyber-physical system based factory monitoring and fault diagnosis framework with plant-wide performance optimization. In Proceedings of the 2018 IEEE Industrial Cyber-Physical Systems (ICPS), St. Petersburg, Russia, 15–18 May 2018; pp. 240–245. [Google Scholar]
- Jiang, Y.; Yin, S. Recent advances in key-performance-indicator oriented prognosis and diagnosis with a matlab toolbox: Db-kit. IEEE Trans. Ind. Inform. 2018, 15, 2849–2858. [Google Scholar] [CrossRef]
- Mooney, C.H.; Roddick, J.F. Sequential pattern mining–approaches and algorithms. ACM Comput. Surv. (CSUR) 2013, 45, 19. [Google Scholar] [CrossRef]
- Chena, Y.L.; Kuo, M.H.; Wub, S.Y.; Tang, K. Discovering recency, frequency, and monetary (RFM) sequential patterns from customers’ purchasing data. Electron. Commer. Res. Appl. 2009, 8, 241–251. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, A.; Li, D.; Wang, L. Discovering novel multistage attack strategies. In International Conference on Advanced Data Mining and Applications; Springer: Berlin/Heidelberg, Germany, 2007; pp. 45–56. [Google Scholar]
- Buffett, S.; Pagiatakis, C.; Jiang, D. Pattern-Based Behavioural Analysis on Neurosurgical Simulation Data. Proc. Mach. Learn. Res. 2018, 85, 514–533. [Google Scholar]
- Fournier-Viger, P.; Gomariz, A.; Gueniche, T.; Soltani, A.; Wu, C.; Tseng, V.S. SPMF: A Java Open-Source Pattern Mining Library. J. Mach. Learn. Res. (JMLR) 2014, 15, 3389–3393. [Google Scholar]
- Lichman, M. UCI Machine Learning Repository. 2013. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 11 January 2020).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Total Util | # Seq | # Items | Avg Length | Type |
|---|---|---|---|---|---|
| BMS | 59,601 | 497 | 2.5 | click-stream | |
| ds3 | 59,476 | 811 | 5.9 | transactions | |
| msnbc | 989,818 | 17 | 4.74 | page visits | |
| SIGN | 730 | 267 | 52.0 | sign language |
| Dataset | Total Util | # Seq | # Items | Avg Length | Type |
|---|---|---|---|---|---|
| FIFA | 20,450 | 2990 | 36.24 | click-stream | |
| Kosarak10K | 10,000 | 10,094 | 8.14 | click-stream |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buffett, S. Dramatically Reducing Search for High Utility Sequential Patterns by Maintaining Candidate Lists. Information 2020, 11, 44. https://doi.org/10.3390/info11010044
Buffett S. Dramatically Reducing Search for High Utility Sequential Patterns by Maintaining Candidate Lists. Information. 2020; 11(1):44. https://doi.org/10.3390/info11010044
Chicago/Turabian StyleBuffett, Scott. 2020. "Dramatically Reducing Search for High Utility Sequential Patterns by Maintaining Candidate Lists" Information 11, no. 1: 44. https://doi.org/10.3390/info11010044
APA StyleBuffett, S. (2020). Dramatically Reducing Search for High Utility Sequential Patterns by Maintaining Candidate Lists. Information, 11(1), 44. https://doi.org/10.3390/info11010044