
Quantitative and Qualitative Comparison of 2D and 3D Projection Techniques for High-Dimensional Data

 , ,
, , 
Abstract
:1. Introduction
- We run a quantitative study that compares 29 projection techniques, run to create both 2D and 3D scatterplots, from the perspective of 3 quality metrics over 8 high-dimensional datasets. We compare the computed quality metrics of the respective 2D and 3D scatterplots to gauge the added-value of the third dimension;
- We perform a qualitative user study that compares the resulting 2D and 3D projection scatterplots, augmented with the visual explanation proposed by Da Silva [22], from the perspective of explaining projection patterns by the data dimensions;
- Our two studies show that, in general, 3D projections have roughly the same quality (measured by metrics and user feedback) as compared to their 2D counterparts, while they require more effort to analyze. However, we also found that, in some cases, 3D projections—when augmented by visual explanations—can show more data structure; and they can motivate users to explore the data more than 2D projections do.
2. Related Work
2.1. Preliminaries
2.2. Evaluating Projections
2.3. Three-Dimensional Projections
2.4. Explaining Projections
3. Quantitative Study
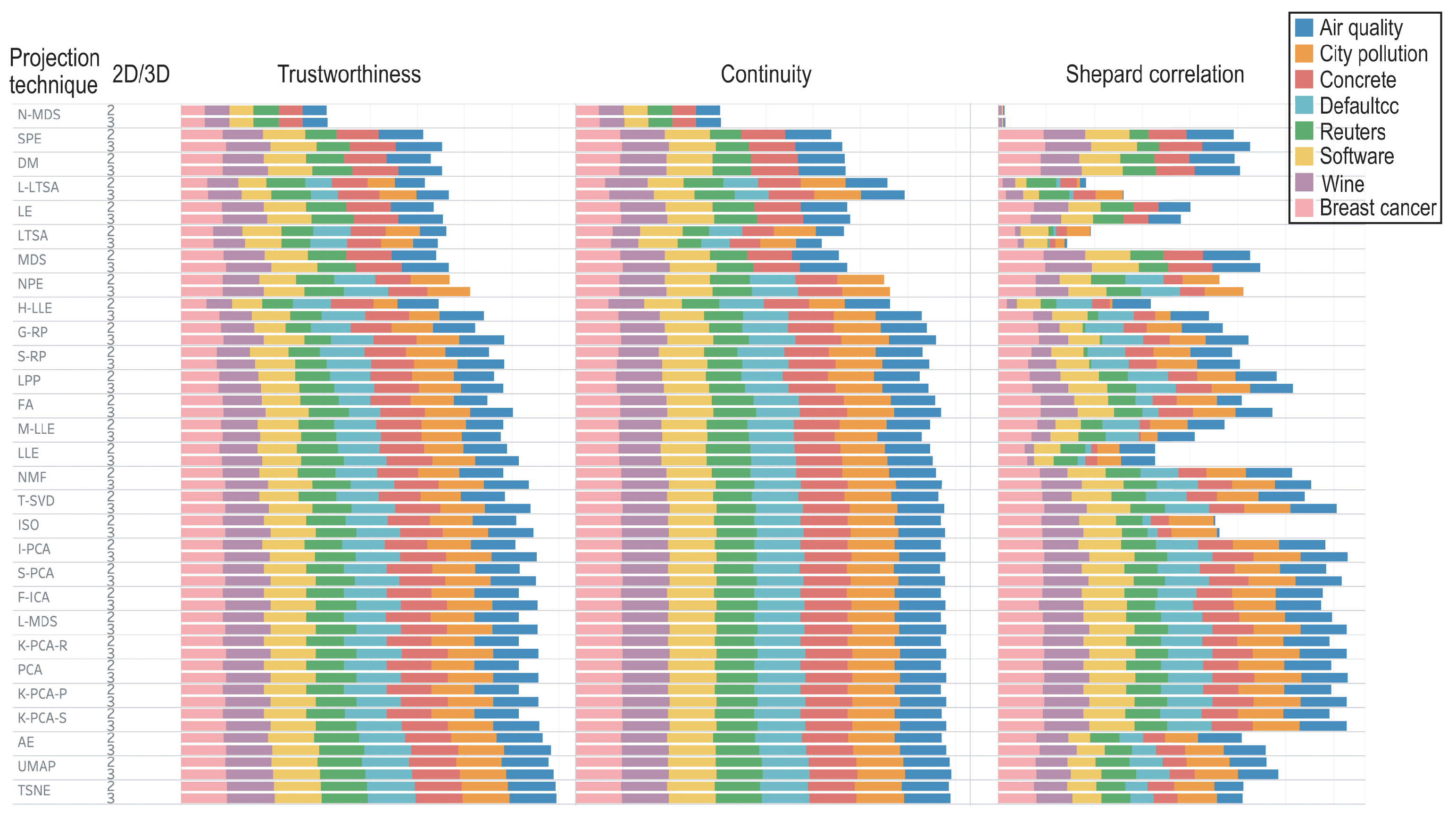
3.1. Datasets
3.2. Projections
3.3. Metrics
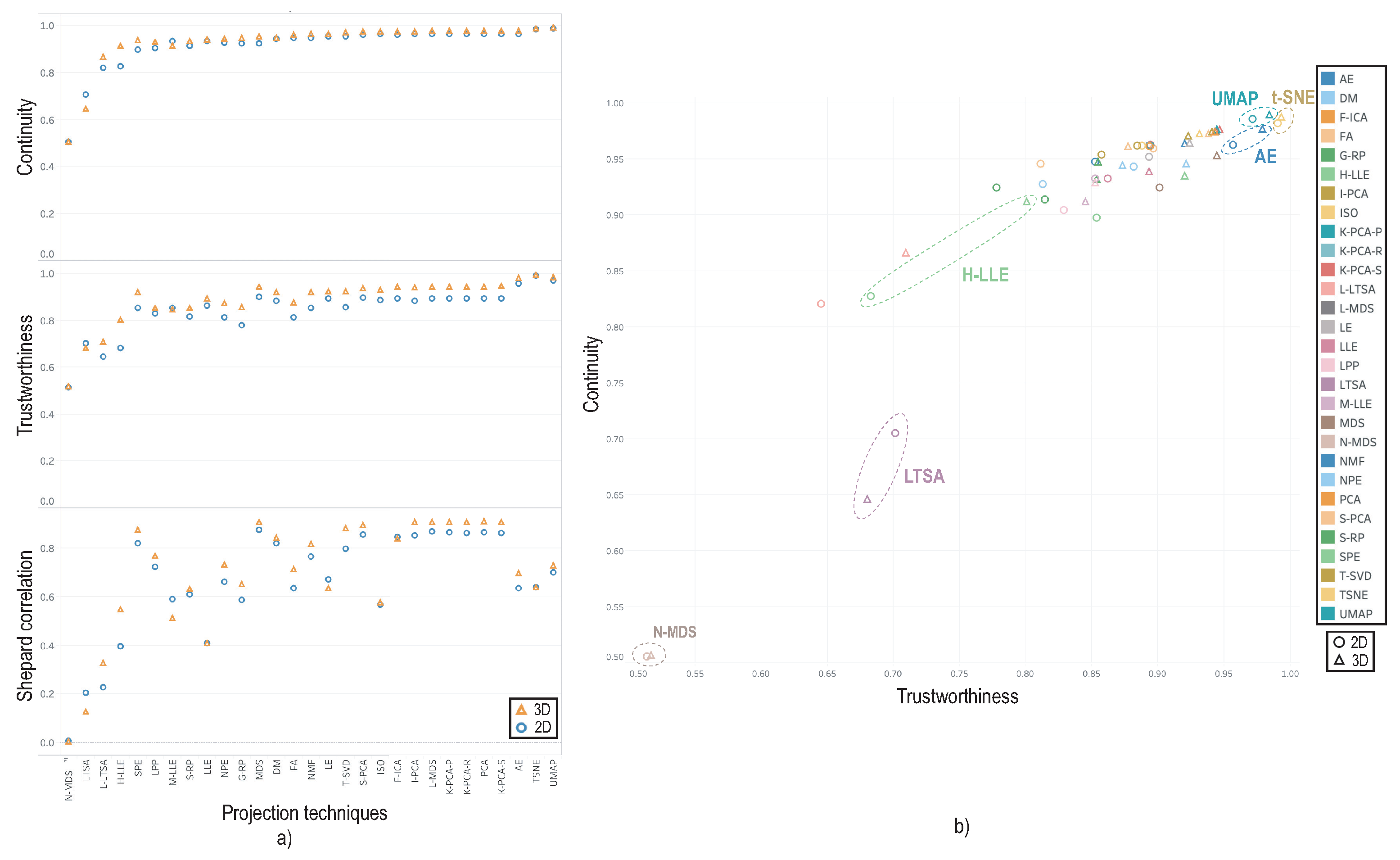
3.4. Evaluation Results
4. Qualitative Study
4.1. Identifying Visual Structure
4.2. Explaining Visual Structure
4.3. Expert Evaluation
- the 2D and 3D variants are equally good and informative;
- the 2D variant is clearly preferred;
- the 3D variantis clearly preferred;
- both variants are equally poor (hard to understand, thus useless).
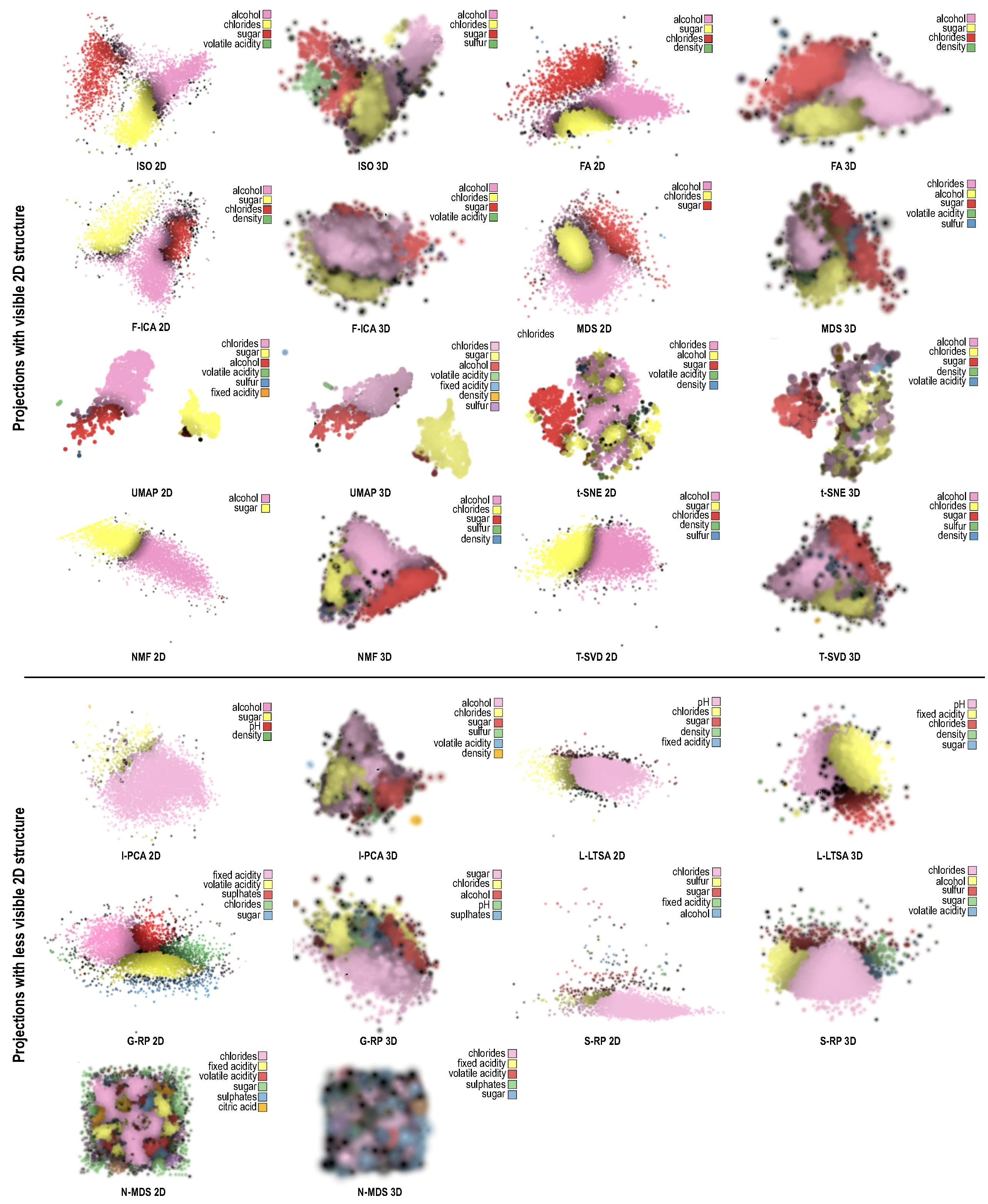
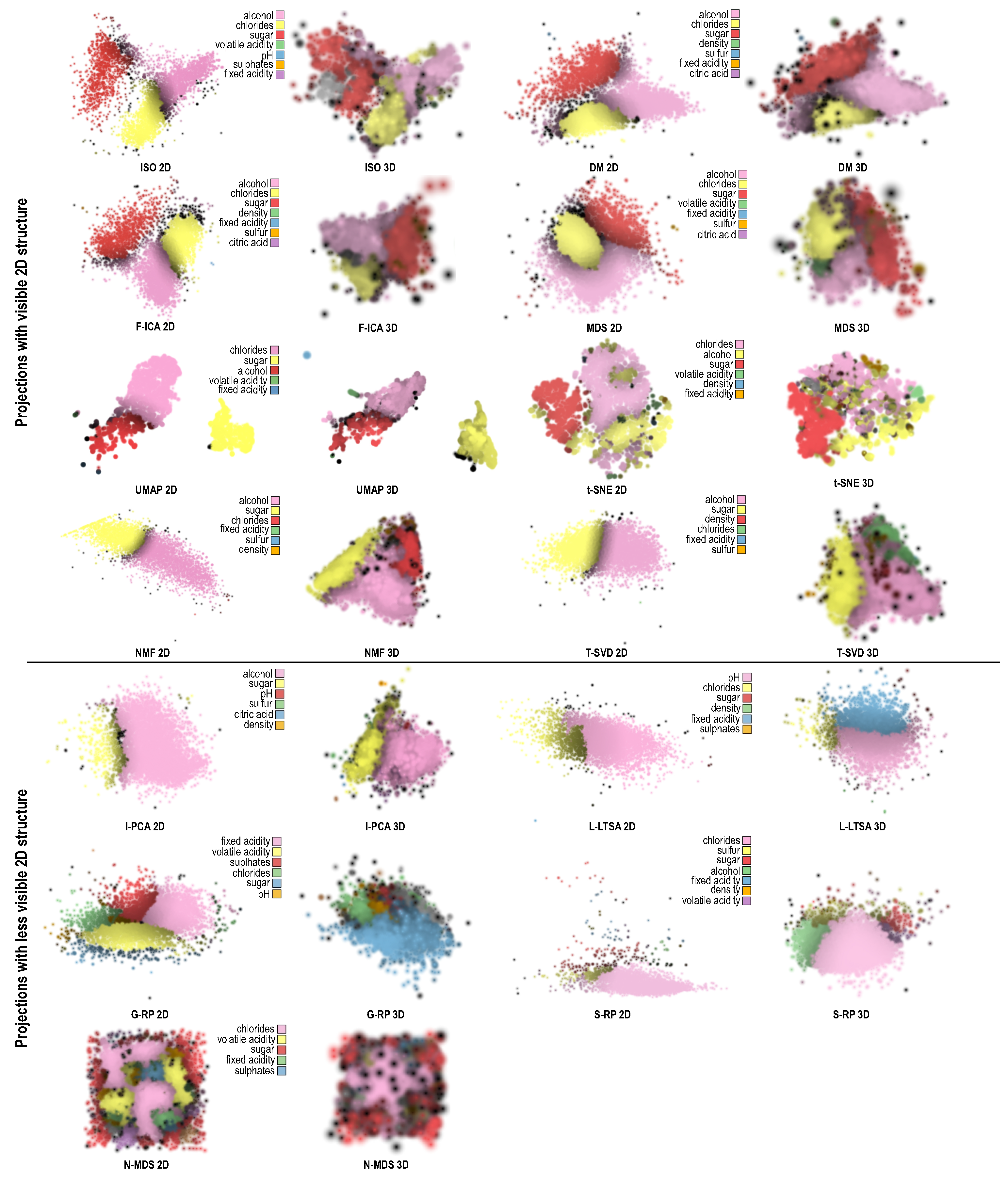
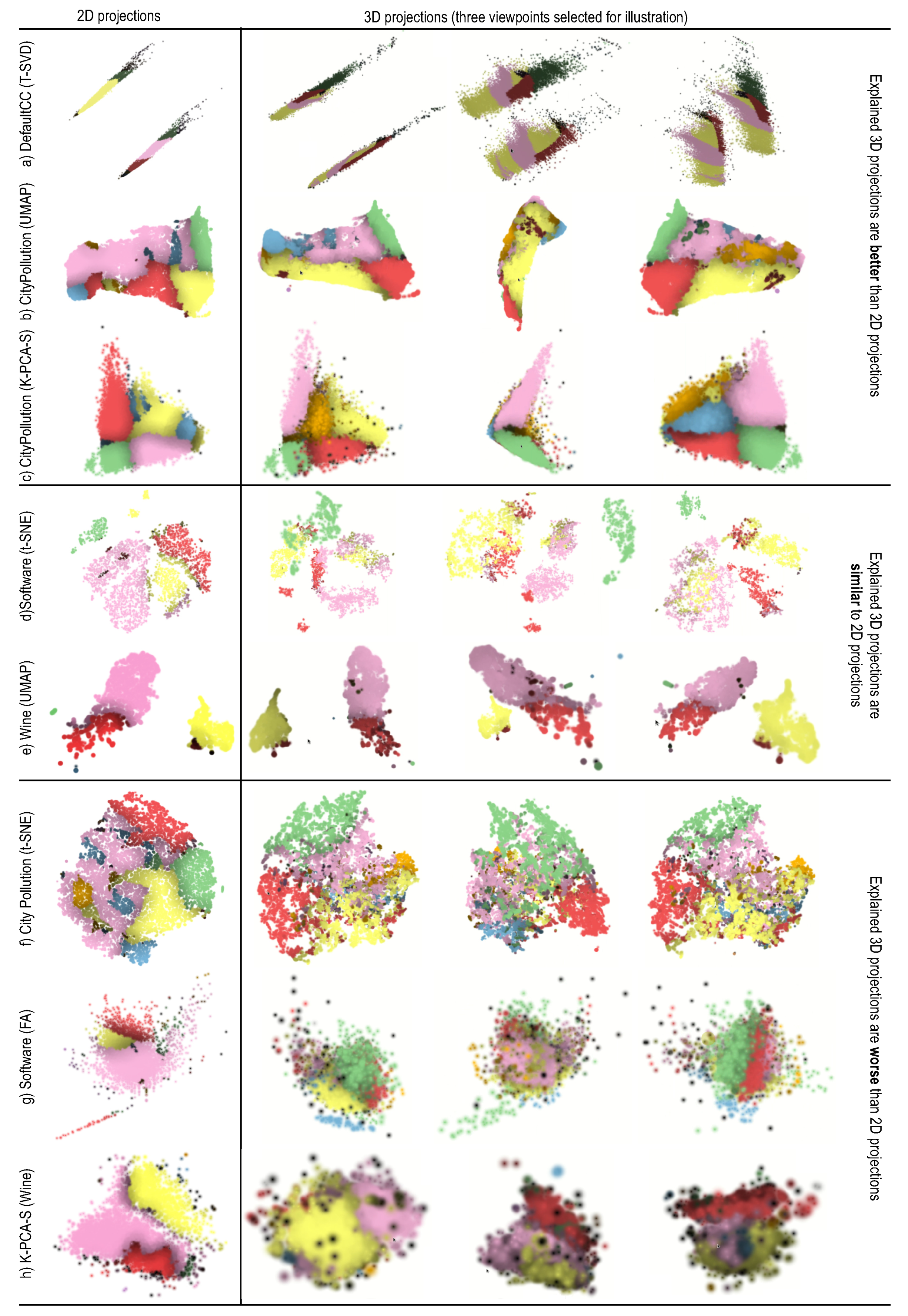
- 3D projections spread the points over a larger space, so can show more complex patterns. Figure 6a shows an example: the 2D T-SVD projection essentially creates two narrow bands along which little structure is visible. The 3D variant creates two plane-like structures that can show more explanation details. The 3D dimension also increases the chance that more variables will be involved in the explanation, which is good, since the explanation becomes more fine-grained. Figure 6b,c show this for CityPollution projected with UMAP and K-PCA-S: In both cases, the 2D projection cannot really show the orange cluster (points similar due to the dimension). This is because points are too tightly packed in 2D, so there is no room to ‘spread out’ this dimension. In 3D, the projections yield a similar (triangular-shape) surface to the 2D case. Yet, the additional spatial dimension allows spreading out points above the surface, so the orange cluster becomes visible. Also, the third dimension gives more chance for visual cluster separation as compared to 2D projections.
- 3D projections were found to give the user a sense of control in terms of selecting which are interesting views. While no ideal viewpoint can be found in general, different viewpoints could be used to show different parts of the data in turn, one by one. This allows further finding and exploring structures (one by one) which would otherwise be occluded, and have no chance to show up, in a 2D projection—see e.g., the three viewpoints for Figure 6b,c; only in two of these is the orange cluster visible. Overall, 3D projections were found more versatile than 2D ones, being able to tell different stories about the data, depending on the chosen viewpoint.
- One user remarked that the key advantage of 2D projections was their ease of use. No interaction is required to examine them, while one can get lost or frustrated in the process of zooming, panning, and viewpoint rotation for 3D projections. As such, this user noted that, in about 80% of the class-1 cases (2D found similar to 3D), this ignored the interaction effort. If this effort were to be considered, then those cases should be marked as class 2 (the 2D variant is preferred). Quoting from this user: “Both 2D and 3D are fine. Yet, I prefer 2D because it gives very clear results without further interaction needed”. Figure 6d,e show two such cases. The visible clusters and their explanations are very similar in 2D and 3D, so, for these cases, the 3D variant does not add any perceived value.
- Some projection techniques, in particular t-SNE, were consistently found to create clearer explanations in 2D than in 3D—something already visible in Figure 4 and Figure 5. This is an important observation, since t-SNE is known as a very high-quality projection. Such quality would, thus, be lost if using the 3D variant. Figure 6f shows this. The 3D t-SNE projection actually spreads points on a ball-like surface, with some points also being placed inside. It is very hard, even with interaction, to find out which points are close together on the same ‘side’ of the surface.
- 2D projections were definitely preferred in the cases where the nature of the data would create densely-packed clusters. These would map to close groups of points in the 2D projection (which are fine). In 3D, however, this would create a densely packed ‘hairball’ of regions explained by the different variables (Figure 6h). Occlusion would then prevent the user from discovering interesting structures and/or explanations inside such a 3D structure.
- Outliers were also found easier to spot with 2D projections. They would appear as points separated by large amounts of whitespace from the high-density ‘core’ of the projection. In 3D, however, outliers could appear in front or behind the high-density core, and thus be hard to spot (Figure 6h).
5. Discussion
- The question “which projection technique is the best for a given dataset type” is not in our scope. Rather, as explained in Section 1 and next in the paper, our research question is how can visual explanations and/or 3D projections bring added value. These questions do not focus on comparing projection techniques against each other, but the same techniques against their instances with or without visual explanations, and with or without a third dimension;
- Comparing ‘raw’ projection techniques against each other has been done in detail in [15]. As said earlier, we aim here not to compare raw techniques, but techniques with (or without) the additions of a third dimension and/or visual explanations;
- It is inherently hard to link the performance of projection techniques to the ‘nature’ of a given dataset. We did this by using the so-called dataset traits (dimensionality, intrinsic dimensionality, and sparsity) outlined in Section 3.1. Of course, additional traits can be defined, such as the nature of the distribution that characterizes the samples in a dataset. However, doing this is far from trivial: There are, to our knowledge, no established ‘classes’ of cannonical distributions for nD datasets. The goal of characterizing how projection techniques cope with various such distributions is definitely an interesting topic to study, but one out of the scope of our paper which focuses on comparing 2D vs. 3D projections, with vs. without visual explanations.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hoffman, P.; Grinstein, G. A survey of visualizations for high-dimensional data mining. Inf. Vis. Data Min. Knowl. Discov. 2002, 104, 47–82. [Google Scholar]
- Liu, S.; Maljovec, D.; Wang, B.; Bremer, P.T.; Pascucci, V. Visualizing High-Dimensional Data: Advances in the Past Decade. IEEE TVCG 2015, 23, 1249–1268. [Google Scholar] [CrossRef] [PubMed]
- Kehrer, J.; Hauser, H. Visualization and Visual Analysis of Multifaceted Scientific Data: A Survey. IEEE TVCG 2013, 19, 495–513. [Google Scholar] [CrossRef]
- Tang, J.; Liu, J.; Zhang, M.; Mei, Q. Visualizing Large-scale and High-dimensional Data. In Proceedings of the WWW, Montreal, QC, Canada, 11–15 April 2016; pp. 287–297. [Google Scholar]
- Inselberg, A.; Dimsdale, B. Parallel coordinates: A tool for visualizing multi-dimensional geometry. In Proceedings of the IEEE VIS, San Francisco, CA, USA, 23–26 October 1990; pp. 361–378. [Google Scholar]
- Rao, R.; Card, S.K. The Table Lens: Merging graphical and symbolic representations in an interactive focus+context visualization for tabular information. Proceedings of the ACM SIGCHI conference on Human factors in computing systems; ACM: New York, NY, USA, 1994; pp. 318–322. [Google Scholar]
- Telea, A.C. Combining Extended Table Lens and Treemap Techniques for Visualizing Tabular Data. Proceedings of the Eighth Joint Eurographics/IEEE VGTC conference on Visualization; ACM: New York, NY, USA, 2006; pp. 120–127. [Google Scholar]
- Becker, R.; Cleveland, W.; Shyu, M. The visual design and control of trellis display. J. Comput. Graph. Stat. 1996, 5, 123–155. [Google Scholar]
- Nonato, L.; Aupetit, M. Multidimensional Projection for Visual Analytics: Linking Techniques with Distortions, Tasks, and Layout Enrichment. IEEE TVCG 2018. [Google Scholar] [CrossRef]
- Sorzano, C.; Vargas, J.; Pascual-Montano, A. A survey of dimensionality reduction techniques. arXiv 2014, arXiv:1403.2877. [Google Scholar]
- van der Maaten, L.; Postma, E. Dimensionality Reduction: A Comparative Review; Technical Report, Tech. Report TiCC TR 2009-005; Tilburg University: Tilburg, The Netherlands, 2009. [Google Scholar]
- van der Maaten, L.; Hinton, G.E. Visualizing data using t-SNE. JMLR 2008, 9, 2579–2605. [Google Scholar]
- Yin, H. Nonlinear Dimensionality Reduction and Data Visualization: A Review. Int. J. Autom. Comput. 2007, 4, 294–303. [Google Scholar] [CrossRef]
- Heulot, N.; Fekete, J.D.; Aupetit, M. Visualizing Dimensionality Reduction Artifacts: An Evaluation. arXiv 2017, arXiv:1705.05283v1. [Google Scholar]
- Espadoto, M.; Martins, R.; Kerren, A.; Hirata, N.; Telea, A. Toward a Quantitative Survey of Dimension Reduction Techniques. IEEE TVCG 2019, 27, 2153–2173. [Google Scholar] [CrossRef]
- Poco, J.; Etemadpour, R.; Paulovich, F.V.; Long, T.; Rosenthal, P.; Oliveira, M.C.F.; Linsen, L.; Minghim, R. A framework for exploring multidimensional data with 3D projections. Comput. Graph Forum 2011, 30, 1111–1120. [Google Scholar] [CrossRef]
- Coimbra, D.; Martins, R.; Neves, T.; Telea, A.; Paulovich, F. Explaining three-dimensional dimensionality reduction plots. Inf. Vis. 2016, 15, 154–172. [Google Scholar] [CrossRef] [Green Version]
- Sedlmair, M.; Munzner, T.; Tory, M. Empirical guidance on scatterplot and dimension reduction technique choices. IEEE TVCG 2013, 19, 2634–2643. [Google Scholar] [CrossRef] [Green Version]
- Jolliffe, I.T. Principal Component Analysis; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Newby, G. Empirical study of a 3D visualization for information retrieval tasks. J. Intell. Inf. Syst. 2002, 18, 31–53. [Google Scholar] [CrossRef]
- Westerman, S.; Collins, J.; Cribbin, T. Browsing a document collection represented in two- and three- dimensional virtual information space. Int. J. Hum. Comput. Stud. 2005, 62, 713–736. [Google Scholar] [CrossRef]
- da Silva, R.; Rauber, P.; Martins, R.; Minghim, R.; Telea, A.C. Attribute-based Visual Explanation of Multidimensional Projections. In Proceedings of the EuroVA, Cagliari, Sardinia, 25–26 May 2015. [Google Scholar]
- van Driel, D.; Zhai, X.; Tian, Z.; Telea, A. Enhanced Attribute-Based Explanations of Multidimensional Projections; The Eurographics Association: Lyon, France, 2020. [Google Scholar]
- Tian, Z.; Zhai, X.; van Driel, D.; van Steenpaal, G.; Espadoto, M.; Telea, A. Using Multiple Attribute-Based Explanations of Multidimensional Projections to Explore High-Dimensional Data. Comput. Graph. 2021. [Google Scholar] [CrossRef]
- Pearson, K. On lines and planes of closest fit to systems of points in space. Philos. Mag. 1901, 2, 559–572. [Google Scholar] [CrossRef] [Green Version]
- Hotelling, H. Analysis of a Complex of Statistical Variables Into Principal Components. J. Edu. Pysiol. 1933, 24, 417–441. [Google Scholar]
- Fodor, I.K. A Survey of Dimension Reduction Techniques; Technical Report, Tech. Report UCRL-ID-148494; US Dept. of Energy, Lawrence Livermore National Labs: Livermore, CA, USA, 2002.
- Cunningham, J.; Ghahramani, Z. Linear Dimensionality Reduction: Survey, Insights, and Generalizations. JMLR 2015, 16, 2859–2900. [Google Scholar]
- Engel, D.; Hüttenberger, L.; Hamann, B. A Survey of Dimension Reduction Methods for High-dimensional Data Analysis and Visualization. In Proceedings of the IRTG Workshop, Freiburg, Germany, 8–9 November 2012; Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik: Wadern, Germany, 2012; Volume 27, pp. 135–149. [Google Scholar]
- Bunte, K.; Biehl, M.; Hammer, B. A general framework for dimensionality reducing data visualization mapping. Neural Comput. 2012, 24, 771–804. [Google Scholar] [CrossRef] [Green Version]
- Xie, H.; Li, J.; Xue, H. A survey of dimensionality reduction techniques based on random projection. arXiv 2017, arXiv:1706.04371. [Google Scholar]
- Dasgupta, S. Experiments with Random Projection. In Proceedings of the UAI. Morgan Kaufmann, Stanford, CA, USA, 30 June–3 July 2000; pp. 143–151. [Google Scholar]
- Buja, A.; Cook, D.; Swayne, D.F. Interactive High-Dimensional Data Visualization. J. Comput. Graph. Stat. 1996, 5, 78–99. [Google Scholar]
- Gisbrecht, A.; Hammer, B. Data visualization by nonlinear dimensionality reduction. Wires Data Min. Knowl. Discov. 2015, 5, 51–73. [Google Scholar] [CrossRef]
- Piringer, H.; Kosara, R.; Hauser, H. Interactive F+C visualization with linked 2D/3D scatterplots. Proceedings of the International Conference on Coordinated and Multiple Views in Exploratory Visulization; IEEE: Piscataway, NJ, USA, 2014; pp. 49–60. [Google Scholar]
- Elmqvist, N.; Dragicevic, P.; Fekete, J.D. Rolling the dice: multidimensional visual exploration using scatter- plot matrix navigation. IEEE TVCG 2008, 14, 1141–1148. [Google Scholar] [CrossRef] [Green Version]
- Sanftmann, H.; Weiskopf, D. Illuminated 3D scatterplots. Comput. Graph Forum 2009, 28, 642–651. [Google Scholar] [CrossRef]
- Tavanti, M.; Lind, M. 2D vs. 3D, implications on spatial memory. In Proceedings of the IEEE InfoVis, San Diego, CA, USA, 22–23 October 2001; pp. 139–145. [Google Scholar]
- Westerman, S.; Cribbin, T. Mapping semantic information in virtual space: Dimensions, variance and individual differences. Int. J. Hum. Comput. Stud. 2000, 53, 765–787. [Google Scholar] [CrossRef]
- Fabrikant, S.I. Spatial Metaphors for Browsing Large Data Archives. Ph.D. Thesis, University of Colorado Boulder, Boulder, CO, USA, 2000. [Google Scholar]
- Chan, Y.; Correa, C.; Ma, K.L. Regression cube: A technique for multidimensional visual exploration and interactive pattern finding. ACM Trans. Interact. Intell. Syst. 2014, 4. [Google Scholar] [CrossRef]
- Yuan, J.; Xiang, S.; Xia, J.; Yu, L.; Liu, S. Evaluation of Sampling Methods for Scatterplots. IEEE TVCG 2021, 27, 1720–1730. [Google Scholar] [CrossRef]
- Yu, L.; Efstathiou, K.; Isenberg, P.; Isenberg, T. Efficient Structure-Aware Selection Techniques for 3D Point Cloud Visualizations with 2DOF Input. IEEE TVCG 2012, 18, 2245–2254. [Google Scholar]
- Sanftmann, H.; Weiskopf, D. 3D scatterplot navigation. IEEE TVCG 2012, 18, 1969–1978. [Google Scholar] [CrossRef] [PubMed]
- TensorFlow. Embedding Projector Tool. 2021. Available online: https://projector.tensorflow.org (accessed on 31 May 2021).
- Paulovich, F.V.; Nonato, L.G.; Minghim, R.; Levkowitz, H. Least square projection: A fast high-precision multidimensional projection technique and its application to document mapping. IEEE TVCG 2008, 14, 564–575. [Google Scholar] [CrossRef]
- Eler, D.; Nakazaki, M.; Paulovich, F.; Santos, D.; Andery, G.; Oliveira, M.; Neto, J.; Minghim, R. Visual analysis of image collections. Vis. Comput. 2009, 25, 677–792. [Google Scholar] [CrossRef]
- Greenacre, M. Biplots in Practice; Fundacion BBVA: Bilbao, Spain, 2010. [Google Scholar]
- Gower, J.; Lubbe, S.; Roux, N. Understanding Biplots; Wiley: Hoboken, NJ, USA, 2011. [Google Scholar]
- Broeksema, B.; Baudel, T.; Telea, A. Visual Analysis of Multidimensional Categorical Datasets. Comput. Graph. Forum 2013, 32, 158–169. [Google Scholar] [CrossRef] [Green Version]
- Aupetit, M. Visualizing distortions and recovering topology in continuous projection techniques. Neurocomputing 2007, 10, 1304–1330. [Google Scholar] [CrossRef]
- Schreck, T.; von Landesberger, T.; Bremm, S. Techniques for precision-based visual analysis of projected data. Inf. Vis. 2010, 9, 181–193. [Google Scholar] [CrossRef] [Green Version]
- Martins, R.; Coimbra, D.; Minghim, R.; Telea, A.C. Visual analysis of dimensionality reduction quality for parameterized projections. Comput. Graph. 2014, 41, 26–42. [Google Scholar] [CrossRef]
- Paulovich, F.V.; Toledo, F.; Telles, G.; Minghim, R.; Nonato, L.G. Semantic Wordification of Document Collections. Comput. Fraphics Forum 2012, 31, 1145–1153. [Google Scholar] [CrossRef]
- Bellman, R. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Beyer, K.; Goldstein, J.; Ramakrishnan, R.; Shaft, U. When is “nearest neighbor” meaningful? In Proceedings of the International Conference on Database Theory, Jerusalem, Israel, 10–12 January 1999; pp. 217–235. [Google Scholar]
- Tenenbaum, J.B.; De Silva, V.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef] [PubMed]
- Vito, S.D.; Massera, E.; Piga, M.; Martinotto, L.; Francia, G.D. On field calibration of an electronic nose for benzene estimation in an urban pollution monitoring scenario. Sens. Actuators B Chem. 2008, 129, 750–757. Available online: https://archive.ics.uci.edu/ml/datasets/Air+Quality (accessed on 31 May 2021). [CrossRef]
- Wisconsin Breast Cancer Dataset. 2021. Available online: https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic) (accessed on 31 May 2021).
- Zhang, S.; Guo, B.; Dong, A.; He, J.; Xu, Z.; Chen, S. Cautionary Tales on Air-Quality Improvement in Beijing. Proc. R. Soc. A 2017, 473, 20170457. Available online: https://archive.ics.uci.edu/ml/datasets/Beijing+Multi-Site+Air-Quality+Data (accessed on 31 May 2021). [CrossRef] [Green Version]
- Concrete Compressive Strength Dataset. 2021. Available online: https://archive.ics.uci.edu/ml/datasets/concrete+compressive+strength (accessed on 31 May 2021).
- Default of Credit Card Clients Dataset. 2021. Available online: https://archive.ics.uci.edu/ml/datasets/default+of+credit+card+clients (accessed on 31 May 2021).
- Meirelles, P.; Santos, C.; Miranda, J.; Kon, F.; Terceiro, A.; Chavez, C. A study of the relationships between source code metrics and attractiveness in free software projects. In Proceedings of the Brazilian Symposium on Software Engineering (SBES), Sao Carlos, Brazil, 17–21 September 2010; pp. 11–20. [Google Scholar]
- Wine Dataset. 2021. Available online: https://archive.ics.uci.edu/ml/datasets/wine+quality (accessed on 31 May 2021).
- Reuters Dataset. 2021. Available online: https://keras.io/api/datasets/reuters (accessed on 31 May 2021).
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Coifman, R.R.; Lafon, S. Diffusion maps. Appl. Comput. Harmon. Anal. 2006, 21, 5–30. [Google Scholar] [CrossRef] [Green Version]
- Jolliffe, I.T. Principal component analysis and factor analysis. In Principal Component Analysis; Springer: Berlin/Heidelberg, Germany, 1986; pp. 115–128. [Google Scholar]
- Hyvarinen, A. Fast ICA for noisy data using Gaussian moments. In Proceedings of the IEEE ISCAS, Orlando, FL, USA, 30 May–2 June 1999; Volume 5, pp. 57–61. [Google Scholar]
- Donoho, D.L.; Grimes, C. Hessian eigenmaps: Locally linear embedding techniques for high-dimensional data. Proc. Natl. Acad. Sci. USA 2003, 100, 5591–5596. [Google Scholar] [CrossRef] [Green Version]
- Ross, D.A.; Lim, J.; Lin, R.S.; Yang, M.H. Incremental learning for robust visual tracking. Int. J. Comput. Vis. 2008, 77, 125–141. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.; Müller, K.R. Kernel principal component analysis. In Proceedings of the ICANN, Lausanne, Switzerland, 8–10 October 1997; pp. 583–588. [Google Scholar]
- Belkin, M.; Niyogi, P. Laplacian Eigenmaps and Spectral Techniques for Embedding and Clustering; MIT Press: Cambridge, CA, USA, 2002; pp. 585–591. [Google Scholar]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Yang, J.; Zhao, D.; Ge, X. Linear local tangent space alignment and application to face recognition. Neurocomputing 2007, 70, 1547–1553. [Google Scholar] [CrossRef]
- De Silva, V.; Tenenbaum, J.B. Sparse Multidimensional Scaling Using Landmark Points; Technical Report; Stanford University: Stanford, CA, USA, 2004. [Google Scholar]
- He, X.; Niyogi, P. Locality preserving projections. In Proceedings of the NIPS, Vancouver, BC, Canada, 3–8 December 2004; pp. 153–160. [Google Scholar]
- Zhang, Z.; Zha, H. Principal manifolds and nonlinear dimensionality reduction via tangent space alignment. SIAM J. Sci. Comput. 2004, 26, 313–338. [Google Scholar] [CrossRef] [Green Version]
- Torgerson, W.S. Theory and Methods of Scaling; Wiley: Hoboken, NJ, USA, 1958. [Google Scholar]
- Zhang, Z.; Wang, J. MLLE: Modified locally linear embedding using multiple weights. In Proceedings of the NIPS, Kitakyushu, Japan, 13–16 November 2007; pp. 1593–1600. [Google Scholar]
- Kruskal, J.B. Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis. Psychometrika 1964, 29, 1–27. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Algorithms for non-negative matrix factorization. In Proceedings of the NIPS, Vancouver, BC, Canada, 3–8 December 2001; pp. 556–562. [Google Scholar]
- He, X.; Cai, D.; Yan, S.; Zhang, H. Neighborhood preserving embedding. In Proceedings of the IEEE ICCV, Beijing, China, 17–21 October 2005; pp. 1208–1213. [Google Scholar]
- Zou, H.; Hastie, T.; Tibshirani, R. Sparse principal component analysis. J. Comput. Graph. Stat. 2006, 15, 265–286. [Google Scholar] [CrossRef] [Green Version]
- Agrafiotis, D.K. Stochastic proximity embedding. J. Comput. Chem. 2003, 24, 1215–1221. [Google Scholar] [CrossRef]
- Halko, N.; Martinsson, P.G.; Tropp, J.A. Finding structure with randomness: Stochastic algorithms for constructing approximate matrix decompositions. arXiv 2009, arXiv:0909.4061. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2018, arXiv:1802.03426v2. [Google Scholar]
- Venna, J.; Kaski, S. Visualizing gene interaction graphs with local multidimensional scaling. In Proceedings of the ESANN, Bruges, Belgium, 26–28 April 2006; pp. 557–562. [Google Scholar]
- Martins, R.; Minghim, R.; Telea, A.C. Explaining neighborhood preservation for multidimensional projections. In Proceedings of the CGVC, Eurographics, London, UK, 16–17 September 2015; pp. 121–128. [Google Scholar]
- Joia, P.; Coimbra, D.; Cuminato, J.A.; Paulovich, F.V.; Nonato, L.G. Local affine multidimensional projection. IEEE TVCG 2011, 17, 2563–2571. [Google Scholar] [CrossRef] [PubMed]
- Lespinats, S.; Aupetit, M. CheckViz: Sanity check and topological clues for linear and Nonlinear mappings. Comput. Graph. Forum 2011, 30, 113–125. [Google Scholar] [CrossRef]
- Lee, J.A.; Verleysen, M. Quality assessment of dimensionality reduction: Rank-based criteria. Neurocomputing 2009, 72, 1431–1443. [Google Scholar] [CrossRef]
- Sips, M.; Neubert, B.; Lewis, J.; Hanrahan, P. Selecting good views of high-dimensional data using class consistency. Comput. Graph Forum 2009, 28, 831–838. [Google Scholar] [CrossRef]
- Tatu, A.; Bak, P.; Bertini, E.; Keim, D.; Schneidewind, J. Visual quality metrics and human perception: An initial study on 2D projections of large multidimensional data. In Proceedings of the AVI, ACM, Roma, Italy, 26–28 May 2010; pp. 49–56. [Google Scholar]
- Albuquerque, G.; Eisemann, M.; Magnor, M. Perception-based visual quality measures. In Proceedings of the IEEE VAST, Providence, RI, USA, 23–28 October 2011; pp. 11–18. [Google Scholar]
- Motta, R.; Minghim, R.; Lopes, A.; Oliveira, M. Graph-based measures to assist user assessment of multidimensional projections. Neurocomputing 2015, 150, 583–598. [Google Scholar] [CrossRef]
- Sedlmair, M.; Aupetit, M. Data-driven Evaluation of Visual Quality Measures. Comput. Graph Forum 2015, 34, 545–559. [Google Scholar] [CrossRef]
- Comparing 2D and 3D Explained Projections—Evaluation Datasets, Metrics, and Results. 2021. Available online: https://tianzonglin.github.io/project-compare (accessed on 31 May 2021).
- Explanatory Visualization Tool for 2D and 3D Projections. 2021. Available online: https://git.science.uu.nl/vig/mscprojects/Pointctl (accessed on 31 May 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Type | Samples N | Dimensions n | Intrinsic Dimensionality | Sparsity |
|---|---|---|---|---|---|
| Air quality [58] | tables | 9357 | 13 | 5 | 0.1372 |
| Breast cancer [59] | tables | 569 | 30 | 10 | 0.0059 |
| City pollution [60] | tables | 32,681 | 10 | 6 | 0.0052 |
| Concrete [61] | tables | 1030 | 8 | 6 | 0.1773 |
| DefaultCC [62] | tables | 30,000 | 23 | 8 | 0.1070 |
| Software [63] | tables | 6773 | 12 | 7 | 0.0818 |
| Wine [64] | tables | 6497 | 11 | 8 | 0.0023 |
| Reuters [65] | text | 8432 | 1000 | 696 | 0.9488 |
| Projection | linearity | Input | Neighborhood | Complexity | Out-of-Sample | Deterministic | Implementation |
|---|---|---|---|---|---|---|---|
| AE [66] | nonlinear | samples | global | yes | no | Keras | |
| DM [67] | nonlinear | samples | local | no | yes | Tapkee | |
| FA [68] | linear | samples | global | yes | yes | scikit-learn | |
| F-ICA [69] | linear | samples | global | yes | yes | scikit-learn | |
| G-RP [32] | nonlinear | samples | global | yes | no | scikit-learn | |
| H-LLE [70] | nonlinear | samples | local | yes | no | scikit-learn | |
| I-PCA [71] | linear | samples | global | yes | no | scikit-learn | |
| ISO [57] | nonlinear | samples | local | yes | yes | scikit-learn | |
| K-PCA-P [72] | nonlinear | samples | global | yes | no | scikit-learn | |
| K-PCA-R [72] | nonlinear | samples | global | yes | no | scikit-learn | |
| K-PCA-S [72] | nonlinear | samples | global | yes | no | scikit-learn | |
| LE [73] | nonlinear | distances | local | no | no | scikit-learn | |
| LLE [74] | nonlinear | samples | local | yes | no | scikit-learn | |
| L-LTSA [75] | linear | samples | local | no | no | Tapkee | |
| L-MDS [76] | nonlinear | distances | global | no | no | Tapkee | |
| LPP [77] | linear | samples | global | yes | yes | Tapkee | |
| LTSA [78] | nonlinear | samples | local | yes | no | scikit-learn | |
| MDS [79] | nonlinear | distances | global | no | no | scikit-learn | |
| M-LLE [80] | nonlinear | samples | local | yes | no | scikit-learn | |
| N-MDS [81] | nonlinear | samples | global | no | no | scikit-learn | |
| NMF [82] | linear | samples | global | yes | no | scikit-learn | |
| NPE [83] | nonlinear | samples | local | yes | no | Tapkee | |
| PCA [68] | linear | samples | global | yes | yes | scikit-learn | |
| S-PCA [84] | linear | samples | global | yes | yes | scikit-learn | |
| SPE [85] | nonlinear | samples | global | no | no | Tapkee | |
| S-RP [32] | nonlinear | samples | global | yes | no | scikit-learn | |
| T-SNE [12] | nonlinear | distances | local | no | no | Multicore TSNE | |
| T-SVD [86] | linear | samples | global | yes | no | scikit-learn | |
| UMAP [87] | nonlinear | distances | local | yes | no | umap-learn |
| Metric | Definition |
|---|---|
| Trustworthiness () | |
| Continuity () | |
| Shepard diagram (S) | |
| Shepard goodness () | Spearman rank correlation of S |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, Z.; Zhai, X.; van Steenpaal, G.; Yu, L.; Dimara, E.; Espadoto, M.; Telea, A. Quantitative and Qualitative Comparison of 2D and 3D Projection Techniques for High-Dimensional Data. Information 2021, 12, 239. https://doi.org/10.3390/info12060239
Tian Z, Zhai X, van Steenpaal G, Yu L, Dimara E, Espadoto M, Telea A. Quantitative and Qualitative Comparison of 2D and 3D Projection Techniques for High-Dimensional Data. Information. 2021; 12(6):239. https://doi.org/10.3390/info12060239
Chicago/Turabian StyleTian, Zonglin, Xiaorui Zhai, Gijs van Steenpaal, Lingyun Yu, Evanthia Dimara, Mateus Espadoto, and Alexandru Telea. 2021. "Quantitative and Qualitative Comparison of 2D and 3D Projection Techniques for High-Dimensional Data" Information 12, no. 6: 239. https://doi.org/10.3390/info12060239
APA StyleTian, Z., Zhai, X., van Steenpaal, G., Yu, L., Dimara, E., Espadoto, M., & Telea, A. (2021). Quantitative and Qualitative Comparison of 2D and 3D Projection Techniques for High-Dimensional Data. Information, 12(6), 239. https://doi.org/10.3390/info12060239