A Fast Algorithm to Initialize Cluster Centroids in Fuzzy Clustering Applications



Abstract
:1. Introduction
2. Materials and Methods
2.1. Fuzzy C-Means Clustering and Fuzzy Validity Indices
- Initialize the membership matrix and the prototype matrix .
- Update the cluster prototypes:
- Update the membership values with:
- If then stop else go to the step 2, where is the iteration number.
2.2. Related Works on Initialization of Cluster Centroids
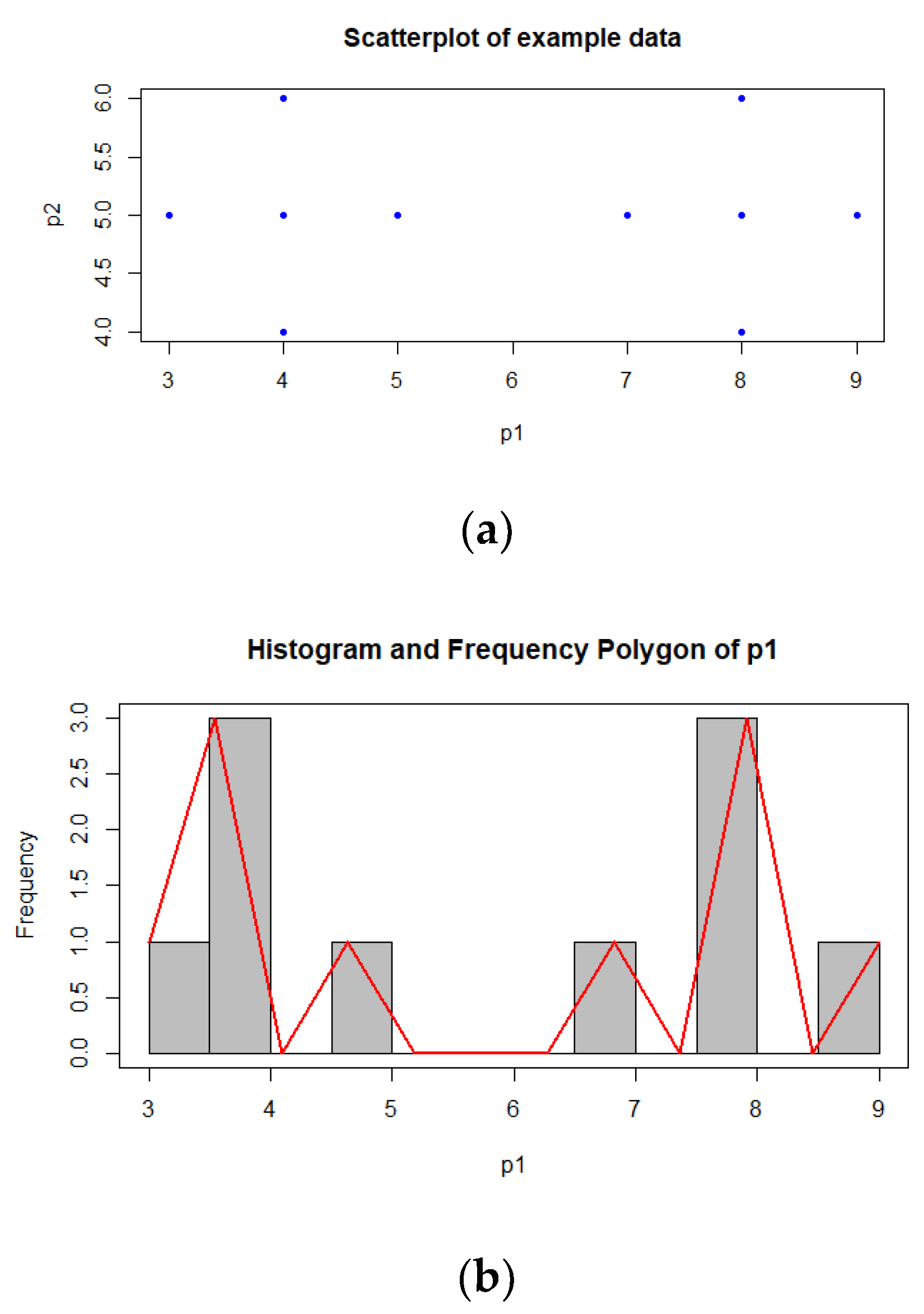
2.3. Proposed Algorithm: Initialization on Frequency Polygons
- pv1 = {3.75, 4.75, 6.75, 7.75, 8.75}; pc1 = {3, 1, 1, 2, 1}
- pv2 = {4.75, 5.75}; pc2 = {6, 2}
| Algorithm 1. findpolypeaks |
| Input: xc, vector for the frequencies of classes (or bins) of a frequency polygon xm, vector for the middle values of classes (or bins) of a frequency polygon tc, threshold frequency value for filtering frequency polygon data, default value is 1 Output: PM: Peaks matrix for a feature Init: 1: xc ← xc [xc >= tc]; xm ← xm [xc >= tc] //Filter xm and xc for the class frequencies >= tc 2: pfreqs ← {} //Atomic vector for the frequencies of peaks 3: pvalues ← {} // Atomic vector for the values of peaks 4: nc ← length of xc //Number of classes (or number of bins) 5: pidx ← 1 //Index of the first peak Run: 6: IF nc > 1 THEN 7: IF xc [1] > xc [2] THEN 8: pvalues [1]← xm [1]; pfreqs [1]← xc [1] 9: pidx ← 2 10: ENDIF 11: FOR i = 2 to nc-1 DO 12: IF xc [i] not equal to xc [i − 1] THEN 13: IF xc [i] > xc [i − 1] AND xc [i] >= xc [i + 1] THEN 14: pvalues [pidx] ← xm [i] 15: pfreqs [pidx] ← xc [i] 16: pidx ← pidx + 1 17: ENDIF 18: ENDIF 19: ENDFOR 20: IF xc [nc] > xc [nc − 1] THEN 21: pvalues [pidx]← xm [nc]; pfreqs [pidx]← xc [nc] 22: ENDIF 23: ELSE 24: pvalues [pidx] ← xm [1]; pfreqs [pidx]← xc [1] 25: ENDIF 26: np ← length of pvalues 27: PMnpx2 ← 0 //Create peaks matrix 28: PM [1] ← pvalues; PM [2] ← pfreqs 29: RETURN PM, np |
| Algorithm 2. InoFrep |
| Input: Xnxp, dataset as matrix (n: number of instances, p: number of features) c, Number of clusters used by the partitioning algorithm nc, Number of classes to generate frequency polygons Output: Vnxc, Initial centroids matrix Init: 1: V [i,j] ← 0 //Set 0 to V matrix; i = 1,…,c; j = 1,...,p 2: peakcounts ← { } //Atomic vector to store the peak counts Run: 3: FOR each feature j DO 4: COMPUTE the middle values and frequencies from the frequency polygon of the feature j using nc 5: jmids ← {Middle values of the classes of frequency polygon of feature j} 6: jcounts ← {Frequencies of the classes of frequency polygon of feature j} 7: CALL findpolypeaks with jmids and jcounts 8: peakcounts [j] ← number of rows of PM //number of peaks for the feature j from findpolypeaks 9: ENDFOR 10: maxj ← index of max{peakcounts} 11: COMPUTE the middle values and frequencies from the frequency polygon of the feature maxj using nc 12: midsmaxj ← {Middle values of the classes of frequency polygon of the feature maxj} 13: countmaxj ← {Frequencies of the classes of frequency polygon of the feature maxj} 14: CALL findpolypeaks with midsmaxj and countmaxj 15: np ← number of peak counts for the feature maxj from the findpolypeaks algorithm 16: PM [1] ← {Peak values of the feature maxj} 17: PM [2] ← {Peak frequencies of the feature maxj} 18: PMS ← SORT PM on the 2nd column in descending order and store in PMS 19: i ← 1 20: WHILE i <= c DO 21: IF i ≤ np THEN 22: //Find the nearest data point of the feature maxj to the ith peak value 23: idx ← argmin{|X [,maxj]–PMS [i,1]|} 24: ELSE 25: REPEAT 26: duplicatedcenters ← false 27: idx ← rand(X [,maxj]) // One random sample on the feature maxj 28: FOR k = 1 to i − 1 29: IF X [idx, maxj] = V [k,maxj] THEN 30: duplicatedcenters ← true 31: ENDIF 32: ENDFOR 33: UNTIL not duplicatedcenters 34: ENDIF 35: FOR each feature j DO 36: V [i,j] ← X [idx, j] 37: ENDFOR 38: INCREMENT i 39: ENDWHILE 40: RETURN V |
3. Results and Discussion
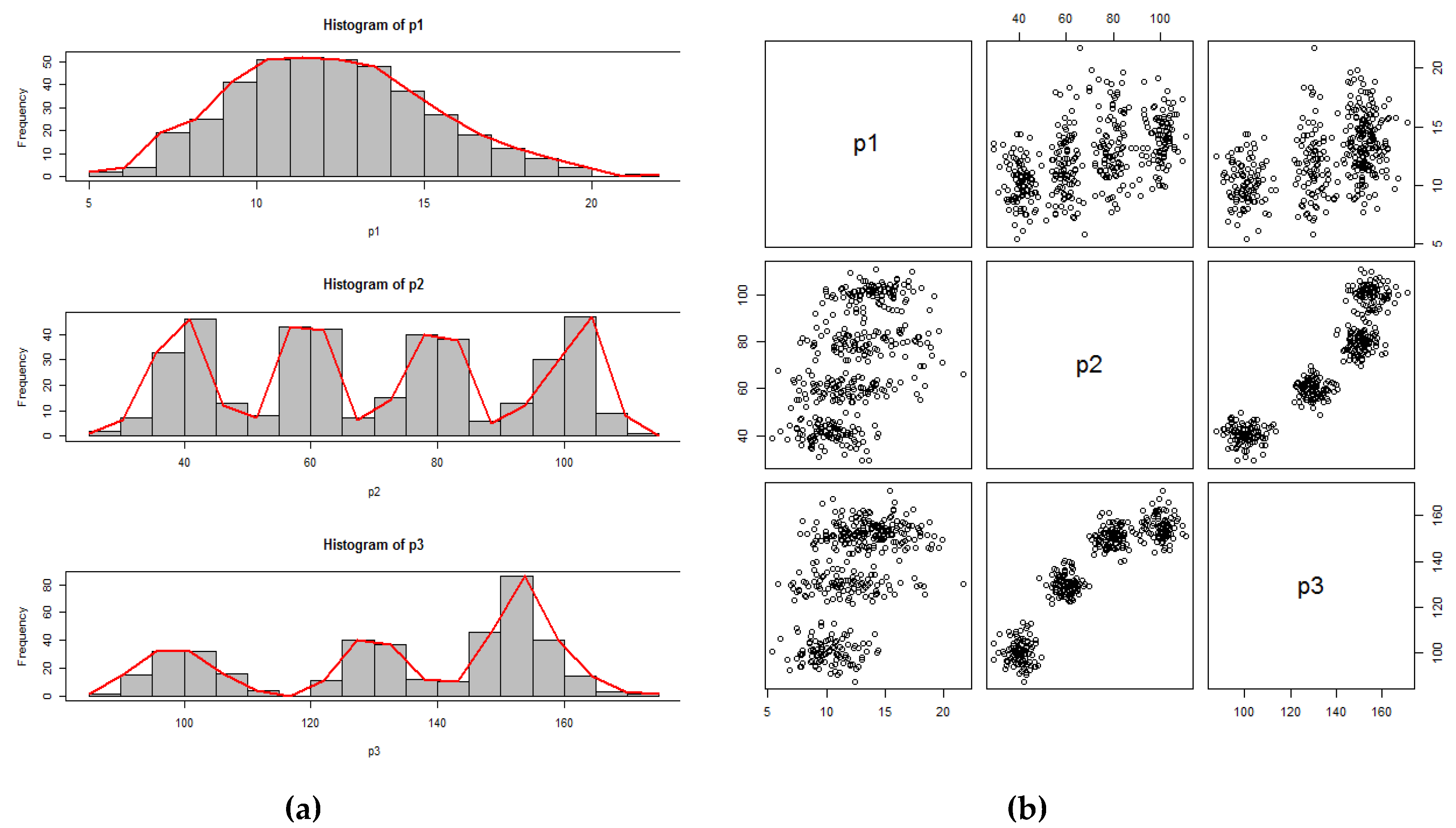
3.1. Experiment on a Synthetic Dataset
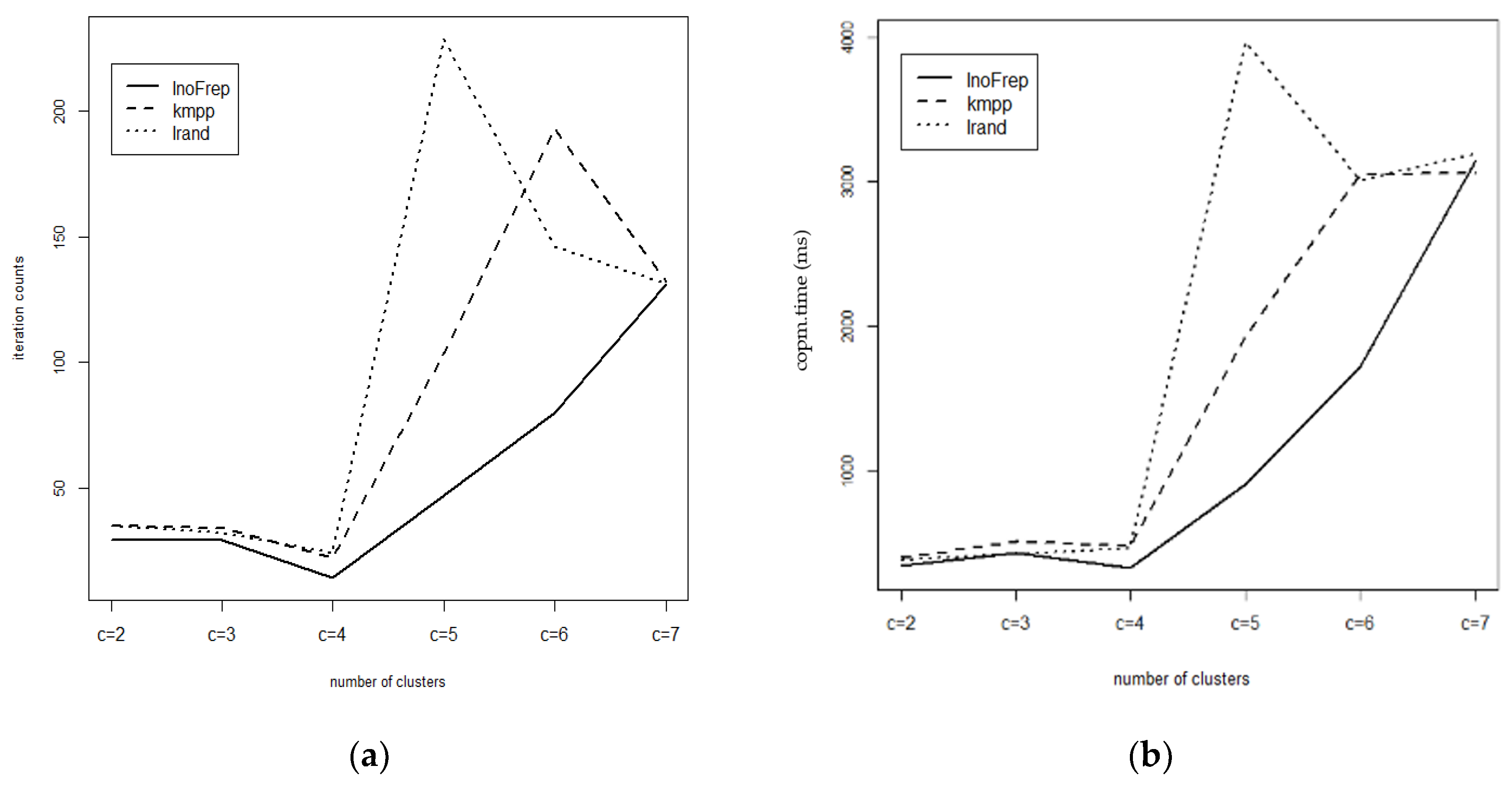
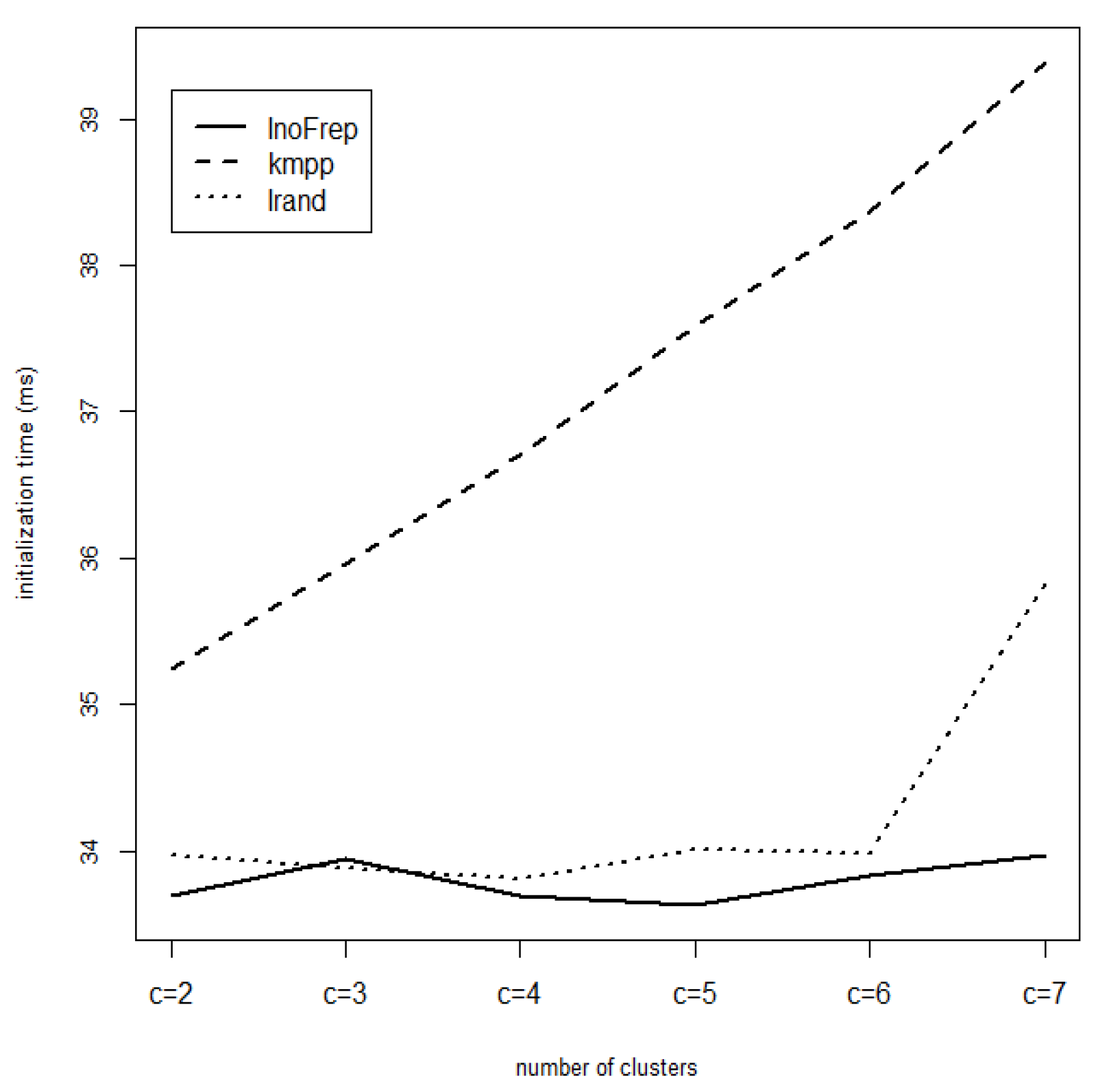
3.2. Experimental Results on Real Datasets
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Borgelt, C. Prototype-based Classification and Clustering; Habilitationsschrift zur Erlangung der Venia Legendi für Informatik, vorgelegt der Fakultaet für Informatik der Otto-von-Guericke-Universitaet Magdeburg: Magdeburg, Germany, 2005. [Google Scholar]
- Äyrämö, S.; Kärkkäinen, L. Introduction to Partitioning-based Clustering Methods with a Robust Example. In Reports of the Department of Mathematical Information Technology (University of Jyväskylä) Series C: Software and Computational Engineering C1; University of Jyväskylä: Jyväskylän, Finland, 2006; pp. 1–36. [Google Scholar]
- Kim, D.-W.; Lee, K.H.; Lee, D. A novel initialization scheme for the fuzzy c-means algorithm for color clustering. Pattern Recognit. Lett. 2004, 25, 227–237. [Google Scholar] [CrossRef]
- Moertini, V.S. Introduction to five clustering algorithms. Integral 2002, 7, 87–96. [Google Scholar]
- Fahad, A.; Alshatri, N.; Tari, Z.; Alamri, A.; Khalil, I.; Zomaya, A.; Foufou, S.; Bouras, A. A survey of clustering algorithms for big data: Taxonomy and empirical analysis. IEEE Trans. Emerg. Top. Comp. 2014, 2, 267–279. [Google Scholar] [CrossRef]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Plenum Press: New York, NY, USA, 1981. [Google Scholar]
- Bezdek, J.C. Cluster validity with fuzzy sets. J. Cybern. 1973, 3, 58–73. [Google Scholar] [CrossRef]
- Dave, R.N. Validating fuzzy partitions obtained through c-shells clustering. Pattern Recognit. Lett. 1996, 17, 613–623. [Google Scholar] [CrossRef]
- Xie, X.L.; Beni, G. A validity measure for fuzzy clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 841–847. [Google Scholar] [CrossRef]
- Kwon, S.H. Cluster validity index for fuzzy clustering. Electron. Lett. 1998, 3, 2176–2178. [Google Scholar] [CrossRef]
- Pakhira, M.K.; Bandyopadhyay, S.; Maulik, U. Validity index for crisp and fuzzy clusters. Pattern Recognit. 2004, 37, 487–501. [Google Scholar] [CrossRef]
- Zou, K.; Wang, Z.; Hu, M. A new initialization method for fuzzy c-means algorithm. Fuzzy Optim. Decis. Mak. 2008, 7, 409–416. [Google Scholar] [CrossRef]
- Xianfeng, Y.; Pengfei, L. Tailoring fuzzy c-means clustering algorithm for big data using random sampling and particle swarm optimization. Int. J. Database Theory Appl. 2015, 8, 191–202. [Google Scholar] [CrossRef]
- Yager, R.R.; Filev, D.P. Generation of fuzzy rules by mountain clustering. J. Intell. Fuzzy Syst. 1994, 2, 209–219. [Google Scholar] [CrossRef]
- Chiu, S. Fuzzy model identification based on cluster estimation. J. Intell. Fuzzy Syst. 1994, 2, 267–278. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. K-means++: The Advantages of Careful Seeding. In Proceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; Gabow, H., Ed.; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2007; pp. 1027–1035. [Google Scholar]
- Stetco, A.; Zeng, X.-J.; Keane, J. Fuzzy c-means++: Fuzzy c-means with effective seeding initialization. Expert Syst. Appl. 2015, 42, 7541–7548. [Google Scholar] [CrossRef]
- Aitnouri, E.M.; Wang, S.; Ziou, D.; Vaillancourt, J.; Gagnon, L. An Algorithm for Determination of the Number of Modes for Pdf Estimation of Multi-modal Histograms. In Proceedings of the Vision Interface 99, Trois-Rivieres, QC, Canada, 18–21 May 1999; pp. 368–374. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013; Available online: https://www.R-project.org (accessed on 28 December 2019).
- UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml (accessed on 28 December 2019).
- Pavan, K.K.; Rao, A.P.; Rao, A.V.D.; Sridhar, G.R. Robust seed selection algorithm for k-means type algorithms. Int. J. Comput. Sci. Inf. Technol. 2011, 3, 147–163. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Index Formula |
|---|---|
| Partition Entropy [7] | |
| Modified Partition Coefficient [8] | |
| Xie-Beni Index [9] | |
| Kwon Index [10] | |
| PBMF Index [11] |
| Features | p1 | p2 | p3 |
|---|---|---|---|
| Number of instances | 400 | 400 | 400 |
| Mean | 12.29 | 70.02 | 133.94 |
| Standard deviation | 2.86 | 22.69 | 22.02 |
| Frequencies of classes | 2 4 19 25 41 51 52 51 48 37 27 18 12 8 4 0 1 | 2 7 33 46 13 8 43 42 7 15 40 38 6 13 30 47 9 1 | 1 15 32 32 16 4 0 11 40 37 12 10 46 86 40 14 3 1 |
| Mid values of classes | 5.5 6.5 7.5 8.5 9.5 10.5 11.5 12.5 13.5 14.5 15.5 16.5 17.5 18.5 19.5 20.5 21.5 | 27.5 32.5 37.5 42.5 47.5 52.5 57.5 62.5 67.5 72.5 77.5 82.5 87.5 92.5 97.5 102.5 107.5 112.5 | 87.5 92.5 97.5 102.5 107.5 112.5 117.5 122.5 127.5 132.5 137.5 142.5 147.5 152.5 157.5 162.5 167.5 172.5 |
| Number of peaks | 1 | 4 | 3 |
| Values of peaks | 11.5 | 42.5 57.5 77.5 102.5 | 97.5 127.5 152.5 |
| Frequencies of peaks | 52 | 46 43 40 47 | 32 40 86 |
| c = 2 | c = 3 | c = 4 | |||||||
| Kmpp | InoFrep | Irand | Kmpp | InoFrep | Irand | Kmpp | InoFrep | Irand | |
| imin | 34 | 29 | 34 | 29 | 29 | 29 | 17 | 14 | 14 |
| iavg | 35 | 29 | 35 | 34 | 29 | 32 | 22 | 14 | 24 |
| imax | 35 | 29 | 36 | 34 | 29 | 32 | 23 | 14 | 25 |
| isum | 351 | 290 | 352 | 341 | 290 | 319 | 273 | 140 | 245 |
| ctime | 402.05 | 345.06 | 383.43 | 508.24 | 435.01 | 426.15 | 477.79 | 325.88 | 462.42 |
| itime | 35.24 | 33.70 | 33.97 | 35.96 | 33.95 | 33.88 | 36.70 | 33.70 | 33.81 |
| c = 5 | c = 6 | c = 7 | |||||||
| Kmpp | InoFrep | Irand | Kmpp | InoFrep | Irand | Kmpp | InoFrep | Irand | |
| imin | 48 | 47 | 43 | 57 | 80 | 83 | 77 | 80 | 78 |
| iavg | 104 | 47 | 229 | 142 | 80 | 146 | 120 | 131 | 131 |
| imax | 132 | 47 | 250 | 193 | 80 | 150 | 132 | 147 | 136 |
| isum | 1038 | 470 | 2292 | 1423 | 800 | 1457 | 1205 | 1311 | 1660 |
| ctime | 1934.24 | 909.68 | 3970.68 | 3051.58 | 1722.15 | 3007.69 | 3060.21 | 3147.02 | 3194.27 |
| itime | 37.59 | 33.63 | 34.01 | 38.36 | 33.84 | 33.98 | 39.39 | 33.97 | 35.82 |
| IXB | IKwon | IPBMF | IMPC | IPE | |
|---|---|---|---|---|---|
| c = 2 | 0.06398359 | 25.84344 | 1.112161 × 104 | 0.6855225 | 0.1996096 |
| c = 3 | 0.05879530 | 24.19019 | 4.466028 × 105 | 0.7490964 | 0.1941429 |
| c = 4 | 0.07750218 | 33.07070 | 7.096132 × 101 | 0.7850980 | 0.1768860 |
| c = 5 | 0.65254444 | 279.28554 | 1.284663 × 106 | 0.6786742 | 0.2800888 |
| c = 6 | 0.70858359 | 306.77753 | 8.637914 × 106 | 0.6237016 | 0.3345075 |
| c = 7 | 0.79080017 | 345.13123 | 7.018537 × 106 | 0.5474565 | 0.4175081 |
| Dataset | n | p | c | ec | sp |
|---|---|---|---|---|---|
| Iris | 150 | 4 | 2–3 | 2 | 2 |
| Forest | 198 | 27 | 4 | 4–5 | 5 |
| Wine | 178 | 13 | 3 | 2 | 8 |
| Glass | 214 | 9 | 6 | 2–3 | 7 |
| Vaweform | 5000 | 21 | 3 | 2–3 | 8 |
| Wilt train | 4889 | 6 | 2 | 2 | 1 |
| c = 2 | c = 3 | c = 4 | c = 5 | c = 6 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | iters | ctime | iters | ctime | iters | ctime | iters | ctime | iters | ctime |
| Iris | 16 | 117.81 | 37 | 223.11 | 69 | 442.58 | 55 | 453.90 | 157 | 1368.10 |
| Forest | 46. | 253.65 | 57 | 397.24 | 32 | 317.61 | 105 | 1073.27 | 146 | 1729.45 |
| Wine | 24 | 146.06 | 70 | 407.61 | 57 | 417.63 | 93 | 784.84 | 256 | 2428.10 |
| Glass | 28 | 174.91 | 43 | 315.07 | 55 | 465.42 | 175 | 1661.62 | 94 | 1099.79 |
| Vaweform | 32 | 3164.89 | 50 | 7146.28 | 210 | 38,958.49 | 433 | 107,249.2 | 233 | 67,886.63 |
| Wilt train | 39 | 3133.99 | 94 | 10,993.57 | 116 | 17,744.25 | 316 | 60,230.48 | 258 | 59,319.35 |
| c = 2 | c = 3 | c = 4 | c = 5 | c = 6 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | iters | ctime | iters | ctime | iters | ctime | iters | ctime | iters | ctime |
| Iris | 17 | 122.07 | 40 | 238.38 | 68 | 455.57 | 78 | 614.10 | 98 | 938.85 |
| Forest | 43 | 250.92 | 63 | 460.88 | 33 | 343.51 | 98 | 1072.61 | 123 | 1589.85 |
| Wine | 26 | 157.96 | 69 | 414.39 | 57 | 442.89 | 199 | 1684.91 | 107 | 1128.61 |
| Glass | 27 | 175.51 | 91 | 609.56 | 59 | 518.89 | 75 | 792.68 | 95 | 1156.62 |
| Vaweform | 33 | 3466.88 | 57 | 8480.23 | 231 | 44,947.23 | 443 | 108,892.3 | 234 | 69,624.66 |
| Wilt train | 43 | 3584.90 | 105 | 12,644.0 | 179 | 28,135.95 | 303 | 59,471.17 | 197 | 46,778.42 |
| c = 2 | c = 3 | c = 4 | c = 5 | c = 6 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | iters | ctime | iters | ctime | iters | ctime | iters | ctime | iters | ctime |
| Iris | 16 | 112.61 | 42 | 245.35 | 66 | 434.33 | 69 | 547.09 | 107 | 948.51 |
| Forest | 44 | 245.36 | 63 | 440.27 | 34 | 332.64 | 104 | 1063.77 | 113 | 1378.91 |
| Wine | 26 | 150.71 | 65 | 381.95 | 58 | 428.45 | 172 | 1384.01 | 96 | 963.75 |
| Glass | 28 | 179.42 | 183 | 1104.22 | 58 | 502.50 | 105 | 1031.04 | 95 | 1116.48 |
| Vawefom | 32 | 3197.51 | 52 | 7467.45 | 214 | 40,291.86 | 447 | 103,733.3 | 234 | 65,361.30 |
| Wilt train | 40 | 3210.52 | 100 | 11,734.20 | 167 | 25,997.59 | 258 | 48,890.90 | 294 | 67,168.03 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cebeci, Z.; Cebeci, C. A Fast Algorithm to Initialize Cluster Centroids in Fuzzy Clustering Applications. Information 2020, 11, 446. https://doi.org/10.3390/info11090446
Cebeci Z, Cebeci C. A Fast Algorithm to Initialize Cluster Centroids in Fuzzy Clustering Applications. Information. 2020; 11(9):446. https://doi.org/10.3390/info11090446
Chicago/Turabian StyleCebeci, Zeynel, and Cagatay Cebeci. 2020. "A Fast Algorithm to Initialize Cluster Centroids in Fuzzy Clustering Applications" Information 11, no. 9: 446. https://doi.org/10.3390/info11090446
APA StyleCebeci, Z., & Cebeci, C. (2020). A Fast Algorithm to Initialize Cluster Centroids in Fuzzy Clustering Applications. Information, 11(9), 446. https://doi.org/10.3390/info11090446