AI-Based Semantic Multimedia Indexing and Retrieval for Social Media on Smartphones †



Abstract
:1. Introduction and Motivation
2. State of the Art and Related Work
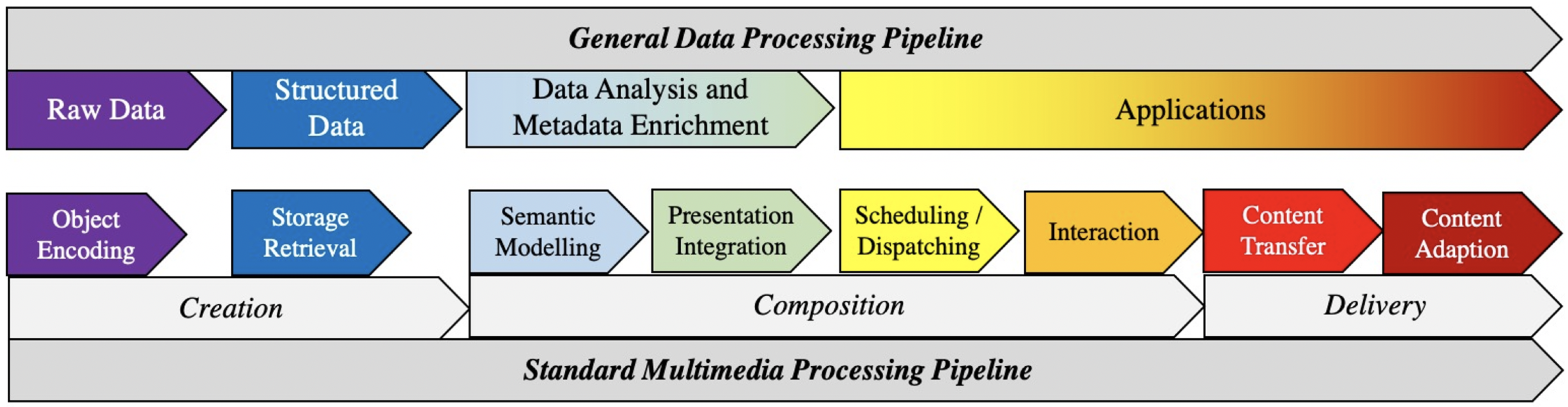
2.1. Multimedia Processing
2.2. Semantic Analysis and Representation
2.3. Multimedia Indexing, Querying and Retrieval
2.4. Graph Representation Processing
2.5. Mathematical Background
2.6. AI Pattern Matching
2.7. Social Media
2.8. Related Work
2.9. Discussion and Summary
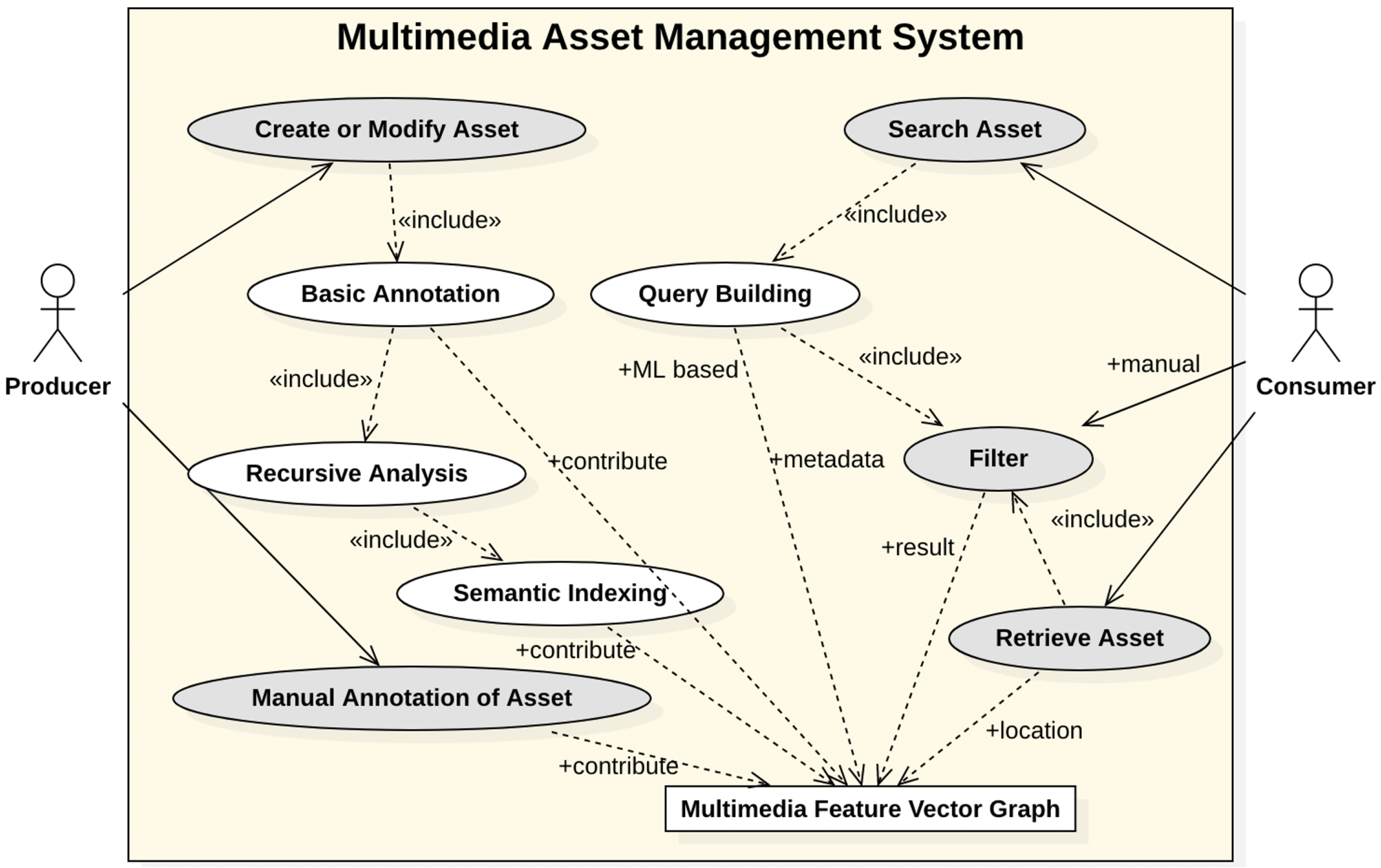
3. Conceptual Design
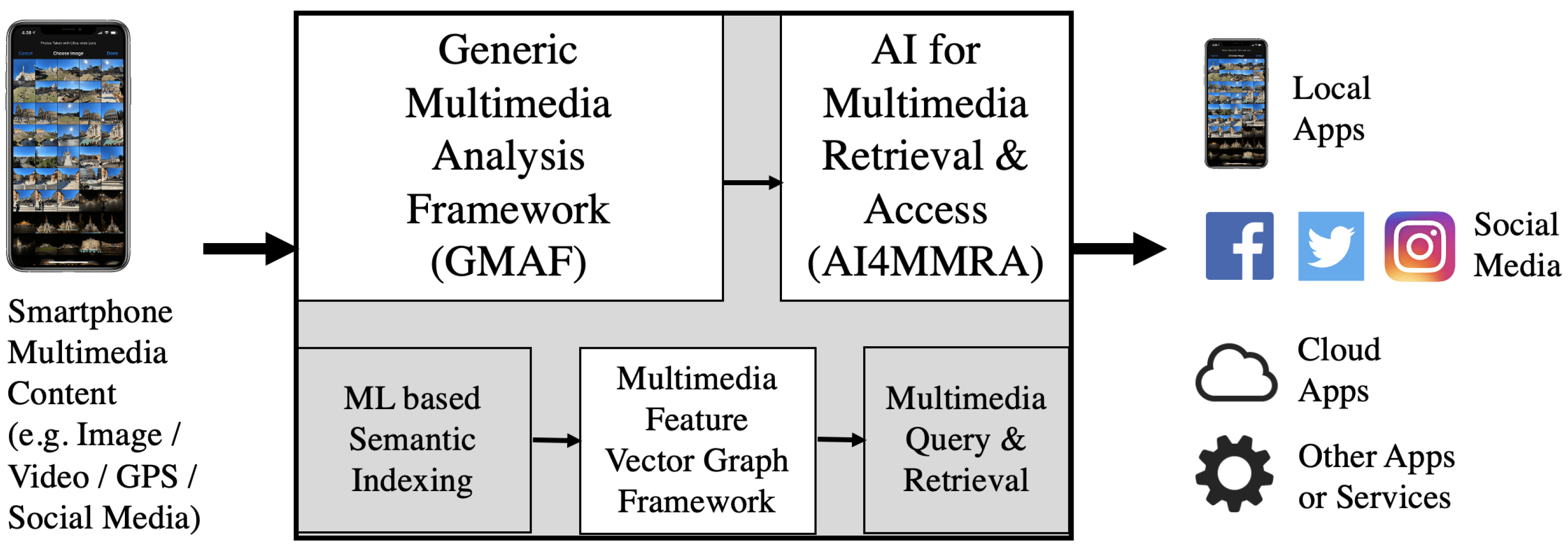
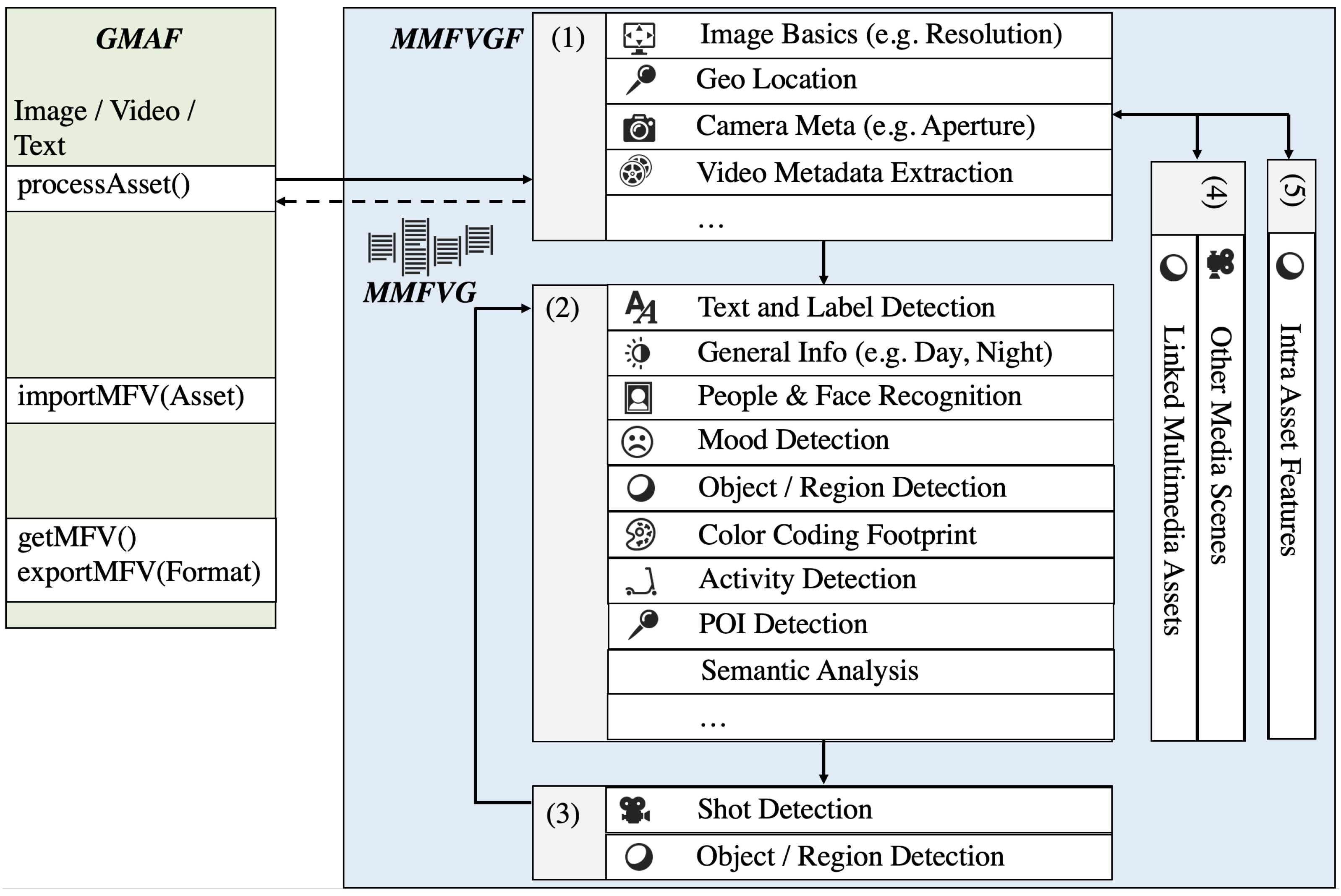
3.1. Framework Overview
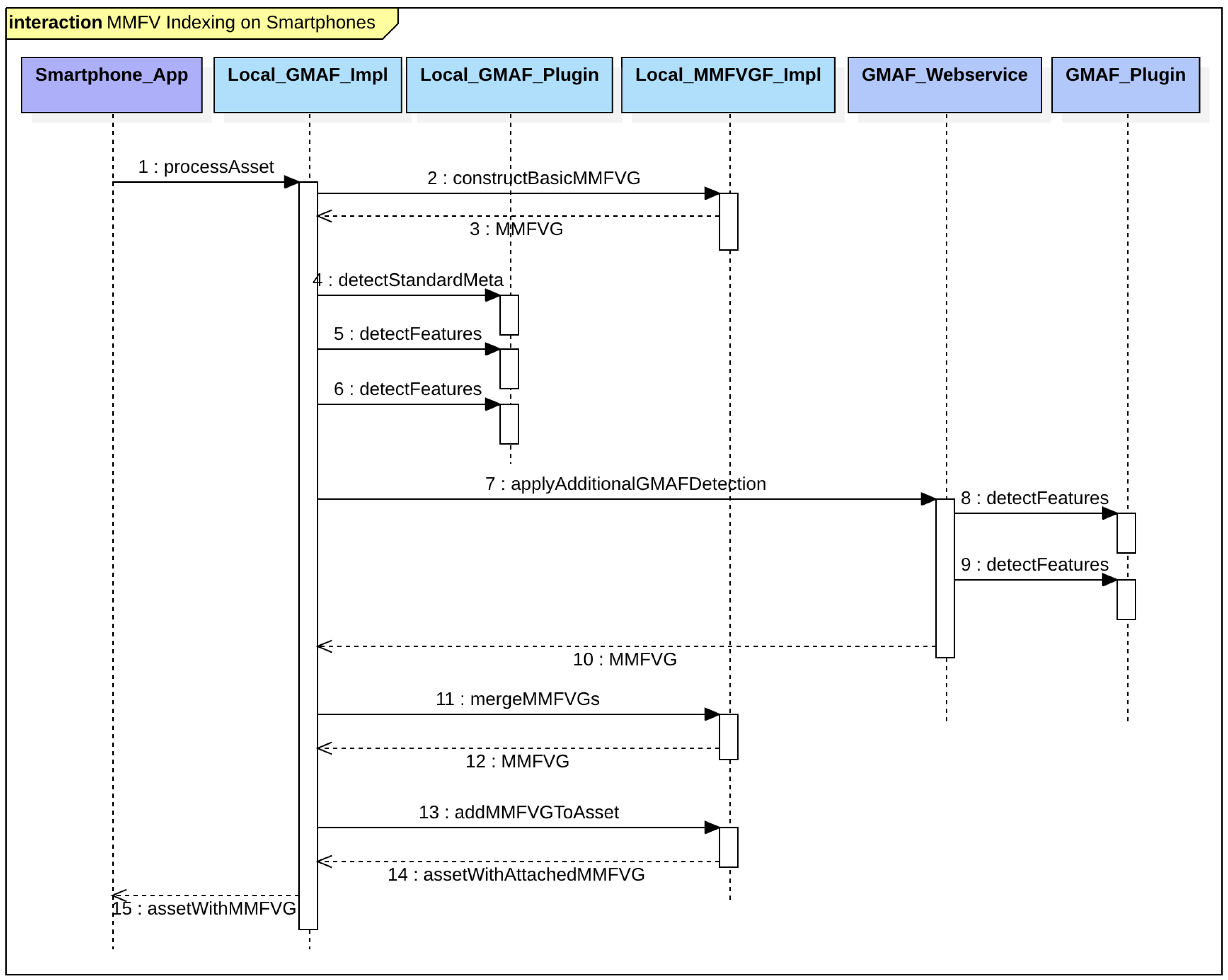
- Generic multimedia analysis framework (GMAF): a framework capable of combining and utilizing existing multimedia processing systems for image, video and text data (such as social media posts). It can be regarded as a chain of semantic metadata providers, which will produce all the data that is required to construct a semantic index. The GMAF represents the use cases Basic Annotation, Recursive Analysis and Semantic Indexing.
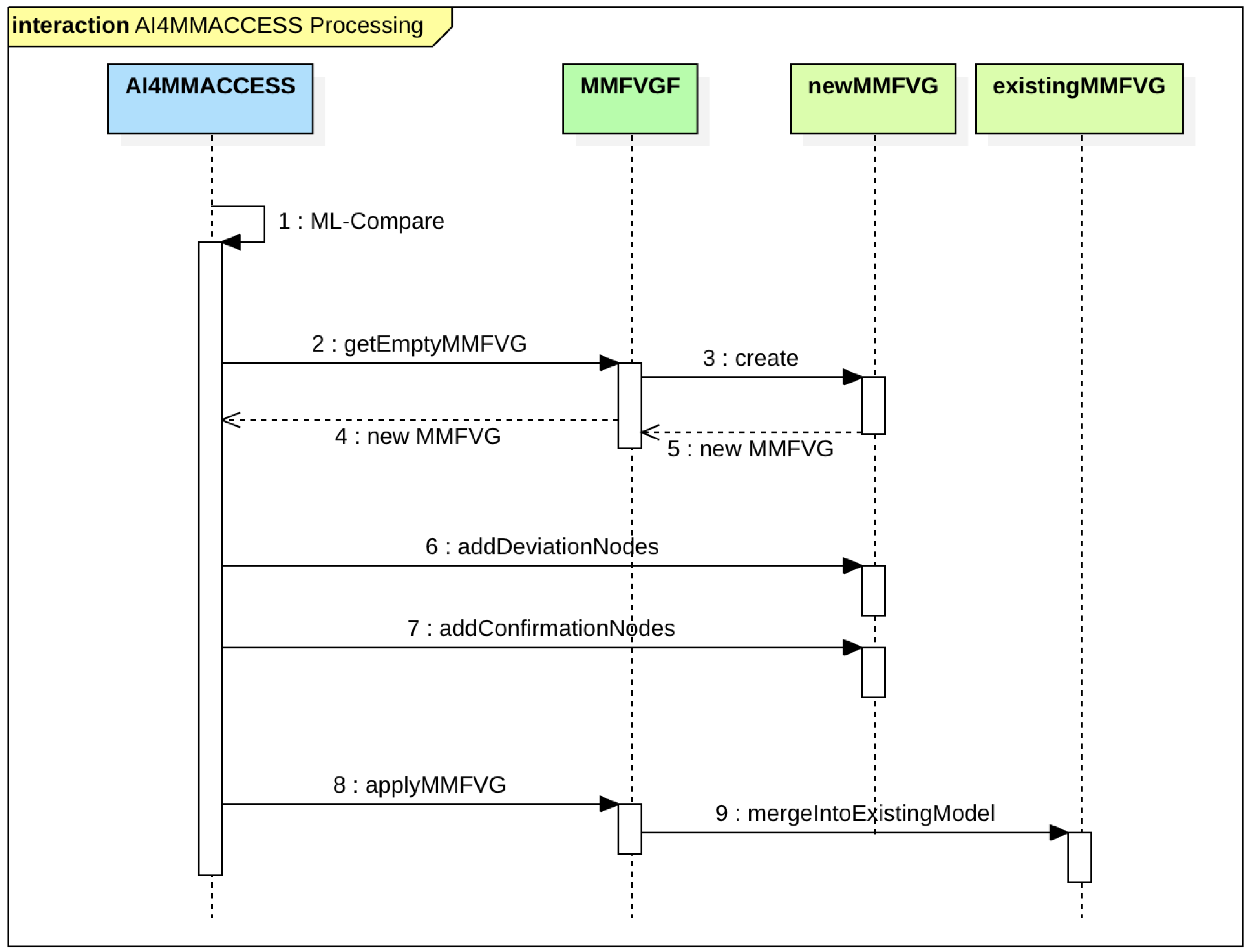
- Multimedia feature vector graph framework (MMFVGF): a framework that fuses all the semantic metadata into a large semantic feature vector graph and assigns it to each media asset. Weights, nodes and references are structured in a way such that the relevance of features within a multimedia asset can be determined accurately.
- AI for multimedia retrieval and access (AI4MMRA): an ML-component to process and permanently adjust the feature vector graphs of each image or video in order to refine the relevance data. AI4MMRA provides a permanent reprocessing in terms of the use case Semantic Indexing in addition to a Query Builder component.
3.2. Initial Query Types
- Q1:
- “show me the picture from Florida, where Jane wore flipflops”—Some of the algorithms will locate pictures of Jane, and possibly also pictures where a person is wearing flipflops, but most of the algorithms will fail on their intersection. One would also retrieve pictures of Jane, where another person next to her is wearing flipflops.
- Q2:
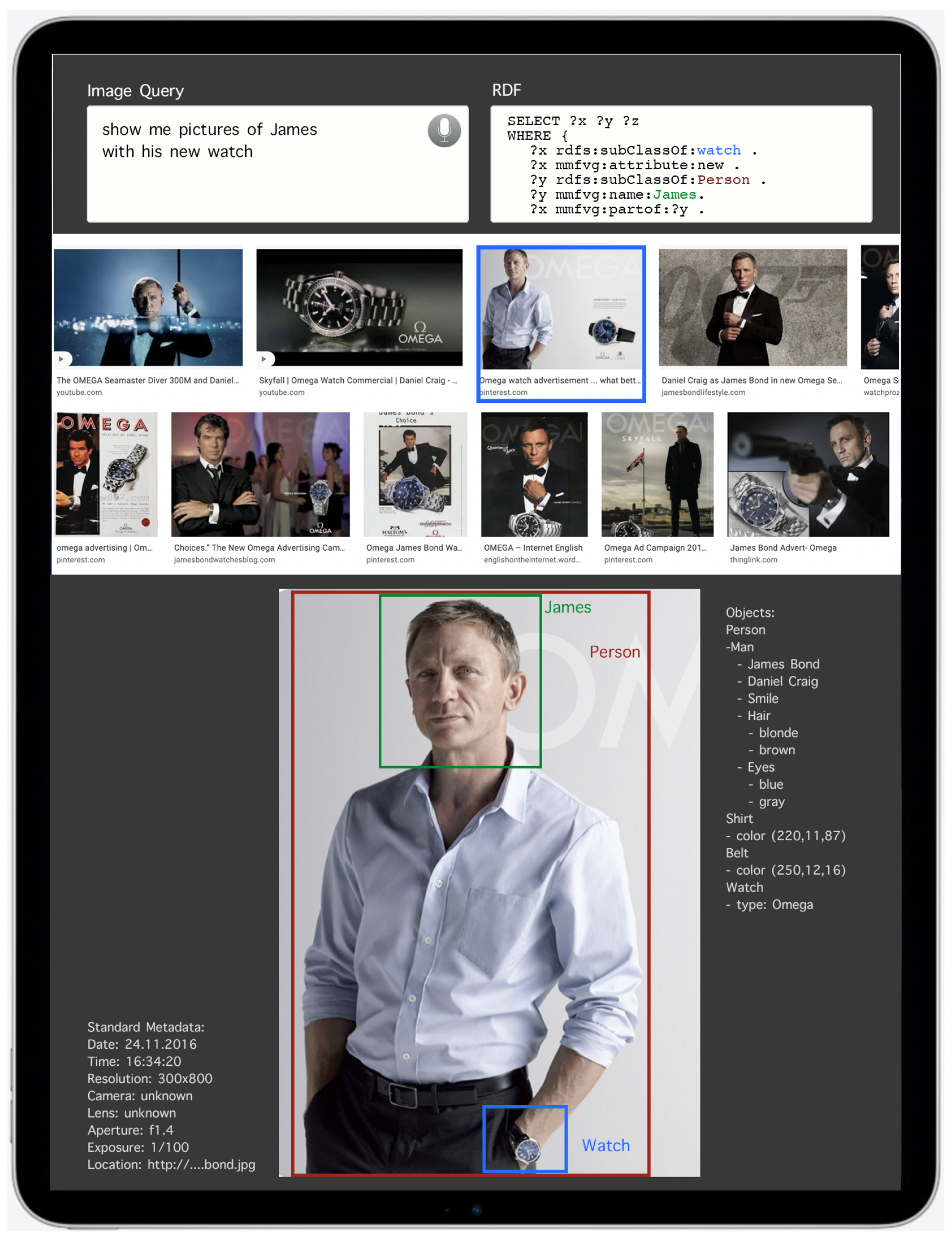
- “show me a picture where I got my new watch”—This type of query is problematic for most of the current algorithms. One reason is that data from more than one picture are required to solve this query. A comparison of “old” pictures with those where a “new” object appears is required. The second reason is that all the object detection algorithms are trained to find relevant objects, which usually a watch is not. Even employing the fine-grained object detection, the “watch” will not receive any relevance for indexing. Even more difficult to answer is the question, “what happens if my “new” watch becomes “old” again”. (This is one reason why AI4MMRA performs a permanent reprocessing of feature vectors graphs.)
- Q3:
- “can you find the picture where I had my leg broken”—This is also difficult to solve with current technology. How should a broken leg be detected? The semantics that broken legs might be detected by a white plaster cast in combination with the region detection “leg” is hardly possible. Maybe I broke my arm at another time? How should current algorithms distinguish? Even if you would have a Twitter post with that picture, none of the current algorithms would be able to combine this properly.
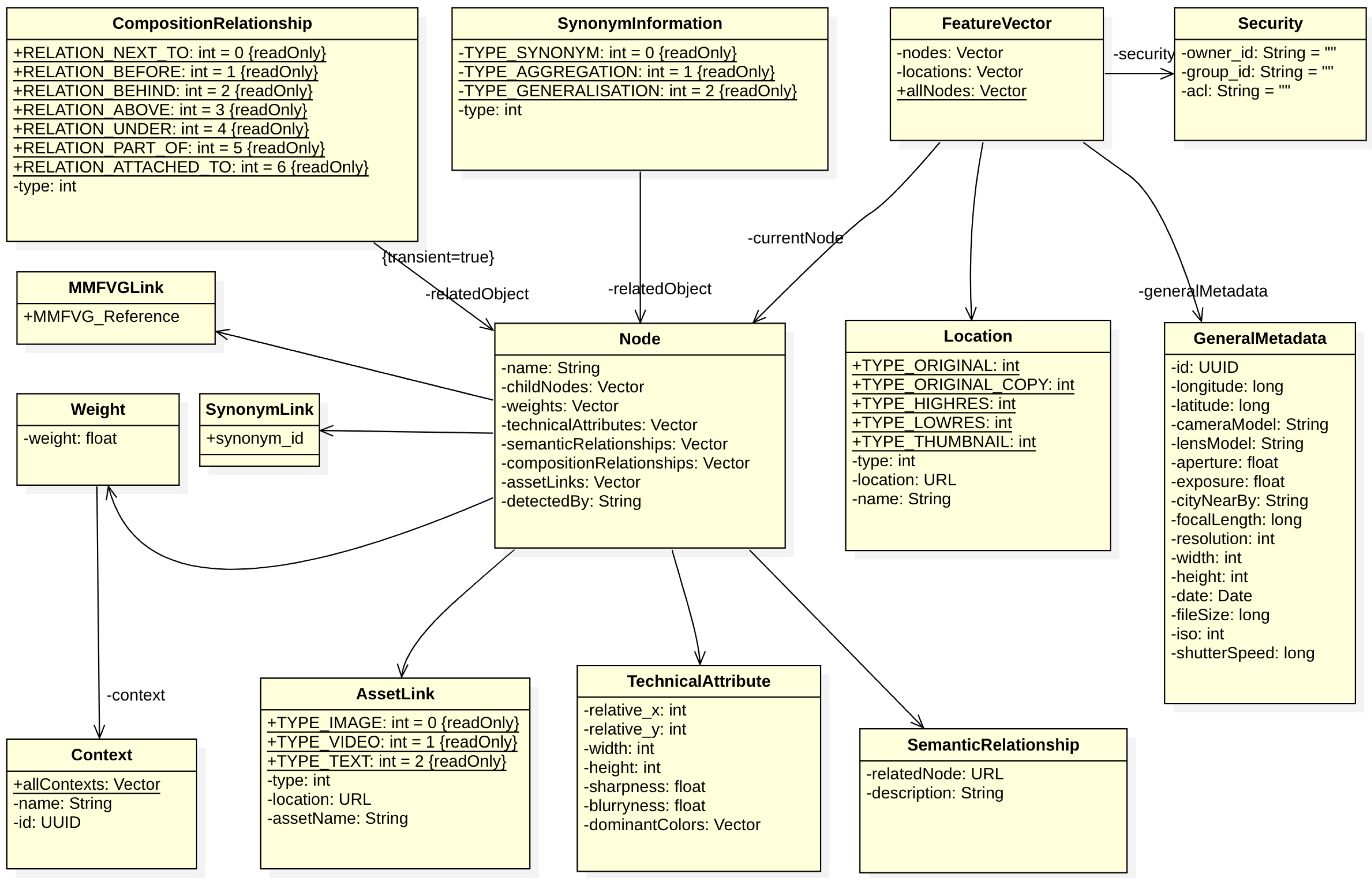
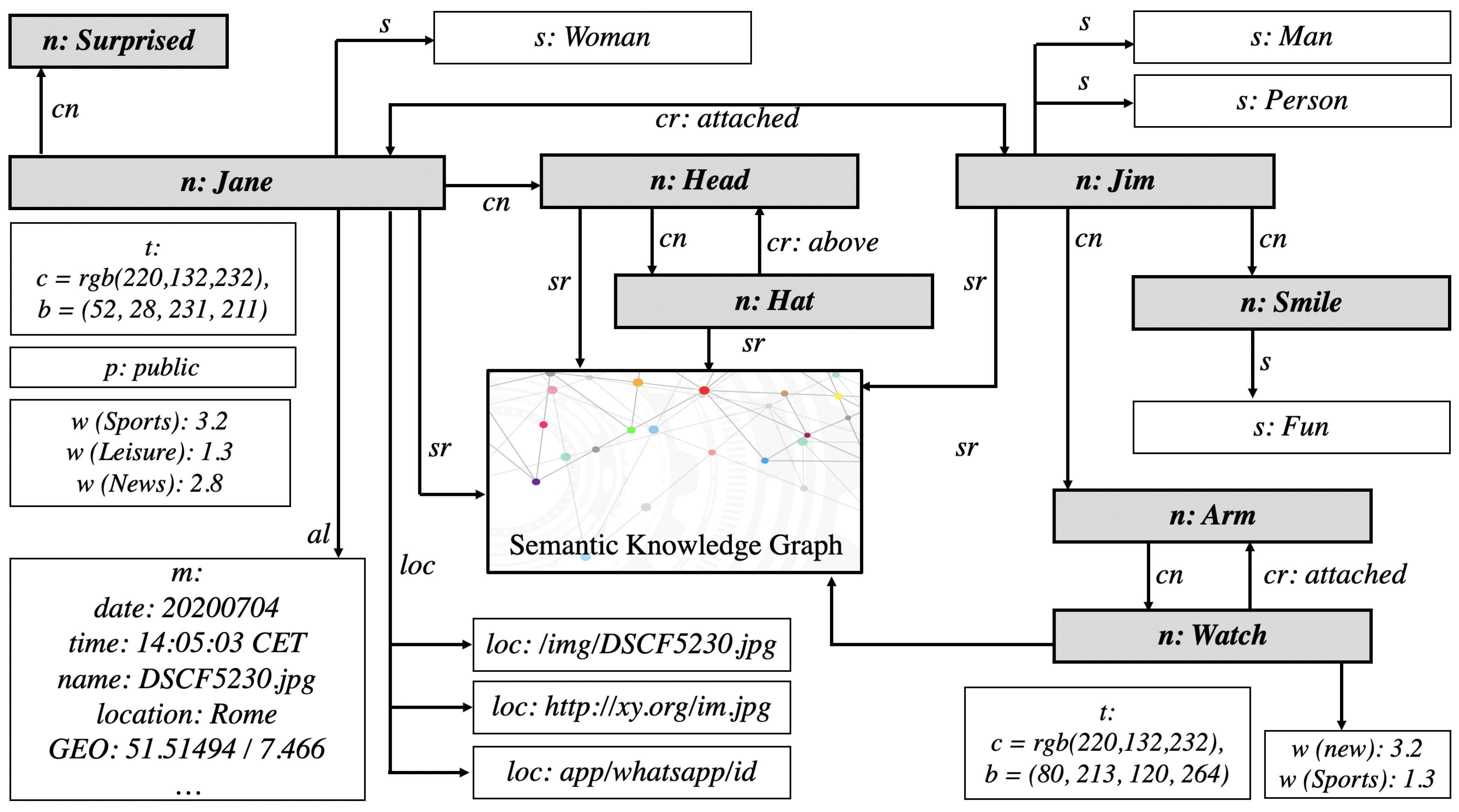
3.3. The Multimedia Feature Vector Graph
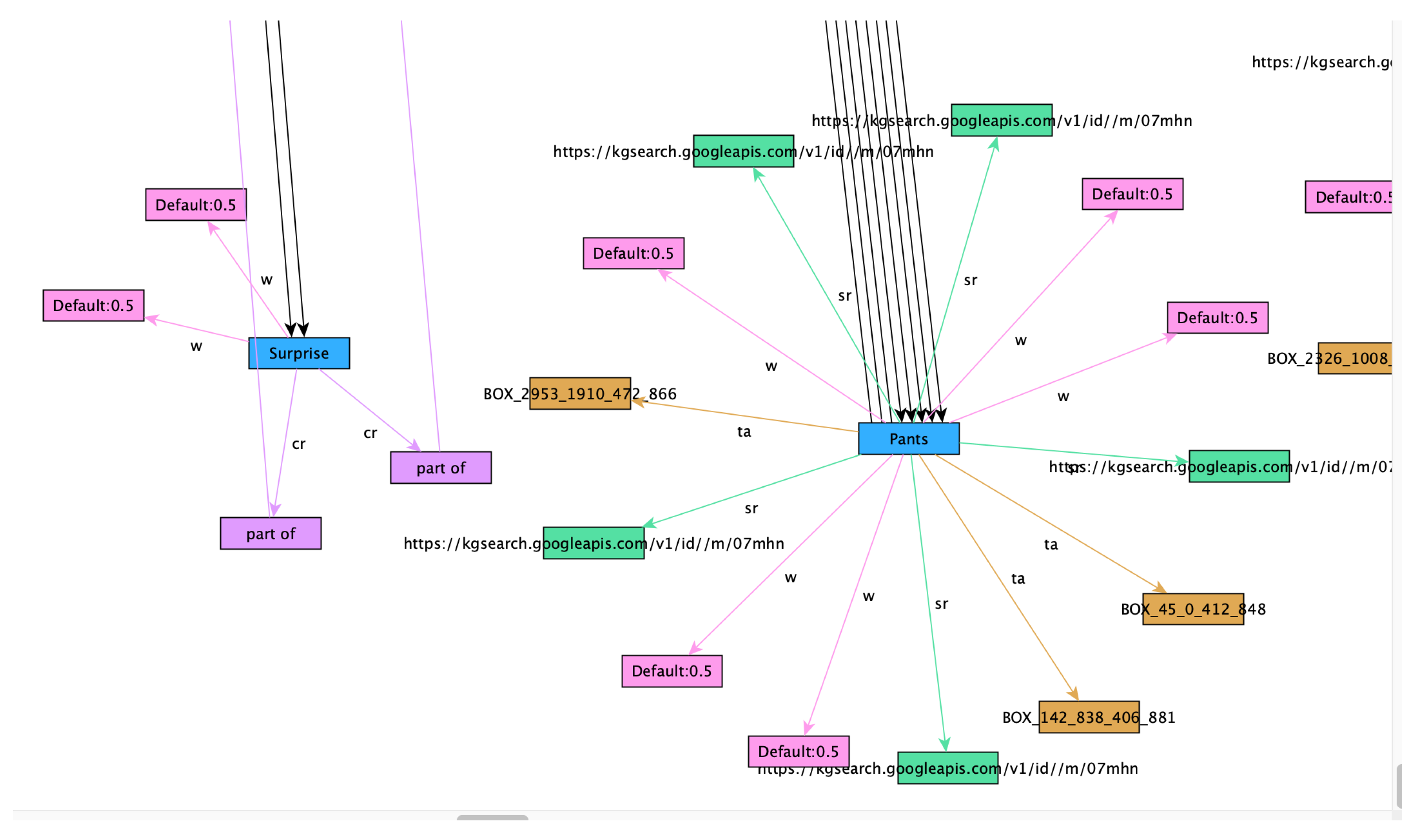
- Nodes represent objects, activities or regions of relevance that have been detected within an asset. The root node r is the dominating node of the MMFVG for a given multimedia asset and is also represented by the node class. External nodes e represent external information structures such as [14,15] or parts of other MMFVGs and are also represented by the node class.
- Weights represent the relevance of a node according to a special context. The context is an important description to refine the search and query scope. It is created by the related metadata of an MMFVG stucture and helps to determine the correct usage of homonyms. The context can also represent different aspects of the same object, such as in the timeline of a movie, where the same object can be used differently during the story of the movie. A weight represents the importance of the node in the overall image or video and the deviation from “normal” content compared to other assets of a similar kind (c.f. the “new watch” example). It is calculated initially by the GMAF, but constantly refined by AI4MMRA.
- Childnodes are subobjects that have been detected by recursive application of the GMAF, e.g., Person → Body → Arm → Left Hand → Fourth Finger → Ring. So, one of the Person’s child nodes would be the “Body”, one of the Body’s child nodes would be “Arm”, and so on. Child relationships in the MMFVG are transitive.
- TechnicalAttributes represent nonsemantic features of a node. These can be the color footprint of this node (c), its bounding box (b) within the image (defined by x, y, width, height), the DPI resolution of the section, information about, e.g., sharpness or blurring, etc.
- GeneralMetadatam represent the asset’s general metadata object, which is extracted by EXIF or MPEG7 [12,13] and contains information such as, e.g., Date, Time, GEO-coding, Aperture, Exposure, Lens, Focal Length, Height, Width and Resolution. In m, a unique identifier for the multimedia asset is also stored.
- Location Nodes represent locations where the original multimedia asset or copies of the asset in original or different resolutions or segments are placed.
- SynonymInformation point to a normalized synonym graph, where the “is a” relationship is modeled. So, for a “Person”, we would find also, e.g., “individual”, “being”, “human”, “creature” and “human being”.
- Security and Privacy p define the asset’s privacy and security settings, such as for an access control List. This ensures that users will only process and receive their own content and content that has been shared with them by other users.
- CompositionRelationships providing a relationship between a multimedia asset’s objects. It contains information such as, e.g., “next to”, “in front of”, “behind”, “attached to”, and is calculated by recursively applying the object bounding boxes and measuring the distances between them.
- Semantic Relationships connect each node to a position within external semantic knowledge graphs such as [14].
- SynonymLinks reference synonym information.
- MMFVGLinks represent the connection to other MMFVGs as standard references in the node class.
- AssetLinks point to location nodes.
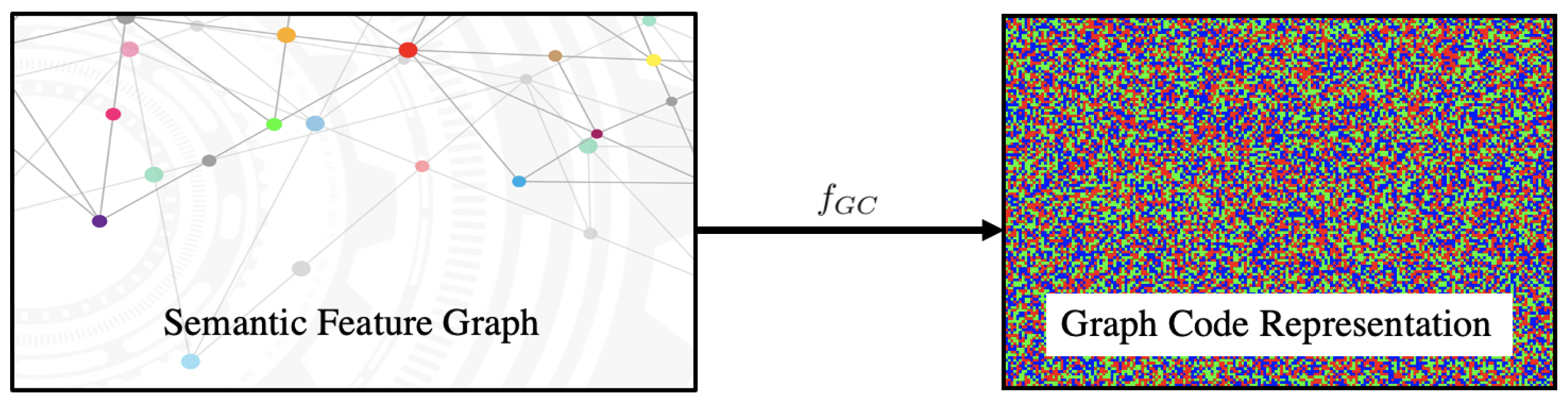
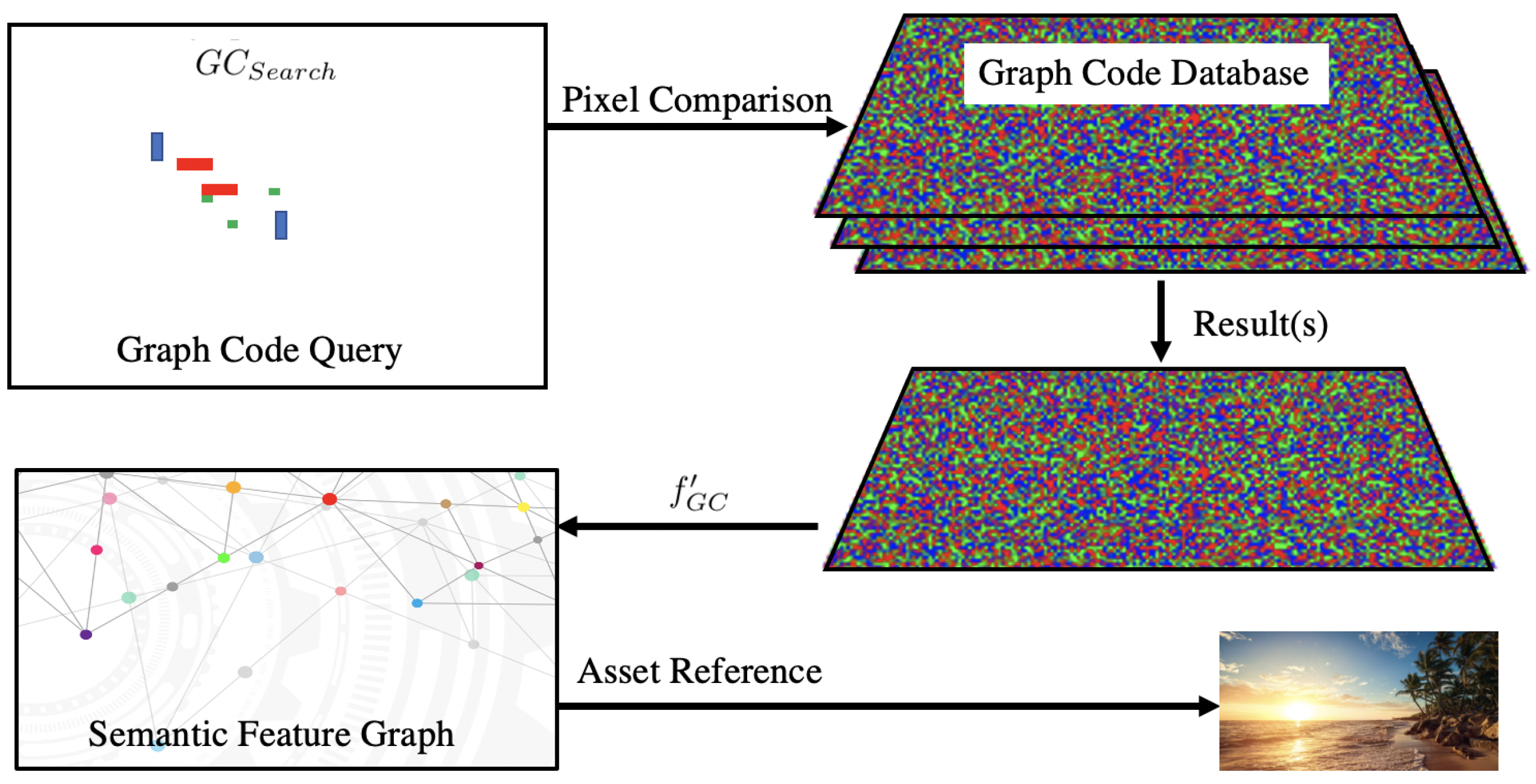
3.4. Fast Indexing and Retrieval for Graphs on Smartphones
3.5. A Graph Encoding Algorithm Example
3.6. The Generic Multimedia Annotation Framework
- Features within a single multimedia asset, such as object detection, technical metadata and basic semantic metadata;
- Features on higher semantic levels, such as people or face recognition, mood detection and ontology links;
- Recursive features, which result from applying the GMAF recursively to subsets of the multimedia asset;
- Indirect features, which result from linked assets and refine the features of the current asset (other scenes in a video, corresponding social media posts);
- Intra-asset features, which use information from assets of the same series, location or timestamp or data from generally similar assets to refine an asset’s features.
3.7. Natural Language Processing (NLP)
3.8. Social Media
3.9. Summary
4. Implementation
4.1. Generic Multimedia Annotation Framework (GMAF)
4.2. Multidimensional Feature Vector Framework (MMFVGF)
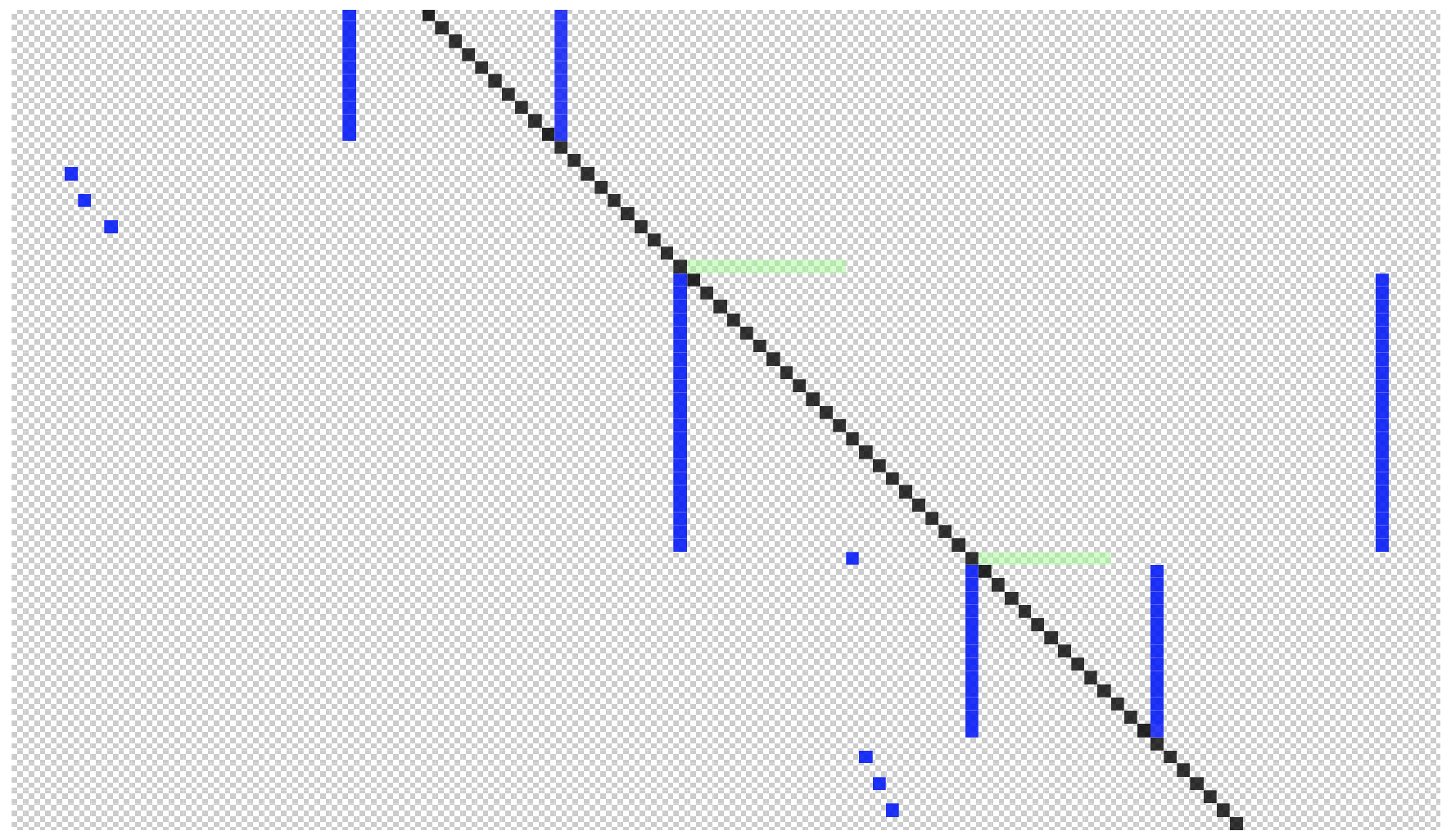
4.3. Graph Code Implementation
- public void process(Node n) {
- for (ChildNode cn : childnodes) {
- int x = getIndexFor(n.getNodeName());
- int y = getIndexFor(cn.getNodeName());
- Color color = getColorForType(Node.CHILD_NODE);
- pixels[x][y].setColor(color);
- process(cn);
- }
- }
- public int getIndexFor(String name) {
- // wordMap is a Hashtable containing all
- // words of the current ontology
- return wordMap.get(name);
- }
- public Color getColorForType{int type} {
- if (type == Node.CHILD_NODE)
- return new Color(220,220,100);
- if (type == Node.SYNONYM)
- return new Color(100, 100,220);
- // ...
- }
- public Color getColorForWeight(float weight,
- Context c) {
- // weight is between 0 and 1
- String name = c.getName();
- int r = getColorForContext(name);
- int g = (int)()255 ∗ weight);
- int b = 255;
- return new Color(r, g, b);
- }
4.4. AI4MMRA
4.5. Querying
- SELECT ?x ?y ?z
- WHERE {
- ?x rdfs:subClassOf:watch .
- ?x mmfvg:attribute:new .
- ?y rdfs:subClassOf:Person .
- ?y mmfvg:name:Jim .
- ?x mmfvg:partof:?y .
- ?z mmfvg:type:Image
- }
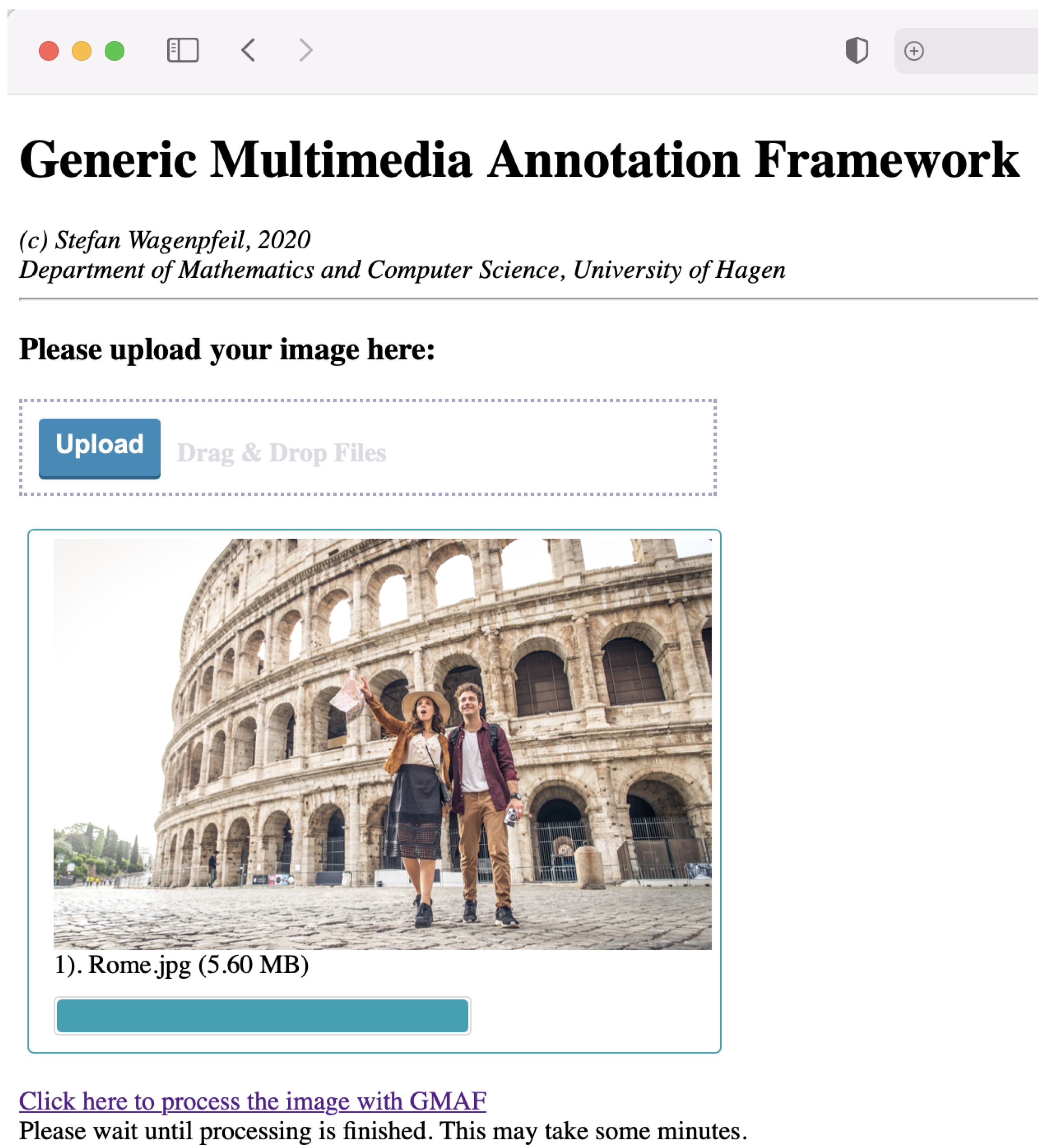
4.6. Swift Prototype
4.7. Summary
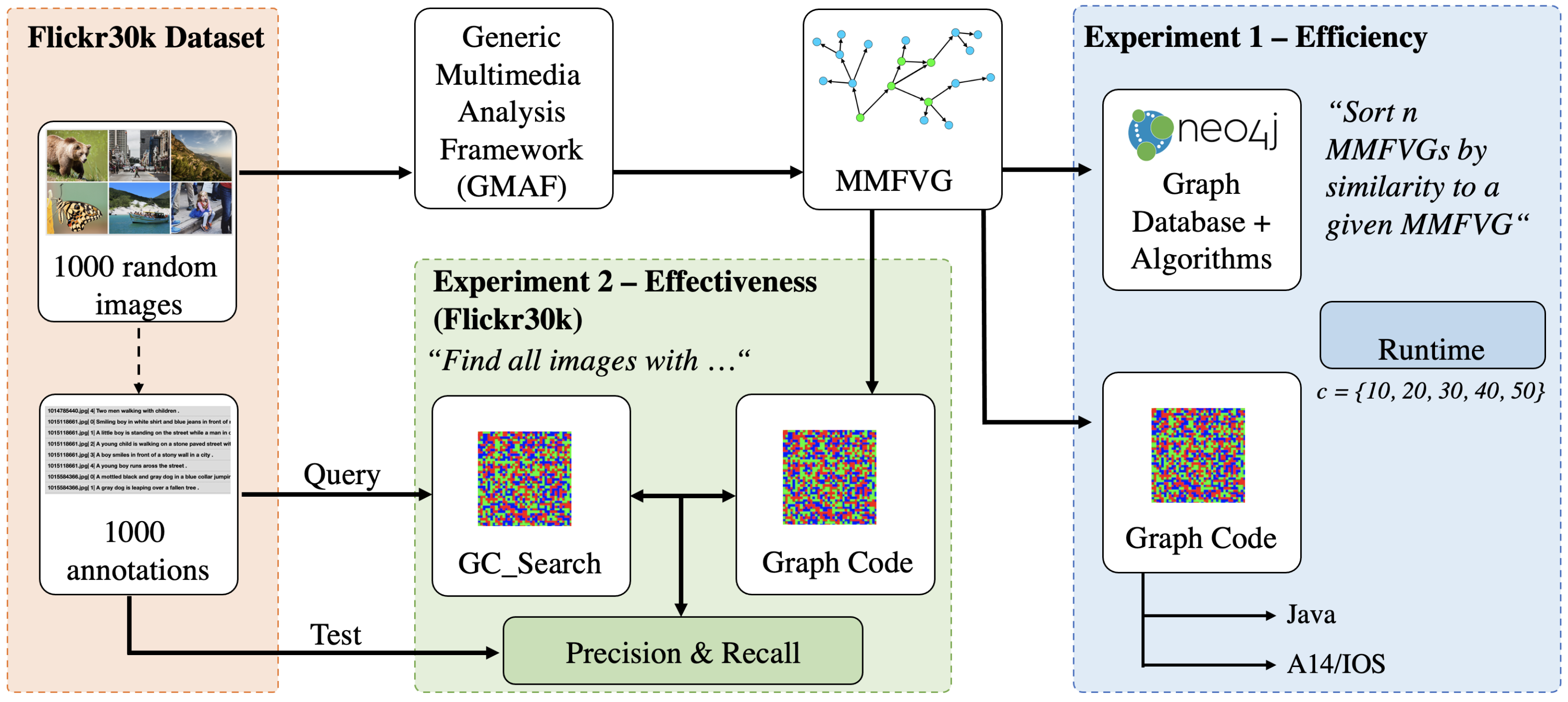
5. Evaluation and Experiments
5.1. Java Prototype Implementation
5.2. Swift/UI5-Prototype
- Software design: The described design (see Section 3.1) has to be adapted to the requirements for Swift and iOS programming, especially regarding UI handling and requirements regarding Apple’s App Development program [91]. As the prototype focuses on the capabilities of local processing, the GMAF contains only Apple plugins for local object detection such as those in [70].
- Local processing: Compared to the Web-based services for object detection such as [9], local detection is much faster. Local processing does not need to upload images to a remote server and wait for remote processing results, and can employ specialized hardware in smartphones such as that in [16]. While remote object detection usually takes about 25 s for an image to be processed, the local call is finished in milliseconds.
- Multimedia source: We built the Swift prototype to access the user’s local image library to index and retrieve multimedia objects and to comply to Apple’s standards.
5.3. Graph Encoding Algorithm
- Density: The graph structure must be dense enough to employ as many pixels as possible. Large white spots in the graph code lead to reduced performance. For multimedia assets, this is typical, but for records such as the IMDb dataset, the performance of the graph encoding algorithm is low.
- Ontology size: As the graph encoding algorithm is based on a finite set of possible nodes, the size of this set directly affects performance. Our tests give promising results with ontologies including less than one million possible nodes. Dynamic ontologies based on the available content can be considered to increase the processing performance.
- Hardware support: The more parallelism can be employed, the better the performance achieved. In the best case, the graph encoding algorithm performs in . For smaller graphs, an unparallelized version can also provide suitable performance, but for larger graphs, special hardware must be employed.
5.4. AI4MMRA
5.5. Experiments
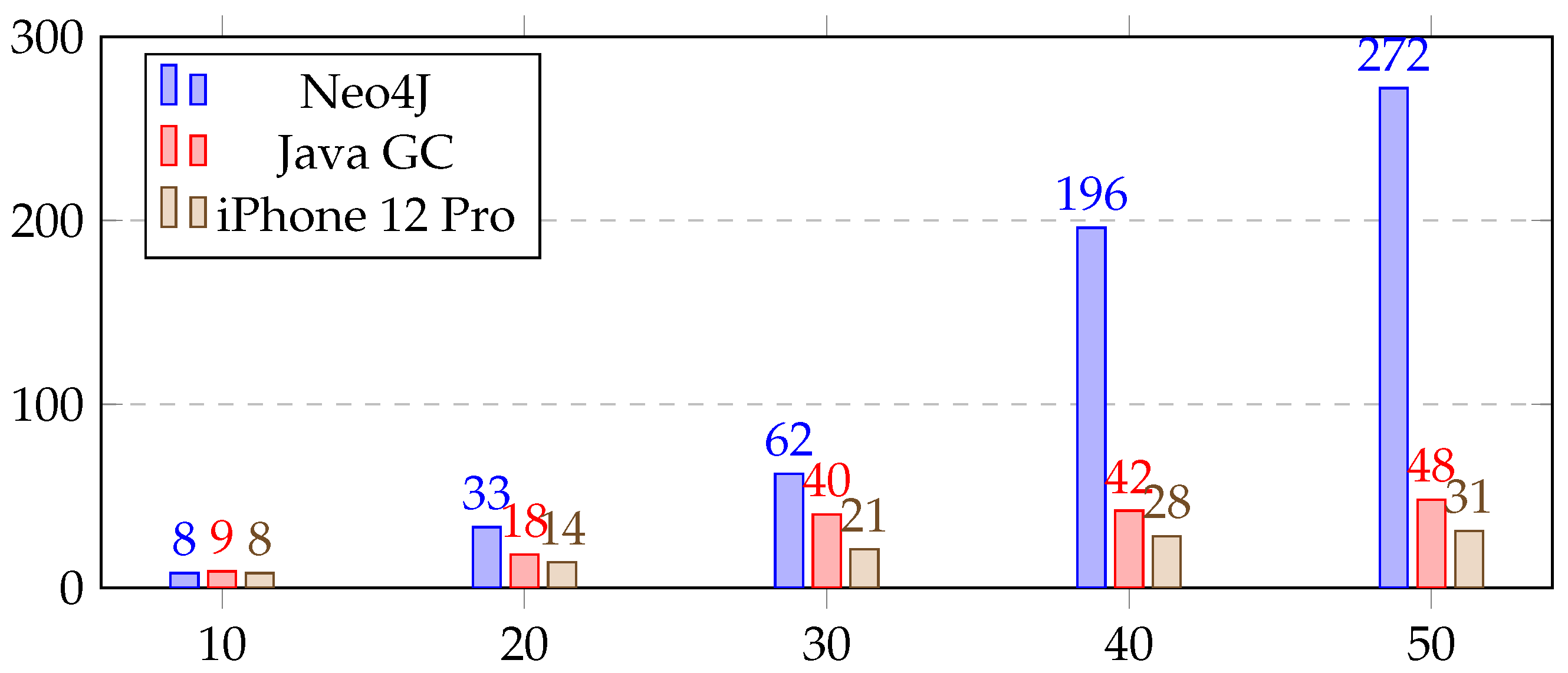
5.5.1. Experiment 1—Efficiency
- MATCH (r1:Node {name: ’N_Root_Image_Search’}
- )-[*..4]->(child1)
- WITH r1, collect(id(child1)) AS r1Child
- MATCH (i:Image)-[:img]->
- (r2:Node {name: ’N_Root_Image’}
- )-[*..4]->(child2)
- WHERE r1 <> r2
- WITH r1, r1Child, r2, collect(id(child2))
- AS r2Child
- RETURN r1.image AS from, r2.image AS to,
- gds.alpha.similarity.jaccard
- (r1Child, r2Child)
- AS similarity
5.5.2. Experiment 2—Effectiveness
5.5.3. Experiment 3—Quality
5.5.4. Discussion
6. Summary and Relevance
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nudelman, M. Smartphones Cause a Photography Boom. 2020. Available online: http://www.businessinsider.com/12-trillion-photos-to-be-taken-in-2017-thanks-to-smartphones-chart-2017-8 (accessed on 23 August 2020).
- Mazhelis, O. Impact of Storage Acquisition Intervals on the Cost-Efficiency of the Private vs. Public Storage. In Proceedings of the 2012 IEEE Fifth International Conference on Cloud Computing, Honolulu, HI, USA, 24–29 June 2012; pp. 646–653. [Google Scholar]
- Apple.com. iCloud–the Best Place for Photos. 2020. Available online: http://www.apple.com/icloud/ (accessed on 23 August 2020).
- Beyerer, J. Pattern Recognition-Introduction; Walter de Gruyter GmbH & Co KG: Berlin, Germany, 2017; pp. 10–37. ISBN 978-3-110-53794-9. [Google Scholar]
- Bond, R.R.; Engel, F.; Fuchs, M.; Hemmje, M.; McKevitt, P.M.; McTear, M.; Mulvenna, M.; Walsh, P.; Zheng, H. Digital empathy secures Frankenstein’s monster. In Proceedings of the 5th Collaborative European Research Conference (CERC 2019), Hochschule Darmstadt, University of Applied Sciences, Faculty of Computer Science, Darmstadt, Germany, 29–30 March 2019; Volume 2348, pp. 335–349. [Google Scholar]
- Beierle, C. Methoden Wissensbasierter Systeme-Grundlagen; Springer: Berlin/Heidelberg, Germany; New York, NY, USA, 2019; pp. 89–157. ISBN 978-3-658-27084-1. [Google Scholar]
- Goodfellow, I. Deep Learning; MIT Press: Cambridge, UK, 2016; ISBN 978-0-262-03561-3. [Google Scholar]
- Heaton, J. Deep Learning and Neural Networks; Springer: Berlin/Heidelberg, Germany, 2015; pp. 1–25. ISBN 978-1505714340. [Google Scholar]
- Google.com. Google Vision AI–Derive Insights from Images. 2020. Available online: http://cloud.google.com/vision (accessed on 23 August 2020).
- Microsoft.com. Machine Visioning. 2020. Available online: http://azure.microsoft.com/services/cognitive-services/computer-vision (accessed on 23 August 2020).
- Amazon.com. Amazon Recognition. 2020. Available online: http://aws.amazon.com/recognition (accessed on 23 August 2020).
- MIT—Massachutsetts Institute of Technology. Description of Exif File Format. 2020. Available online: http://media.mit.edu/pia/Research/deepview/exif.html (accessed on 23 August 2020).
- Chang, S. Overview of the MPEG-7 standard. IEEE Trans. Circuits Syst. Video Technol. 2001, 11, 688–695. [Google Scholar] [CrossRef]
- Google.com. Google Knowledge Search API. 2020. Available online: http://developers.google.com/knowledge-graph (accessed on 23 August 2020).
- W3C.org. W3C Semantic Web Activity. 2020. Available online: http://w3.org/2001/sw (accessed on 23 August 2020).
- Wikipedia.com. Apple A14 Bionic. 2020. Available online: https://en.wikipedia.org/wiki/Apple_A14 (accessed on 28 October 2020).
- Wikipedia.com. Information Age. 2020. Available online: https://en.wikipedia.org/wiki/Information_Age (accessed on 28 October 2020).
- Storage Newsletter. Total WW Storage Data at 6.8ZB in 2020. Available online: https://www.storagenewsletter.com/2020/05/14/total-ww-storage-data-at-6-8zb-in-2020-up-17-from-2019-idc/ (accessed on 24 October 2020).
- Wikipedia.com. Bandwidth (Computing). 2020. Available online: https://en.wikipedia.org/wiki/Bandwidth_(computing) (accessed on 27 October 2020).
- Wikipedia.com. 5G. 2020. Available online: https://en.wikipedia.org/wiki/5G (accessed on 27 October 2020).
- Avola, D. Low-Level Feature Detectors and Descriptors for Smart Image and Video Analysis: A Comparative Study. In Intelligent Systems Reference Library; Springer: Berlin/Heidelberg, Germany, 2018; pp. 7–29. ISBN 978-3-319-73890-1. [Google Scholar]
- Kankanhalli, M. Video modeling using strata-based annotation. IEEE Multimed. 2000, 7, 68–74. [Google Scholar] [CrossRef]
- Wagenpfeil, S. Towards AI-bases Semantic Multimedia Indexing and Retrieval for Social Media on Smartphones. In Proceedings of the 2020 15th International Workshop on Semantic and Social Media Adaptation and Personalization (SMAP 2020 Conference Paper), Zakynthos, Greece, 29–30 October 2020. [Google Scholar]
- FFMpeg.org. ffmpeg Documentation. 2020. Available online: http://ffmpeg.org (accessed on 23 August 2020).
- Open Images. Overview of Open Images V6. 2020. Available online: http://storage.googleapis.com/openimages/web/factsfigures.html (accessed on 23 August 2020).
- Adobe.com. Work with Metadata in Adobe Bridge. 2020. Available online: http://helpx.adobe.com/bridge/using/metadata-adobe-bridge.html (accessed on 23 August 2020).
- EBU Recommendations. Material Exchange Format. 2007. Available online: http://mxf.irt.de/information/eburecommendations/R121-2007.pdf (accessed on 23 August 2020).
- Apple.com. Siri for Developers. 2020. Available online: https://developer.apple.com/siri/ (accessed on 23 August 2020).
- Microsoft.com. Your Personal Productivity Assistant in Microsoft 365. Available online: https://www.microsoft.com/en-us/cortana (accessed on 14 November 2020).
- Amazon.com. Amazon Alexa Home. Available online: https://developer.amazon.com/en-US/alexa (accessed on 11 December 2020).
- Domingue, J. Introduction to the Semantic Web Technologies. In Handbook of Semantic Web Technologies; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar] [CrossRef]
- Kwasnicka. Bridging the Semantic Gap in Image and Video Analysis; Springer: Berlin/Heidelberg, Germany, 2018; pp. 97–118. ISBN 978-3-319-73891-8. [Google Scholar]
- Mc Kevitt, P. MultiModal semantic representation. In SIGSEM Working Group on the Representation of MultiModal Semantic Information; Bunt, H., Lee, K., Romary, L., Krahmer, E., Eds.; Tilburg University: Tilburg, The Netherlands, 2003. [Google Scholar]
- Spyrou. Semantic Multimedia Analysis and Processing; CRC Press: Boca Raton, FL, USA, 2017; pp. 31–63. ISBN 978-1-351-83183-3. [Google Scholar]
- MIRFlickr25000 dataset. The MIRFlickr Retrieval Evaluation. 2020. Available online: http://press.liacs.nl/mirflickr (accessed on 23 August 2020).
- Scherer, R. Computer Vision Methods for Fast Image Classification and Retrieval; Polish Academy of Science: Warsaw, Poland, 2020; pp. 33–134. ISBN 978-3-030-12194-5. [Google Scholar]
- Nixon, M. Feature Extraction and Image Processing for Computer Vision; Academic Press Elsevir: Cambridge, MA, USA, 2020. [Google Scholar]
- Bhute, B. Multimedia Indexing and Retrieval Techniques: A Review. Int. J. Comput. Appl. 2012, 58, 35–42. [Google Scholar]
- Wikipedia.com. Image Histograms. Available online: https://en.wikipedia.org/wiki/Image_histogram (accessed on 10 October 2020).
- Wikipedia.com. Color Histograms. Available online: https://en.wikipedia.org/wiki/Color_histogram (accessed on 10 October 2020).
- Wikipedia.com. Fast Fourier Transformation. Available online: https://en.wikipedia.org/wiki/Fast_Fourier_transform (accessed on 13 November 2020).
- Smeulders, A. Content-based image retrieval at the end of the early years. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1349–1380. [Google Scholar] [CrossRef]
- Gurski, F. On Characterizations for Subclasses of Directed Co-Graphs. 2019. Available online: http://arxiv.org/abs/1907.00801 (accessed on 24 August 2020).
- Needham, M. Graph Algorithms, Practical Examples in Apache Spark and Neo4j; O’Reilly: Newton, MA, USA, 2020; ISBN 978-1-492-05781-9. [Google Scholar]
- Robbinson, I. Graph Databases; O’Reilly: Newton, MA, USA, 2015; ISBN 978-1-491-93089-2. [Google Scholar]
- Jiezhong, Q. Network Embedding as Matrix Factorization: Unifying DeepWalk. 2017. Available online: http://arxiv.org/abs/1710.02971 (accessed on 24 September 2020).
- Bai, Y.; Ding, H.; Bian, S.; Chen, T.; Sun, Y.; Wang, W. SimGNN: A Neural Network Approach to Fast Graph Similarity Computation. In Proceedings of the WSDM ’19: Twelfth ACM International Conference on Web Search and Data Mining 2019, Melbourne, VIC, Australia, 11–15 February 2019. [Google Scholar] [CrossRef]
- W3C.org. SPARQL Query Language for RDF. 2013. Available online: https://www.w3.org/TR/sparql11-overview/ (accessed on 23 August 2020).
- Nkgau, T. Graph similarity algorithm evaluation. In Proceedings of the 2017 Computing Conference, London, UK, 18–20 July 2017; pp. 272–278. [Google Scholar]
- Sciencedirect.com. Adjacency Matrix. Available online: https://www.sciencedirect.com/topics/mathematics/adjacency-matrix (accessed on 17 December 2020).
- Fischer, G. Lineare Algebra; Springer Spektrim Wiesbaden: Berlin/Heidelberg, Germany, 2014; pp. 143–163. ISBN 978-3-658-03945-5. [Google Scholar]
- Yuan, Y. Graph Similarity Search on Large Uncertain Graph Databases. VLDB J. 2015, 24, 271–296. [Google Scholar] [CrossRef]
- Samir, S. Seo For Social Media: It Ranked First in the Search Engines. Kindle Edition, ASIN: B08B434ZM2. Available online: https://www.amazon.de/-/en/Samir-Sami-ebook/dp/B08B434ZM2 (accessed on 14 October 2020).
- Bultermann, D. Socially-Aware Multimedia Authoring: Past. Acm Trans. Multimed. Comput. Commun. Appl. 2013. [Google Scholar] [CrossRef]
- Krig, S. Interest Point Detector and Feature Descriptor Survey; Springer: Berlin/Heidelberg, Germany, 2016; pp. 187–246. ISBN 978-3-319-33761-6. [Google Scholar]
- Hannane, R.; Elboushaki, A.; Afdel, K.; Naghabhushan, P.; Javed, M. An efficient method for video shot boundary detection and keyframe extraction using SIFT-point distribution histogram. Int. J. Multimed. Inf. Retr. 2016, 5, 89–104. [Google Scholar] [CrossRef]
- Sluzek, A. Local Detection and Identification of Visual Data; LAP LAMBERT Academic Publishing: Saarbrucken, Germany, 2013. [Google Scholar]
- Sevak, J.S.; Kapadia, A.D.; Chavda, J.B.; Shah, A.; Rahevar, M. Survey on semantic image segmentation techniques. In Proceedings of the 2017 International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 7–8 December 2017; pp. 306–313. [Google Scholar]
- Wang, G. Efficient Perceptual Region Detector Based on Object Boundary; Springer: Cham, Switzerland, 2016; pp. 66–78. ISBN 978-3-319-27673-1. [Google Scholar]
- Ballan, L.; Bertini, M.; Del Bimbo, A.; Seidenari, L.; Serra, G. Event Detection and Recognition for Semantic Annotation of Video. Multimed. Tools Appl. 2011, 51, 279–302. [Google Scholar] [CrossRef]
- Arndt, R.; Troncy, R.; Staab, S.; Hardman, L. COMM: A Core Ontology for Multimedia Annotation. J. Comb. Theory 2008, 403–421. [Google Scholar]
- Ni, J.; Qian, X.; Li, Q.; Xu, X. Research on Semantic Annotation Based Image Fusion Algorithm. In Proceedings of the 2017 International Conference on Computer Systems, Electronics and Control (ICCSEC), Dalian, China, 25–27 December 2017; pp. 945–948. [Google Scholar]
- Gayathri, N. An Efficient Video Indexing and Retrieval Algorithm using Ensemble Classifier. In Proceedings of the 2019 4th International Conference on Electrical, Electronics, Communication, Computer Technologies and Optimization Techniques (ICEECCOT), Karnataka, India, 13–14 December 2019; pp. 250–258. [Google Scholar]
- Zhao, F. Learning Specific and General Realm Feature Representations for Image Fusion. IEEE Trans. Multimed. 2020, 1. [Google Scholar] [CrossRef]
- Hu, Q.; Wu, C.; Chi, J.; Yu, X.; Wang, H. Multi-level Feature Fusion Facial Expression Recognition Network. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 23–25 May 2020; pp. 5267–5272. [Google Scholar]
- Goh, K.; Li, B.; Chang, E.Y. Semantics and Feature Discovery via Confidence-Based Ensemble. ACM Trans. Multimed. Comput. Commun. Appl. 2005, 1, 168–189. [Google Scholar] [CrossRef]
- Norman, D.A.; Draper, S.W. User Centered System Design-New Perspectives on Human-computer Interaction; Taylor & Francis: Oxfordshire, UK; Justus-Liebig-Universität: Giessen, Germany, 1986; ISBN 978-0-898-59872-8. [Google Scholar]
- Nunamaker, J. Systems Development in InformationSystems Research. J. Manag. Inf. Syst. 1991, 89–106. [Google Scholar]
- Fowler, M. UML Distilled-A Brief Guide to the Standard Object Modeling Language; Addison-Wesley Professional: Boston, MA, USA, 2004; ISBN 978-0-321-19368-1. [Google Scholar]
- Apple.com. Face Recognition in Apple Fotos. 2020. Available online: https://support.apple.com/de-de/guide/photos/phtad9d981ab/mac (accessed on 23 August 2020).
- Iyer, G. A Graph-Based Approach for Data Fusion and Segmentation of Multimodal Images. IEEE Trans. Geosci. Remote. Sens. 2020, 1–11. [Google Scholar] [CrossRef]
- yWorks GmbH. yEd Graph Editor. 2020. Available online: https://www.yworks.com/products/yed (accessed on 23 August 2020).
- Wikipedia.org. Barcodes. Available online: https://en.wikipedia.org/wiki/Barcode (accessed on 11 December 2020).
- Wikipedia.org. QR Codes. Available online: https://en.wikipedia.org/wiki/QR_code (accessed on 11 December 2020).
- Aggarwal, C. Linear Algebra and Optimization for Machine Learning: A Textbook; Springer Publishing: Cham, Switzerland, 2020; ISBN 978-3030403430. [Google Scholar]
- Foster, I. Designing and Building Parallel Programs; Addison Wesley: Boston, MA, USA, 1995; ISBN 0-201-57594-9. [Google Scholar]
- Planche, B. Computer Vision with TensorFlow 2; Packt Publishing: Birmingham, UK, 2019; pp. 77–99. ISBN 978-1-78883-064-5. [Google Scholar]
- Tuomanen, B. GPU Programming with Python and CUDA; Packt Publishing: Birmingham, UK, 2018; pp. 101–184. ISBN 978-1-78899-391-3. [Google Scholar]
- Nvidia.com. RTX 2080. Available online: https://www.nvidia.com/de-de/geforce/graphics-cards/rtx-2080/ (accessed on 10 November 2020).
- Schmitt, I. WS-QBE: A QBE-Like Query Language for Complex Multimedia Queries. In Proceedings of the 11th International Multimedia Modelling Conference, Melbourne, Australia, 12–14 January 2005; pp. 222–229. [Google Scholar]
- Dufour, R.; Esteve, Y.; Deléglise, P.; Béchet, F. Local and global models for spontaneous speech segment detection and characterization. In Proceedings of the 2009 IEEE Workshop on Automatic Speech Recognition & Understanding, Meran, Italy, 13–17 December 2010; pp. 558–561. [Google Scholar]
- Jung, H. Automated Conversion from Natural Language Query to SPARQL Query. J. Intell. Inf. Syst. 2020, 1–20. [Google Scholar] [CrossRef]
- Wagenpfeil, S. GMAF Prototype. 2020. Available online: http://diss.step2e.de:8080/GMAFWeb/ (accessed on 23 August 2020).
- Apache Software Foundation. Apache Commons Imaging API. 2020. Available online: https://commons.apache.org/proper/commons-imaging/ (accessed on 23 August 2020).
- Oracle.com. Java Enterprise Edition. 2020. Available online: https://www.oracle.com/de/java/technologies/java-ee-glance.html (accessed on 23 August 2020).
- Docker.Inc. What Is a Container. 2020. Available online: https://www.docker.com/resources/what-container (accessed on 23 August 2020).
- Adobe.com. Adobe Stock. 2020. Available online: https://stock.adobe.com (accessed on 2 October 2020).
- Bornschlegel, M. IVIS4BigData: A Reference Model for Advanced Visual Interfaces Supporting Big Data Analysis in Virtual Research Environments. In AVI Workshop on Big Data Applications; Springer: Cham, Switzerland, 2020. [Google Scholar]
- EDISON Project-European Union’s Horizon 2020 research-grant agreement No. 675419. Available online: https://cordis.europa.eu/project/id/675419/de (accessed on 14 December 2020).
- Wagenpfeil, S. Github Repository of GMAF and MMFVG. 2020. Available online: https://github.com/stefanwagenpfeil/GMAF/ (accessed on 25 September 2020).
- Apple.com. Apple Development Programme. Available online: http://developer.apple.com (accessed on 21 November 2020).
- Apple.com. Apple Machine Learning. Available online: https://developer.apple.com/machine-learning/ (accessed on 24 November 2020).
- Neo4J.com. Neo4J Graph Database. Available online: https://neo4j.com/ (accessed on 24 November 2020).




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Jane | Head | Hat | Surprised | Woman | Jim | Arm | Watch | Smile | Fun | Sports | New | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Jane | ||||||||||||
| Head | ||||||||||||
| Hat | ||||||||||||
| Surprised | ||||||||||||
| Woman | ||||||||||||
| Jim | ||||||||||||
| Arm | ||||||||||||
| Watch | ||||||||||||
| Smile | ||||||||||||
| Fun | ||||||||||||
| Sports | ||||||||||||
| New |
| Hypothesis | Description |
|---|---|
| A. Efficiency | The described approach of using graph codes is more efficient than current solutions based on graph traversal algorithms. |
| B. Effectiveness | Images that have been processed with the GMAF can deliver good semantic results. |
| C. Quality | Recursive processing within the GMAF leads to more levels of semantic details. |
| c | n | v | Neo4J | Java | iPhone Pro |
|---|---|---|---|---|---|
| 10 | 326 | 1591 | 8 ms | 9 ms | 8 ms |
| 20 | 634 | 3218 | 33 ms | 18 ms | 14 ms |
| 30 | 885 | 4843 | 62 ms | 40 ms | 21 ms |
| 40 | 1100 | 5140 | 196 ms | 42 ms | 28 ms |
| 50 | 1384 | 7512 | 272 ms | 48 ms | 31 ms |
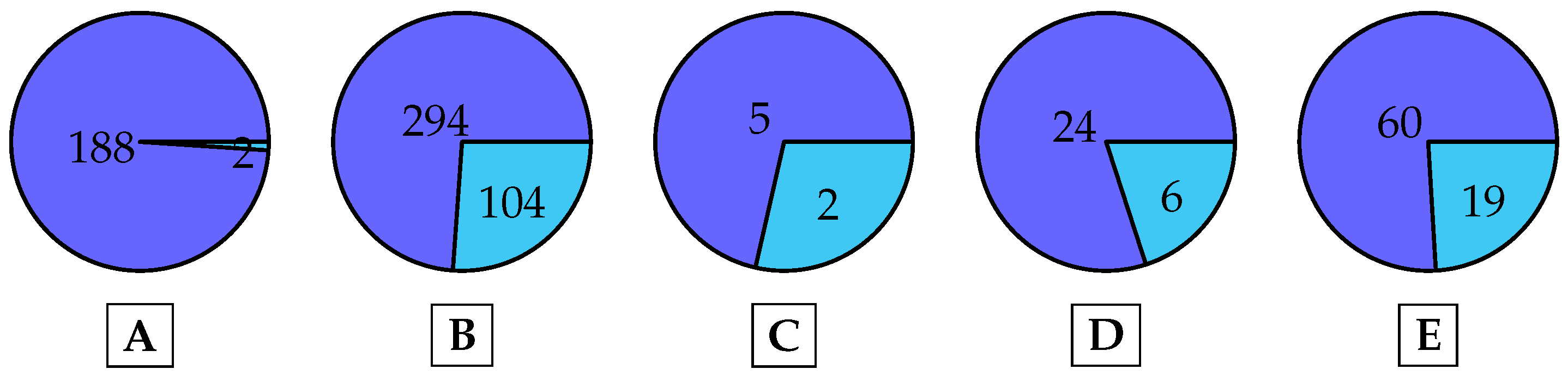
| Query | rel | rsel | tp | tn | P | R |
|---|---|---|---|---|---|---|
| (A) “Dog” | 206 | 190 | 188 | 2 | 0.98 | 0.91 |
| (B) “Man” | 629 | 398 | 294 | 104 | 0.76 | 0.47 |
| (C) “Golf” | 11 | 7 | 5 | 2 | 0.71 | 0.45 |
| (D) “Guitar” | 36 | 30 | 24 | 6 | 0.80 | 0.66 |
| (E) “Bicycle” | 66 | 79 | 60 | 19 | 0.75 | 0.90 |
| Recursions | Nodes | Edges | Detection Example |
|---|---|---|---|
| 0 | 53 | 204 | Person, Travel, Piazza Venezia, Joy |
| 1 | 71 | 274 | Pants, Top, Pocket, Street fashion |
| 2 | 119 | 475 | Camera, Bermuda Shorts, Shoe |
| 3 | 192 | 789 | Sun Hat, Fashion accessory, Watch, Bergen County (Logo) |
| 4 | 228 | 956 | Mouth, Lip, Eyebrow, Pocket, Maroon |
| 4 | 274 | 1189 | Leather, Grey, Single-lens reflex camera |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wagenpfeil, S.; Engel, F.; Kevitt, P.M.; Hemmje, M. AI-Based Semantic Multimedia Indexing and Retrieval for Social Media on Smartphones. Information 2021, 12, 43. https://doi.org/10.3390/info12010043
Wagenpfeil S, Engel F, Kevitt PM, Hemmje M. AI-Based Semantic Multimedia Indexing and Retrieval for Social Media on Smartphones. Information. 2021; 12(1):43. https://doi.org/10.3390/info12010043
Chicago/Turabian StyleWagenpfeil, Stefan, Felix Engel, Paul Mc Kevitt, and Matthias Hemmje. 2021. "AI-Based Semantic Multimedia Indexing and Retrieval for Social Media on Smartphones" Information 12, no. 1: 43. https://doi.org/10.3390/info12010043
APA StyleWagenpfeil, S., Engel, F., Kevitt, P. M., & Hemmje, M. (2021). AI-Based Semantic Multimedia Indexing and Retrieval for Social Media on Smartphones. Information, 12(1), 43. https://doi.org/10.3390/info12010043