1. Introduction
Named entity recognition (NER) is a sub-task of information extraction (IE) to identify and classify textual elements (words or sequences of words) into a pre-defined set of categories called named entities (NEs) such as the name of a person, organization, or location, expressions of time, quantities, monetary values, percentages, etc. The term
named entity was first coined at the 6th Message Understanding Conference (MUC-6) [
1]. NER plays an essential role in extracting knowledge from the digital information stored in a structured or unstructured form. It acts as a pre-processing tool for many applications, and some of these applications are listed below:
Information retrieval (IR) is the task of retrieving relevant documents from a collection of documents based on an input query. A study by Guo et al. [
2] states that 71% of the queries in search engines are NEs and thus IR [
3] can benefit from NER by identifying the NEs within the query.
Machine translation (MT) is the task of automatically translating a text from a source to a target language. NEs require a different technique of translation than the rest of the words because, in general, NEs are not vocabulary words. If the errors of an MT system are mainly due to incorrect translation of NEs, then the post-editing step is more expensive to handle. The research study by Babych and Hartley [
4] showed that including a pre-processing step by tagging text with NEs achieved higher accuracy in the MT system. The quality of the NER system plays a vital role in machine translation [
5,
6].
Question answering (QA) systems are tasked with automatically generating answers to questions asked by a human being in natural language. The answers to questions starting with the wh-words (What, When, Which, Where, Who) [
7]) are generally NEs. So, incorporating NER in QA systems [
8,
9,
10,
11] makes the task of finding answers to questions considerably easier.
Automatic text summarization includes topic identification of where the NEs are as an essential indication of a topic in the text [
12]. It is shown that integrating named entity recognition significantly improves the performance of resulting summaries [
13,
14].
The problem of the identification and classification of NEs is quite challenging because of the open nature of vocabulary. There has been a significant amount of work on NER in English, wherein the earlier work on NER is based on rule-based and dictionary-based approaches.
Rule-based NER relies on hand-crafted rules for identifying and classifying NEs. These rules can be structural, contextual, or lexical patterns [
15]. For example, the following list shows two rules for recognizing organization and person names:
〈proper noun〉 + 〈organization designator〉 ⟶ 〈organization name〉
〈capitalized last name〉, 〈capitalized first name〉 ⟶ 〈person name〉
The first rule detects organization names that consist of one or more proper nouns followed by an organization designator such as “Corporation” or “Company”. The second rule recognizes person names written in the order of family name, comma, and given the name. The first limitation of the rule-based approach is in the design of generic rules with high precision by the domain expert/linguist. This process takes a significant amount of time and often needs many iterations to improve the performance. Secondly, the rules obtained for a given domain may not be appliccable to other areas for some languages. For example, NEs for the health domain may not be suitable for finance.
Dictionary-based NER uses dictionaries of target entity types (e.g., dictionaries of the names of people, companies, locations, etc.) and identifies the occurrences of the dictionary entries (e.g., Bill Gates, Facebook, Madison Square, etc.) in text [
16]. This approach looks very straightforward at first glance but has difficulties due to the ambiguity of natural language. Firstly, the entities can be referred to by different names. For example, Thomas Alva Edison can also be written as Thomas Edison or Edison. It is not practically possible to create a comprehensive dictionary that enumerates all of these variations. Secondly, the same name might represent different entities like a person or location. For example, “Washington” is the name of the first president of the U.S. as well as the name of a state in the U.S. [
17]. Since NER systems have to deal with these issues, machine learning approaches have been adopted for NER.
The state-of-the-art of NER systems are machine learning techniques, which can automatically learn to identify and classify NEs based on the data. Supervised learning techniques like hidden Markov model (HMM) [
18], maximum entropy model (ME) [
19], decision tree [
20], conditional random fields [
21], neural networks [
22], naïve Bayes [
23], and support vector machines [
24] has been explored to build NER models. There have been few attempts to solve the problem using semi-supervised [
25] and unsupervised learning techniques [
26]. NER for the English language has been widely researched. However, for South-East Asian languages (especially Telugu) there has not been much progress. Though we may get some insights from the learning models developed for NER in English or other languages, the language-dependent features make it difficult to use similar models for the Telugu language. Telugu (తెలుగు) is a Dravidian language mostly spoken in the states of Andhra Pradesh, Telangana, and other neighboring states of Southern India. Telugu [
27] ranks fourth in terms of the number of people speaking it as a first language in India. The main challenges for Telugu NER are listed below:
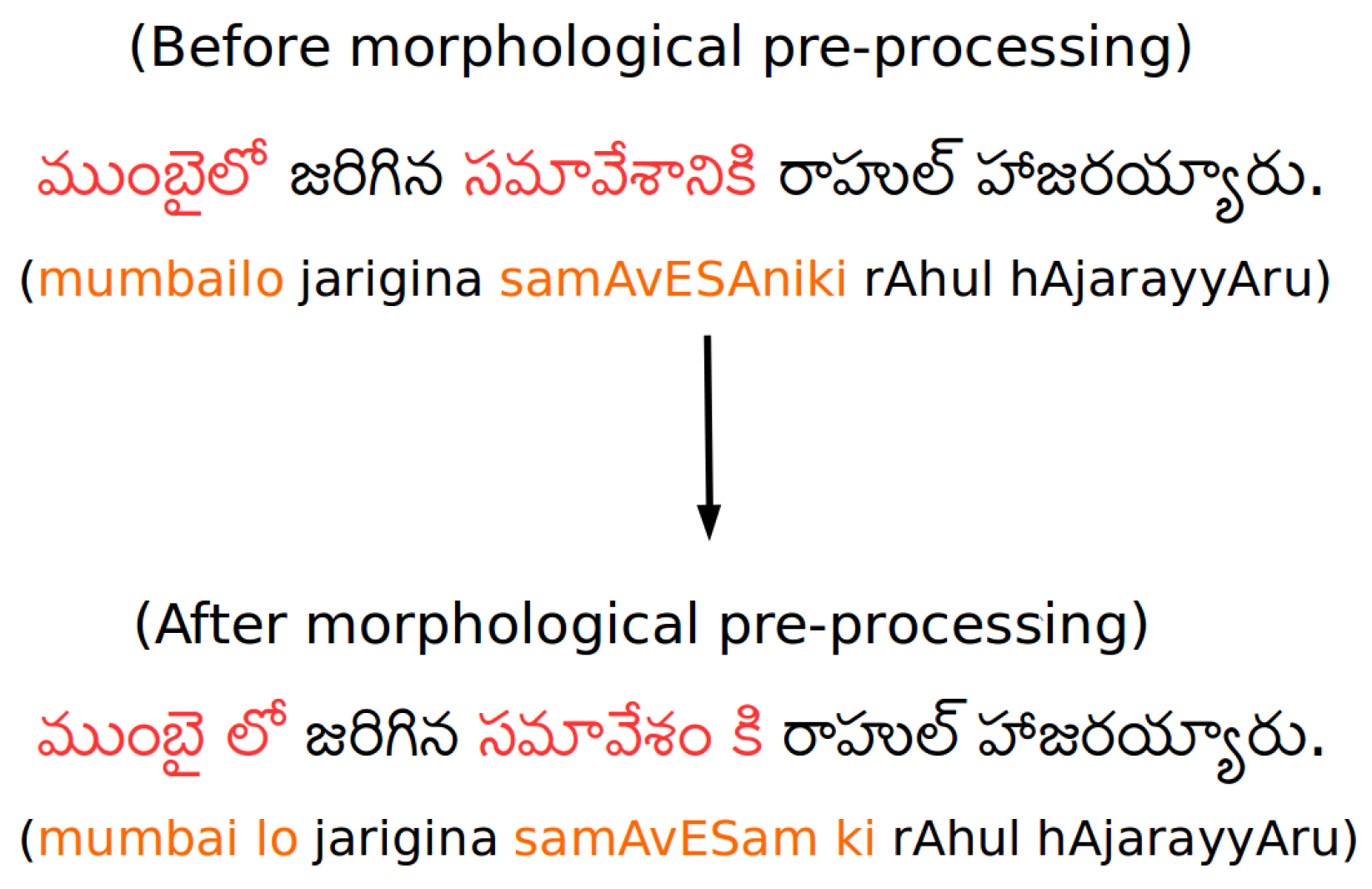
Telugu is a highly inflectional and agglutinating language: The way lexical forms get generated in Telugu are different from English. In Telugu, words are formed by inflectional suffixes added to roots or stems. For example: in the word హైదరాబాదులో (haidarAbAdlo (transliteration in English)) (in Hyderabad) = హైదరాబాద్ (haidarAbAd) + లో (lo) (root word + post-position).
The absence of capitalization: In English, named entities start with a capital letter and this capitalization plays an important role in identifying and classifying NEs, whereas there is no concept of capitalization in Telugu. For example: పూజ (puja) could be the name of a person or the common meaning “worship”. In English, we write “Puja” when it is name of a person and “puja” when it refers to the common noun. In Telugu, we write పూజ (puja) in both cases. Thus, capitalization is an important feature to distinguish proper nouns from common nouns.
Resource-poor language: For the Telugu language, resources like annotated corpora, name dictionaries (gazetteers), morphological analyzers, part-of-speech (POS) taggers, etc. are not adequately available.
Relatively free order: The primary word order of Telugu is SOV (subject–object–verb), but the word order of subject and object is largely free. For example, in the sentence: “Ramu sent necklace to sita” can be written as రాము సీతకు హారాన్నిపంపాడు (rAmu sItaku hArAnni oampADu) or రాముహారాన్ని సీతాకు పంపాడు (rAmu hArAnni sItaku pampADu) in Telugu. Internal changes or position swaps among words in sentences or phrases will not affect the meaning of the sentence.
NER for Telugu has been receiving increasing attention, but there are only a few articles in the recent past. Most of the previous works on NER for Telugu [
28,
29,
30,
31] build NER models using language-independent features like contextual information, prefix/suffix, orthogonal and POS of current words. The language-dependent features help in improving the performance of the NER task [
32] and gazetteers (entity dictionaries) or entity clue lists are part of the language-dependent features. In one of the previous works on Telugu NER [
33] the model is built using both language-independent and language-dependent features, but the language-dependent-feature gazetteers are generated manually. However, building and maintaining high-quality gazetteers by hand is time-consuming. Many methods have been proposed for the automatic generation of gazetteers [
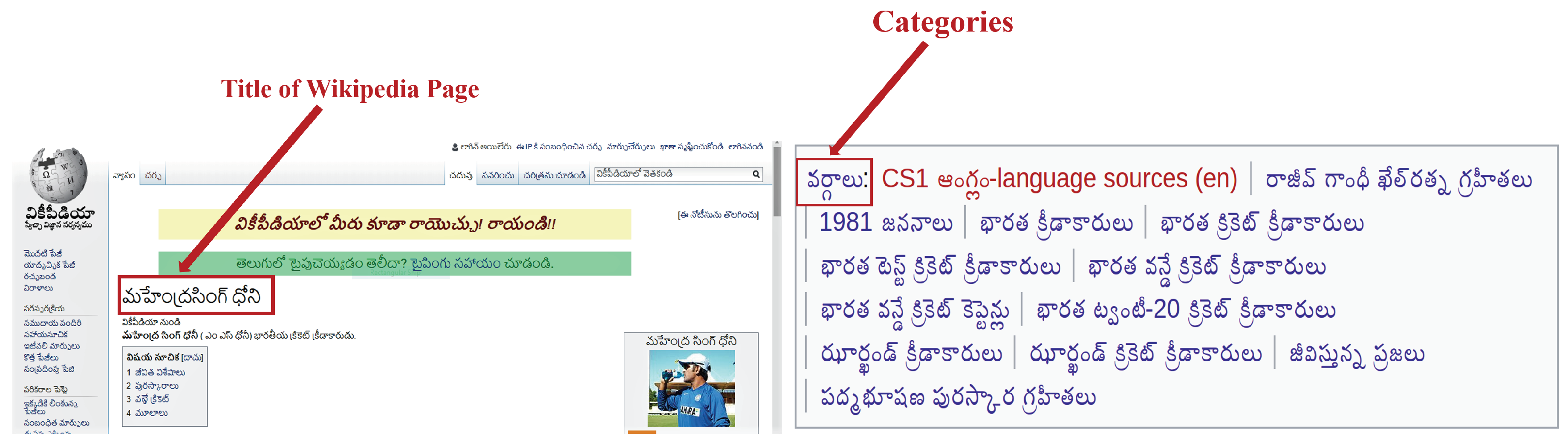
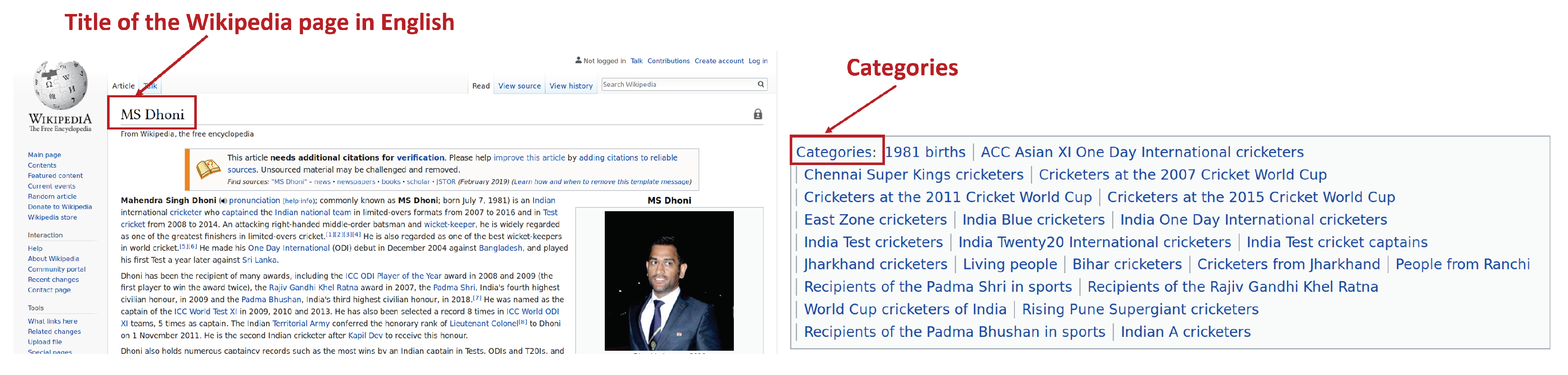
34]. However, these methods require patterns or statistical methods to extract high-quality gazetteers. The exponential growth in information content, especially in Wikipedia, has made it increasingly popular for solving a wide range of NLP problems across different domains. Wikipedia has 69,450 (
https://meta.wikimedia.org/wiki/List_of_Wikipedias) articles in the Telugu language as of July 2018. Each article in Wikipedia is identified by a unique name known as an “entity name”. These articles have many useful structures for knowledge extraction such as headings, lists, internal links, categories, and tables. In this work, we used category labels for the dynamic creation of gazetteer features. The process is explained in
Section 3.3.3.
The major contributions in this work are listed below:
Morphological pre-processing is proposed to handle the inflectional and agglutinating issues of the language.
We propose to use language-dependent features like clue words (surname, prefix/suffix, location, organization, and designation) to build an NER model.
We present a methodology for the dynamic generation of gazetteers using Wikipedia categories.
We extract the proposed features for the FIRE data set and make it publicly available to facilitate future research.
We perform a comparative study of NER models built using three well-known machine learning algorithms—support vector machine (SVM), conditional random field (CRF), and margin infused relaxed algorithm (MIRA).
We study the impact of gazetteer-related features on NER models.
The rest of this article is organized as follows: The related work on NER in Indian languages is discussed in
Section 2.
Section 3 explains the NER corpus, tag-set with potential features, and briefly explains the three different classifiers used to build the models. The experimental results are discussed in
Section 4 followed by the conclusion of the article in
Section 5.
2. Related Work on NER
In this section, we first discuss NER-related studies in the Telugu language, followed by some studies of other Indian languages—Hindi, Bengali, and Tamil.
Srikanth and Murthy [
33] were some of the first authors to explore NER in Telugu. They built a two-stage classifier which they tested using the LERC-UoH (Language Engineering Research Centre at University of Hyderabad) Telugu corpus. In the early stage, they built a CRF-based binary classifier for noun identification, which was trained on manually tagged data of 13,425 words and tested on 6223 words. Then, they developed a rule-based NER system for Telugu, where their primary focus was on identifying the name of person, location, and organization. A manually verified NE-tagged corpus of 72,157 words was used to develop this rule-based tagger through boot-strapping. Then, they developed a CRF-based NER system for Telugu using features such as prefix/suffix, orthographic information, and gazetteers, which were manually generated, and reported an F1-score of 88.5%. In our work we present a methodology for the dynamic generation of gazetteers using Wikipedia categories.
Praneeth et al. [
28] proposed a CRF-based NER model for Telugu using contextual word of length three, prefix/suffix of the current word, POS, and chunk information. They conducted experiments on data released as a part of the NER for South and South-East Asian Languages (NERSSEAL) (
http://ltrc.iiit.ac.in/ner-ssea-08/) competition with 12 classes. The best-performing model gave an F1-Score of 44.91%.
Ekbal et al. [
31] proposed a multiobjective optimization (MOO)-based ensemble classifier using a three-base machine learning algorithm (maximum entropy (ME), CRF, and SVM). The ensemble was used to build NER models for Hindi, Telugu, and Bengali languages. The features used to construct the Bengali NER were contextual words, prefix/suffix, length of the word, the position of the word in the sentence, POS information, digital information, and manually generated gazetteer features. They reported an F1-Score of 94.5%. To build an NER model for Hindi and Telugu, they used the contextual words, prefix/suffix, length of the word, the position of the word in the sentence, and POS information, and reported F1-Scores of 92.80% and 89.85% for Hindi and Telugu, respectively.
Sriparna and Asif [
30] extended the above work by building an ensemble classifier using base classifiers ME, Naïve Bayes, CRF, Memory-Based Learner, Decision Tree (DT), SVM, and hidden Markov model (HMM) without using any domain knowledge or language-specific resources. The proposed technique was evaluated for three languages—Bengali, Hindi, and Telugu. Results using a MOO-based method yielded the overall F1-Scores of 94.74% for Bengali, 94.66% for Hindi, and 88.55% for Telugu.
Arjun Das and Utpal Garain [
29] proposed CRF-based NER systems for the Indian language on the data set provided as a part of the ICON 2013 conference. In this task, the NER model for the Telugu language was built using language-independent features like contextual words, word prefix and suffix, POS and chunk information, and first and last words of the sentence. The model obtained an F1-Score of 69%.
SaiKiranmai et al. [
35] built a Telugu NER model using three classification learning algorithms (i.e., CRF, SVM, and ME) on the data set provided as a part of the NER for South and South-East Asian Languages (NERSSEAL) (
http://ltrc.iiit.ac.in/ner-ssea-08/) competition. The features used to build the model were contextual information, POS tags, morphological information, word length, orthogonal information, and sentence information. The results show that the SVM achieved the best F1-Score of 54.78%.
SaiKiranmai et al. [
36] developed an NER model which classifies textual content from on-line Telugu newspapers using a well-known generative model. They used generic features like contextual words and their POS tags to build the learning model. By understanding the syntax and grammar of the Telugu language, they introduced some language-dependent features like post-position features, clue word features, and gazetteer features to improve the performance of the model. The model achieved an overall average F1-Score of 88.87% for person, 87.32% for location, and 72.69% for organization identification.
SaiKiranmai et al. [
37] attempted to cluster NEs based on semantic similarity. They used vector space models to build a word-context matrix. The row vector was constructed with and without considering the different occurrences of NEs in a corpus. Experimental results show that the row vector considering different occurrences of NEs enhanced the clustering results.
In the Hindi language, Li and McCallum [
38] built a CRF-based NER model by making use of 340k words with three NE tags, namely person, location, and organization, and reported an F1-score of 71.5%. Saha et al. [
39] developed a Hindi NER model using maximum entropy (ME). They developed the model using language-specific and context pattern features, obtaining an F1-score of 81.52%. Saha et al. [
40] proposed a novel kernel function for SVM to build an NER model for Hindi and bio-medical data. The NER model achieved an F1-score of 84.62% for Hindi.
In the Bengali language, Ekbal and Sivaji [
41] developed an NER model using SVM. The corpus consisted of 150k words annotated with sixteen NE tags. The features used to build the model were context word, word prefix/suffix, POS information, and gazetteers, and it achieved an average F1-score of 91.8%. Ekbal et al. [
42] developed an NER model for Bengali and Hindi using SVM. These models use different contextual information of words in predicting four NE classes, such as a person, location, organization, and miscellaneous. The annotated corpora consist of 122,467 tokens for Bengali and 502,974 tokens for Hindi. This model reported an F1-score of 84.15% for Bengali and 77.17% for Hindi. Ekbal et al. [
43] developed an NER model using CRF for Bengali and Hindi using contextual features with an F1-score of 83.89% for Bengali and 80.93% for Hindi. Banerjee et al. [
44] developed an NER model for Bengali using the margin infused relaxed algorithm. They used IJCNLP-08 NERSSEAL data, which are annotated with twelve NE tags, and obtained an F1-Score of 89.69%.
Vijayakrishna and Sobha [
45] developed a Tamil Named Entity Recognizer for the tourism domain using CRF. It handles nested NEs with a tag-set consisting of 106 tags, and reported an overall F1-Score of 80.44%. Abinaya et al. [
46] present a NER model for Tamil using the random kitchen sink (RKS) algorithm, which is a statistical and supervised approach. They also implemented the NER model using SVM and CRF and reported overall F1-Scores of 86.61% for RKS, 81.62% for SVM, and 87.21% for CRF.






{kind=link}
{kind=link}
{kind=link}