Using a Long Short-Term Memory Recurrent Neural Network (LSTM-RNN) to Classify Network Attacks




Abstract
:1. Introduction
2. Background
2.1. Deep Learning Architecture
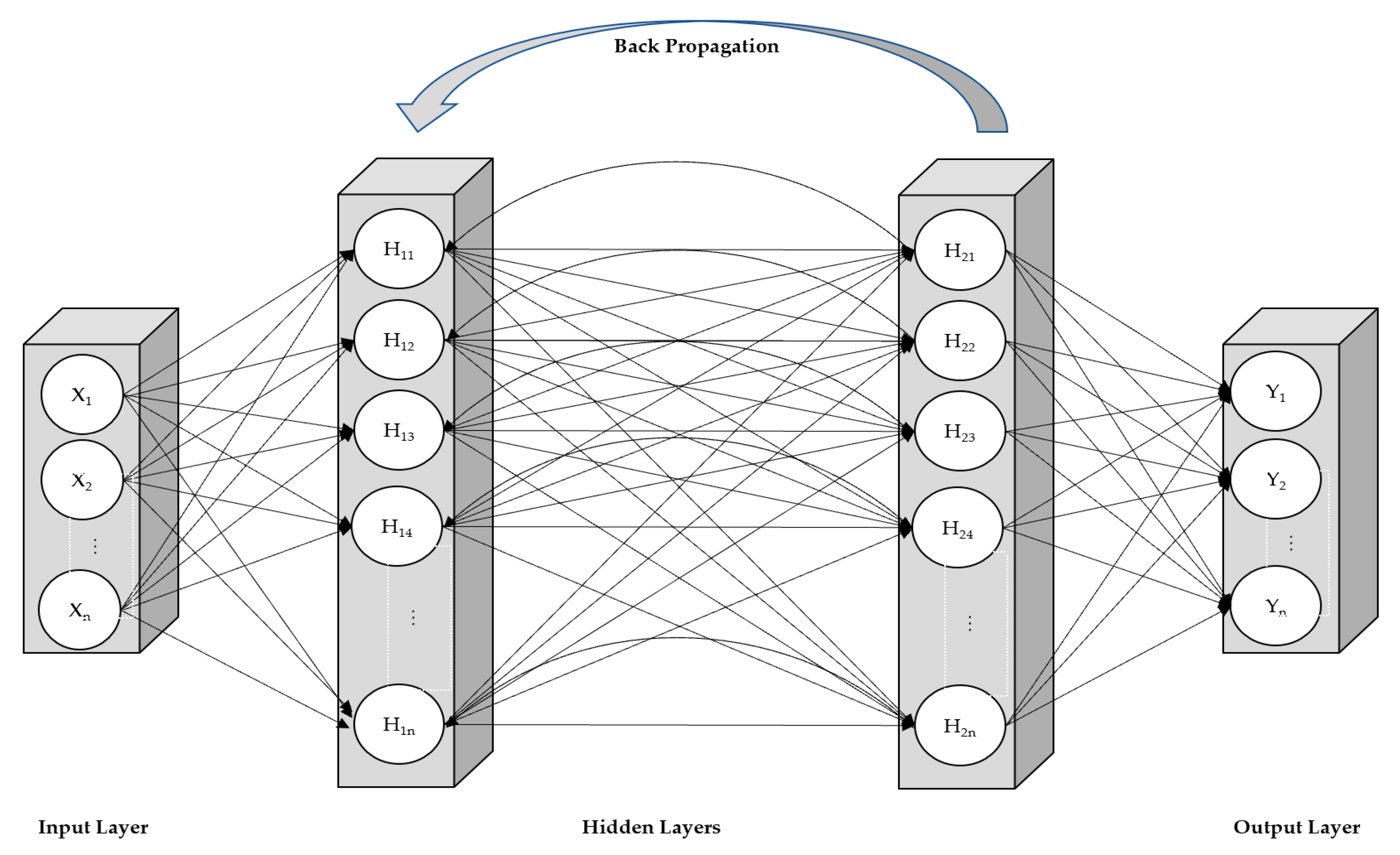
2.1.1. Recurrent Neural Network (RNN)
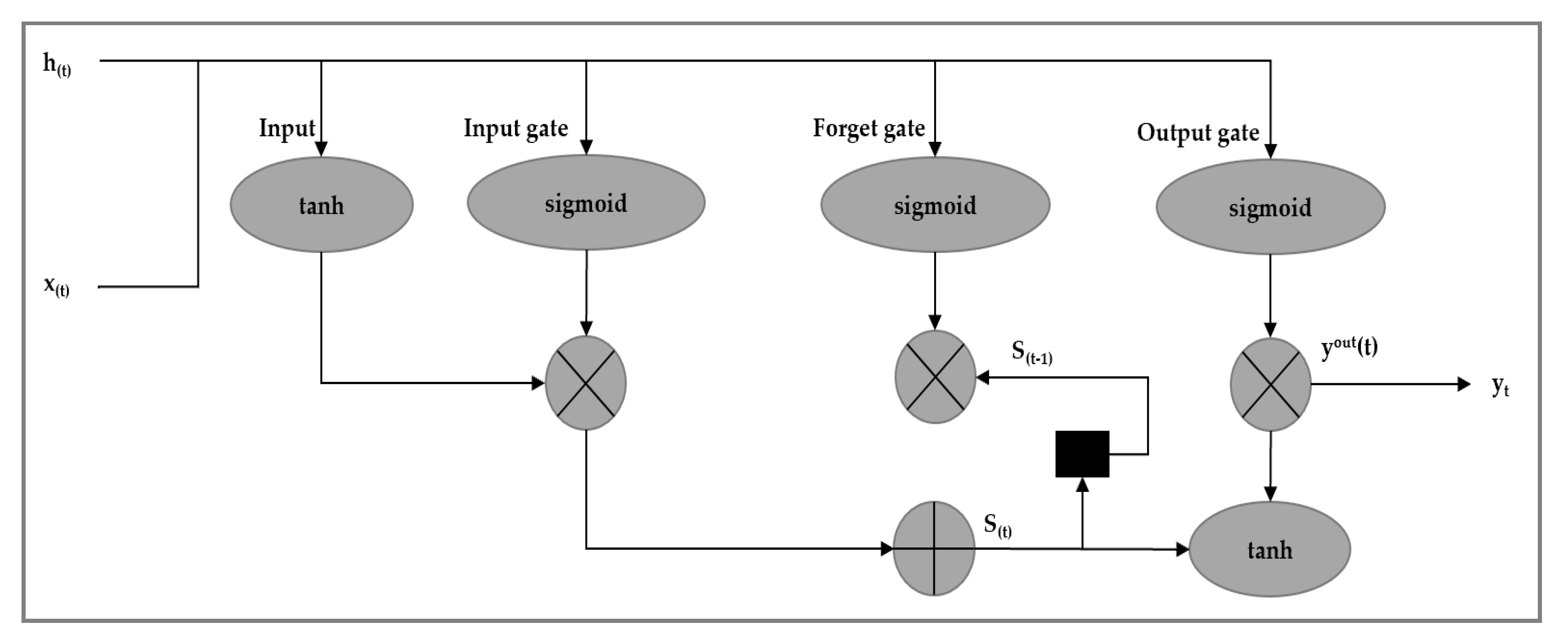
2.1.2. Long Short-Term Memory
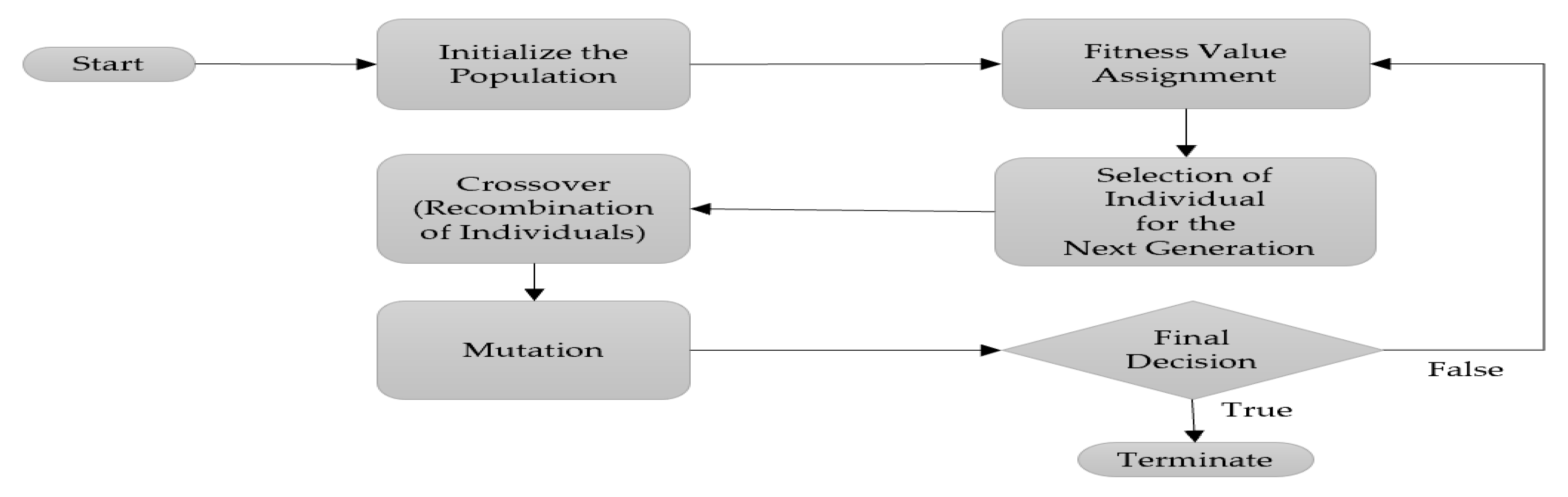
2.1.3. Genetic Algorithm (GA)
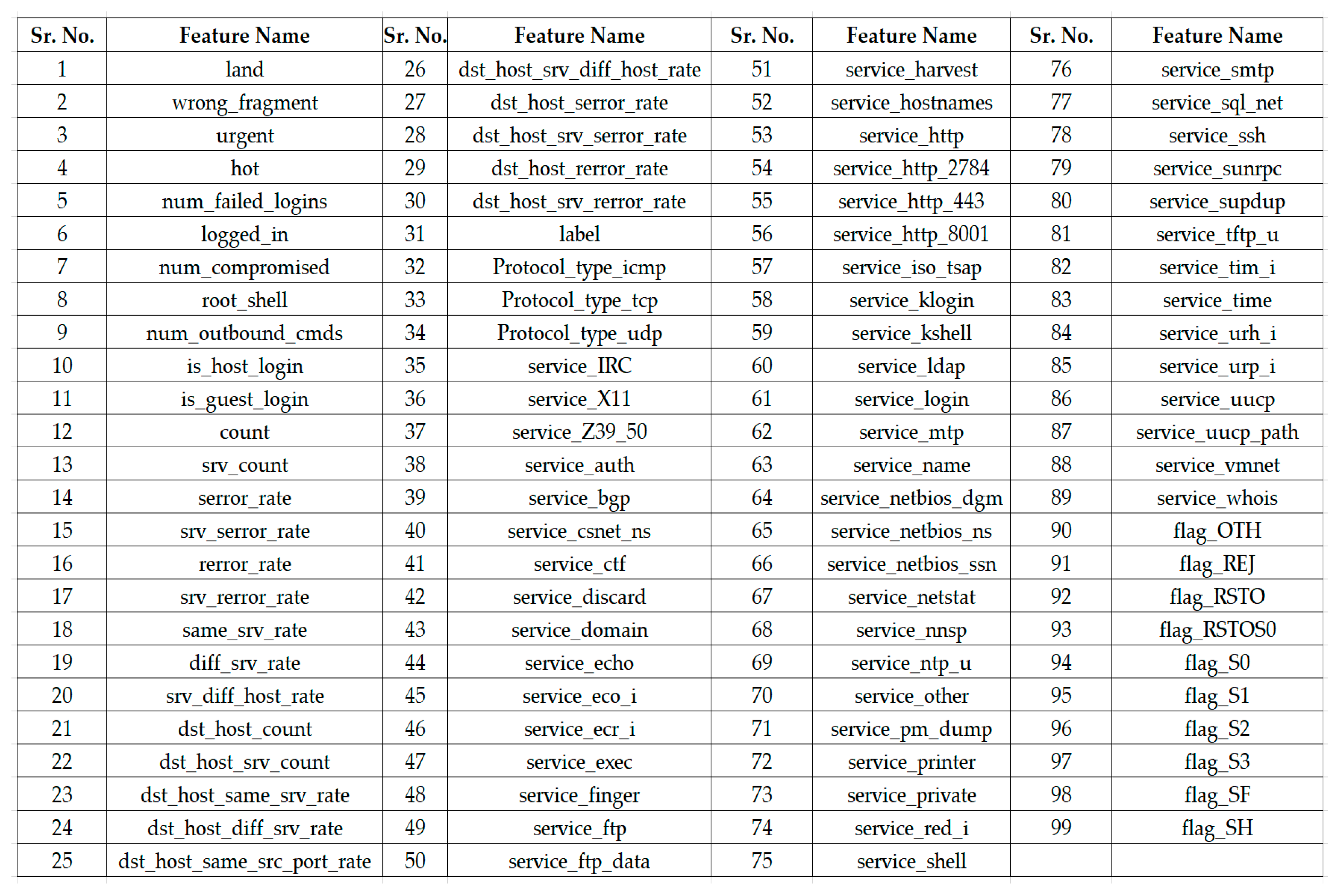
2.2. NSL-KDD Dataset
3. Related Work
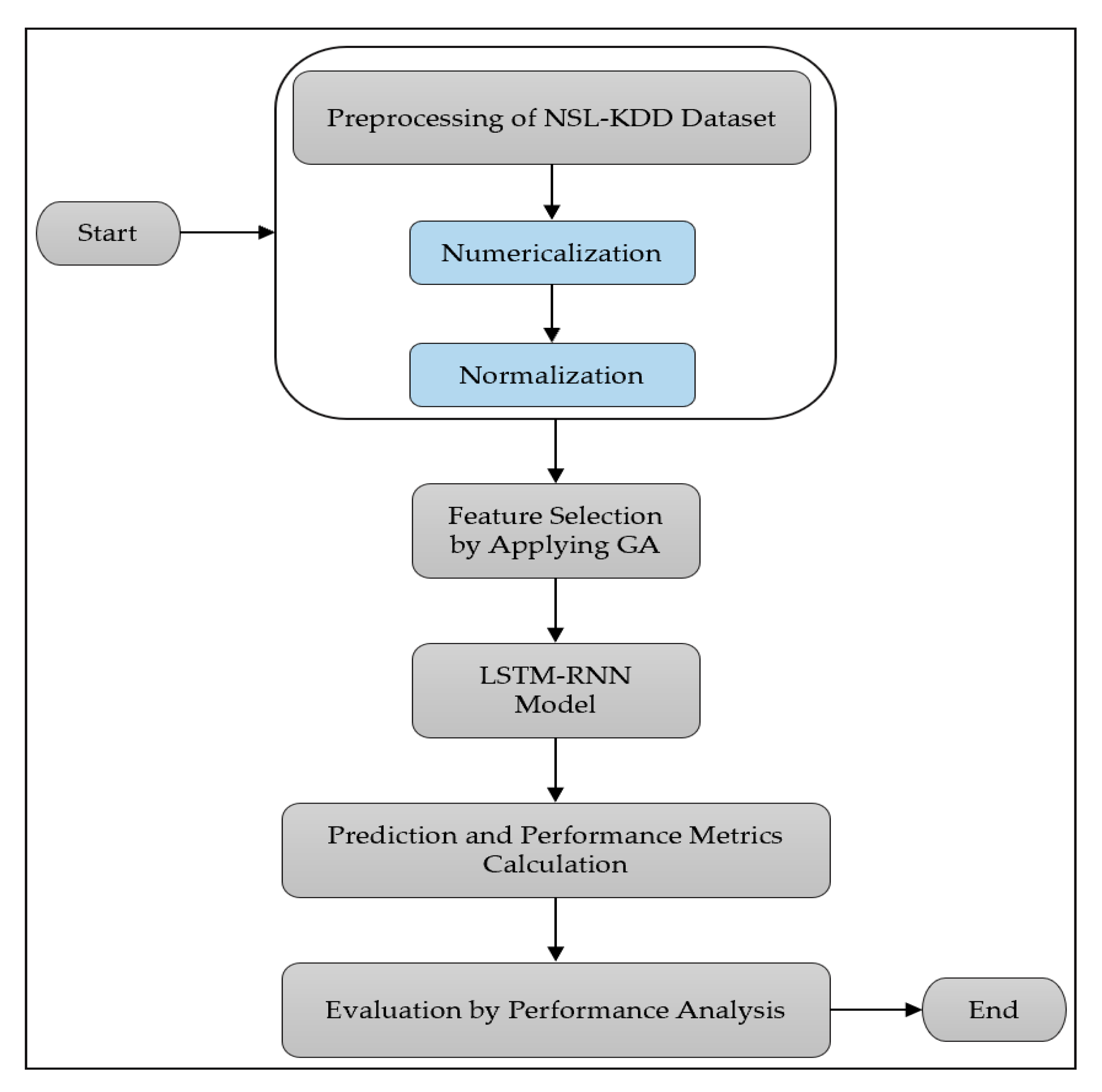
4. LSTM-RNN NIDS with a Genetic Algorithm
4.1. LSTM-RNN Classifier with GA Architecture
- Batch size is the number of training records in one forward and one backward pass.
- An epoch means one forward and one backward pass of all the training examples.
- Learning rate is the proportion of the weights that are updated during the training of the LSTM-RNN model. It can be chosen from the range [0.0–1.0].
- Dropout is a regularization technique, where randomly selected neurons are ignored during training. The selected neurons are temporarily removed on the forward pass.
- The activation function converts an input signal of a node in a neural network to an output signal, which is then used as the input of the next hidden layer and so on. To find the output of a layer, we calculated the sum of the products of inputs and their corresponding weights, applied the activation function to that sum, and then fed that output as an input to the next layer.
4.2. Experiment Environment Setup
Hyper-Parameter Setup for Experiments with the LSTM-RNN Model
5. Experimental Results
5.1. Classification Results of the LSTM-RNN Classifier
5.1.1. Classification Results Using all Features
5.1.2. Classification Results Using Optimal Feature Set
5.2. Performance Comparison between Classifiers
5.2.1. Performance Comparison Using All Features
5.2.2. Performance Comparison Using Optimal Features
6. Discussion
6.1. Binary Classification
6.2. Multi-Class Classification
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Class | ||
|---|---|---|
| Actual Class | Anomaly | Normal |
| Anomaly | # of TP | # of FN |
| Normal | # of FP | # of TN |
References
- Denning, D.E. An intrusion-detection model. IEEE Trans. Softw. Eng. 1987, 13, 222–232. [Google Scholar] [CrossRef]
- Peddabachigari, S.; Abraham, A.; Thomas, J. Intrusion Detection Systems Using Decision Trees and Support Vector Machines. Int. J. Appl. Sci. Comput. 2004, 11, 118–134. [Google Scholar]
- Rai, K.; Devi, M.S.; Guleria, A. Decision Tree Based Algorithm for Intrusion Detection. Int. J. Adv. Netw. Appl. 2016, 7, 2828–2834. [Google Scholar]
- Ingre, B.; Yadav, A.; Soni, A. K Decision Tree-Based Intrusion Detection System for NSL-KDD Dataset. In Proceedings of the International Conference on Information and Communication Technology for Intelligent Systems, Ahmedabad, India, 25–26 March 2017. [Google Scholar] [CrossRef]
- Farnaaz, N.; Jabbar, M.A. Random Forest Modeling for Network Intrusion Detection System. Procedia Comput. Sci. 2016, 89, 213–217. [Google Scholar] [CrossRef] [Green Version]
- Alom, M.Z.; Taha, T.M. Network intrusion detection for cybersecurity using unsupervised deep learning approaches. In Proceedings of the IEEE National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 27–30 June 2017. [Google Scholar] [CrossRef]
- Yuan, Y.; Huo, L.; Hogrefe, D. Two Layers Multi-class Detection Method for Network Intrusion Detection System. In Proceedings of the IEEE Symposium on Computers and Communications (ISCC), Heraklion, Greece, 3–6 July 2017. [Google Scholar] [CrossRef]
- Gurav, R.; Junnarkar, A.A. Classifying Attacks in NIDS Using Naïve- Bayes and MLP. Int. J. Sci. Eng. Technol. Res. (IJSETR) 2015, 4, 2440–2443. [Google Scholar]
- Tangi, S.D.; Ingale, M.D. A Survey: Importance of ANN-based NIDS in Detection of DoS Attacks. Int. J. Comput. Appl. 2013, 83. [Google Scholar] [CrossRef]
- Szegedy, C.; Toshev, A.; Erhan, D. Deep Neural Networks for Object Detection. In Proceedings of the 26th International Conference on Neural Information Processing Systems—Volume 2; Curran Associates Inc.: Red Hook, NY, USA, 2013; pp. 2553–2561. [Google Scholar]
- Wang, M.; Huang, Q.; Zhang, J.; Li, Z.; Pu, H.; Lei, J.; Wang, L. Deep Learning Approaches for Voice Activity Detection. In Proceedings of the International Conference on Cyber Security Intelligence and Analytics, Shenyang, China, 21–22 February 2019; pp. 816–826. [Google Scholar]
- Tang, T.A.; Mhamdi, L.; McLernon, D.; Zaidi, S.A.R.; Ghogho, M. Deep Learning Approach for Network Intrusion Detection in Software-Defined Networking. In Proceedings of the 2016 International Conference on Wireless Networks and Mobile Communications, Fez, Morocco, 26–29 October 2016. [Google Scholar] [CrossRef]
- Arora, K.; Chauhan, R. Improvement in the Performance of Deep Neural Network Model using learning rate. In Proceedings of the Innovations in Power and Advanced Computing Technologies (i-PACT), Vellore, India, 21–22 April 2017. [Google Scholar] [CrossRef]
- Tang, T.A.; Mhamdi, L.; McLernon, D.; Zaidi SA, R.; Ghogho, M. Deep Recurrent Neural Network for Intrusion Detection in SDN-based Networks. In Proceedings of the 4th IEEE International Conference on Network Softwarization (NetSoft), Montreal, QC, Canada, 25–29 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Yin, C.; Zhu, Y.; Fei, J.; He, X. A Deep Learning Approach for Intrusion Detection Using Recurrent Neural Networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Soman, K.P.; Poornachandran, P. Applying convolutional neural network for network intrusion detection. In Proceedings of the International Conference on Advances in Computing, Communications, and Informatics (ICACCI), Udupi, India, 13–16 September 2017. [Google Scholar] [CrossRef]
- Zhao, G.; Zhang, C.; Zheng, L. Intrusion Detection Using Deep Belief Network and Probabilistic Neural Network. In Proceedings of the IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Guangzhou, China, 21–24 July 2017. [Google Scholar] [CrossRef]
- Kim, J.; Kim, J.; Thu HL, T.; Kim, H. Long Short-Term Memory Recurrent Neural Network Classifier for Intrusion Detection. In Proceedings of the International Conference on Platform Technology and Service (PlatCon), Jeju, Korea, 15–17 February 2016. [Google Scholar] [CrossRef]
- Staudemeyer, R.C. Applying long short-term memory recurrent neural networks to intrusion detection. S. Afr. Comput. J. 2015, 56, 136–154. [Google Scholar] [CrossRef]
- Meng, F.; Fu, Y.; Lou, F.; Chen, Z. An Effective Network Attack Detection Method Based on Kernel PCA and LSTM-RNN. In Proceedings of the International Conference on Computer Systems, Electronics, and Control (ICCSEC), Dalian, China, 25–27 December 2017. [Google Scholar] [CrossRef]
- Staudemeyer, R.C.; Omlin, C.W. Evaluating performance of long short-term memory recurrent neural networks on intrusion detection data. In Proceedings of the South African Institute for Computer Scientists and Information Technologists Conference; Association for Computing Machinery: New York, NY, USA, 2013; pp. 218–224. [Google Scholar] [CrossRef]
- Javaid, A.; Niyaz, Q.; Sun, W.; Alam, M. A Deep Learning Approach for Network Intrusion Detection System. In Proceedings of the 9th EAI International Conference on Bio-inspired Information and Communications Technologies (BIONETICS), New York, NY, USA, 24 May 2016; pp. 21–26. [Google Scholar] [CrossRef] [Green Version]
- Hindy, H.; Brosset, D.; Bayne, E.; Seeam, A.; Tachtatzis, C.; Atkinson, R.; Bellekens, X. A Taxonomy and Survey of Intrusion Detection System Design Techniques, Network Threats and Datasets. arXiv 2018, arXiv:1806.03517. [Google Scholar]
- Artificial Neural Network–Wikipedia. Available online: https://en.wikipedia.org/wiki/Artificial_neural_network (accessed on 29 April 2020).
- Recurrent Neural Network-Wikipedia. Available online: https://en.wikipedia.org/wiki/Recurrent_neural_network (accessed on 29 April 2020).
- Hochreiter, S.; Bengio, Y.; Frasconi, P.; Schmidhuber, J. Gradient Flow in Recurrent Nets: The Difficulty of Learning Long-term Dependencies. In A Field Guide to Dynamical Recurrent Neural Networks; IEEE Press: Piscataway, NJ, USA, 2001; pp. 237–243. [Google Scholar] [CrossRef]
- Williams, R.J.; Zipser, D. Gradient based learning algorithms for recurrent networks and their computational complexity. In Backpropagation: Theory, Architectures, and Applications; Lawrence Erlbaum Associates: Hillsdale, NJ, USA, 1995; pp. 433–486. [Google Scholar]
- Genetic Algorithms—Introduction. Available online: https://www.tutorialspoint.com/genetic_algorithms/genetic_algorithms_introduction.htm (accessed on 29 April 2020).
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A Detailed Analysis of the KDD CUP 99 Data Set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Dhanabal, L.; Shantharajah, S.P. A Study on NSL_KDD Dataset for Intrusion Detection System Based on Classification Algorithms. Int. J. Adv. Research Comput. Commun. Eng. 2015, 4, 446–452. [Google Scholar]
- Hamid, Y.; Balasaraswathi, V.R.; Journaux, L.; Sugumaran, M. Benchmark Datasets for Network Intrusion Detection: A Review. Int. J. Netw. Secur. 2018, 20, 645–654. [Google Scholar] [CrossRef]
- Evolutionary Tools. Available online: https://deap.readthedocs.io/en/master/api/tools.html (accessed on 29 April 2020).





| Major Categories | Subcategories |
|---|---|
| Denial of Service (DoS) | ping of Death, LAND, neptune, backscatter, smurf, teardrop |
| User to Root (U2R) | buffer Overflow, loadmodule, perl, rootkit |
| Remote to Local (R2L) | ftp-write, password guessing, imap, multi-hop, phf, spy, warezclient, warezmaster |
| Probing | ipsweeping, nmap, portsweeping, satan |
| Attack | Total Instances in NSL-KDD Dataset | Attack Category |
|---|---|---|
| Back | 956 | DoS |
| Land | 18 | |
| Neptune | 41,214 | |
| Pod | 201 | |
| Smurf | 2646 | |
| Teardrop | 892 | |
| Satan | 3633 | |
| Ipsweep | 3599 | Probe |
| Nmap | 1493 | |
| Portsweep | 2931 | |
| Normal | 67,343 | Normal |
| guess-passwd | 53 | R2L |
| ftp-write | 8 | |
| Imap | 11 | |
| Phf | 4 | |
| Multihop | 7 | |
| Warezmaster | 20 | |
| Warezclient | 1020 | |
| Spy | 2 | |
| buffer-overflow | 30 | U2R |
| Loadmodule | 9 | |
| Perl | 3 | |
| Rootkit | 2931 |
| Dataset | Total No. of Instances | |||||
|---|---|---|---|---|---|---|
| Instances | Normal | DoS | Probe | U2R | R2L | |
| KDDTrain+ | 125,973 | 67,343 | 45,927 | 11,656 | 52 | 995 |
| KDDTest+ | 22,544 | 9711 | 7460 | 2421 | 67 | 2885 |
| Hyper-Parameter | Binary Classification | Multi-Class Classification |
|---|---|---|
| Learning Rate | 0.01 | 0.01 |
| Dropout | 0.01, 0.15, 0.2, 0.3 | 0.01, 0.15, 0.2, 0.3 |
| Activation function | sigmoid | Softmax |
| Optimizer | adam | SGD |
| Epoch | 500 | 500 |
| Batch size | 50 | 50 |
| Loss function | binary_crossentropy | categorical_crossentropy |
| No. of Neurons in Hidden Layers | Number of the Hidden Layers |
|---|---|
| 5 | 2 |
| 10 | 3 |
| 20 | 4 |
| 40 | 5 |
| 60 | 6 |
| 80 | 7 |
| 100 | 8 |
| No. of Neurons in Hidden Layers | Accuracy | Precision | Recall | f1-Score | TPR | FPR | |
|---|---|---|---|---|---|---|---|
| Training % | Testing % | ||||||
| 5 | 99.88 | 96.51 | 0.97 | 0.97 | 0.97 | 0.944 | 0.007 |
| 10 | 99.90 | 96.29 | 0.96 | 0.96 | 0.96 | 0.944 | 0.012 |
| 20 | 99.90 | 96.41 | 0.96 | 0.96 | 0.96 | 0.942 | 0.006 |
| 40 | 99.89 | 96.28 | 0.95 | 0.96 | 0.96 | 0.943 | 0.011 |
| 60 | 99.88 | 96.25 | 0.96 | 0.96 | 0.96 | 0.939 | 0.006 |
| 80 | 99.86 | 96.04 | 0.96 | 0.96 | 0.96 | 0.936 | 0.007 |
| 100 | 99.85 | 95.94 | 0.96 | 0.96 | 0.96 | 0.934 | 0.008 |
| No. of Neurons in Hidden Layers | Accuracy | Precision | Recall | f1-Score | TPR | FPR | |
|---|---|---|---|---|---|---|---|
| Train % | Test % | ||||||
| 5 | 96.00 | 85.65 | 0.86 | 0.86 | 0.85 | 0.765 | 0.023 |
| 10 | 98.00 | 78.13 | 0.80 | 0.78 | 0.73 | 0.630 | 0.019 |
| 20 | 98.70 | 76.61 | 0.72 | 0.74 | 0.69 | 0.589 | 0.060 |
| 40 | 99.89 | 82.42 | 0.87 | 0.82 | 0.81 | 0.697 | 0.008 |
| 60 | 99.87 | 82.68 | 0.87 | 0.83 | 0.81 | 0.707 | 0.015 |
| 80 | 99.84 | 81.33 | 0.87 | 0.81 | 0.79 | 0.685 | 0.017 |
| 100 | 99.85 | 82.06 | 0.85 | 0.82 | 0.81 | 0.689 | 0.006 |
| No. of Neurons in Hidden Layers | Accuracy | Precision | Recall | f1-Score | TPR | FPR | |
|---|---|---|---|---|---|---|---|
| Training (%) | Testing (%) | ||||||
| 5 | 99.99 | 99.83 | 1.00 | 1.00 | 1.00 | 0.999 | 0.004 |
| 10 | 99.99 | 99.81 | 1.00 | 1.00 | 1.00 | 0.999 | 0.003 |
| 20 | 99.99 | 99.80 | 1.00 | 1.00 | 1.00 | 0.999 | 0.004 |
| 40 | 99.99 | 99.91 | 1.00 | 1.00 | 1.00 | 0.999 | 0.003 |
| 60 | 99.99 | 99.91 | 1.00 | 1.00 | 1.00 | 0.999 | 0.004 |
| 80 | 99.99 | 99.84 | 1.00 | 1.00 | 1.00 | 0.999 | 0.003 |
| 100 | 99.99 | 99.82 | 1.00 | 1.00 | 1.00 | 0.999 | 0.007 |
| No. of Neurons in Hidden Layers | Accuracy | Precision | Recall | f1-Score | TPR | FPR | |
|---|---|---|---|---|---|---|---|
| Training (%) | Testing (%) | ||||||
| 5 | 98.4 | 87.77 | 0.92 | 0.88 | 0.86 | 0.792 | 0.009 |
| 10 | 98.2 | 82.58 | 0.87 | 0.83 | 0.81 | 0.751 | 0.076 |
| 20 | 98.3 | 67.65 | 0.72 | 0.68 | 0.63 | 0.472 | 0.053 |
| 40 | 98.6 | 87.62 | 0.90 | 0.88 | 0.86 | 0.794 | 0.015 |
| 60 | 99.0 | 89.74 | 0.93 | 0.90 | 0.89 | 0.825 | 0.006 |
| 80 | 99.0 | 93.88 | 0.96 | 0.94 | 0.94 | 0.896 | 0.005 |
| 100 | 99.8 | 91.39 | 0.93 | 0.89 | 0.89 | 0.810 | 0.007 |
| Method | Testing Accuracy (%) | Precision | Recall | f1-Score | TPR | FPR |
|---|---|---|---|---|---|---|
| SVM | 92.90 | 0.94 | 0.93 | 0.93 | 0.876 | 0.002 |
| Random forest | 99.99 | 1.00 | 1.00 | 1.00 | 0.999 | 0.0001 |
| LSTM-RNN | 96.51 | 0.97 | 0.97 | 0.97 | 0.944 | 0.007 |
| Method | Testing Accuracy (%) | Precision | Recall | f1-Score | TPR | FPR |
|---|---|---|---|---|---|---|
| SVM | 67.20 | 0.43 | 0.42 | 0.41 | 0.478 | 0.071 |
| Random forest | 80.70 | 0.90 | 0.55 | 0.53 | 0.661 | 0.001 |
| LSTM-RNN | 82.68 | 0.87 | 0.83 | 0.81 | 0.707 | 0.015 |
| Method | Testing Accuracy (%) | Precision | Recall | f1-Score | TPR | FPR |
|---|---|---|---|---|---|---|
| SVM | 99.90 | 0.99 | 0.99 | 0.99 | 0.999 | 0.001 |
| Random forest | 99.99 | 1.00 | 1.00 | 1.00 | 1.00 | 0.0001 |
| LSTM-RNN | 99.91 | 1.00 | 1.00 | 1.00 | 0.999 | 0.003 |
| Method | Testing Accuracy % | Precision | Recall | f1-Score | TPR | FPR |
|---|---|---|---|---|---|---|
| SVM | 68.10 | 0.70 | 0.43 | 0.44 | 0.480 | 0.053 |
| Random forest | 84.90 | 0.89 | 0.59 | 0.57 | 0.735 | 0.0001 |
| LSTM-RNN | 93.88 | 0.96 | 0.94 | 0.94 | 0.896 | 0.005 |
| Predicted Class | ||||
|---|---|---|---|---|
| Using 122 Features | Using 99 Features | |||
| Actual Class | Anomaly | Normal | Anomaly | Normal |
| Anomaly | 12115 | 718 | 12831 | 2 |
| Normal | 68 | 9643 | 18 | 9693 |
| Predicted Class | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Using 122 Features | Using 99 Features | |||||||||
| Actual Class | Normal | DoS | Probe | R2L | U2R | Normal | DoS | Probe | R2L | U2R |
| Normal | 9562 | 147 | 2 | 0 | 0 | 9660 | 50 | 1 | 0 | 0 |
| DoS | 795 | 6143 | 522 | 0 | 0 | 0 | 7417 | 43 | 0 | 0 |
| Probe | 5 | 157 | 2232 | 25 | 2 | 0 | 46 | 2271 | 79 | 25 |
| R2L | 250 | 7 | 1907 | 686 | 35 | 0 | 1 | 877 | 1770 | 237 |
| U2R | 20 | 4 | 3 | 23 | 17 | 1 | 0 | 0 | 20 | 46 |
| Normal/Attack Type | Precision | Recall | f1-Score | Accuracy (%) |
|---|---|---|---|---|
| Normal | 0.90 | 0.98 | 0.94 | 98.47 |
| DoS | 0.95 | 0.82 | 0.88 | 82.35 |
| Probe | 0.48 | 0.92 | 0.63 | 92.19 |
| R2L | 0.93 | 0.24 | 0.38 | 23.78 |
| U2R | 0.31 | 0.25 | 0.28 | 25.37 |
| Normal/Attack Type | Precision | Recall | f1-Score | Accuracy (%) |
|---|---|---|---|---|
| Normal | 1.00 | 0.99 | 1.00 | 99.47 |
| DoS | 0.99 | 0.99 | 0.99 | 99.43 |
| Probe | 0.71 | 0.94 | 0.81 | 93.80 |
| R2L | 0.95 | 0.61 | 0.74 | 61.35 |
| U2R | 0.15 | 0.69 | 0.25 | 68.66 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muhuri, P.S.; Chatterjee, P.; Yuan, X.; Roy, K.; Esterline, A. Using a Long Short-Term Memory Recurrent Neural Network (LSTM-RNN) to Classify Network Attacks. Information 2020, 11, 243. https://doi.org/10.3390/info11050243
Muhuri PS, Chatterjee P, Yuan X, Roy K, Esterline A. Using a Long Short-Term Memory Recurrent Neural Network (LSTM-RNN) to Classify Network Attacks. Information. 2020; 11(5):243. https://doi.org/10.3390/info11050243
Chicago/Turabian StyleMuhuri, Pramita Sree, Prosenjit Chatterjee, Xiaohong Yuan, Kaushik Roy, and Albert Esterline. 2020. "Using a Long Short-Term Memory Recurrent Neural Network (LSTM-RNN) to Classify Network Attacks" Information 11, no. 5: 243. https://doi.org/10.3390/info11050243
APA StyleMuhuri, P. S., Chatterjee, P., Yuan, X., Roy, K., & Esterline, A. (2020). Using a Long Short-Term Memory Recurrent Neural Network (LSTM-RNN) to Classify Network Attacks. Information, 11(5), 243. https://doi.org/10.3390/info11050243