Ensemble-Based Spam Detection in Smart Home IoT Devices Time Series Data Using Machine Learning Techniques




Abstract
:1. Introduction
- Analyzing the time-series data of the smart home IoT devices to understand the underlying structure of the data for better predictions.
- Use of machine learning modeling to assign a feature importance score to the IoT device and predict the total consumption of energy.
- Calculation of a spam score of IoT devices to enhance the security of the smart home environment with the help of feature importance scores and the errors in energy prediction.
2. Related Work
3. Materials and Methods
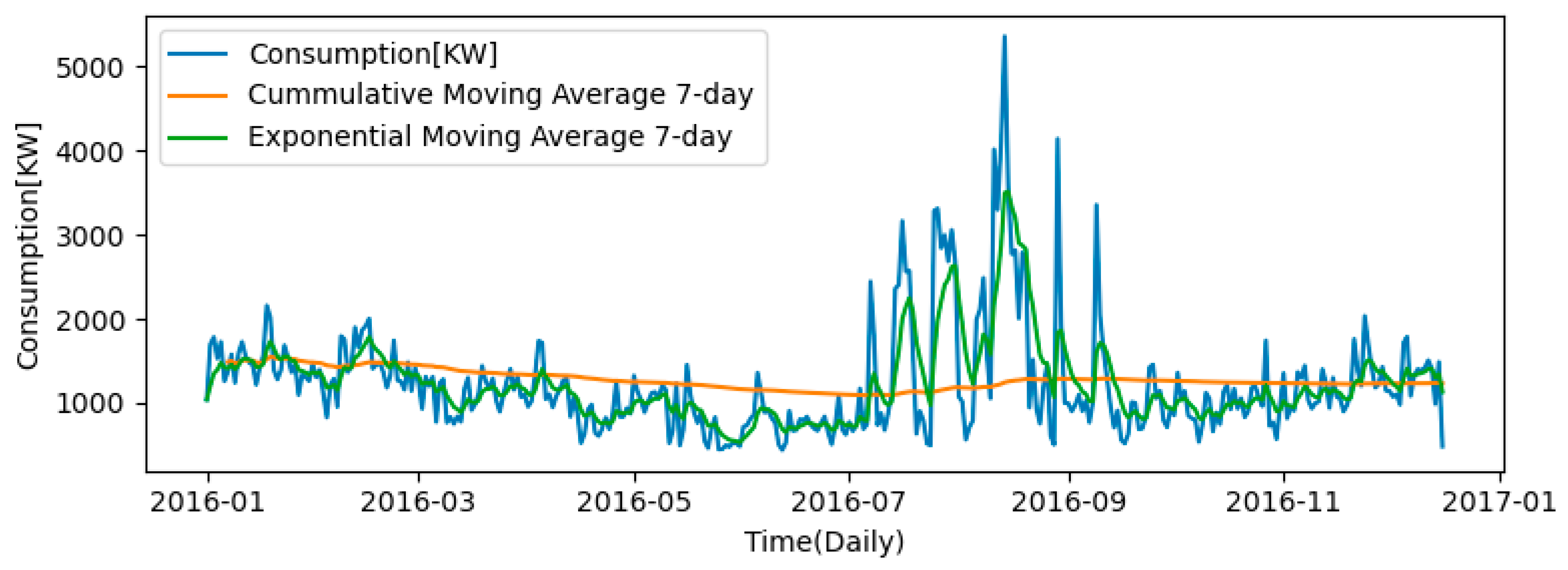
3.1. Moving Average
- Simple Moving Average (SMA)
- Exponential Moving Average (EMA)
3.2. Machine Learning Models
- (1)
- Extreme Gradient Boosting (XGBoost): This is a popular supervised machine learning model with characteristics of distributed and out-of-core computation, efficiency, and parallelization [25]. The parallelization occurs for multiple nodes in a single tree and not across trees. The complexity in XGboost is defined as:The term penalizes the complexity of the regression tree functions. is a constant (a larger value of is associated with complex decision rules in which deeper nodes are penalized severely), the weight, and the number of leaves in a tree. The regularization added term helps in avoiding overfitting by smoothing the final learned weights. The main advantage of XGBoost is its scalability and quick execution speed, and it usually outperforms the other ML models [26].
- (2)
- Decision Trees: It employs a top-down approach, by utilizing standard deviation reduction to partition the data into subsets of homogeneous values [27]. It incorporates mixtures of categorical and numerical predictor variables with an integral part of the procedure to perform internal feature selection. These are the reasons why decision trees have emerged as one of the most popular data mining learning methods [28]. Decision trees can create an over-complex tree, which does not tend to generalize the data well and can result in overfitting. Even though the decision tree does not perform as well as neural networks for nonlinear networks, it is usually susceptible to noisy data. Decision trees expect visible trends in the data and also perform well on sequential patterns; if this is not the case, then decision trees have to be avoided for time series applications [29].
- (3)
- Random Forest: A supervised learning algorithm used for both classification and regression. It is an ensemble of decision trees which helps in reducing the variance in decision trees [30]. It performs a balance between high variance and high bias by sampling with each tree fitted and a sample of features at each split, respectively. The performance of random forest is dependent on the suitable selection of the number of trees, N. As in the case of bagging, a greater value of N does not necessarily overfit the data, and hence, a sufficiently large value of N can be chosen [31].
- (4)
- Gradient Boosted regression model: This model is like random forests, but the key difference is that the trees are built successively. The residual errors from the previous trees are fixed with the next tree to improve the fit [32]. One of the noticeable features of gradient boosted trees is that the algorithm detects the interactions among the features is detected automatically. However, the performance of gradient boosted trees is based on careful tuning and performs better than random forests if tuned appropriately. Gradient boosted trees are not preferred if the data consists of a lot of noise and can result in overfitting.
- a value closer to 100% indicates the model is highly correlated,
- a value closer to 0 indicates the model to be perfect.
3.3. Methodology
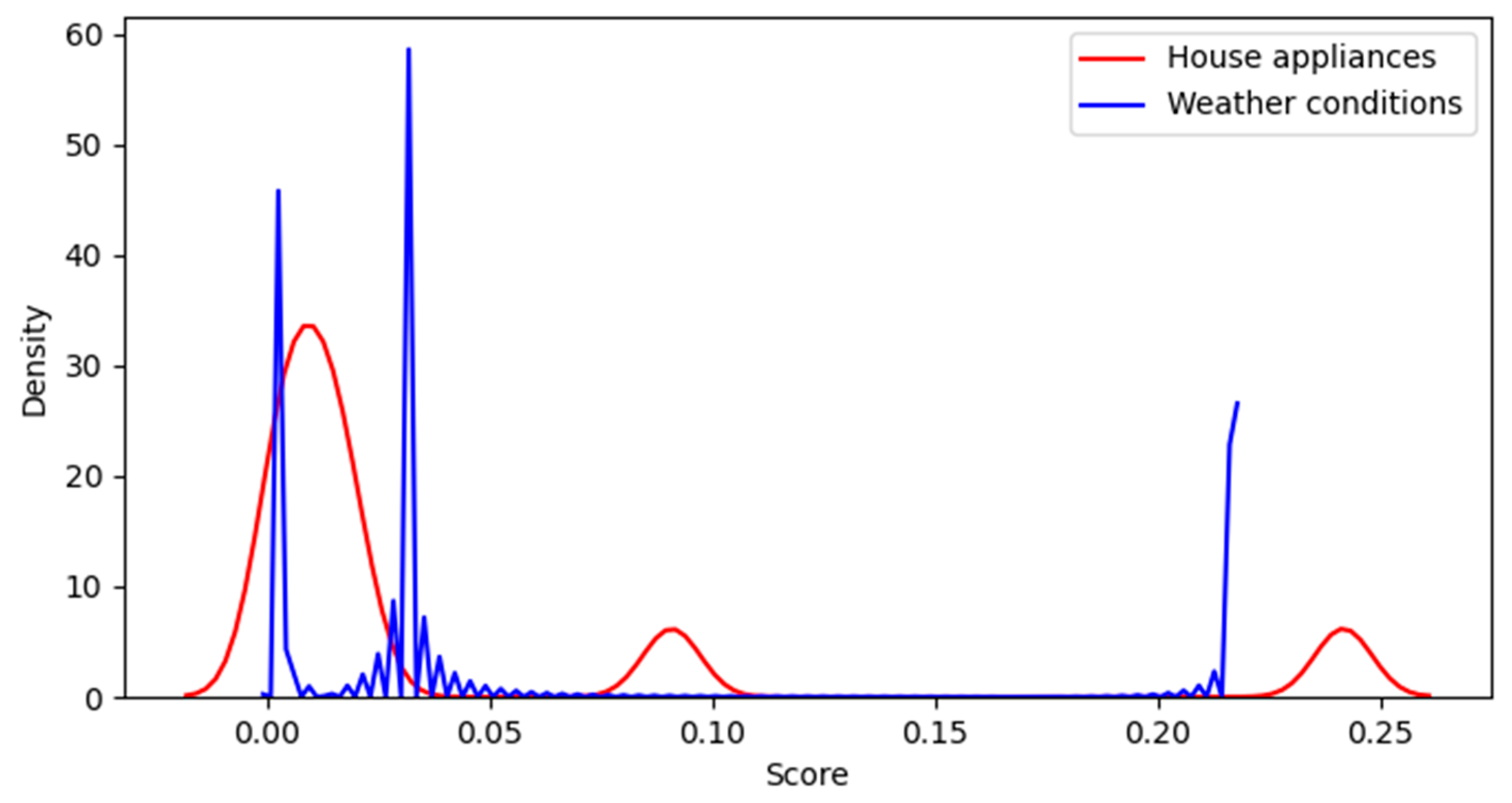
3.4. Spamicity Score
| Algorithm 1 | Calculation of Spamicity Score |
| Input | Time series data |
| Output | Spamicity score |
| f <- Features (data) | |
| Target <- data | |
| Model (Features, target) Choice of ML model | |
| importance <- model(feature importances) for i, v <- enumerate(importance) calculating the feature scores end for params <- {p1, p2, p3} for i in params model (params) R2 score [i] R2[i]= best parameter <- result end for | |
| def MLpool(i) for m = 1 to count(Mi) do model(best parameter) RMSE[i] RMSE[i]= end for w <- workers p <- pool(w)p (MLpool, f) end def for j = 1 to count(f) do S ⇐ | |
| end for |
4. Results
4.1. Data Description
4.2. Feature Selection
4.3. Data Preprocessing
4.4. Data Statistics
4.5. Results of Machine Learning Models on the Smart Home Dataset
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chapter 19: Admission Control-Based Load Protection in the Smart Grid—Security and Privacy in Cyber-Physical Systems. Available online: https://learning.oreilly.com/library/view/security-and-privacy/9781119226048/c19.xhtml (accessed on 30 April 2020).
- Smart Meters—Threats and Attacks to PRIME Meters—Tarlogic Security—Cyber Security and Ethical Hacking. Available online: https://www.tarlogic.com/en/blog/smart-meters-threats-and-attacks-to-prime-meters/ (accessed on 5 May 2020).
- Makkar, A.; Garg, S.; Kumar, N.; Hossain, M.S.; Ghoneim, A.; Alrashoud, M. An Efficient Spam Detection Technique for IoT Devices using Machine Learning. IEEE Trans. Ind. Inform. 2020. [Google Scholar] [CrossRef]
- Choi, J.; Jeoung, H.; Kim, J.; Ko, Y.; Jung, W.; Kim, H.; Kim, J. Detecting and identifying faulty IoT devices in smart home with context extraction. In Proceedings of the 48th Annual IEEE/IFIP International Conference on Dependable Systems and Networks, DSN 2018, Luxembourg, 25–28 June 2018; pp. 610–621. [Google Scholar] [CrossRef]
- Tang, S.; Gu, Z.; Yang, Q.; Fu, S. Smart Home IoT Anomaly Detection based on Ensemble Model Learning from Heterogeneous Data. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 4185–4190. [Google Scholar] [CrossRef]
- Wang, Y.; Amin, M.M.; Fu, J.; Moussa, H.B. A novel data analytical approach for false data injection cyber-physical attack mitigation in smart grids. IEEE Access 2017, 5, 26022–26033. [Google Scholar] [CrossRef]
- Alagha, A.; Singh, S.; Mizouni, R.; Ouali, A.; Otrok, H. Data-Driven Dynamic Active Node Selection for Event Localization in IoT Applications—A Case Study of Radiation Localization. IEEE Access 2019, 7, 16168–16183. [Google Scholar] [CrossRef]
- Mishra, P.; Gudla, S.K.; ShanBhag, A.D.; Bose, J. Enhanced Alternate Action Recommender System Using Recurrent Patterns and Fault Detection System for Smart Home Users. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 651–656. [Google Scholar] [CrossRef]
- Gaddam, A.; Wilkin, T.; Angelova, M. Anomaly detection models for detecting sensor faults and outliers in the iot-a survey. In Proceedings of the 2019 13th International Conference on Sensing Technology (ICST), Sydney, Australia, 2–4 December 2019. [Google Scholar] [CrossRef]
- Motlagh, N.H.; Khajavi, S.H.; Jaribion, A.; Holmstrom, J. An IoT-based automation system for older homes: A use case for lighting system. In Proceedings of the 2018 IEEE 11th Conference on Service-Oriented Computing and Applications (SOCA), Paris, France, 20–22 November 2018; pp. 247–252. [Google Scholar] [CrossRef]
- Osuwa, A.A.; Ekhoragbon, E.B.; Fat, L.T. Application of artificial intelligence in Internet of Things. In Proceedings of the 9th International Conference on Computational Intelligence and Communication Networks, CICN 2017, Girne, Cyprus, 16–17 September 2017; pp. 169–173. [Google Scholar] [CrossRef]
- Song, M.; Zhong, K.; Zhang, J.; Hu, Y.; Liu, D.; Zhang, W.; Wang, J.; Li, T. In-Situ AI: Towards Autonomous and Incremental Deep Learning for IoT Systems. In Proceedings of the 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), Vienna, Austria, 24–28 February 2018; pp. 92–103. [Google Scholar] [CrossRef]
- Ma, J.; Perkins, S. Online novelty detection on temporal sequences. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003; pp. 613–618. [Google Scholar] [CrossRef]
- Li, J.; Pedrycz, W.; Jamal, I. Multivariate time series anomaly detection: A framework of Hidden Markov Models. Appl. Soft Comput. J. 2017, 60, 229–240. [Google Scholar] [CrossRef]
- Flanagan, K.; Fallon, E.; Connolly, P.; Awad, A. Network anomaly detection in time series using distance based outlier detection with cluster density analysis. In Proceedings of the 2017 Internet Technologies and Applications (ITA), Wrexham, UK, 12–15 September 2017; pp. 116–121. [Google Scholar] [CrossRef]
- Zhang, A.; Song, S.; Wang, J.; Yu, P.S. Time series data cleaning: From anomaly detection to anomaly repairing. Proc. VLDB Endow. 2017, 10, 1046–1057. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Zuo, W.; Wang, Y. Research on Opinion Spam Detection by Time Series Anomaly Detection. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer Nature: Cham, Switzerland, 2019; Volume 11632, pp. 182–193. [Google Scholar] [CrossRef]
- Makkar, A.; Kumar, N. Cognitive spammer: A Framework for PageRank analysis with Split by Over-sampling and Train by Under-fitting. Future Gener. Comput. Syst. 2019, 90, 381–404. [Google Scholar] [CrossRef]
- Hau, Z.; Lupu, E.C. Exploiting correlations to detect false data injections in low-density wireless sensor networks. In Proceedings of the CPSS 2019 5th on Cyber-Physical System Security Workshop, Auckland, New Zealand, 8 July 2019; Volume 19, pp. 1–12. [Google Scholar] [CrossRef] [Green Version]
- Mehrdad, S.; Mousavian, S.; Madraki, G.; Dvorkin, Y. Cyber-Physical Resilience of Electrical Power Systems Against Malicious Attacks: A Review. Curr. Sustain. Energy Rep. 2018, 5, 14–22. [Google Scholar] [CrossRef]
- Prasad, N.R.; Almanza-Garcia, S.; Lu, T.T. Anomaly detection. Comput. Mater. Contin. 2009, 14, 1–22. [Google Scholar] [CrossRef]
- Risteska Stojkoska, B.L.; Trivodaliev, K.V. A review of Internet of Things for smart home: Challenges and solutions. J. Clean. Prod. 2017, 140, 1454–1464. [Google Scholar] [CrossRef]
- Bakar, U.A.B.U.A.; Ghayvat, H.; Hasanm, S.F.; Mukhopadhyay, S.C. Activity and anomaly detection in smart home: A survey. In Smart Sensors, Measurement and Instrumentation; Springer International Publishing: Cham, Switzerland, 2016; Volume 16, pp. 191–220. [Google Scholar]
- Massana, J.; Pous, C.; Burgas, L.; Melendez, J.; Colomer, J. Short-term load forecasting in a non-residential building contrasting models and attributes. Energy Build. 2015, 92, 322–330. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Ruiz-Abellón MD, C.; Gabaldón, A.; Guillamón, A. Load forecasting for a campus university using ensemble methods based on regression trees. Energies 2018, 11, 2038. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. Simplifying decision trees. Int. J. Hum. Comput. Stud. 1999, 51, 497–510. [Google Scholar] [CrossRef] [Green Version]
- Ruppert, D. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. J. Am. Stat. Assoc. 2004, 99, 567. [Google Scholar] [CrossRef]
- Tso, G.K.; Yau, K.K. Predicting electricity energy consumption: A comparison of regression analysis, decision tree and neural networks. Energy 2007, 32, 1761–1768. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Smart Home Dataset with Weather Information | Kaggle. Available online: https://www.kaggle.com/taranvee/smart-home-dataset-with-weather-information (accessed on 24 May 2020).
- Dickey, D.A.; Fuller, W.A. Distribution of the Estimators for Autoregressive Time Series with a Unit Root. J. Am. Stat. Assoc. 1979, 74, 427–431. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Tuning Parameter | Result | Package | Method |
|---|---|---|---|---|
| Model 1 | N_estimators, max depth | 1000, 9 | xgboost | XGBRegressor |
| Model 2 | Max depth | 9 | sklearn | DecisionTreeRegressor |
| Model 3 | Max features, max depth | 10, 9 | ensemble | RandomForestRegressor |
| Model 4 | Max features, learning rate | 12, 0.1 | ensemble | GradientBoostingRegressor |
| Feature | Attribute Importance |
|---|---|
| Solar [kW] | 0.02406 |
| Dishwasher [kW] | 0.01054 |
| Home office [kW] | 0.01611 |
| Fridge [kW] | 0.01409 |
| Wine cellar [kW] | 0.00530 |
| Garage door [kW] | 0.35486 |
| Barn [kW] | 0.02593 |
| Well [kW] | 0.12521 |
| Microwave [kW] | 0.00646 |
| Living room [kW] | 0.03306 |
| Icon | 0.00292 |
| Humidity | 0.00210 |
| Visibility | 0.00147 |
| Apparent temperature | 0.00238 |
| Pressure | 0.00434 |
| Windspeed | 0.00336 |
| CloudCover | 0.00185 |
| Wind Bearing | 0.00296 |
| PrecipIntensity | 0.00048 |
| DewPoint | 0.05101 |
| PrecipProbability | 0.00030 |
| SumFurnace | 0.29437 |
| AvgKitchen | 0.01681 |
| Count | 503,909 |
|---|---|
| Average | 0.858962 |
| Standard deviation | 1.058208 |
| Minimum | 0.000000 |
| 25% | 0.367667 |
| 50% | 0.562333 |
| 75% | 0.970250 |
| max | 14.71456 |
| Test Statistic | Value |
|---|---|
| p-value | 0.0 |
| Test statistic | −93.5733 |
| 1% Critical values | −3.43036 |
| 5% Critical values | −2.86154 |
| 10% Critical values | −2.56677 |
| Model | R2 Score | Mean Absolute Error | Explained Variance | Score Distribution |
|---|---|---|---|---|
| Model—1 (XGBoost) | 0.809 | 0.152 | 0.809 | Refer—Figure 8 |
| Model—2 (Decision Trees) | 0.692 | 0.192 | 0.692 | Refer—Figure 9 |
| Model—3 (Random Forest) | 0.789 | 0.186 | 0.790 | Refer—Figure 10 |
| Model—4 (Gradient Boosted regression) | 0.798 | 0.176 | 0.799 | Refer—Figure 11 |
| IoT Device | Model 1 | Model 2 | Model 3 | Model 4 |
|---|---|---|---|---|
| Solar [kW] | 0.01756 | 0.01805 | 0.01298 | 0.01365 |
| Dishwasher [kW] | 0.00706 | 0.00748 | 0.00596 | 0.02428 |
| Home office [kW] | 0.01176 | 0.01273 | 0.00685 | 0.00740 |
| Fridge [kW] | 0.00972 | 0.00986 | 0.00355 | 0.00676 |
| Wine cellar [kW] | 0.00398 | 0.00435 | 0.00119 | 0.00534 |
| Garage door [kW] | 0.20937 | 0.21646 | 0.24176 | 0.16634 |
| Barn [kW] | 0.01919 | 0.02023 | 0.01334 | 0.01344 |
| Well [kW] | 0.08514 | 0.08765 | 0.09095 | 0.09633 |
| Microwave [kW] | 0.00510 | 0.05278 | 0.01580 | 0.24607 |
| Living room [kW] | 0.02347 | 0.02777 | 0.02019 | 0.01847 |
| IoT Device | Model 1 | Model 2 | Model 3 | Model 4 |
|---|---|---|---|---|
| Temperature | 0.00213 | 0.00225 | 0.00043 | 0.00949 |
| Humidity | 0.00155 | 0.00160 | 0.00008 | 0.00012 |
| Visibility | 0.00109 | 0.00118 | 0.00019 | 0.00028 |
| Apparent Temperature | 0.00174 | 0.00179 | 0.00057 | 0.00568 |
| Pressure | 0.00321 | 0.00347 | 0.00019 | 0.00011 |
| WindSpeed | 0.00249 | 0.00272 | 0.00062 | 0.00002 |
| CloudCover | 0.00137 | 0.00141 | 0.00017 | 0.00002 |
| WindBearing | 0.00219 | 0.00228 | 0.00005 | 0.00008 |
| PrecipIntensity | 0.00036 | 0.00036 | 0.00000 | 0.00002 |
| DewPoint | 0.03724 | 0.03877 | 0.03218 | 0.07196 |
| PrecipProbability | 0.00022 | 0.00023 | 0.00000 | 0.00000 |
| SumFurnace | 0.18545 | 0.18840 | 0.21717 | 0.18320 |
| AvgKitchen | 0.01126 | 0.01143 | 0.00311 | 0.01108 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zainab, A.; S. Refaat, S.; Bouhali, O. Ensemble-Based Spam Detection in Smart Home IoT Devices Time Series Data Using Machine Learning Techniques. Information 2020, 11, 344. https://doi.org/10.3390/info11070344
Zainab A, S. Refaat S, Bouhali O. Ensemble-Based Spam Detection in Smart Home IoT Devices Time Series Data Using Machine Learning Techniques. Information. 2020; 11(7):344. https://doi.org/10.3390/info11070344
Chicago/Turabian StyleZainab, Ameema, Shady S. Refaat, and Othmane Bouhali. 2020. "Ensemble-Based Spam Detection in Smart Home IoT Devices Time Series Data Using Machine Learning Techniques" Information 11, no. 7: 344. https://doi.org/10.3390/info11070344
APA StyleZainab, A., S. Refaat, S., & Bouhali, O. (2020). Ensemble-Based Spam Detection in Smart Home IoT Devices Time Series Data Using Machine Learning Techniques. Information, 11(7), 344. https://doi.org/10.3390/info11070344