1. Introduction
In recent years, different organizations such as governments, hospitals and other institutions have published more and more microdata. Microdata plays a key role in data analysis, data mining and scientific research. However, publishing microdata unavoidably exposes the privacy of the individual. To protect the privacy of the individual, Sweeney et al. proposed a
k-anonymity model [
1,
2]. The model requires that the microdata is partitioned into a set of equivalence classes, each equivalence class contains at least
k records, and all records within an equivalence class are assigned the same generalized value over each of their quasi-identifier attributes. Thus, each record in the
k-anonymity model cannot be identified successfully with a probability greater than 1/
k. The
l-diversity model in [
3] extends the
k-anonymity model. It requires that each equivalence class has at least
l different “well-represented” values for a sensitive attribute, so it also implies
l-anonymity. To address the limitations of the
k-anonymity and
l-diversity models, Li et al. [
4] introduced the concept of
t-closeness, which requires that the distribution of the sensitive attribute values within each equivalence class of indistinguishable records is similar to that of the sensitive attribute values in the entire microdata. Then, various enhanced anonymity methods were proposed, such as (
α,
k)-anonymity [
5],
p-sensitive
k-anonymity [
6], anatomy [
7], slicing [
8], anatomy and generalization (ANGEL) [
9], and permutation anonymization [
10].
The above-mentioned works focus on anonymizing the microdata with only one sensitive attribute. They cannot be directly applied to the microdata with multiple sensitive attributes. Therefore, some extended
k-anonymity,
l-diversity,
p-sensitive and
t-closeness methods for multiple sensitive attributes [
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32] were proposed. And some extended anatomy methods combining multi-sensitive bucketization (MSB), clustering, generalization or permutation for multiple sensitive attributes [
33,
34,
35,
36] were proposed. To apply the slicing technique to the microdata with multiple sensitive attributes, some enhanced slicing techniques for multiple sensitive attributes were proposed [
37,
38,
39,
40,
41,
42,
43]. Additionally, decomposition and decomposition plus were introduced to achieve
l-diversity for multiple sensitive attributes [
44,
45]. The above methods for multiple sensitive attributes do not consider the sensitive requirements of various sensitive attributes. Different sensitive attributes may have different sensitivity requirements, so the rating techniques for multiple sensitive attributes were introduced [
46,
47]. These rating techniques not only protect privacy for multiple sensitive attributes, but also keep a large amount of correlations of the microdata. In real world, different values of a sensitive attribute may have different sensitivity requirements. It is not appropriate to apply the same sensitive requirement to all values of the sensitivity attribute. Hence, the above rating techniques for multiple sensitive attributes are not suitable for this situation.
To solve this problem, we defined three security levels for different sensitive attribute values that have different sensitivity requirements, and given an
-diversity model for multiple sensitive attributes. Then, we proposed three specific greed algorithms based on the maximal-bucket first (MBF), maximal single-dimension-capacity first (MSDCF) and maximal multi-dimension-capacity first (MMDCF) algorithms [
33] and the maximal security-level first (MSLF) greedy policy, named as MBF based on MSLF (MBF-MSLF), MSDCF based on MSLF (MSDCF-MSLF) and MMDCF based on MSLF (MMDCF-MSLF), to implement the
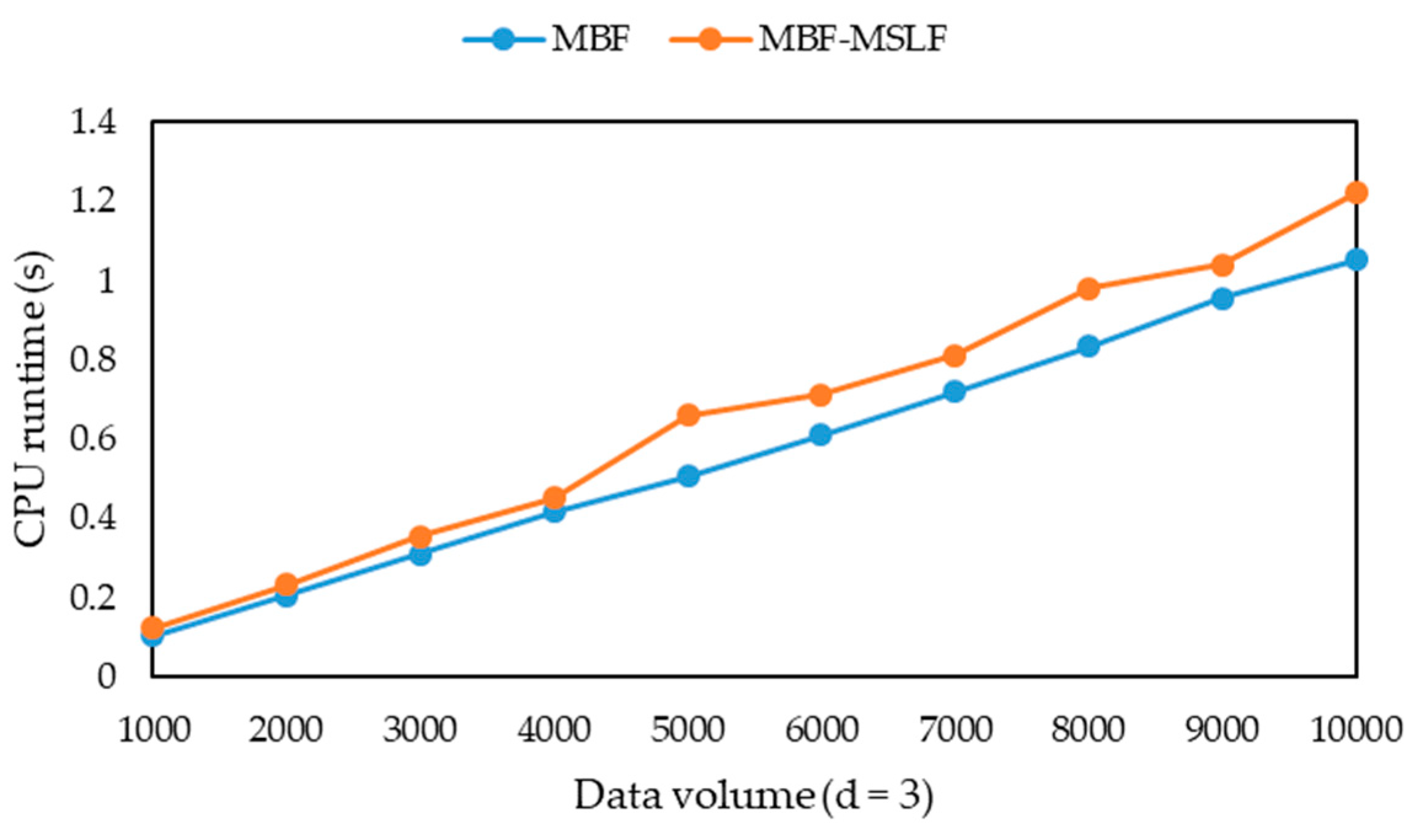
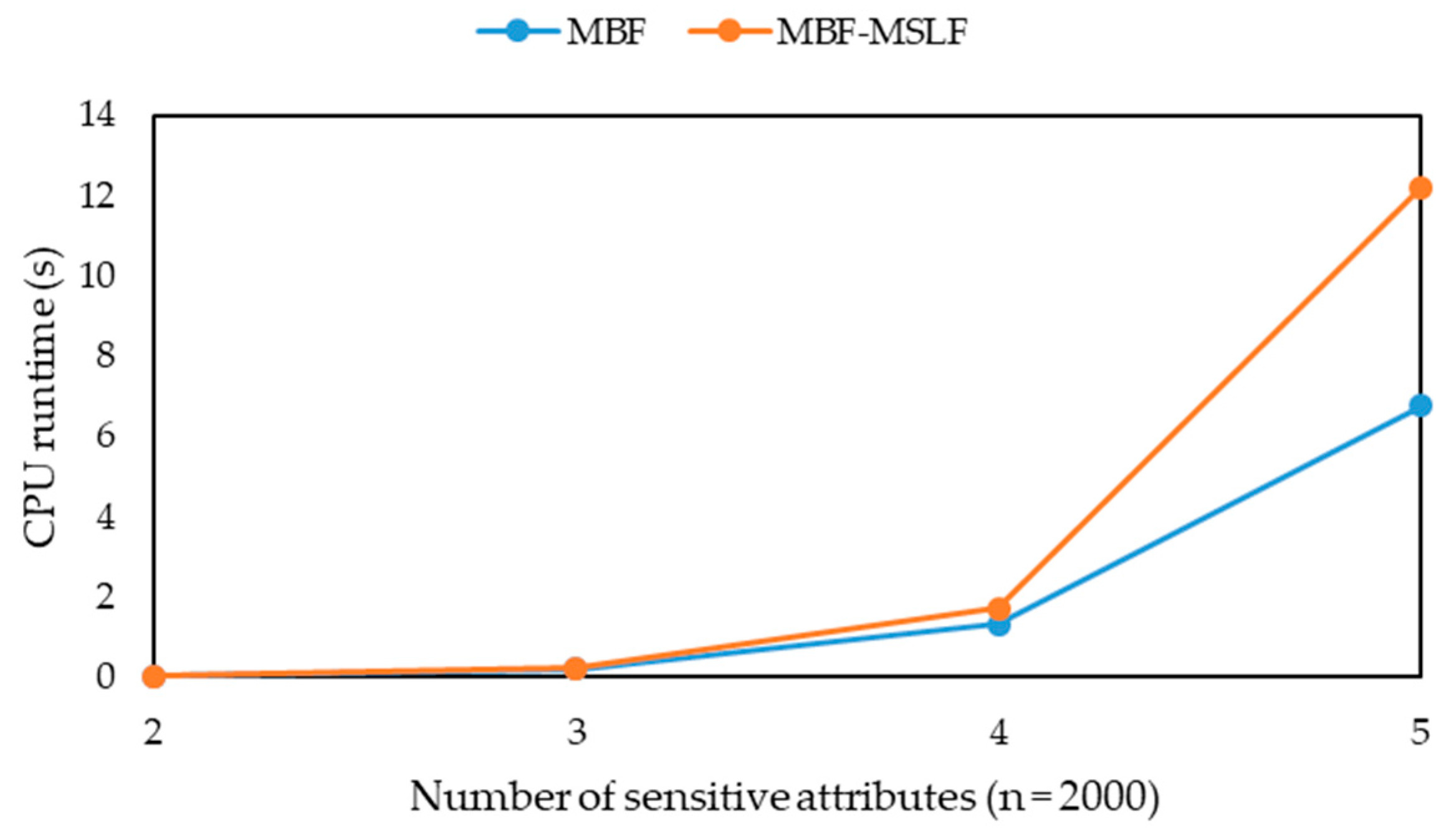
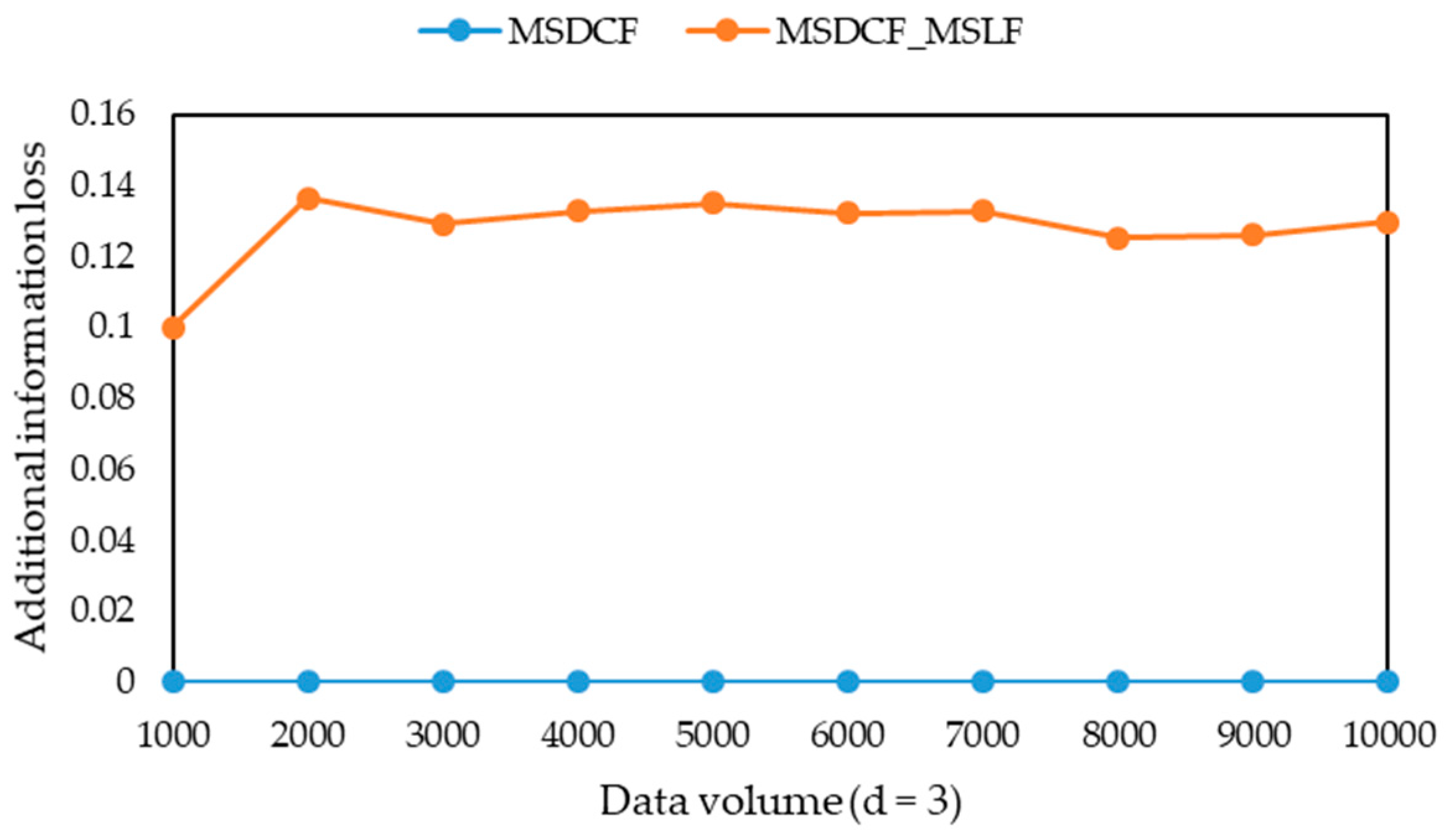
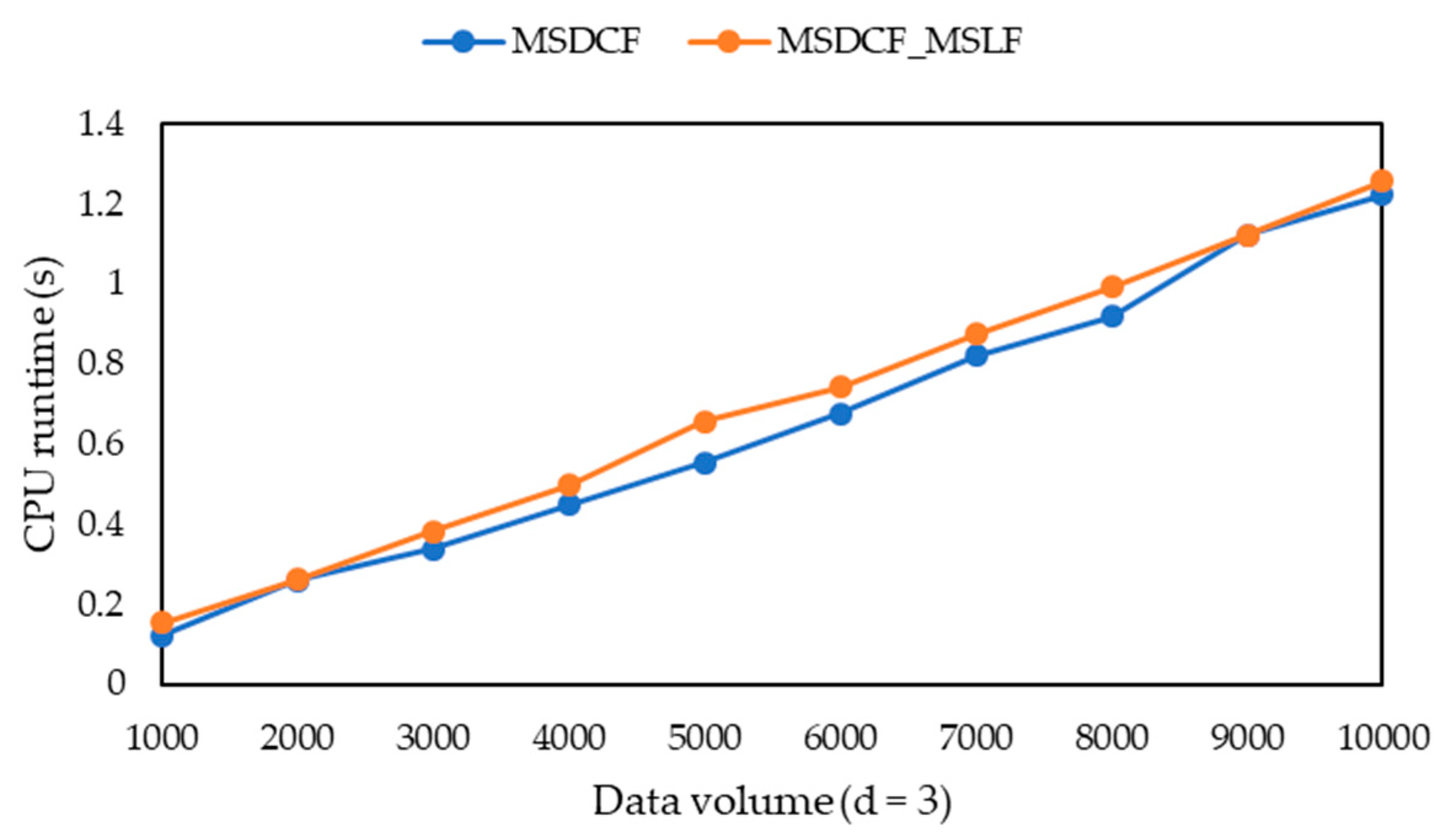
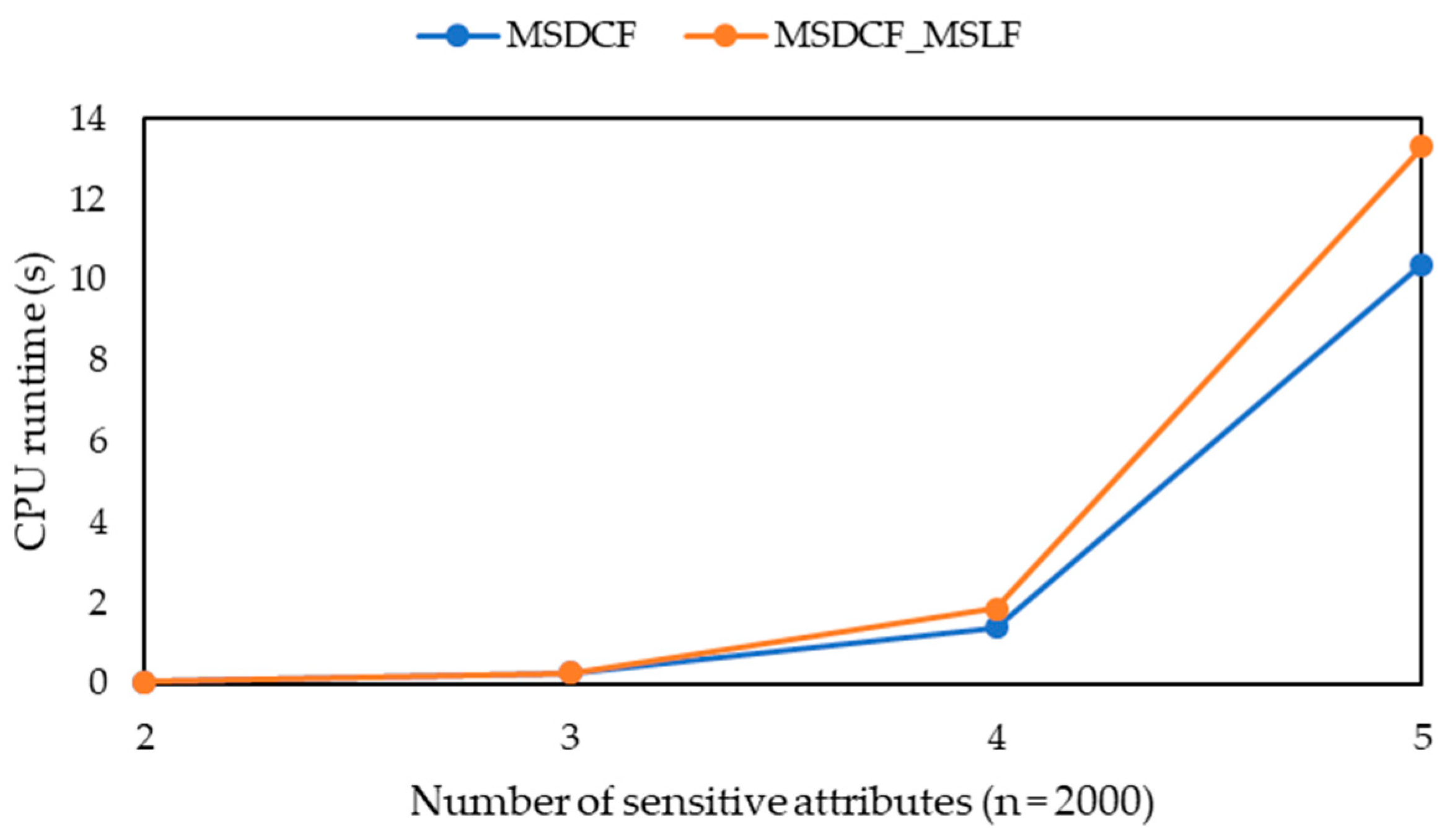
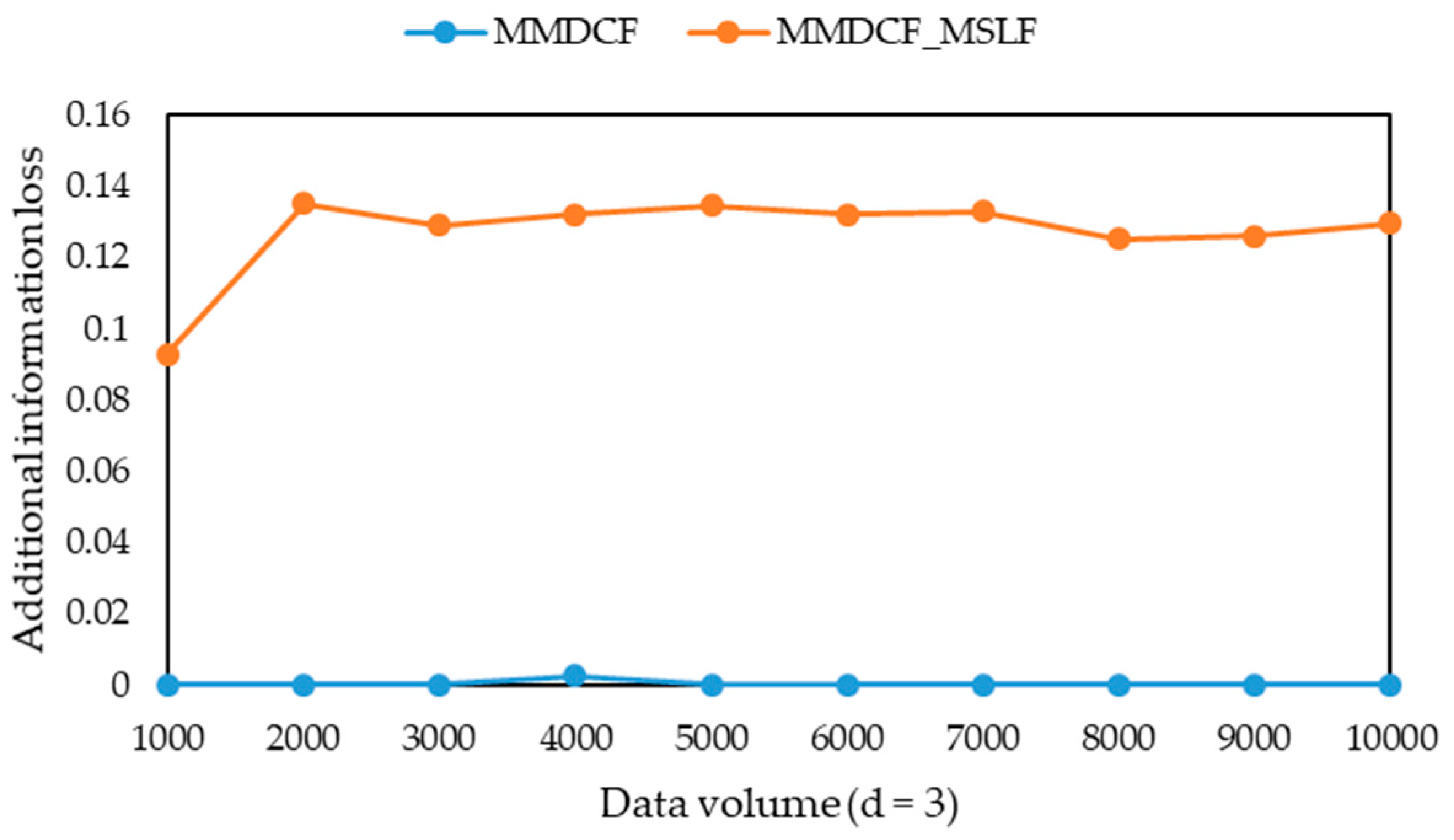
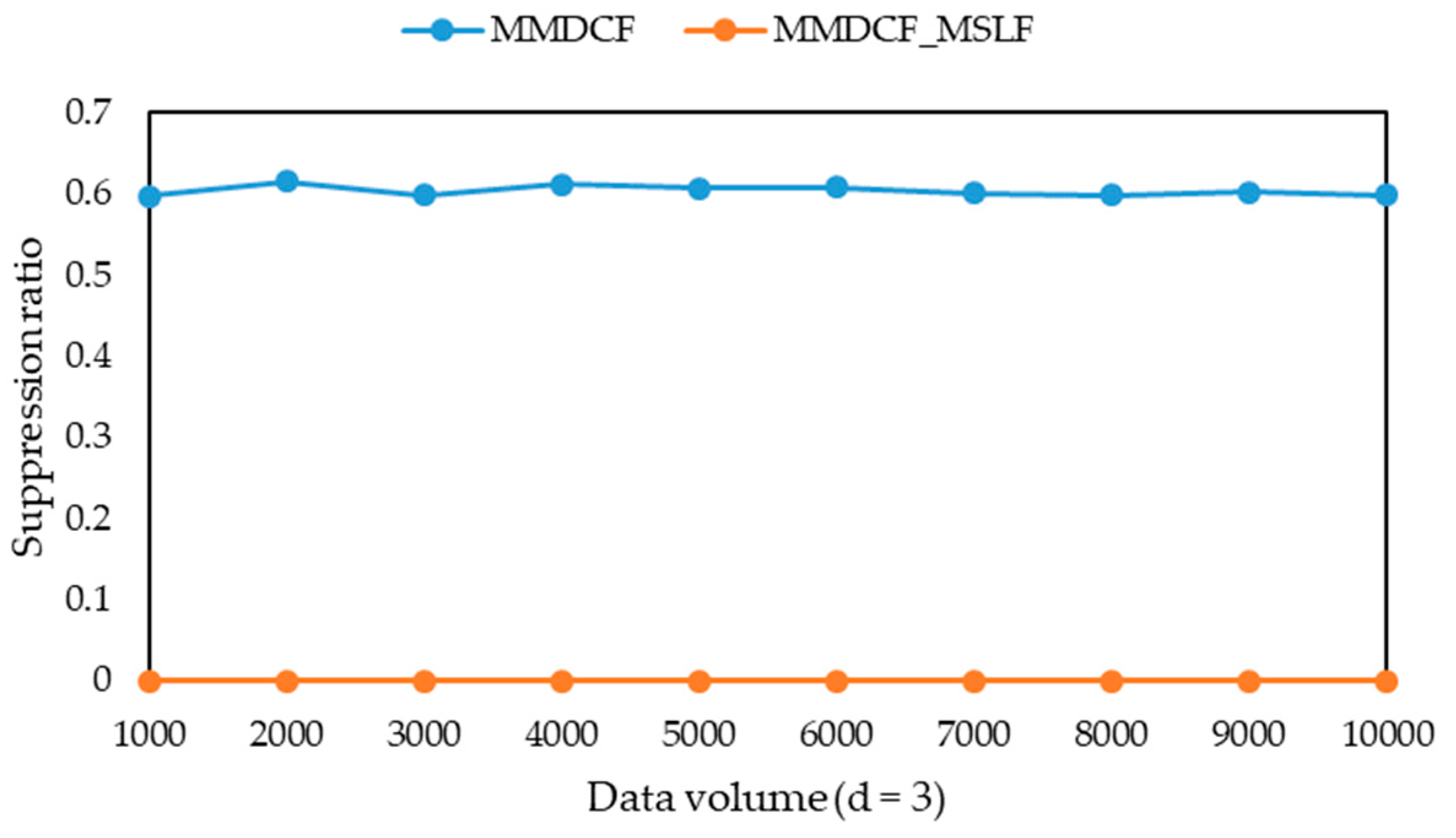
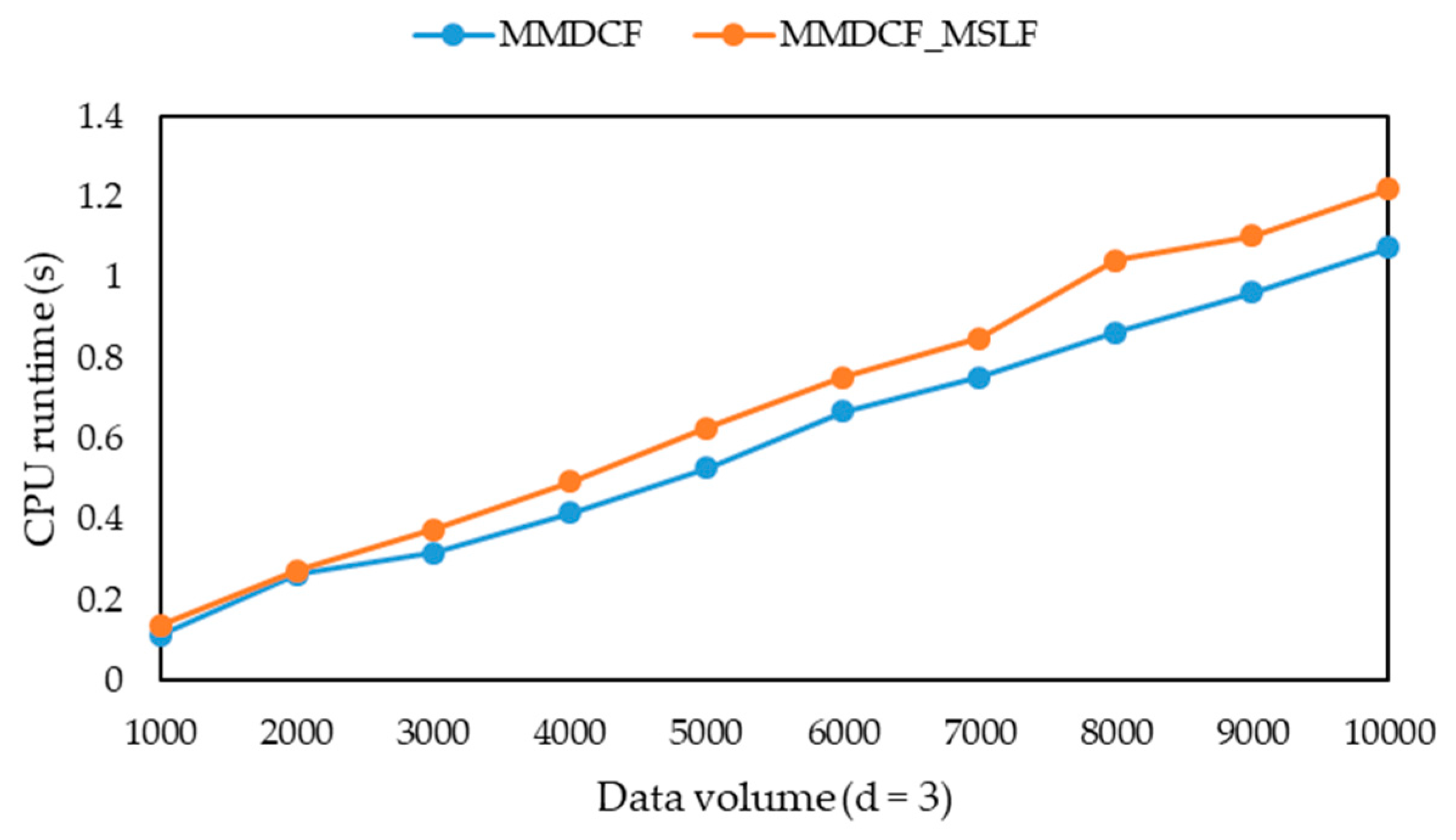
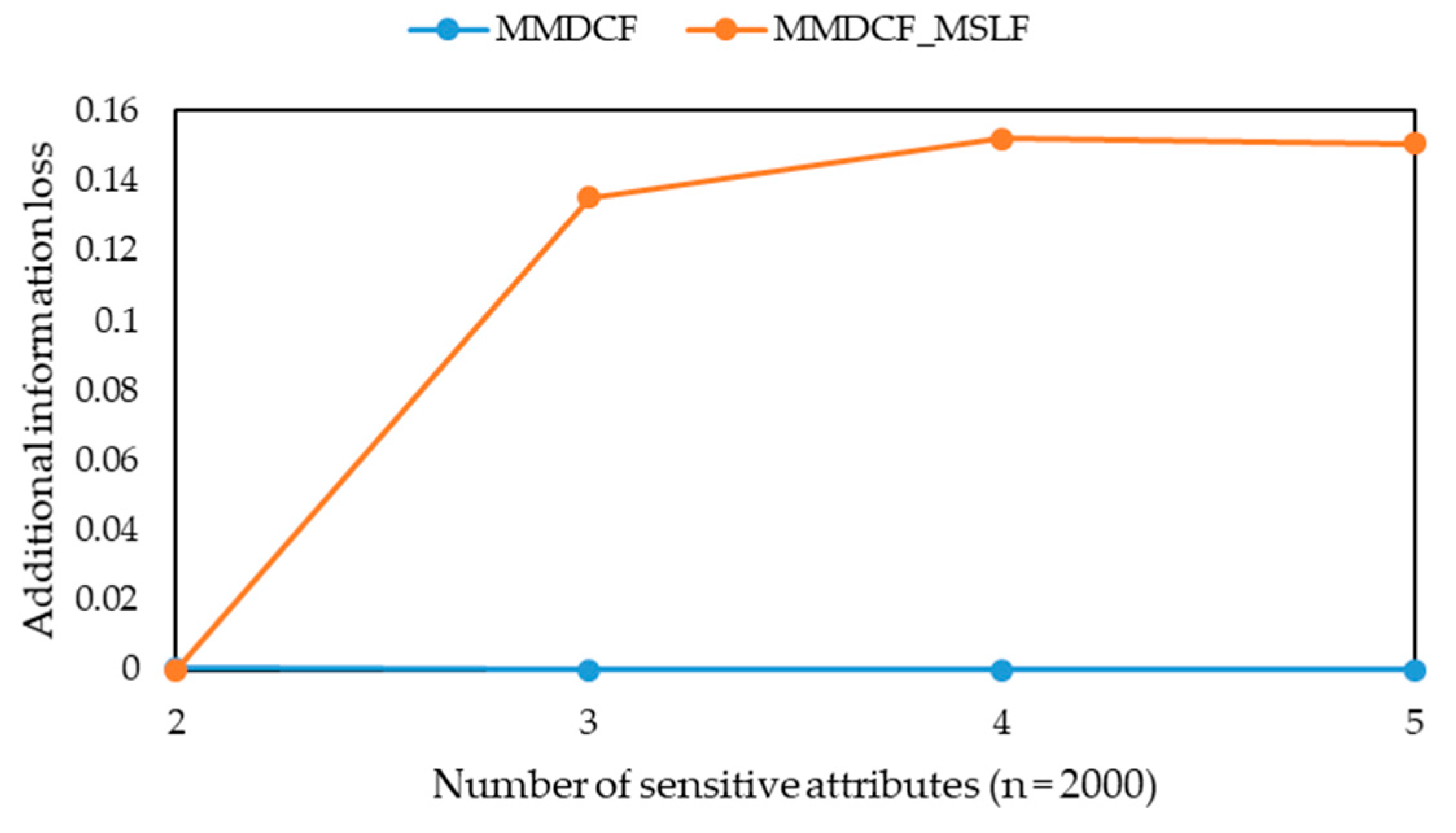
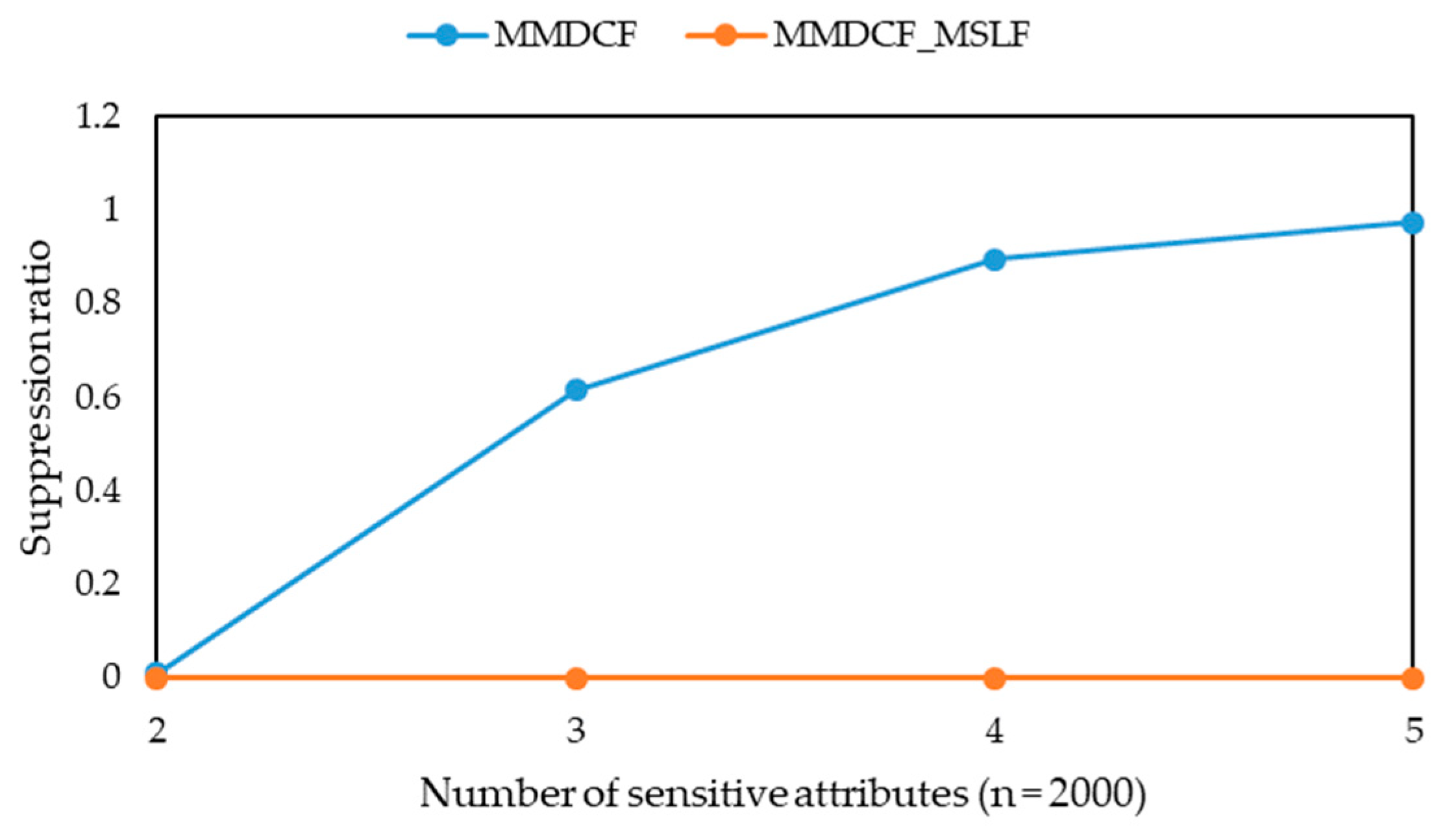
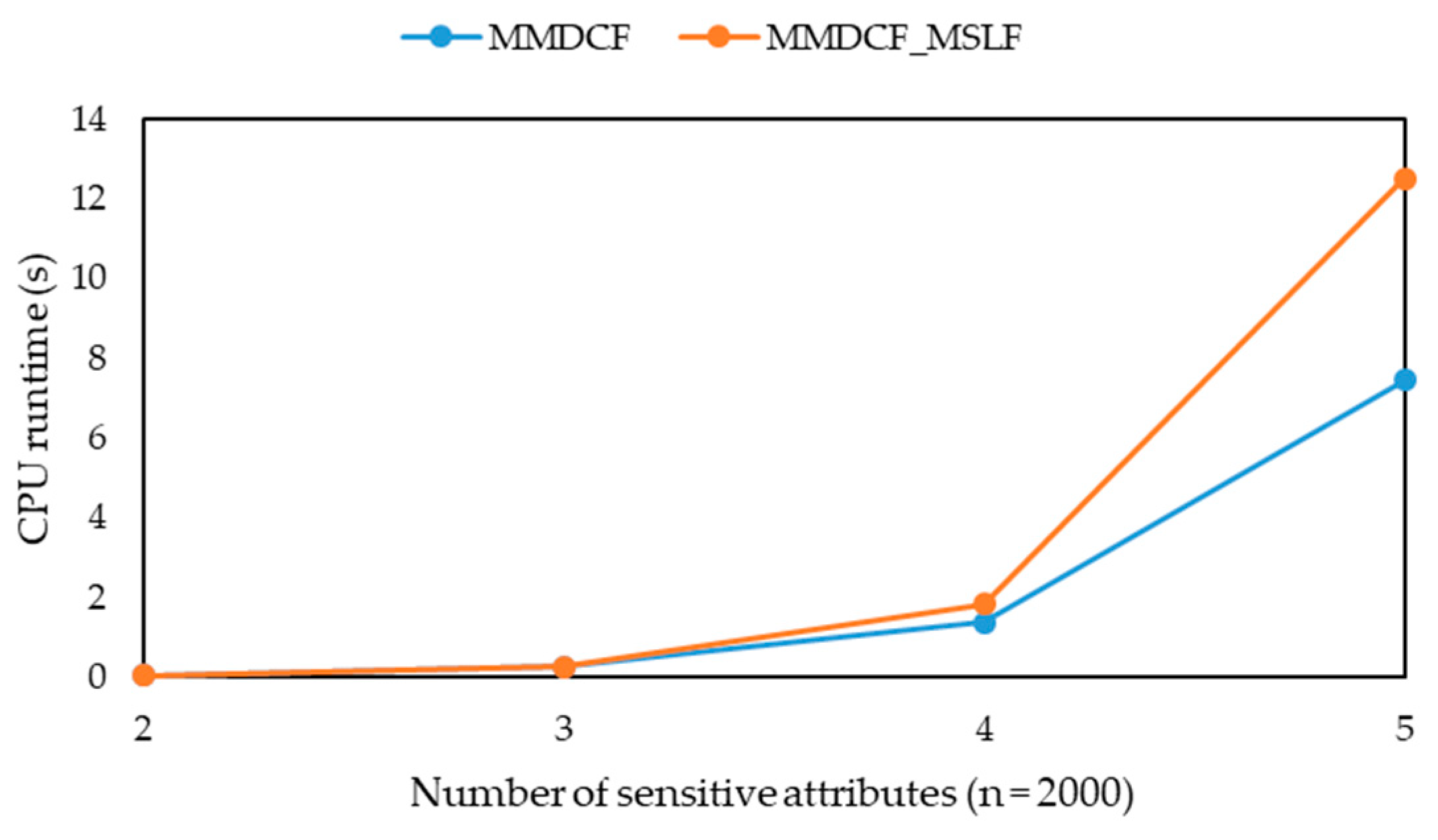
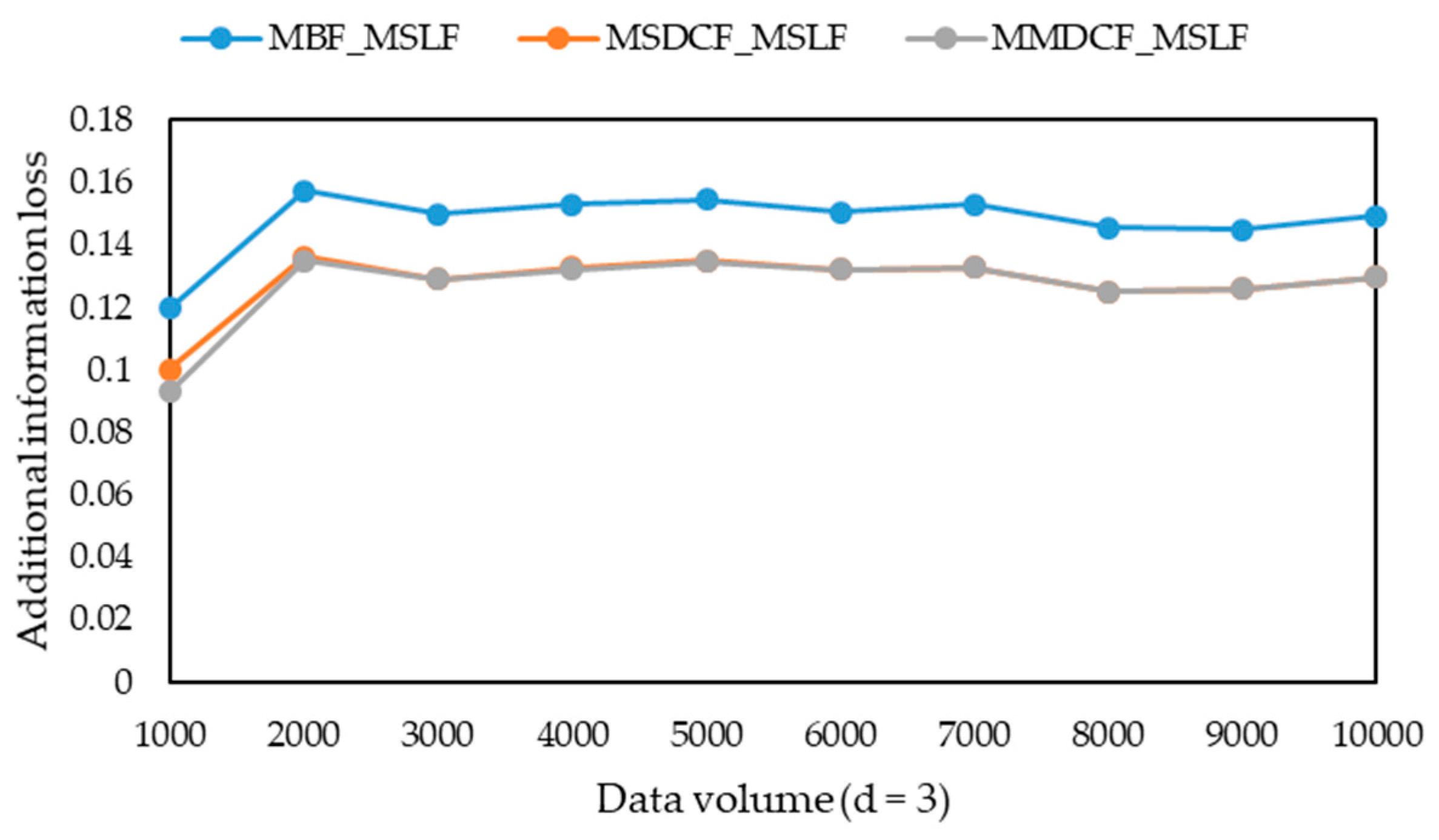
-diversity model for multiple sensitive attributes. The experimental results show that the three algorithms can greatly reduce the information loss of published microdata, but their runtime is only a small increase, and their information loss tends to be stable with the increasing of data volume. Moreover, they can solve the problem that the information loss of the MBF, MSDCF and MMDCF algorithms increases greatly with the increasing of sensitive attribute number.
The remainder of this article is organized as follows.
Section 2 provides an overview of the existing privacy preserving data publishing methods for multiple sensitive attributes. In
Section 3, we provide some notations and definitions.
Section 4 describes the three specific greed algorithms in detail. In
Section 5, we present the experimental results and analysis, and concludes the paper in
Section 6.
2. Related Works
A large variety of privacy preserving data publishing methods have been proposed for multiple sensitive attributes. In terms of the extended
k-anonymity,
l-diversity,
p-sensitive and
t-closeness methods for multiple sensitive attributes. Nidhi et al. [
11] proposed a new
k-anonymity model for multiple sensitive attributes, which realizes record suppression with minimum data distortion. Usha et al. [
12] extended the
k-anonymity model for multiple sensitive attributes, and provided several algorithms for implementation of the extended
k-anonymity model. Liu et al. [
13] proposed a new
k-anonymity algorithm for multiple sensitive attributes, which uses the distribution of sensitive attribute values as a parameter to prevent association disclosure. Wang et al. [
14] proposed a novel privacy preserving model for multiple sensitive attributes based on
k-anonymity, called (
α,
β,
k)-anonymity. They set a hierarchy sensitive attribute rule to achieve (
α,
β,
k)-anonymity and developed a corresponding algorithm to anonymize the microdata by using generalization and hierarchy. Wang et al. [
15] clustered multiple sensitive attributes based on a utility matrix, and then used a greedy strategy to partition records into equivalence classes. This method can guarantee that the size of each equivalence class is
k except the last one, and can also guarantee the diversity of each sensitive attribute value within an equivalence class.
Ahmed et al. [
16] proposed a probabilistic model of multiple sensitive attribute diversity to prevent identification or non-membership attack that arises when the microdata with multiple sensitive attributes is published. In [
17,
18,
19], a (
α,
l) model was applied to satisfy the diversity requirements for multiple sensitive attributes. Zhang et al. [
17] used anatomization with generalization and suppression based on the (
α,
l) model. Guo et al. [
18] proposed a personalized privacy preserving model for multiple sensitive attributes based on MSB, called personalized (
α,
l)-anonymity model. Li et al. [
19] considered the associations between multiple sensitive attributes to prevent all chances of the positive and negative disclosure, and used a two-step greedy generalization algorithm to manage multiple sensitive attributes. Zhu et al. [
20] proposed an addictive noise approach that publishes some anonymized tables after fulfilling the requirement of
l-diversity. This approach replaces the multiple sensitive attribute values of each record by a value set and at least
l-1 random selected noise values. Huang et al. [
21] proposed a (
v,
l)-anonymity model which checks the differences of sensitive attribute values by incorporating the classification of sensitive attribute values. And
(l1,
l2)-diversity is used to validate the model. Jin et al. [
22] proposed a
l-coverage cluster grouping model which can handle multiple sensitive attributes. And this model is based on cluster algorithm.
Gal et al. [
23] proposed a new model that extends
k-anonymity and
l-diversity to handle multiple sensitive attributes, and proposed a practical algorithm to implement this model. The algorithm used for this model contains two steps. In the first step, the microdata is divided into partitions, so that every partition contains at least
k records and satisfies
l-diversity. In the subsequent step, the microdata is anatomized. Wahyu et al. [
24] proposed a distribution model to set sensitive attribute values when
p-sensitive is applied to multiple sensitive attributes, minimizing their probability of disclosure. Wu et al. [
25] proposed a
p-cover
k-anonymity model for protecting multiple sensitive attributes, and extended the incognito algorithm [
26] to implement this model. Lin et al. [
27] proposed a novel (
k,
p)-anonymity framework to solve the disclosure problem of sensitive attributes in the
k-anonymity and
l-diversity models. Anjum et al. [
28] proposed an efficient approach for the anonymization of multiple sensitive attributes, called (
p,
k)-Angelization. The (
p,
k)-Angelization approach not only protects the privacy of the individual, but also improves the utility of the released information. Kanwala et al. [
29] proposed a privacy-preserving model for 1:M records (i.e., an individual can have multiple records) dataset with multiple sensitive attributes, called (
p,
l)- Angelization.
Wang et al. [
30] proposed two privacy-preserving algorithms for multiple sensitive attributes to satisfy the t-closeness model. The two algorithms use different methods to partition records into groups in terms of sensitive attributes. One uses a clustering method, while the other leverages a principal component analysis. Sowmyarani et al. [
31] proposes a (
p+)-sensitive,
t-closeness model for multiple sensitive attributes. It combines the advantages of the
t-closeness and the
p-sensitive
k-anonymity approaches to reduce the possibility of the similarity and skewness attacks of the anonymization techniques. Saraswathi et al. [
32] proposed an enhanced
t-closeness algorithm for multiple sensitive attributes. In the algorithm,
t-closeness is applied over MSB
k-anonymity clustering attribute hierarchy (MSB-KACA) algorithm. And they used earth mover distance (EMD) to avoid probabilistic inference attack due to bucketization.
In terms of the extended anatomy methods combining MSB, clustering, generalization or permutation for multiple sensitive attributes, Yang et al. [
33] proposed an MSB approach. The main idea of the MSB approach is to partition the given table into a quasi-identifier attribute table and a sensitive attribute table, and to make that each sensitive attribute satisfies the
l-diversity constraints. Lin et al. [
34] proposed a technique to handle multiple numerical sensitive attributes and to eliminate the threat of proximity breach for multiple sensitive attributes. They applied clustering and MSB techniques to release the microdata with multiple numerical sensitive attributes. Luo et al. [
35] proposed an improved framework for multiple sensitive attributes, named anatomy and generalization on multiple sensitive attributes (ANGELMS). This approach vertically partitions the attributes into one quasi-identifier attribute table and several sensitive attribute tables. Each sensitive attribute table divides the records of the microdata into groups (i.e., buckets). Each bucket obeys the
l-diversity requirement. In the quasi-identifier attribute table, each group generalizes the quasi-identifier attribute values by following the
k-anonymity principle. Ye et al. [
36] proposed an anonymization method combining anatomy and permutation for protecting privacy of the microdata with multiple sensitive attributes. This method includes two major steps: anatomizing microdata and permutating quasi-identifier attributes. To realize the anonymization method, they further proposed two algorithms, namely naive multi-sensitive bucketization permutation algorithm (NMBPA) and closest distance multi-sensitive bucketization permutation algorithm (CDMBPA).
In terms of the extended slicing methods for multiple sensitive attributes, Dhumal et al. [
37] applied the slicing technique without permuting the values of multiple sensitive attributes and did not consider the quasi-identifier attributes while proposing this technique. Kiruthika et al. [
38] proposed some enhanced slicing techniques like Mondrian and suppression slicing. Mondrian slicing randomly switches all the buckets whereas suppression slicing permutes the quasi-identifier attribute values of the records. Suppression slicing maintains the microdata’s utility by guaranteeing the
l-diversity principle in each quasi-identifier attribute group. Luo et al. [
39] extended the slicing technique from single sensitive attribute to multiple sensitive attributes, which is called slicing on multiple sensitive (SLOMS). Further, they proposed an MSB-KACA algorithm to anonymize the microdata with multiple sensitive attributes by SLOMS. In [
40], a dynamic data publishing technique for multiple sensitive attributes was proposed, named the KC slice. The proposed technique integrates the features of LKC-privacy and slicing techniques. Raju et al. [
41] proposed a novel dynamic KCi-Slice publishing prototype for retaining the privacy and utility of multiple sensitive attributes, which is an improvement of KC-Slice. Reddy et al. [
42] proposed a privacy preserving data publishing model that manages personalization for publishing the microdata with multiple sensitive attributes. The model uses the slicing technique supported by deterministic anonymization for quasi-identifier attribute, i.e., generalization for categorical sensitive attributes and fuzzy approach for numerical sensitive attributes based on diversity. Susan et al. [
43] conducted a work which combined the anatomy and slicing techniques for multiple sensitive attributes, called anatomization with slicing for multiple sensitive attributes (SLAMSA). They used anatomization to reduce information loss and enhanced the slicing technique to improve attribute correlation.
In terms of the decomposition methods for multiple sensitive attributes, Ye et al. [
44] proposed a decomposition technique to achieve
l-diversity for multiple sensitive attributes. In the decomposition technique, vertical partitioning of multiple sensitive attributes is done that divides the original table into two tables, i.e., a sensitive table and a non-sensitive table. But adding noise in the decomposition technique causes distortion. Hence, Das et al. [
45] extended the decomposition technique by optimizing the noise value selection (i.e., choosing the noise value closer to the original values), called decomposition plus.
The above methods for multiple sensitive attributes do not consider the sensitive requirements of sensitive attributes. Because different sensitive attributes may have different sensitivity requirements, Liu et al. [
46] introduced a rating technique for multiple sensitive attributes, which is based on different sensitivity coefficients for different attributes. This approach not only protects privacy for multiple sensitive attributes, but also keeps a large amount of correlations of the microdata. But the rating technique can be attacked by applying association rules due to the relationship between sensitive attribute values. Yi et al. [
47] removed the weaknesses of the rating technique and eliminated the threat of association attack.
3. Notations and Definitions
In the real world, different values of a sensitive attribute may have different sensitivity requirements. Some values of the sensitive attribute have no sensitivity requirement, i.e., these sensitive attribute values do not need to be protected because their leakage is not harmful to the individual. Some values of the sensitive attribute have low sensitivity requirement, i.e., these sensitive attribute values need to be protected to some extent because their leakage cause certain harm to the individual. Furthermore, some values of the sensitive attribute have high sensitivity requirement, i.e., these sensitive attribute values need to be well protected because their leakage cause serious harm to the individual. Accordingly, three sensitive attribute security levels are defined as follows.
Definition 1 (sensitive attribute security Level 0). Sensitive attribute security Level 0 is the security level of a sensitive attribute value with no sensitivity requirement, i.e., a sensitive attribute value with sensitive attribute security Level 0 have no sensitivity requirement.
Definition 2 (sensitive attribute security Level 1). Sensitive attribute security Level 1 is the security level of a sensitive attribute value with low sensitivity requirement, i.e., a sensitive attribute value with sensitive attribute security Level 1 have low sensitivity requirement.
Definition 3 (sensitive attribute security Level 2). Sensitive attribute security Level 2 is the security level of a sensitive attribute value with high sensitivity requirement, i.e., a sensitive attribute value with sensitive attribute security Level 2 have high sensitivity requirement.
Let
be the microdata, where
denotes the
th quasi-identifier attribute and
,
denotes the
th sensitive attribute and
,
denotes the number of quasi-identifier attributes and
denotes the number of sensitive attributes,
denotes the number of records of
(i.e.,
),
denotes the
th record of
and
, and
denotes the value of the attribute
of the
th record. An example of the microdata is shown in
Table 1.
In
Table 1, social security number (SSN) and name are two identifier attributes. Age, sex, race and zipcode are four quasi-identifier attributes. Further, physician and disease are two sensitive attributes.
,
,
,
,
,
,
,
and
are nine records of the microdata. The values of the sensitive attribute physician are John, Bob, Anne, Sam and Mary. Following this, the values of the sensitive attribute disease are flu, pneumonia, gastritis, human immunodeficiency virus (HIV) and cancer. For the former, the security levels of all sensitive attribute values can be set to sensitive attribute security Level 1 because these sensitive attribute values have the same and low sensitivity requirement. For the latter, the security level of flu can be set to sensitive attribute security Level 0 because the sensitive attribute value has no sensitivity requirement. The security levels of Pneumonia and Gastritis can be set to sensitive attribute security Level 1 because the two sensitive attribute values have the same and low sensitivity requirement. Further, the security levels of HIV and cancer can be set to sensitive attribute security Level 2 because the two sensitive attribute values have the same and high sensitivity requirement.
Definition 4 (composite sensitive attribute) [33]. A composite sensitive attribute is the whole of all sensitive attributes of, denoted by, where theth sensitive attribute() is theth dimension of the composite sensitive attribute.is the value field of, andrepresents the number of.
Definition 5 (composite sensitive attribute vector) [33]. A composite sensitive attribute vector is a vector form of all sensitive attribute values of theth recordin, denoted by.
Definition 6 (group) [33]. A group is a subset of records of. each record ofbelongs to only one group. All groups ofis denoted as, wheredenotes the number of all groups of.
For
Table 1, the composite sensitive attribute of the microdata is {Physician, Disease}, and a composite sensitive attribute vector can be <John, Flu>.
,
and
can be three groups of the microdata, and
.
Definition 7 (l-diversity for single sensitive attribute) [33]. For a groupwith single sensitive attribute, ifis the sensitive attribute value with the maximum frequency and, wheredenotes the frequency of,denotes the number of records of, thensatisfies-diversity for single sensitive attribute.
Definition 8 (l-diversity for multiple sensitive attributes) [33]. For a groupwith multiple sensitive attributes, if each sensitive attribute of the composite sensitive attribute insatisfies-diversity for single sensitive attribute, thensatisfies-diversity for multiple sensitive attributes.
Definition 9 (l-diversity group for multiple sensitive attributes) [33]. An-diversity group for multiple sensitive attributes is a group ofand the group satisfies-diversity for multiple sensitive attributes. All-diversity groups for multiple sensitive attributes are denoted as, wheredenotes the number of all-diversity groups for multiple sensitive attributes.
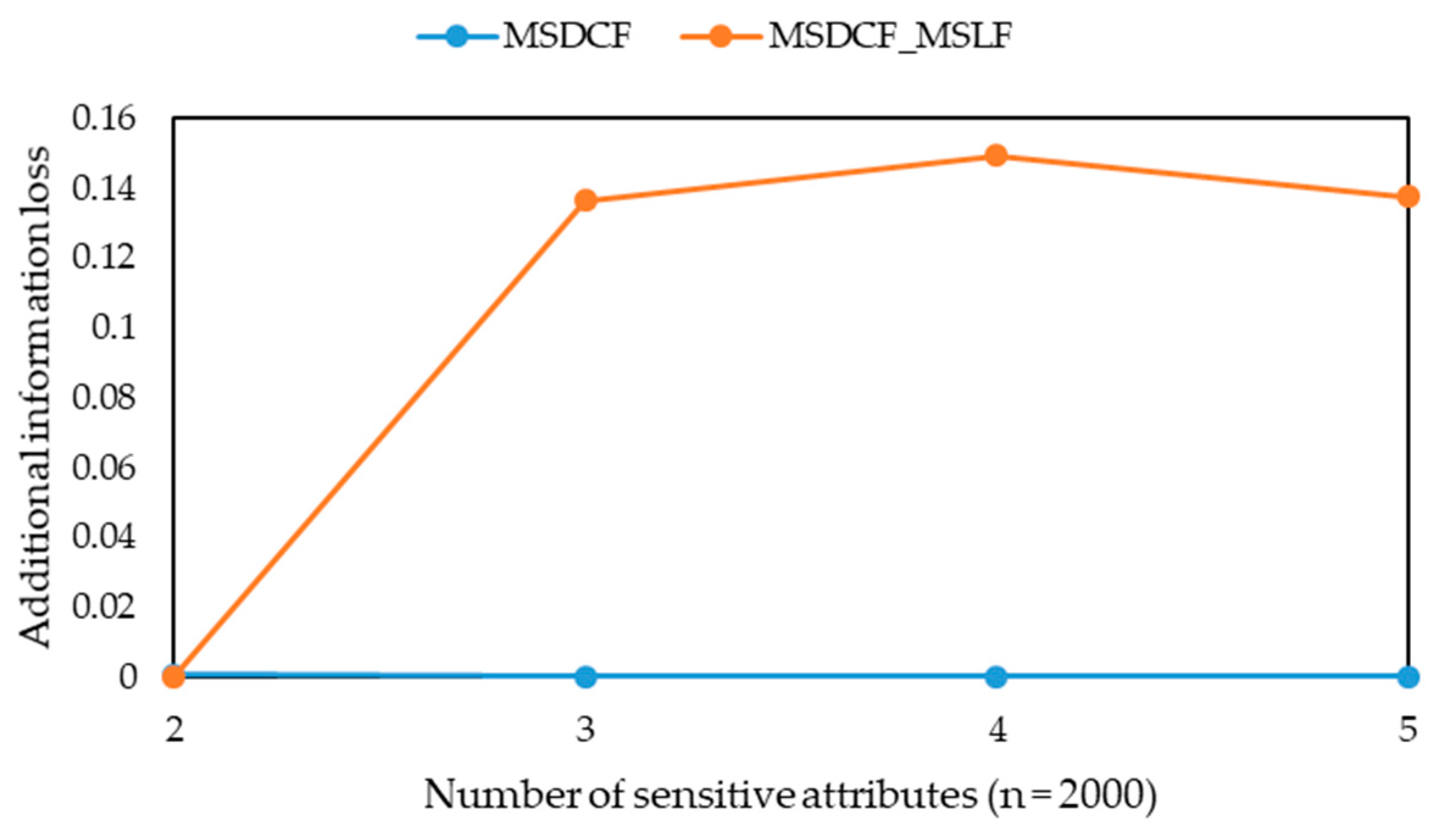
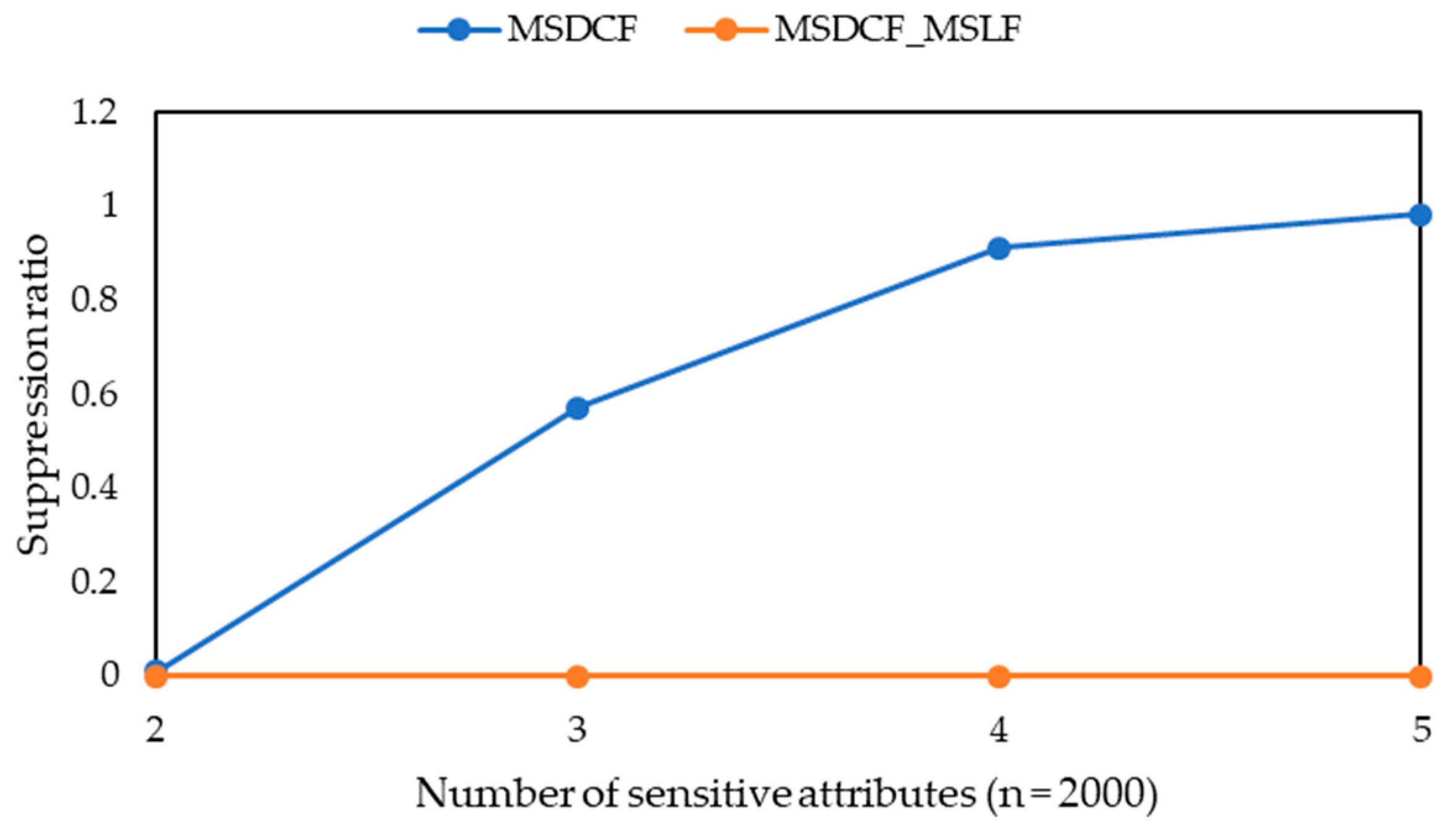
From Definitions 7, 8 and 9, all the sensitive attribute values of each group obey the same l-diversity requirement, i.e., the same sensitive requirement is applied to them. This is not appropriate and will cause extra information loss of the microdata. Because the maximal security level of sensitive attribute values in the microdata shown in
Table 1 is sensitive attribute security Level 2, so
is set to 3 in this paper. Thus, only three diversity groups for multiple sensitive attributes can be formed. For different sensitive attribute values with different sensitive attribute security levels, they should have different
l-diversity requirements because they have different sensitivity requirements. Hence,
-diversity for single sensitive attribute and
-diversity for multiple sensitive attributes are defined as follows, where
,
for sensitive attribute security level 0,
for sensitive attribute security Level 1,
for sensitive attribute security Level 2, and
are set to 1, 2 and 3 in this paper, respectively.
Definition 10 (-diversity for single sensitive attribute). For a groupwith single sensitive attribute, ifis a sensitive attribute value with sensitive attribute security level 0 of, then, wheredenotes the frequency ofin,denotes the number of records in. Similarly, ifis a sensitive attribute value with sensitive attribute security level 1 of, then, wheredenotes the frequency ofin. Further, ifis a sensitive attribute value with sensitive attribute security level 2 of, then, wheredenotes the frequency ofin. Then,satisfies-diversity for single sensitive attribute.
Definition 11 (-diversity for multiple sensitive attributes). For a groupwith multiple sensitive attributes, if each sensitive attribute of the composite sensitive attribute insatisfies-diversity for single sensitive attribute, thensatisfies-diversity for multiple sensitive attributes.
Definition 12 (-diversity group for multiple sensitive attributes). An-diversity group for multiple sensitive attributes is a group ofand the group satisfies-diversity for multiple sensitive attributes. All-diversity groups ofis denoted as, wheredenotes the number of all-diversity groups of.
For
Table 1, as described above, the security levels of all values of the sensitive attribute Physician is sensitive attribute security Level 1. Further, the security level of Flu is sensitive attribute security Level 0, the security levels of pneumonia and gastritis are sensitive attribute security Level 1, and the security levels of HIV and Cancer are sensitive attribute security Level 2. Any record of the microdata shown in
Table 1 consists of one value of the sensitive attribute physician and one value of the sensitive attribute disease. As a result,
includes at least
, so
-diversity groups for multiple sensitive attributes,
-diversity groups for multiple sensitive attributes,
-diversity groups for multiple sensitive attributes and
-diversity groups for multiple sensitive attributes can be formed.
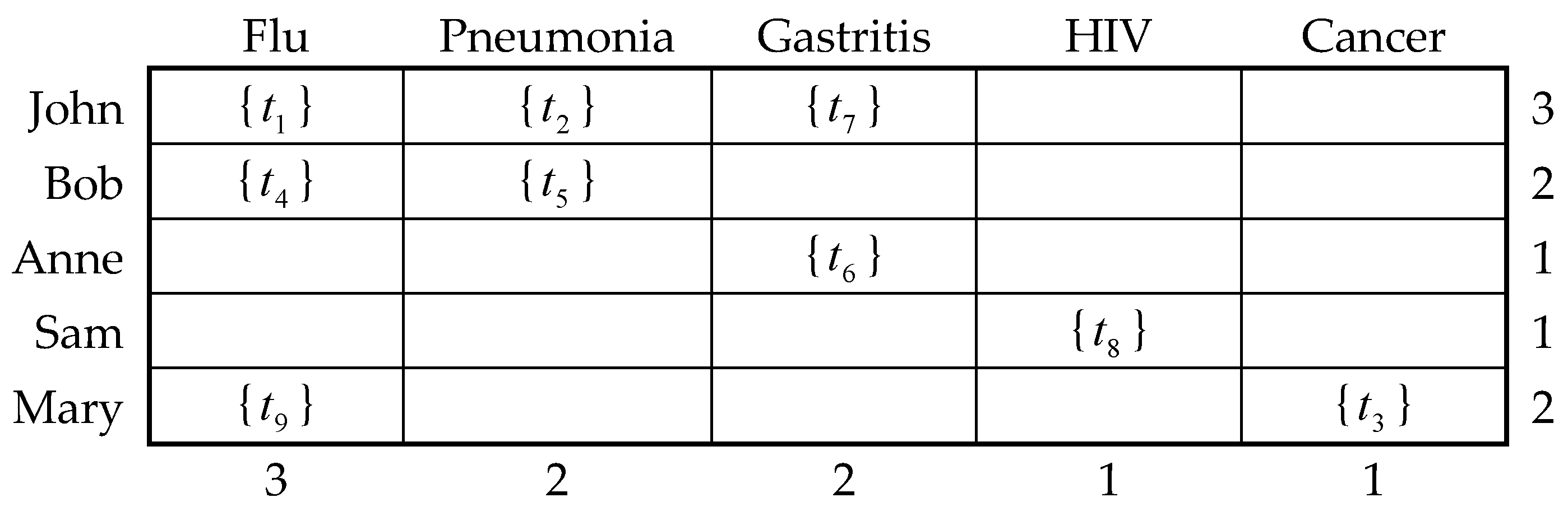
Definition 13 (multiple dimensional bucket) [33]. A multiple dimensional bucket is a bucket that each dimension of the composite sensitive attribute is one of dimensions of the bucket. Therefore, the records ofcan be mapped to corresponding buckets according to the sensitive attribute values of each dimension of their composite sensitive attribute vectors. If the number of dimensions of the composite sensitive attribute inis, thendimensional buckets ofcan be established, denoted as, where eachdimensional bucket is denoted as,and, and the size of eachdimensional bucket of is denoted as, i.e., the number of records in thedimensional bucket. Further, the dimension capacity of a certain valueon thedimension of thedimensional bucket is the sum of all the bucket sizes with the certain valueon this dimension, denoted as.
According to
Table 1, two-dimensional buckets of
can be established, as shown in
Figure 1.
In
Figure 1, the leftmost column is the values of the sensitive attribute physician, and the top row is the values of the sensitive attribute disease. The rightmost column is the dimension capacities of the values of the sensitive attribute physician, and the bottom row is the dimension capacities of the values of the sensitive attribute disease. Further, the five rows and five columns in the middle are 2-dimensional buckets of
. For example, when
is Anne and
is gastritis,
is a certain two-dimensional bucket, i.e., {
} in
Figure 1, and
is the size of
and
.
is the dimension capacity of
and
, and
is the dimension capacity of
and
.
In [
33], the MSB method includes two stages: grouping phase and residual processing phase. In the first stage, according to a greedy strategy,
l buckets with different values on each dimension are selected, and one record is extracted from each bucket to form an
l-diversity group for multiple sensitive attributes, which circulates until it cannot form a new
l-diversity group for multiple sensitive attributes that meets the requirements. In the second stage, for the remaining records in the multi-dimensional buckets after grouping, add them to the existing
l-diversity groups for multiple sensitive attributes as much as possible without destroying
l-diversity for multiple sensitive attributes. Finally, records that do not belong to any
l-diversity group for multiple sensitive attributes are suppressed from the published microdata. After the above steps, the quasi-identifier attributes of each
l-diversity group for multiple sensitive attributes are published as a quasi-identifier attribute table, and the sensitive attributes of each
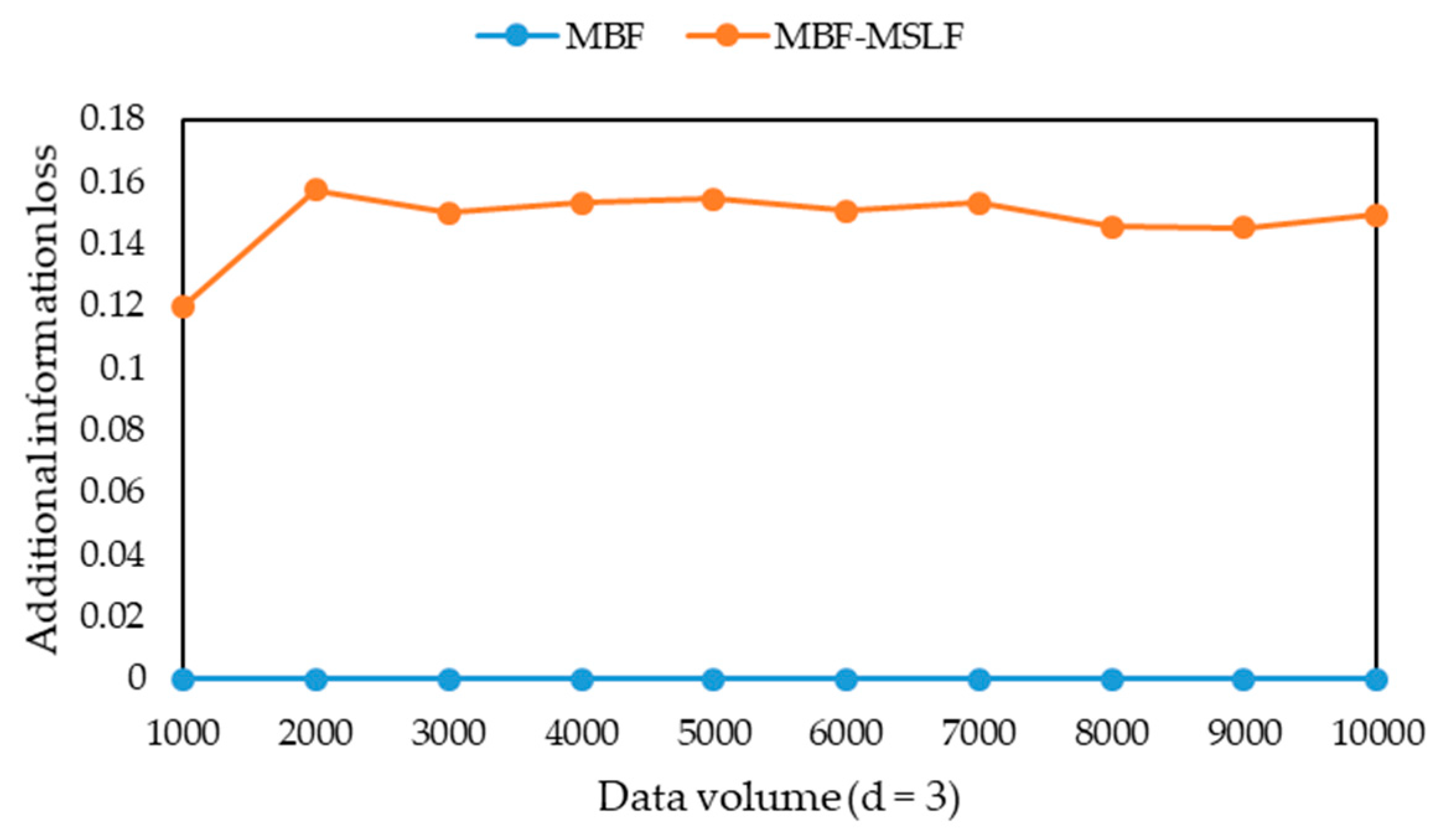
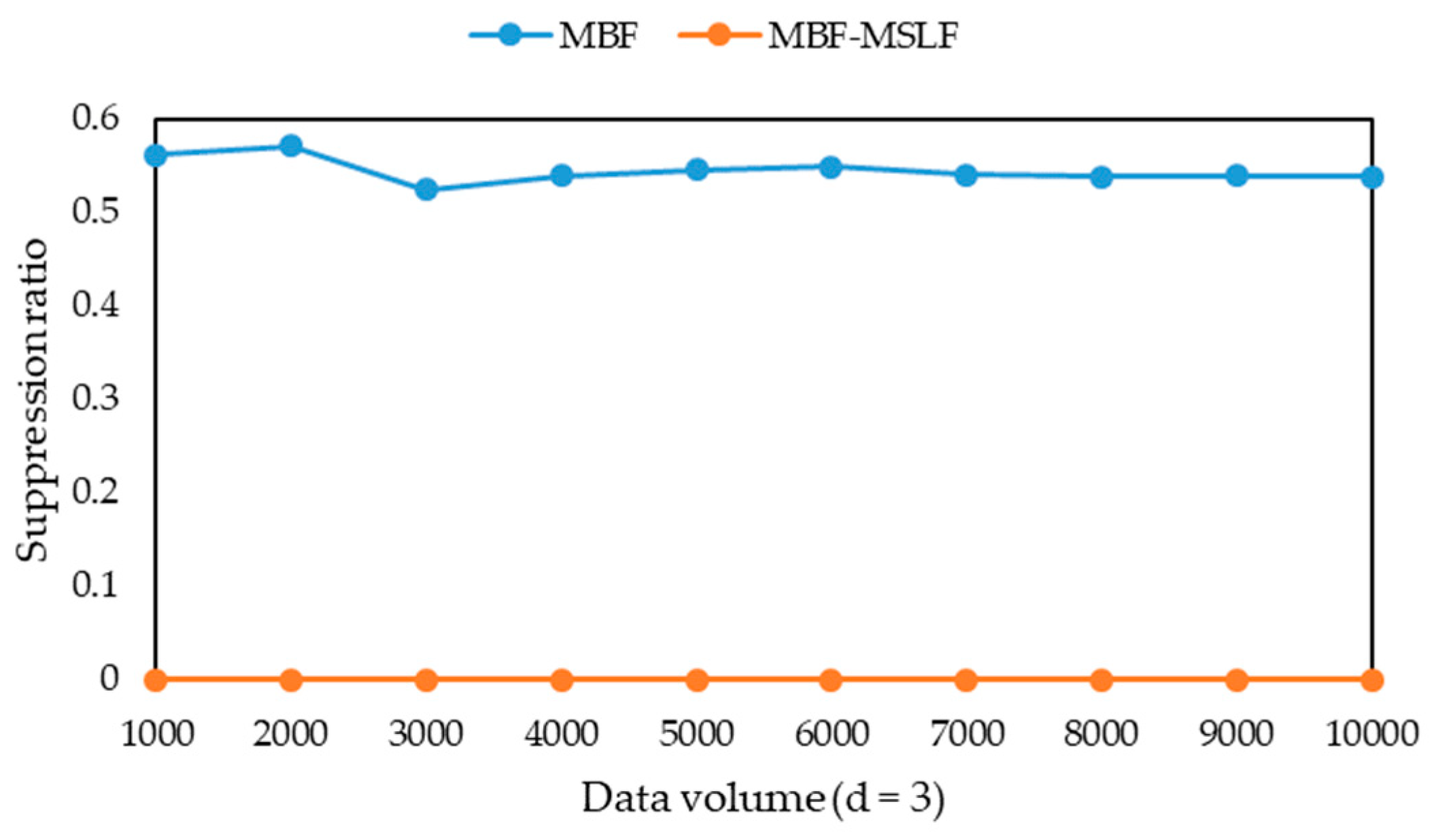
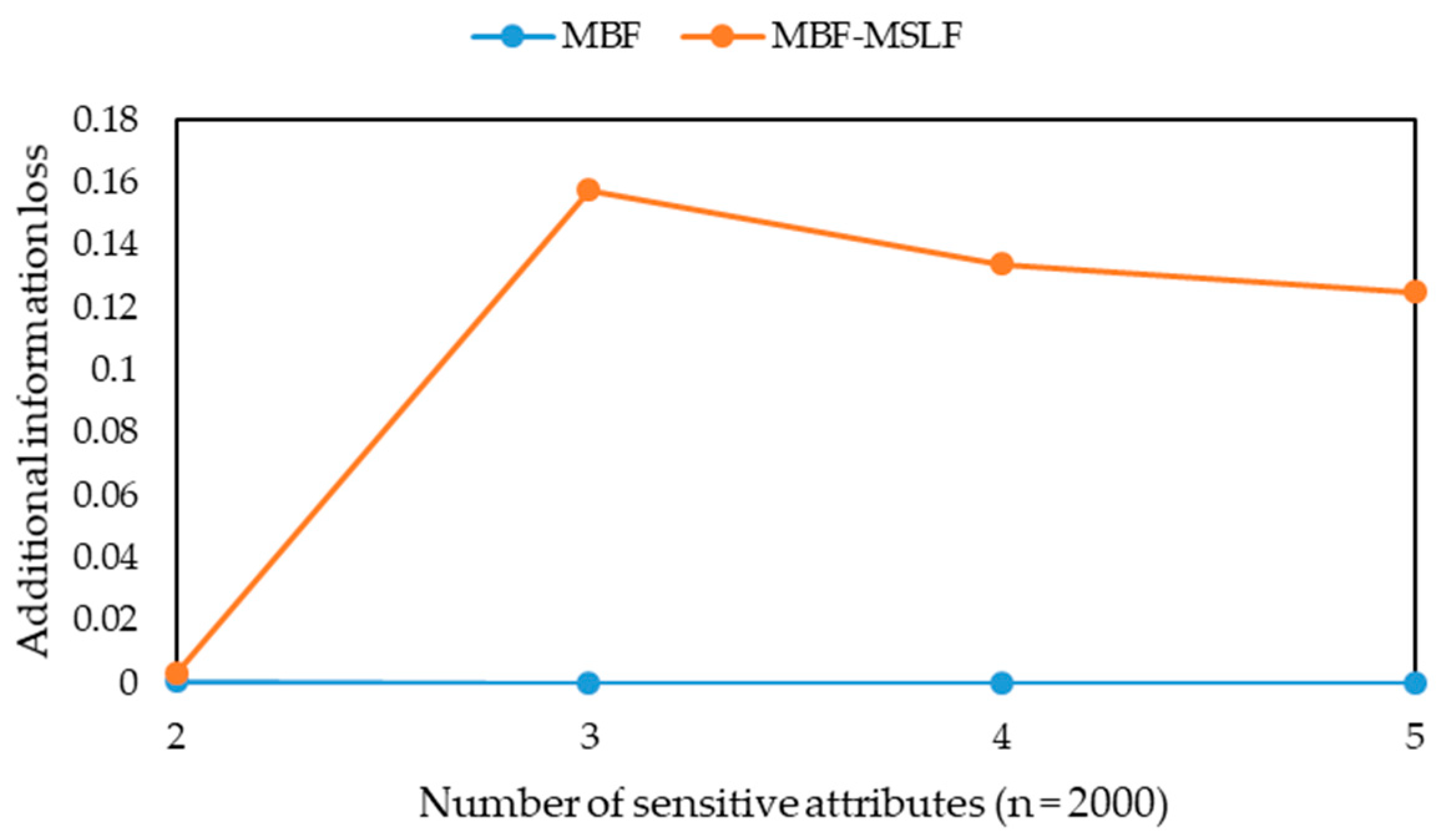
l-diversity group for multiple sensitive attributes are published as a sensitive attribute table. Further, both the additional information loss and the suppression ratio are taken as the standard to measure the quality of the published microdata. The definition of additional information loss is extended as follows.
Definition 14 (additional information loss). Forof, its additional information loss is, wheredenotes the number of records in, anddenotes the l value for the maximal sensitive attribute security level of sensitive attribute values in.
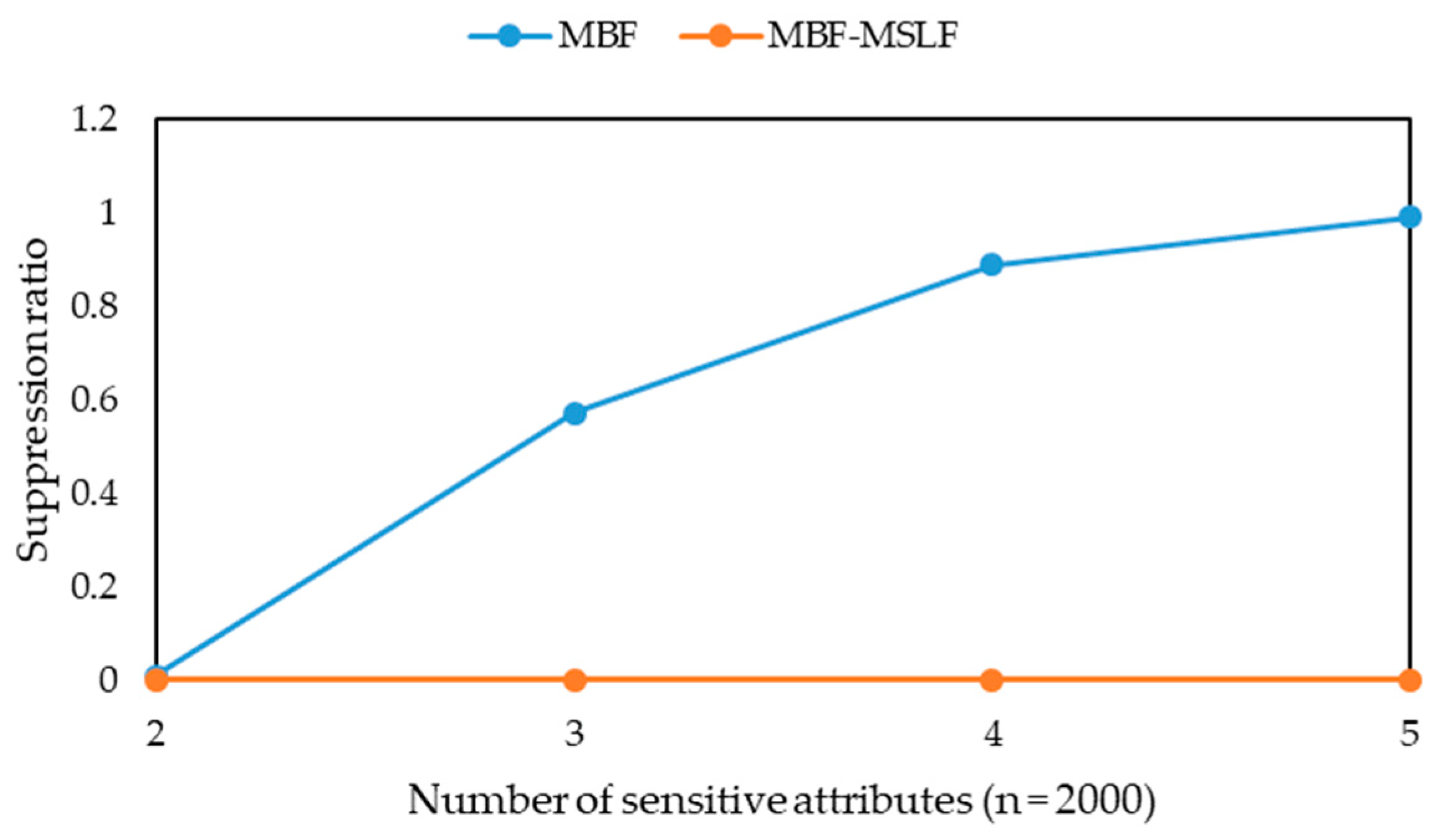
Definition 15 (suppression ratio) [33]. After generatingof, the suppression ratio of T is, wheredenotes the number of suppressed records of.
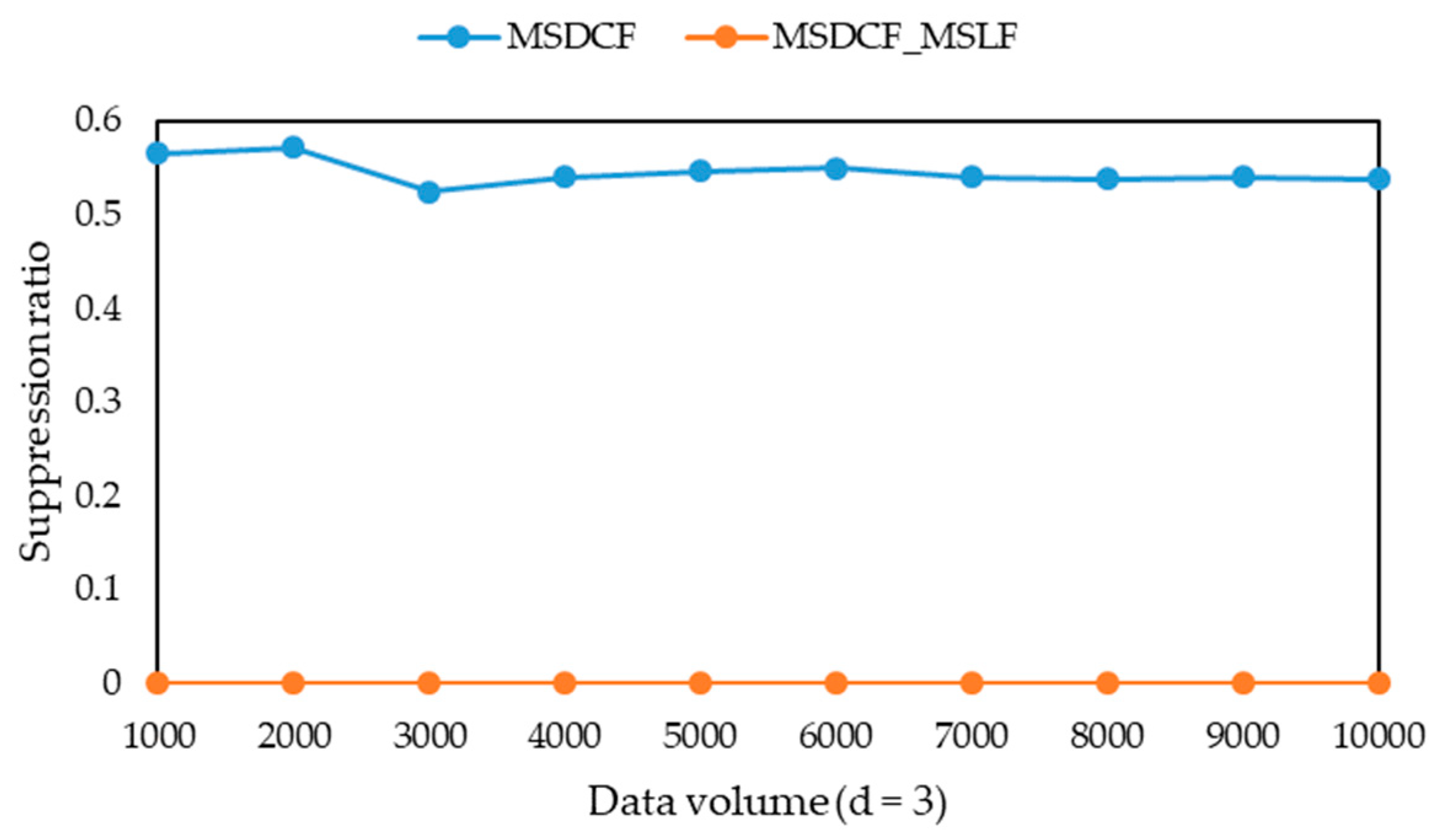
Obviously, the smaller the suppression ratio is, the less records are lost. When the suppression ratio is the same, the smaller the additional information loss, the less information is lost.





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}