Outpatient Text Classification Using Attention-Based Bidirectional LSTM for Robot-Assisted Servicing in Hospital


Abstract
:1. Introduction
- Collecting asked questions and response text in hospitals into a database.
- Creating an attention-based bidirectional long-short term memory (LSTM) model for outpatient classification.
- Integrating the classification module into the robot system of a service robot.
2. Related Work
2.1. Machine Learning-Based Model
2.2. Deep Learning-Based Model
3. Material
3.1. Robot Hardware
3.2. Robot System
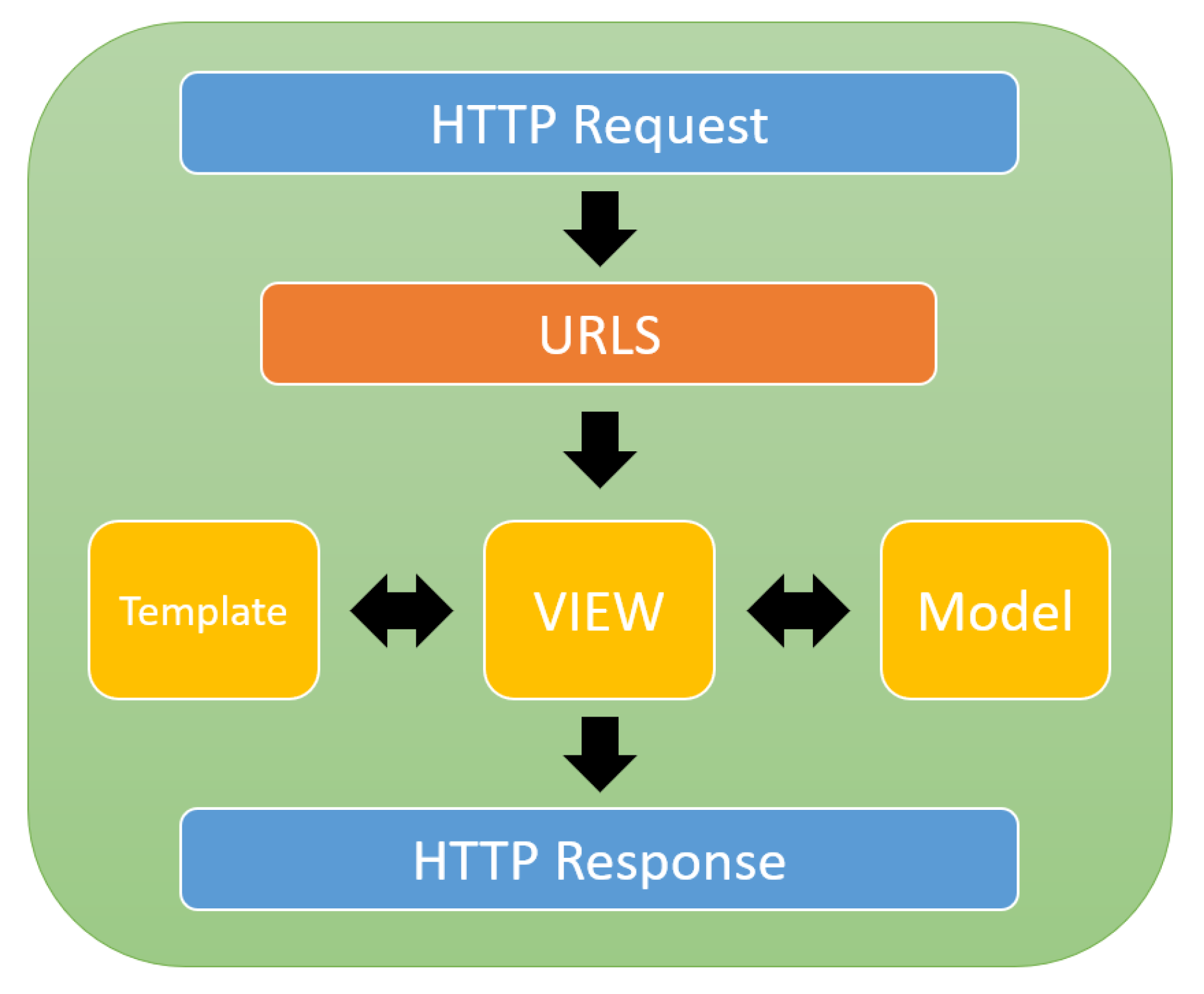
3.3. Web Server
3.4. Experimental Environment
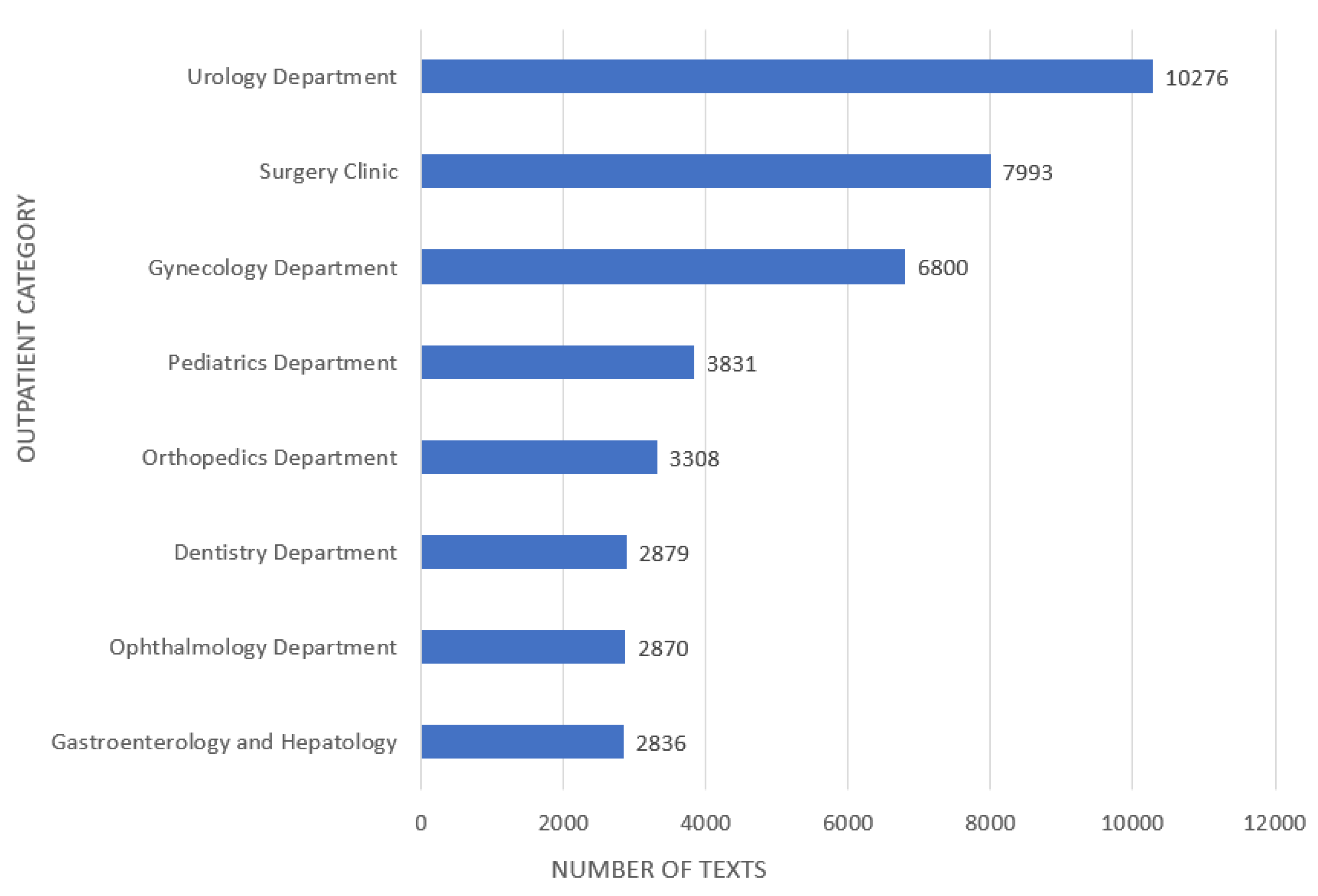
3.5. Dataset
4. Methodology
4.1. Pre-Processing
4.1.1. Segmentation
4.1.2. TF–IDF
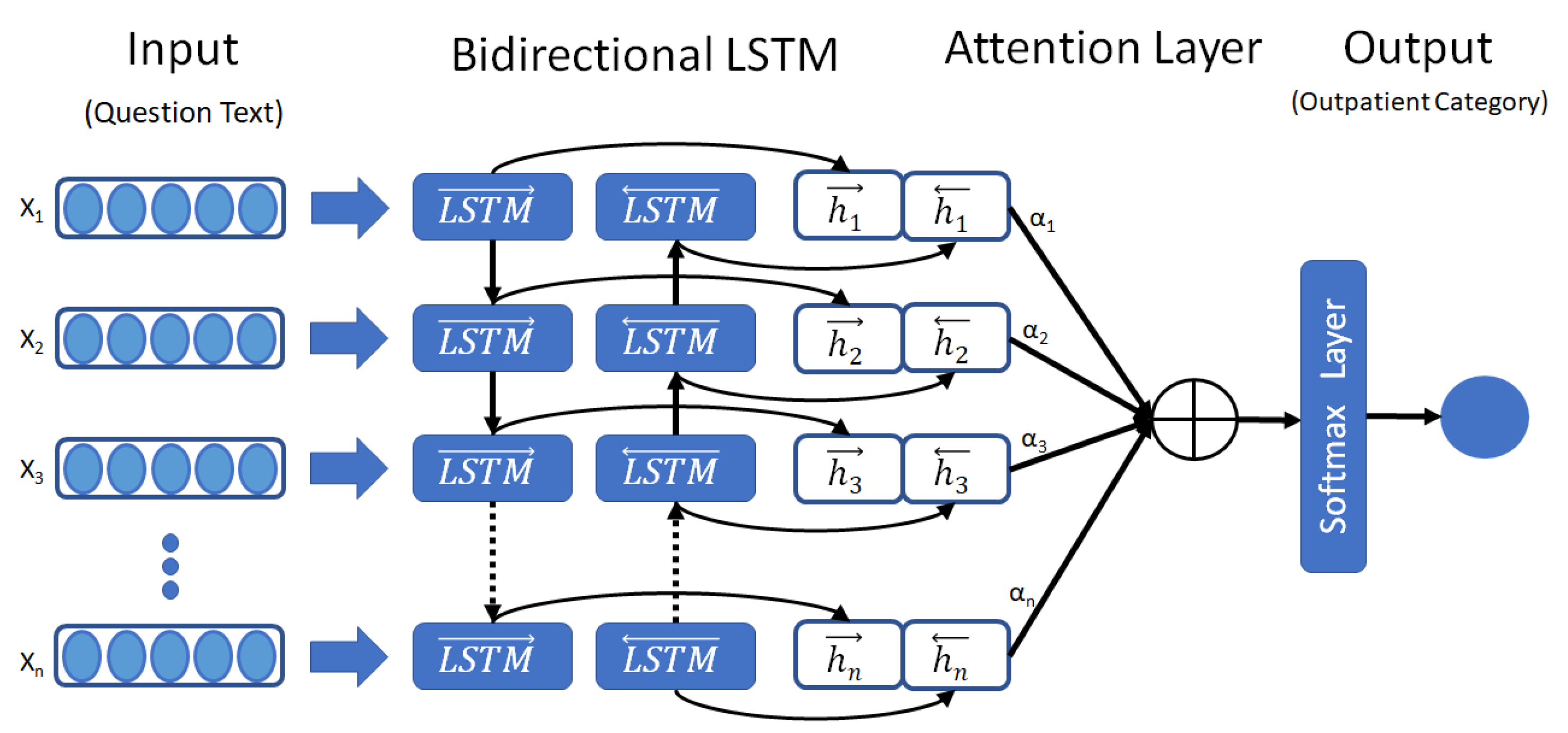
4.2. Attention-Based Bidirectional LSTM Model
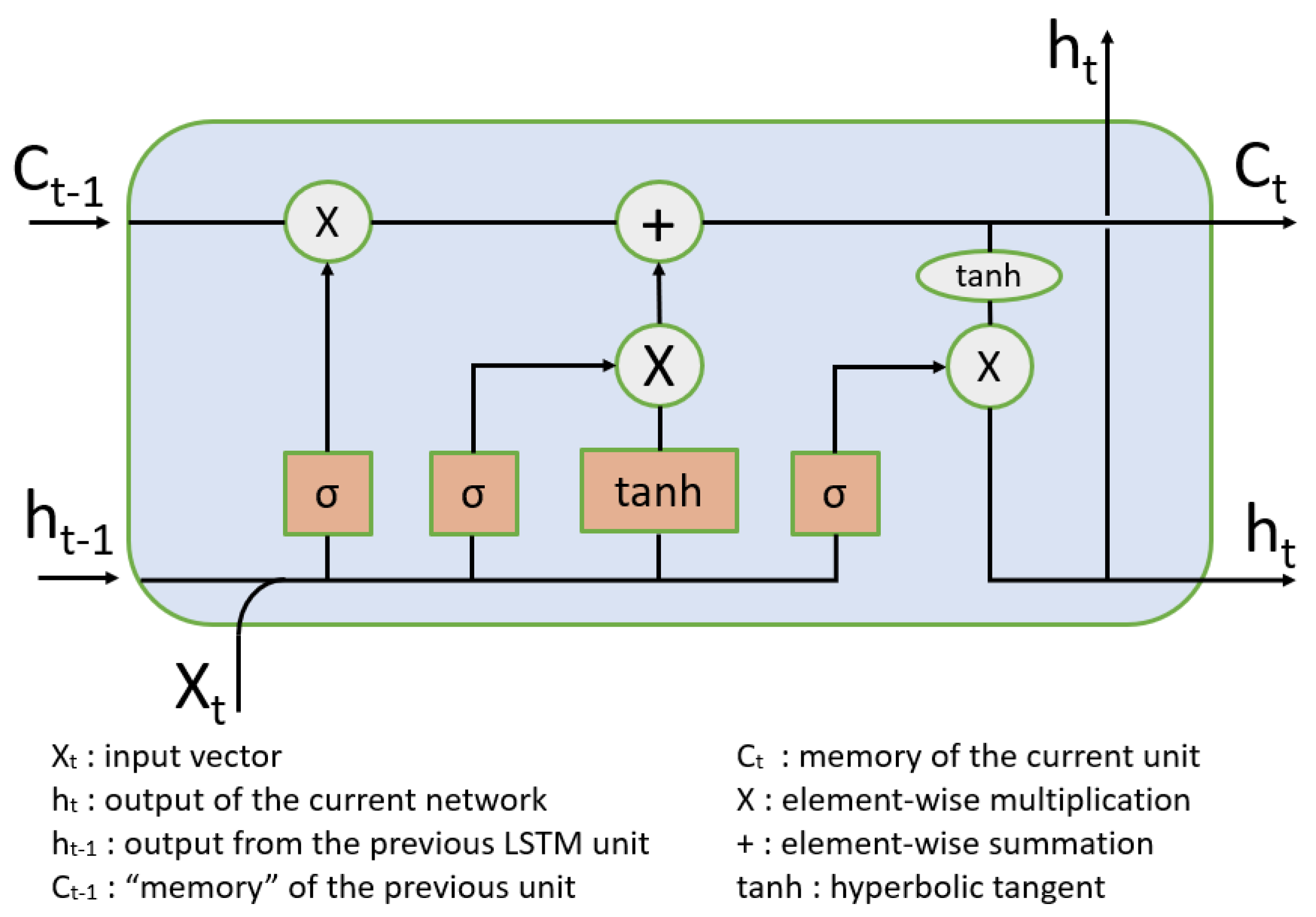
4.2.1. Long Short-Term Memory
4.2.2. Bidirectional LSTM
4.2.3. Attention Layer
4.3. Softmax
5. Experimental Evaluation and Results
5.1. Experimental Datasets
5.2. Parameter Setting
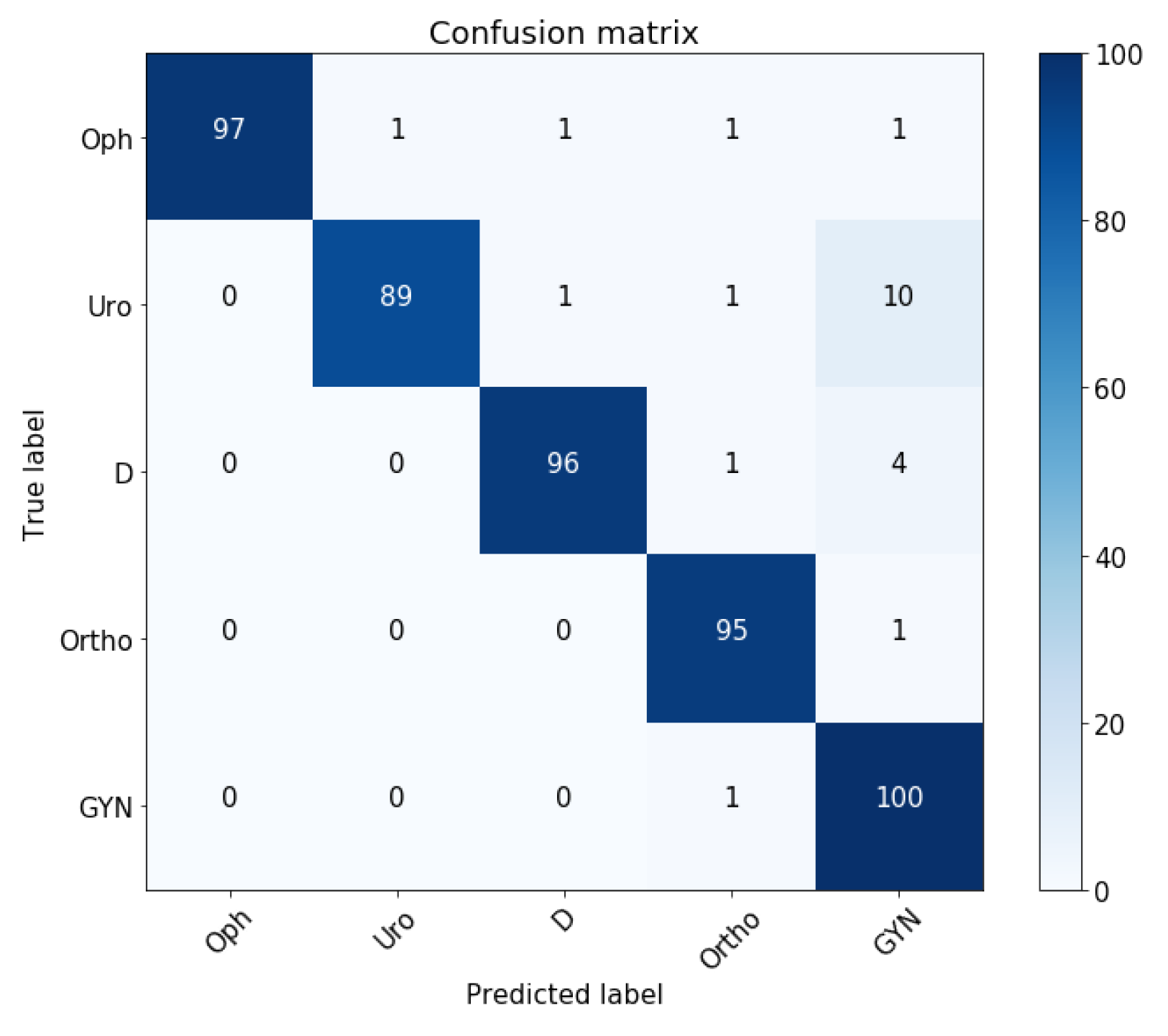
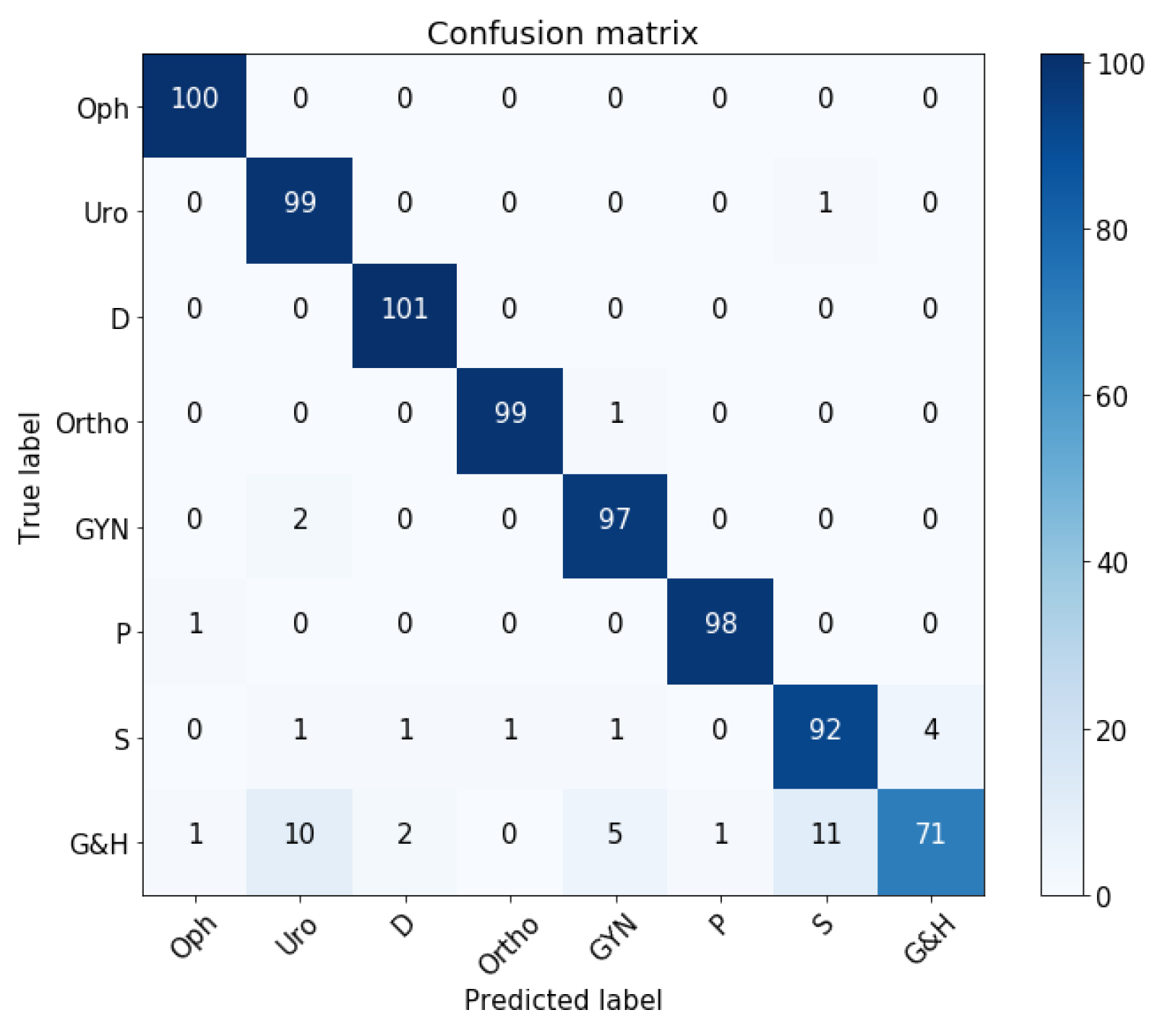
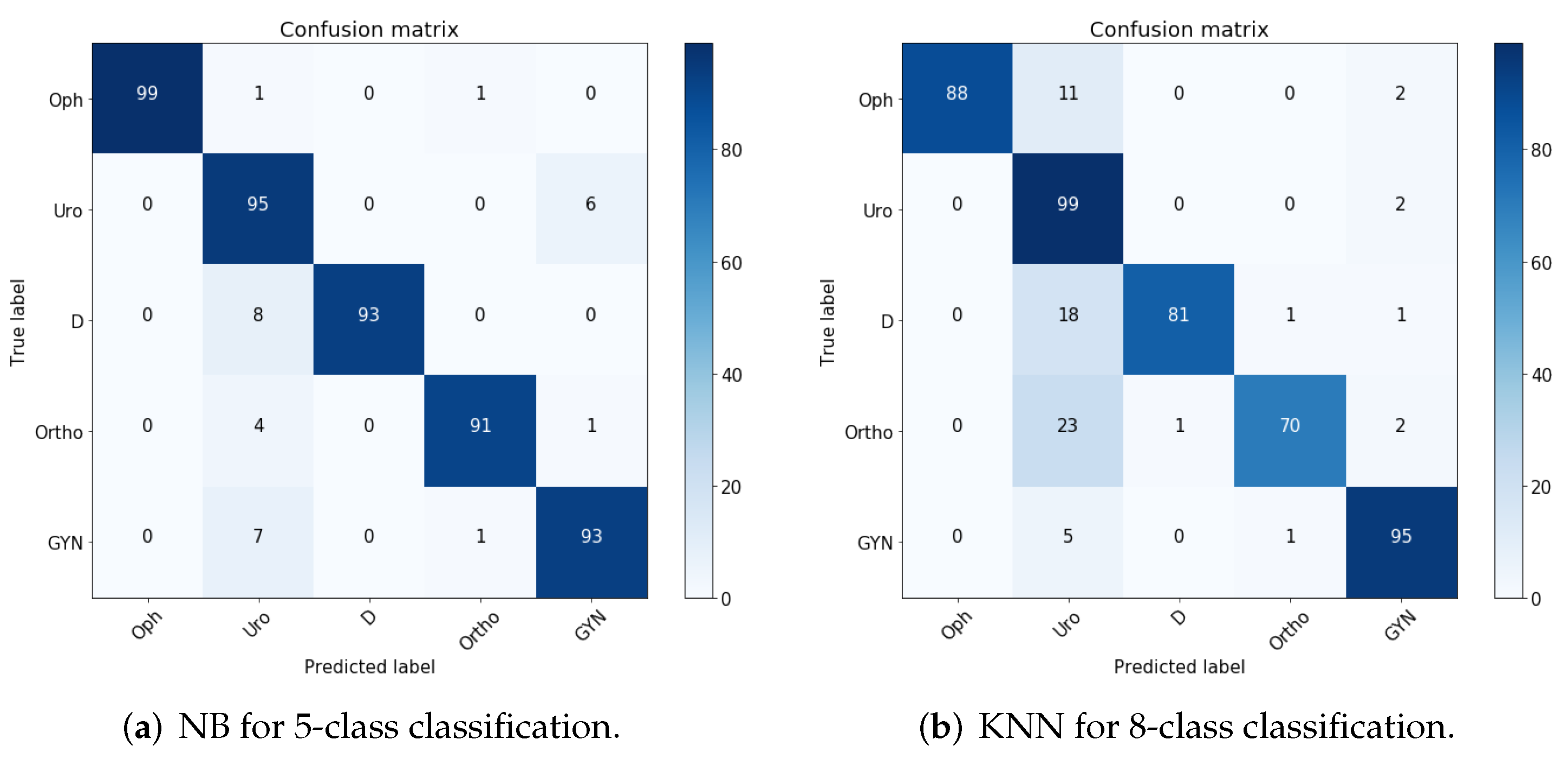
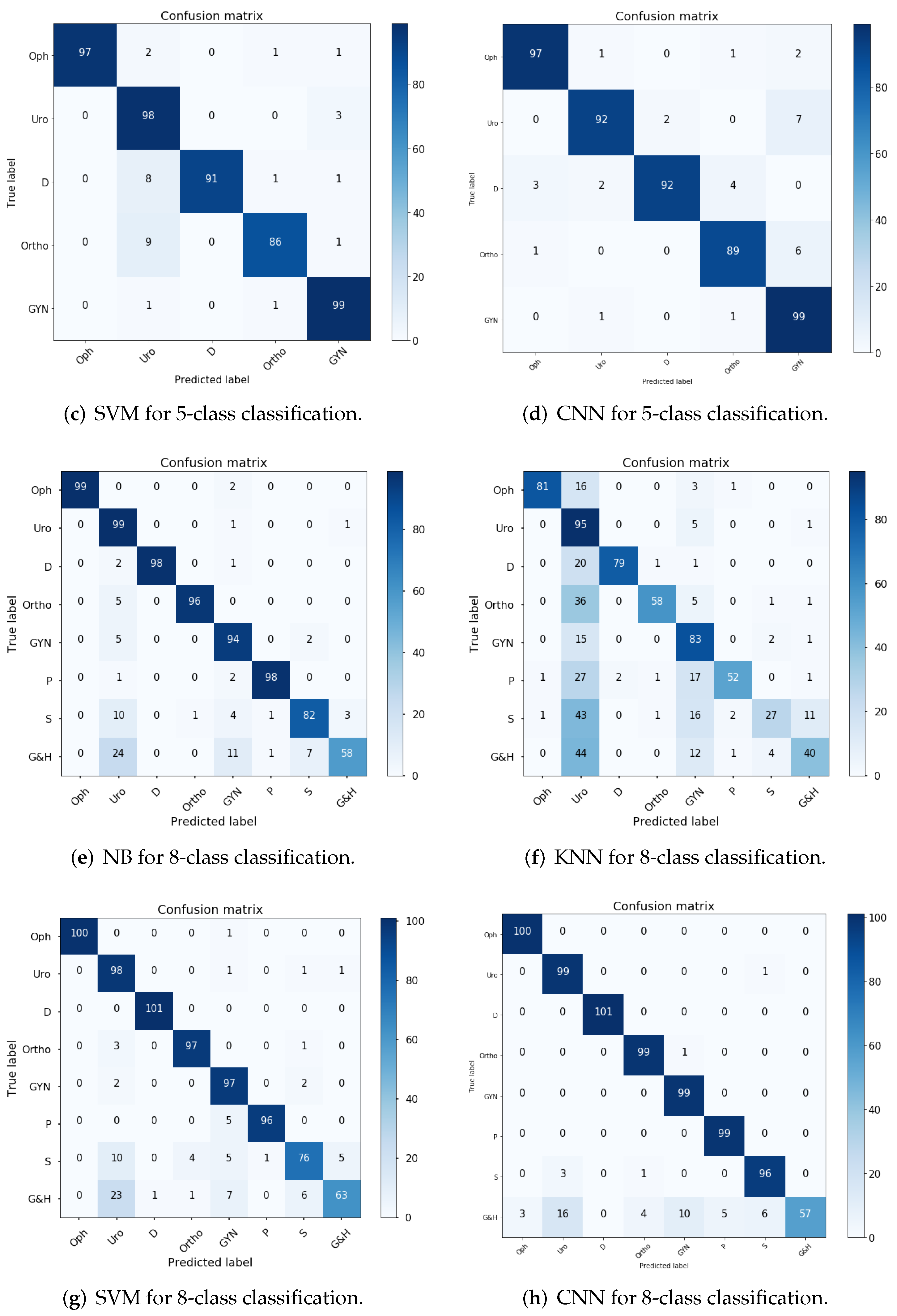
5.3. Comparison with Other Systems
- NB [19]: Naïve Bayes classifiers are a collection of classification algorithms based on Bayes’ Theorem. It is not a single algorithm, but a family of algorithms which all share a common principle (i.e., every pair of features being classified is independent of each other). The parameter used was = 0.05.
- SVM [40]: Support-vector machines are supervised learning models with associated learning algorithms that analyze data, which are used for classification and regression analysis. An SVM model is a representation of the examples as points in space, mapped such that the examples of separate categories are divided by a clear gap that is as wide as possible. New examples are then mapped into that same space and predicted to belong to a category based on the side of the gap on which they fall. The parameter used was kernel: linear.
- KNN [41]: The K-nearest neighbor classifier is a supervised learning algorithm which makes predictions without any model training by choosing the number of k nearest neighbors and a distance metric. Finding the k nearest neighbors of the sample that we wished to classify, we assigned the class label by majority vote. The parameter used was .
- CNN [29]: In a convolutional neural network, the input to NLP tasks are sentences or documents represented as a matrix. Each row of the matrix corresponds to one token, and each row is a vector that represents a word. A CNN is basically a neural-based approach which represents a feature function that is applied to constituting words or n-grams to extract higher-level features. The resulting abstract features have been effectively used in sentiment analysis, machine translation, and question answering, among other tasks. The parameters used were input dim = 100, filters = 250, activation: ReLU, and activation: softmax.
5.4. Evaluation Settings
- Accuracy: Measures the proportion of correctly predicted labels over all predictions:
- Precision: Measures the number of true samples out of those classified as positive. The overall precision is the average of the precision for each class:
- Recall: Measures the number of correctly classified samples out of the total samples of a class. The overall recall is the average of the recall for each class:
- F1-score: F1 score is a classifier metric which calculates a mean of precision and recall in a way that emphasizes the lowest value:
5.5. Experimental Results
5.6. Visualization of Attention
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ASR | Automatic Speech Recognition |
| TF–IDF | Term Frequency–Inverse Document Frequency |
| TTS | Text-To-Speech |
| NB | Naïve Bayes |
| SVM | Support-Vector Machine |
| KNN | K-Nearest Neighbor |
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Networks |
| LSTM | Long Short-Term Memory |
| Oph | Ophthalmology |
| Uro | Urology department |
| D | Dentistry |
| P | Pediatrics department |
| S | Surgery |
| Ortho | Orthopedics |
| GYN | Gynecology |
| GandH | Gastroenterology and Hepatology |
Appendix A


References
- Tzafestas, S. Roboethics: Fundamental concepts and future prospects. Information 2018, 9, 148. [Google Scholar] [CrossRef] [Green Version]
- Ju, M.; Luo, H.; Wang, Z.; Hui, B.; Chang, Z. The Application of Improved YOLO V3 in Multi-Scale Target Detection. Appl. Sci. 2019, 9, 3775. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Zhou, Z. A Heuristic Elastic Particle Swarm Optimization Algorithm for Robot Path Planning. Information 2019, 10, 99. [Google Scholar] [CrossRef] [Green Version]
- Batsuren, K.; Yun, D. Soft robotic gripper with chambered fingers for performing in-hand manipulation. Appl. Sci. 2019, 9, 2967. [Google Scholar] [CrossRef] [Green Version]
- Lee, M.S.; Lee, Y.K.; Pae, D.S.; Lim, M.T.; Kim, D.W.; Kang, T.K. Fast Emotion Recognition Based on Single Pulse PPG Signal with Convolutional Neural Network. Appl. Sci. 2019, 9, 3355. [Google Scholar] [CrossRef] [Green Version]
- Badenhorst, J.; De Wet, F. The usefulness of imperfect speech data for ASR development in low-resource languages. Information 2019, 10, 268. [Google Scholar] [CrossRef] [Green Version]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach. Available online: https://ugeb.pw/30195311.pdf (accessed on 14 February 2020).
- Santosh, K. Speech Processing in Healthcare: Can We Integrate? Available online: https://www.sciencedirect.com/science/article/pii/B9780128181300000015 (accessed on 12 February 2020).
- Li, Q.; Li, S.; Zhang, S.; Hu, J.; Hu, J. A Review of Text Corpus-Based Tourism Big Data Mining. Appl. Sci. 2019, 9, 3300. [Google Scholar] [CrossRef] [Green Version]
- Cheng, C.H.; Chen, C.Y.; Liang, J.J.; Tsai, T.N.; Liu, C.Y.; Li, T.H.S. Design and implementation of prototype service robot for shopping in a supermarket. In Proceedings of the 2017 International Conference on Advanced Robotics and Intelligent Systems (ARIS), Taipei, Taiwan, 6–8 September 2017; pp. 46–51. [Google Scholar]
- Massaro, A.; Maritati, V.; Savino, N.; Galiano, A.; Convertini, D.; De Fonte, E.; Di Muro, M. A Study of a Health Resources Management Platform Integrating Neural Networks and DSS Telemedicine for Homecare Assistance. Information 2018, 9, 176. [Google Scholar] [CrossRef] [Green Version]
- Fei, L.; Na, L.; Jian, L. A new service composition method for service robot based on data-driven mechanism. In Proceedings of the 2014 9th International Conference on Computer Science and Education, Vancouver, Canada, 22–24 August 2014; pp. 1038–1043. [Google Scholar]
- Garcia, E.; Jimenez, M.A.; De Santos, P.G.; Armada, M. The evolution of robotics research. IEEE Robot. Autom. Mag. 2007, 14, 90–103. [Google Scholar] [CrossRef]
- ASUS. Zenbo: Your Smart Little Companion. Available online: https://zenbo.asus.com/tw/ (accessed on 12 February 2020).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Wallach, H.M. Topic modeling: Beyond bag-of-words. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 977–984. [Google Scholar]
- Damashek, M. Gauging similarity with n-grams: Language-independent categorization of text. Science 1995, 267, 843–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Joachims, T. A Probabilistic Analysis of the Rocchio Algorithm with TFIDF for Text Categorization. Available online: https://apps.dtic.mil/docs/citations/ADA307731 (accessed on 12 February 2020).
- McCallum, A.; Nigam, K. A Comparison of Event Models for Naive Bayes Text Classification. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.65.9324&rep=rep1&type=pdf (accessed on 12 February 2020).
- Trstenjak, B.; Mikac, S.; Donko, D. KNN with TF-IDF based framework for text categorization. Procedia Eng. 2014, 69, 1356–1364. [Google Scholar] [CrossRef] [Green Version]
- Joachims, T. Text categorization with support vector machines: Learning with many relevant features. In Machine Learning: ECML-98; Nédellec, C., Rouveirol, C., Eds.; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Melville, P.; Gryc, W.; Lawrence, R.D. Sentiment analysis of blogs by combining lexical knowledge with text classification. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 1275–1284. [Google Scholar]
- Zhang, Y.; Gong, L.; Wang, Y. An improved TF-IDF approach for text classification. J. Zhejiang-Univ.-Sci. A 2005, 6, 49–55. [Google Scholar] [CrossRef]
- Kang, H.; Yoo, S.J.; Han, D. Senti-lexicon and improved Naïve Bayes algorithms for sentiment analysis of restaurant reviews. Expert Syst. Appl. 2012, 39, 6000–6010. [Google Scholar] [CrossRef]
- Johnson, R.; Zhang, T. Semi-Supervised Convolutional Neural Networks for Text Categorization via Region Embedding. Available online: https://papers.nips.cc/paper/5849-semi-supervised-convolutional-neural (accessed on 12 February 2020).
- Johnson, R.; Zhang, T. Supervised and semi-supervised text categorization using LSTM for region embeddings. arXiv 2016, arXiv:1602.02373. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. Available online: https://www.aclweb.org/anthology/D14-1162.pdf (accessed on 12 February 2020).
- Tang, D.; Wei, F.; Qin, B.; Yang, N.; Liu, T.; Zhou, M. Sentiment embeddings with applications to sentiment analysis. IEEE Trans. Knowl. Data Eng. 2015, 28, 496–509. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Zhou, C.; Sun, C.; Liu, Z.; Lau, F. A C-LSTM neural network for text classification. arXiv 2015, arXiv:1511.08630. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Recurrent neural network for text classification with multi-task learning. arXiv Prepr. 2016, arXiv:1605.05101. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A System for Large-Scale Machine Learning. Available online: https://www.usenix.org/conference/osdi16/technical-sessions/presentation/abadi (accessed on 12 February 2020).
- Ryoo, S.; Rodrigues, C.I.; Baghsorkhi, S.S.; Stone, S.S.; Kirk, D.B.; Hwu, W.W. Optimization principles and application performance evaluation of a multithreaded GPU using CUDA. In Proceedings of the 13th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Salt Lake City, UT, USA, 20 February 2008; pp. 73–82. [Google Scholar]
- Salton, G.; Wong, A.; Yang, C.S. A vector space model for automatic indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef] [Green Version]
- Sun, J. ‘Jieba’ Chinese Word Segmentation Tool. Available online: https://github.com/fxsjy/jieba (accessed on 12 February 2020).
- Srivastava, N.; Mansimov, E.; Salakhudinov, R. Unsupervised Learning of Video Representations Using LSTMs. Available online: https://proceedings.mlr.press/v37/srivastava15.pdf (accessed on 12 February 2020).
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, D.; Lee, W.S. Question classification using support vector machines. In Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Informaion Retrieval, Toronto, ON, Canada, 28 July–1 August 2003; pp. 26–32. [Google Scholar]
- Zhang, Y.; Peng, S.; Lv, J. Improvement and application of TFIDF method based on text classification. Jisuanji Gongcheng/Comput. Eng. 2006, 32, 76–78. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware | Specification |
|---|---|
| Appearance | 37 x 37 x 62 cm (L x W x H) |
| Weight | 10 kg |
| System | Android |
| Memory | 4 GB |
| Ultrasonic ranging sensor | |
| Sensors | Automatic recharge sensor |
| Capacitive touch sensor | |
| Screen | 10.1 inch LCD screen |
| Microphone | Digital microphone |
| Wi-Fi 802.11 a/b/g/n/ac | |
| Connection | 2.4 G/5 GHz, |
| Bluetooth BT4.0 |
| Function | Feedback Action |
|---|---|
| Health Education | Play health care education video |
| About Hospital | Show information about the hospital |
| Promotional Activity | Show promotional goods |
| Product Location Search | Answer questions on the location of drugs and goods |
| Navigation | Answer questions on map information |
| Medical QA | Answer medical questions |
| Ambulance Knowledge | Ambulance knowledge education promotion |
| Travel Health Tips | Show health information to pay attention to while traveling |
| QA | Text content |
|---|---|
| Question | Hi! Doctor, I have occasionally been dizzy recently, and can’t see clearly when I look at things. But I’ve seen ophthalmology to confirm that the retina is OK. Which department do I need to check for these symptoms? Thank you. |
| Answer | Hello! According to your description, I suggest you go to the division of Neurology. Changhua Hospital cares about you. |
| Outpatient Category | Number of Texts |
|---|---|
| Ophthalmology (Oph) | 2879 |
| Urology department (Uro) | 10,276 |
| Dentistry (D) | 2870 |
| Pediatrics department (P) | 3831 |
| Surgery (S) | 7993 |
| Orthopedics (Ortho) | 3308 |
| Gynecology (GYN) | 6800 |
| Gastroenterology and Hepatology (GandH) | 2836 |
| Total | 47,093 |
| Parameter | Value |
|---|---|
| Size of input vector | 250 |
| Max features | 100 |
| Number of hidden nodes | 128 |
| Size of batch | 32 |
| Epochs | 50 |
| Learning rate | 0.001 |
| Regularization rate | 0.025 |
| Probability of dropout | 0.2 |
| Activation function | ReLU |
| Optimization | Adam |
| Output layer | Softmax |
| Method | Accuracy | Precise | Recall | F1-Score |
|---|---|---|---|---|
| NB | 94% | 95% | 94% | 94% |
| KNN | 87% | 90% | 87% | 87% |
| SVM | 94% | 95% | 94% | 94% |
| CNN | 93% | 94% | 94% | 94% |
| LSTM | 95% | 94% | 94% | 94% |
| Att-BiLSTM | 96% | 96% | 96% | 96% |
| Method | Accuracy | Precise | Recall | F1-Score |
|---|---|---|---|---|
| NB | 90% | 91% | 90% | 89% |
| KNN | 64% | 78% | 64% | 65% |
| SVM | 90% | 91% | 90% | 90% |
| CNN | 93% | 94% | 94% | 93% |
| LSTM | 95% | 94% | 94% | 94% |
| Att-BiLSTM | 96% | 96% | 96% | 96% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.-W.; Tseng, S.-P.; Kuan, T.-W.; Wang, J.-F. Outpatient Text Classification Using Attention-Based Bidirectional LSTM for Robot-Assisted Servicing in Hospital. Information 2020, 11, 106. https://doi.org/10.3390/info11020106
Chen C-W, Tseng S-P, Kuan T-W, Wang J-F. Outpatient Text Classification Using Attention-Based Bidirectional LSTM for Robot-Assisted Servicing in Hospital. Information. 2020; 11(2):106. https://doi.org/10.3390/info11020106
Chicago/Turabian StyleChen, Che-Wen, Shih-Pang Tseng, Ta-Wen Kuan, and Jhing-Fa Wang. 2020. "Outpatient Text Classification Using Attention-Based Bidirectional LSTM for Robot-Assisted Servicing in Hospital" Information 11, no. 2: 106. https://doi.org/10.3390/info11020106
APA StyleChen, C. -W., Tseng, S. -P., Kuan, T. -W., & Wang, J. -F. (2020). Outpatient Text Classification Using Attention-Based Bidirectional LSTM for Robot-Assisted Servicing in Hospital. Information, 11(2), 106. https://doi.org/10.3390/info11020106