
An Online Iterative Linear Quadratic Approach for a Satisfactory Working Point Attainment at FERMI

 , , , , , and
, , , , , and
Abstract
:1. Introduction
2. Materials and Methods
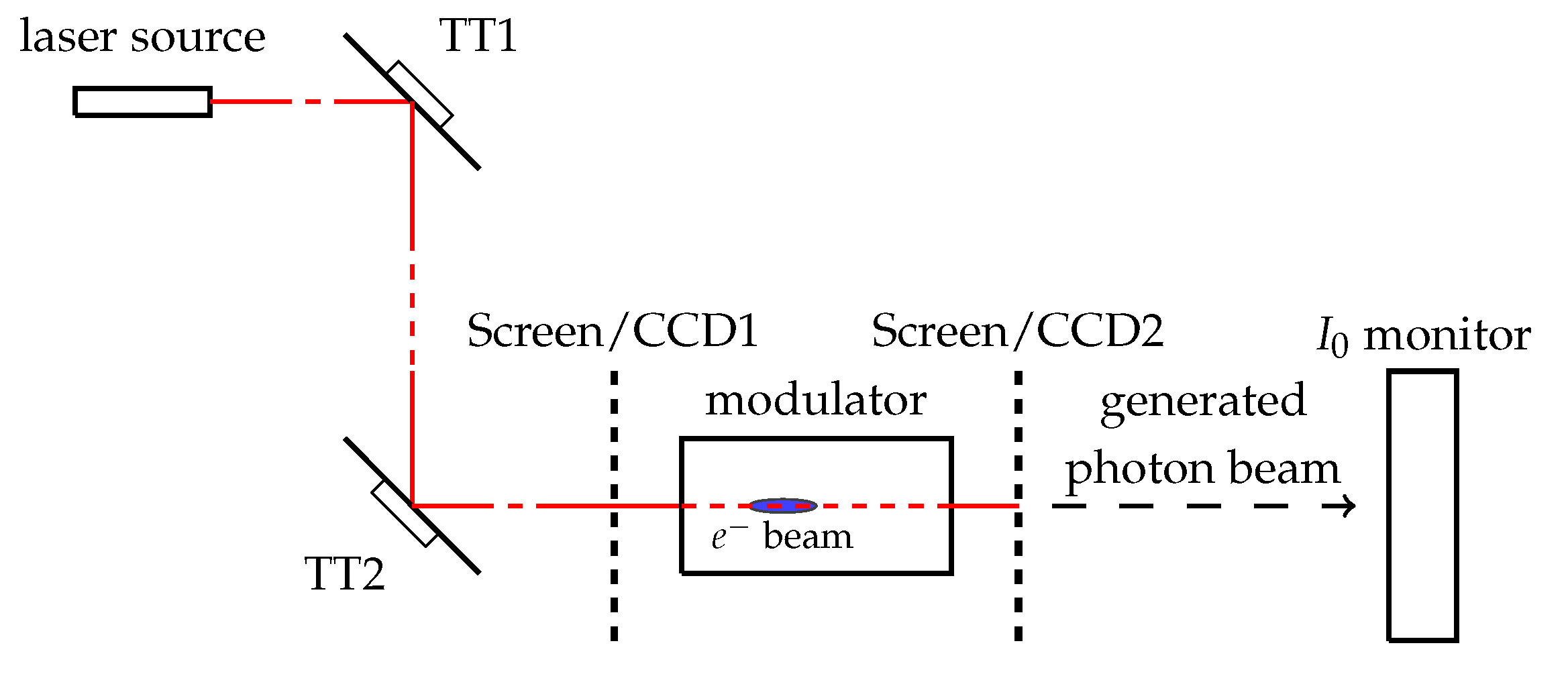
2.1. FERMI Facility
2.2. Iterative Linear Quadratic Regulator
- the non-linear system is linearized around a nominal trajectory , and the result of a nominal control sequence applied to the open-loop system;
- a finite-horizon LQR problem is solved, providing as output a new control sequence ; where are the gain matrices that solve the finite-horizon LQR problem and is the vector operator.
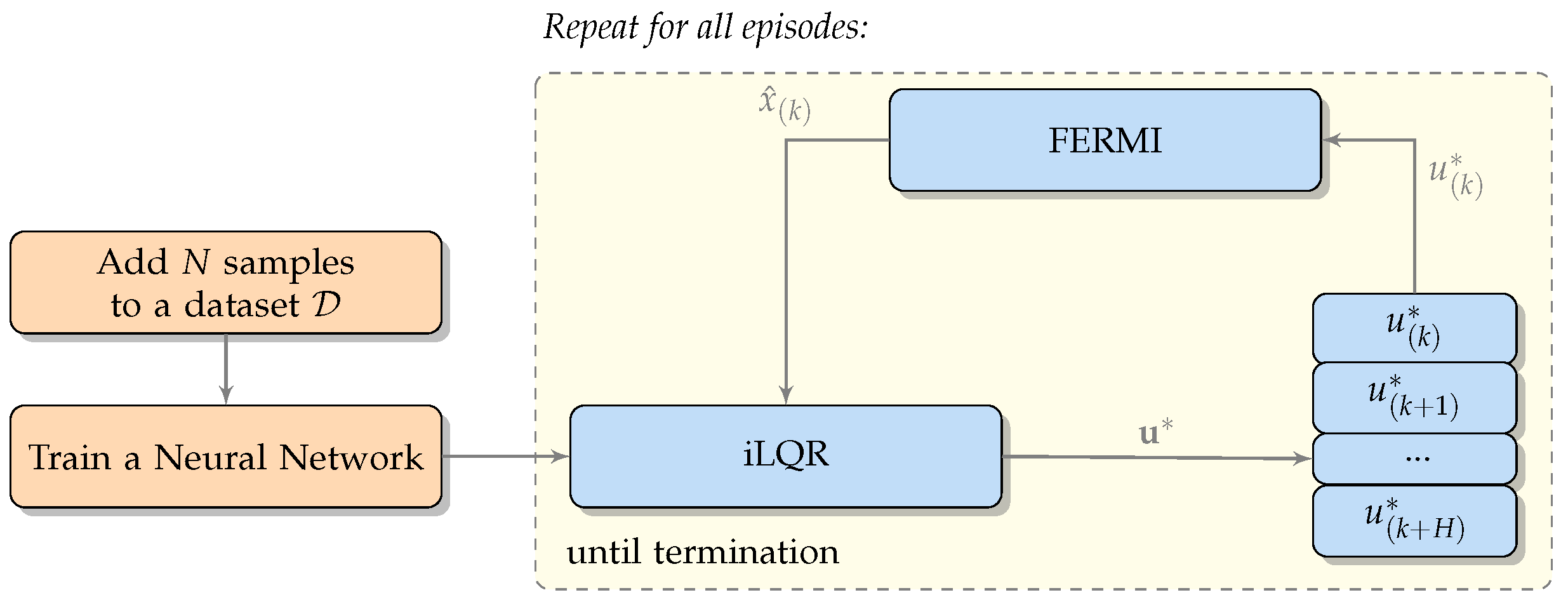
2.3. Online iLQR and Augmented State
3. Implementations and Results
3.1. Experimental Procedure
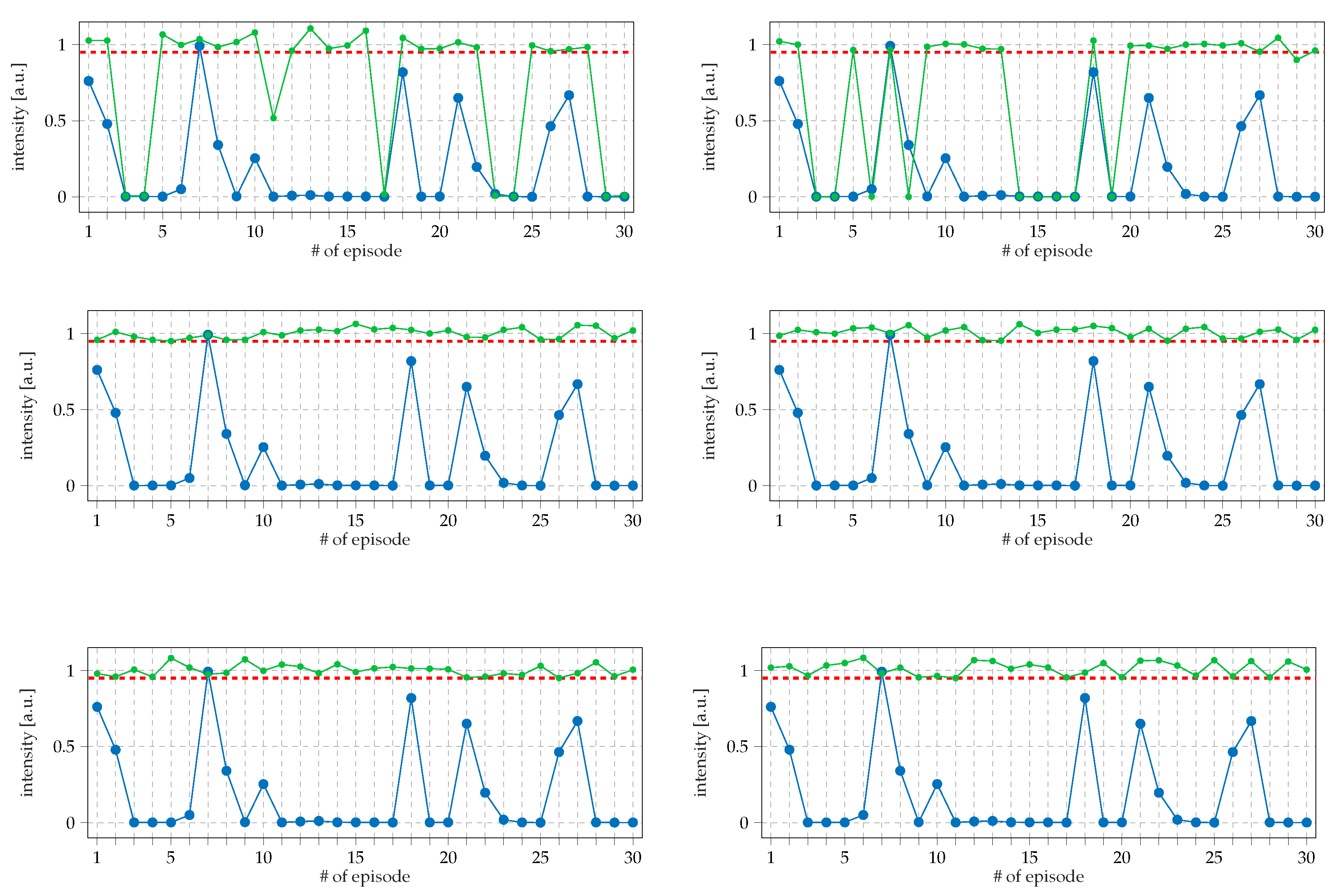
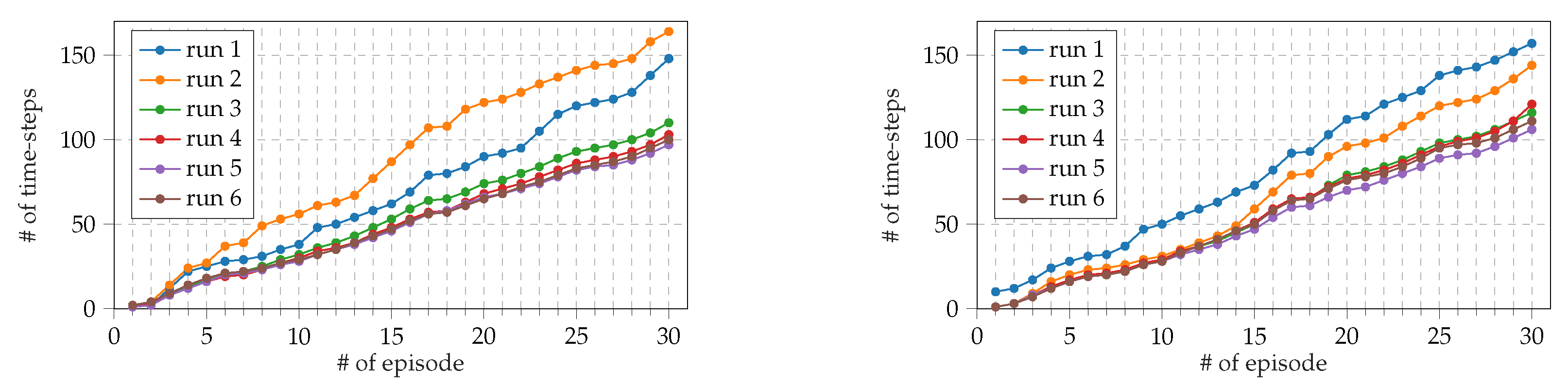
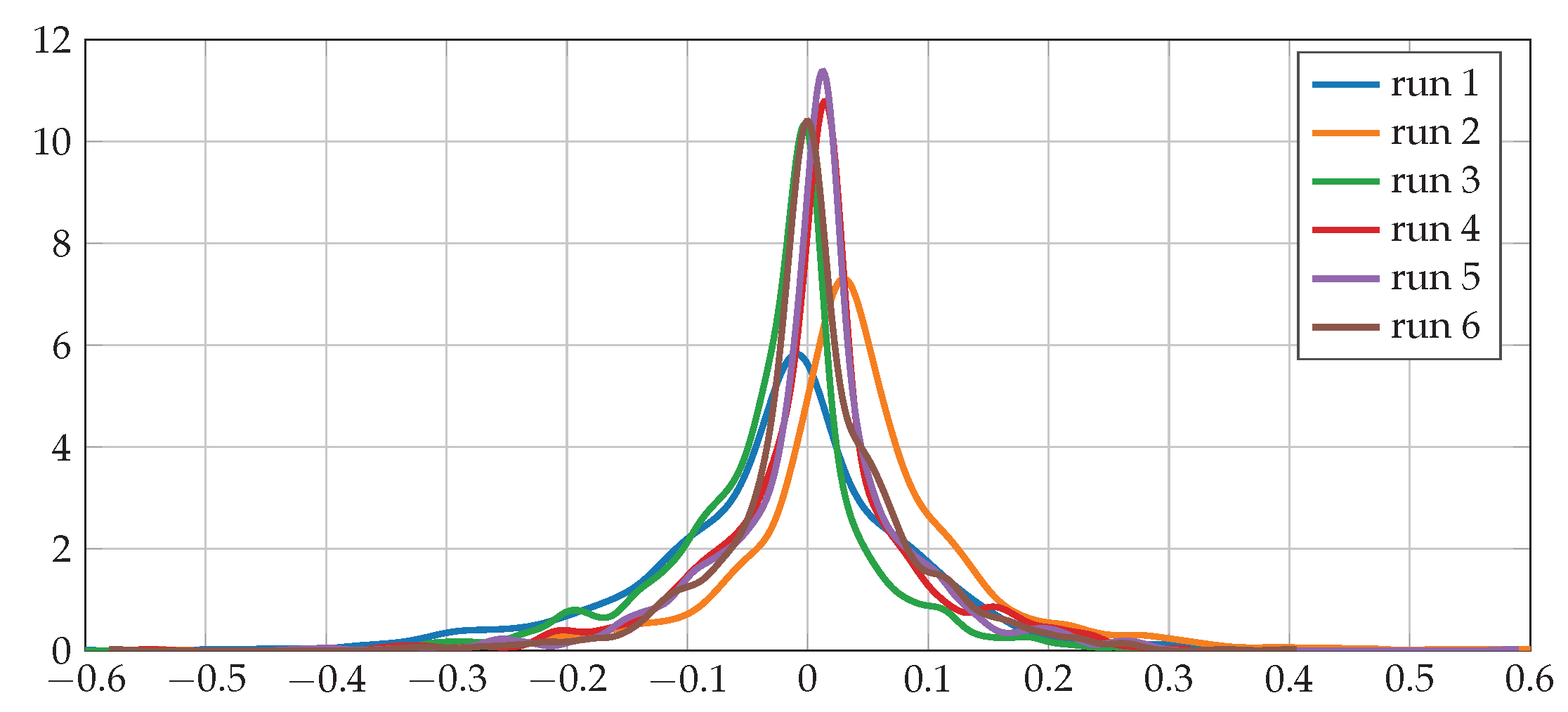
3.2. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FEL | Free-electron laser |
| SASE | Self-amplified spontaneous emission |
| SLAC | Stanford linear accelerator center |
| FLASH | Free electron laser in Hamburg |
| DESY | Deutsches elektronen-synchrotron |
| ML | Machine learning |
| RL | Reinforcement learning |
| FERMI | Free electron laser radiation for multidisciplinary investigation |
| iLQR | Iterative linear quadratic regulator |
| AWAKE | Advanced proton driven plasma wakefield acceleration experiment |
| CERN | Conseil europén pour la recherche nucléaire |
| NN | Neural network |
| MPC | Model-predictive control |
| GA | Gradient ascent |
| TT | Tip–tilt |
| YAG | Yttrium aluminum garnet |
| CCD | Charge-coupled device |
| LQR | Linear quadratic regulator |
References
- Colson, W. Theory of a free electron laser. Phys. Lett. A 1976, 59, 187–190. [Google Scholar] [CrossRef]
- Kim, K.J. An analysis of self-amplified spontaneous emission. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrom. Detect. Assoc. Equip. 1986, 250, 396–403. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.H. Generation of intense UV radiation by subharmonically seeded single-pass free-electron lasers. Phys. Rev. A 1991, 44, 5178. [Google Scholar] [CrossRef] [PubMed]
- Allaria, E.; Appio, R.; Badano, L.; Barletta, W.; Bassanese, S.; Biedron, S.; Borga, A.; Busetto, E.; Castronovo, D.; Cinquegrana, P.; et al. Highly coherent and stable pulses from the FERMI seeded free-electron laser in the extreme ultraviolet. Nat. Photonics 2012, 6, 699. [Google Scholar] [CrossRef]
- Allaria, E.; Castronovo, D.; Cinquegrana, P.; Craievich, P.; Dal Forno, M.; Danailov, M.; D’Auria, G.; Demidovich, A.; De Ninno, G.; Di Mitri, S.; et al. Two-stage seeded soft-X-ray free-electron laser. Nat. Photonics 2013, 7, 913. [Google Scholar] [CrossRef]
- Allaria, E.; Badano, L.; Bassanese, S.; Capotondi, F.; Castronovo, D.; Cinquegrana, P.; Danailov, M.; D’Auria, G.; Demidovich, A.; De Monte, R.; et al. The FERMI free-electron lasers. J. Synchrotron Radiat. 2015, 22, 485–491. [Google Scholar] [CrossRef] [PubMed]
- Tomin, S.; Geloni, G.; Zagorodnov, I.; Egger, A.; Colocho, W.; Valentinov, A.; Fomin, Y.; Agapov, I.; Cope, T.; Ratner, D.; et al. Progress in Automatic Software-based Optimization of Accelerator Performance. In Proceedings of the 7th International Particle Accelerator Conference (IPAC 2016), Busan, Korea, 8–13 May 2016. [Google Scholar]
- Bruchon, N.; Fenu, G.; Gaio, G.; Lonza, M.; Pellegrino, F.A.; Saule, L. Free-electron laser spectrum evaluation and automatic optimization. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrom. Detect. Assoc. Equip. 2017, 871, 20–29. [Google Scholar] [CrossRef] [Green Version]
- Agapov, I.; Geloni, G.; Tomin, S.; Zagorodnov, I. OCELOT: A software framework for synchrotron light source and FEL studies. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrom. Detect. Assoc. Equip. 2014, 768, 151–156. [Google Scholar] [CrossRef]
- McIntire, M.; Ratner, D.; Ermon, S. Sparse Gaussian Processes for Bayesian Optimization. In Proceedings of the Thirty-Second Conference on Uncertainty in Artificial Intelligence UAI, New York, NY, USA, 25–29 June 2016. [Google Scholar]
- McIntire, M.; Cope, T.; Ratner, D.; Ermon, S. Bayesian optimization of FEL performance at LCLS. In Proceedings of the 7th International Particle Accelerator Conference (IPAC 2016), Busan, Korea, 8–13 May 2016. [Google Scholar]
- Agapov, I.; Geloni, G.; Zagorodnov, I. Statistical optimization of FEL performance. In Proceedings of the 6th International Particle Accelerator Conference (IPAC 2015), Richmond, VA, USA, 3–8 May 2015. [Google Scholar]
- Radovic, A.; Williams, M.; Rousseau, D.; Kagan, M.; Bonacorsi, D.; Himmel, A.; Aurisano, A.; Terao, K.; Wongjirad, T. Machine learning at the energy and intensity frontiers of particle physics. Nature 2018, 560, 41–48. [Google Scholar] [CrossRef] [PubMed]
- Emma, C.; Edelen, A.; Hogan, M.; O’Shea, B.; White, G.; Yakimenko, V. Machine learning-based longitudinal phase space prediction of particle accelerators. Phys. Rev. Accel. Beams 2018, 21, 112802. [Google Scholar] [CrossRef] [Green Version]
- Edelen, A.; Neveu, N.; Frey, M.; Huber, Y.; Mayes, C.; Adelmann, A. Machine learning for orders of magnitude speedup in multiobjective optimization of particle accelerator systems. Phys. Rev. Accel. Beams 2020, 23, 044601. [Google Scholar] [CrossRef] [Green Version]
- Fol, E.; de Portugal, J.C.; Franchetti, G.; Tomás, R. Optics corrections using Machine Learning in the LHC. In Proceedings of the 2019 International Particle Accelerator Conference, Melbourne, Australia, 19–24 May 2019. [Google Scholar]
- Azzopardi, G.; Salvachua, B.; Valentino, G.; Redaelli, S.; Muscat, A. Operational results on the fully automatic LHC collimator alignment. Phys. Rev. Accel. Beams 2019, 22, 093001. [Google Scholar] [CrossRef] [Green Version]
- Müller, R.; Balzer, A.; Baumgärtel, P.; Sauer, O.; Hartmann, G.; Viefhaus, J. Modernization of experimental data taking at BESSY II. In Proceedings of the 17th International Conference on Accelerator and Large Experimental Physics Control Systems, ICALEPCS2019, New York, NY, USA, 5–11 October 2019. [Google Scholar]
- Edelen, A.; Mayes, C.; Bowring, D.; Ratner, D.; Adelmann, A.; Ischebeck, R.; Snuverink, J.; Agapov, I.; Kammering, R.; Edelen, J.; et al. Opportunities in machine learning for particle accelerators. arXiv 2018, arXiv:1811.03172. [Google Scholar]
- Kain, V.; Hirlander, S.; Goddard, B.; Velotti, F.M.; Zevi Della Porta, G.; Bruchon, N.; Valentino, G. Sample-efficient reinforcement learning for CERN accelerator control. Phys. Rev. Accelerat. Beams 2020, 23, 124801. [Google Scholar] [CrossRef]
- Ramirez, L.V.; Mertens, T.; Mueller, R.; Viefhaus, J.; Hartmann, G. Adding Machine Learning to the Analysis and Optimization Toolsets at the Light Source BESSY II. In Proceedings of the 17th International Conference on Accelerator and Large Experimental Physics Control Systems, ICALEPCS2019, New York, NY, USA, 5–11 October 2019. [Google Scholar]
- Edelen, A.; Biedron, S.; Chase, B.; Edstrom, D.; Milton, S.; Stabile, P. Neural networks for modeling and control of particle accelerators. IEEE Trans. Nucl. Sci. 2016, 63, 878–897. [Google Scholar] [CrossRef] [Green Version]
- Edelen, A.L.; Edelen, J.P.; RadiaSoft, L.; Biedron, S.G.; Milton, S.V.; van der Slot, P.J. Using Neural Network Control Policies For Rapid Switching Between Beam Parameters in a Free-Electron Laser. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Edelen, A.L.; Milton, S.V.; Biedron, S.G.; Edelen, J.P.; van der Slot, P.J.M. Using A Neural Network Control Policy For Rapid Switching between Beam Parameters in an FEL; Technical Report; Los Alamos National Lab. (LANL): Los Alamos, NM, USA, 2017. [Google Scholar]
- Hirlaender, S.; Kain, V.; Schenk, M. New paradigms for tuning accelerators: Automatic performance optimization and first steps towards reinforcement learning at the CERN Low Energy Ion Ring. In 2nd ICFA Workshop on Machine Learning for Charged Particle; 2019; Accelerators; Available online: https://indico.cern.ch/event/784769/contributions/3265006/attachments/1807476/2950489/CO-technical-meeting-_Hirlaender.pdf (accessed on 22 June 2021).
- Bruchon, N.; Fenu, G.; Gaio, G.; Lonza, M.; Pellegrino, F.A.; Salvato, E. Toward the application of reinforcement learning to the intensity control of a seeded free-electron laser. In Proceedings of the 2019 23rd International Conference on Mechatronics Technology (ICMT), Salerno, Italy, 23–26 October 2019; pp. 1–6. [Google Scholar]
- Bruchon, N.; Fenu, G.; Gaio, G.; Lonza, M.; O’Shea, F.H.; Pellegrino, F.A.; Salvato, E. Basic reinforcement learning techniques to control the intensity of a seeded free-electron laser. Electronics 2020, 9, 781. [Google Scholar] [CrossRef]
- O’Shea, F.; Bruchon, N.; Gaio, G. Policy gradient methods for free-electron laser and terahertz source optimization and stabilization at the FERMI free-electron laser at Elettra. Phys. Rev. Accel. Beams 2020, 23, 122802. [Google Scholar] [CrossRef]
- Hirlaender, S.; Bruchon, N. Model-free and Bayesian Ensembling Model-based Deep Reinforcement Learning for Particle Accelerator Control Demonstrated on the FERMI FEL. arXiv 2020, arXiv:2012.09737. [Google Scholar]
- Li, W.; Todorov, E. Iterative linear quadratic regulator design for nonlinear biological movement systems. In Proceedings of the First International Conference on Informatics in Control, Automation and Robotics, Setúbal, Portugal, 25–28 August 2004; pp. 222–229. [Google Scholar]
- Kain, V.; Bruchon, N.; Goddard, B.; Hirlander, S.; Madysa, N.; Valentino, G.; Velotti, F. Sample-Efficient Reinforcement Learning for CERN Accelerator Control. The One World Charged ParticLe accElerator (OWLE) Colloquium & Seminar Series. 2020. Available online: https://drive.google.com/file/d/1-OcdlK57VDNZnTOmkE_h28ZnTUqv7qza/view (accessed on 22 June 2021).
- Åström, K.J.; Wittenmark, B. Computer-Controlled Systems: Theory and Design; Courier Corporation: North Chelmsford, MA, USA, 2013. [Google Scholar]
- Al-Duwaish, H.; Karim, M.N.; Chandrasekar, V. Use of multilayer feedforward neural networks in identification and control of Wiener model. IEE Proc. Control Theory Appl. 1996, 143, 255–258. [Google Scholar] [CrossRef] [Green Version]
- Sjöberg, J.; Hjalmarsson, H.; Ljung, L. Neural networks in system identification. IFAC Proc. Vol. 1994, 27, 359–382. [Google Scholar] [CrossRef] [Green Version]
- Nørgård, P.M.; Ravn, O.; Poulsen, N.K.; Hansen, L.K. Neural Networks for Modelling and Control of Dynamic Systems—A Practitioner’s Handbook. 2000. Available online: https://orbit.dtu.dk/en/publications/neural-networks-for-modelling-and-control-of-dynamic-systems-a-pr (accessed on 22 June 2021).
- Jäntschi, L.; Bálint, D.; Bolboacă, S.D. Multiple linear regressions by maximizing the likelihood under assumption of generalized Gauss-Laplace distribution of the error. Comput. Math. Methods Med. 2016, 2016. [Google Scholar] [CrossRef] [PubMed]
- Gómez, Y.M.; Gallardo, D.I.; Leão, J.; Gómez, H.W. Extended exponential regression model: Diagnostics and application to mineral data. Symmetry 2020, 12, 2042. [Google Scholar] [CrossRef]
- Mzyk, G. Wiener System. In Combined Parametric-Nonparametric Identification of Block-Oriented Systems; Springer International Publishing: Cham, Switzerland, 2014; pp. 87–102. [Google Scholar] [CrossRef]
- Lewis, F.L.; Vrabie, D.; Syrmos, V.L. Optimal Control; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Borrelli, F.; Bemporad, A.; Morari, M. Predictive Control for Linear and Hybrid Systems; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Chen, J.; Zhan, W.; Tomizuka, M. Autonomous driving motion planning with constrained iterative LQR. IEEE Trans. Intell. Veh. 2019, 4, 244–254. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NN Hyperparameters | |||
|---|---|---|---|
| # of hidden units (h.u.) | 3 | ||
| # of neurons for h.u. | 10 | 16 | 10 |
| activation function for h.u. | tanh | sigmoid | sigmoid |
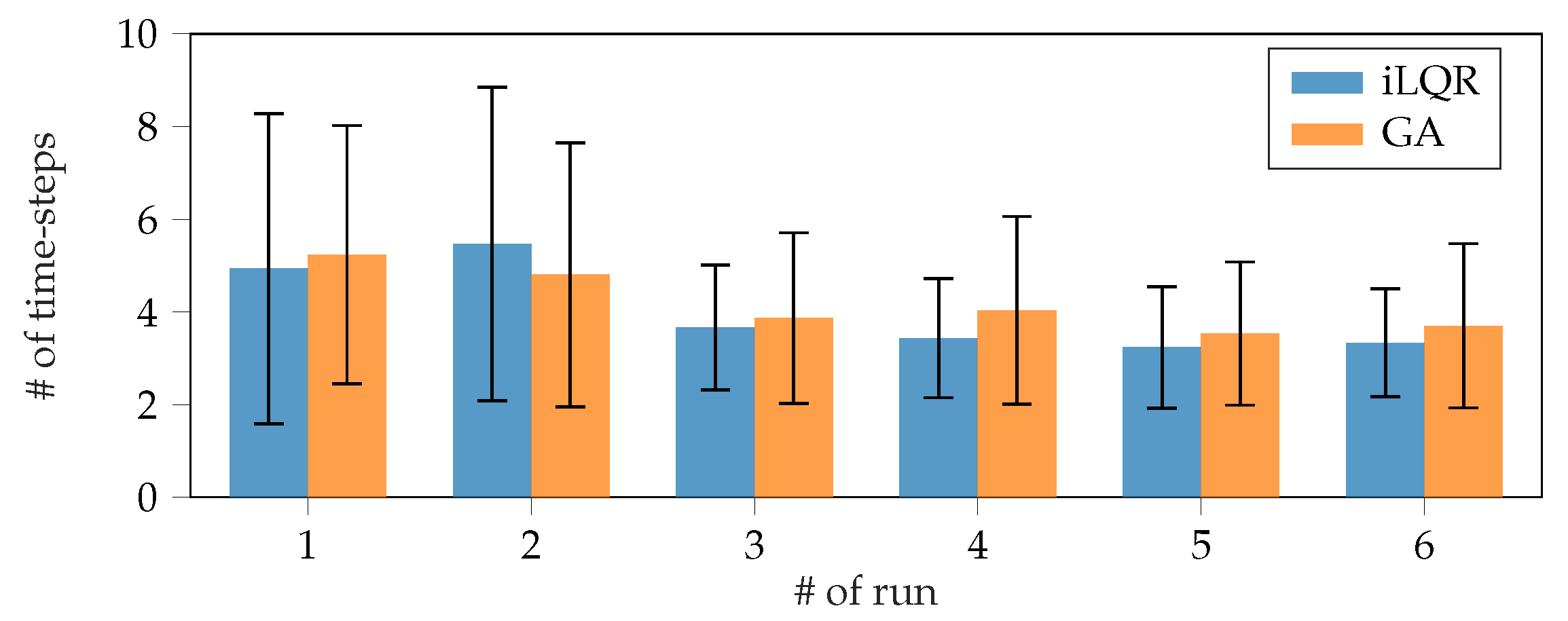
| Run | NN MSE | Success Rate | Mean # of Steps | ||
|---|---|---|---|---|---|
| iLQR | GA | iLQR | GA | ||
| 1 | 0.0133 | 73% | 90% | 4.93 | 5.2 |
| 2 | 0.0136 | 67% | 87% | 5.47 | 4.8 |
| ine 3 | 0.0076 | 100% | 73% | 3.67 | 3.87 |
| ine 4 | 0.0072 | 100% | 97% | 3.43 | 4.03 |
| ine 5 | 0.0069 | 100% | 100% | 3.23 | 3.53 |
| ine 6 | 0.0061 | 100% | 100% | 3.33 | 3.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bruchon, N.; Fenu, G.; Gaio, G.; Hirlander, S.; Lonza, M.; Pellegrino, F.A.; Salvato, E. An Online Iterative Linear Quadratic Approach for a Satisfactory Working Point Attainment at FERMI. Information 2021, 12, 262. https://doi.org/10.3390/info12070262
Bruchon N, Fenu G, Gaio G, Hirlander S, Lonza M, Pellegrino FA, Salvato E. An Online Iterative Linear Quadratic Approach for a Satisfactory Working Point Attainment at FERMI. Information. 2021; 12(7):262. https://doi.org/10.3390/info12070262
Chicago/Turabian StyleBruchon, Niky, Gianfranco Fenu, Giulio Gaio, Simon Hirlander, Marco Lonza, Felice Andrea Pellegrino, and Erica Salvato. 2021. "An Online Iterative Linear Quadratic Approach for a Satisfactory Working Point Attainment at FERMI" Information 12, no. 7: 262. https://doi.org/10.3390/info12070262
APA StyleBruchon, N., Fenu, G., Gaio, G., Hirlander, S., Lonza, M., Pellegrino, F. A., & Salvato, E. (2021). An Online Iterative Linear Quadratic Approach for a Satisfactory Working Point Attainment at FERMI. Information, 12(7), 262. https://doi.org/10.3390/info12070262