A Flexible IoT Stream Processing Architecture Based on Microservices



Abstract
:1. Introduction
1.1. Motivations
1.2. Challenges
- IoT application often requires real-time stream processing at two different levels: at edge level and at core/cloud level. Both approaches offer different benefits but the great difference in available resources (processing power, energy consumption, scalability factor, etc) at edge level and core level imposes quite different requirements that affect the choice of the stream processing engines.
- Due to the point we previously mentioned, different stream processing engines have been introduced in existing IoT platform. A single stream processing technology rarely covers both edge-level and cloud-level requirements.
- Having different stream processing engines means having different processing models and languages that must be handled for implementing stream processing rules.
- Real-time IoT stream processing rules are typically based on a dynamic lifecycle. For instance, real-time stream processing services can be executed on demand and then removed after a while or they can behave as long-running functionalities that are never modified (e.g., a remote monitoring process).
- It is often required to deploy rules directly on edge devices for reducing the response latency time or applying some pre-filtering operations. However, when the workload increases, it would be desirable to provide some degree of scalability for instance by dynamically reallocating the considered filters on a different stream processing engine.
1.3. Contributions
- We introduce the notion of -service, a stream processing unit that can be indifferently allocated on the edge- and core-level.
- To implement the different roles of -services, we propose a Reference Architecture based on Proxy, Adapter and Data Processing -services for dealing with real-time stream processing in a very flexible way.
- To abstract away from the underlying stream processing engine and IoT layer (edge/cloud) and provide interoperability, portability and compositionality, our service definition languages consists of the following ingredients:
- –
- for facilitating systems interoperability, we define a configuration language based on the JSON format, a widely adopted standard for data exchange messages;
- –
- to ensure portability, we define a rule-based query language that provide basic filter and join operations inspired to existing stream processing query languages;
- –
- to provide compositionality, we define connectors in order to pipeline filters defined in our query language so as to create complex filters on top of simpler ones.
1.4. Plan
2. Preliminary Notions
2.1. The Microservice Architectural Style and Java OSGi
2.2. Java OSGi
2.3. Microservices in OSGi
2.4. The Senseioty Platform
3. A Microservices Architecture for Adaptive Real-Time IoT Stream Processing
3.1. Requirements for Stream Processing Services
3.2. Goals of the Proposed Architecture
- Providing adaptivity, meaning that the stream processing units can be indifferently allocated on the edge or on the core and moved around, making it possible to cover the two different levels of data stream processing—the edge level and the core/cloud level—and exploiting all their different benefits.
- Providing flexibility, allowing a punctual and on-demand deployment of the stream processing units, as the user or the client application/service defines when and where to allocate, start, stop and deallocate the stream processing rules.
- Providing a set of portable and composable rules that can be defined in a standard way and then automatically deployed on different stream processing engines without depending on their own languages and models. The rules can be combined together, in order to apply a sort of stream processing pipeline. The rules are not only dynamically manageable, but composable and engine independent.
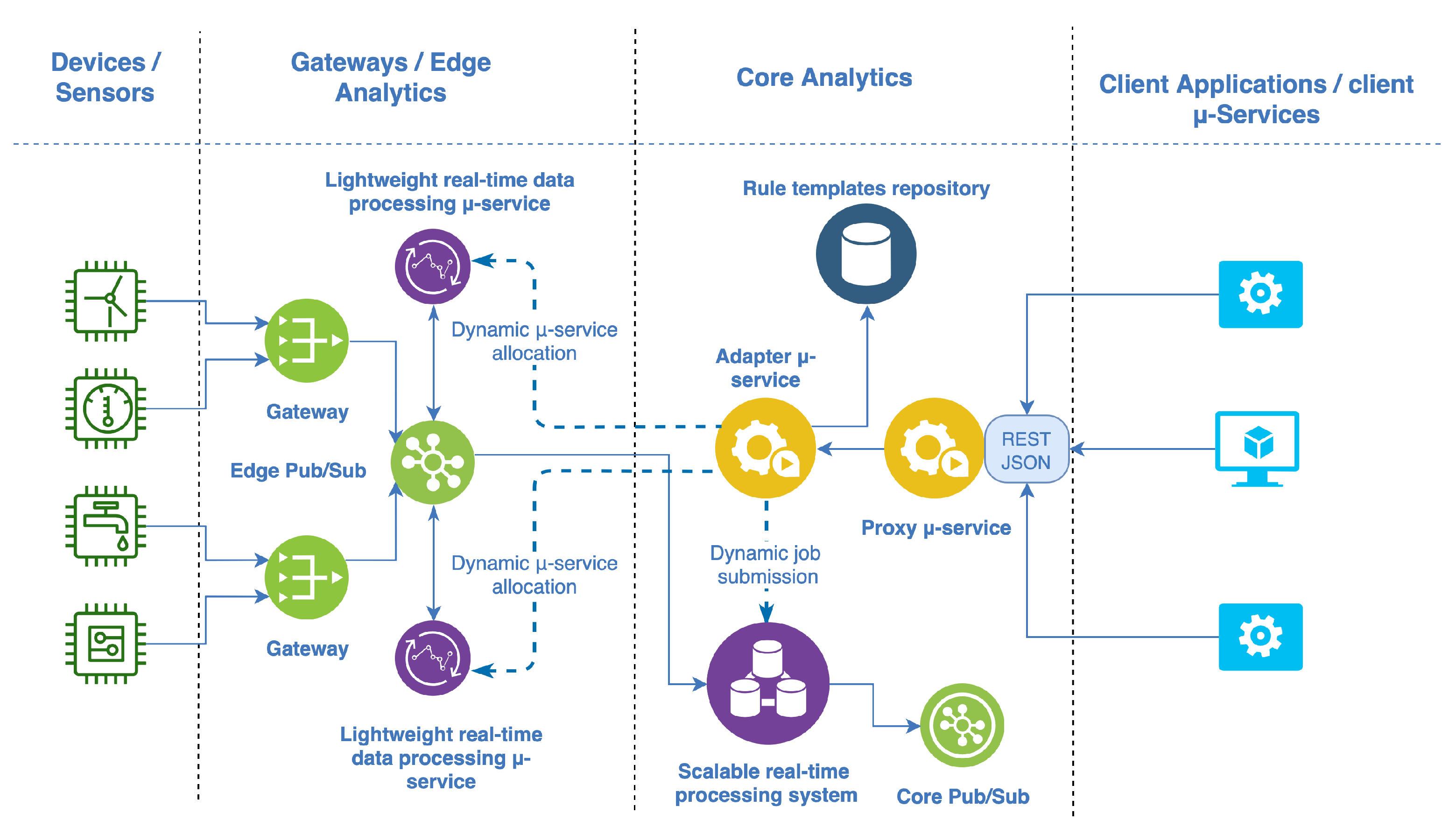
3.3. Reference Architecture
- The proxy -service, which is the entry point of the architecture, offering a RESTful API for installing, uninstalling, starting, stopping, and moving stream processing rules on demand.
- The adapter -service, which is responsible for physically executing the functionalities offered by the proxy -service, interacting with the different stream processing engines available on the edge and on the core of the architecture.
3.3.1. Filter Rule Language
- Filtering query (e.g., SELECT * FROM inputEvents WHERE field > threshold);
- Aggregation query over a window (e.g., SELECT SUM (field) FROM inputEvents [5 s]);
- Joining query between two streams over windows (e.g., SELECT field1 field2 FROM stream1 [1 m] JOIN stream2 [1 m] ON stream1.field3 = stream2.field).
3.3.2. Connectors
3.3.3. Adapters
- A procedure for installing a new rule;
- A procedure for starting/stopping/uninstalling an existing rule;
- A procedure for moving an existing rule from its current runtime to another one.
3.3.4. Application Layer
4. Prototype Implementation
- Exchanges, which are components of the broker responsible for distributing message copies to queues using rules called bindings. There are different exchange types, depending on the binding rules that they apply. This prototype uses only exchanges of the type direct, which delivers messages to queues based on a message routing key included when publishing an event.
- Queues, which are the component that collects the messages coming from exchanges. A consumer reads the events from a queue in order to process the messages.
- inputEndPoint: The URL for connecting to the RabbitMQ broker (it might be different from outputEndPoint).
- inputExchange: The name of the exchange from which the input queue will read the messages. If the exchange does not already exist, it is created automatically.
- inputQueue: The name of the queue that will be bind to the inputExchange. If the queue does not already exist, it is created automatically.
- inputRoutingKey: The routing key that is used for binding the inputExchange to the InputQueue.
- outputEndPoint: The URL for connecting to the RabbitMQ broker.
- outputExchange: The name of the exchange in which the events are published. If the exchange does not already exist, it is created automatically.
- outputRoutingKey: The routing key that is included with the event when publishing it.
5. Related Work
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fowler, M.; Lewis, J. Microservices—A Definition of This New Architectural Term. 2014. Available online: https://martinfowler.com/articles/microservices.html (accessed on 30 November 2020).
- Abbott, M.; Fisher, M. The Art of Scalability: Scalable Web Architecture, Processes, and Organizations for the Modern Enterprise; Addison-Wesley Professional: Boston, MA, USA, 2015. [Google Scholar]
- Robert, M. Agile Software Development: Principles Patterns and Practices; Pearson: London, UK, 2003. [Google Scholar]
- Richardson, C. Building Microservices: Using an API Gateway. 2015. Available online: https://www.nginx.com/blog/introduction-to-microservices/ (accessed on 30 November 2020).
- Richardson, C. Event-Driven Data Management for Microservices. 2015. Available online: https://www.nginx.com/blog/event-driven-data-management-microservices/ (accessed on 30 November 2020).
- Richardson, C. Choosing a Microservices Deployment Strategy. 2016. Available online: https://www.nginx.com/blog/deploying-microservices (accessed on 30 November 2020).
- OSGi Alliance. Available online: https://www.osgi.org (accessed on 30 November 2020).
- OSGi Architecture. Available online: https://www.osgi.org/developer/architecture/ (accessed on 30 November 2020).
- Hall, R.; Pauls, K.; McCulloch, S.; Savage, D. OSGi in Action, Creating Modular Applications in Java; Manning: Hong Kong, China, 2011. [Google Scholar]
- OSGi Service Layer. Available online: https://osgi.org/specification/osgi.core/7.0.0/framework.service.html (accessed on 30 November 2020).
- Remote Services Specification. Available online: https://osgi.org/specification/osgi.cmpn/7.0.0/service.remoteservices.html (accessed on 30 November 2020).
- Apache CXF Distributed OSGi. Available online: https://cxf.apache.org/distributed-osgi.html (accessed on 30 November 2020).
- Apache Zookeeper. Available online: https://zookeeper.apache.org/ (accessed on 30 November 2020).
- Senseioty. Available online: http://senseioty.com/ (accessed on 30 November 2020).
- Apache Karaf. Available online: https://karaf.apache.org/ (accessed on 30 November 2020).
- Arvind, A.B.S.; Jennifer, W. The CQL Continuous Query Language: Semantic Foundations and Query Execution. 2003. Available online: http://ilpubs.stanford.edu:8090/758/1/2003-67.pdf (accessed on 30 November 2020).
- Siddhi Streaming and Complex Event Processing System. Available online: https://siddhi.io/ (accessed on 30 November 2020).
- Bnd Tools. Available online: https://bnd.bndtools.org/ (accessed on 30 November 2020).
- Apache Ignite. Available online: https://ignite.apache.org/ (accessed on 30 November 2020).
- Apache Samza. Available online: http://samza.apache.org/ (accessed on 30 November 2020).
- Apache Flink. Available online: https://flink.apache.org/ (accessed on 30 November 2020).
- Apache Storm. Available online: https://storm.apache.org/ (accessed on 30 November 2020).
- Kafka Streams. Available online: https://kafka.apache.org/documentation/streams/ (accessed on 30 November 2020).
- Apache CXF. Available online: http://cxf.apache.org/ (accessed on 30 November 2020).
- Kubernetes. Available online: https://kubernetes.io/ (accessed on 30 November 2020).
- RabbitMQ. Available online: https://www.rabbitmq.com/ (accessed on 30 November 2020).
- AMQP Protocol. Available online: https://www.amqp.org/ (accessed on 30 November 2020).
- OSGi Event Admin Service. Available online: https://osgi.org/specification/osgi.cmpn/7.0.0/service.event.html (accessed on 30 November 2020).
- Maven. Available online: https://maven.apache.org/ (accessed on 30 November 2020).
- Pax URL. Available online: https://ops4j1.jira.com/wiki/spaces/paxurl/overview (accessed on 30 November 2020).
- Alfian, G.; Ijaz, M.F.; Syafrudin, M.; Syaekhoni, M.A.; Fitriyani, N.L.; Rhee, J. Customer behavior analysis using real-time data processing: A case study of digital signage-based online stores. Asia Pac. J. Mark. Logist. 2019, 31, 265–290. [Google Scholar] [CrossRef]
- Ali, F.; El-Sappagh, S.H.A.; Islam, S.M.R.; Ali, A.; Attique, M.; Imran, M.; Kwak, K. An intelligent healthcare monitoring framework using wearable sensors and social networking data. Future Gener. Comput. Syst. 2021, 114, 23–43. [Google Scholar] [CrossRef]
- Alfian, G.; Syafrudin, M.; Ijaz, M.F.; Syaekhoni, M.A.; Fitriyani, N.L.; Rhee, J. A Personalized Healthcare Monitoring System for Diabetic Patients by Utilizing BLE-Based Sensors and Real-Time Data Processing. Sensors 2018, 18, 2183. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
| URL Method | Request Body | Response Body |
|---|---|---|
| /api/install POST | JSON installation object | JSON jobinfo object |
| /api/uninstall POST | JSON jobinfo object | JSON jobinfo object |
| /api/start POST | JSON jobinfo object | JSON jobinfo object |
| /api/stop POST | JSON jobinfo object | JSON jobinfo object |
| /api/move POST | JSON relocation object | JSON jobinfo object |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bixio, L.; Delzanno, G.; Rebora, S.; Rulli, M. A Flexible IoT Stream Processing Architecture Based on Microservices. Information 2020, 11, 565. https://doi.org/10.3390/info11120565
Bixio L, Delzanno G, Rebora S, Rulli M. A Flexible IoT Stream Processing Architecture Based on Microservices. Information. 2020; 11(12):565. https://doi.org/10.3390/info11120565
Chicago/Turabian StyleBixio, Luca, Giorgio Delzanno, Stefano Rebora, and Matteo Rulli. 2020. "A Flexible IoT Stream Processing Architecture Based on Microservices" Information 11, no. 12: 565. https://doi.org/10.3390/info11120565
APA StyleBixio, L., Delzanno, G., Rebora, S., & Rulli, M. (2020). A Flexible IoT Stream Processing Architecture Based on Microservices. Information, 11(12), 565. https://doi.org/10.3390/info11120565