
Missing Link Prediction Using Non-Overlapped Features and Multiple Sources of Social Networks


Abstract
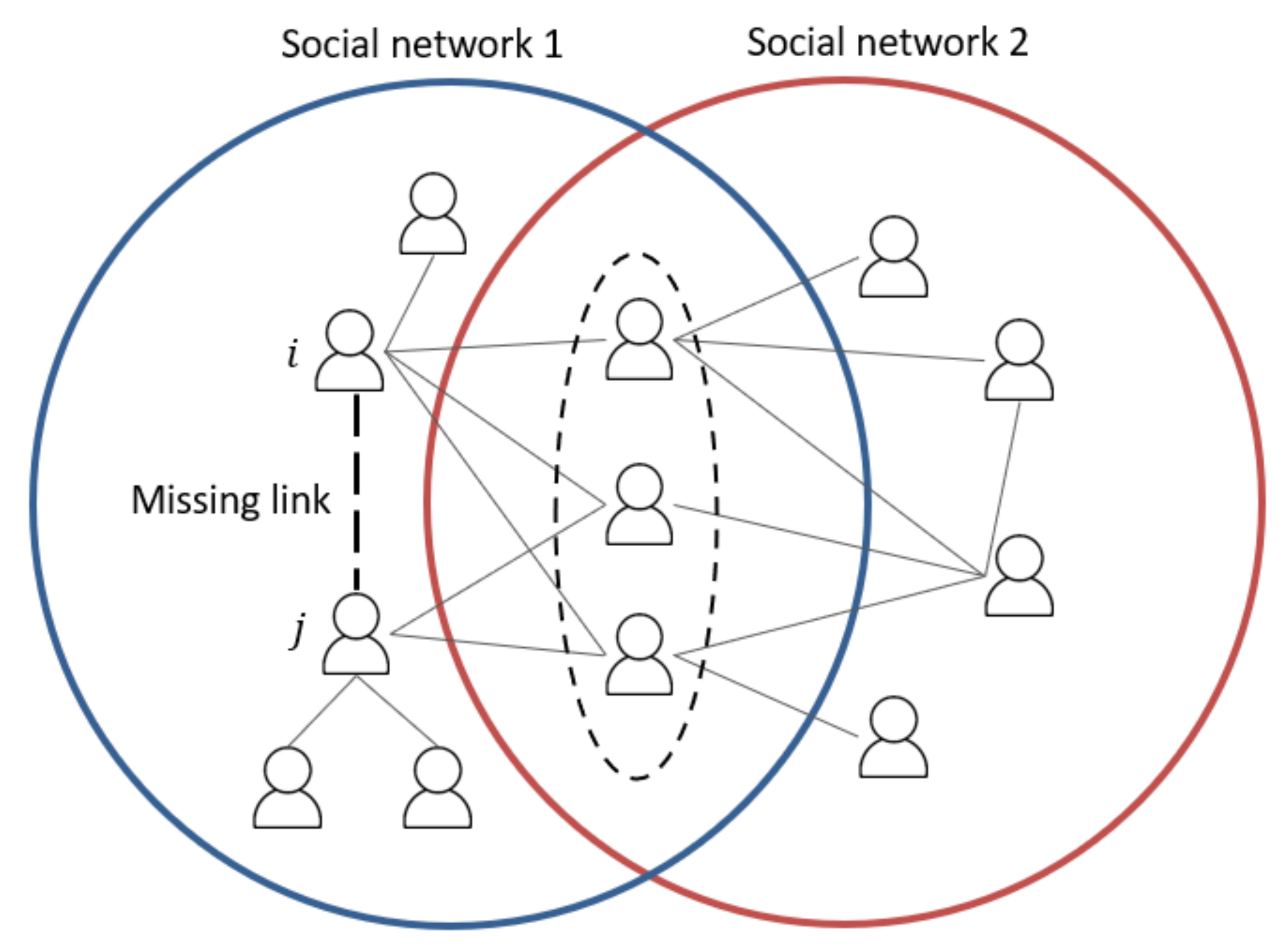
:1. Introduction
2. Literature Reviews
3. Research Methodology
3.1. Data Sources
- Facebook network structure can be divided into two parts as follows:
- (a)
- A node represents a user with features including personal information.
- (b)
- Non-directional link shows friends in the network.
- Twitter structure of the network is divided into two parts as follows:
- (a)
- A node represents a user with features including personal information, tweet messages, hashtags, and referring node.
- (b)
- Directional link shows the user following status and followed status in the network.
3.2. Basic Link Prediction Features
3.2.1. Graph-Based Features
3.2.2. Qualitative Features
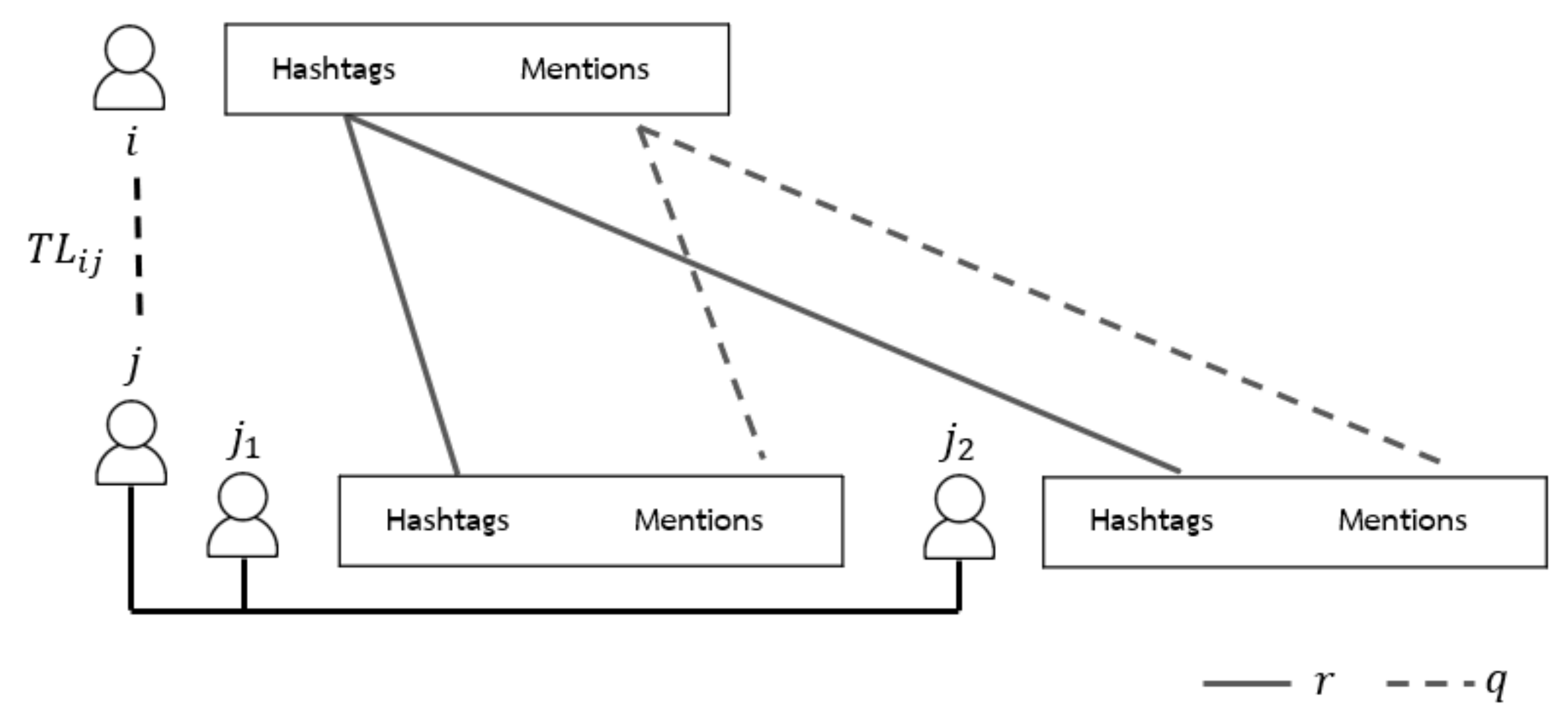
- Hashtag overlap () is the similarity between nodes on Twitter that is detected through interest topics in the form of hashtags. The number of hashtags commonly used between two users on Twitter [15] is calculated as shown in Equation (9),where is the set of tweeted hashtags of node i and is the set of tweeted hashtags of node j.
- The mention frequency () between the two considering nodes is used to indicate the relationship. Many mentions between two nodes are considered to be a high probability that the two nodes will know each other [14]. This can be calculated from Equation (11),where =1, in case when node i mentions node j.
4. Proposed Features
4.1. Graph-Based Features
4.1.1. Node Latent
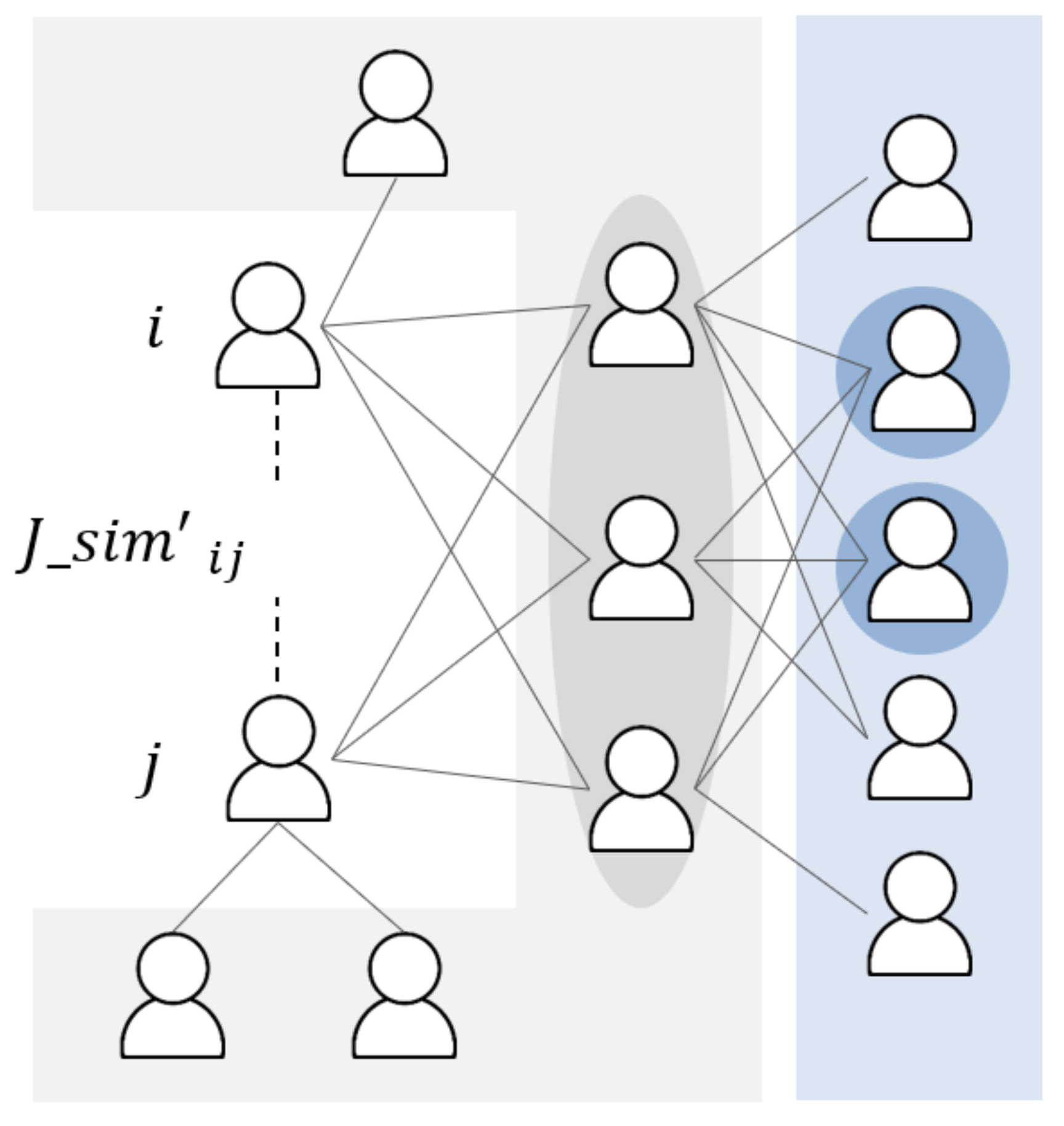
4.1.2. Jaccard Similarity of Second-Order Neighbor
4.1.3. Enhanced Friend of Similar
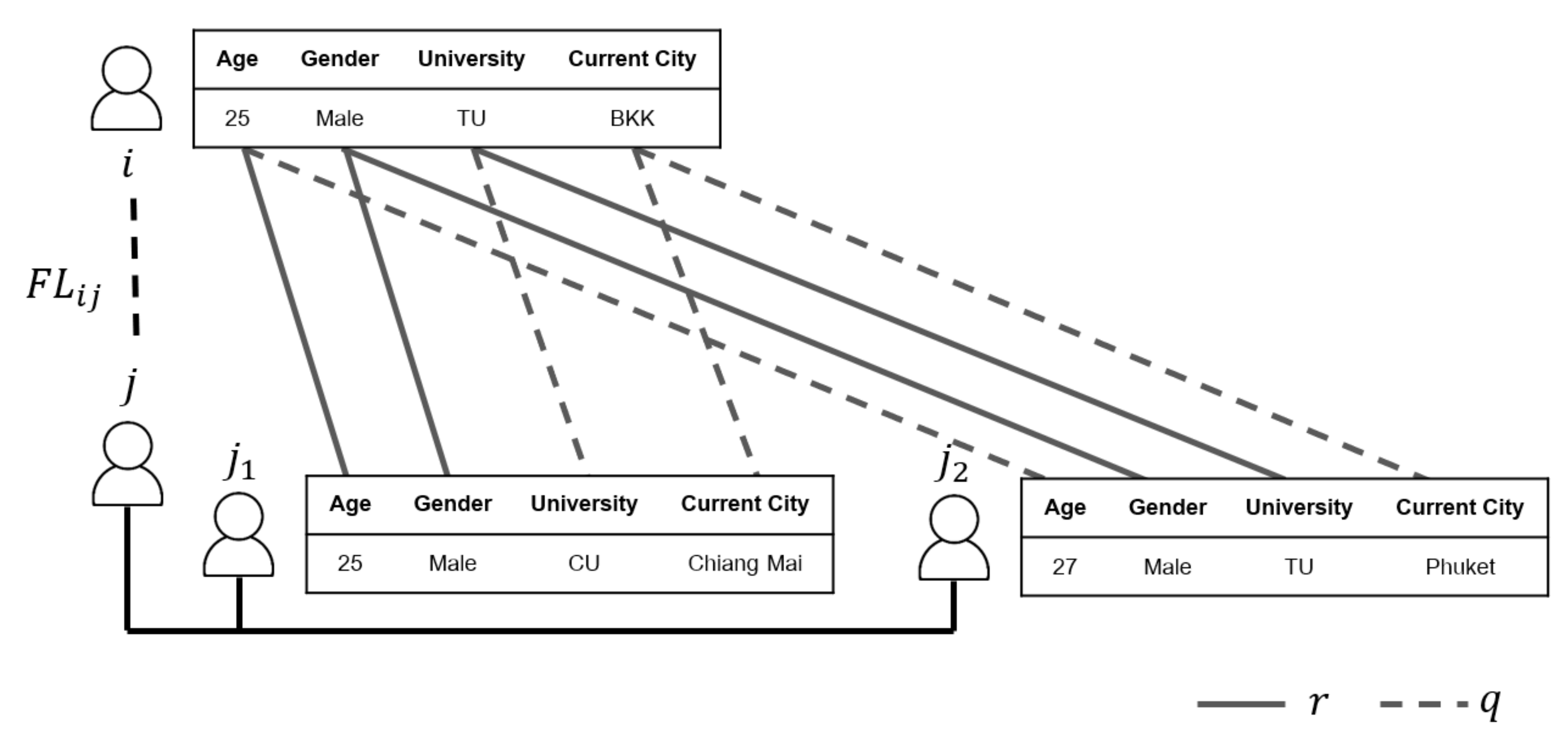
4.2. Node Qualitative Feature
5. Experiment
5.1. Network Density
5.2. Data Collection
- Dataset from Facebook: two datasets with different network densities. Dataset 1 contains a low network-density of 0.01, and dataset 2 contains a high network-density of 0.03, which is three times higher than the density of dataset 1.
- Dataset from Twitter: one dataset with a network-density of 0.01.
- Dataset 1, Twitter dataset, which represents a single SN source with a network-density of 0.01 (Single-SN);
- Dataset 2, Twitter and Facebook datasets with a low network-density that represent multiple SN sources with a low network-density of 0.01 (Multi-SN-low); and
- Dataset 3, Twitter and Facebook datasets with a high network-density represent multiple SN sources with a high network-density of 0.02 (Multi-SN-high).
5.3. Evaluation Metrics
5.4. Link Prediction Techniques and Features
- For each technique, it is necessary to specify the parameters for model creation. Therefore, we conduct an experiment to find the suitable parameters for data classification techniques. There are three classification techniques used in the experiment: specifying parameter k for kNN [30,31], specifying hidden layer parameters and hidden node for ANN [32,33], and specifying parameters of the number of trees for RF [34,35]. We develop the program for this experiment to train and test the prediction models written using Scikit-learn and Python.
- An experiment is set to compare the prediction efficiency between data usage from a single SN source and multiple SN sources by considering overlapping and non-overlapping nodes via three data classification techniques: kNN, RF, and ANN.
6. Results
6.1. Prediction Model Parameter Investigation Result
6.2. Link Prediction Techniques and Features Evaluation Result
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Long, J.; Wang, Y.; Yuan, X.; Li, T.; Liu, Q. A Recommendation Model Based on Multi-Emotion Similarity in the Social Networks. Information 2019, 10, 18. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.; Kwan, C. Missing Link Prediction in Social Networks. In Advances in Neural Networks—ISNN 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 346–354. [Google Scholar] [CrossRef]
- Yazdavar, A.H.; Mahdavinejad, M.S.; Bajaj, G.; Thirunarayan, K.; Pathak, J.; Sheth, A. Mental Health Analysis Via Social Media Data. In Proceedings of the 2018 IEEE International Conference on Healthcare Informatics (ICHI), New York, NY, USA, 4–7 June 2018. [Google Scholar] [CrossRef]
- Pantic, I. Online Social Networking and Mental Health. Cyberpsychol. Behav. Soc. Netw. 2014, 17, 652–657. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tanantong, T.; Sanglerdsinlapachai, N.; Donkhampai, U. Sentiment Classification on Thai Social Media Using a Domain-Specific Trained Lexicon. In Proceedings of the 2020 17th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Phuket, Thailand, 24–27 June 2020; pp. 580–583. [Google Scholar] [CrossRef]
- Tanantong, T.; Kreangkriwanich, S.; Laosen, N. Extraction of Trend Keywords from Thai Twitters using N-Gram Word Combination. In Proceedings of the 2020 17th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Phuket, Thailand, 24–27 June 2020; pp. 320–323. [Google Scholar] [CrossRef]
- Yi, S.; Liu, X. Machine learning based customer sentiment analysis for recommending shoppers, shops based on customers’ review. Complex Intell. Syst. 2020, 6, 621–634. [Google Scholar] [CrossRef]
- Mercorio, F.; Mezzanzanica, M.; Moscato, V.; Picariello, A.; Sperli, G. DICO: A Graph-DB Framework for Community Detection on Big Scholarly Data. IEEE Trans. Emerg. Top. Comput. 2019. [Google Scholar] [CrossRef]
- Ouyang, G.; Dey, D.K.; Zhang, P. Clique-Based Method for Social Network Clustering. J. Classif. 2020, 37, 254–274. [Google Scholar] [CrossRef] [Green Version]
- Abdolhosseini-Qomi, A.M.; Yazdani, N.; Asadpour, M. Overlapping communities and the prediction of missing links in multiplex networks. Phys. A Stat. Mech. Its Appl. 2020, 554, 124650. [Google Scholar] [CrossRef]
- Wang, P.; Xu, B.; Wu, Y.; Zhou, X. Link Prediction in Social Networks: The State-of-the-Art. arXiv 2014, arXiv:1411.5118. [Google Scholar] [CrossRef] [Green Version]
- Han, X.; Wang, L.; Han, S.N.; Chen, C.; Crespi, N.; Farahbakhsh, R. Link prediction for new users in Social Networks. In Proceedings of the 2015 IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 1250–1255. [Google Scholar] [CrossRef]
- Berlusconi, G.; Calderoni, F.; Parolini, N.; Verani, M.; Piccardi, C. Link Prediction in Criminal Networks: A Tool for Criminal Intelligence Analysis. PLoS ONE 2016, 11, e0154244. [Google Scholar] [CrossRef]
- Ahmed, C.; ElKorany, A.; Bahgat, R. A supervised learning approach to link prediction in Twitter. Soc. Netw. Anal. Min. 2016, 6, 24. [Google Scholar] [CrossRef]
- Hristova, D.; Noulas, A.; Brown, C.; Musolesi, M.; Mascolo, C. A multilayer approach to multiplexity and link prediction in online geo-social networks. EPJ Data Sci. 2016, 5, 24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martinčić-Ipšić, S.; Močibob, E.; Perc, M. Link prediction on Twitter. PLoS ONE 2017, 12, e0181079. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jalili, M.; Orouskhani, Y.; Asgari, M.; Alipourfard, N.; Perc, M. Link prediction in multiplex online social networks. R. Soc. Open Sci. 2017, 4, 160863. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sirisup, C.; Songmuang, P. Exploring Efficiency of Data Mining Techniques for Missing Link in Online Social Network. In Proceedings of the 2018 International Joint Symposium on Artificial Intelligence and Natural Language Processing (iSAI-NLP), Pattaya, Thailand, 15–17 November 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Akhtar, M.U.; Ahmad, I.; Khalil, M.I.K.; Ahmed, S. Missing Link Prediction in Complex Networks. Int. J. Sci. Eng. Res. 2018, 9, 82–87. [Google Scholar]
- Mandal, H.; Mirchev, M.; Gramatikov, S.; Mishkovski, I. Multilayer Link Prediction in Online Social Networks. In Proceedings of the 2018 26th Telecommunications Forum (TELFOR), Belgrade, Serbia, 20–21 November 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Ahmad, I.; Akhtar, M.U.; Noor, S.; Shahnaz, A. Missing Link Prediction using Common Neighbor and Centrality based Parameterized Algorithm. Sci. Rep. 2020, 10, 364. [Google Scholar] [CrossRef] [PubMed]
- Adamic, L.A.; Adar, E. Friends and Neighbors on the Web. Soc. Netw. 2001, 25, 211–230. [Google Scholar] [CrossRef] [Green Version]
- Fire, M.; Tenenboim, L.; Lesser, O.; Puzis, R.; Rokach, L.; Elovici, Y. Link Prediction in Social Networks Using Computationally Efficient Topological Features. In Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third International Conference on Social Computing, Boston, MA, USA, 9–11 October 2011; pp. 73–80. [Google Scholar] [CrossRef] [Green Version]
- McAuley, J.; Leskovec, J. Discovering Social Circles in Ego Networks. arXiv 2013, arXiv:1210.8182. [Google Scholar] [CrossRef] [Green Version]
- Pujari, M. Link Prediction in Large-Scale Complex Networks (Application to Bibliographical Networks). Ph.D. Thesis, Université Paris 13, Villetaneuse, France, 2015. [Google Scholar]
- Hoppe, B.; Reinelt, C. Social network analysis and the evaluation of leadership networks. Leadersh. Q. 2010, 21, 600–619. [Google Scholar] [CrossRef]
- Silva, T.; Zhao, L. Semi-supervised learning guided by the modularity measure in complex networks. Neurocomputing 2012, 78, 30–37. [Google Scholar] [CrossRef]
- Guimerà, R.; Danon, L.; Díaz-Guilera, A.; Giralt, F.; Arenas, A. Self-similar community structure in a network of human interactions. Phys. Rev. E 2003, 68. [Google Scholar] [CrossRef] [Green Version]
- McAuley, J.; Leskovec, J. Learning to Discover Social Circles in Ego Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems (NIPS’12)—Volume 1; Curran Associates Inc.: Red Hook, NY, USA, 2012; pp. 539–547. [Google Scholar]
- Ma, C.M.; Yang, W.S.; Cheng, B.W. How the Parameters of K-nearest Neighbor Algorithm Impact on the Best Classification Accuracy: In Case of Parkinson Dataset. J. Appl. Sci. 2014, 14, 171–176. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Neskovic, P.; Cooper, L.N. Improving Nearest Neighbor Rule with a Simple Adaptive Distance Measure. Pattern Recogn. Lett. 2007, 28, 207–213. [Google Scholar] [CrossRef]
- Thomas, A.J.; Petridis, M.; Walters, S.D.; Gheytassi, S.M.; Morgan, R.E. On Predicting the Optimal Number of Hidden Nodes. In Proceedings of the 2015 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 7–9 December 2015; pp. 565–570. [Google Scholar] [CrossRef]
- Panchal, F.S.; Panchal, M. Review on Methods of Selecting Number of Hidden Nodes in Artificial Neural Network. Int. J. Comput. Sci. Mob. Comput. 2014, 3, 455–464. [Google Scholar]
- Norouzi, M.; Collins, M.D.; Fleet, D.J.; Kohli, P. CO2 Forest: Improved Random Forest by Continuous Optimization of Oblique Splits. arXiv 2015, arXiv:1506.06155. [Google Scholar]
- Cuzzocrea, A.; Francis, S.L.; Gaber, M.M. An Information-Theoretic Approach for Setting the Optimal Number of Decision Trees in Random Forests. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 1013–1019. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | SN Sources | N | M | D |
|---|---|---|---|---|
| 1 | Twitter (Single-SN) | 200 | 265 | 0.01 |
| 2 | Twitter and Facebook with low density (Multi-SN-low) | 305 | 449 | 0.01 |
| 3 | Twitter and Facebook with high density (Multi-SN-high) | 305 | 823 | 0.02 |
| No. | Basic Features | Combined Features |
|---|---|---|
| 1 | Common neighbor | Common neighbor |
| 2 | Jaccard similarity | Jaccard similarity |
| 3 | Adamic/Adar similarity | Adamic/Adar similarity |
| 4 | Friend measure | Friend measure |
| 5 | Friend of similarity | Enhanced friend of similarity * |
| 6 | Facebook latent | Facebook latent |
| 7 | Common hashtag | Common hashtag |
| 8 | Common user mentioned | Common user mentioned |
| 9 | Frequency of user mentioned | Frequency of user mentioned |
| 10 | Response frequency | Response frequency |
| 11 | Node latent * | |
| 12 | Jaccard similarity of the second-order neighbor * | |
| 13 | Twitter latent * |
| Data Classification Techniques | Single-SN | Multi-SN-Low | Multi-SN-High | |||
|---|---|---|---|---|---|---|
| Basic Features | Combined Features | Basic Features | Combined Features | Basic Features | Combined Features | |
| kNN | 73.23 | 68.31 | 71.41 | 74.46 | 70.95 | 91.79 |
| ANN | 75.38 | 66.67 | 77.36 | 81.18 | 75.46 | 90.03 |
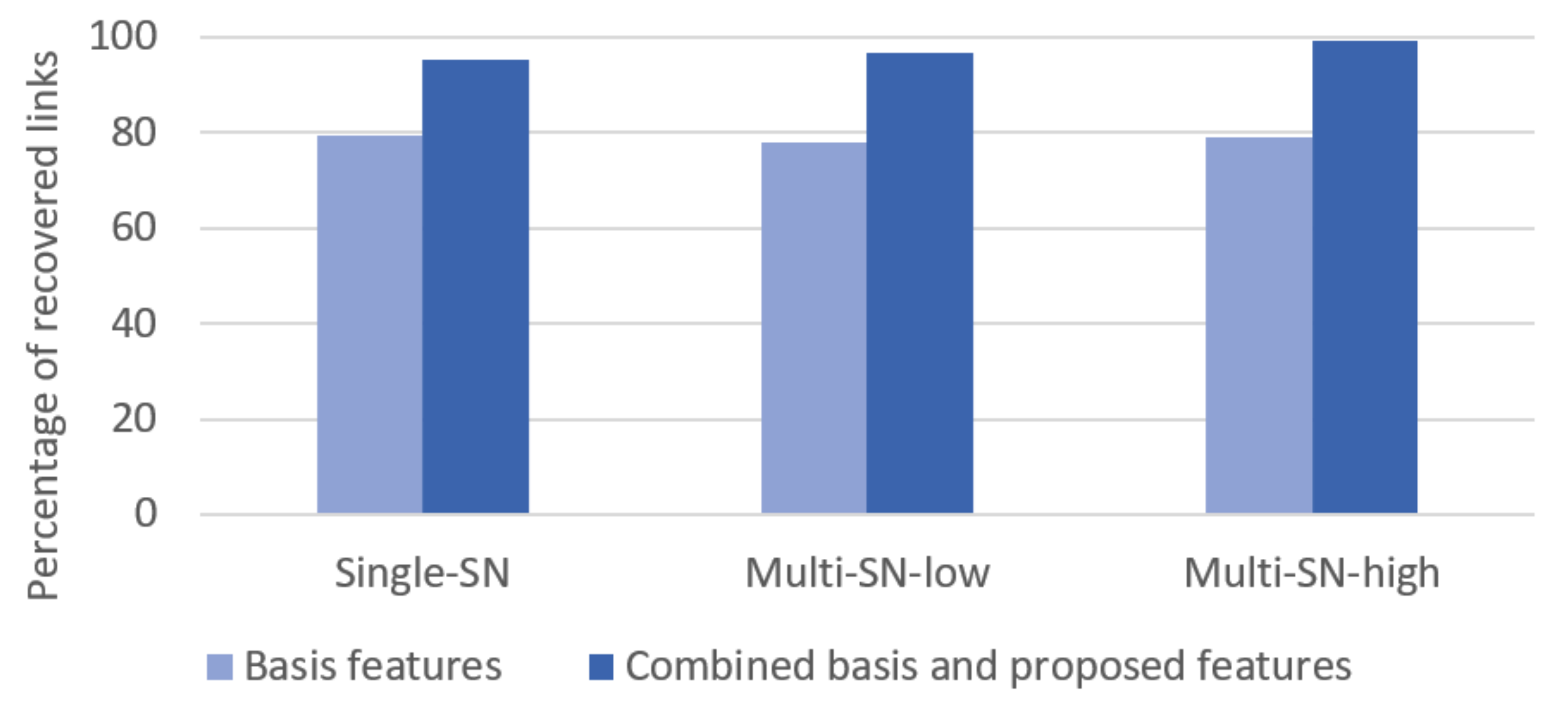
| RF | 79.38 | 95.46 | 77.85 | 96.62 | 79.08 | 99.15 |
| Data Classification Techniques | Single-SN | Multi-SN-Low | Multi-SN-High | |||
|---|---|---|---|---|---|---|
| Basic Features | Combined Features | Basic Features | Combined Features | Basic Features | Combined Features | |
| kNN | 0.66 | 0.67 | 0.69 | 0.63 | 0.69 | 0.86 |
| ANN | 0.73 | 0.74 | 0.73 | 0.63 | 0.76 | 0.84 |
| RF | 0.73 | 0.74 | 0.75 | 0.86 | 0.89 | 0.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Songmuang, P.; Sirisup, C.; Suebsriwichai, A. Missing Link Prediction Using Non-Overlapped Features and Multiple Sources of Social Networks. Information 2021, 12, 214. https://doi.org/10.3390/info12050214
Songmuang P, Sirisup C, Suebsriwichai A. Missing Link Prediction Using Non-Overlapped Features and Multiple Sources of Social Networks. Information. 2021; 12(5):214. https://doi.org/10.3390/info12050214
Chicago/Turabian StyleSongmuang, Pokpong, Chainarong Sirisup, and Aroonwan Suebsriwichai. 2021. "Missing Link Prediction Using Non-Overlapped Features and Multiple Sources of Social Networks" Information 12, no. 5: 214. https://doi.org/10.3390/info12050214
APA StyleSongmuang, P., Sirisup, C., & Suebsriwichai, A. (2021). Missing Link Prediction Using Non-Overlapped Features and Multiple Sources of Social Networks. Information, 12(5), 214. https://doi.org/10.3390/info12050214