
Exploring Clustering-Based Reinforcement Learning for Personalized Book Recommendation in Digital Library

 ,
,
Abstract
:1. Introduction
- We introduce HRL into the book recommendation task in the digital library, where a basic book recommender is first pre-trained, and then a hierarchical agent is devised to filter out the interactions that might miss leading this recommender.
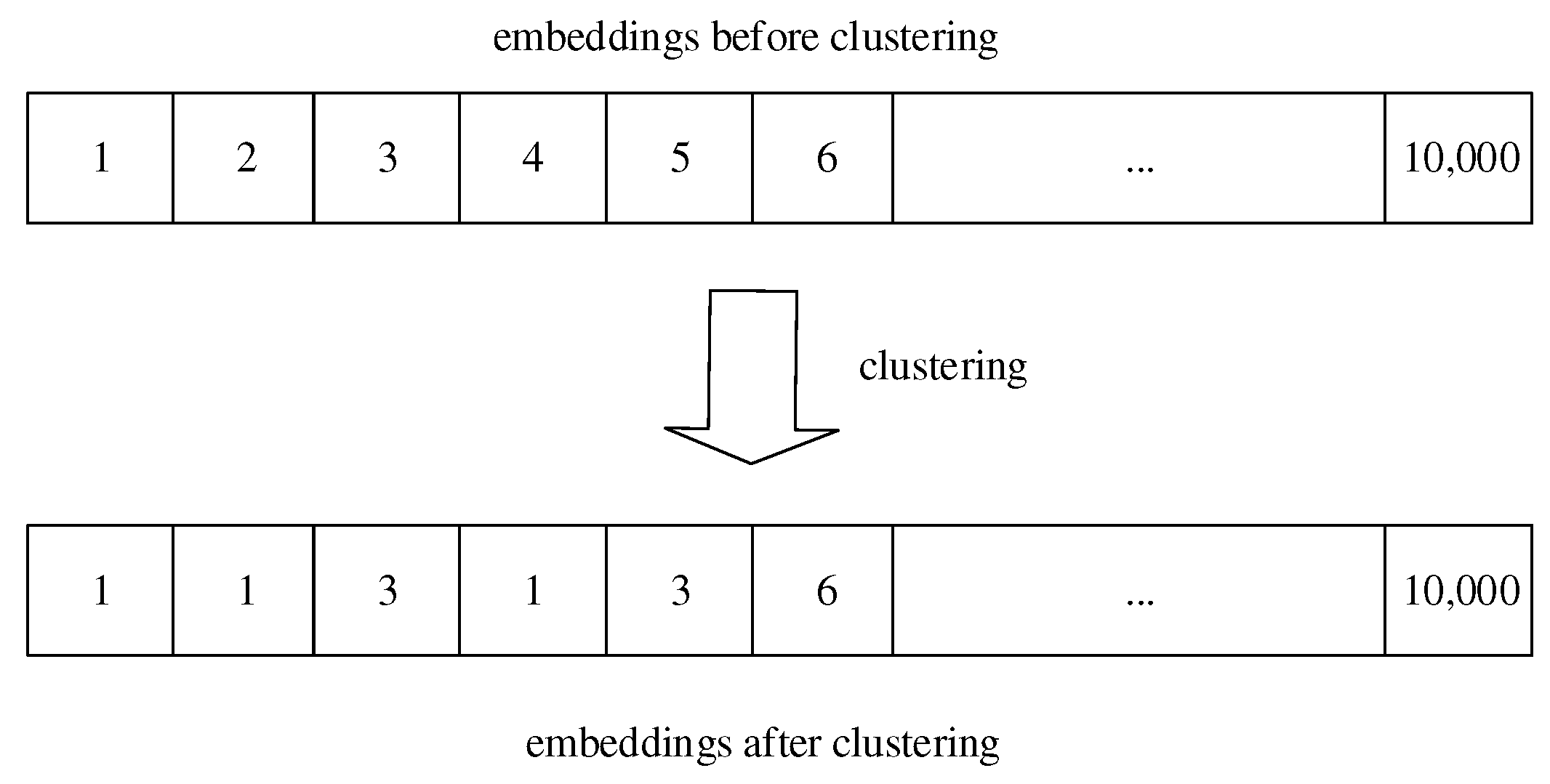
- To reduce the impact of the sparsity issue, we further enhanced the HRL by a clustering-based strategy, where a clustering strategy between the pre-trained network and the hierarchical reinforcement network is incorporated to reduce the data sparsity issue of the book borrowing data.
- We conduct extensive experiments on two real-world datasets, and the experimental results demonstrate the superiority of our solution compared with several state-of-the-art recommendation methods.
2. Related Works
2.1. Book Recommendation Methods
2.2. Deep Reinforcement Learning
2.3. Reinforcement Learning-Based Recommendation Methods
3. Our Recommendation Framework
3.1. Task Definition
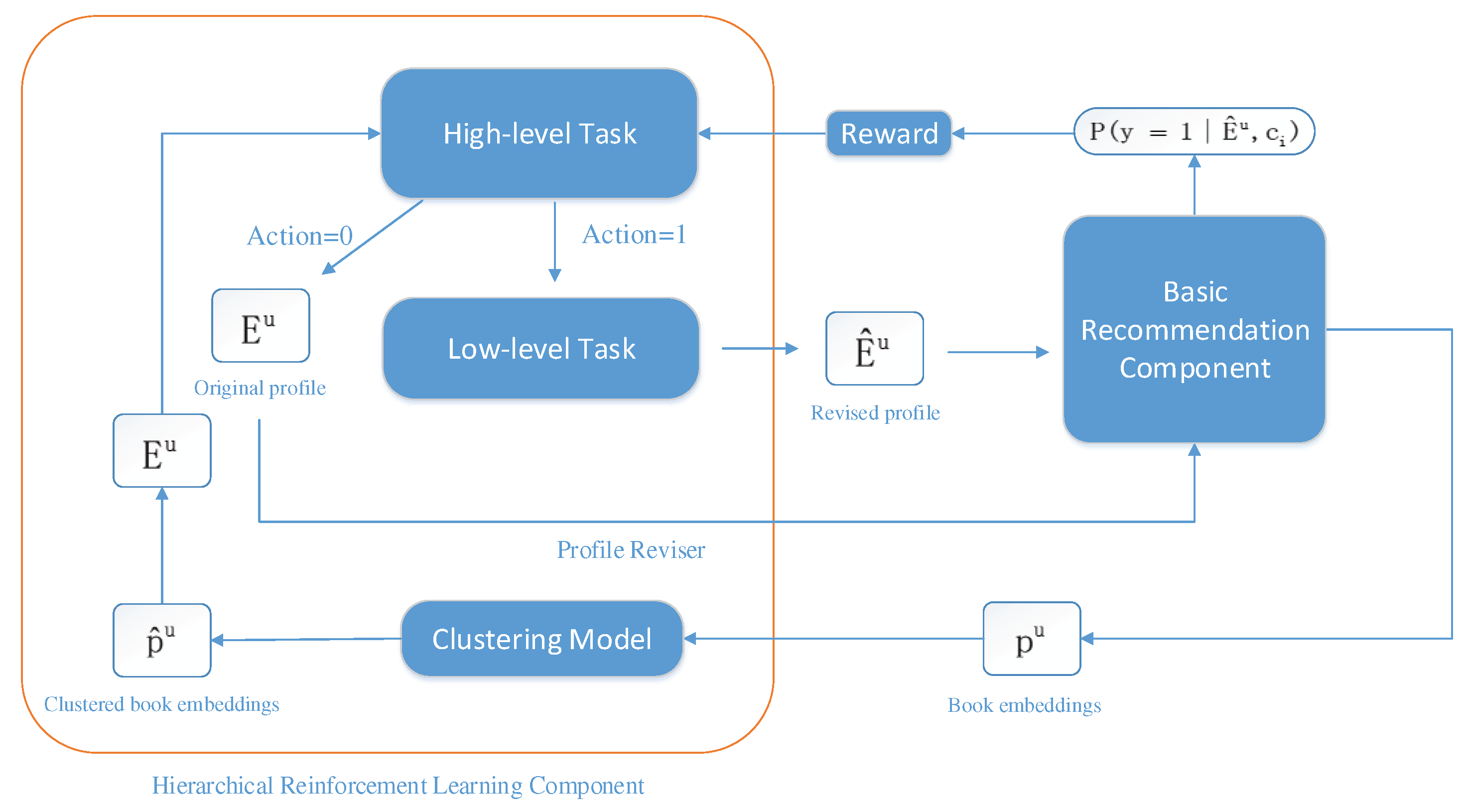
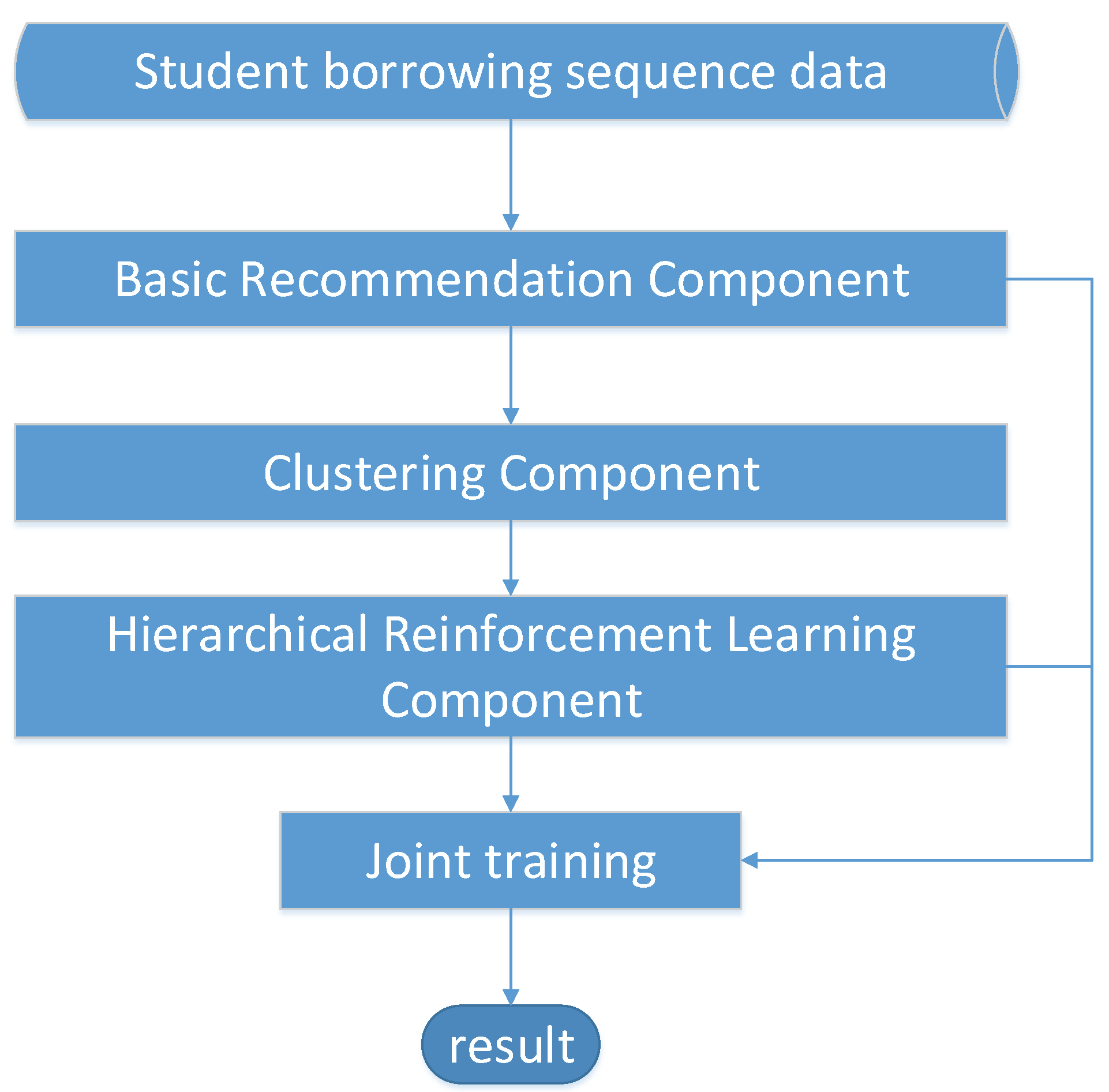
3.2. Overview of Our CHRL Method
3.3. Basic Recommender
3.4. The Sequence Modification Component
3.5. Joint Training
| Algorithm 1 The joint training strategy of CHRL |
| Input: Training sequence , , parameters in the basic model , parameters in the sequence modification model . |
| Output: Prediction results for each sequence. |
|
4. Experiments
4.1. Datasets and Experimental Settings
4.2. Implementation Details
4.3. Baseline Methods
5. Experimental Results and Analysis
5.1. Experimental Results
- For school borrowing data, it can be seen from Table 3 that is in prediction performance, our model is better than the baseline methods, compared with the collaborative filtering algorithm, and our algorithm uses feature vectors to classify books, which can better predict what kind of books students like and recommend these books to students. Collaborative filtering algorithms cannot classify books, so it is difficult to recommend sparse data. For goodbooks data, the recommendation results of our model are significantly better than those of other models.
- The two algorithms of FISM and NAIS are item-to-item collaborative filtering algorithms. They use a deep learning method, and the NAIS algorithm adds an attention mechanism to the FISM algorithm, but sparse data will have a greater impact on the training process of these two algorithms, resulting in poorer final results. The results obtained by the light-GCN algorithm are slightly better, but not particularly perfect.
- The HRL algorithm combines reinforcement learning with deep learning removes noise in the sequence and improves the model’s ability to process sparse data to a certain extent. Our CHRL algorithm deals with both sparse data and noise, and the results are better than other algorithms. In Goodbooks data, the HRL algorithms cannot get a good result, and our improved model CHRL can get better results than other models, which proves the effectiveness of our model.
5.2. Model Analysis
5.3. Analysis of Hyperparameters
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goldberg, D.; Nichols, D.; Oki, B.M.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Pazzani, M.J.; Billsus, D. Content-based recommendation systems. In The Adaptive Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 325–341. [Google Scholar]
- Zhang, Z.K.; Zhou, T.; Zhang, Y.C. Tag-aware recommender systems: A state-of-the-art survey. J. Comput. Sci. Technol. 2011, 26, 767. [Google Scholar] [CrossRef] [Green Version]
- Burke, R. Knowledge-based recommender systems. Encycl. Libr. Inf. Syst. 2000, 69, 175–186. [Google Scholar]
- Yang, S.T.; Hung, M.C. A model for book inquiry history analysis and book-acquisition recommendation of libraries. Libr. Collect. Acquis. Tech. Serv. 2012, 36, 127–142. [Google Scholar] [CrossRef]
- Sohail, S.S.; Siddiqui, J.; Ali, R. An OWA-based ranking approach for university books recommendation. Int. J. Intell. Syst. 2018, 33, 396–416. [Google Scholar] [CrossRef]
- Priyanka, K.; Tewari, A.S.; Barman, A.G. Personalised book recommendation system based on opinion mining technique. In Proceedings of the 2015 Global Conference on Communication Technologies (GCCT), Thuckalay, India, 23–24 April 2015; pp. 285–289. [Google Scholar]
- Zhang, J.; Hao, B.; Chen, B.; Li, C.; Chen, H.; Sun, J. Hierarchical Reinforcement Learning for Course Recommendation in MOOCs. AAAI Conf. Artif. Intell. 2019, 33, 435–442. [Google Scholar] [CrossRef]
- Ansari, A.; Essegaier, S.; Kohli, R. Internet Recommendation Systems. J. Market. Res. 2000, 37, 363–375. [Google Scholar] [CrossRef]
- Ziegler, C.N.; McNee, S.M.; Konstan, J.A.; Lausen, G. Improving recommendation lists through topic diversification. In Proceedings of the 14th International Conference on World Wide Web, Chiba, Japan, 10–14 May 2005; pp. 22–32. [Google Scholar]
- Konstas, I.; Stathopoulos, V.; Jose, J.M. On social networks and collaborative recommendation. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009; pp. 195–202. [Google Scholar]
- Robillard, M.; Walker, R.; Zimmermann, T. Recommendation systems for software engineering. IEEE Softw. 2009, 27, 80–86. [Google Scholar] [CrossRef]
- Smyth, B. Case-based recommendation. In The Adaptive Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 342–376. [Google Scholar]
- Fu, X.; Budzik, J.; Hammond, K.J. Mining navigation history for recommendation. In Proceedings of the 5th International Conference on Intelligent User Interfaces, New Orleans, LA, USA, 9–12 January 2000; pp. 106–112. [Google Scholar]
- Drineas, P.; Kerenidis, I.; Raghavan, P. Competitive recommendation systems. In Proceedings of the Thiry-Fourth Annual ACM Symposium on Theory of Computing, Montreal, QC, Canada, 19–21 May 2002; pp. 82–90. [Google Scholar]
- Sabitha, S.; Choudhury, T. Proposed approach for book recommendation based on user k-NN. In Advances in Computer and Computational Sciences; Springer: Berlin/Heidelberg, Germany, 2018; pp. 543–558. [Google Scholar]
- Goel, A.; Khandelwal, D.; Mundhra, J.; Tiwari, R. Intelligent and integrated book recommendation and best price identifier system using machine learning. In Intelligent Engineering Informatics; Springer: Berlin/Heidelberg, Germany, 2018; pp. 397–412. [Google Scholar]
- Mikawa, M.; Izumi, S.; Tanaka, K. Book recommendation signage system using silhouette-based gait classification. In Proceedings of the 2011 10th International Conference on Machine Learning and Applications and Workshops, Honolulu, HI, USA, 18–21 December 2011; Volume 1, pp. 416–419. [Google Scholar]
- Xin, L.; Haihong, E.; Junde, S.; Meina, S.; Junjie, T. Collaborative book recommendation based on readers’ borrowing records. In Proceedings of the 2013 International Conference on Advanced Cloud and Big Data, Nanjing, China, 13–15 December 2013; pp. 159–163. [Google Scholar]
- Maneewongvatana, S.; Maneewongvatana, S. A recommendation model for personalized book lists. In Proceedings of the 2010 10th International Symposium on Communications and Information Technologies, Tokyo, Japan, 26–29 October 2010; pp. 389–394. [Google Scholar]
- Yang, S.T. An active recommendation approach to improve book-acquisition process. Int. J. Electron. Bus. Manag. 2012, 10, 163–173. [Google Scholar]
- Tewari, A.S.; Kumar, A.; Barman, A.G. Book recommendation system based on combine features of content based filtering, collaborative filtering and association rule mining. In Proceedings of the 2014 IEEE International Advance Computing Conference (IACC), Gurgaon, India, 21–22 February 2014; pp. 500–503. [Google Scholar]
- Sohail, S.S.; Siddiqui, J.; Ali, R. Book recommendation system using opinion mining technique. In Proceedings of the 2013 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Mysore, India, 22–25 August 2013; pp. 1609–1614. [Google Scholar]
- Kanetkar, S.; Nayak, A.; Swamy, S.; Bhatia, G. Web-based personalized hybrid book recommendation system. In Proceedings of the 2014 International Conference on Advances in Engineering & Technology Research (ICAETR-2014), Unnao, India, 1–2 August 2014; pp. 1–5. [Google Scholar]
- Vaz, P.C.; Martins de Matos, D.; Martins, B.; Calado, P. Improving a hybrid literary book recommendation system through author ranking. In Proceedings of the 12th ACM/IEEE-CS joint conference on Digital Libraries, Washington, DC, USA, 10–14 June 2012; pp. 387–388. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Hausknecht, M.; Stone, P. Deep recurrent q-learning for partially observable mdps. arXiv 2015, arXiv:1507.06527. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Van Hasselt, H.; Lanctot, M.; De Freitas, N. Dueling network architectures for deep reinforcement learning. arXiv 2015, arXiv:1511.06581. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Hessel, M.; Modayil, J.; Van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining improvements in deep reinforcement learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Vezhnevets, A.; Mnih, V.; Osindero, S.; Graves, A.; Vinyals, O.; Agapiou, J. Strategic attentive writer for learning macro-actions. arXiv 2016, arXiv:1606.04695. [Google Scholar]
- Vezhnevets, A.S.; Osindero, S.; Schaul, T.; Heess, N.; Jaderberg, M.; Silver, D.; Kavukcuoglu, K. Feudal networks for hierarchical reinforcement learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 3540–3549. [Google Scholar]
- Nachum, O.; Gu, S.S.; Lee, H.; Levine, S. Data-efficient hierarchical reinforcement learning. arXiv 2018, arXiv:1805.08296. [Google Scholar]
- Theocharous, G.; Thomas, P.S.; Ghavamzadeh, M. Personalized ad recommendation systems for life-time value optimization with guarantees. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Wang, X.; Wang, Y.; Hsu, D.; Wang, Y. Exploration in interactive personalized music recommendation: A reinforcement learning approach. ACM Trans. Multimed. Comput. Commun. Appl. TOMM 2014, 11, 1–22. [Google Scholar] [CrossRef]
- Zheng, G.; Zhang, F.; Zheng, Z.; Xiang, Y.; Yuan, N.J.; Xie, X.; Li, Z. DRN: A deep reinforcement learning framework for news recommendation. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 167–176. [Google Scholar]
- Wang, L.; Zhang, W.; He, X.; Zha, H. Supervised reinforcement learning with recurrent neural network for dynamic treatment recommendation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2447–2456. [Google Scholar]
- Zhao, X.; Zhang, L.; Ding, Z.; Xia, L.; Tang, J.; Yin, D. Recommendations with negative feedback via pairwise deep reinforcement learning. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1040–1048. [Google Scholar]
- Zhao, X.; Xia, L.; Zhang, L.; Ding, Z.; Yin, D.; Tang, J. Deep reinforcement learning for page-wise recommendations. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2–7 October 2018; pp. 95–103. [Google Scholar]
- Chen, S.Y.; Yu, Y.; Da, Q.; Tan, J.; Huang, H.K.; Tang, H.H. Stabilizing reinforcement learning in dynamic environment with application to online recommendation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1187–1196. [Google Scholar]
- Rohde, D.; Bonner, S.; Dunlop, T.; Vasile, F.; Karatzoglou, A. Recogym: A reinforcement learning environment for the problem of product recommendation in online advertising. arXiv 2018, arXiv:1808.00720. [Google Scholar]
- He, X.; He, Z.; Song, J.; Liu, Z.; Jiang, Y.G.; Chua, T.S. Nais: Neural attentive item similarity model for recommendation. IEEE Trans. Knowl. Data Eng. 2018, 30, 2354–2366. [Google Scholar] [CrossRef] [Green Version]
- Linden, G.; Smith, B.; York, J. Amazon. com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef] [Green Version]
- Kabbur, S.; Ning, X.; Karypis, G. Fism: Factored item similarity models for top-n recommender systems. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 659–667. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. arXiv 2020, arXiv:2002.02126. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| School Borrowing Data | Goodbooks-10k Data | |
|---|---|---|
| Records | 518,605 | 898,195 |
| Students | 22,572 | 41,314 |
| Books | 124,468 | 10,000 |
| Training record | 496,033 | 856,881 |
| Testing record | 22,572 | 41,314 |
| School Borrowing Data | Goodbooks-10k Data | |
|---|---|---|
| Basic model epochs | 20 | 20 |
| Basic model learning rate | 0.02 | 0.02 |
| Basic model embedding size | 16 | 16 |
| cateorties | 2000 | 1000 |
| pre-training epochs | 50 | 50 |
| pre-training learning rate | 0.05 | 0.05 |
| joint trainging learning rate | 0.05 | 0.05 |
| joint delayed coefficient | 0.0005 | 0.0005 |
| HR@5 | HR@10 | NDCG@5 | NDCG@10 | |
|---|---|---|---|---|
| CF | 0.4518 | 0.4877 | 0.2856 | 0.2736 |
| FISM | 0.2358 | 0.3238 | 0.1771 | 0.2052 |
| NAIS | 0.2149 | 0.2860 | 0.1599 | 0.1828 |
| Light-GCN | 0.4702 | 0.5890 | 0.3231 | 0.3768 |
| HRL-NAIS | 0.6509 | 0.7834 | 0.4722 | 0.5156 |
| CHRL | 0.8293 | 0.9212 | 0.5909 | 0.6213 |
| HR@5 | HR@10 | NDCG@5 | NDCG@10 | |
|---|---|---|---|---|
| CF | 0.4070 | 0.5749 | 0.1004 | 0.1214 |
| FISM | 0.4017 | 0.5442 | 0.2791 | 0.3251 |
| NAIS | 0.3546 | 0.4988 | 0.2429 | 0.2894 |
| Light-GCN | 0.4294 | 0.5925 | 0.2821 | 0.3460 |
| HRL-NAIS | 0.2155 | 0.3216 | 0.1646 | 0.1927 |
| CHRL | 0.4811 | 0.7013 | 0.3682 | 0.4388 |
| HR@5 | HR@10 | NDCG@5 | NDCG@10 | ||
|---|---|---|---|---|---|
| HRL | average | 0.2482 | 0.3292 | 0.1785 | 0.2045 |
| standard deviation | 0.2043 | 0.2374 | 0.1473 | 0.1581 | |
| CHRL | average | 0.7777 | 0.9020 | 0.5372 | 0.5782 |
| standard deviation | 0.0373 | 0.0133 | 0.0538 | 0.0430 |
| HR@5 | HR@10 | NDCG@5 | NDCG@10 | |
|---|---|---|---|---|
| Basic recommender | 0.2149 | 0.2860 | 0.2860 | 0.1828 |
| Sequence modification component | 0.7583 | 0.8208 | 0.5527 | 0.5826 |
| Jointly training | 0.8293 | 0.9212 | 0.5909 | 0.6213 |
| Category | HR@5 | HR@10 | NDCG@5 | NDCG@10 |
|---|---|---|---|---|
| 10,000 | 0.3460 | 0.4057 | 0.2351 | 0.2576 |
| 5000 | 0.6528 | 0.7021 | 0.4953 | 0.5182 |
| 2000 | 0.8293 | 0.9212 | 0.5909 | 0.6213 |
| 1000 | 0.8053 | 0.8974 | 0.5680 | 0.5926 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Wang, Y.; Guo, L.; Xu, L.; Gao, B.; Liu, F.; Li, W. Exploring Clustering-Based Reinforcement Learning for Personalized Book Recommendation in Digital Library. Information 2021, 12, 198. https://doi.org/10.3390/info12050198
Wang X, Wang Y, Guo L, Xu L, Gao B, Liu F, Li W. Exploring Clustering-Based Reinforcement Learning for Personalized Book Recommendation in Digital Library. Information. 2021; 12(5):198. https://doi.org/10.3390/info12050198
Chicago/Turabian StyleWang, Xinhua, Yuchen Wang, Lei Guo, Liancheng Xu, Baozhong Gao, Fangai Liu, and Wei Li. 2021. "Exploring Clustering-Based Reinforcement Learning for Personalized Book Recommendation in Digital Library" Information 12, no. 5: 198. https://doi.org/10.3390/info12050198
APA StyleWang, X., Wang, Y., Guo, L., Xu, L., Gao, B., Liu, F., & Li, W. (2021). Exploring Clustering-Based Reinforcement Learning for Personalized Book Recommendation in Digital Library. Information, 12(5), 198. https://doi.org/10.3390/info12050198