
A Study of Multilingual Toxic Text Detection Approaches under Imbalanced Sample Distribution



Abstract
:1. Introduction
2. Related Work
2.1. Monolingual Toxic Text Detection
2.2. Multilingual Toxic Text Detection
2.3. Toxicity Detection Models
2.3.1. Conventional Learning Models
2.3.2. Deep Learning Models
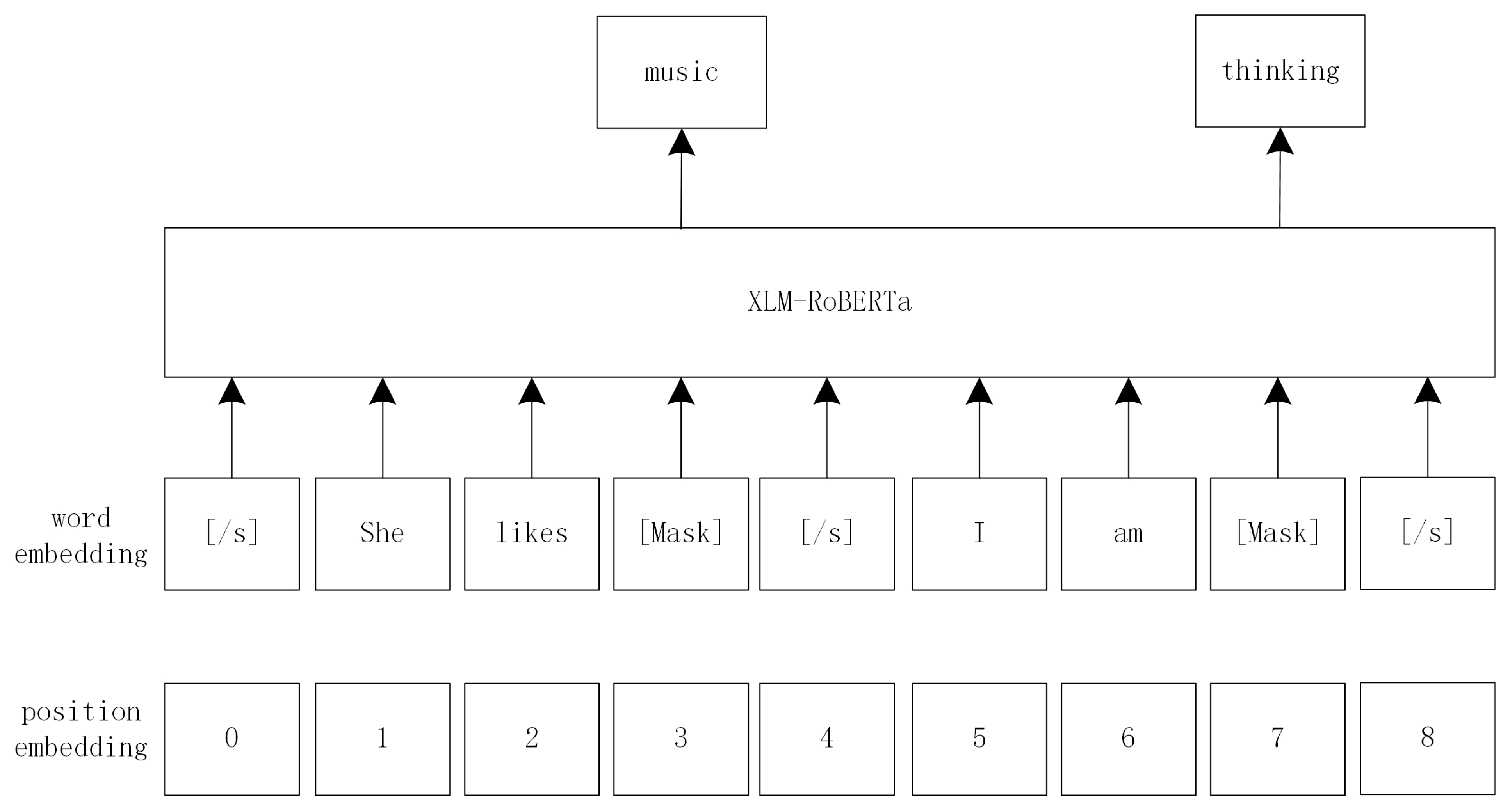
2.3.3. Transfer Learning via Masked Language Models
2.3.4. Model Fusion
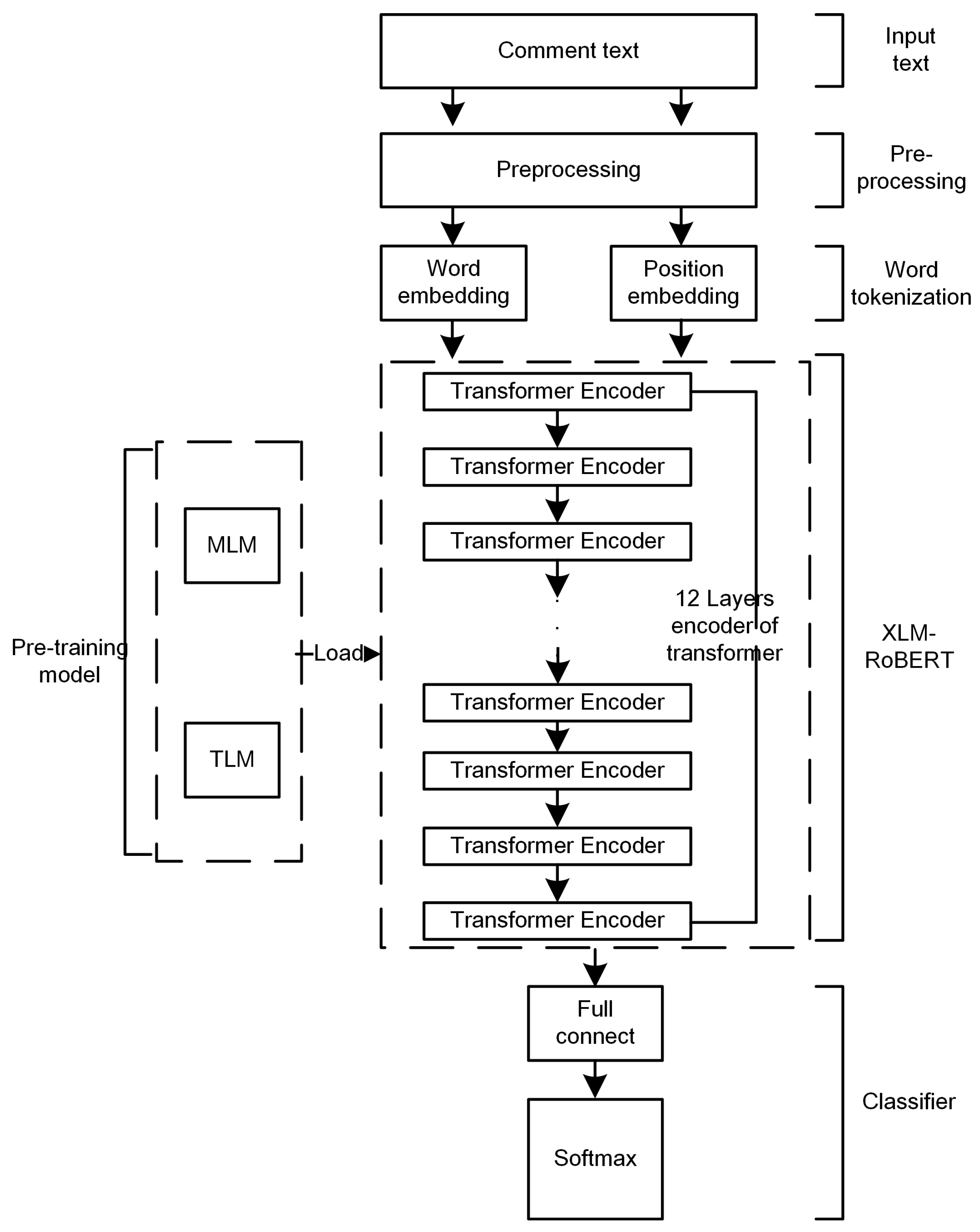
3. Multilingual Toxic Text Detection Model Based on Multi-Model Fusion
3.1. Text Pre-Processing
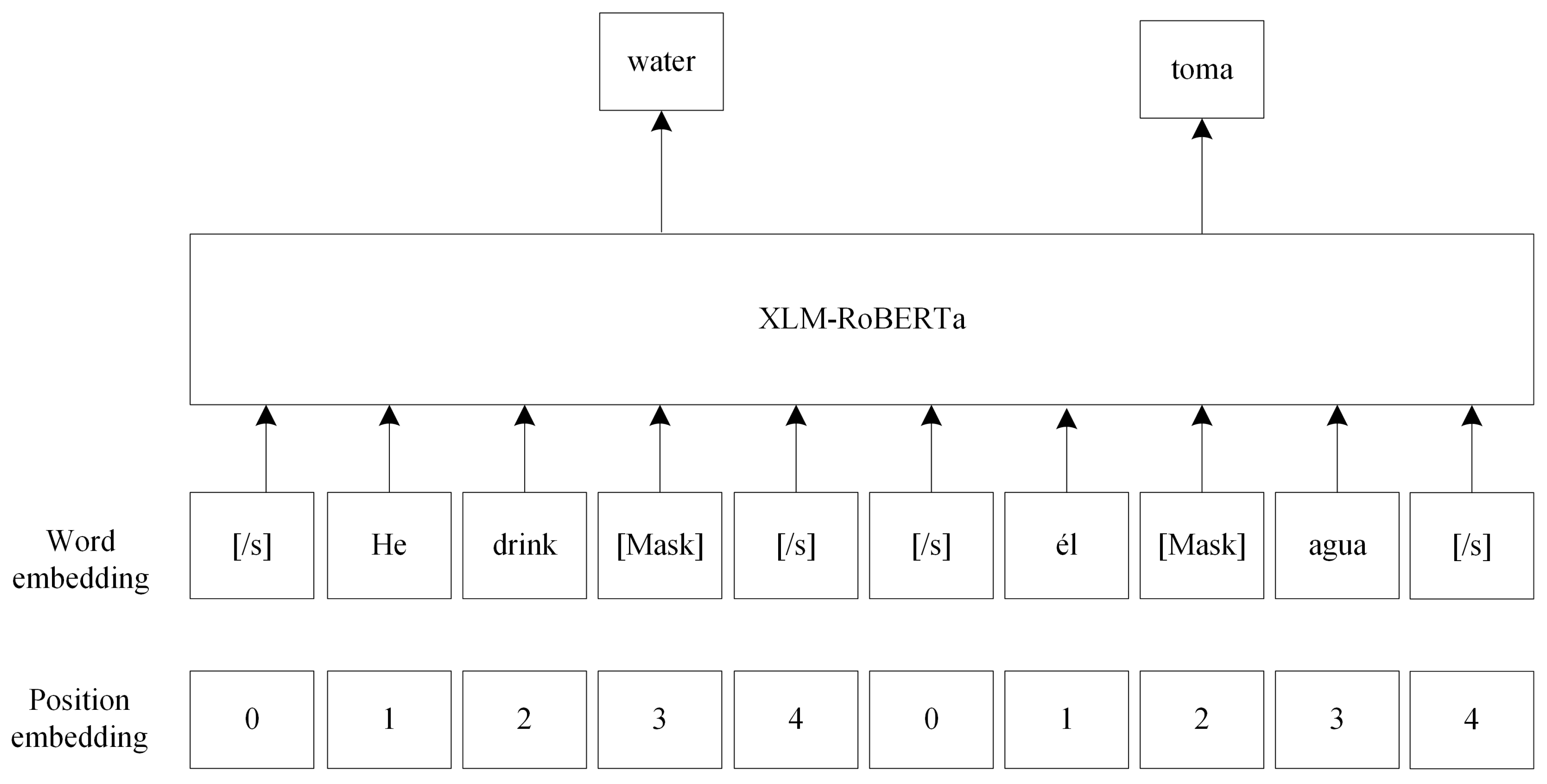
3.1.1. Translation
3.1.2. Word Segmentation
3.1.3. Text Purification
3.1.4. Sample Equilibrium
3.1.5. Lexicon Solidification
3.1.6. Word Embedding
3.1.7. Position Embedding
3.2. Pre-Training and Fine-Tuning Multilingual Models
3.2.1. The BERT Language Model
3.2.2. Pre-Training with Masking-Based Language Modeling
3.2.3. Pre-Training with Translation-Based Language Modeling
3.2.4. Fine-Tuning
3.3. Model Fusion
3.3.1. A Fusion of Loss Functions
3.3.2. A Fusion of Multilingual Models
4. Experimental Results and Analysis
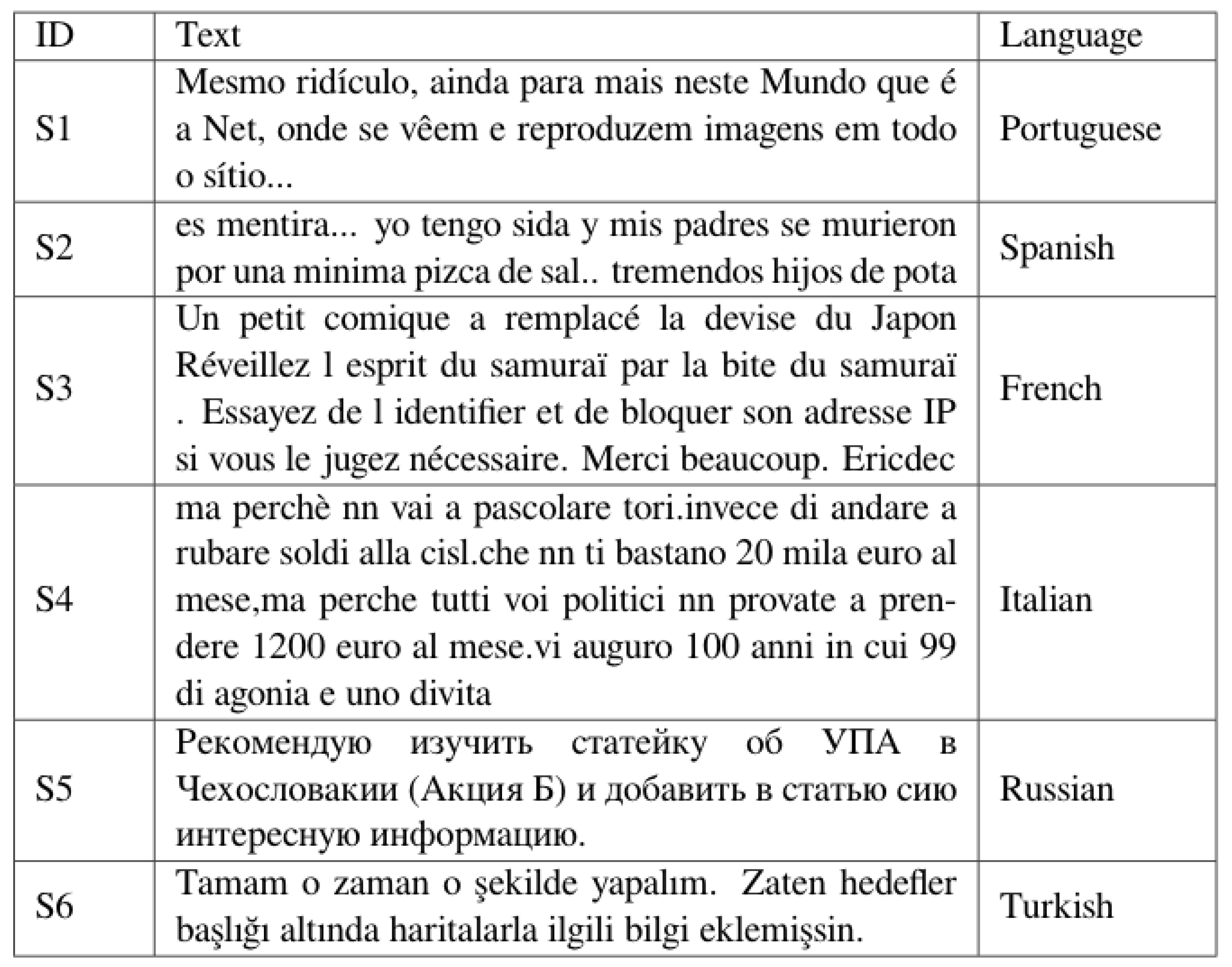
4.1. Dataset
- The original training set contains 435,775 labeled samples, all in English. After translation, we obtain a total of 3,050,425 labeled samples in the seven languages considered in this task, and fine-tuning is conducted on the augmented training set;
- The validation set contains 8000 labeled samples in three languages, including 3000 Turkish samples, 2000 Italian samples, and 2000 Spanish samples;
- The test set consists of 63,812 unlabeled samples in six languages, including 8438 Spanish samples, 10,920 French samples, 8494 Italian samples, 11,012 Portuguese samples, 10,948 Russian samples, and 14,000 Turkish samples.
4.2. Evaluation Metrics
4.3. Models
- MBERT_BCE: Using MBERT as a pre-training model and BCE loss as the loss function;
- MBERT_FOCAL: Using MBERT as a pre-training model and focal loss as the loss function;
- MBERT_MIX: Using MBERT as a pre-training model and the mixed BCE and focal loss at a ratio of 1:1;
- XLM-R_BCE: Using XLM-R as a pre-training model and BCE loss as the loss function;
- XLM-R_FOCAL: Using XLM-R as a pre-training model and focal loss as the loss function;
- XLM-R_MIX: Using XLM-R as a pre-training model and BCE loss and focal loss at a ratio of 1:1 as the loss function;
- Model-Fusion-1: The two models 3 and 6 are fused with the validation values used as the fusion weights;
- Model-Fusion-2: The four models of 2, 3, 5, and 6 are fused with the validation values used as the fusion weights;
- Model-Fusion-3: The six models 1-6 are fused with the validation values used as the fusion weights.
4.4. Benchmarks
4.5. Experimental Environment and Parameter Settings
4.6. Experimental Results and Analysis
5. Summary and Prospect
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- van Aken, B.; Risch, J.; Krestel, R.; Löser, A. Challenges for toxic comment classification: An in-depth error analysis. arXiv 2018, arXiv:1809.07572. [Google Scholar]
- Bashar, M.A.; Nayak, R. QutNocturnal@ HASOC’19: CNN for hate speech and offensive content identification in Hindi language. arXiv 2020, arXiv:2008.12448. [Google Scholar]
- Moon, J.; Cho, W.I.; Lee, J. BEEP! Korean Corpus of Online News Comments for Toxic Speech Detection. arXiv 2020, arXiv:2005.12503. [Google Scholar]
- Zueva, N.; Kabirova, M.; Kalaidin, P. Reducing Unintended Identity Bias in Russian Hate Speech Detection. arXiv 2020, arXiv:2010.11666. [Google Scholar]
- Plaza-del Arco, F.M.; Molina-González, M.D.; Ureña-López, L.A.; Martín-Valdivia, M.T. Comparing pre-trained language models for Spanish hate speech detection. Expert Syst. Appl. 2021, 166, 114120. [Google Scholar] [CrossRef]
- Waseem, Z.; Hovy, D. Hateful symbols or hateful people? Predictive features for hate speech detection on twitter. In Proceedings of the NAACL Student Research Workshop, Berlin, Germany, 7–12 August 2016; pp. 88–93. [Google Scholar]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated hate speech detection and the problem of offensive language. In Proceedings of the International AAAI Conference on Web and Social Media, Montréal, QC, Canada, 15–18 May 2017; Volume 11. [Google Scholar]
- Sharma, S.; Agrawal, S.; Shrivastava, M. Degree based classification of harmful speech using twitter data. arXiv 2018, arXiv:1806.04197. [Google Scholar]
- Salminen, J.; Almerekhi, H.; Kamel, A.M.; Jung, S.G.; Jansen, B.J. Online hate ratings vary by extremes: A statistical analysis. In Proceedings of the 2019 Conference on Human Information Interaction and Retrieval, Glasgow, UK, 10–14 March 2019; pp. 213–217. [Google Scholar]
- Kajla, H.; Hooda, J.; Saini, G. Classification of Online Toxic Comments Using Machine Learning Algorithms. In Proceedings of the 2020 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 13–15 May 2020; pp. 1119–1123. [Google Scholar]
- Greevy, E.; Smeaton, A.F. Classifying racist texts using a support vector machine. In Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Sheffield, UK, 25–29 July 2004; pp. 468–469. [Google Scholar]
- Alfina, I.; Mulia, R.; Fanany, M.I.; Ekanata, Y. Hate speech detection in the Indonesian language: A dataset and preliminary study. In Proceedings of the 2017 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Jakarta, Indonesia, 28–29 October 2017; pp. 233–238. [Google Scholar]
- Kwok, I.; Wang, Y. Locate the hate: Detecting tweets against blacks. In Proceedings of the AAAI Conference on Artificial Intelligence, Bellevue, WA, USA, 14–18 July 2013; Volume 27. [Google Scholar]
- Saif, M.A.; Medvedev, A.N.; Medvedev, M.A.; Atanasova, T. Classification of online toxic comments using the logistic regression and neural networks models. In AIP Conference Proceedings; AIP Publishing LLC.: New York, NY, USA, 2018; Volume 2048, p. 060011. [Google Scholar]
- Georgakopoulos, S.V.; Tasoulis, S.K.; Vrahatis, A.G.; Plagianakos, V.P. Convolutional neural networks for toxic comment classification. In Proceedings of the 10th Hellenic Conference on Artificial Intelligence, Patras, Greece, 9–12 July 2018; pp. 1–6. [Google Scholar]
- Jubaer, A.; Sayem, A.; Rahman, M.A. Bangla toxic comment classification (machine learning and deep learning approach). In Proceedings of the 2019 8th International Conference System Modeling and Advancement in Research Trends (SMART), Moradabad, India, 22–23 November 2019; pp. 62–66. [Google Scholar]
- Dubey, K.; Nair, R.; Khan, M.U.; Shaikh, S. Toxic Comment Detection using LSTM. In Proceedings of the 2020 Third International Conference on Advances in Electronics, Computers and Communications (ICAECC), Bengaluru, India, 11–12 December 2020; pp. 1–8. [Google Scholar]
- Mahajan, A.; Shah, D.; Jafar, G. Explainable AI Approach towards Toxic Comment Classification. EasyChair Preprint, 26 February 2020. [Google Scholar]
- Halim, Z.; Waqar, M.; Tahir, M. A machine learning-based investigation utilizing the in-text features for the identification of dominant emotion in an email. Knowl. Based Syst. 2020, 208, 106443. [Google Scholar] [CrossRef]
- Jia, X.; Deng, Z.; Min, F.; Liu, D. Three-way decisions based feature fusion for Chinese irony detection. Int. J. Approx. Reason. 2019, 113, 324–335. [Google Scholar] [CrossRef]
- Tzogka, C.; Passalis, N.; Iosifidis, A.; Gabbouj, M.; Tefas, A. Less Is More: Deep Learning Using Subjective Annotations for Sentiment Analysis from Social Media. In Proceedings of the 2019 IEEE 29th International Workshop on Machine Learning for Signal Processing (MLSP), Pittsburgh, PA, USA, 13–16 October 2019; pp. 1–6. [Google Scholar]
- Ranasinghe, T.; Zampieri, M. MUDES: Multilingual Detection of Offensive Spans. arXiv 2021, arXiv:2102.09665. [Google Scholar]
- Ranasinghe, T.; Hettiarachchi, H. BRUMS at SemEval-2020 task 12: Transformer based multilingual offensive language identification in social media. arXiv 2020, arXiv:2010.06278. [Google Scholar]
- Becker, K.; Moreira, V.P.; dos Santos, A.G. Multilingual emotion classification using supervised learning: Comparative experiments. Inf. Process. Manag. 2017, 53, 684–704. [Google Scholar] [CrossRef]
- Ousidhoum, N.; Lin, Z.; Zhang, H.; Song, Y.; Yeung, D.Y. Multilingual and multi-aspect hate speech analysis. arXiv 2019, arXiv:1908.11049. [Google Scholar]
- Corazza, M.; Menini, S.; Cabrio, E.; Tonelli, S.; Villata, S. A multilingual evaluation for online hate speech detection. ACM Trans. Internet Technol. 2020, 20, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Pamungkas, E.W.; Basile, V.; Patti, V. Misogyny detection in twitter: A multilingual and cross-domain study. Inf. Process. Manag. 2020, 57, 102360. [Google Scholar] [CrossRef]
- Rasooli, M.S.; Farra, N.; Radeva, A.; Yu, T.; McKeown, K. Cross-lingual sentiment transfer with limited resources. Mach. Transl. 2018, 32, 143–165. [Google Scholar] [CrossRef]
- Dong, X.; De Melo, G. Cross-lingual propagation for deep sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Can, E.F.; Ezen-Can, A.; Can, F. Multilingual sentiment analysis: An RNN-based framework for limited data. arXiv 2018, arXiv:1806.04511. [Google Scholar]
- Li, X.; Li, Z.; Sheng, J.; Slamu, W. Low-Resource Text Classification via Cross-Lingual Language Model Fine-Tuning. In China National Conference on Chinese Computational Linguistics; Springer: Cham, Switzerland, 2020; pp. 231–246. [Google Scholar]
- Roy, S.G.; Narayan, U.; Raha, T.; Abid, Z.; Varma, V. Leveraging Multilingual Transformers for Hate Speech Detection. arXiv 2021, arXiv:2101.03207. [Google Scholar]
- Mohammad, F. Is preprocessing of text really worth your time for online comment classification? arXiv 2018, arXiv:1806.02908. [Google Scholar]
- Kalouli, A.L.; Kaiser, K.; Hautli, A.; Kaiser, G.A.; Butt, M. A multilingual approach to question classification. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Wang, Z.; Lee, S.; Li, S.; Zhou, G. Emotion detection in code-switching texts via bilingual and sentimental information. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Beijing, China, 26–31 July 2015; pp. 763–768. [Google Scholar]
- Ibrahim, M.; Torki, M.; El-Makky, N. Imbalanced toxic comments classification using data augmentation and deep learning. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 875–878. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised cross-lingual representation learning at scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]
- Huang, X.; Xing, L.; Dernoncourt, F.; Paul, M.J. Multilingual Twitter corpus and baselines for evaluating demographic bias in hate speech recognition. arXiv 2020, arXiv:2002.10361. [Google Scholar]
- Aluru, S.S.; Mathew, B.; Saha, P.; Mukherjee, A. Deep learning models for multilingual hate speech detection. arXiv 2020, arXiv:2004.06465. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Černockỳ, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Makuhari, Japan, 26–30 September 2010. [Google Scholar]
- Ghosh, S.; Kumar, S.; Lepcha, S.; Jain, S.S. Toxic Text Classification. In Data Science and Security; Springer: Singapore, 2021; pp. 251–260. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Mozafari, M.; Farahbakhsh, R.; Crespi, N. A BERT-based transfer learning approach for hate speech detection in online social media. In International Conference on Complex Networks and Their Applications; Springer: Cham, Switzerland, 2019; pp. 928–940. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Kim, Y.; Jernite, Y.; Sontag, D.; Rush, A. Character-aware neural language models. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Pamungkas, E.W.; Basile, V.; Patti, V. A joint learning approach with knowledge injection for zero-shot cross-lingual hate speech detection. Inf. Process. Manag. 2021, 58, 102544. [Google Scholar] [CrossRef]
- Conneau, A.; Lample, G.; Ranzato, M.; Denoyer, L.; Jégou, H. Word translation without parallel data. arXiv 2017, arXiv:1710.04087. [Google Scholar]
- Bassignana, E.; Basile, V.; Patti, V. Hurtlex: A multilingual lexicon of words to hurt. In Proceedings of the 5th Italian Conference on Computational Linguistics, CLiC-it 2018. CEUR-WS, Torino, Italy, 10–12 December 2018; Volume 2253, pp. 1–6. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lample, G.; Conneau, A. Cross-lingual language model pretraining. arXiv 2019, arXiv:1901.07291. [Google Scholar]
- Burnap, P.; Williams, M.L. Cyber hate speech on twitter: An application of machine classification and statistical modeling for policy and decision making. Policy Internet 2015, 7, 223–242. [Google Scholar] [CrossRef] [Green Version]
- Gao, L.; Huang, R. Detecting online hate speech using context aware models. arXiv 2017, arXiv:1710.07395. [Google Scholar]
- Zimmerman, S.; Kruschwitz, U.; Fox, C. Improving hate speech detection with deep learning ensembles. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Zhang, L.; Wu, L.; Li, S.; Wang, Z.; Zhou, G. Cross-lingual emotion classification with auxiliary and attention neural networks. In CCF International Conference on Natural Language Processing and Chinese Computing; Springer: Cham, Switzerland, 2018; pp. 429–441. [Google Scholar]
- Yin, W.; Kann, K.; Yu, M.; Schütze, H. Comparative study of CNN and RNN for natural language processing. arXiv 2017, arXiv:1702.01923. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S1 | “Esta canción es tan sentida!” |
| S2 | “Estoy muy emocionado por dentro, So easy!” |
| S3 | “Hi, guys. Eres basura” |
| S4 | “Me decepciono tanto, you are son of a b**ch.” |
| S5 | “Put up or shut up” |
| Work | Task | Model | # Languages | Dataset |
|---|---|---|---|---|
| Roy et al. [32] | Hate speech detection | Transformer | Three | HASOC 2020 |
| Ranasinghe et al. [23] | Offensive language detection | Transformer | Five | OffensEval 2020 |
| Becker et al. [24] | Emotion detection | Stacking of meta learners | Four | SemEvalNews and BRNews |
| Ousidhoum et al. [25] | Hate speech detection | BiLSTM and LR | Three | Collected from Twitter |
| Huang et al. [39] | Demographic bias analysis | LR, CNN, RNN, and BERT | Five | Collected from Twitter |
| Corazza et al. [26] | Hate speech detection | LSTM, BiLSTM, and GRU | Three | From three sources |
| Aluru et al. [40] | Hate speech detection | LR and mBERT | Nine | from 16 sources |
| Pamungkas et al. [27] | Misogyny Detection | LSTM, GRU, and BERT | Three | AMI IberEval 2018 |
| Rasooli et al. [28] | Sentiment analysis | LSTM | Sixteen | Collected from Twitter |
| Dong et al. [29] | Sentiment analysis | dual-channel CNN | Nine | From five sources |
| Zhang et al. [56] | Sentiment analysis | attention network | Two | Emotion corpus |
| Kalouli et al. [34] | Question classification | Heuristics | Four | KRoQ |
| Can et al. [30] | Sentiment analysis | RNN | Five | Amazon and Yelp reviews |
| Our work | Toxic text detection | MBERT and XLM-R | Seven | Jigsaw 2020 |
| Parameter Name | Parameter Value |
|---|---|
| Number of fully Connected layers | 2 |
| Number of hidden cells of fully connected layer | 768 × 2 |
| Learning rate | 1 × 10 |
| Word vector dimension | 768 |
| Training batch size | 16 |
| XLM-R input sentence length | 224 |
| Input sentence length | 512 |
| Model | Accuracy | Recall | Precision | F1 |
|---|---|---|---|---|
| Logistic Regression [14] | 0.8584 | 0.7874 | 0.7443 | 0.7594 |
| CNN+fastText [45] | 0.8787 | 0.8097 | 0.7587 | 0.7822 |
| Bi-LSTM [42] | 0.8656 | 0.7939 | 0.7736 | 0.7828 |
| Bi-GRU [42] | 0.8912 | 0.8586 | 0.8015 | 0.8249 |
| XLM-R_BCE | 0.9376 | 0.8698 * | 0.8129 | 0.8381 |
| XLM-R_FOCAL (SOTA) | 0.9450 | 0.8232 | 0.8529 | 0.8372 |
| XLM-R_MIX | 0.9411 | 0.8514 | 0.8276 | 0.8389 |
| MBERT_BCE | 0.9094 | 0.8605 | 0.7505 | 0.7907 |
| MBERT_FOCAL (SOTA) | 0.9420 | 0.7381 | 0.9035 | 0.7943 |
| MBERT_MIX | 0.9408 | 0.8479 | 0.8274 | 0.8373 |
| Model-Fusion-1 | 0.9437 | 0.8539 | 0.8360 | 0.8446 |
| Model-Fusion-2 | 0.9469 | 0.8344 | 0.8560 | 0.8448 |
| Model-Fusion-3 | 0.9437 | 0.8548 | 0.8357 | 0.8449 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, G.; Huang, D.; Xiao, Z. A Study of Multilingual Toxic Text Detection Approaches under Imbalanced Sample Distribution. Information 2021, 12, 205. https://doi.org/10.3390/info12050205
Song G, Huang D, Xiao Z. A Study of Multilingual Toxic Text Detection Approaches under Imbalanced Sample Distribution. Information. 2021; 12(5):205. https://doi.org/10.3390/info12050205
Chicago/Turabian StyleSong, Guizhe, Degen Huang, and Zhifeng Xiao. 2021. "A Study of Multilingual Toxic Text Detection Approaches under Imbalanced Sample Distribution" Information 12, no. 5: 205. https://doi.org/10.3390/info12050205
APA StyleSong, G., Huang, D., & Xiao, Z. (2021). A Study of Multilingual Toxic Text Detection Approaches under Imbalanced Sample Distribution. Information, 12(5), 205. https://doi.org/10.3390/info12050205