A Sentiment-Statistical Approach for Identifying Problematic Mobile App Updates Based on User Reviews



Abstract
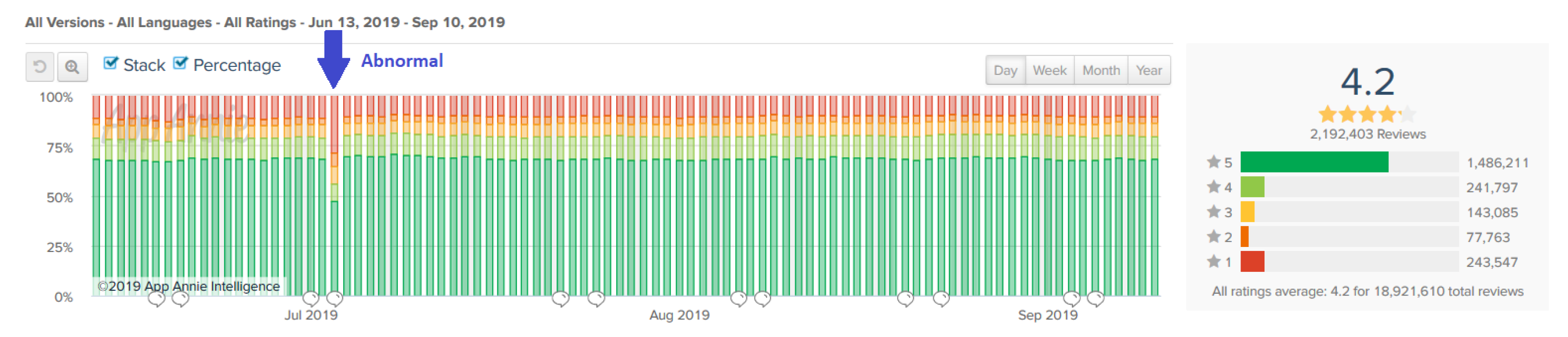
:1. Introduction
- How to identify the collective dissatisfaction of users based on their reviews?
- How to verify it is the recent update that results in the users’ dissatisfaction?
2. Related Work
3. Method
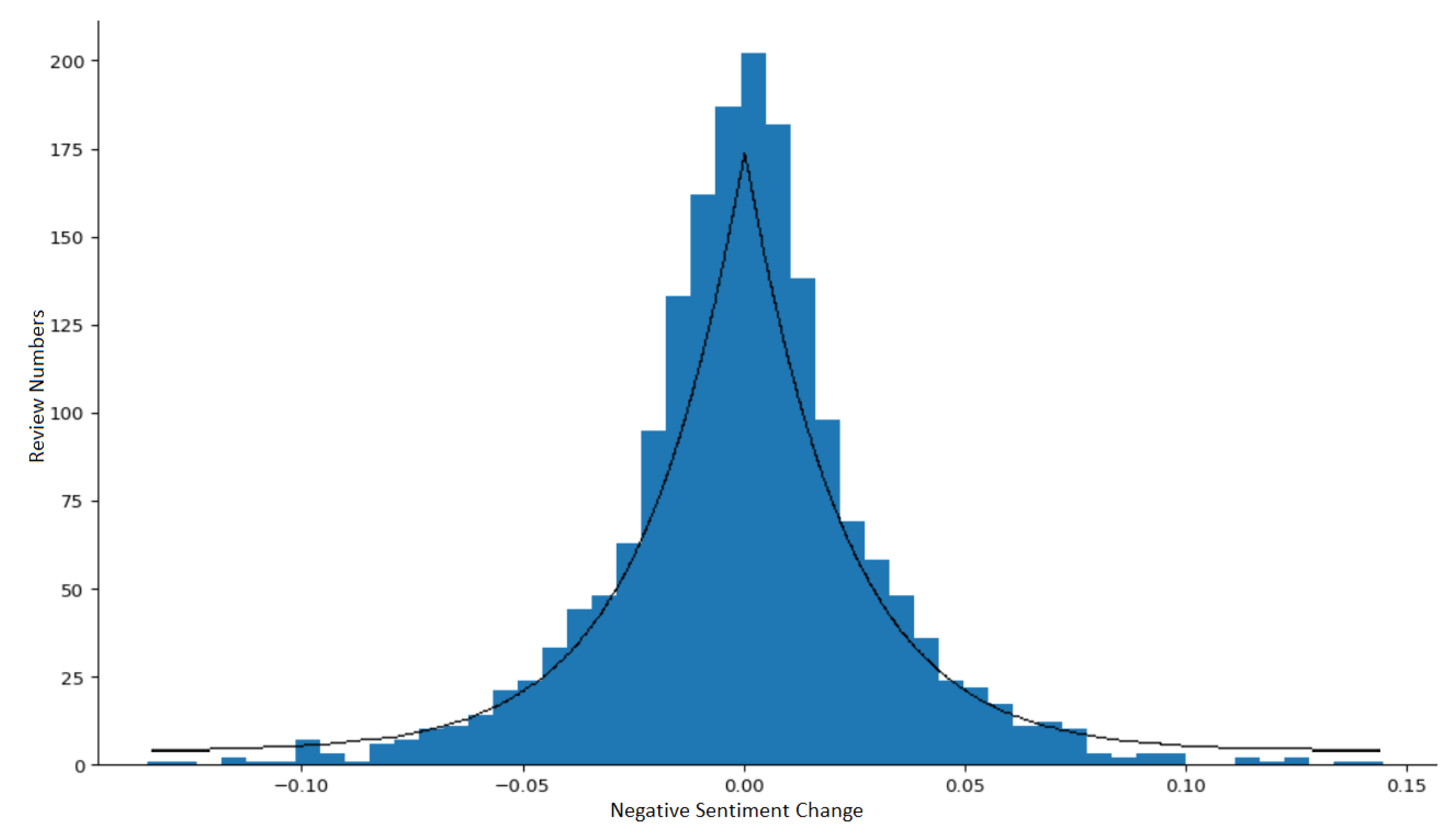
3.1. Sentiment Change Distribution
3.2. Identify Abnormal Sentiment Changes
3.3. Identify Problematic Updates
3.4. Algorithm
- Calculate the parameters of the exponential power distribution model of the daily review sentiment changes.
- Identify the abnormal sentiment change days based on the distribution model, if any.
- Check whether it is the nearest previous update that is problematic and causing such detected abnormality in user review sentiment change by comparing the similarity between the negative reviews of the abnormal days and the update description texts.
| Algorithm 1: Algorithm of identifying abnormal days and problematic updates. |
 |
4. Case Study
4.1. Data Preprocessing
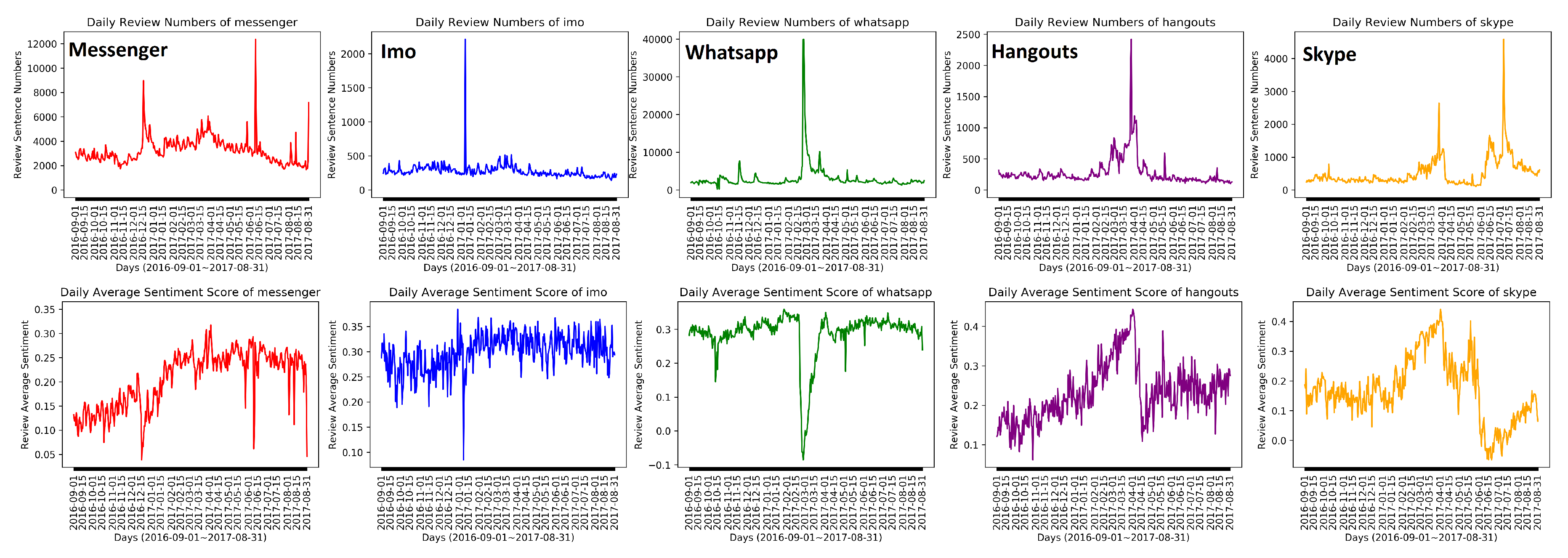
4.2. Data Description
4.3. Results
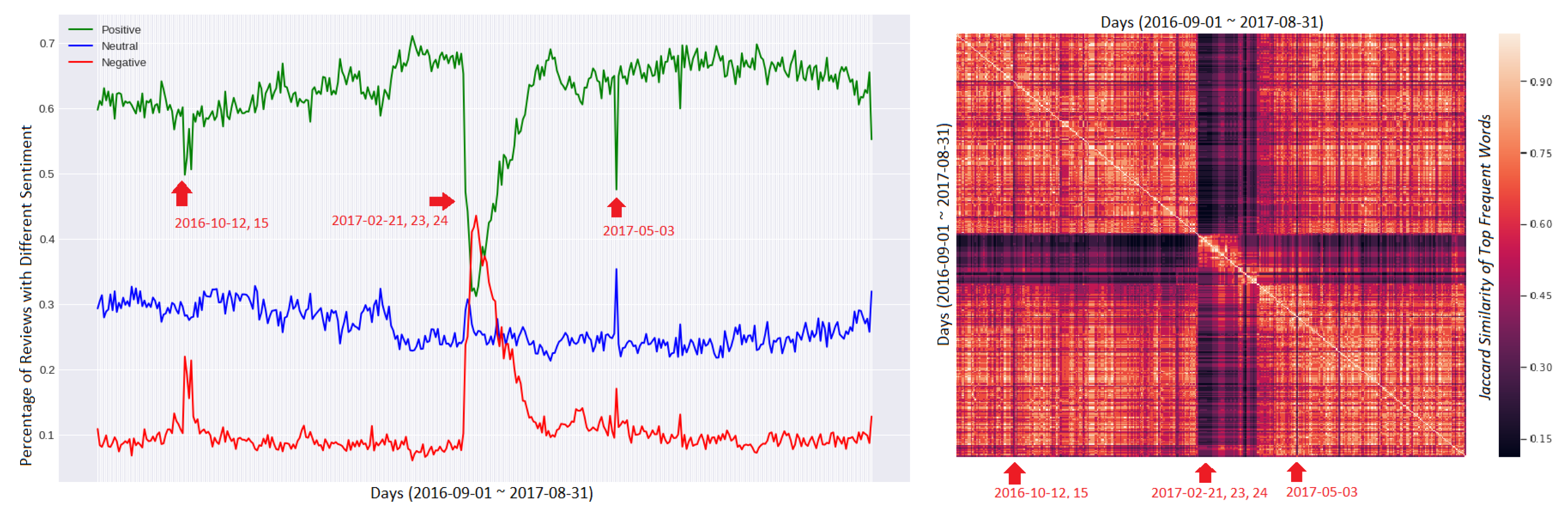
4.3.1. Identify Abnormal Days
4.3.2. Identify Problematic Updates
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nayebi, M.; Adams, B.; Ruhe, G. Release Practices for Mobile Apps–What do Users and Developers Think? In Proceedings of the 2016 IEEE 23rd International Conference on Software Analysis, Evolution, and Reengineering (Saner), Osaka, Japan, 14–18 March 2016; Volume 1, pp. 552–562. [Google Scholar]
- Khalid, H.; Shihab, E.; Nagappan, M.; Hassan, A.E. What do mobile app users complain about? IEEE Softw. 2014, 32, 70–77. [Google Scholar] [CrossRef]
- Holzer, A.; Ondrus, J. Mobile application market: A developer’s perspective. Telemat. Inf. 2011, 28, 22–31. [Google Scholar] [CrossRef]
- Galvis Carreño, L.V.; Winbladh, K. Analysis of user comments: An approach for software requirements evolution. In Proceedings of the 2013 International Conference on Software Engineering, San Francisco, CA, USA, 18–26 May 2013; pp. 582–591. [Google Scholar]
- Chen, N.; Lin, J.; Hoi, S.C.; Xiao, X.; Zhang, B. AR-miner: Mining informative reviews for developers from mobile app marketplace. In Proceedings of the 36th International Conference on Software Engineering, Hyderabad, India, 31 May 31–7 June 2014; pp. 767–778. [Google Scholar]
- Guzman, E.; Maalej, W. How do users like this feature? a fine grained sentiment analysis of app reviews. In Proceedings of the 2014 IEEE 22nd international requirements engineering conference (RE), Karlskrona, Sweden, 25–29 August 2014; pp. 153–162. [Google Scholar]
- Maalej, W.; Nabil, H. Bug report, feature request, or simply praise? on automatically classifying app reviews. In Proceedings of the 2015 IEEE 23rd international requirements engineering conference (RE), Ottawa, ON, Canada, 24–28 August 2015; pp. 116–125. [Google Scholar]
- Panichella, S.; Di Sorbo, A.; Guzman, E.; Visaggio, C.A.; Canfora, G.; Gall, H.C. How can i improve my app? classifying user reviews for software maintenance and evolution. In Proceedings of the 2015 IEEE international conference on software maintenance and evolution (ICSME), Bremen, Germany, 27 September–3 October 2015; pp. 281–290. [Google Scholar]
- McIlroy, S.; Ali, N.; Khalid, H.; Hassan, A.E. Analyzing and automatically labelling the types of user issues that are raised in mobile app reviews. Empir. Softw. Eng. 2016, 21, 1067–1106. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Z.; Stefanidis, K. Sentiment-aware Analysis of Mobile Apps User Reviews Regarding Particular Updates. In Proceedings of the Thirteenth International Conference on Software Engineering Advances (ICSEA), Nice, France, 14–18 October 2018; p. 109. [Google Scholar]
- Fu, B.; Lin, J.; Li, L.; Faloutsos, C.; Hong, J.; Sadeh, N. Why people hate your app: Making sense of user feedback in a mobile app store. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–13 August 2013; pp. 1276–1284. [Google Scholar]
- Zhang, L.; Hua, K.; Wang, H.; Qian, G.; Zhang, L. Sentiment analysis on reviews of mobile users. Procedia Comput. Sci. 2014, 34, 458–465. [Google Scholar] [CrossRef] [Green Version]
- Fafalios, P.; Iosifidis, V.; Stefanidis, K.; Ntoutsi, E. Multi-aspect Entity-Centric Analysis of Big Social Media Archives. In Proceedings of the Research and Advanced Technology for Digital Libraries—21st International Conference on Theory and Practice of Digital Libraries TPDL, Thessaloniki, Greece, 18–21 September 2017; pp. 261–273. [Google Scholar]
- Stratigi, M.; Li, X.; Stefanidis, K.; Zhang, Z. Ratings vs. Reviews in Recommender Systems: A Case Study on the Amazon Movies Dataset. In European Conference on Advances in Databases and Information Systems; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Villarroel, L.; Bavota, G.; Russo, B.; Oliveto, R.; Di Penta, M. Release planning of mobile apps based on user reviews. In Proceedings of the 2016 IEEE/ACM 38th International Conference on Software Engineering (ICSE), Austin, TX, USA, 14–22 May 2016; pp. 14–24. [Google Scholar]
- Ciurumelea, A.; Schaufelbühl, A.; Panichella, S.; Gall, H.C. Analyzing reviews and code of mobile apps for better release planning. In Proceedings of the 2017 IEEE 24th International Conference on Software Analysis, Evolution and Reengineering (SANER), Klagenfurt, Austria, 20–24 February 2017; pp. 91–102. [Google Scholar]
- Palomba, F.; Salza, P.; Ciurumelea, A.; Panichella, S.; Gall, H.; Ferrucci, F.; De Lucia, A. Recommending and localizing change requests for mobile apps based on user reviews. In Proceedings of the 39th International Conference on Software Engineering, Buenos Aires, Argentina, 20–28 May 2017; pp. 106–117. [Google Scholar]
- Koskela, M.; Simola, I.; Stefanidis, K. Open Source Software Recommendations Using Github. In Proceedings of the Digital Libraries for Open Knowledge, 22nd International Conference on Theory and Practice of Digital Libraries TPDL, Porto, Portugal, 10–13 September 2018; pp. 279–285. [Google Scholar]
- Möller, A.; Michahelles, F.; Diewald, S.; Roalter, L.; Kranz, M. Update behavior in app markets and security implications: A case study in google play. In Proceedings of the 14th International Conference on Human Computer Interaction with Mobile Devices and Services, San Francisco, CA, USA; 2012; pp. 3–6. [Google Scholar]
- Xia, X.; Shihab, E.; Kamei, Y.; Lo, D.; Wang, X. Predicting crashing releases of mobile applications. In Proceedings of the 10th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Ciudad Real, Spain, 8–9 September 2016; p. 29. [Google Scholar]
- Genc-Nayebi, N.; Abran, A. A systematic literature review: Opinion mining studies from mobile app store user reviews. J. Syst. Softw. 2017, 125, 207–219. [Google Scholar] [CrossRef]
- Gao, C.; Xu, H.; Hu, J.; Zhou, Y. Ar-tracker: Track the dynamics of mobile apps via user review mining. In Proceedings of the 2015 IEEE Symposium on Service-Oriented System Engineering, San Francisco, CA, USA, 30 March 30–3 April 2015; pp. 284–290. [Google Scholar]
- Chandy, R.; Gu, H. Identifying spam in the iOS app store. In Proceedings of the 2nd Joint WICOW/AIRWeb Workshop on Web Quality, Lyon, France, 16 April 2012; pp. 56–59. [Google Scholar]
- Vu, P.M.; Nguyen, T.T.; Pham, H.V.; Nguyen, T.T. Mining user opinions in mobile app reviews: A keyword-based approach (t). In Proceedings of the 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lincoln, NA, USA, 9–13 November 2015; pp. 749–759. [Google Scholar]
- Iacob, C.; Harrison, R. Retrieving and analyzing mobile apps feature requests from online reviews. In Proceedings of the 10th Working Conference on Mining Software Repositories, San Francisco, CA, USA, 18–19 May 2013; pp. 41–44. [Google Scholar]
- Pagano, D.; Maalej, W. User feedback in the appstore: An empirical study. In Proceedings of the 2013 21st IEEE international requirements engineering conference (RE), Rio de Janeiro, Brazil, 15–19 July 2013; pp. 125–134. [Google Scholar]
- Zimina, E.; Nummenmaa, J.; Järvelin, K.; Peltonen, J.; Stefanidis, K.; Hyyrö, H. GQA: Grammatical Question Answering for RDF Data. In Proceedings of the Semantic Web Challenges—5th SemWebEval Challenge at ESWC, Heraklion, Greece, 3–7 June 2018; pp. 82–97. [Google Scholar]
- Wang, S.; Wang, Z.; Xu, X.; Sheng, Q.Z. App Update Patterns: How Developers Act on User Reviews in Mobile App Stores. In International Conference on Service-Oriented Computing; Springer: Berlin, Germany, 2017; pp. 125–141. [Google Scholar]
- Li, X.; Zhang, Z.; Stefanidis, K. Mobile App Evolution Analysis Based on User Reviews. In Proceedings of the International Conference on Intelligent Software Methodologies, Tools, and Techniques, Granada, Spain, 26–28 September 2018; pp. 773–786. [Google Scholar]
- Massey, F.J., Jr. The Kolmogorov-Smirnov test for goodness of fit. J. Am. Stat. Assoc. 1951, 46, 68–78. [Google Scholar] [CrossRef]
- Nadarajah, S. A generalized normal distribution. J. Appl. Stat. 2005, 32, 685–694. [Google Scholar] [CrossRef]
- Pukelsheim, F. The three sigma rule. Am. Stat. 1994, 48, 88–91. [Google Scholar]
- Chebyshev, P.L. Des valeurs moyennes, Liouville’s. J. Math. Pures Appl. 1867, 12, 177–184. [Google Scholar]
- Hoon, L.; Vasa, R.; Schneider, J.G.; Grundy, J. An Analysis of the Mobile App Review Landscape: Trends And Implications; Faculty of Information and Communication Technologies, Swinburne University of Technology: Melbourne, Australia, 2013. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2013; pp. 3111–3119. [Google Scholar]
- Xue, B.; Fu, C.; Shaobin, Z. A study on sentiment computing and classification of sina weibo with word2vec. In Proceedings of the 2014 IEEE International Congress on Big Data, Anchorage, AK, USA, 27 June–2 July 2014; pp. 358–363. [Google Scholar]
- Ramos, J. Using tf-idf to determine word relevance in document queries. In Proceedings of the First Instructional Conference on Machine Learning, Piscataway, NJ, USA, 3–8 December 2003; Volume 242, pp. 133–142. [Google Scholar]
- Langdetect. Available online: https://pypi.python.org/pypi/langdetect (accessed on 30 September 2019).
- NLTK. Available online: http://www.nltk.org (accessed on 30 September 2019).
- Hutto, C.J.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the Eighth international AAAI conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014. [Google Scholar]
- Cambria, E.; Speer, R.; Havasi, C.; Hussain, A. Senticnet: A publicly available semantic resource for opinion mining. In Proceedings of the AAAI Fall Symposium: Commonsense Knowledge, Arlington, VA, USA, 11–13 November 2010; Volume 10. [Google Scholar]
- Baccianella, S.; Esuli, A.; Sebastiani, F. Sentiwordnet 3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining; Lrec: Baton Rouge, Louisiana, 2010; Volume 10, pp. 2200–2204. [Google Scholar]
- Bradley, M.M.; Lang, P.J. Affective Norms for English Words (ANEW): Instruction Manual and Affective Ratings; Technical Report; University of Florida, The Center for Research in Psychophysiology: Gainesville, FL, USA, 1999. [Google Scholar]
- Stevenson, M.; Wilks, Y. Word sense disambiguation. In The Oxford Handbook of Computational Linguistics; Oxford University Press: Oxford, UK, 2003; pp. 249–265. [Google Scholar]
- Li, X.; Zhang, Z.; Nummenmaa, J. Models for mobile application maintenance based on update history. In Proceedings of the 2014 9th International Conference on Evaluation of Novel Approaches to Software Engineering (ENASE), Lisbon, Portugal, 28–30 April 2014; pp. 1–6. [Google Scholar]
- Qiu, Y.; Gopal, A.; Hann, I.H. Logic pluralism in mobile platform ecosystems: A study of indie app developers on the iOS app store. Inf. Syst. Res. 2017, 28, 225–249. [Google Scholar] [CrossRef]
- Thet, T.T.; Na, J.C.; Khoo, C.S. Aspect-based sentiment analysis of movie reviews on discussion boards. J. Inf. Sci. 2010, 36, 823–848. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
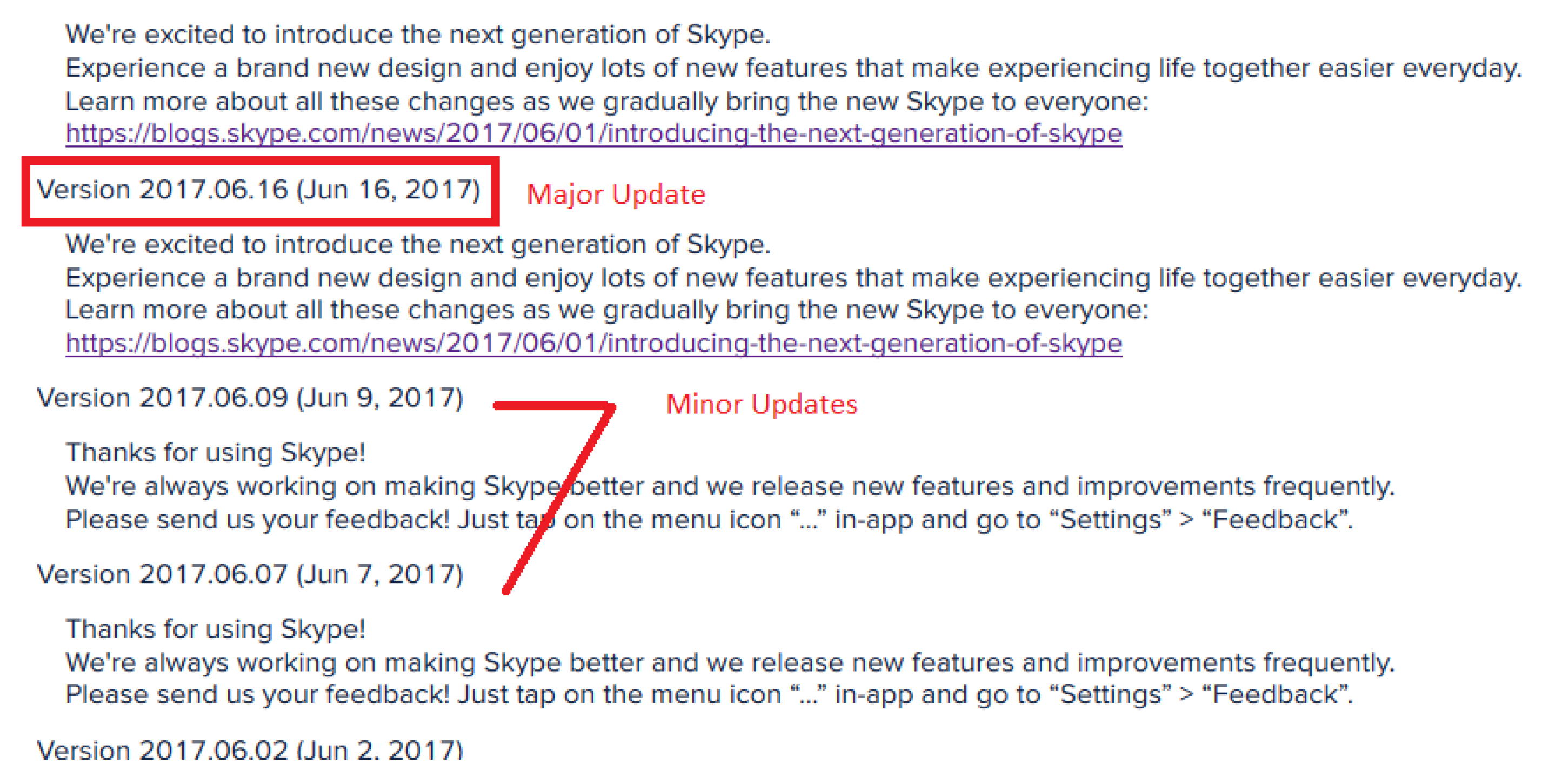{kind=link}
{kind=link}
{kind=link}
| App | Review-Level | Sentence-Level | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | Precision | Recall | F1 Score | |
| Imo | 0.826 | 0.786 | 0.804 | 0.822 | 0.777 | 0.797 |
| Hangouts | 0.839 | 0.803 | 0.819 | 0.802 | 0.780 | 0.790 |
| Messenger | 0.883 | 0.835 | 0.855 | 0.869 | 0.815 | 0.836 |
| Skype | 0.874 | 0.828 | 0.844 | 0.828 | 0.790 | 0.795 |
| 0.851 | 0.814 | 0.830 | 0.833 | 0.787 | 0.805 | |
| Overall | 0.868 | 0.823 | 0.842 | 0.850 | 0.800 | 0.819 |
| App Name | Reviews | English Reviews | Sentences | Updates |
|---|---|---|---|---|
| Imo | 202,870 | 86,194 | 100,838 | 84 |
| Hangouts | 122,622 | 68,535 | 10,1704 | 43 |
| Messenger | 1,654,360 | 886,643 | 1,185,368 | 105 |
| Skype | 153,128 | 105,875 | 189,995 | 76 |
| 1,660,145 | 851,662 | 109,8583 | 49 | |
| total | 3,793,125 | 1,998,909 | 2,676,488 | 357 |
| App Name | CI | Abnormal Days (Year-Month-Day) |
|---|---|---|
| Imo | (−0.082, 0.083) | [‘13 December 2016’, ‘7 January 2017’, ‘3 August 2017’] |
| Hangouts | (−0.098, 0.099) | [ ] |
| Messenger | (−0.060, 0.061) | [‘16 December 2016’, ‘9 June 2017’, ‘3 August 2017’, ‘31 August 2017’] |
| Skype | (−0.095, 0.096) | [‘4 September 2016’, ‘21 May 2017’, ‘25 May 2017’] |
| (−0.053, 0.052) | [‘12 October 2016’, ‘15 October 2016’, ‘21 February 2017’, ‘23 February 2017’, | |
| ‘24 February 2017’, ‘3 May 2017’] |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Zhang, B.; Zhang, Z.; Stefanidis, K. A Sentiment-Statistical Approach for Identifying Problematic Mobile App Updates Based on User Reviews. Information 2020, 11, 152. https://doi.org/10.3390/info11030152
Li X, Zhang B, Zhang Z, Stefanidis K. A Sentiment-Statistical Approach for Identifying Problematic Mobile App Updates Based on User Reviews. Information. 2020; 11(3):152. https://doi.org/10.3390/info11030152
Chicago/Turabian StyleLi, Xiaozhou, Boyang Zhang, Zheying Zhang, and Kostas Stefanidis. 2020. "A Sentiment-Statistical Approach for Identifying Problematic Mobile App Updates Based on User Reviews" Information 11, no. 3: 152. https://doi.org/10.3390/info11030152
APA StyleLi, X., Zhang, B., Zhang, Z., & Stefanidis, K. (2020). A Sentiment-Statistical Approach for Identifying Problematic Mobile App Updates Based on User Reviews. Information, 11(3), 152. https://doi.org/10.3390/info11030152