1. Introduction
Robust information about the emotional state of a user is key to providing an empathetic experience during human–machine interaction (HCI) [
1]. To make the interaction go well, it is important to ensure that the computers can understand the feelings of users through the interaction process [
2]. In recent decades, emotion recognition has become a significant field in HCI, and it has been applied in a wide range of areas such as usability testing, development process improvement, enhanced website customization, and video games [
3].
In the study of emotion recognition, different data resources have been applied, including facial and body expressions, eye gaze, audio signals, physiological signals (ECG, EEG, and EDA/GSR), respiration amplitude, and skin temperature [
4]. Among these data resources, physiological signals have been paid more attention in studies recently, as they can reflect the emotional states objectively, while expressions and body motions can be influenced by subjective behavior and therefore misleading. In the research on emotion recognition based on physiological signals, studies have come up with a subject-dependent method [
5]. In this field, subject-dependent means that the source of data comes from the same person. After decades of research, the subject-dependent method has achieved an accuracy of more than 90% [
6]. However, the subject-dependent model is not satisfying on robustness and universality, as the performance shows instability when moving from experiment participants to the general population [
7]. Hence, some researchers have started to focus on the subject-independent method, where the data is acquired from multiple persons. Compared to the subject-dependent method, the great generality determines that the subject-independent approaches perform better on different subjects. Until now, researchers still haven’t achieved a satisfying recognition accuracy [
8,
9,
10,
11]. Circumventing this problem, we make great attempts on subject-independent emotion recognition in this work.
Many studies in the past years have focused on physiological signals, such as EEG [
12,
13], ECG [
14,
15], and EDA [
9,
10]. Compared with other physiological signals, EDA can be measured on the skin surfaces of hands and wrists in a non-invasive way. Benefiting from this easy and efficient acquisition method, the EDA-based emotion recognition algorithm has a broad application prospect in the development of sensors, Internet of Things (IoT), and intelligent wearable devices. Moreover, EDA is controlled by the autonomic nervous system, which corresponds to the arousal state of people [
16]. On the other aspect, EDA has fewer channels and data, compared to EEG signals. Therefore, making full use of the limited EDA data is a great challenge in the field of EDA-based emotion recognition.
The methods of physiological-signal-based emotion recognition can be classified into two types based on how features are extracted: Hand-crafted feature selection and auto feature extraction. In the first method, hand-crafted features can be extracted in the time domain, the frequency domain, the time-frequency domain, etc. [
17]. After that, the hand-crafted features are fed into classifiers such as KNN [
18] and SVM [
19]. However, the formula of feature extraction is established manually, which means that it cannot extract other unknown important features. The method based on auto feature extraction can solve the defect of hand-crafted feature selection. It utilize deep learning networks, which can extract implicit and complex features automatically. In the field of emotion recognition based on physiological signals, an increasing amount of advanced research uses the auto feature extraction method rather than hand-crafted feature selection for its advantages mentioned above. Hence, we choose the auto feature extraction method utilizing deep learning model.
According to the ability of utilizing sequential messages, deep neural networks can be divided into Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). As EDA is a sequence in the time domain essentially, we intuitively conduct an RNN to mine the sequential relationships between different periods of EDA signals. Meanwhile, the CNN has achieved great performance in sequential classification tasks, such as video classification [
20,
21] and audio classification [
22,
23]. Therefore, it is necessary to compare CNN and RNN models as regards EDA-based emotion recognition. Considering the descriptive powers of CNNs and the ability to capture sequential features of RNNs, researchers have also combined the advantages of CNNs and RNNs to propose hybrid CNN+RNN networks, the effectiveness of which has been demonstrated in language identification [
24], video-based emotion recognition [
25], etc. To the best of the authors’ knowledge, no previous study has tackled a systematic comparison of the three above-mentioned networks. Hence, we seek to compare the performance of CNN, RNN, and CNN+RNN on EDA-based emotion recognition in this paper.
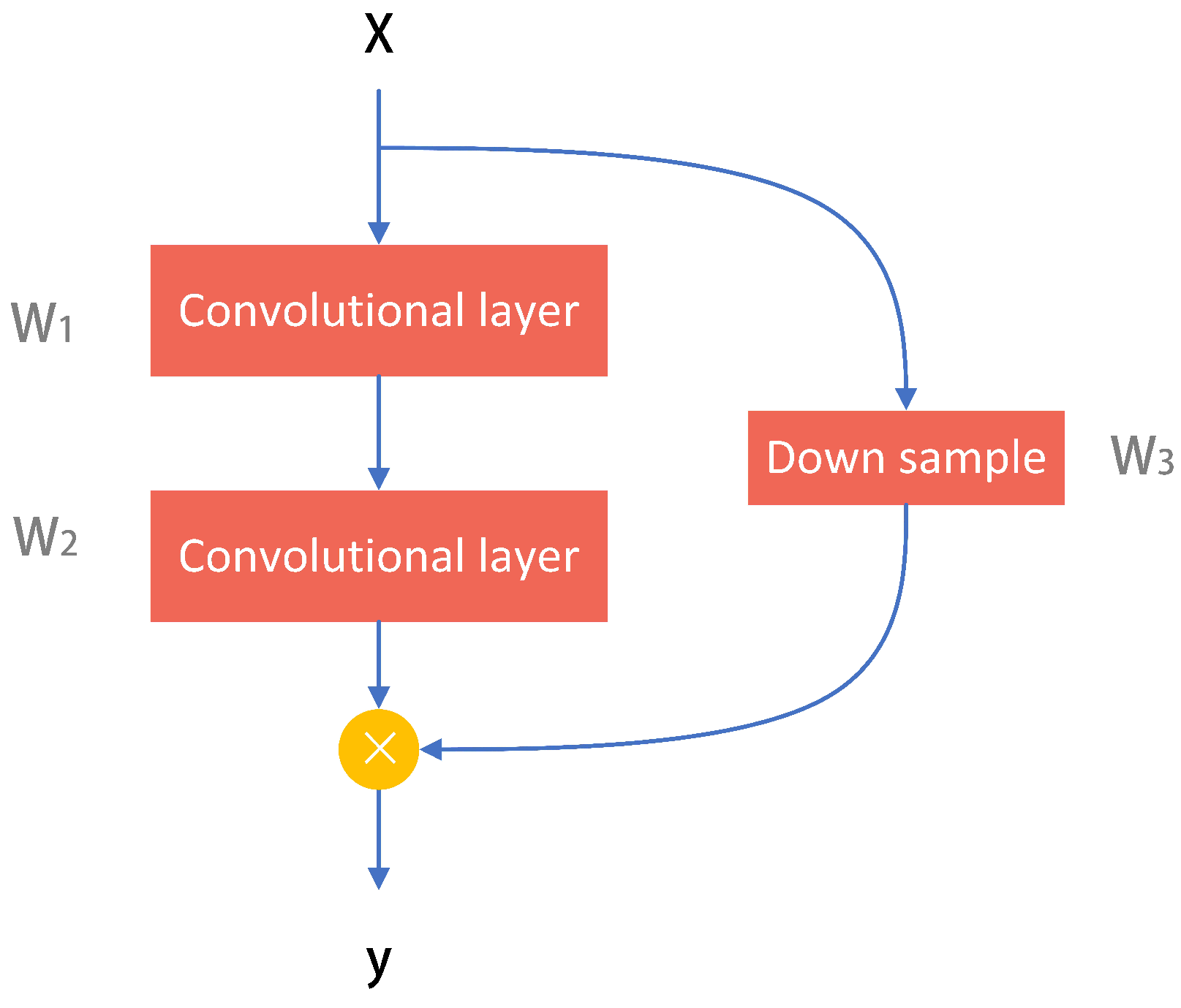
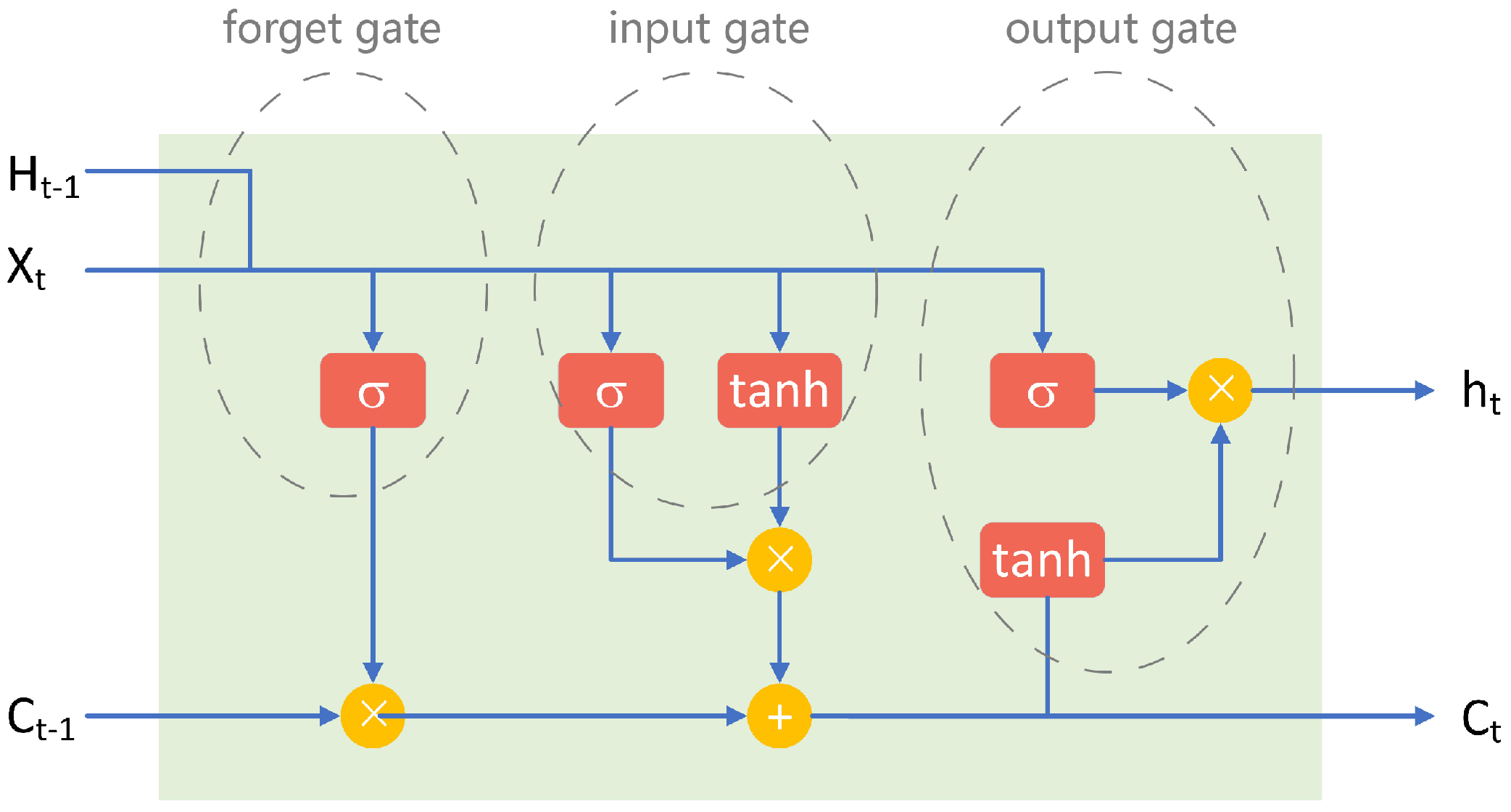
To compare CNN, RNN, and CNN+RNN, we need to choose a typical structure for each of them. There are many CNN architectures, such as VGG [
26], GoogLeNet [
27], and ResNet [
28]. Benefiting from the advantage of solving the degradation problem, ResNet has been broadly used in various tasks such as object detection [
29] and image classification [
30]. Thus, we choose ResNet as the backbone of our CNN model. To fit with the EDA signal, we adapt the original ResNet to replace the 2D convolution operation with 1D convolution operation. For RNN, we choose the most popular LSTM network and adapt it to fit our task. For consistency of the comparison, the CNN+RNN network is composed of ResNet and LSTM as well. To make full use of the representation ability of DNN, we apply CvxEDA [
31] to decompose the dynamic and static changes from original EDA inputs (more details in
Section 3.1).
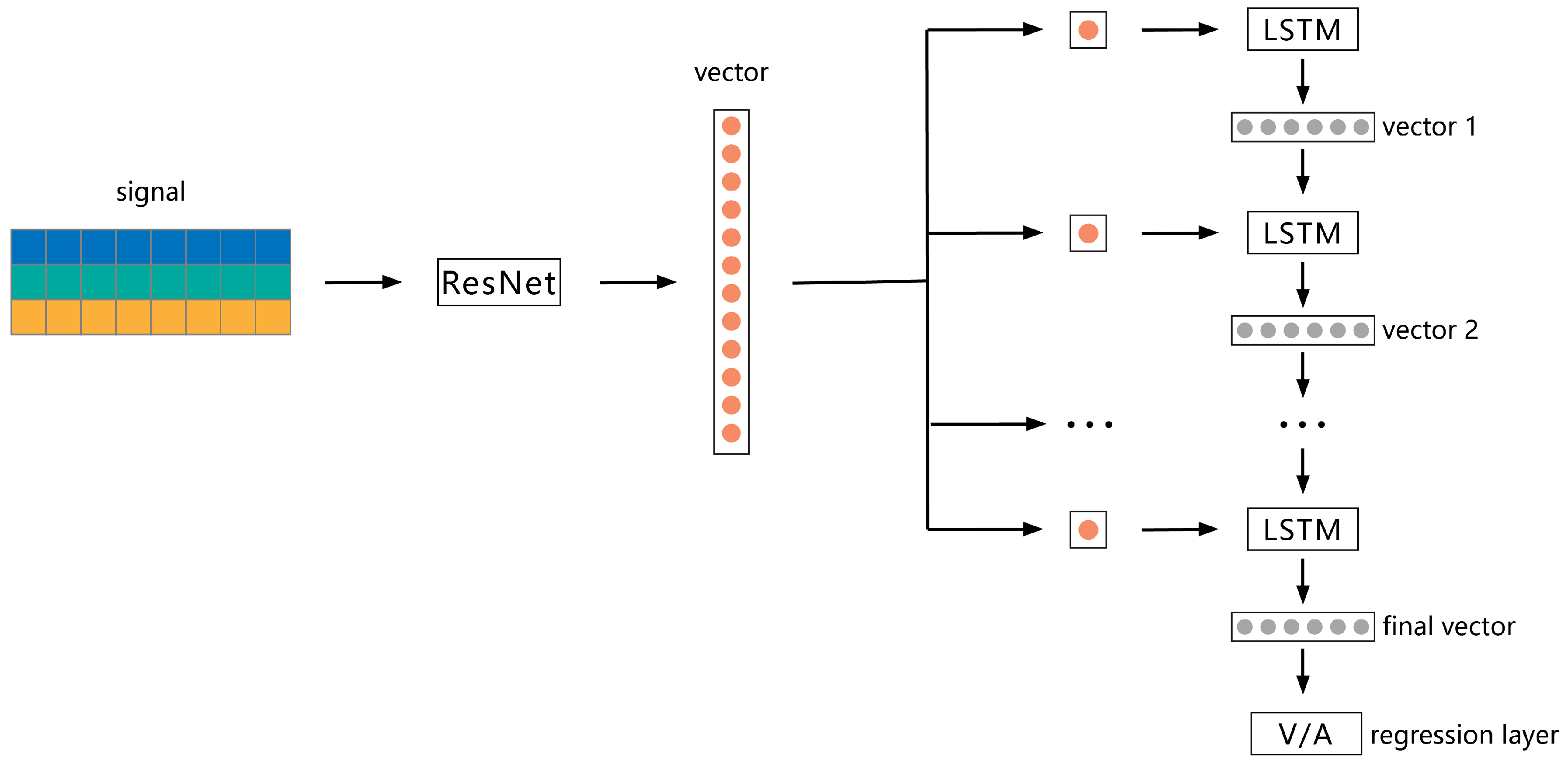
In this work, we systematically compare three typical deep neural networks for EDA-based emotion recognition. To make full use of limited 1-channel EDA signals, we apply a novel EDA analysis method—the Convex Optimization-Based EDA method (CvxEDA) [
31]—to decompose EDA into phasic and tonic components. After that, the three-channel EDA signals (the origin signal parallels with tonic and phasic signals) are, respectively, fed into ResNet, LSTM, and hybrid ResNet-LSTM for emotion classification. To fit with our task, the dimension of the convolutional operation in the original ResNet is changed from 2D to 1D, which can directly process the sequential EDA signal. We evaluate our models in the commonly used open-source dataset MAHNOB-HCI for three-class classification. The extensive ablation experiments are used to systematically compare the performance between the different structures of three types of deep neural networks, the results of which also demonstrate the superiority of the deep neural network by comparison with previous methods in the MAHNOB-HCI dataset.
The rest of this article is structured as follows:
Section 2 reviews the related works, including the theories of emotion models and EDA analysis.
Section 3 presents our proposed method.
Section 4 discusses the results, and
Section 5 presents the conclusions.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}