Crowd Counting Guided by Attention Network


Abstract
:1. Introduction
- The proposed GLANet generates low-quality density by enhancing different spatial semantic features using multi-column attention mechanisms.
- GLANet utilizes the mean structural similarity to obtain connections between different pixels and the local correlation in density maps.
2. Related Work
2.1. Detection-Based
2.2. Regression-Based
2.3. Density-Based
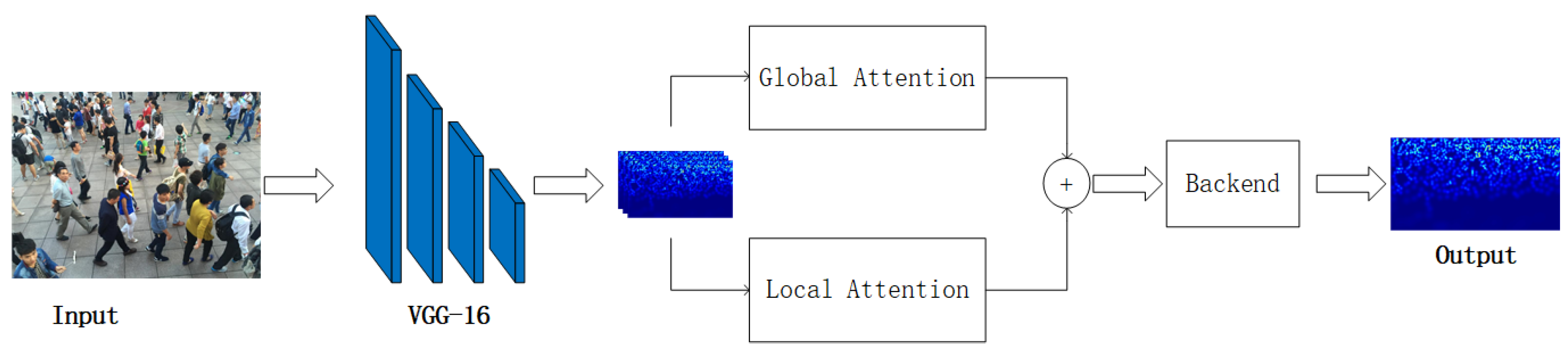
3. Our Approach
3.1. Architecture
3.1.1. Feature Extractor Module
3.1.2. Global and Local Attention Module
3.1.3. Feature Fusing Module
3.2. Density Map Generation
3.3. Loss Function
3.3.1. Euclidean Distance
3.3.2. SSIM Loss
4. Experiments
4.1. Evaluation Metrics
4.2. Dataset
4.2.1. ShanghaiTech
4.2.2. UCF QNRF
4.2.3. UCF-CC 50
4.3. Ablation Study on ShanghaiTech Part A
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Cao, X.; Wang, Z.; Zhao, Y.; Su, F. Scale aggregation network for accurate and efficient crowd counting. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Generating high-quality crowd density maps using contextual pyramid cnns. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1861–1870. [Google Scholar]
- Zhao, M.; Zhang, J.; Zhang, C.; Zhang, W. Leveraging heterogeneous auxiliary tasks to assist crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12736–12745. [Google Scholar]
- Liu, J.; Gao, C.; Meng, D.; Hauptmann, A.G. Decidenet: Counting varying density crowds through attention guided detection and density estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5197–5206. [Google Scholar]
- Zhang, Y.; Zhou, C.; Chang, F.; Kot, A.C.; Zhang, W. Attention to head locations for crowd counting. In Proceedings of the International Conference on Image and Graphics. Springer, Beijing, China, 23–25 August 2019; pp. 727–737. [Google Scholar]
- Onoro-Rubio, D.; López-Sastre, R.J. Towards perspective-free object counting with deep learning. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 615–629. [Google Scholar]
- Shi, M.; Yang, Z.; Xu, C.; Chen, Q. Revisiting perspective information for efficient crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7279–7288. [Google Scholar]
- Zhang, C.; Li, H.; Wang, X.; Yang, X. Cross-scene crowd counting via deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 833–841. [Google Scholar]
- Sam, D.B.; Surya, S.; Babu, R.V. Switching convolutional neural network for crowd counting. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4031–4039. [Google Scholar]
- Abdolrashidi, A.; Minaei, M.; Azimi, E.; Minaee, S. Age and Gender Prediction From Face Images Using Attentional Convolutional Network. arXiv 2020, arXiv:2010.03791. [Google Scholar]
- Li, L.; Tang, S.; Deng, L.; Zhang, Y.; Tian, Q. Image caption with global-local attention. In Proceedings of the Thirty-first AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4133–4139. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, M.; Zhang, Z.; Huang, K.; Tan, T. Estimating the number of people in crowded scenes by mid based foreground segmentation and head-shoulder detection. In Proceedings of the IEEE 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, M.; Wang, X. Automatic adaptation of a generic pedestrian detector to a specific traffic scene. In Proceedings of the IEEE CVPR, Providence, RI, USA, 20–25 June 2011; pp. 3401–3408. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; IEEE: Montreal, QC, Canada, 2015; pp. 91–99. [Google Scholar]
- Paragios, N.; Ramesh, V. A MRF-based approach for real-time subway monitoring. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Regazzoni, C.S.; Tesei, A. Distributed data fusion for real-time crowding estimation. Signal Process. 1996, 53, 47–63. [Google Scholar] [CrossRef]
- Chan, A.B.; Liang, Z.S.J.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–7. [Google Scholar]
- Chan, A.B.; Vasconcelos, N. Counting people with low-level features and Bayesian regression. IEEE Trans. Image Process. 2011, 21, 2160–2177. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, X.; Van De Weijer, J.; Bagdanov, A.D. Leveraging unlabeled data for crowd counting by learning to rank. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7661–7669. [Google Scholar]
- Liu, L.; Wang, H.; Li, G.; Ouyang, W.; Lin, L. Crowd counting using deep recurrent spatial-aware network. arXiv 2018, arXiv:1807.00601. [Google Scholar]
- Li, Y.; Zhang, X.; Chen, D. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1091–1100. [Google Scholar]
- Chen, X.; Bin, Y.; Sang, N.; Gao, C. Scale pyramid network for crowd counting. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1941–1950. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; So Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Advances in Neural Information Processing Systems; NIPS’14: Montreal, QC, Canada, 2014; pp. 2204–2212. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Hou, Y.; Li, C.; Yang, F.; Ma, C.; Zhu, L.; Li, Y.; Jia, H.; Xie, X. BBA-NET: A Bi-Branch Attention Network For Crowd Counting. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 4072–4076. [Google Scholar]
- Guo, D.; Li, K.; Zha, Z.J.; Wang, M. Dadnet: Dilated-attention-deformable convnet for crowd counting. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1823–1832. [Google Scholar]
- Von Borstel, M.; Kandemir, M.; Schmidt, P.; Rao, M.K.; Rajamani, K.; Hamprecht, F.A. Gaussian process density counting from weak supervision. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 365–380. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Cnn-based cascaded multi-task learning of high-level prior and density estimation for crowd counting. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Shi, Z.; Mettes, P.; Snoek, C.G. Counting with focus for free. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4200–4209. [Google Scholar]
- Jiang, S.; Lu, X.; Lei, Y.; Liu, L. Mask-aware networks for crowd counting. IEEE Trans. Circuits Syst. Video Technol. 2019. [Google Scholar] [CrossRef] [Green Version]
- Gao, J.; Wang, Q.; Li, X. PCC Net: Perspective Crowd Counting via Spatial Convolutional Network. IEEE Trans. Circuits Syst. Video Technol. 2019. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Shi, Z.; Zhang, L.; Liu, Y.; Cao, X.; Ye, Y.; Cheng, M.-M.; Zheng, G. Crowd counting with deep negative correlation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5382–5390. [Google Scholar]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source multi-scale counting in extremely dense crowd images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2547–2554. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Detection-Base | Regression-Base | Density-Base | |
|---|---|---|---|
| distribution | √ | × | √ |
| overlap | × | √ | √ |
| ShanghaiTech Part A | ShanghaiTech Part B | UCF_CC_50 | UCF-QNRF | |||||
|---|---|---|---|---|---|---|---|---|
| Model | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE |
| MCNN [2] | 110.2 | 173.2 | 26.4 | 41.3 | 377.6 | 509.1 | 277 | 426 |
| Switch-CNN [11] | 90.4 | 135 | 21.6 | 33.4 | 318.1 | 439.2 | 228 | 445 |
| CP-CNN [4] | 73.6 | 106.4 | 20.1 | 30.1 | 295.8 | 320.9 | 295.8 | 320 |
| SANet [3] | 67 | 104.5 | 8.4 | 13.6 | 258.4 | 334.9 | - | - |
| CSRNet [25] | 68.2 | 115 | 10.6 | 115 | 266.1 | 397.5 | 148 | 234 |
| DadNet [33] | 64.2 | 99.9 | 8.8 | 13.5 | 285.5 | 389.7 | - | - |
| D-ConvNet [40] | 73.5 | 112.3 | 18.7 | 26 | 288.4 | 404.7 | - | - |
| Ours | 63.9 | 104.2 | 8.3 | 13 | 254.6 | 330 | 123.8 | 243 |
| MAE | MSE | |
|---|---|---|
| FEM + FFM | 69.7 | 119 |
| Ours | 63.9 | 104.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nie, P.; Fan, C.; Zou, L.; Chen, L.; Li, X. Crowd Counting Guided by Attention Network. Information 2020, 11, 567. https://doi.org/10.3390/info11120567
Nie P, Fan C, Zou L, Chen L, Li X. Crowd Counting Guided by Attention Network. Information. 2020; 11(12):567. https://doi.org/10.3390/info11120567
Chicago/Turabian StyleNie, Pei, Cien Fan, Lian Zou, Liqiong Chen, and Xiaopeng Li. 2020. "Crowd Counting Guided by Attention Network" Information 11, no. 12: 567. https://doi.org/10.3390/info11120567
APA StyleNie, P., Fan, C., Zou, L., Chen, L., & Li, X. (2020). Crowd Counting Guided by Attention Network. Information, 11(12), 567. https://doi.org/10.3390/info11120567