COVID-19 Public Sentiment Insights and Machine Learning for Tweets Classification


Abstract
:1. Introduction
2. Literature Review
2.1. Textual Analytics
2.2. Twitter Analytics
2.3. Classification Methods
2.3.1. Linear Regression Model
2.3.2. Naïve Bayes Classifier
2.3.3. Logistic Regression
2.3.4. K-Nearest Neighbor
2.3.5. Summary
3. Methods and Textual Data Analytics
3.1. Exploratory Textual Analytics
3.1.1. Data Acquisition and Preparation
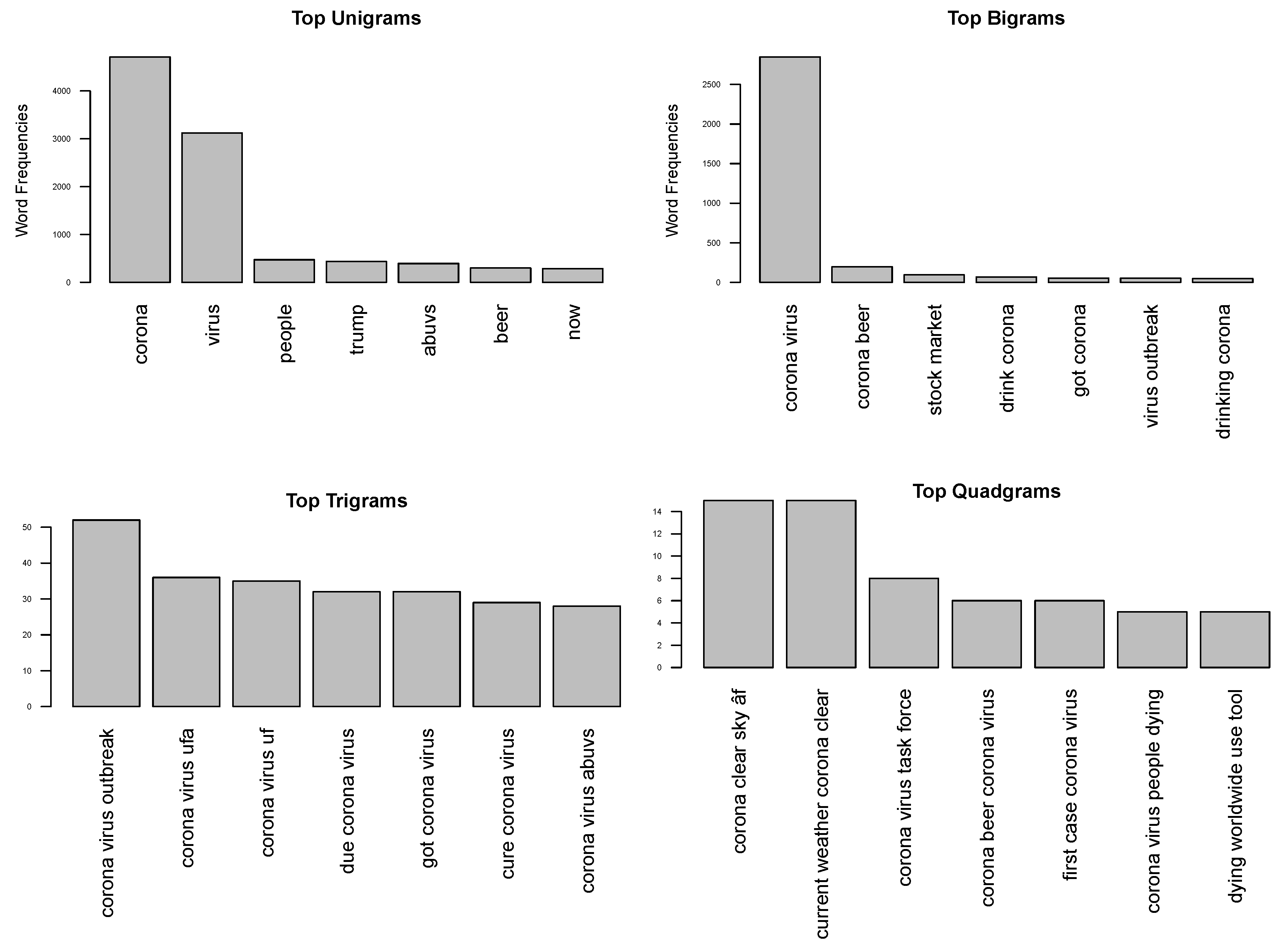
3.1.2. Word and Phrase Associations
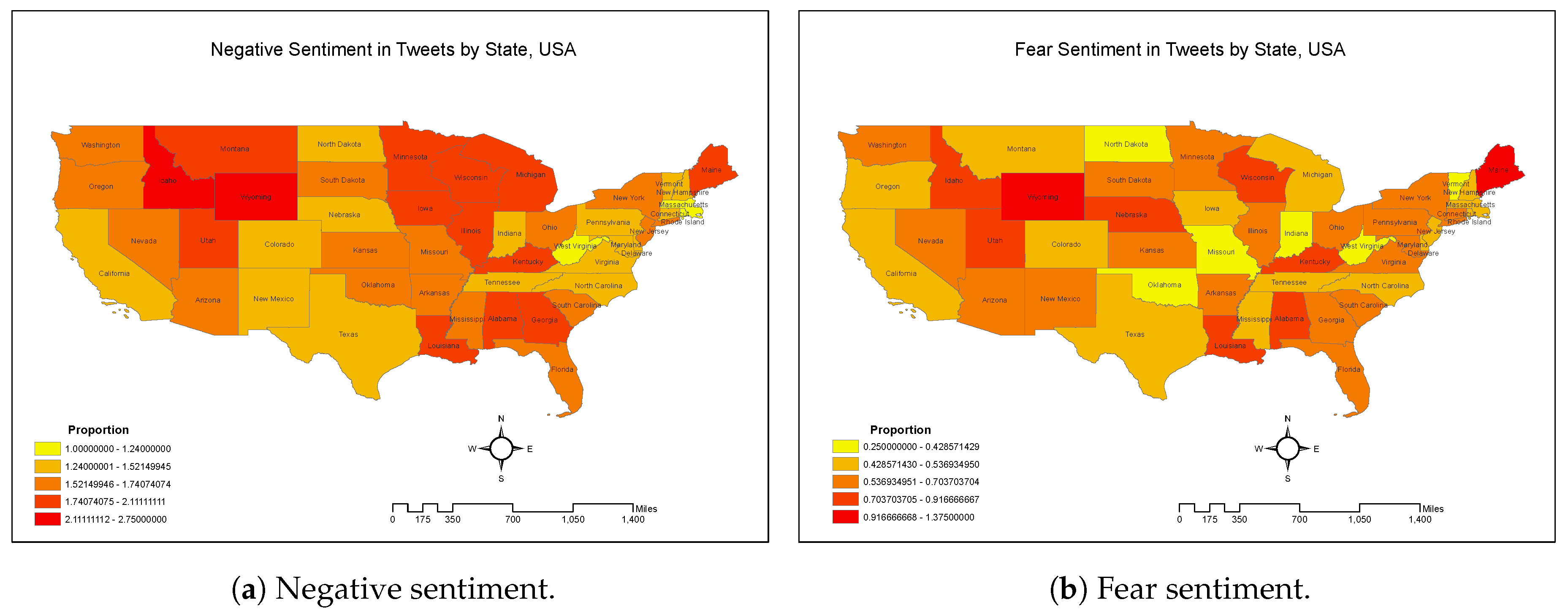
3.1.3. Geo-Tagged Analytics
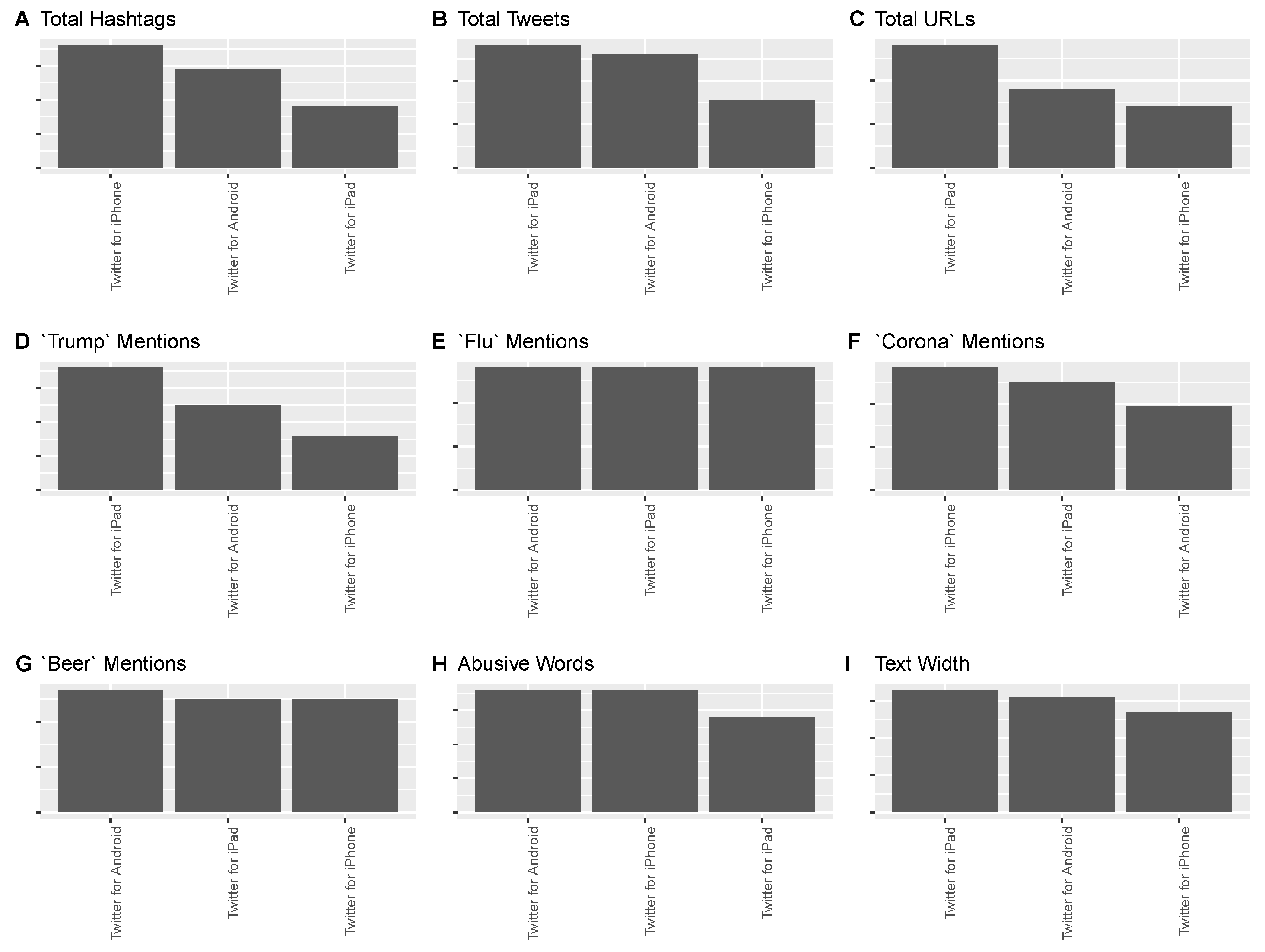
3.1.4. Association with Non-Textual Variables
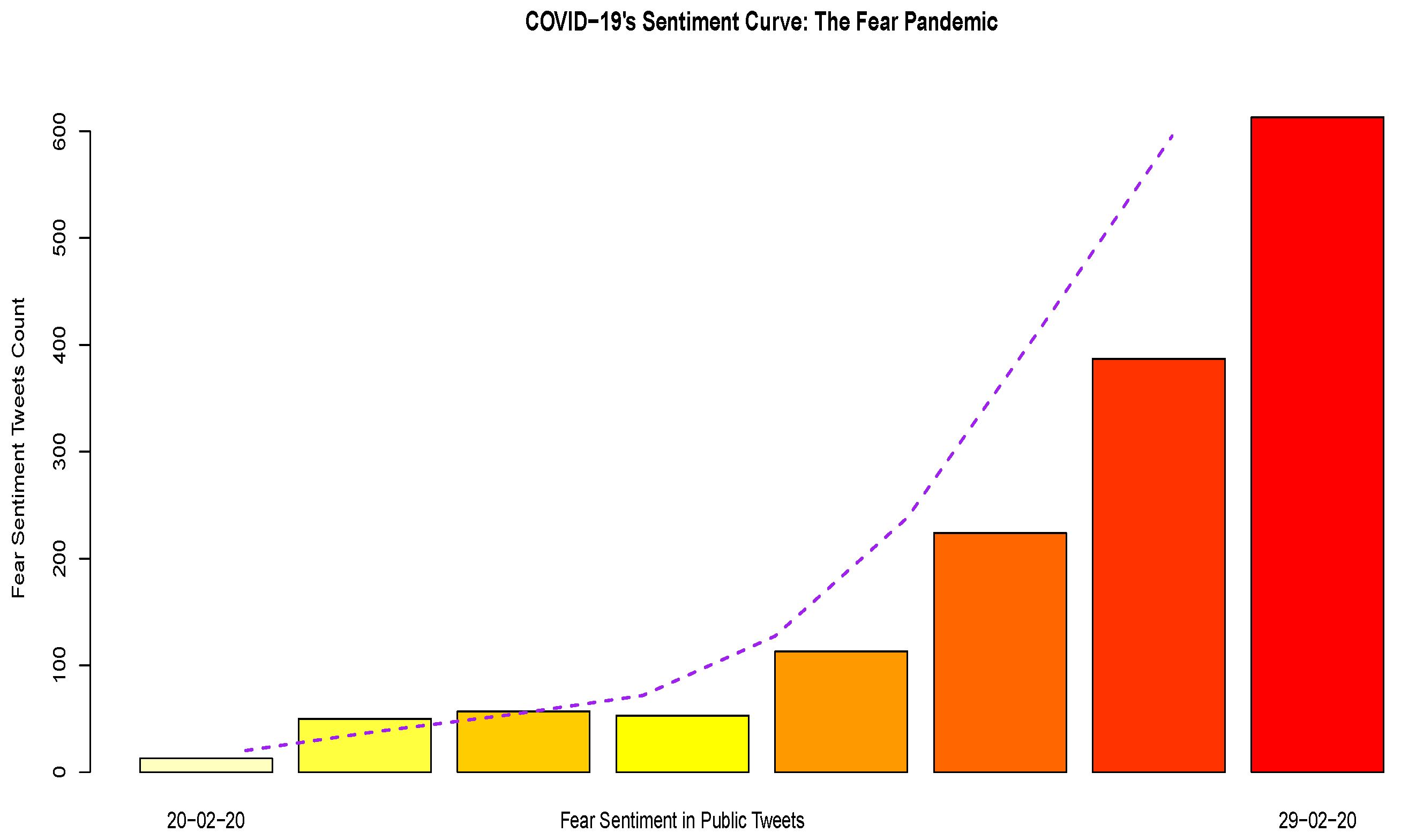
3.1.5. Sentiment Analytics
3.2. Machine Learning with Classification Methods
3.3. Naïve Bayes Classifier
Classifier Training
3.4. Application of Naïve Bayes for Coronavirus Tweet Classification
3.5. Logistic Regression
- A feature representation of the input: For each input observation , this will be represented by a vector of features, .
- A classification function: It computes the estimated class . The sigmoid function is used in classification.
- An objective function: The job of objective function is to minimize the error of training examples. The cross-entropy loss function is often used for this purpose.
- An optimizing algorithm: This algorithm will be used for optimizing the objective function. The stochastic gradient descent algorithm is popularly used for this task.
3.5.1. The Classification Function
3.5.2. Objective Function
3.5.3. Optimization Algorithm
3.6. Application of Logistic Regression for Coronavirus Tweet Classification
4. Discussion
4.1. Limitations
4.2. Implications and Ethics
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| COVID-19 | Coronavirus Disease 2019 |
| ML | Machine Learning |
| NLP | Natural Language Processing |
References
- COVID-19:Briefing Materials. Available online: https://www.mckinsey.com/~/media/mckinsey/business%20functions/risk/our%20insights/covid%2019%20implications%20for%20business/covid%2019%20may%2013/covid-19-facts-and-insights-may-6.ashx (accessed on 11 June 2020).
- Jin, D.; Jin, Z.; Zhou, J.T.; Szolovits, P. Is bert really robust? natural language attack on text classification and entailment. arXiv 2019, arXiv:1907.11932. [Google Scholar]
- Samuel, J. Information Token Driven Machine Learning for Electronic Markets: Performance Effects in Behavioral Financial Big Data Analytics. JISTEM J. Inf. Syst. Technol. Manag. 2017, 14, 371–383. [Google Scholar] [CrossRef] [Green Version]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake news detection on social media: A data mining perspective. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Makris, C.; Pispirigos, G.; Rizos, I.O. A Distributed Bagging Ensemble Methodology for Community Prediction in Social Networks. Information 2020, 11, 199. [Google Scholar] [CrossRef] [Green Version]
- Heist, N.; Hertling, S.; Paulheim, H. Language-agnostic relation extraction from abstracts in Wikis. Information 2018, 9, 75. [Google Scholar] [CrossRef] [Green Version]
- He, W.; Wu, H.; Yan, G.; Akula, V.; Shen, J. A novel social media competitive analytics framework with sentiment benchmarks. Inf. Manag. 2015, 52, 801–812. [Google Scholar] [CrossRef]
- Widener, M.J.; Li, W. Using geolocated Twitter data to monitor the prevalence of healthy and unhealthy food references across the US. Appl. Geogr. 2014, 54, 189–197. [Google Scholar] [CrossRef]
- Kretinin, A.; Samuel, J.; Kashyap, R. When the Going Gets Tough, The Tweets Get Going! An Exploratory Analysis of Tweets Sentiments in the Stock Market. Am. J. Manag. 2018, 18. [Google Scholar]
- De Choudhury, M.; Counts, S.; Horvitz, E. Predicting Postpartum Changes in Emotion and Behavior via Social Media. In Proceedings of the SIGCHI conference on human factors in computing systems, Paris, France, 27 April–2 May 2013; pp. 3267–3276. [Google Scholar]
- Wang, Z.; Ye, X.; Tsou, M.H. Spatial, temporal, and content analysis of Twitter for wildfire hazards. Nat. Hazards 2016, 83, 523–540. [Google Scholar] [CrossRef]
- Skoric, M.M.; Liu, J.; Jaidka, K. Electoral and Public Opinion Forecasts with Social Media Data: A Meta-Analysis. Information 2020, 11, 187. [Google Scholar] [CrossRef] [Green Version]
- Samuel, J. Eagles & Lions Winning Against Coronavirus! 8 Principles from Winston Churchill for Overcoming COVID-19 & Fear. Researchgate Preprint. 2020. Available online: https://www.researchgate.net/publication/340610688 (accessed on 21 April 2020). [CrossRef]
- Chen, X.; Xie, H.; Cheng, G.; Poon, L.K.; Leng, M.; Wang, F.L. Trends and Features of the Applications of Natural Language Processing Techniques for Clinical Trials Text Analysis. Appl. Sci. 2020, 10, 2157. [Google Scholar] [CrossRef] [Green Version]
- Reyes-Menendez, A.; Saura, J.R.; Alvarez-Alonso, C. Understanding# WorldEnvironmentDay user opinions in Twitter: A topic-based sentiment analysis approach. Int. J. Environ. Res. Public Health 2018, 15, 2537. [Google Scholar]
- Saura, J.R.; Palos-Sanchez, P.; Grilo, A. Detecting indicators for startup business success: Sentiment analysis using text data mining. Sustainability 2019, 11, 917. [Google Scholar] [CrossRef] [Green Version]
- Samuel, J.; Holowczak, R.; Benbunan-Fich, R.; Levine, I. Automating Discovery of Dominance in Synchronous Computer-Mediated Communication. In Proceedings of the 2014 47th IEEE Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 6–9 January 2014; pp. 1804–1812. [Google Scholar]
- Rocha, G.; Lopes Cardoso, H. Recognizing textual entailment: Challenges in the Portuguese language. Information 2018, 9, 76. [Google Scholar] [CrossRef] [Green Version]
- Carducci, G.; Rizzo, G.; Monti, D.; Palumbo, E.; Morisio, M. Twitpersonality: Computing personality traits from tweets using word embeddings and supervised learning. Information 2018, 9, 127. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, T.; Ramsay, A.; Ahmed, H. Detecting Emotions in English and Arabic Tweets. Information 2019, 10, 98. [Google Scholar] [CrossRef] [Green Version]
- Pépin, L.; Kuntz, P.; Blanchard, J.; Guillet, F.; Suignard, P. Visual analytics for exploring topic long-term evolution and detecting weak signals in company targeted tweets. Comput. Ind. Eng. 2017, 112, 450–458. [Google Scholar] [CrossRef]
- De Maio, C.; Fenza, G.; Loia, V.; Parente, M. Time aware knowledge extraction for microblog summarization on twitter. Inf. Fusion 2016, 28, 60–74. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, N.; Siddique, J. Personality assessment using Twitter tweets. Procedia Comput. Sci. 2017, 112, 1964–1973. [Google Scholar] [CrossRef]
- Jain, V.K.; Kumar, S.; Fernandes, S.L. Extraction of emotions from multilingual text using intelligent text processing and computational linguistics. J. Comput. Sci. 2017, 21, 316–326. [Google Scholar] [CrossRef]
- Ye, X.; Li, S.; Yang, X.; Qin, C. Use of social media for the detection and analysis of infectious diseases in China. ISPRS Int. J. Geo-Inf. 2016, 5, 156. [Google Scholar] [CrossRef] [Green Version]
- Fung, I.C.H.; Yin, J.; Pressley, K.D.; Duke, C.H.; Mo, C.; Liang, H.; Fu, K.W.; Tse, Z.T.H.; Hou, S.I. Pedagogical Demonstration of Twitter Data Analysis: A Case Study of World AIDS Day, 2014. Data 2019, 4, 84. [Google Scholar] [CrossRef] [Green Version]
- Kim, E.H.J.; Jeong, Y.K.; Kim, Y.; Kang, K.Y.; Song, M. Topic-based content and sentiment analysis of Ebola virus on Twitter and in the news. J. Inf. Sci. 2016, 42, 763–781. [Google Scholar] [CrossRef]
- Samuel, J.; Ali, N.; Rahman, M.; Samuel, Y.; Pelaez, A. Feeling Like it is Time to Reopen Now? COVID-19 New Normal Scenarios Based on Reopening Sentiment Analytics. arXiv 2005, arXiv:2005.10961. [Google Scholar] [CrossRef]
- Nagar, R.; Yuan, Q.; Freifeld, C.C.; Santillana, M.; Nojima, A.; Chunara, R.; Brownstein, J.S. A case study of the New York City 2012–2013 influenza season with daily geocoded Twitter data from temporal and spatiotemporal perspectives. J. Med Internet Res. 2014, 16, e236. [Google Scholar] [CrossRef] [Green Version]
- Chae, B.K. Insights from hashtag# supplychain and Twitter Analytics: Considering Twitter and Twitter data for supply chain practice and research. Int. J. Prod. Econ. 2015, 165, 247–259. [Google Scholar]
- Carvalho, J.P.; Rosa, H.; Brogueira, G.; Batista, F. MISNIS: An intelligent platform for twitter topic mining. Expert Syst. Appl. 2017, 89, 374–388. [Google Scholar] [CrossRef] [Green Version]
- Vijayan, V.K.; Bindu, K.; Parameswaran, L. A comprehensive study of text classification algorithms. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017; pp. 1109–1113. [Google Scholar]
- Zhang, J.; Yang, Y. Robustness of regularized linear classification methods in text categorization. In Proceedings of the 26th Annual International ACM SIGIR Conference On Research and Development in Informaion Retrieval, Toronto, ON, Canada, 28 July 2003; pp. 190–197. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Liu, B.; Blasch, E.; Chen, Y.; Shen, D.; Chen, G. Scalable sentiment classification for big data analysis using naive bayes classifier. In Proceedings of the 2013 IEEE International Conference on Big Data, Silicon Valley, CA, USA, 6–9 October 2013; pp. 99–104. [Google Scholar]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef] [Green Version]
- Troussas, C.; Virvou, M.; Espinosa, K.J.; Llaguno, K.; Caro, J. Sentiment analysis of Facebook statuses using Naive Bayes classifier for language learning. In Proceedings of the IISA 2013, Piraeus, Greece, 10–12 July 2013; pp. 1–6. [Google Scholar]
- Ting, S.; Ip, W.; Tsang, A.H. Is Naive Bayes a good classifier for document classification. Int. J. Softw. Eng. Appl. 2011, 5, 37–46. [Google Scholar]
- Boiy, E.; Hens, P.; Deschacht, K.; Moens, M.F. Automatic Sentiment Analysis in On-line Text. In Proceedings of the ELPUB 2007 Conference on Electronic Publishing, Vienna, Austria, 13–15 June 2007; pp. 349–360. [Google Scholar]
- Pranckevičius, T.; Marcinkevičius, V. Comparison of naive bayes, random forest, decision tree, support vector machines, and logistic regression classifiers for text reviews classification. Balt. J. Mod. Comput. 2017, 5, 221. [Google Scholar] [CrossRef]
- Ramadhan, W.; Novianty, S.A.; Setianingsih, S.C. Sentiment analysis using multinomial logistic regression. In Proceedings of the 2017 International Conference on Control, Electronics, Renewable Energy and Communications (ICCREC), Yogyakarta, Indonesia, 26–28 September 2017; pp. 46–49. [Google Scholar]
- Rubegni, P.; Cevenini, G.; Burroni, M.; Dell’Eva, G.; Sbano, P.; Cuccia, A.; Andreassi, L. Digital dermoscopy analysis of atypical pigmented skin lesions: A stepwise logistic discriminant analysis approach. Skin Res. Technol. 2002, 8, 276–281. [Google Scholar] [CrossRef]
- Silva, I.; Eugenio Naranjo, J. A Systematic Methodology to Evaluate Prediction Models for Driving Style Classification. Sensors 2020, 20, 1692. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Buldin, I.D.; Ivanov, N.S. Text Classification of Illegal Activities on Onion Sites. In Proceedings of the 2020 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), St. Petersburg/Moscow, Russia, 27–30 January 2020; pp. 245–247. [Google Scholar]
- Tan, Y. An improved KNN text classification algorithm based on K-medoids and rough set. In Proceedings of the 2018 10th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC), Hangzhou, China, 25–26 August 2018; Volume 1, pp. 109–113. [Google Scholar]
- Conner, C.; Samuel, J.; Kretinin, A.; Samuel, Y.; Nadeau, L. A Picture for The Words! Textual Visualization in Big Data Analytics. Northeast Bus. Econ. Assoc. Annu. Proc. 2019, 46, 37–43. [Google Scholar]
- Samuel, Y.; George, J.; Samuel, J. Beyond STEM, How Can Women Engage Big Data, Analytics, Robotics & Artificial Intelligence? An Exploratory Analysis of Confidence & Educational Factors in the Emerging Technology Waves Influencing the Role of, & Impact Upon, Women. arXiv 2020, arXiv:2003.11746. [Google Scholar]
- Svetlov, K.; Platonov, K. Sentiment Analysis of Posts and Comments in the Accounts of Russian Politicians on the Social Network. In Proceedings of the 2019 25th Conference of Open Innovations Association (FRUCT), Helsinki, Finland, 5–8 November 2019; pp. 299–305. [Google Scholar]
- Saif, H.; Fernández, M.; He, Y.; Alani, H. On Stopwords, Filtering and Data Sparsity for Sentiment Analysis of Twitter; European Language Resources Association (ELRA): Reykjavik, Iceland, 2014. [Google Scholar]
- Ravi, K.; Ravi, V. A survey on opinion mining and sentiment analysis: Tasks, approaches and applications. Knowl. Based Syst. 2015, 89, 14–46. [Google Scholar] [CrossRef]
- Jockers, M.L. Syuzhet: Extract Sentiment and Plot Arcs from Text, R package version 1.0.4; CRAN, 2017. Available online: https://cran.r-project.org/web/packages/syuzhet/syuzhet.pdf (accessed on 11 June 2020).
- Rinker, T.W. sentimentr: Calculate Text Polarity Sentiment; Version 2.7.1; Buffalo: New York, NY, USA, 2019. [Google Scholar]
- Almatarneh, S.; Gamallo, P. Comparing supervised machine learning strategies and linguistic features to search for very negative opinions. Information 2019, 10, 16. [Google Scholar] [CrossRef] [Green Version]
- Jurafsky, D.; Martin, J. Speech and Language Processing, 3rd ed.; Stanford University: Stanford, CA, USA, 2019. [Google Scholar]
- Bayes, T. An Essay Toward Solving a Problem in the Doctrine of Chances, 1763. In MD Computing: Computers in Medical Practice; NCBI: Bethesda, MD, USA, 1991; Volume 8, p. 157. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Sharma, S.; Jain, A. Hybrid Ensemble Learning With Feature Selection for Sentiment Classification in Social Media. Int. J. Inf. Retr. Res. (IJIRR) 2020, 10, 40–58. [Google Scholar] [CrossRef]
- Evangelopoulos, N.; Zhang, X.; Prybutok, V.R. Latent semantic analysis: Five methodological recommendations. Eur. J. Inf. Syst. 2012, 21, 70–86. [Google Scholar] [CrossRef]
- Samuel, J.; Holowczak, R.; Pelaez, A. The Effects of Technology Driven Information Categories on Performance in Electronic Trading Markets. J. Inf. Technol. Manag. 2017, 28, 1–14. [Google Scholar]
- Ahmed, W.; Bath, P.; Demartini, G. Using Twitter as a data source: An overview of ethical, legal, and methodological challenges. Adv. Res. Ethics Integr. 2017, 2, 79–107. [Google Scholar]
- Buchanan, E. Considering the ethics of big data research: A case of Twitter and ISIS/ISIL. PLoS ONE 2017, 12, e0187155. [Google Scholar] [CrossRef] [PubMed] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Total | Hashtags | Mentions | Urls | Pols | Corona | Flu | Beer | AbuseW |
|---|---|---|---|---|---|---|---|---|---|
| iPhone | 3281 | 495 | 2305 | 77 | 218 | 4238 | 171 | 336 | 111 |
| Android | 1180 | 149 | 1397 | 37 | 125 | 1050 | 67 | 140 | 41 |
| iPad | 75 | 6 | 96 | 4 | 12 | 85 | 4 | 8 | 2 |
| Cities | 30 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Tagged | Frequency | Hashtag | Frequency |
|---|---|---|---|
| realDonaldTrump | 74 | coronavirus | 23 |
| CNN | 21 | DemDebate | 16 |
| ImtiazMadmood | 16 | corona | 8 |
| corona | 13 | CoronavirusOutbreak | 8 |
| AOC | 12 | CoronaVirusUpdates | 7 |
| coronaextrausa | 12 | coronavirususa | 7 |
| POTUS | 12 | Corona | 6 |
| CNN MSNBC | 11 | COVID19 | 5 |
| Source | Frequency | Screen Name | Frequency |
|---|---|---|---|
| Twitter for iPhone | 3281 | _CoronaCA | 30 |
| Twitter for Android | 1180 | MBilalY | 25 |
| Twitter for iPad | 75 | joanna_corona | 17 |
| Cities | 30 | eads_john | 13 |
| Tweetbot for i<U+039F>S | 29 | _jvm2222 | 11 |
| CareerArc2.0 | 14 | AlAboutNothing | 11 |
| Twitter Web Client | 16 | dallasreese | 9 |
| 511NY-Tweets | 3 | CpaCarter | 8 |
| Classifier | Characteristic | Strength | Weakness |
|---|---|---|---|
| Linear regression | Minimize sum of squared differences between predicted and true values | Intuitive, useful and stable, easy to understand | Sensitive to outliers; Ineffective with non-linearity |
| Logistic regression | Probability of an outcome is based on a logistic function | Transparent and easy to understand; Regularized to avoid over-fitting | Expensive training phase; Assumption of linearity |
| Naïve Bayes classifier | Based on assumption of independence between predictor variables | Effective with real-world data; Efficient and can deal with dimensionality | Over-simplified assumptions; Limited by data scarcity |
| K-Nearest Neighbor | Computes classification based on weights of the nearest neighbors, instance based | KNN is easy to implement, efficient with small data, applicable for multi-class problems | Inefficient with big data; Sensitive to data quality; Noisy features degrade the performance |
| Tagged | Frequency | Stated | Frequency |
|---|---|---|---|
| Los Angeles, CA | 183 | Los Angeles, CA | 78 |
| Manhattan, NY | 130 | United States | 75 |
| Florida, USA | 84 | Washington, DC | 60 |
| Chicago, IL | 71 | New York, NY | 54 |
| Houston, TX | 65 | California, USA | 49 |
| Texas, USA | 57 | Chicago, IL | 40 |
| Brooklyn, NY | 51 | Houston, TX | 39 |
| San Antonio, TX | 51 | Corona, CA | 33 |
| Tweets (nchar < 77) | Tweets (nchar < 120) | ||||
|---|---|---|---|---|---|
| Negative | Positive | Negative | Positive | ||
| Negative | 34 | 1 | Negative | 34 | 1 |
| Positive | 5 | 30 | Positive | 29 | 6 |
| Accuracy: 0.9143 | Accuracy: 0.5714 | ||||
| Tweets (nchar < 77) | Tweets (nchar < 120) | ||||
|---|---|---|---|---|---|
| Negative | Positive | Negative | Positive | ||
| Negative | 30 | 5 | Negative | 21 | 14 |
| Positive | 13 | 22 | Positive | 19 | 16 |
| Accuracy: 0.7429 | Accuracy: 0.52 | ||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samuel, J.; Ali, G.G.M.N.; Rahman, M.M.; Esawi, E.; Samuel, Y. COVID-19 Public Sentiment Insights and Machine Learning for Tweets Classification. Information 2020, 11, 314. https://doi.org/10.3390/info11060314
Samuel J, Ali GGMN, Rahman MM, Esawi E, Samuel Y. COVID-19 Public Sentiment Insights and Machine Learning for Tweets Classification. Information. 2020; 11(6):314. https://doi.org/10.3390/info11060314
Chicago/Turabian StyleSamuel, Jim, G. G. Md. Nawaz Ali, Md. Mokhlesur Rahman, Ek Esawi, and Yana Samuel. 2020. "COVID-19 Public Sentiment Insights and Machine Learning for Tweets Classification" Information 11, no. 6: 314. https://doi.org/10.3390/info11060314
APA StyleSamuel, J., Ali, G. G. M. N., Rahman, M. M., Esawi, E., & Samuel, Y. (2020). COVID-19 Public Sentiment Insights and Machine Learning for Tweets Classification. Information, 11(6), 314. https://doi.org/10.3390/info11060314