MANNWARE: A Malware Classification Approach with a Few Samples Using a Memory Augmented Neural Network


Abstract
:1. Introduction
2. Meta-Learning with Neural Turing Machine in One-Shot Learning Tasks
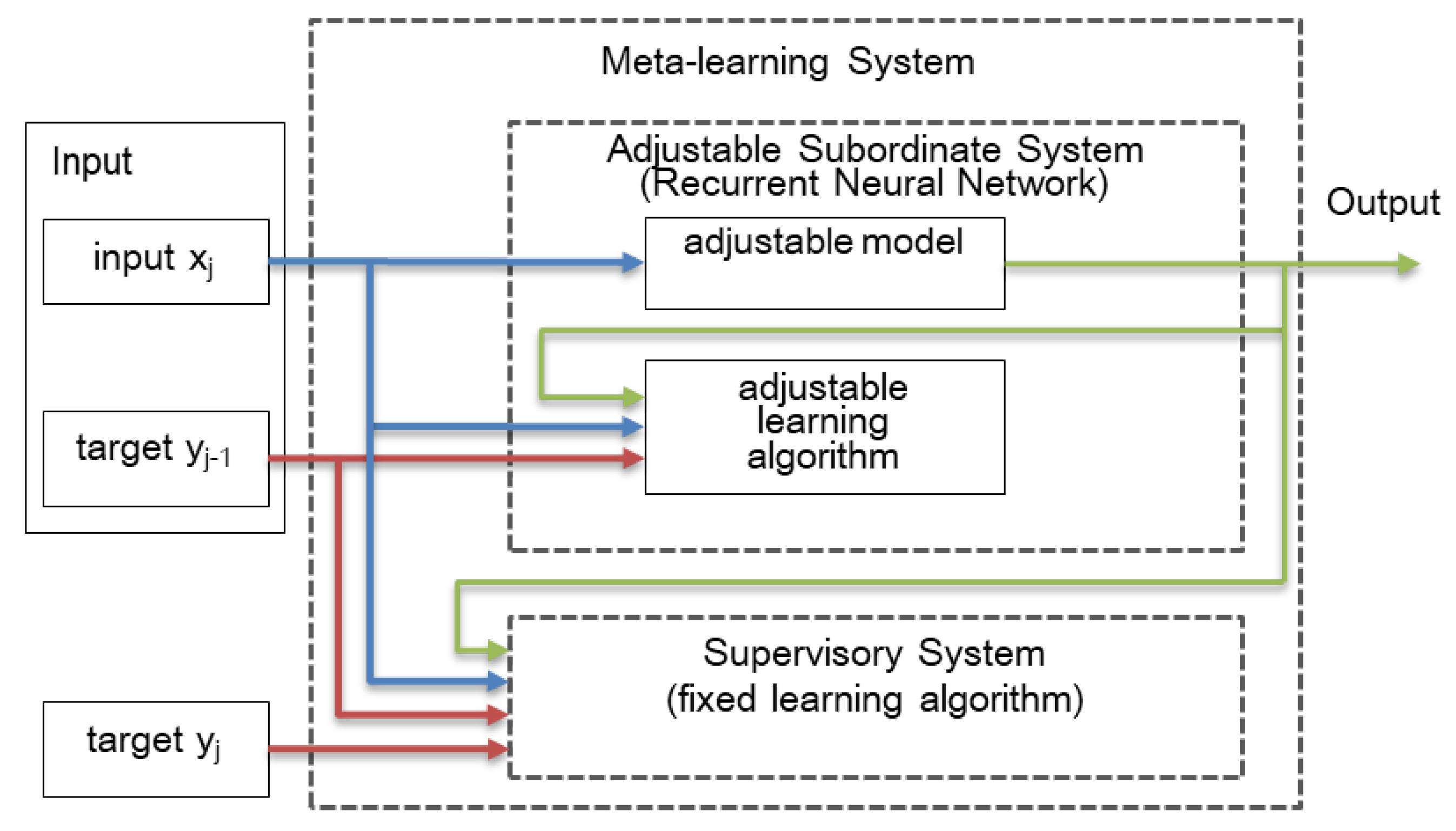
2.1. Meta-Learning
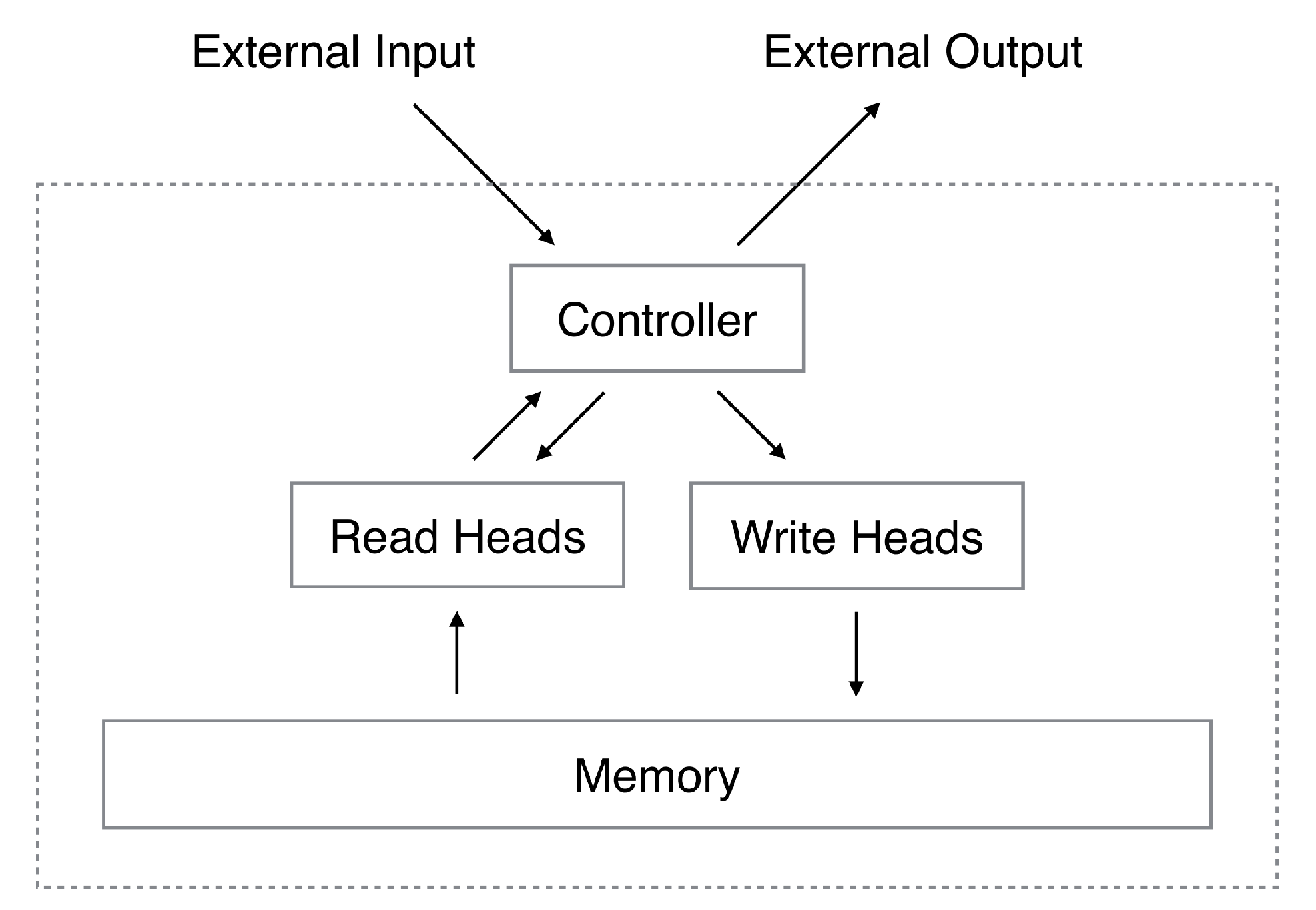
2.2. Meta-Learning with Memory Augmented Neural Network
3. Related Works
3.1. Anomally Detection
3.2. Domain Adaptation
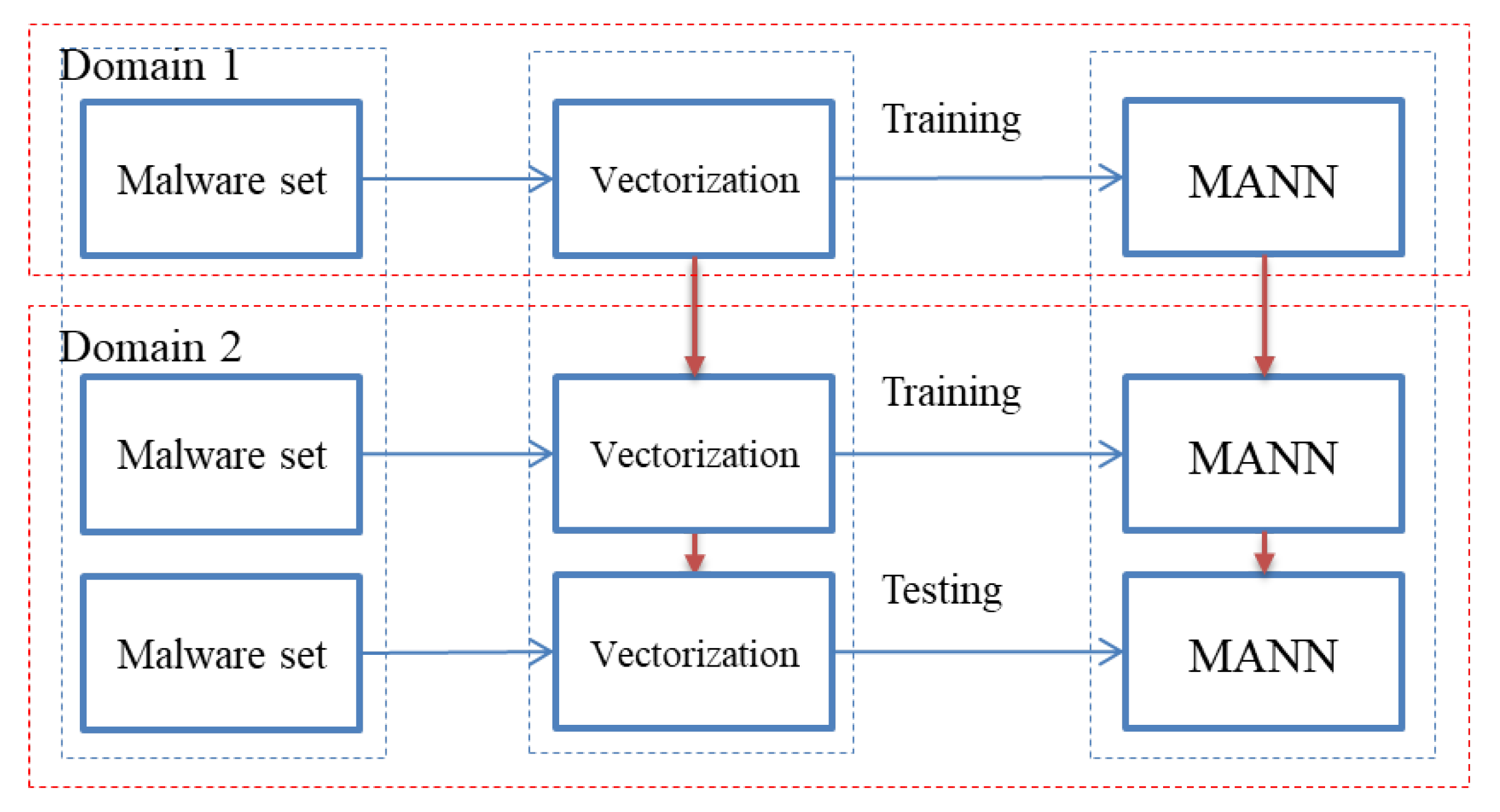
4. Proposed Method
4.1. Collect Malware’s Behavior Characteristics
4.2. Extract Feature
4.3. Vectorize Feature
4.4. Train the Memory Augmented Neural Network
4.5. Adapt Trained Network to the New Domain
5. Experiments
5.1. Hyper Parameters
- N-gram: The number of API calls are used to create a new n-gram API.
- Min-count: A threshold such that all n-gram APIs with total frequency in a malware’s API sequence lower than it will be ignored.
- Window-size: Maximum distance between the current and predicted word within a sentence.
- Vector-size: Dimensionality of the malware vectors.
- Word2vec model: A selection between two models of word2vec model, skip-gram or CBOW model.
5.2. Case 1: FFRI 2017 Dataset
5.2.1. Training of the Model in Domain 1
5.2.2. Classification of the Unknown Ransomware in Domain 2
5.3. Case 2: API-Based Malware Detection System Dataset
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kaspersky. Kaspersky Lab Report. Available online: https://www.kaspersky.com/about/press-release/2017kaspersky-lab-detects-360000-new-malicious-files-daily (accessed on 10 November 2019).
- Symantec Corporation. ISTR-Internet Security Threat Report. February 2019; Volume 24. Available online: https://www.symantec.com/content/dam/symantec/docs/reports/istr-24-2019-en.pdf (accessed on 18 August 2019).
- Li, F.-F.; Fergus, R.; Perona, P. One-shot learning of object categories. IEEE Trans. Partern Anal. Mach. Intell. 2006, 28, 594–611. [Google Scholar]
- Lake, B.M.; Salakhutdinov, R.; Tenenbaum, J.B. Human-level concept learning through probabilistic program induction. Science 2015, 350, 1332–1338. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Salakhutdinov, R.; Tenenbaum, J.B.; Torralba, A. One-shot learning with a hierarchical nonparametric bayesian model. J. Mach. Learn. Res. Proc. Track. 2012, 27, 195–207. [Google Scholar]
- Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; Lillicrap, T. Meta-learning with memory-augmented neural networks. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1842–1850. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching networks for one shot learning. arXiv 2016, arXiv:1606.04080, 3630–3638. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. Deep Learning Workshop (ICML), Lille Metropole, France, 10–11 July 2015. Available online: https://sites.google.com/site/deeplearning2015/accepted-papers (accessed on 6 January 2020).
- Tran, T.K.; Sato, H.; Kubo, M. One-shot Learning Approach for Unknown Malware Classification. In Proceedings of the 2018 5th Asian Conference on Defense Technology (ACDT), Hanoi, Vietnam, 25–27 October 2018; pp. 8–13. [Google Scholar] [CrossRef]
- FFRI Company. Introduction to FFRI 2017 Dataset. Available online: https://www.iwsec.org/mws/2017/20170606/FFRI_Dataset_2017.pdf (accessed on 18 August 2018). (In Japanese).
- Kim, H.K. API-Based Malware Detection System Dataset. Available online: http://ocslab.hksecurity.net/apimds-dataset (accessed on 18 August 2017).
- Brazdil, P.; Vilalta, R.; Giraud-Carrier, C.; Soares, C. Metalearning. In Encyclopedia of Machine Learning and Data Mining; Sammut, C., Webb, G.I., Eds.; Springer: New York, NY, USA, 2017; pp. 818–823. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1126–1135. [Google Scholar]
- Hochreiter, S.; Younger, A.S.; Conwell, P.R. Learning to learn using gradient descent. In Proceedings of the International Conference on Artificial Neural Networks (ICANN 2001), Vienna, Austria, 21–25 August 2001; pp. 87–94. [Google Scholar]
- Graves, A.; Wayne, G.; Danihelka, I. Neural turing machines. arXiv 2014, arXiv:1410.5401. [Google Scholar]
- Daniel, S. Neural Turing Machines: Perils and Promise. Machine Learning Conference 2016. Available online: https://mlconf.com/sessions/neural-turing-machines-are-a-landmark-architecture/ (accessed on 8 December 2019).
- Graves, A.; Wayne, G.; Reynolds, M.; Harley, T.; Danihelka, I.; Grabska-Barwińska, A.; Colmenarejo, S.G.; Grefenstette, E.; Ramalho, T.; Agapiou, J.; et al. Hybrid computing using a neural network with dynamic external memory. Nature 2016, 538, 471–476. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Wayne, G.; Graves, A.; Lillicrap, T. The Kanerva Machine: A Generative Distributed Memory. arXiv 2018, arXiv:1804.01756. [Google Scholar]
- Teng, H.S.; Chen, K.; Lu, S.C. Adaptive real-time anomaly detection using inductively generated sequential patterns. In Proceedings of the 1990 IEEE Computer Society Symposium on Research in Security and Privacy, Oakland, CA, USA, 7–9 May 1990; pp. 278–284. [Google Scholar]
- Garcia-Teodoro, P.; Diaz-Verdejo, J.; Macia-Fernandez, G.; Vazquez, E. Anomaly-based network intrusion detection:Techniques, systems and challenges. Comput. Secur. 2009, 28, 18–28. [Google Scholar] [CrossRef]
- Burnaev, E.; Smolyakov, D. One-Class SVM with Privileged Information and Its Application to Malware Detection. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 273–280. [Google Scholar] [CrossRef] [Green Version]
- Idika, N.C.; Mathur, A.P. A Survey of Malware Detection Techniques. 2007. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.75.4594&rep=rep1&type=pdf (accessed on 6 January 2020).
- Stefano, C.; Sansone, C.; Vento, M. To reject or not to reject: that is the question–an answer in case of neural classifiers. IEEE Trans. Syst. Manag. Cybern. 2000, 30, 84–94. [Google Scholar] [CrossRef]
- Barbara, D.; Couto, J.; Jajodia, S.; Wu, N. Detecting novel network intrusions using bayes estimators. In Proceedings of the First SIAM International Conference on Data Mining, Chicago, IL, USA, 5–7 April 2001; pp. 1–17. [Google Scholar]
- Vilalta, R.; Giraud-Carrier, C.; Brazdil, P.; Soares, C. Inductive Transfer. In Encyclopedia of Machine Learning and Data Mining; Sammut, C., Webb, G.I., Eds.; Springer: New York, NY, USA, 2017; pp. 666–671. [Google Scholar]
- Kruczkowski, M.; Szynkiewicz, E.N. Support vector machine for malware analysis and classification, Web Intelligence (WI) and Intelligent Agent Technologies (IAT). IEEE Comput. Soc. 2014, 2, 415–420. [Google Scholar]
- Ahmadi, M.; Giacinto, G.; Ulyanov, D.; Semenov, S.; Trofimov, M. Novel feature extraction, selection and fusion for effective malware family classification. In Proceedings of the Sixth ACM Conference on Data and Application Security and Privacy (CODASPY), New Orleans, LA, USA, 9–11 March 2016; pp. 183–194. [Google Scholar]
- MicroSoft Github Source Code. Available online: https://github.com/microsoft/Detours (accessed on 8 December 2019).
- Christoph Husse, H.; Justin, S. Easy Hook Source Code. Available online: https://easyhook.github.io/ (accessed on 8 December 2019).
- Guo, S.; Yuan, Q.; Lin, F.; Wang, F.; Ban, T. A malware detection algorithm based on multi-view fusion. In Proceedings of the 17th International Conference on Neural Information Processing: Models and Applications, Sydney, Australia, 22–25 November 2010; pp. 259–266. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Chung, J.; Caglar, G.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Rafal, J.; Wojciech, Z.; Ilya, S. An empirical exploration of recurrent network architectures. In Proceedings of the 32nd International Conference on Machine Learning (ICML-15), Lille, France, 6–11 July 2015; pp. 2342–2350. [Google Scholar]
- Malicia, P. Available online: http://malicia-project.com/dataset.html (accessed on 6 January 2020).
- Virus Total. Available online: https://virustotal.com (accessed on 6 January 2020).
- Ki, Y.; Kim, E.; Kang, K.H. A novel approach to detect malware based on API call sequence analysis. Int. J. Distrib. Sens. Netw. 2015, 11, 659101. Available online: https://journals.sagepub.com/doi/full/10.1155/2015/659101 (accessed on 6 January 2020). [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Families | Number of Samples |
|---|---|
| trojan-ransom.win32.shade | 21 |
| trojan-ransom.win32.foreign | 23 |
| trojan-ransom.win32.crusis | 27 |
| trojan-ransom.win32.locky | 41 |
| trojan-ransom.win32.spora | 50 |
| trojan-ransom.win32.sagecrypt | 60 |
| trojan-ransom.win32.genericcryptor | 95 |
| trojan-ransom.win32.blocker | 555 |
| trojan-ransom.win32.zerber | 702 |
| Model | Vector Size | Window Size | Min-Count | n-Gram | 6th | 10th |
|---|---|---|---|---|---|---|
| Skip-gram | 50 | 5 | 2 | 1 | 69.58 | 71.99 |
| Skip-gram | 200 | 4 | 1 | 1 | 64.5 | 67.05 |
| CBOW | 50 | 5 | 2 | 2 | 58.18 | 61.35 |
| CBOW | 100 | 5 | 1 | 1 | 55.94 | 58.91 |
| CBOW | 250 | 5 | 1 | 1 | 55.37 | 58.63 |
| Controller | 1st | 2nd | 3rd | 4th | 6th | 10th |
|---|---|---|---|---|---|---|
| LSTM | 20.03 | 53.86 | 64.41 | 65.75 | 69.58 | 71.99 |
| GRU | 28.5 | 51.62 | 58.4 | 62.36 | 66.38 | 68.44 |
| Model | Controller | 6th | 10th |
|---|---|---|---|
| MANN | LSTM | 69.58 | 71.99 |
| MANN | GRU | 66.38 | 68.44 |
| LSTM | - | 52.17 | 52.86 |
| GRU | - | 51.78 | 53.27 |
| SVM | - | 52.56 | 60.51 |
| KNN (K = 4) | - | 25.63 | 32.76 |
| MLP | - | 52.49 | 60.97 |
| RF | - | 45.06 | 51.82 |
| Model | Controller | 1st | 2nd | 6th | 10th |
|---|---|---|---|---|---|
| MANN | LSTM | 41.16 | 83.36 | 89.78 | 90.59 |
| MANN | GRU | 40.53 | 84.59 | 90.88 | 91.77 |
| LSTM | - | 40.28 | 81.63 | 86.58 | 87.08 |
| GRU | - | 39.99 | 81.01 | 86.10 | 86.63 |
| SVM | - | 82.88 | 83.32 | 83.51 | 84.22 |
| KNN (K = 4) | - | 80.02 | 80.69 | 80.51 | 81.53 |
| MLP | - | 85.10 | 84.93 | 84.98 | 85.21 |
| RF | - | 80.40 | 81.96 | 81.56 | 82.52 |
| Category | Subcategory | Ratio (%) |
|---|---|---|
| Backdoor | - | 3.37 |
| Worm | Worm | 3.32 |
| Email-Worm | 0.55 | |
| Net-Worm | 0.79 | |
| P2P-Worm | 0.3 | |
| Packed | - | 5.57 |
| PUP | Adware | 13.63 |
| Downloader | 2.94 | |
| WebToolbar | 1.22 | |
| Trojan | Trojan (Generic) | 29.3 |
| Trojan-Banker | 0.14 | |
| Trojan-Clicker | 0.12 | |
| Trojan-Downloader | 2.29 | |
| Trojan-Dropper | 1.91 | |
| Trojan-FakeAV | 18.8 | |
| Trojan-GameThief | 0.63 | |
| Trojan-PSW | 3.79 | |
| Trojan-Ransomware | 2.58 | |
| Trojan-Spy | 3.12 | |
| Misc. | - | 5.52 |
| Families | Samples |
|---|---|
| trojan-ransom.win32.blocker | 18 |
| trojan-ransom.win32.mbro | 84 |
| trojan-ransom.win32.agent | 93 |
| trojan-ransom.win32.pornoasset | 90 |
| trojan-ransom.win32.foreign | 145 |
| Model | Vector Size | Window Size | Min-Count | n-Gram | 6th | 10th |
|---|---|---|---|---|---|---|
| CBOW | 250 | 5 | 1 | 1 | 75.66 | 78.85 |
| Skip-gram | 50 | 5 | 2 | 1 | 64.86 | 69.66 |
| Skip-gram | 200 | 4 | 1 | 1 | 68.0 | 7268 |
| CBOW | 50 | 5 | 2 | 2 | 55.51 | 60.61 |
| CBOW | 100 | 5 | 1 | 1 | 73.44 | 77.47 |
| Controller | 1st | 2nd | 3rd | 4th | 6th | 10th |
|---|---|---|---|---|---|---|
| LSTM | 16.61 | 53.20 | 64.77 | 70.24 | 75.66 | 78.85 |
| GRU | 13.70 | 54.51 | 66.55 | 71.74 | 75.53 | 77.21 |
| Model | Controller | 6th | 10th |
|---|---|---|---|
| MANN | LSTM | 75.66 | 78.85 |
| MANN | GRU | 75.53 | 77.21 |
| LSTM | - | 59.90 | 62.54 |
| GRU | - | 65.41 | 68.65 |
| SVM | - | 41.26 | 51.58 |
| KNN (K = 4) | - | 19.57 | 28.65 |
| MLP | - | 49.2 | 52.81 |
| RF | - | 39.79 | 45.91 |
| Model | Controller | 1st | 2nd | 6th | 10th |
|---|---|---|---|---|---|
| MANN | LSTM | 32.46 | 75.92 | 88.98 | 89.59 |
| MANN | GRU | 34.02 | 80.55 | 88.3 | 88.73 |
| LSTM | - | 33.38 | 77.19 | 80.45 | 80.62 |
| GRU | - | 33.68 | 80.19 | 83.29 | 83.64 |
| SVM | - | 78.3 | 78.5 | 78.09 | 79.56 |
| KNN (K = 4) | - | 54.4 | 55.0 | 56.02 | 57.41 |
| MLP | - | 78.24 | 78.87 | 78.58 | 78.85 |
| RF | - | 71.72 | 70.39 | 70.98 | 73.27 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, K.; Sato, H.; Kubo, M. MANNWARE: A Malware Classification Approach with a Few Samples Using a Memory Augmented Neural Network. Information 2020, 11, 51. https://doi.org/10.3390/info11010051
Tran K, Sato H, Kubo M. MANNWARE: A Malware Classification Approach with a Few Samples Using a Memory Augmented Neural Network. Information. 2020; 11(1):51. https://doi.org/10.3390/info11010051
Chicago/Turabian StyleTran, Kien, Hiroshi Sato, and Masao Kubo. 2020. "MANNWARE: A Malware Classification Approach with a Few Samples Using a Memory Augmented Neural Network" Information 11, no. 1: 51. https://doi.org/10.3390/info11010051
APA StyleTran, K., Sato, H., & Kubo, M. (2020). MANNWARE: A Malware Classification Approach with a Few Samples Using a Memory Augmented Neural Network. Information, 11(1), 51. https://doi.org/10.3390/info11010051