Integrated Question-Answering System for Natural Disaster Domains Based on Social Media Messages Posted at the Time of Disaster


Abstract
:1. Introduction
2. Related Work
3. Methodology
3.1. Classification Algorithm
3.2. KNN Algorithm
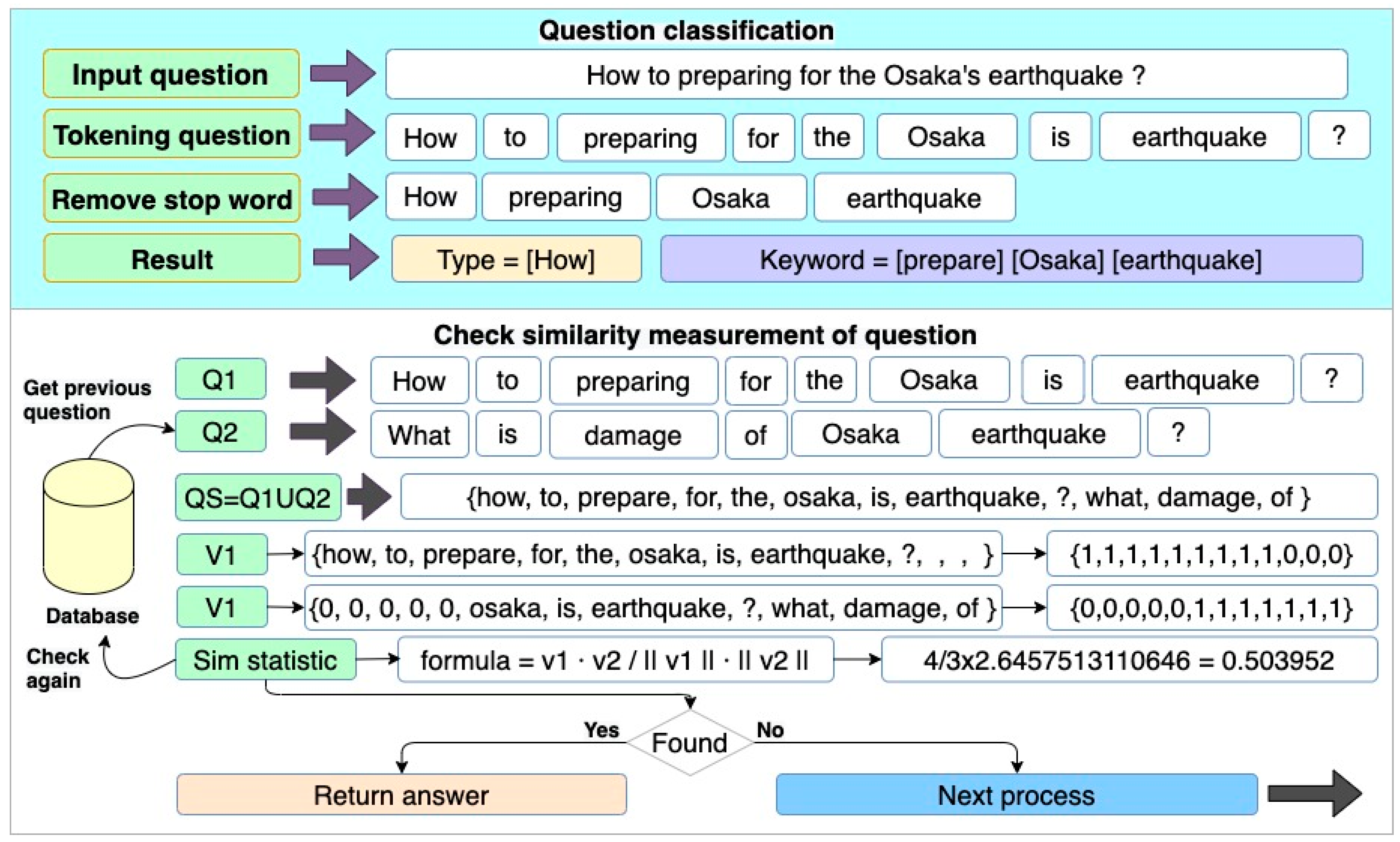
3.3. Statistic Similarity
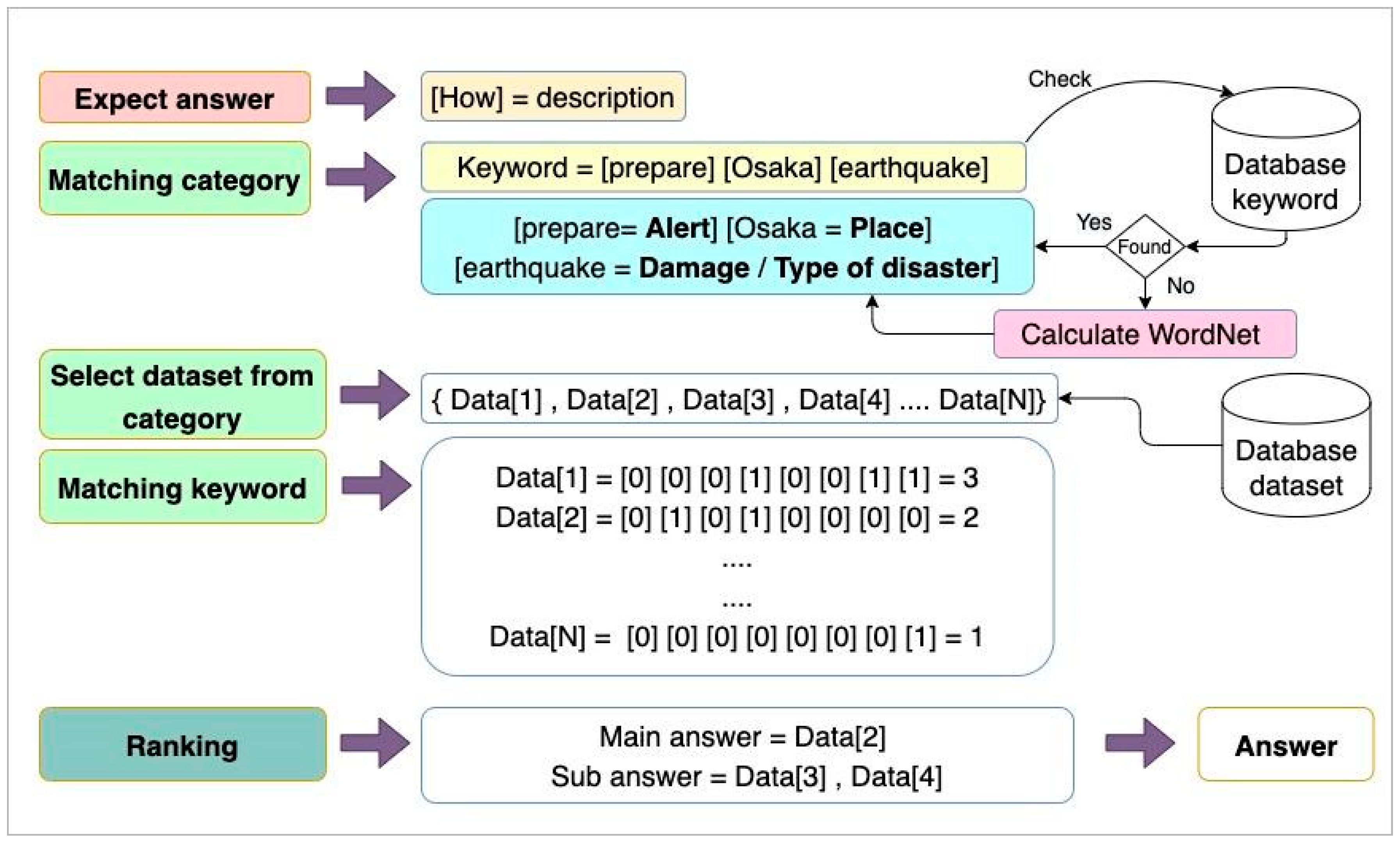
3.4. Word Similarity on WordNet
3.5. Confusion Matrix
- Accuracy: The predicted accuracy matches what actually happens. The accuracy formula is (TP + TN)/(TP + TN + FP + FN).
- Precision: Correct and true predictions are compared with true predictions, but what happens is not true. The precision formula is TP/(TP + FP).
- Recall: The true prediction accuracy compared to the number of occurrences where both the prediction and occurrence are true. The recall formula is TP/(TP + FN).
4. Framework Design
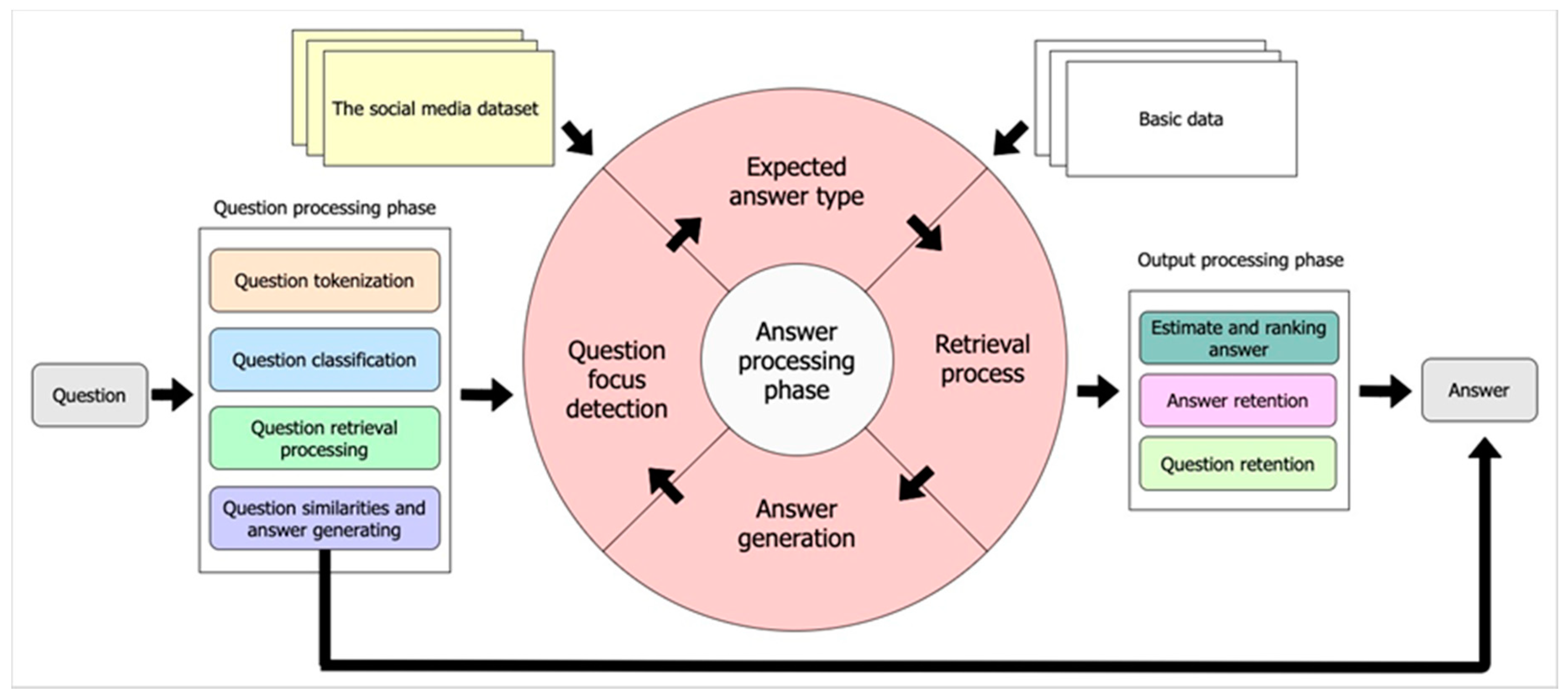
4.1. Framework of Our Proposed Integrated QA System
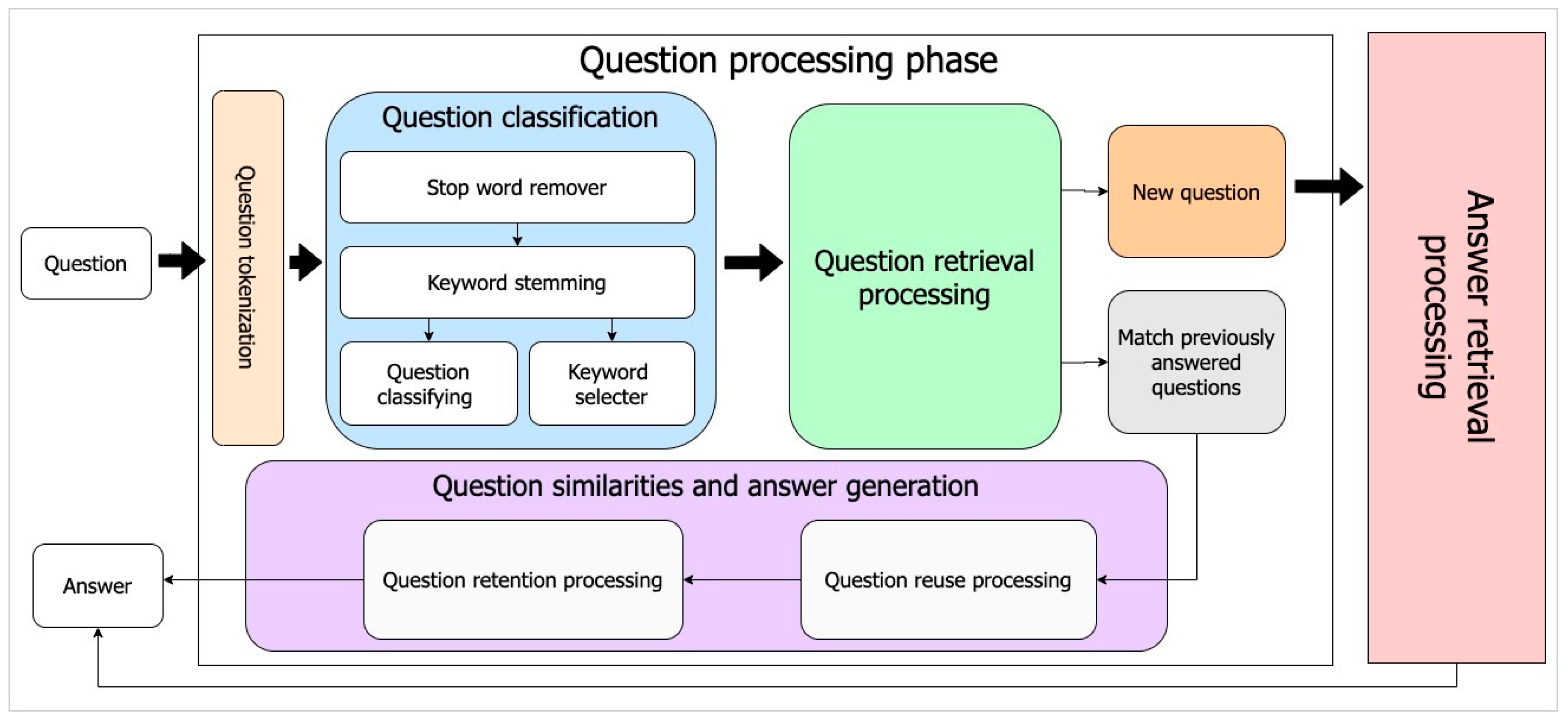
4.2. Question Processing Phase Framework
4.3. Framework Part of Answer Retrieval Processing and Answer Output
5. Experiments
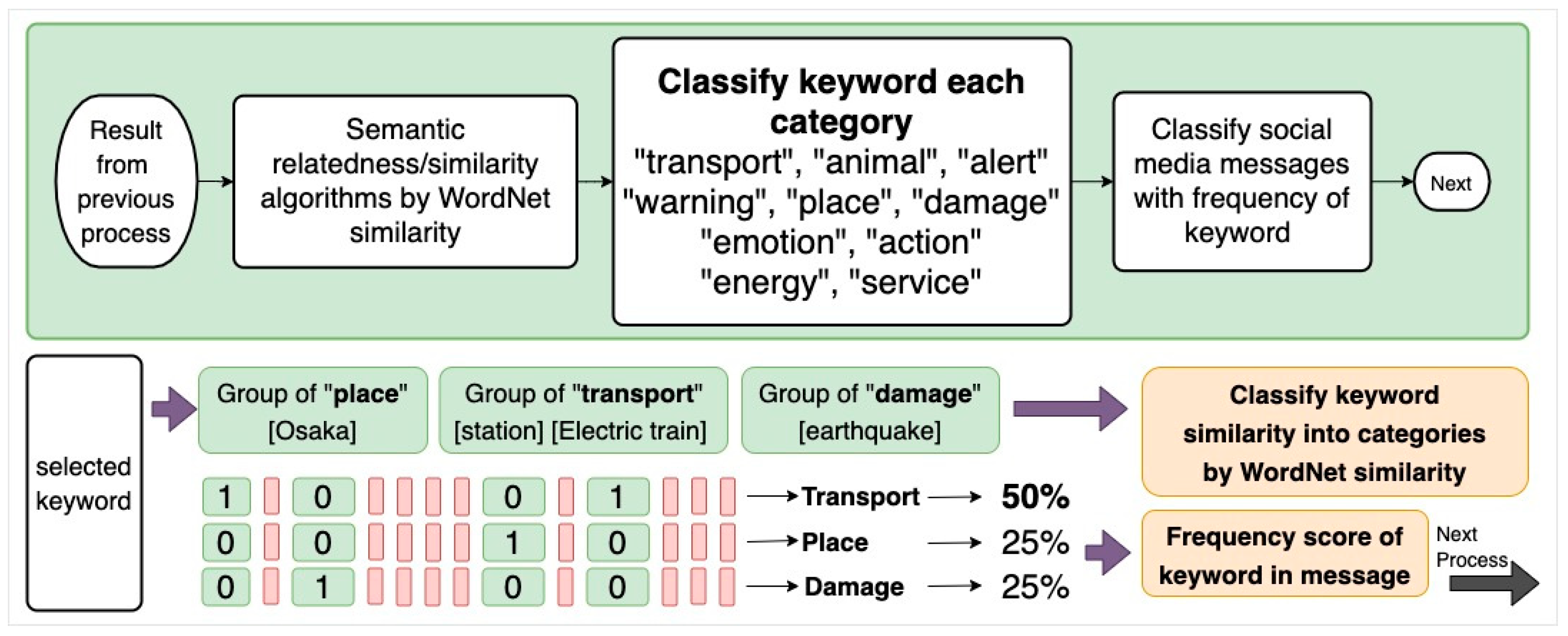
5.1. Data Classification of Social Media Messages
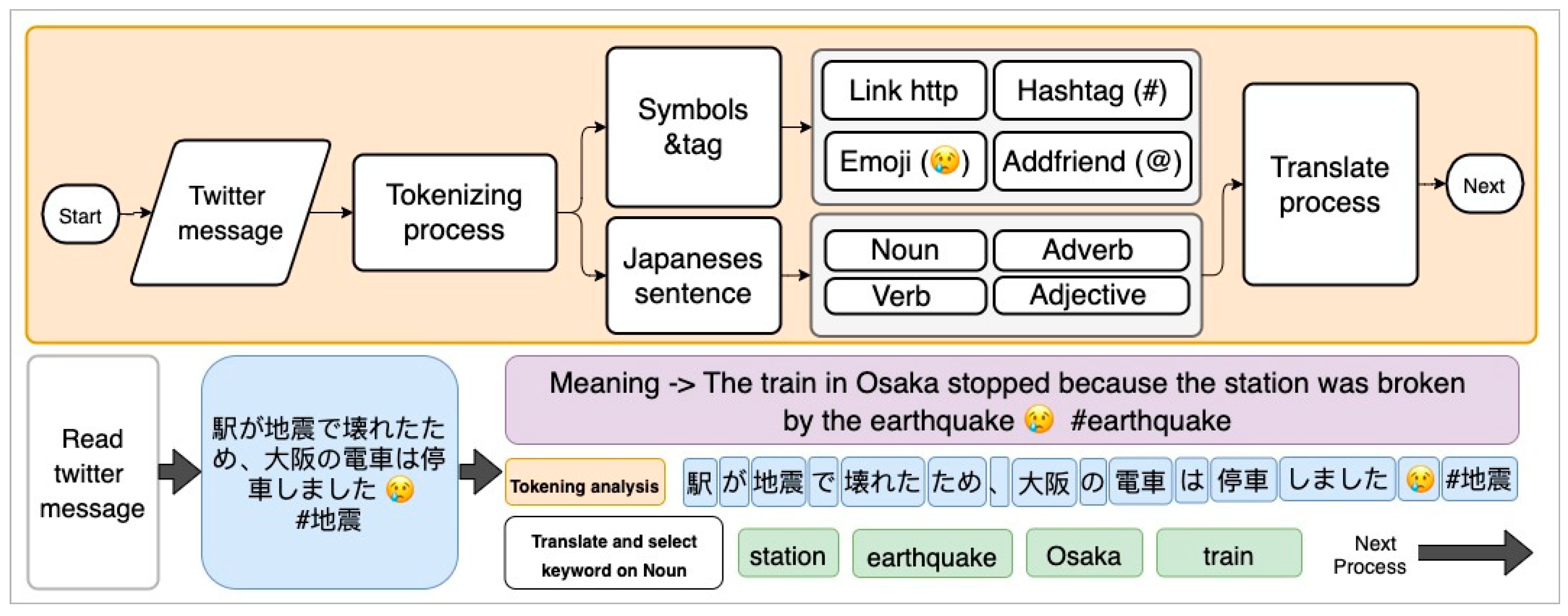
5.2. Question Processing
5.3. Answer Retrieval Processing and Answer Output
5.4. Retrieval Performance and Evaluation Results
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yamada, S.; Utsu, K.; Uchida, O. An Analysis of Tweets during the 2018 Osaka North Earthquake in Japan—A Brief Report. In Proceedings of the 5th International Conference on Information and Communication Technologies for Disaster Management (ICT-DM’2018), Sendai, Japan, 4–7 December 2018; IEEE: Piscataway Township, NJ, USA, 2019; ISBN 978-1-5386-6638-8. [Google Scholar] [CrossRef]
- Utsu, K.; Uchida, O. Analysis of Rescue Request and Damage Report Tweets Posted During 2019 Typhoon Hagibis. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2020. [Google Scholar] [CrossRef]
- Van den Hooff, B.; Huysman, M. Managing knowledge sharing: Emergent and engineering approaches. Inf. Manag. 2009, 46, 1–8. [Google Scholar] [CrossRef]
- Josef, D.; Francesco, C.; Jaroslav, R. Complex Network Analysis for Knowledge Management and Organizational Intelligence. J. Knowl. Econ. 2020, 11, 405–424. [Google Scholar] [CrossRef]
- Nishikawa, S.; Uchida, O.; Utsu, K. Analysis of Rescue Request Tweets in the 2018 Japan Floods. In Proceedings of the 2019 International Conference on Information Technology and Computer Communications (ITCC), Singapore, 16–18 August 2019; pp. 29–36, ISBN 978-1-4503-7228-2. [Google Scholar] [CrossRef]
- Hendriks, P. Why share knowledge? The influence of ICT on the motivation for knowledge sharing. Knowl. Process Manag. 1999, 6, 91–100. [Google Scholar] [CrossRef]
- Kemavuthanon, K.; Uchida, O. Social Media Messages during Disasters in Japan: An Empirical Study of 2018 Osaka North Earthquake in Japan. In Proceedings of the 2019 IEEE 2nd International Conference on Information and Computer Technologies (ICICT), Kahului, HI, USA, 14–17 March 2019; IEEE: Piscataway Township, NJ, USA, 2019; pp. 199–203. ISBN 978-1-7281-3323-2. [Google Scholar] [CrossRef]
- Kemavuthanon, K.; Uchida, O. Classification of Social Media Messages Posted at the Time of Disaster. In Proceedings of the IFIP Advances in Information and Communication Technology (ITDRR 2019), Kyiv, Ukraine 3–4 December 2019; Springer: Cham, Switzerland, 2020; pp. 212–226. ISBN 978-3-030-48939-7. [Google Scholar] [CrossRef]
- Dodiya, T.; Jain, S. Question classification for medical domain Question Answering system. In Proceedings of the 2016 IEEE International WIE Conference on Electrical and Computer Engineering (WIECON-ECE), une, India, 19–21 December 2016; IEEE: Piscataway Township, NJ, USA, 2017; pp. 204–207. ISBN 978-1-5090-3745-2. [Google Scholar] [CrossRef]
- Agarwal, A.; Sachdeva, N.; Yadav, R.K.; Udandarao, V.; Mittal, V.; Gupta, A.; Mathur, A. EDUQA: Educational Domain Question Answering System Using Conceptual Network Mapping. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway Township, NJ, USA, 2019; pp. 8137–8141. ISBN 978-1-4799-8131-1. [Google Scholar] [CrossRef] [Green Version]
- Shah, S.S.; Bavaskar, T.S.; Ukhale, S.S.; Patil, R.A.; Kalyankar, A.S. Answer Ranking in Community Question Answer (QA) System and Questions Recommendation. In Proceedings of the 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 16–18 August 2018; IEEE: Piscataway Township, NJ, USA, 2019; ISBN 978-1-5386-5257-2. [Google Scholar] [CrossRef]
- Cai, L.; Wei, M.; Zhou, S.; Yan, X. Intelligent Question Answering in Restricted Domains Using Deep Learning and Question Pair Matching. IEEE Access 2020, 8, 32922–33293. [Google Scholar] [CrossRef]
- Trakultaweekoon, K.; Thaiprayoon, S.; Palingoon, P.; Rugchatjaroen, A. The First Wikipedia Questions and Factoid Answers Corpus in the Thai Language. In Proceedings of the 2019 14th International Joint Symposium on Artificial Intelligence and Natural Language Processing (iSAI-NLP), Chiang Mai, Thailand, 30 October–1 November 2019; IEEE: Piscataway Township, NJ, USA, 2020; ISBN 978-1-7281-5631-6. [Google Scholar] [CrossRef]
- Uchida, O.; Kosugi, M.; Endo, G.; Funayama, T.; Utsu, K.; Tajima, S.; Tomita, M.; Kajita, Y.; Yamamoto, Y. A Real-Time Information Sharing System to Support Self-, Mutual-, and Public-Help in the Aftermath of a Disaster Utilizing Twitter. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2016, E99–A, 1551–1554. [Google Scholar] [CrossRef]
- Layek, A.K.; Pal, A.; Saha, R.; Mandal, S. DETSApp: An App for Disaster Event Tweets Summarization using Images Posted on Twitter. In Proceedings of the 2018 Fifth International Conference on Emerging Applications of Information Technology (EAIT), Kolkata, India, 12–13 January 2018; IEEE: Piscataway Township, NJ, USA, 2018; ISBN 978-1-5386-3719-7. [Google Scholar] [CrossRef]
- Mizuno, J.; Tanaka, M.; Ohtake, K.; Jong-Hoon, O.; Kloetzer, J.; Chikara, H.; Torisawa, K. WISDOM X, DISAANA and D-SUMM: Large-scale NLP Systems for Analyzing Textual Big Data. In Proceedings of the 26th International Conference on Computational Linguistics: System Demonstrations, Osaka, Japan, 11–16 December 2016; pp. 263–267. [Google Scholar]
- Nunavath, V.; Goodwin, M. The Use of Artificial Intelligence in Disaster Management-A Systematic Literature Review. In Proceedings of the 2019 International Conference on Information and Communication Technologies for Disaster Management (ICT-DM), Paris, France, 18–20 December 2019; IEEE: Piscataway Township, NJ, USA, 2020; pp. 1–8. ISBN 978-1-7281-4920-2. [Google Scholar] [CrossRef]
- Li, H.; Wang, N.; Hu, G.; Yang, W. PGM-WV: A context-aware hybrid model for heuristic and semantic question classification in question-answering system. In Proceedings of the 2017 International Conference on Progress in Informatics and Computing (PIC), Nanjing, China, 15–17 December 2017; IEEE: Piscataway Township, NJ, USA, 2018; pp. 240–244. ISBN 978-1-5386-1978-0. [Google Scholar] [CrossRef]
- Singh, K.; Nagpal, R.; Sehgal, R. Exploratory Data Analysis and Machine Learning on Titanic Disaster Dataset. In Proceedings of the 2020 10th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 29–31 January 2020; IEEE: Piscataway Township, NJ, USA, 2020; pp. 320–326. ISBN 978-1-7281-2791-0. [Google Scholar] [CrossRef]
- Gosavi, J.; Jagdale, B.N. Answer Selection in Community Question Answering Portals. In Proceedings of the 2018 IEEE Punecon, Pune, India, 30 November–2 December 2018; IEEE: Piscataway Township, NJ, USA, 2019; ISBN 978-1-5386-7278-5. [Google Scholar] [CrossRef]
- Song, W.; Feng, M.; Gu, N.; Wenyin, L. Question Similarity Calculation for FAQ Answering. In Proceedings of the Semantics, Knowledge and Grid, Third International Conference on, Xian, Shan Xi, China, 29–31 October 2007; pp. 298–301, ISBN 0-7695-3007-9. [Google Scholar] [CrossRef]
- Li, H.; Tian, Y.; Ye, B.; Cai, Q. Comparison of Current Semantic Similarity Methods in WordNet. In Proceedings of the 2010 International Conference on Computer Application and System Modeling (ICCASM 2010), Taiyuan, China, 22–24 October 2010; IEEE: Piscataway Township, NJ, USA, 2010; pp. 408–411. ISBN 978-1-4244-7237-6. [Google Scholar] [CrossRef]
- Hasi, N.-U. The Automatic Construction Method of Mongolian Lexical Semantic Network Based on WordNet. In Proceedings of the 2012 Fifth International Conference on Intelligent Networks and Intelligent Systems (ICINIS), Tianjin, China, 1–3 November 2012; IEEE: Piscataway Township, NJ, USA, 2012; pp. 220–223. ISBN 978-1-4673-3083-1. [Google Scholar] [CrossRef]
- Pedersen, T.; Patwardhan, S.; Michelizzi, J. WordNet:Similarity-Measuring the Relatedness of Concepts. In Proceedings of the Nineteenth National Conference on Artificial Intelligence, San Jose, CA, USA, 25–29 July 2004; AAAI Press: San Francisco, CA, USA, 2004; pp. 1024–1025. ISBN 978-0-262-51183-4. [Google Scholar]
- Kale, S.; Padmadas, V. Sentiment Analysis of Tweets Using Semantic Analysis. In Proceedings of the 2017 International Conference on Computing, Communication, Control and Automation (ICCUBEA), Pune, India, 17–18 August 2017; IEEE: Piscataway Township, NJ, USA, 2018; ISBN 978-1-5386-4008-1. [Google Scholar] [CrossRef]
- Vekariya, D.V.; Limbasiya, N.R. A Novel Approach for Semantic Similarity Measurement for High Quality Answer Selection in Question Answering using Deep Learning Methods. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; IEEE: Piscataway Township, NJ, USA, 2020; pp. 518–522. ISBN 978-1-7281-5197-7. [Google Scholar] [CrossRef]
- Janssens, O.; Slembrouck, M.; Verstockt, S.; Hoecke, S.V.; Walle, R.V. Real-time Emotion Classification of Tweets. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2013), Niagara Falls, ON, Canada, 25–28 August 2013; IEEE: Piscataway Township, NJ, USA, 2014; pp. 1430–1431. ISBN 978-1-4503-2240-9. [Google Scholar] [CrossRef]
- Riyadh, A.Z.; Alvi, N.; Talukder, K.H. Exploring Human Emotion via Twitter. In Proceedings of the 2017 20th International Conference of Computer and Information Technology (ICCIT), Dhaka, Banglades, 22–24 December 2017; IEEE: Piscataway Township, NJ, USA, 2017; pp. 22–24. ISBN 978-1-5386-1150-0. [Google Scholar] [CrossRef]
- Kosugi, M.; Utsu, K.; Yamamoto, Y.; Uchida, O. A Twitter-Based Disaster Information Sharing System. In Proceedings of the 2019 IEEE 4th International Conference on Computer and Communication Systems (ICCCS), Singapore, 23–25 February 2019; IEEE: Piscataway Township, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Okazaki, R.; Hirotomo, M.; Mohri, M.; Shiraishi, Y. Dual-Purpose Information Sharing System for Direct User Support in Both Ordinary and Emergency Times. IPSJ J. 2013, 55, 1778–1786. (In Japanese) [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | Precision | Recall | |
|---|---|---|---|
| Confusion Matrix Score | 0.883 | 0.98 | 0.75 |
| Accuracy | Precision | Recall | |
|---|---|---|---|
| Confusion Matrix Score | 0.776 | 0.82 | 0.863 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kemavuthanon, K.; Uchida, O. Integrated Question-Answering System for Natural Disaster Domains Based on Social Media Messages Posted at the Time of Disaster. Information 2020, 11, 456. https://doi.org/10.3390/info11090456
Kemavuthanon K, Uchida O. Integrated Question-Answering System for Natural Disaster Domains Based on Social Media Messages Posted at the Time of Disaster. Information. 2020; 11(9):456. https://doi.org/10.3390/info11090456
Chicago/Turabian StyleKemavuthanon, Kemachart, and Osamu Uchida. 2020. "Integrated Question-Answering System for Natural Disaster Domains Based on Social Media Messages Posted at the Time of Disaster" Information 11, no. 9: 456. https://doi.org/10.3390/info11090456
APA StyleKemavuthanon, K., & Uchida, O. (2020). Integrated Question-Answering System for Natural Disaster Domains Based on Social Media Messages Posted at the Time of Disaster. Information, 11(9), 456. https://doi.org/10.3390/info11090456