
Help Me Learn! Architecture and Strategies to Combine Recommendations and Active Learning in Manufacturing

 ,
,  , , ,
, , ,  , and
, and
Abstract
:1. Introduction
2. Related Work
2.1. Demand Forecasting
2.2. Explainable Artificial Intelligence
2.3. Active Learning
Active Learning for Text Classification
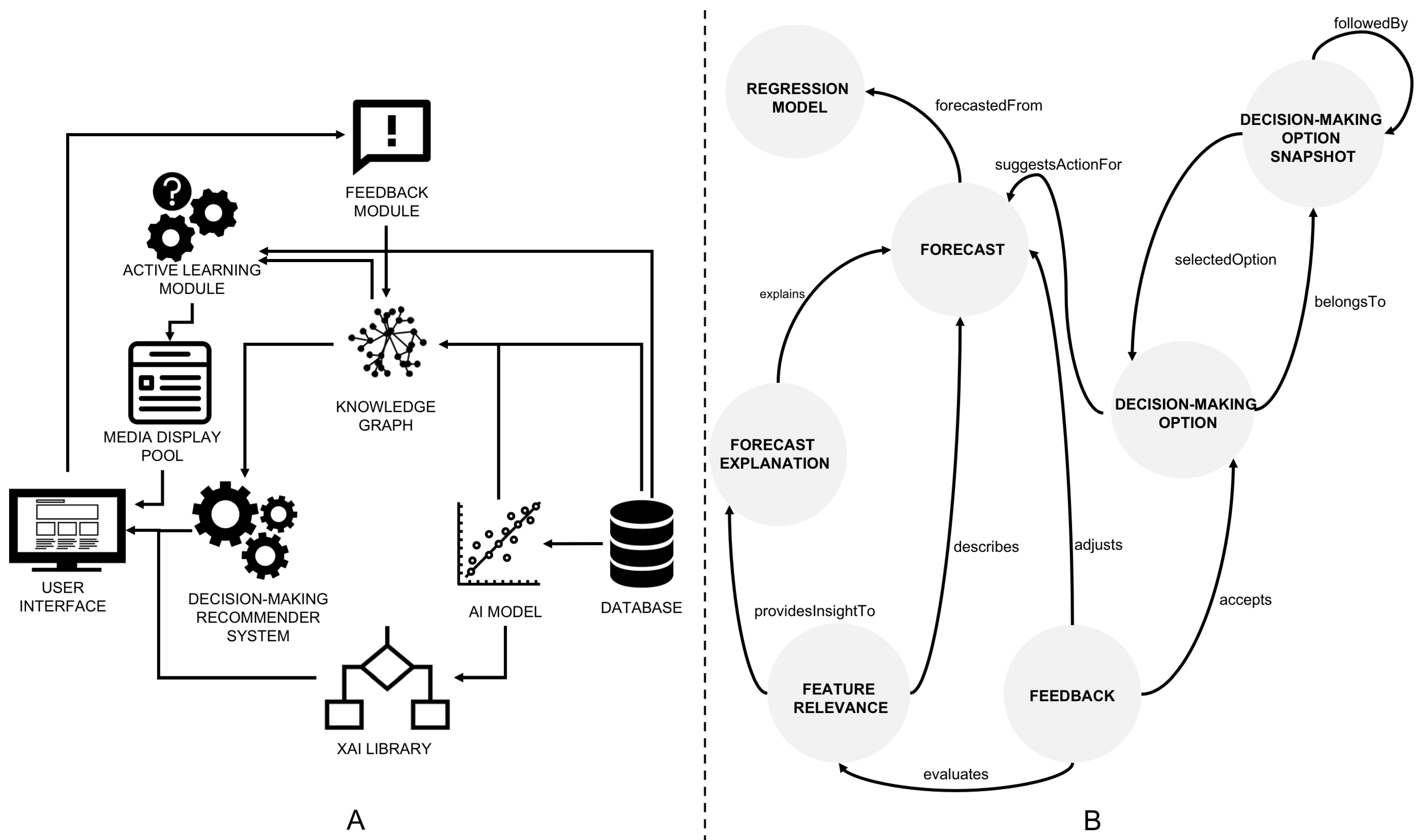
3. Proposed Architecture
- Database, stores operational data from the manufacturing plant. Data can be obtained from ERP, MES, or other manufacturing platforms;
- Knowledge Graph, stores data ingested from a database or external sources and connects it, providing a semantic meaning. To map data from the database to the knowledge graph, virtual mapping procedures can be used, built considering ontology concepts and their relationships;
- Active Learning Module, aims to select data instances whose labels are expected to be most informative to a machine learning model and thus are expected to contribute most to its performance increase when added to the existing dataset. Obtained labels are persisted to the knowledge graph and database;
- AI model, aims to solve a specific task relevant to the use case, such as classification, regression, clustering, or ranking;
- XAI Library, provides some insight into the AI models’ rationale used to produce the output for the input instance considered at the task at hand. E.g., in the case of a classification task, it may indicate the most relevant features for a given forecast or counterfactual examples;
- Decision-Making Recommender System recommends decision-making options to the users. Recommended decision-making options can vary depending on the users’ profile, specific use case context, and feedback provided in the past;
- Feedback module, collects feedback from the users and persists it into the knowledge graph. The feedback can correspond to predetermined options presented to the users (including labels for a classification problem) or custom feedback written by the users;
- User Interface, provides relevant information to the user through a suitable information medium. The interface must enable user interactions to create two-way communication between the human and the system.
4. Use Case
5. User Interface
- A
- Media news panel: displays media news regarding the automotive industry, global economy, unemployment, and logistics. The user can provide explicit feedback on them (if they are suitable or not), acting as an oracle for the active learning classifier. Once feedback is provided, a new piece of news is displayed to the user.
- B
- Forecast panel: given the date and material, it displays the forecasted demand for different clients. For each forecast, three options are available: edit the forecast (providing explicit feedback on the forecast value), display the forecast explanation, and display the decision-making options. The lack of editing on displayed forecasts is considered implicit feedback approving the forecasted demand quantities.
- C
- Forecast explanation panel: displays the forecast explanation for a given forecast. Our implementation displays the top three features identified by the LIME algorithm as relevant to the selected forecast. If users consider that some of the displayed features do not explain the given forecast, they can provide feedback by removing it from the list.
- D
- Decision-making options panel: displays possible decision-making options for a given forecast or step in the decision-making process. In particular, the decision-making options relate to possible shipments. If no good option exists, the user can create its own.
- E
- Feedback panel: gathers feedback from the user to understand the reasons behind the chosen decision-making option. While some pre-defined are shown to the user, we always include the user’s possibility to add their reasons and enrich the existing knowledge base. Furthermore, such data can be used to expand feedback options displayed to the users in the future.
6. Decision-Making Options Recommendation
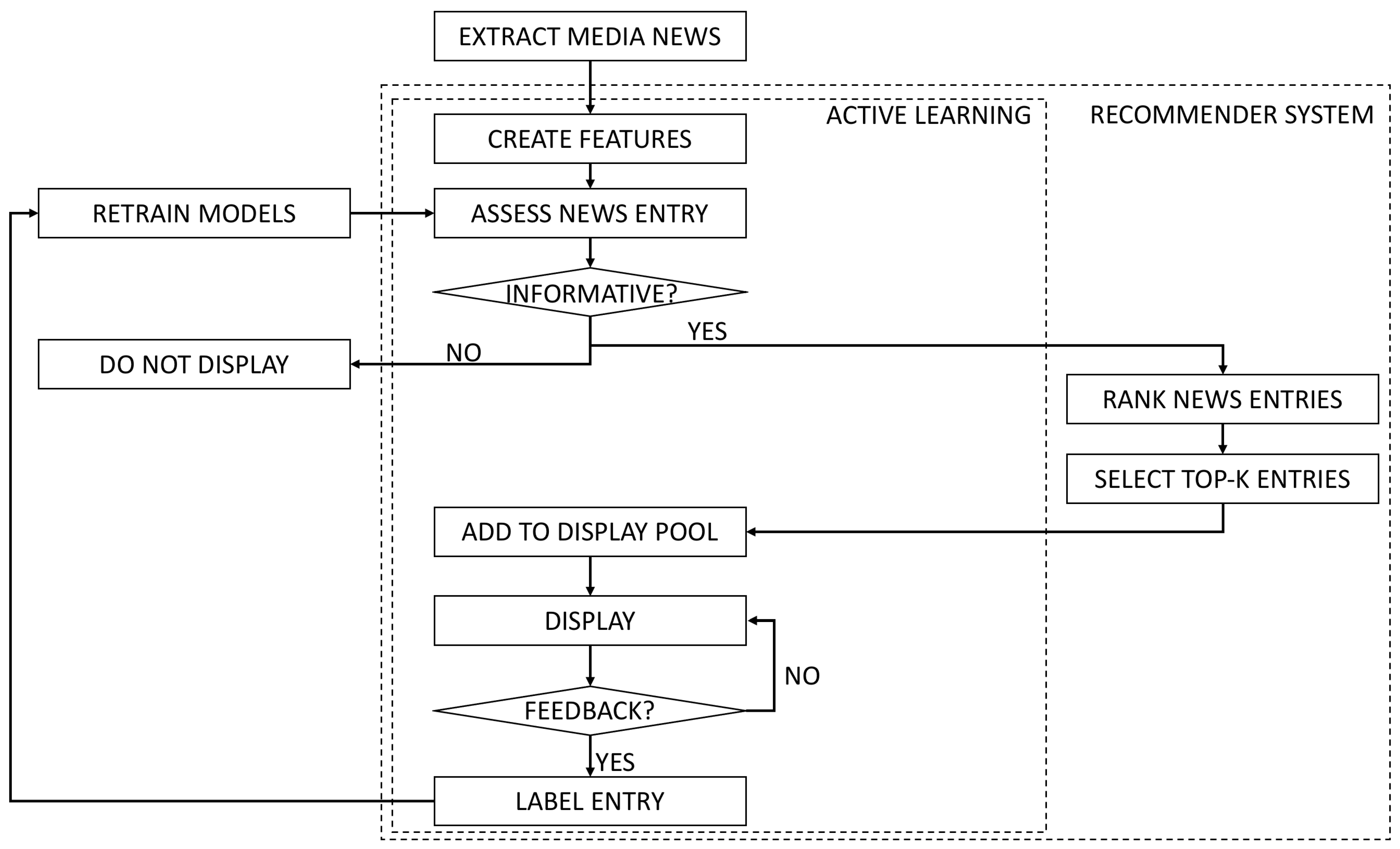
7. Active Learning for Media News Categorization and Recommendation
7.1. Active Learning Experiments
7.2. Results
7.2.1. Evaluating the Classification Baselines
7.2.2. Evaluating the Classification Performance of AL Strategies
7.2.3. Evaluating the Recommendation Performance of AL Strategies
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AL | Active Learning |
| ANN | Artificial Neural Networks Neural Networks |
| ARIMA | AutoRegressive Integrated Moving Average |
| ARMA | AutoRegressive Moving Average |
| ROC AUC | Area Under the Receiver Operating Characteristic Curve |
| BoW | Bag-Of-Words |
| CPS | Cyber-Physical System |
| DT | Digital Twin |
| ERP | Enterprise Resource Planning Resource Planning |
| LIME | Local Interpretable Model-agnostic Explanations |
| MAP | Mean Average Precision |
| MES | Manufacturing Execution System |
| MLR | Multiple Linear Regression |
| SVM | Support Vector Machine |
| TF-IDF | Term Frequency-Inverse Document Frequency |
| USE | Universal Sentence Encoder |
| XAI | Explainable Artificial Intelligence |
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Model | Representation | A | B | C | D |
|---|---|---|---|---|---|
| LR | TF-IDF | 0.7762 | 0.7954 | 0.9533 | 0.8698 |
| RoBERTa | 0.8301 | 0.8903 | 0.9308 | 0.9109 | |
| USE | 0.8556 | 0.8199 | 0.9795 | 0.8931 | |
| SVM | TF-IDF | 0.7805 | 0.7998 | 0.9336 | 0.8576 |
| RoBERTa | 0.8375 | 0.8795 | 0.9280 | 0.8822 | |
| USE | 0.8574 | 0.8571 | 0.9789 | 0.8969 | |
| RF | TF-IDF | 0.7965 | 0.7268 | 0.9268 | 0.8221 |
| RoBERTa | 0.8246 | 0.8607 | 0.8514 | 0.7535 | |
| USE | 0.8765 | 0.8226 | 0.9808 | 0.8177 | |
| PA | Hashing | 0.7598 | 0.7642 | 0.9087 | 0.8027 |
| RoBERTa | 0.7871 | 0.8164 | 0.8870 | 0.8727 | |
| USE | 0.8409 | 0.8291 | 0.9759 | 0.8881 |
| Random | Uncertain | Certain | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Representation | A | B | C | D | A | B | C | D | A | B | C | D |
| LR | TF-IDF | 0.8416 | 0.8763 | 0.9692 | 0.8835 | 0.8391 | 0.8564 | 0.9777 | 0.9019 | 0.8377 | 0.8613 | 0.9702 | 0.8716 |
| RoBERTa | 0.8638 | 0.9015 | 0.9527 | 0.9114 | 0.8209 | 0.8754 | 0.9655 | 0.9208 | 0.8579 | 0.8957 | 0.9494 | 0.9105 | |
| USE | 0.8545 | 0.8655 | 0.9812 | 0.8996 | 0.8595 | 0.8697 | 0.9818 | 0.9257 | 0.8500 | 0.8726 | 0.9805 | 0.8925 | |
| SVM | TF-IDF | 0.8353 | 0.8653 | 0.9722 | 0.8703 | 0.8264 | 0.8629 | 0.9694 | 0.9043 | 0.8305 | 0.8677 | 0.9755 | 0.8719 |
| RoBERTa | 0.8348 | 0.8609 | 0.9453 | 0.8935 | 0.8035 | 0.8747 | 0.9455 | 0.8552 | 0.8400 | 0.8732 | 0.9395 | 0.8919 | |
| USE | 0.8783 | 0.8936 | 0.9837 | 0.9023 | 0.8803 | 0.8957 | 0.9801 | 0.9195 | 0.8827 | 0.8924 | 0.9808 | 0.8960 | |
| RF | TF-IDF | 0.8491 | 0.8132 | 0.9414 | 0.8313 | 0.8332 | 0.8199 | 0.9642 | 0.8553 | 0.8553 | 0.8142 | 0.9544 | 0.8374 |
| RoBERTa | 0.8637 | 0.8860 | 0.8816 | 0.7511 | 0.8828 | 0.8857 | 0.9038 | 0.8230 | 0.8266 | 0.8807 | 0.8323 | 0.7552 | |
| USE | 0.9185 | 0.8728 | 0.9852 | 0.8356 | 0.9060 | 0.8753 | 0.9885 | 0.8743 | 0.9129 | 0.8733 | 0.9797 | 0.8042 | |
| PA | Hashing | 0.8058 | 0.8283 | 0.9726 | 0.8146 | 0.8588 | 0.8449 | 0.9754 | 0.8659 | 0.8157 | 0.8512 | 0.9535 | 0.8112 |
| RoBERTa | 0.8726 | 0.8522 | 0.9115 | 0.9025 | 0.8846 | 0.8534 | 0.9278 | 0.9103 | 0.8814 | 0.8541 | 0.8875 | 0.8918 | |
| USE | 0.9138 | 0.8698 | 0.9770 | 0.8871 | 0.9158 | 0.8718 | 0.9872 | 0.9145 | 0.8987 | 0.8774 | 0.9727 | 0.8857 | |
| Positive Uncertain | Positive Certain | Positive Certain and Uncertain | |||||||||||
| Model | Representation | A | B | C | D | A | B | C | D | A | B | C | D |
| LR | TF-IDF | 0.7730 | 0.8311 | 0.9442 | 0.8644 | 0.7894 | 0.8311 | 0.9442 | 0.8661 | 0.8246 | 0.8609 | 0.9774 | 0.9022 |
| RoBERTa | 0.8076 | 0.8793 | 0.9285 | 0.9191 | 0.8047 | 0.8899 | 0.9305 | 0.9192 | 0.8181 | 0.8978 | 0.9657 | 0.9235 | |
| USE | 0.8308 | 0.8466 | 0.9685 | 0.9090 | 0.8161 | 0.8477 | 0.9685 | 0.9086 | 0.8410 | 0.8677 | 0.9826 | 0.9260 | |
| SVM | TF-IDF | 0.7956 | 0.8031 | 0.9536 | 0.8712 | 0.7352 | 0.8457 | 0.9536 | 0.8713 | 0.8220 | 0.8657 | 0.9688 | 0.8956 |
| RoBERTa | 0.7851 | 0.8669 | 0.9087 | 0.8728 | 0.7768 | 0.8716 | 0.9136 | 0.8670 | 0.8270 | 0.8704 | 0.9624 | 0.8585 | |
| USE | 0.8462 | 0.8700 | 0.9626 | 0.9011 | 0.8465 | 0.8781 | 0.9626 | 0.9011 | 0.8712 | 0.8959 | 0.9838 | 0.9179 | |
| RF | TF-IDF | 0.7998 | 0.7849 | 0.9167 | 0.8327 | 0.7917 | 0.7869 | 0.9476 | 0.8260 | 0.8182 | 0.8253 | 0.9707 | 0.8586 |
| RoBERTa | 0.8430 | 0.8725 | 0.8779 | 0.8133 | 0.8455 | 0.8331 | 0.8876 | 0.7850 | 0.8545 | 0.8861 | 0.9029 | 0.8351 | |
| USE | 0.8912 | 0.8663 | 0.9861 | 0.8403 | 0.8989 | 0.8573 | 0.9842 | 0.8677 | 0.9180 | 0.8765 | 0.9863 | 0.8507 | |
| PA | Hashing | 0.7944 | 0.8028 | 0.9325 | 0.8011 | 0.7682 | 0.7713 | 0.9424 | 0.8044 | 0.8289 | 0.8346 | 0.9767 | 0.8569 |
| RoBERTa | 0.7801 | 0.8164 | 0.8870 | 0.8727 | 0.7782 | 0.8164 | 0.8870 | 0.8727 | 0.8839 | 0.8559 | 0.9339 | 0.9126 | |
| USE | 0.8380 | 0.8281 | 0.9749 | 0.8827 | 0.7928 | 0.8290 | 0.9675 | 0.8731 | 0.9173 | 0.8802 | 0.9832 | 0.9033 | |
| Alpha Trade-Off | Alpha Trade-Off | Alpha Trade-Off | |||||||||||
| Model | Representation | A | B | C | D | A | B | C | D | A | B | C | D |
| LR | TF-IDF | 0.8363 | 0.8791 | 0.9773 | 0.8888 | 0.8303 | 0.8653 | 0.9864 | 0.8766 | 0.8150 | 0.8609 | 0.9773 | 0.9027 |
| RoBERTa | 0.8341 | 0.8973 | 0.9616 | 0.9171 | 0.8303 | 0.8969 | 0.9672 | 0.9134 | 0.8210 | 0.8978 | 0.9658 | 0.9251 | |
| USE | 0.8503 | 0.8644 | 0.9819 | 0.9115 | 0.8480 | 0.8707 | 0.9800 | 0.9048 | 0.8421 | 0.8677 | 0.9813 | 0.9260 | |
| SVM | TF-IDF | 0.8405 | 0.8609 | 0.9627 | 0.8710 | 0.8353 | 0.8644 | 0.9762 | 0.8740 | 0.8324 | 0.8657 | 0.9533 | 0.8969 |
| RoBERTa | 0.8014 | 0.8698 | 0.9570 | 0.8350 | 0.7992 | 0.8688 | 0.9630 | 0.8821 | 0.7770 | 0.8704 | 0.9632 | 0.8252 | |
| USE | 0.8873 | 0.8969 | 0.9803 | 0.9000 | 0.8680 | 0.8978 | 0.9789 | 0.9029 | 0.8702 | 0.8959 | 0.9827 | 0.9179 | |
| RF | TF-IDF | 0.8556 | 0.8295 | 0.9575 | 0.8403 | 0.8374 | 0.8274 | 0.9477 | 0.8347 | 0.8124 | 0.8373 | 0.9688 | 0.8480 |
| RoBERTa | 0.8662 | 0.8749 | 0.8679 | 0.7646 | 0.8811 | 0.8792 | 0.8844 | 0.7860 | 0.8777 | 0.8838 | 0.9049 | 0.8226 | |
| USE | 0.9147 | 0.8747 | 0.9751 | 0.8275 | 0.9003 | 0.8719 | 0.9830 | 0.8366 | 0.9248 | 0.8803 | 0.9872 | 0.8559 | |
| PA | Hashing | 0.8655 | 0.8401 | 0.9743 | 0.8445 | 0.8218 | 0.8555 | 0.9719 | 0.8534 | 0.8319 | 0.8426 | 0.9735 | 0.8453 |
| RoBERTa | 0.8976 | 0.8606 | 0.8998 | 0.9025 | 0.8991 | 0.8552 | 0.9171 | 0.9091 | 0.8929 | 0.8550 | 0.9274 | 0.8963 | |
| USE | 0.9146 | 0.8795 | 0.9780 | 0.8963 | 0.9149 | 0.8821 | 0.9799 | 0.9054 | 0.9106 | 0.8829 | 0.9864 | 0.9221 | |
| Random | Uncertain | Certain | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Representation | A | B | C | D | A | B | C | D | A | B | C | D |
| LR | TF-IDF | 0.2741 | 0.4717 | 0.1265 | 0.0307 | 0.5056 | 0.5227 | 0.5576 | 0.4220 | 0.1791 | 0.4219 | 0.0274 | 0.0103 |
| RoBERTa | 0.2675 | 0.4631 | 0.1005 | 0.0271 | 0.3885 | 0.5212 | 0.4328 | 0.2808 | 0.1623 | 0.4087 | 0.0328 | 0.0101 | |
| USE | 0.2787 | 0.4584 | 0.1062 | 0.0449 | 0.4059 | 0.5235 | 0.5186 | 0.2804 | 0.1676 | 0.4158 | 0.0236 | 0.0106 | |
| SVM | TF-IDF | 0.2699 | 0.4939 | 0.1238 | 0.0312 | 0.5428 | 0.5155 | 0.3572 | 0.1969 | 0.2661 | 0.4084 | 0.0904 | 0.0110 |
| RoBERTa | 0.2799 | 0.4874 | 0.1433 | 0.0349 | 0.3618 | 0.5144 | 0.3313 | 0.2850 | 0.1651 | 0.4308 | 0.0347 | 0.0101 | |
| USE | 0.2694 | 0.4530 | 0.1175 | 0.0298 | 0.3805 | 0.5385 | 0.4531 | 0.2747 | 0.1993 | 0.4227 | 0.0289 | 0.0102 | |
| RF | TF-IDF | 0.2690 | 0.4753 | 0.1283 | 0.0357 | 0.4965 | 0.5687 | 0.5629 | 0.3595 | 0.1285 | 0.3887 | 0.0258 | 0.0102 |
| RoBERTa | 0.2849 | 0.4741 | 0.1309 | 0.0476 | 0.5088 | 0.5468 | 0.4990 | 0.3350 | 0.1390 | 0.4091 | 0.0394 | 0.0131 | |
| USE | 0.2629 | 0.4854 | 0.1193 | 0.0286 | 0.5132 | 0.5476 | 0.5985 | 0.3538 | 0.1203 | 0.4109 | 0.0283 | 0.0114 | |
| PA | Hashing | 0.2618 | 0.4648 | 0.1224 | 0.0242 | 0.4331 | 0.5284 | 0.4656 | 0.2960 | 0.2688 | 0.4561 | 0.0814 | 0.0125 |
| RoBERTa | 0.2884 | 0.4988 | 0.1527 | 0.0331 | 0.4480 | 0.5329 | 0.4759 | 0.1822 | 0.2525 | 0.4592 | 0.0618 | 0.0102 | |
| USE | 0.2766 | 0.5001 | 0.1465 | 0.0252 | 0.4116 | 0.5411 | 0.4092 | 0.2328 | 0.2229 | 0.4278 | 0.0652 | 0.0117 | |
| Positive Uncertain | Positive Certain | Positive Certain and Uncertain | |||||||||||
| Model | Representation | A | B | C | D | A | B | C | D | A | B | C | D |
| LR | TF-IDF | 0.5575 | 0.6555 | 0.9191 | 0.6422 | 0.6145 | 0.7174 | 0.9240 | 0.6379 | 0.6449 | 0.6672 | 0.6296 | 0.4259 |
| RoBERTa | 0.5554 | 0.6876 | 0.7333 | 0.3689 | 0.6448 | 0.7196 | 0.7862 | 0.3922 | 0.6140 | 0.6660 | 0.6093 | 0.3900 | |
| USE | 0.5642 | 0.6423 | 0.8603 | 0.3739 | 0.6655 | 0.7233 | 0.8978 | 0.4124 | 0.6584 | 0.6942 | 0.6312 | 0.3249 | |
| SVM | TF-IDF | 0.5796 | 0.6649 | 0.9378 | 0.9355 | 0.6636 | 0.7012 | 0.9383 | 0.9355 | 0.6325 | 0.6679 | 0.6250 | 0.3826 |
| RoBERTa | 0.5288 | 0.7256 | 0.7001 | 0.4127 | 0.5900 | 0.7363 | 0.7493 | 0.4423 | 0.6012 | 0.6610 | 0.5887 | 0.3730 | |
| USE | 0.6066 | 0.7058 | 0.8721 | 0.5820 | 0.7129 | 0.7610 | 0.8933 | 0.5675 | 0.6912 | 0.7059 | 0.6408 | 0.4162 | |
| RF | TF-IDF | 0.5618 | 0.6373 | 0.8929 | 0.6623 | 0.6742 | 0.6837 | 0.9403 | 0.6226 | 0.6710 | 0.6672 | 0.6260 | 0.3731 |
| RoBERTa | 0.6160 | 0.6476 | 0.8878 | 1.0000 | 0.6675 | 0.7439 | 0.9057 | 1.0000 | 0.6807 | 0.6786 | 0.5192 | 0.3370 | |
| USE | 0.6156 | 0.6565 | 0.9059 | 1.0000 | 0.7528 | 0.7417 | 0.9406 | 1.0000 | 0.7348 | 0.6867 | 0.6134 | 0.3621 | |
| PA | Hashing | 0.6255 | 0.6978 | 0.7151 | 0.4966 | 0.8186 | 0.7727 | 0.8466 | 0.7378 | 0.6198 | 0.6397 | 0.6121 | 0.3572 |
| RoBERTa | 0.4842 | 1.0000 | 1.0000 | 1.0000 | 0.7418 | 1.0000 | 1.0000 | 1.0000 | 0.5650 | 0.6496 | 0.5384 | 0.2268 | |
| USE | 0.6392 | 0.6715 | 0.8088 | 0.5461 | 0.7482 | 0.8585 | 0.8948 | 0.6425 | 0.6649 | 0.6762 | 0.6083 | 0.2846 | |
| Alpha Trade-Off | Alpha Trade-Off | Alpha Trade-Off | |||||||||||
| Model | Representation | A | B | C | D | A | B | C | D | A | B | C | D |
| LR | TF-IDF | 0.3076 | 0.6420 | 0.0794 | 0.0192 | 0.5520 | 0.6495 | 0.1073 | 0.0237 | 0.6691 | 0.6671 | 0.6317 | 0.4211 |
| RoBERTa | 0.3177 | 0.6467 | 0.0874 | 0.0206 | 0.5645 | 0.6620 | 0.1036 | 0.0232 | 0.6767 | 0.6665 | 0.6103 | 0.3914 | |
| USE | 0.3145 | 0.6538 | 0.0857 | 0.0205 | 0.5707 | 0.6871 | 0.1143 | 0.0269 | 0.6769 | 0.6976 | 0.6317 | 0.3257 | |
| SVM | TF-IDF | 0.3246 | 0.6337 | 0.0837 | 0.0224 | 0.5351 | 0.6537 | 0.1237 | 0.0199 | 0.6693 | 0.6679 | 0.6269 | 0.4259 |
| RoBERTa | 0.3566 | 0.6388 | 0.0975 | 0.0238 | 0.5546 | 0.6512 | 0.1386 | 0.0291 | 0.6280 | 0.6619 | 0.5907 | 0.3820 | |
| USE | 0.3319 | 0.6678 | 0.0872 | 0.0188 | 0.5965 | 0.6985 | 0.1377 | 0.0248 | 0.7341 | 0.7087 | 0.6412 | 0.4462 | |
| RF | TF-IDF | 0.3226 | 0.6422 | 0.0931 | 0.0188 | 0.5577 | 0.6589 | 0.1211 | 0.0401 | 0.6856 | 0.6559 | 0.6279 | 0.3605 |
| RoBERTa | 0.3296 | 0.6450 | 0.0973 | 0.0242 | 0.5777 | 0.6664 | 0.1366 | 0.0247 | 0.7076 | 0.6649 | 0.5212 | 0.3458 | |
| USE | 0.3095 | 0.6580 | 0.0970 | 0.0223 | 0.6038 | 0.6818 | 0.1291 | 0.0282 | 0.7765 | 0.6915 | 0.6282 | 0.3444 | |
| PA | Hashing | 0.2958 | 0.6268 | 0.0881 | 0.0232 | 0.4834 | 0.6349 | 0.1240 | 0.0327 | 0.6687 | 0.6500 | 0.6148 | 0.3643 |
| RoBERTa | 0.3397 | 0.6272 | 0.1169 | 0.0326 | 0.4554 | 0.6401 | 0.1500 | 0.0358 | 0.6241 | 0.6469 | 0.5343 | 0.2430 | |
| USE | 0.3355 | 0.6446 | 0.0857 | 0.0200 | 0.5530 | 0.6685 | 0.1321 | 0.0268 | 0.7080 | 0.6765 | 0.6154 | 0.2923 | |
| Random | Uncertain | Certain | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | Representation | A | B | C | D | A | B | C | D | A | B | C | D |
| LR | TF-IDF | 0.5221 | 0.9610 | 0.4113 | 0.0659 | 0.7179 | 0.9804 | 0.9161 | 0.6631 | 0.4300 | 0.9472 | 0.1337 | 0.0114 |
| RoBERTa | 0.5267 | 0.9611 | 0.3750 | 0.0755 | 0.6448 | 0.9778 | 0.8304 | 0.5545 | 0.4016 | 0.9576 | 0.1657 | 0.0091 | |
| USE | 0.5453 | 0.9670 | 0.4424 | 0.0909 | 0.6692 | 0.9759 | 0.9546 | 0.5790 | 0.4285 | 0.9633 | 0.1111 | 0.0110 | |
| SVM | TF-IDF | 0.5517 | 0.9642 | 0.4943 | 0.0734 | 0.7383 | 0.9767 | 0.7693 | 0.4523 | 0.4970 | 0.9549 | 0.2469 | 0.0139 |
| RoBERTa | 0.5537 | 0.9669 | 0.4837 | 0.0905 | 0.6217 | 0.9893 | 0.8141 | 0.5252 | 0.3926 | 0.9569 | 0.1659 | 0.0091 | |
| USE | 0.5270 | 0.9699 | 0.4430 | 0.0722 | 0.6283 | 0.9795 | 0.9022 | 0.5392 | 0.4495 | 0.9594 | 0.1317 | 0.0101 | |
| RF | TF-IDF | 0.5341 | 0.9738 | 0.4774 | 0.0815 | 0.7215 | 0.9841 | 0.9465 | 0.5653 | 0.3565 | 0.9550 | 0.1287 | 0.0101 |
| RoBERTa | 0.5540 | 0.9721 | 0.4844 | 0.1146 | 0.7582 | 0.9778 | 0.8457 | 0.5009 | 0.3662 | 0.9572 | 0.1796 | 0.0139 | |
| USE | 0.5293 | 0.9551 | 0.4781 | 0.0644 | 0.7494 | 0.9845 | 0.9589 | 0.5345 | 0.3333 | 0.9482 | 0.1444 | 0.0205 | |
| PA | Hashing | 0.5270 | 0.9677 | 0.4387 | 0.0582 | 0.6745 | 0.9845 | 0.7987 | 0.5251 | 0.4540 | 0.9496 | 0.2513 | 0.0231 |
| RoBERTa | 0.5392 | 0.9732 | 0.5074 | 0.0606 | 0.6731 | 0.9886 | 0.8550 | 0.3830 | 0.4200 | 0.9591 | 0.2074 | 0.0104 | |
| USE | 0.5401 | 0.9671 | 0.4872 | 0.0771 | 0.6741 | 0.9797 | 0.8459 | 0.5198 | 0.4225 | 0.9431 | 0.2537 | 0.0141 | |
| Positive Uncertain | Positive Certain | Positive Certain and Uncertain | |||||||||||
| Model | Representation | A | B | C | D | A | B | C | D | A | B | C | D |
| LR | TF-IDF | 0.6374 | 0.7670 | 0.4826 | 0.2527 | 0.6550 | 0.7670 | 0.4826 | 0.2565 | 0.8142 | 0.9910 | 0.9650 | 0.6678 |
| RoBERTa | 0.6254 | 0.7617 | 0.6415 | 0.1638 | 0.6451 | 0.7544 | 0.6426 | 0.1638 | 0.7988 | 0.9942 | 0.9531 | 0.6057 | |
| USE | 0.7107 | 0.7544 | 0.6419 | 0.1787 | 0.7307 | 0.7507 | 0.6419 | 0.1805 | 0.8258 | 0.9929 | 0.9885 | 0.6036 | |
| SVM | TF-IDF | 0.6392 | 0.7235 | 0.4333 | 0.2545 | 0.6776 | 0.6928 | 0.4333 | 0.2545 | 0.7972 | 0.9929 | 0.9506 | 0.6395 |
| RoBERTa | 0.6173 | 0.7966 | 0.6665 | 0.2538 | 0.6002 | 0.7948 | 0.6685 | 0.2538 | 0.7718 | 0.9927 | 0.9483 | 0.5771 | |
| USE | 0.7167 | 0.8332 | 0.5974 | 0.3245 | 0.7253 | 0.8167 | 0.5974 | 0.3245 | 0.8373 | 0.9986 | 0.9744 | 0.6509 | |
| RF | TF-IDF | 0.6772 | 0.7300 | 0.4565 | 0.2807 | 0.7207 | 0.7241 | 0.4683 | 0.2647 | 0.8415 | 0.9869 | 0.9633 | 0.5781 |
| RoBERTa | 0.7239 | 0.7688 | 0.4117 | 0.2545 | 0.6999 | 0.7615 | 0.4356 | 0.2545 | 0.8381 | 0.9896 | 0.8493 | 0.5066 | |
| USE | 0.7436 | 0.8180 | 0.4800 | 0.2545 | 0.8001 | 0.8344 | 0.4194 | 0.2561 | 0.8628 | 0.9942 | 0.9681 | 0.5401 | |
| PA | Hashing | 0.2468 | 0.1707 | 0.4556 | 0.0977 | 0.2886 | 0.1674 | 0.4659 | 0.1368 | 0.7812 | 0.9883 | 0.9507 | 0.5838 |
| RoBERTa | 0.0257 | 0.0000 | 0.0000 | 0.0000 | 0.0125 | 0.0000 | 0.0000 | 0.0000 | 0.7266 | 0.9942 | 0.9087 | 0.4460 | |
| USE | 0.2719 | 0.1912 | 0.5193 | 0.0898 | 0.2716 | 0.1735 | 0.3776 | 0.0770 | 0.8222 | 0.9929 | 0.9894 | 0.5453 | |
| Alpha Trade-Off | Alpha Trade-Off | Alpha Trade-Off | |||||||||||
| Model | Representation | A | B | C | D | A | B | C | D | A | B | C | D |
| LR | TF-IDF | 0.4041 | 0.9464 | 0.1189 | 0.0243 | 0.6982 | 0.9722 | 0.1676 | 0.0355 | 0.8444 | 0.9910 | 0.9661 | 0.6668 |
| RoBERTa | 0.4108 | 0.9488 | 0.1389 | 0.0195 | 0.7277 | 0.9838 | 0.1654 | 0.0381 | 0.8431 | 0.9942 | 0.9554 | 0.6111 | |
| USE | 0.4133 | 0.9455 | 0.1139 | 0.0285 | 0.7243 | 0.9852 | 0.1843 | 0.0390 | 0.8541 | 0.9951 | 0.9896 | 0.6036 | |
| SVM | TF-IDF | 0.4336 | 0.9491 | 0.1309 | 0.0254 | 0.6729 | 0.9721 | 0.2031 | 0.0290 | 0.8309 | 0.9929 | 0.9494 | 0.6894 |
| RoBERTa | 0.4720 | 0.9630 | 0.1606 | 0.0261 | 0.7212 | 0.9844 | 0.2548 | 0.0636 | 0.8192 | 0.9949 | 0.9406 | 0.5789 | |
| USE | 0.4122 | 0.9520 | 0.1185 | 0.0200 | 0.7272 | 0.9879 | 0.2372 | 0.0414 | 0.8720 | 0.9986 | 0.9767 | 0.6820 | |
| RF | TF-IDF | 0.4241 | 0.9536 | 0.1396 | 0.0272 | 0.6892 | 0.9784 | 0.2241 | 0.0823 | 0.8487 | 0.9893 | 0.9569 | 0.5325 |
| RoBERTa | 0.4266 | 0.9577 | 0.2072 | 0.0446 | 0.7219 | 0.9787 | 0.3215 | 0.0634 | 0.8732 | 0.9891 | 0.8707 | 0.5271 | |
| USE | 0.3888 | 0.9498 | 0.1444 | 0.0352 | 0.7245 | 0.9813 | 0.2122 | 0.0530 | 0.9055 | 0.9907 | 0.9683 | 0.5246 | |
| PA | Hashing | 0.4179 | 0.9511 | 0.1467 | 0.0369 | 0.6502 | 0.9668 | 0.2296 | 0.0455 | 0.8353 | 0.9883 | 0.9541 | 0.5995 |
| RoBERTa | 0.4916 | 0.9499 | 0.2093 | 0.0529 | 0.6558 | 0.9822 | 0.3470 | 0.0864 | 0.8039 | 0.9942 | 0.9124 | 0.4671 | |
| USE | 0.4355 | 0.9455 | 0.1139 | 0.0281 | 0.6929 | 0.9812 | 0.2193 | 0.0429 | 0.8665 | 0.9929 | 0.9907 | 0.5555 | |
References
- Benbarrad, T.; Salhaoui, M.; Kenitar, S.B.; Arioua, M. Intelligent machine vision model for defective product inspection based on machine learning. J. Sens. Actuator Netw. 2021, 10, 7. [Google Scholar] [CrossRef]
- Raut, R.D.; Gotmare, A.; Narkhede, B.E.; Govindarajan, U.H.; Bokade, S.U. Enabling technologies for Industry 4.0 manufacturing and supply chain: Concepts, current status, and adoption challenges. IEEE Eng. Manag. Rev. 2020, 48, 83–102. [Google Scholar] [CrossRef]
- Lee, E.A. Cyber physical systems: Design challenges. In Proceedings of the 2008 11th IEEE International Symposium on Object and Component-Oriented Real-Time Distributed Computing (ISORC), Orlando, FL, USA, 5–7 May 2008; pp. 363–369. [Google Scholar]
- Rajkumar, R.; Lee, I.; Sha, L.; Stankovic, J. Cyber-physical systems: The next computing revolution. In Proceedings of the Design Automation Conference, Anaheim, CA, USA, 13–18 July 2010; pp. 731–736. [Google Scholar]
- Rosen, R.; Von Wichert, G.; Lo, G.; Bettenhausen, K.D. About the importance of autonomy and digital twins for the future of manufacturing. IFAC-PapersOnLine 2015, 48, 567–572. [Google Scholar] [CrossRef]
- Grieves, M.; Vickers, J. Digital twin: Mitigating unpredictable, undesirable emergent behavior in complex systems. In Transdisciplinary Perspectives on Complex Systems; Springer: Berlin/Heidelberg, Germany, 2017; pp. 85–113. [Google Scholar]
- Grieves, M.W. Virtually Intelligent Product Systems: Digital and Physical Twins; American Institute of Aeronautics and Astronautics: Reston, VA, USA, 2019; pp. 175–200. [Google Scholar]
- Grangel-González, I. A Knowledge Graph Based Integration Approach for Industry 4.0. Ph.D. Thesis, Universitäts-und Landesbibliothek Bonn, Bonn, Germany, 2019. [Google Scholar]
- Mogos, M.F.; Eleftheriadis, R.J.; Myklebust, O. Enablers and inhibitors of Industry 4.0: Results from a survey of industrial companies in Norway. Procedia Cirp 2019, 81, 624–629. [Google Scholar] [CrossRef]
- Tao, F.; Qi, Q.; Liu, A.; Kusiak, A. Data-driven smart manufacturing. J. Manuf. Syst. 2018, 48, 157–169. [Google Scholar] [CrossRef]
- Preece, A.; Webberley, W.; Braines, D.; Hu, N.; La Porta, T.; Zaroukian, E.; Bakdash, J. SHERLOCK: Simple Human Experiments Regarding Locally Observed Collective Knowledge; Technical Report; US Army Research Laboratory Aberdeen Proving Ground: Aberdeen Proving Ground, MD, USA, 2015. [Google Scholar]
- Bradeško, L.; Witbrock, M.; Starc, J.; Herga, Z.; Grobelnik, M.; Mladenić, D. Curious Cat–Mobile, Context-Aware Conversational Crowdsourcing Knowledge Acquisition. ACM Trans. Inf. Syst. (TOIS) 2017, 35, 1–46. [Google Scholar] [CrossRef]
- Settles, B. Active Learning Literature Survey; University of Wisconsin-Madison, Department of Computer Sciences: Madison, WI, USA, 2009. [Google Scholar]
- Elahi, M.; Ricci, F.; Rubens, N. A survey of active learning in collaborative filtering recommender systems. Comput. Sci. Rev. 2016, 20, 29–50. [Google Scholar] [CrossRef]
- Konstan, J.A.; Riedl, J. Recommender systems: From algorithms to user experience. User Model. User-Adapt. Interact. 2012, 22, 101–123. [Google Scholar] [CrossRef] [Green Version]
- Gualtieri, M. Best practices in user experience (UX) design. In Design Compelling User Experiences to Wow Your Customers; Forrester Research, Inc.: Cambridge, MA, USA, 2009; pp. 1–17. [Google Scholar]
- Oard, D.W.; Kim, J. Implicit feedback for recommender systems. In Proceedings of the AAAI Workshop on Recommender Systems, 1998; Volume 83, pp. 81–83. Available online: https://www.aaai.org/Papers/Workshops/1998/WS-98-08/WS98-08-021.pdf (accessed on 11 November 2021).
- Hu, Y.; Koren, Y.; Volinsky, C. Collaborative filtering for implicit feedback datasets. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 263–272. [Google Scholar]
- Zhao, Q.; Harper, F.M.; Adomavicius, G.; Konstan, J.A. Explicit or implicit feedback? Engagement or satisfaction? A field experiment on machine-learning-based recommender systems. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing, Pau, France, 9–13 April 2018; pp. 1331–1340. [Google Scholar]
- Wang, W.; Feng, F.; He, X.; Nie, L.; Chua, T.S. Denoising implicit feedback for recommendation. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Jerusalem, Israel, 8–12 March 2021; pp. 373–381. [Google Scholar]
- Yang, S.C.; Rank, C.; Whritner, J.A.; Nasraoui, O.; Shafto, P. Unifying Recommendation and Active Learning for Information Filtering and Recommender Systems. 2020. Available online: https://psyarxiv.com/jqa83/download?format=pdf (accessed on 11 November 2021).
- Zajec, P.; Rožanec, J.M.; Novalija, I.; Fortuna, B.; Mladenić, D.; Kenda, K. Towards Active Learning Based Smart Assistant for Manufacturing. Advances in Production Management Systems. In Artificial Intelligence for Sustainable and Resilient Production Systems; Dolgui, A., Bernard, A., Lemoine, D., von Cieminski, G., Romero, D., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 295–302. [Google Scholar]
- Rožanec, J.M.; Kažič, B.; Škrjanc, M.; Fortuna, B.; Mladenić, D. Automotive OEM Demand Forecasting: A Comparative Study of Forecasting Algorithms and Strategies. Appl. Sci. 2021, 11, 6787. [Google Scholar] [CrossRef]
- Rožanec, J.M.; Mladenić, D. Reframing demand forecasting: A two-fold approach for lumpy and intermittent demand. arXiv 2021, arXiv:2103.13812. [Google Scholar]
- Rožanec, J. Explainable Demand Forecasting: A Data Mining Goldmine. In Proceedings of the Web Conference 2021 (WWW ’21 Companion), ALjubljana, Slovenia, 19–23 April 2021. [Google Scholar] [CrossRef]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]
- Robertson, S. A new interpretation of average precision. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Singapore, 20–24 July 2008; pp. 689–690. [Google Scholar]
- Schröder, G.; Thiele, M.; Lehner, W. Setting goals and choosing metrics for recommender system evaluations. In Proceedings of the UCERSTI2 Workshop at the 5th ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; Volume 23, p. 53. [Google Scholar]
- Williams, T. Stock control with sporadic and slow-moving demand. J. Oper. Res. Soc. 1984, 35, 939–948. [Google Scholar] [CrossRef]
- Johnston, F.; Boylan, J.E. Forecasting for items with intermittent demand. J. Oper. Res. Soc. 1996, 47, 113–121. [Google Scholar] [CrossRef]
- Syntetos, A.A.; Boylan, J.E.; Croston, J. On the categorization of demand patterns. J. Oper. Res. Soc. 2005, 56, 495–503. [Google Scholar] [CrossRef]
- Wang, F.K.; Chang, K.K.; Tzeng, C.W. Using adaptive network-based fuzzy inference system to forecast automobile sales. Expert Syst. Appl. 2011, 38, 10587–10593. [Google Scholar] [CrossRef]
- Gao, J.; Xie, Y.; Cui, X.; Yu, H.; Gu, F. Chinese automobile sales forecasting using economic indicators and typical domestic brand automobile sales data: A method based on econometric model. Adv. Mech. Eng. 2018, 10, 1687814017749325. [Google Scholar] [CrossRef] [Green Version]
- Ubaidillah, N.Z. A study of car demand and its interdependency in sarawak. Int. J. Bus. Soc. 2020, 21, 997–1011. [Google Scholar] [CrossRef]
- Dargay, J.; Gately, D. Income’s effect on car and vehicle ownership, worldwide: 1960–2015. Transp. Res. Part A Policy Pract. 1999, 33, 101–138. [Google Scholar] [CrossRef]
- Brühl, B.; Hülsmann, M.; Borscheid, D.; Friedrich, C.M.; Reith, D. A sales forecast model for the german automobile market based on time series analysis and data mining methods. In Proceedings of the Industrial Conference on Data Mining; Springer: Berlin/Heidelberg, Germany, 2009; pp. 146–160. [Google Scholar]
- Vahabi, A.; Hosseininia, S.S.; Alborzi, M. A Sales Forecasting Model in Automotive Industry using Adaptive Neuro-Fuzzy Inference System (Anfis) and Genetic Algorithm (GA). Management 2016, 1, 2. [Google Scholar] [CrossRef] [Green Version]
- Dwivedi, A.; Niranjan, M.; Sahu, K. A business intelligence technique for forecasting the automobile sales using Adaptive Intelligent Systems (ANFIS and ANN). Int. J. Comput. Appl. 2013, 74, 7–13. [Google Scholar] [CrossRef]
- Farahani, D.S.; Momeni, M.; Amiri, N.S. Car sales forecasting using artificial neural networks and analytical hierarchy process. In Proceedings of the DATA ANALYTICS 2016—The Fifth International Conference on Data Analytics, Venice, Italy, 9–13 October 2016; p. 69. [Google Scholar]
- Sharma, R.; Sinha, A.K. Sales forecast of an automobile industry. Int. J. Comput. Appl. 2012, 53, 25–28. [Google Scholar] [CrossRef]
- Henkelmann, R. A Deep Learning Based Approach for Automotive Spare Part Demand Forecasting. Available online: https://www.is.ovgu.de/is_media/Master+und+Bachelor_Arbeiten/MasterThesis_RobbyHenkelmann-download-1-p-4746.pdf (accessed on 11 November 2021).
- Chandriah, K.K.; Naraganahalli, R.V. RNN/LSTM with modified Adam optimizer in deep learning approach for automobile spare parts demand forecasting. In Multimedia Tools and Applications; Springer: Berlin/Heidelberg, Germany, 2021; pp. 1–15. [Google Scholar]
- Matsumoto, M.; Komatsu, S. Demand forecasting for production planning in remanufacturing. Int. J. Adv. Manuf. Technol. 2015, 79, 161–175. [Google Scholar] [CrossRef]
- Hanggara, F.D. Forecasting Car Demand in Indonesia with Moving Average Method. J. Eng. Sci. Technol. Manag. (JES-TM) 2021, 1, 1–6. [Google Scholar]
- Biran, O.; McKeown, K.R. Human-Centric Justification of Machine Learning Predictions. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; Volume 2017, pp. 1461–1467. [Google Scholar]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, J.J.; Monteiro, M. The human-AI relationship in decision-making: AI explanation to support people on justifying their decisions. arXiv 2021, arXiv:2102.05460. [Google Scholar]
- Büchi, G.; Cugno, M.; Castagnoli, R. Smart factory performance and Industry 4.0. Technol. Forecast. Soc. Chang. 2020, 150, 119790. [Google Scholar] [CrossRef]
- Micheler, S.; Goh, Y.M.; Lohse, N. Innovation landscape and challenges of smart technologies and systems—A European perspective. Prod. Manuf. Res. 2019, 7, 503–528. [Google Scholar] [CrossRef] [Green Version]
- Müller, V.C. Deep Opacity Undermines Data Protection and Explainable Artificial Intelligence. Overcoming Opacity in Machine Learning. 2021, p. 18. Available online: https://sites.google.com/view/aisb2020cc/home (accessed on 11 November 2021).
- Chan, L. Explainable AI as Epistemic Representation. Overcoming Opacity in Machine Learning. 2021, p. 7. Available online: https://sites.google.com/view/aisb2020cc/home (accessed on 11 November 2021).
- Samek, W.; Müller, K.R. Towards explainable artificial intelligence. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Springer: Cham, Switzerland, 2019; pp. 5–22. [Google Scholar]
- Henin, C.; Le Métayer, D. A Multi-Layered Approach for Tailored Black-Box Explanations; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.; Lee, S.I. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. In Proceedings of the AAAI, New Orleans, LA, USA, 2–7 February 2018; Volume 18, pp. 1527–1535. [Google Scholar]
- Rüping, S. Learning Interpretable Models. 2006. Available online: https://eldorado.tu-dortmund.de/bitstream/2003/23008/1/dissertation_rueping.pdf (accessed on 11 November 2021).
- Artelt, A.; Hammer, B. On the computation of counterfactual explanations—A survey. arXiv 2019, arXiv:1911.07749. [Google Scholar]
- Mothilal, R.K.; Sharma, A.; Tan, C. Explaining machine learning classifiers through diverse counterfactual explanations. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; pp. 607–617. [Google Scholar]
- Verma, S.; Dickerson, J.; Hines, K. Counterfactual explanations for machine learning: A review. arXiv 2020, arXiv:2010.10596. [Google Scholar]
- Singh, R.; Dourish, P.; Howe, P.; Miller, T.; Sonenberg, L.; Velloso, E.; Vetere, F. Directive explanations for actionable explainability in machine learning applications. arXiv 2021, arXiv:2102.02671. [Google Scholar]
- Hrnjica, B.; Softic, S. Explainable AI in Manufacturing: A Predictive Maintenance Case Study. In Proceedings of the IFIP International Conference on Advances in Production Management Systems; Towards Smart and Digital Manufacturing; Lalic, B., Majstorovic, V., Marjanovic, U., von Cieminski, G., Romero, D., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 66–73. [Google Scholar]
- Rehse, J.R.; Mehdiyev, N.; Fettke, P. Towards explainable process predictions for industry 4.0 in the dfki-smart-lego-factory. KI-Künstliche Intell. 2019, 33, 181–187. [Google Scholar] [CrossRef]
- Goldman, C.V.; Baltaxe, M.; Chakraborty, D.; Arinez, J. Explaining Learning Models in Manufacturing Processes. Procedia Comput. Sci. 2021, 180, 259–268. [Google Scholar] [CrossRef]
- van der Waa, J.; Nieuwburg, E.; Cremers, A.; Neerincx, M. Evaluating XAI: A comparison of rule-based and example-based explanations. Artif. Intell. 2021, 291, 103404. [Google Scholar] [CrossRef]
- Ghai, B.; Liao, Q.V.; Zhang, Y.; Bellamy, R.; Mueller, K. Explainable active learning (xal) toward ai explanations as interfaces for machine teachers. Proc. ACM Hum.-Comput. Interact. 2021, 4, 1–28. [Google Scholar] [CrossRef]
- Tulli, S.; Wallkötter, S.; Paiva, A.; Melo, F.S.; Chetouani, M. Learning from Explanations and Demonstrations: A Pilot Study. In Proceedings of the 2nd Workshop on Interactive Natural Language Technology for Explainable Artificial Intelligence, Dublin, Ireland, 15–18 December 2020; pp. 61–66. [Google Scholar]
- Settles, B. From theories to queries: Active learning in practice. In Proceedings of the Active Learning and Experimental Design Workshop in Conjunction with AISTATS 2010, Sardinia, Italy, 16 May 2010; pp. 1–18. [Google Scholar]
- Lughofer, E. On-line active learning: A new paradigm to improve practical useability of data stream modeling methods. Inf. Sci. 2017, 415, 356–376. [Google Scholar] [CrossRef]
- Zhu, J.J.; Bento, J. Generative adversarial active learning. arXiv 2017, arXiv:1702.07956. [Google Scholar]
- Li, Q.; Peng, H.; Li, J.; Xia, C.; Yang, R.; Sun, L.; Yu, P.S.; He, L. A Survey on Text Classification: From Shallow to Deep Learning. arXiv 2020, arXiv:2008.00364. [Google Scholar]
- Jones, K.S. A Statistical Interpretation of Term Specificity and Its Application in Retrieval. In Document Retrieval Systems; Taylor Graham Publishing: New York, NY, USA, 1988; pp. 132–142. [Google Scholar]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning–Based Text Classification: A Comprehensive Review. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Schröder, C.; Niekler, A. A Survey of Active Learning for Text Classification using Deep Neural Networks. arXiv 2020, arXiv:2008.07267. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Le, Q.V.; Mikolov, T. Distributed Representations of Sentences and Documents. arXiv 2014, arXiv:1405.4053. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.Y.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal Sentence Encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lu, J.; MacNamee, B. Investigating the Effectiveness of Representations Based on Pretrained Transformer-based Language Models in Active Learning for Labelling Text Datasets. arXiv 2020, arXiv:2004.13138. [Google Scholar]
- Kazllarof, V.; Karlos, S.; Kotsiantis, S. Active learning Rotation Forest for multiclass classification. Comput. Intell. 2019, 35, 891–918. [Google Scholar] [CrossRef]
- Liu, Q.; Zhu, Y.; Liu, Z.; Zhang, Y.; Wu, S. Deep Active Learning for Text Classification with Diverse Interpretations. arXiv 2021, arXiv:2108.10687. [Google Scholar]
- Liere, R.; Tadepalli, P. Active Learning with Committees for Text Categorization. In Proceedings of the AAAI/IAAI, Providence, RI, USA, 27–31 July 1997. [Google Scholar]
- Schröder, C.; Niekler, A.; Potthast, M. Uncertainty-based Query Strategies for Active Learning with Transformers. arXiv 2021, arXiv:2107.05687. [Google Scholar]
- Mollas, I.; Bassiliades, N.; Vlahavas, I.; Tsoumakas, G. LionForests: Local interpretation of random forests. arXiv 2019, arXiv:1911.08780. [Google Scholar]
- Sundararajan, M.; Najmi, A. The many Shapley values for model explanation. In Proceedings of the International Conference on Machine Learning, Virtual Event (Online), 13–18 July 2020; pp. 9269–9278. [Google Scholar]
- Bloodgood, M. Support Vector Machine Active Learning Algorithms with Query-by-Committee Versus Closest-to-Hyperplane Selection. In Proceedings of the 2018 IEEE 12th International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 31 January–2 February 2018. [Google Scholar] [CrossRef] [Green Version]
- Leban, G.; Fortuna, B.; Brank, J.; Grobelnik, M. Event registry: Learning about world events from news. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 107–110. [Google Scholar]
- Crammer, K.; Dekel, O.; Keshet, J.; Shalev-Shwartz, S.; Singer, Y. Online Passive-Aggressive Algorithms. J. Mach. Learn. Res. 2006, 7, 551–585. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations; Association for Computational Linguistics: New York, NY, USA, 2020; pp. 38–45. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Wilcoxon, F. Individual comparisons by ranking methods. In Breakthroughs in Statistics; Springer: Berlin/Heidelberg, Germany, 1992; pp. 196–202. [Google Scholar]
- Shivaswamy, P.; Joachims, T. Coactive learning. J. Artif. Intell. Res. 2015, 53, 1–40. [Google Scholar] [CrossRef]



| Strategy | Description |
|---|---|
| Random | Selects the k random instances at each step. |
| Uncertain | Selects k instances with highest uncertainty score at each step. |
| Certain | Selects k instances with lowest uncertainty score, that is, most certain examples. |
| Positive Uncertain | Select at most k instances that were labeled as positive by the classifier and have the highest uncertainty scores. |
| Positive Certain | Select at most k instances that were labeled as positive by the classifier and have the lowest uncertainty scores. |
| Positive Certain and Uncertain | Select at most positive points with lowest and at least points with highest uncertainty score. |
| Alpha Trade-Off | We adapt the strategy proposed by [21] |
| Category | Keywords | # Instances | Missing Data | MEPD |
|---|---|---|---|---|
| (A) Automotive Industry | car sales demand, new car sales, vehicle sales, car demand, automotive industry | 3865 | 10 days | 20 |
| (B) Global Economy | global GDP projection, global economic outlook, economic forecast | 853 | 29 days | 5 |
| (C) Unemployment | unemployment rate, unemployment numbers, unemployment report, employment growth, long-term unemployment | 3801 | 8 days | 22 |
| (D) Logistics | logistics, maritime transport, railroad transport, freight, cargo transport, supply chain | 28,231 | 0 days | 133 |
| A | B | C | D | |
|---|---|---|---|---|
| Initialization set size (# instances) | 607 | 128 | 638 | 4388 |
| Learning set size (# instances) | 3070 | 693 | 2882 | 23,051 |
| Test set size (# instances) | 795 | 160 | 919 | 5180 |
| Ratio of negative instances (all sets) | 69.83% | 65.06% | 92.50% | 97.71% |
| Ratio of positive instances (all sets) | 30.17% | 34.94% | 7.50% | 2.29% |
| Number of AL iterations | 122 | 115 | 122 | 123 |
| Number of possible selected instances (given ) | 1138 | 644 | 1132 | 1205 |
| Model | Representation | A | B | C | D |
|---|---|---|---|---|---|
| LR | TF-IDF | 0.8575 | 0.8592 | 0.9856 | 0.9456 |
| RoBERTa | 0.8788 | 0.8681 | 0.9769 | 0.9297 | |
| USE | 0.8654 | 0.8681 | 0.9875 | 0.9195 | |
| SVM | TF-IDF | 0.8639 | 0.8744 | 0.9846 | 0.9494 |
| RoBERTa | 0.8889 | 0.8702 | 0.9693 | 0.8916 | |
| USE | 0.8828 | 0.8920 | 0.9799 | 0.9314 | |
| RF | TF-IDF | 0.8506 | 0.8345 | 0.9733 | 0.8987 |
| RoBERTa | 0.8720 | 0.8850 | 0.9179 | 0.8235 | |
| USE | 0.9197 | 0.8756 | 0.9854 | 0.8899 | |
| PA | Hashing | 0.8538 | 0.8489 | 0.9880 | 0.9049 |
| TF-IDF | 0.8665 | 0.8480 | 0.9845 | 0.9372 | |
| RoBERTa | 0.8985 | 0.8539 | 0.9365 | 0.9237 | |
| USE | 0.9151 | 0.8789 | 0.9859 | 0.9067 | |
| Fine-tuned RoBERTa | RoBERTa | 0.8854 | 0.9081 | 0.9865 | 0.9531 |
| Strategy | A | B | C | D |
|---|---|---|---|---|
| Random | ||||
| Uncertain | ||||
| Certain | ||||
| Positive uncertain | ||||
| Positive certain | ||||
| Positive certain and uncertain | ||||
| Alpha trade-off | ||||
| Alpha trade-off | ||||
| Alpha trade-off |
| Strategy | Mean Rank | Mean Ratio to Best |
|---|---|---|
| Uncertain | 3.3750 | 0.9561 |
| Positive certain and uncertain | 3.3958 | 0.9548 |
| Alpha trade-off | 3.4792 | 0.9532 |
| Alpha trade-off | 4.2708 | 0.9513 |
| Alpha trade-off | 4.5208 | 0.9502 |
| Random | 5.1042 | 0.9482 |
| Certain | 5.4375 | 0.9444 |
| Positive certain | 7.5417 | 0.9208 |
| Positive uncertain | 7.8750 | 0.9235 |
| Strategy | A | B | C | D |
|---|---|---|---|---|
| Random | ||||
| Uncertain | ||||
| Certain | ||||
| Positive uncertain | ||||
| Positive certain | ||||
| Positive certain and uncertain | ||||
| Alpha trade-off | ||||
| Alpha trade-off | ||||
| Alpha trade-off |
| Strategy | A | B | C | D |
|---|---|---|---|---|
| Random | ||||
| Uncertain | ||||
| Certain | ||||
| Positive uncertain | ||||
| Positive certain | ||||
| Positive certain and uncertain | ||||
| Alpha trade-off | ||||
| Alpha trade-off | ||||
| Alpha trade-off |
| Strategy | Mean Rank | Mean Ratio to Best |
|---|---|---|
| Positive certain | 1.3125 | 0.8000 |
| Alpha trade-off | 2.6250 | 0.6192 |
| Positive uncertain | 3.0000 | 0.7316 |
| Positive certain and uncertain | 3.3542 | 0.6054 |
| Alpha trade-off | 5.6458 | 0.3724 |
| Uncertain | 5.6875 | 0.4615 |
| Alpha trade-off | 7.1875 | 0.2883 |
| Random | 7.2292 | 0.2427 |
| Certain | 8.9583 | 0.1772 |
| Strategy | A | B | C | D |
|---|---|---|---|---|
| Random | ||||
| Uncertain | ||||
| Certain | ||||
| Positive uncertain | ||||
| Positive certain | ||||
| Positive certain and uncertain | ||||
| Alpha trade-off | ||||
| Alpha trade-off | ||||
| Alpha trade-off |
| Strategy | Mean Rank | Mean Ratio to Best |
|---|---|---|
| Alpha trade-off | 1.2083 | 0.9362 |
| Positive certain and uncertain | 1.8333 | 0.9218 |
| Uncertain | 3.2917 | 0.8472 |
| Alpha trade-off | 5.3958 | 0.5155 |
| Random | 5.6250 | 0.5345 |
| Positive certain | 5.9167 | 0.4997 |
| Positive uncertain | 6.2292 | 0.4996 |
| Alpha trade-off | 7.6875 | 0.4039 |
| Certain | 7.8125 | 0.4022 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zajec, P.; Rožanec, J.M.; Trajkova, E.; Novalija, I.; Kenda, K.; Fortuna, B.; Mladenić, D. Help Me Learn! Architecture and Strategies to Combine Recommendations and Active Learning in Manufacturing. Information 2021, 12, 473. https://doi.org/10.3390/info12110473
Zajec P, Rožanec JM, Trajkova E, Novalija I, Kenda K, Fortuna B, Mladenić D. Help Me Learn! Architecture and Strategies to Combine Recommendations and Active Learning in Manufacturing. Information. 2021; 12(11):473. https://doi.org/10.3390/info12110473
Chicago/Turabian StyleZajec, Patrik, Jože M. Rožanec, Elena Trajkova, Inna Novalija, Klemen Kenda, Blaž Fortuna, and Dunja Mladenić. 2021. "Help Me Learn! Architecture and Strategies to Combine Recommendations and Active Learning in Manufacturing" Information 12, no. 11: 473. https://doi.org/10.3390/info12110473
APA StyleZajec, P., Rožanec, J. M., Trajkova, E., Novalija, I., Kenda, K., Fortuna, B., & Mladenić, D. (2021). Help Me Learn! Architecture and Strategies to Combine Recommendations and Active Learning in Manufacturing. Information, 12(11), 473. https://doi.org/10.3390/info12110473