
A Buffer Management Algorithm Based on Dynamic Marking Threshold to Restrain MicroBurst in Data Center Network


Abstract
:1. Introduction
- Unlike previous solutions, the HDCQ algorithm is deployed on both the end-host side and network side, making full use of network resources and requiring no additional hardware support, with the exception of only simple modifications. Moreover, dynamically adjusting the small-flow ECN marking threshold in the switch prevents network microbursts, avoids network congestion, and increases the robustness of the data center.
- The HDCQ algorithm speeds up the TCP control loops by setting the ACK and ECN packets to the highest priority, reducing short flows’ completion time, especially the tail flow completion time, and maintaining the throughput of large flows.
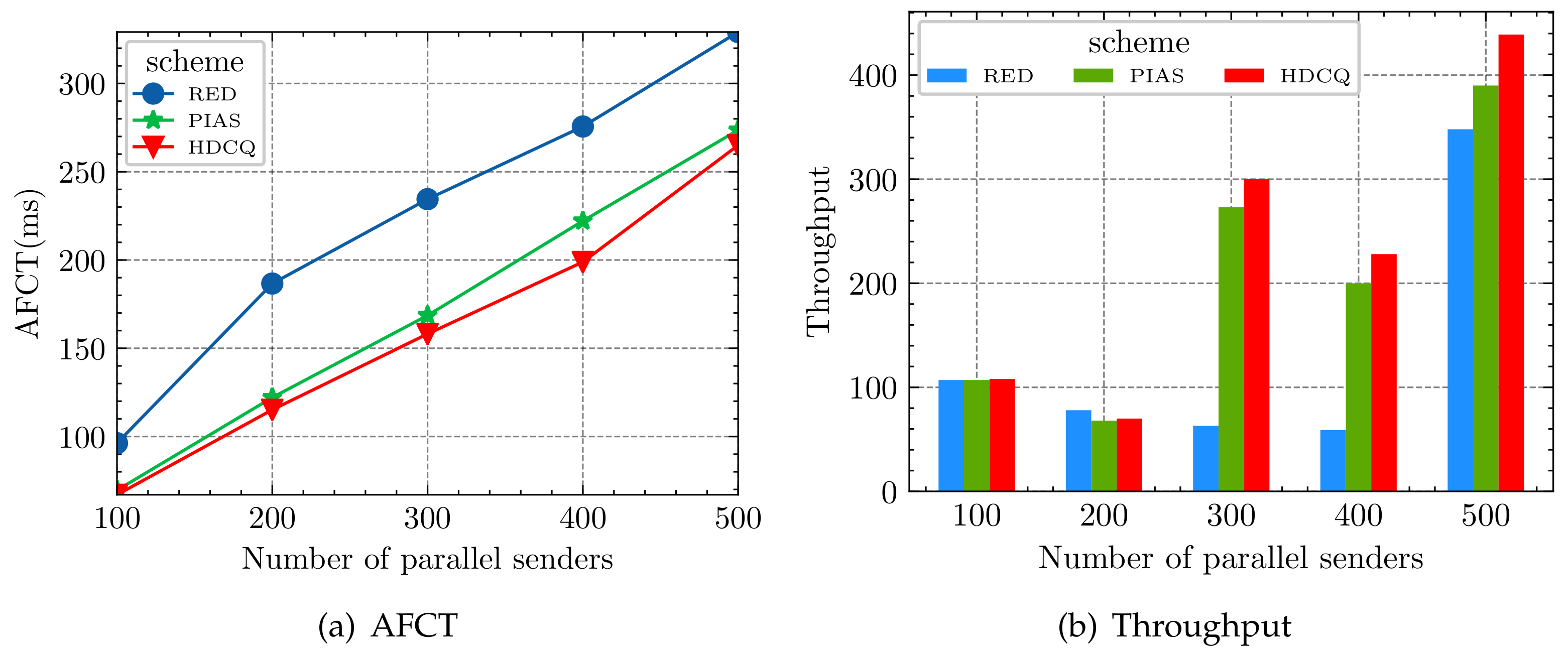
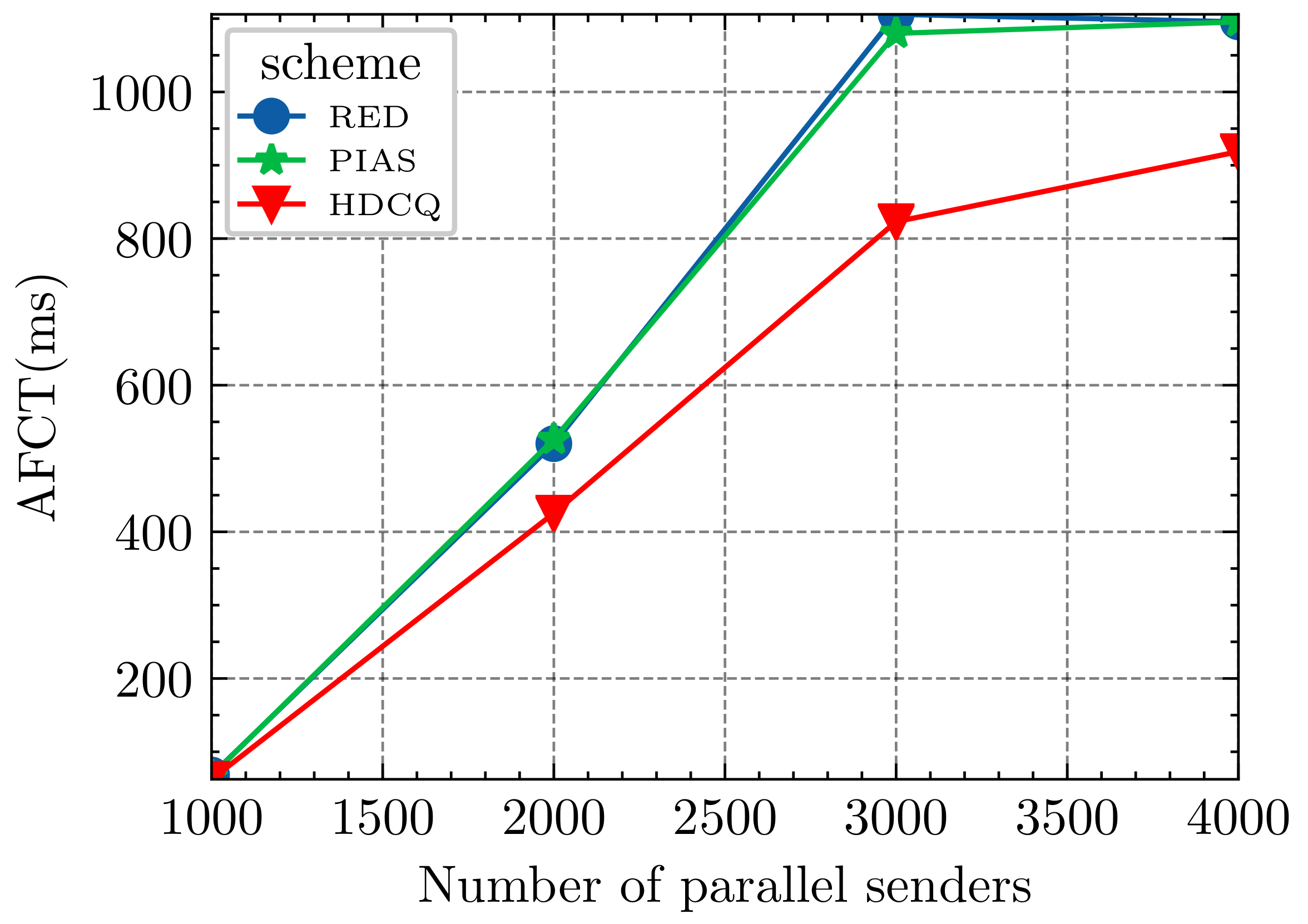
- We conducted experiments in Incast topology and showed that the HDCQ algorithm outperforms both Practical Information-agnostic Flow Scheduling(PIAS) and Random Early Detection (RED) algorithms in terms of Average Flow Completion Time (AFCT) of small flows and the throughput of large flows. Under severe network congestion, it has up to 24% reduction in AFCT of small flows compared to the PIAS algorithm.
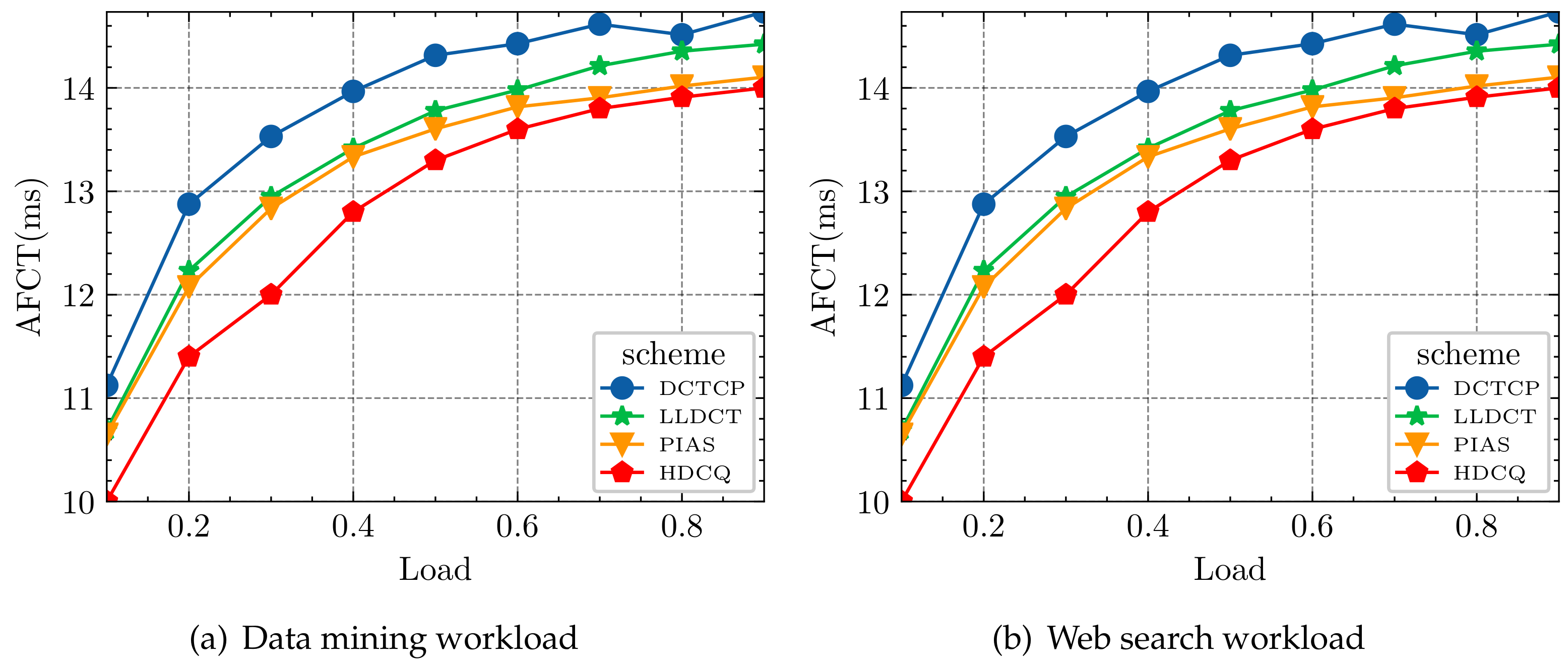
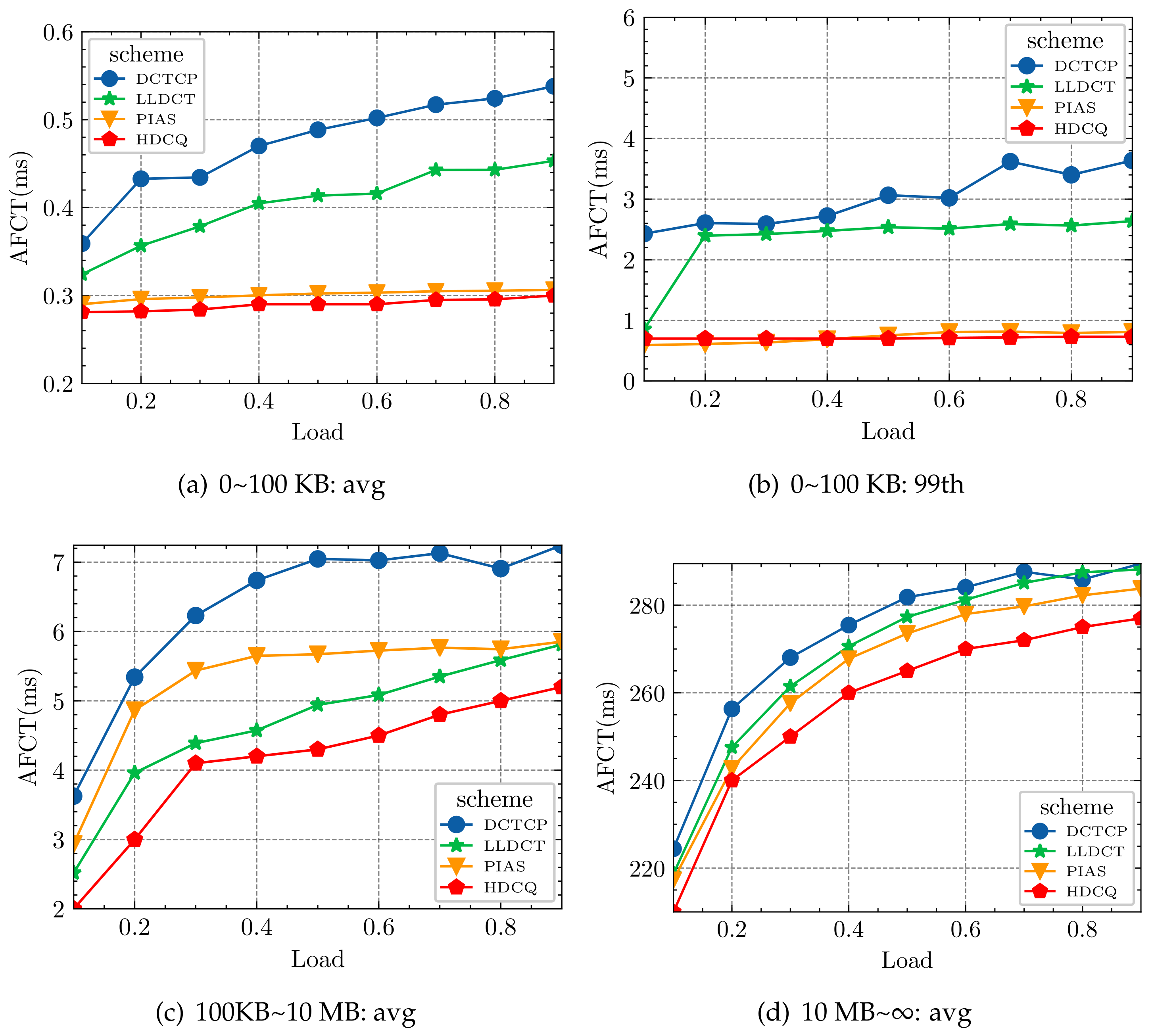
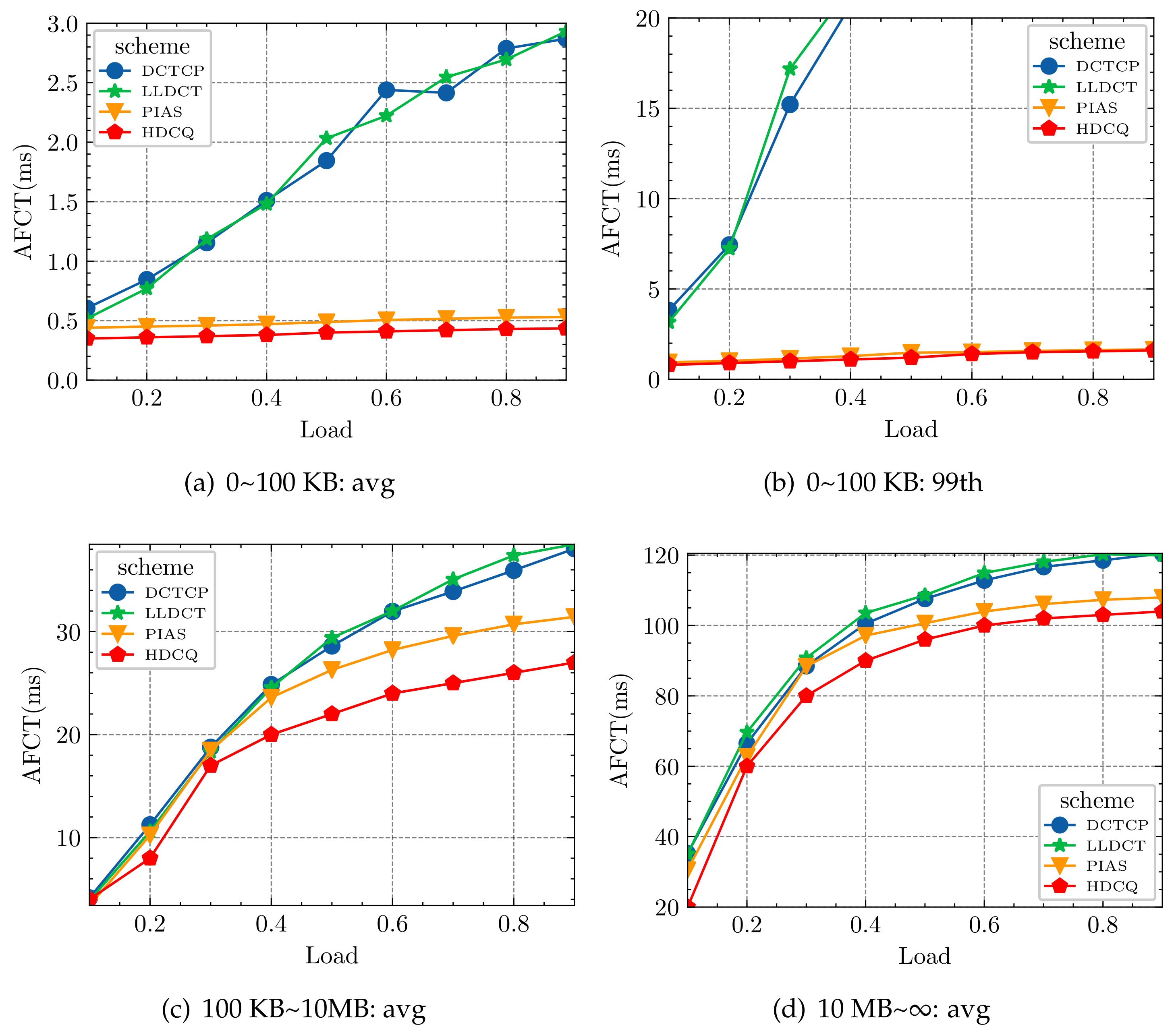
- We evaluated PIAS, Data Center TCP(DCTCP) [12], Low Latency Data Center Transport (LLDCT) [13], and HDCQ algorithms under various web searching and data mining workloads. The results show that the HDCQ algorithm performs well in AFCT under varying traffic. Under small flows, it reduces 2.11~4.70% compared to the PIAS algorithm and 21.74~44.25% on average compared to the DCTCP algorithm (data mining workload). It outperforms other algorithms under both medium and large flows.
2. Relate Work
2.1. Flow Scheduling Schemes
2.1.1. Information-Aware Scheduling
2.1.2. Information-Agnostic Scheduling
2.2. Protocols Using ECN Signals
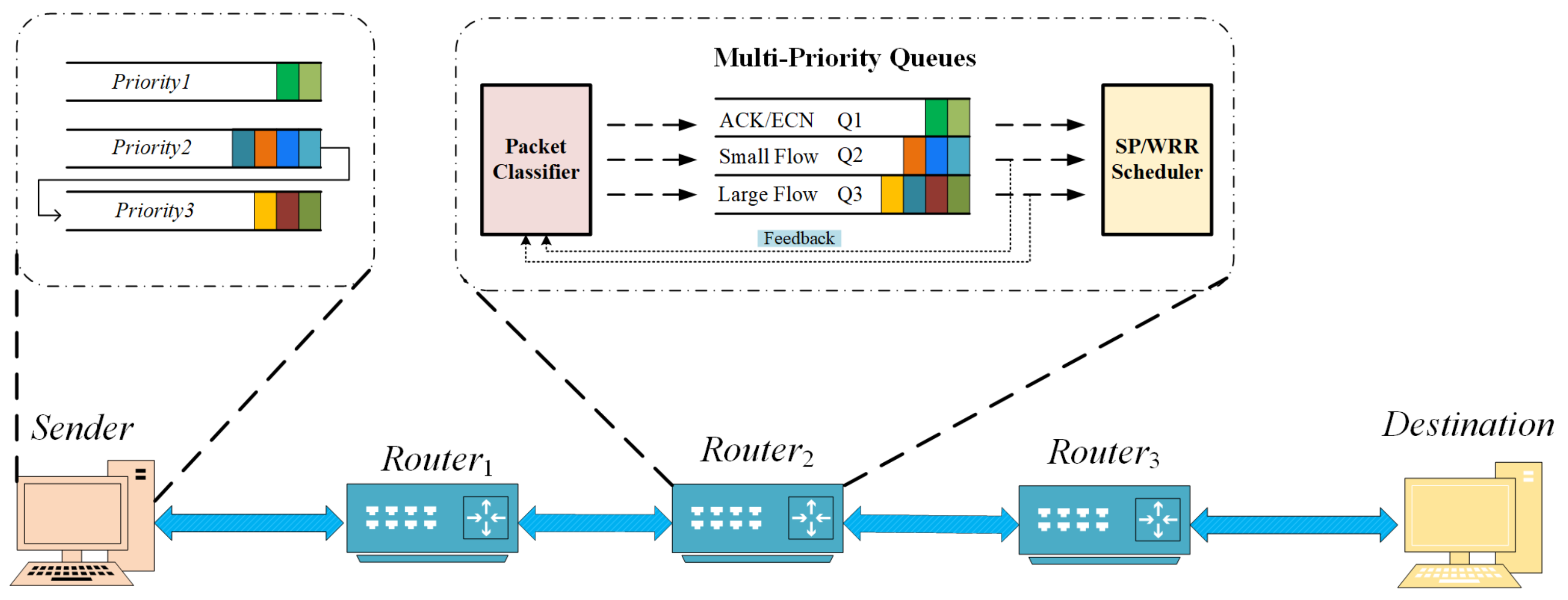
3. The HDCQ Design
3.1. Overall Scheme
3.2. Sender Modifications
| Algorithm 1: Packet Priority Marking Algorithm |
 |
- : The highest priority, which include packets containing ACK or ECN signals, is marked as the highest priority.
- : For small flow priority, the packet marks this priority when the threshold less than is set by the sender.
- : For the priority of large flows, when the accumulated number of packets exceeds , the packets coming after are marked with this priority.
3.3. Switch Buffer Management
3.3.1. ECN Threshold Marking
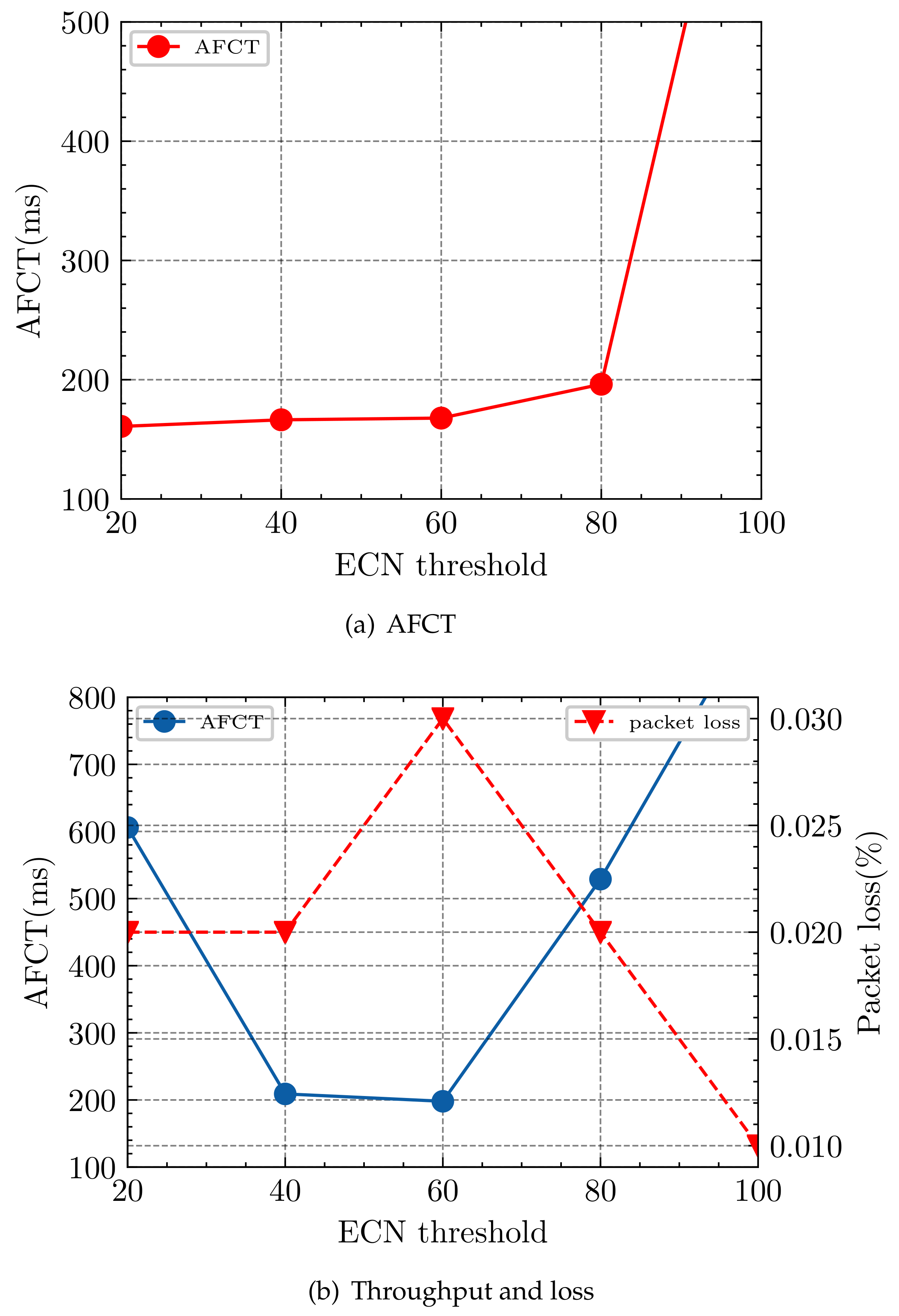
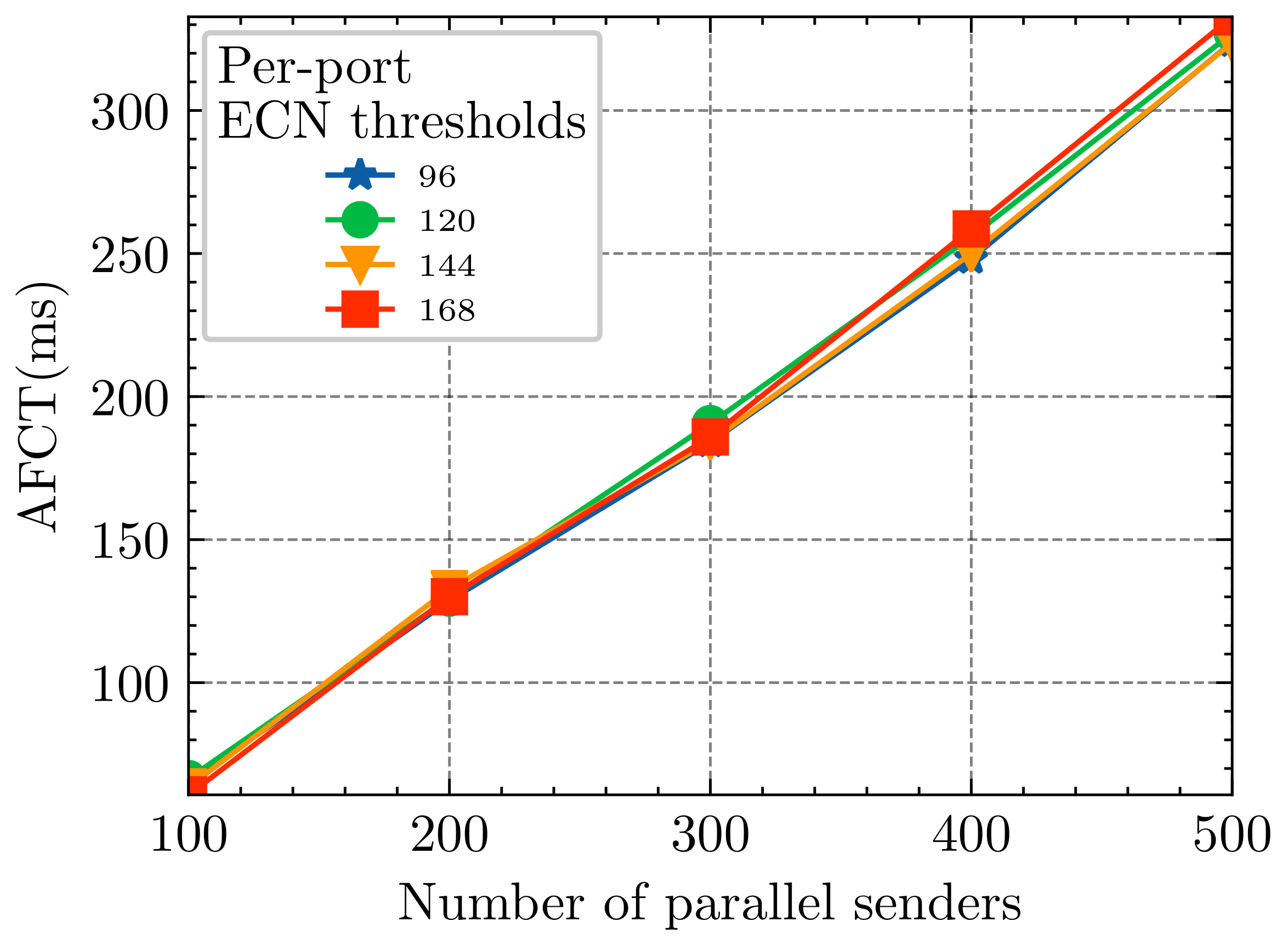
- -. The - parameter marks the ECN threshold of the switch port, which can provide better burst tolerance and prevent packet overflow when traffic bursts. In addition, since we set high priority packets to dequeue first, there are many low priority packets in the switch. When the arrival of a low-priority packet exceeds the - threshold, the packet will be marked ECN. Adjusting its priority to the highest priority () introduces queue , which notifies the sender quickly in order to reduce the sending rate and to prevent the long flows from being starved.
- -. We set the ECN marking threshold - in queue because queue receives packets of small flows with FCT requirements. Establishing a dedicated ECN marking threshold satisfies the network’s sensitivity to the FCT of small flows. When the network condition performs well, the - can be set to a larger value to make full use of the link bandwidth; conversely, if the current network link condition is terrible, the value of - needs to be adjusted to a smaller value in order to reserve space in the switch buffer to prevent packets from overflowing instantaneously, which will result in an increase in the FCT of small flows and a decrease in the throughput of large flows. The above discussion clarifies that the data center network needs to dynamically adjust the - in order to reserve enough buffer space.
3.3.2. Adjusting Packet Priority
| Algorithm 2: Packet Enqueue Algorithm |
 |
| Algorithm 3: Packet Dequeue Algorithm |
 |
3.3.3. Packet Dequeue Scheduling
- The HDCQ algorithm sets the signaling packets to the highest priority to prevent congestion in the data center network. The incoming small and large flows are divided by the MLFQ method and marked as and to ensure the AFCT of small flows and the throughput of large flows.
- The HDCQ algorithm creates only three queues in the switch, reducing the space complexity of the algorithm and keeping the switch in a shallow buffer state to ensure low latency.
- The HDCQ algorithm switches on the - and - parameters to adjust the priority of packets according to their ECN marking, which does not bring about priority reversal since only a small number of packets are marked with ECN.
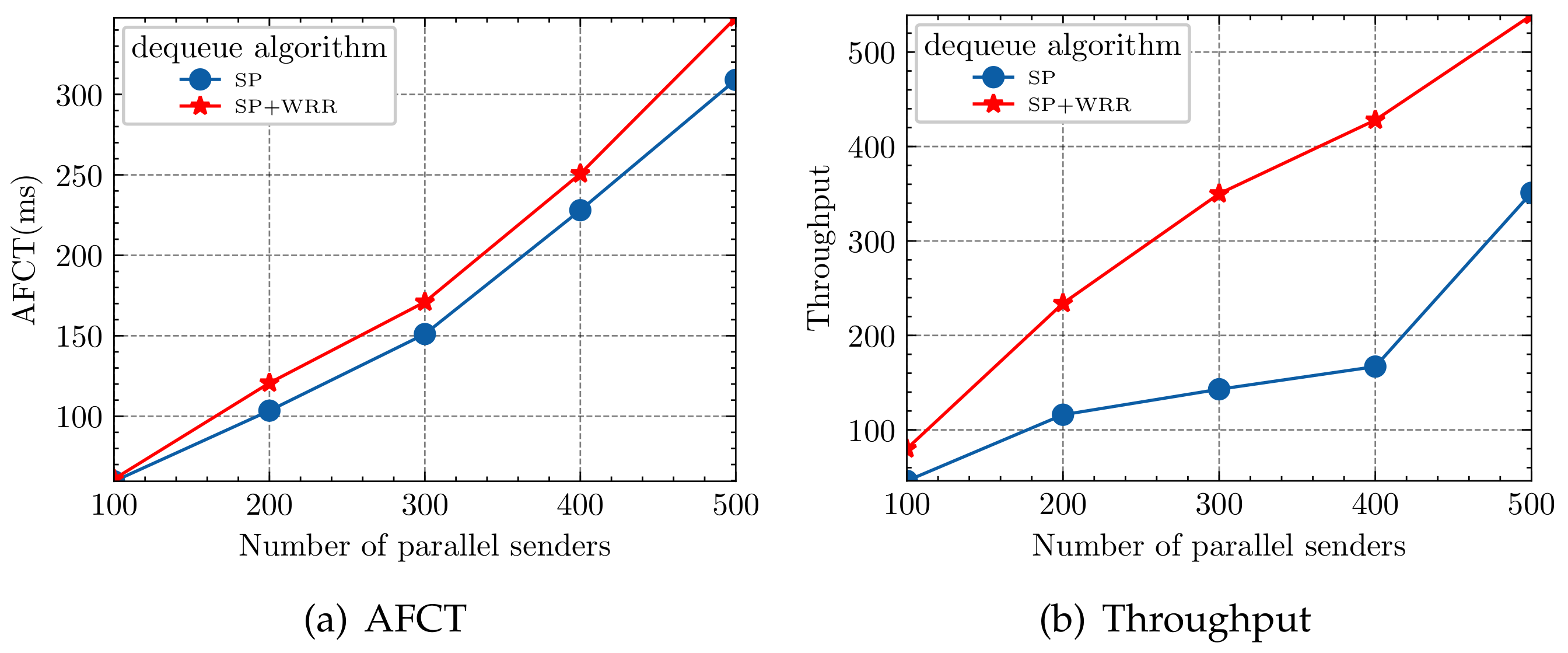
- The HDCQ algorithm uses the SP+WRR queue-out method to prevent the large flows from being starved and by comparing with other experiments prove its effectiveness.
4. The HDCQ’s Parameters
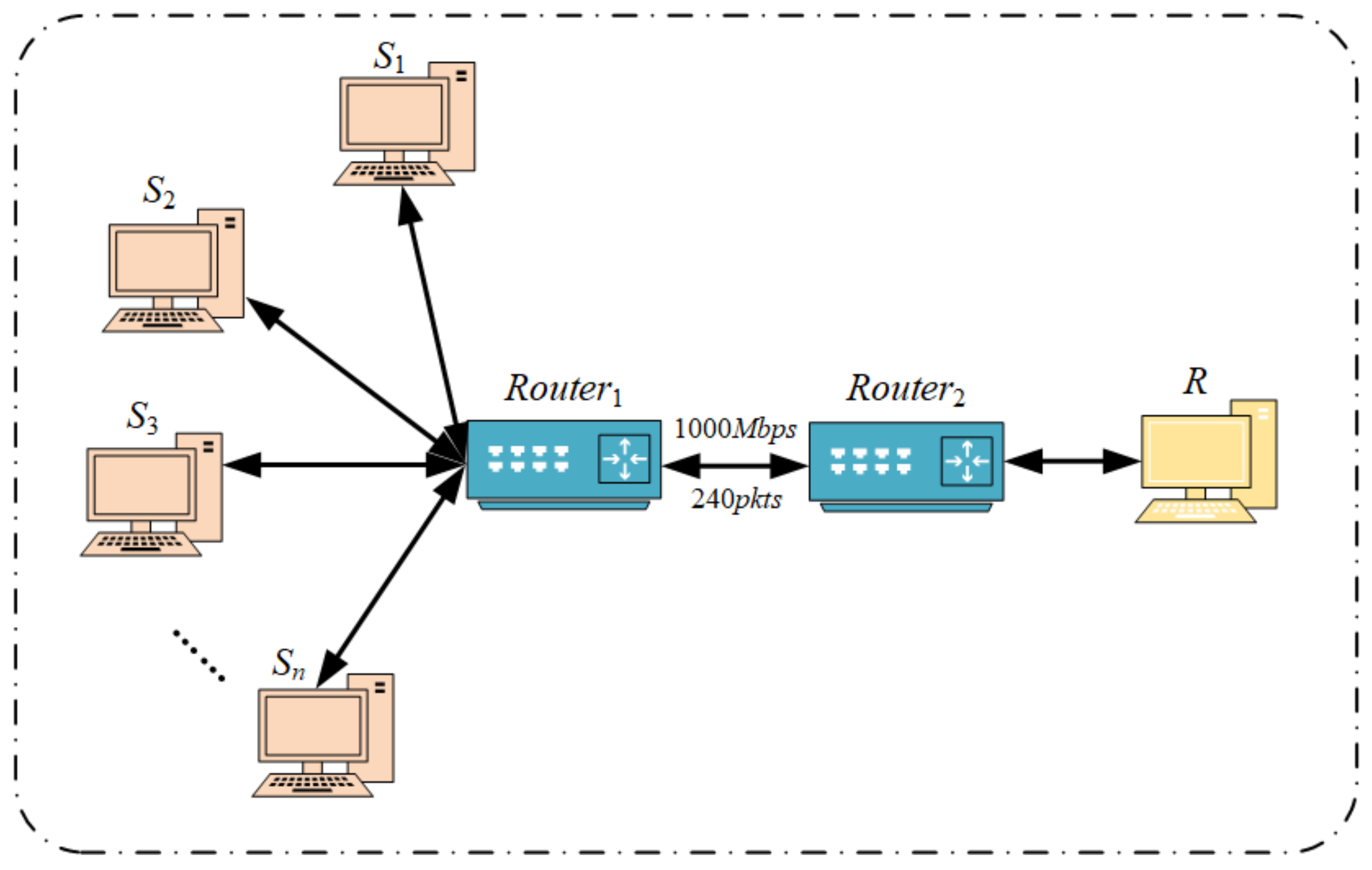
4.1. Incast Experimental Topology and Parameter
4.2. Parameter Analysis
4.2.1. Per-Port ECN
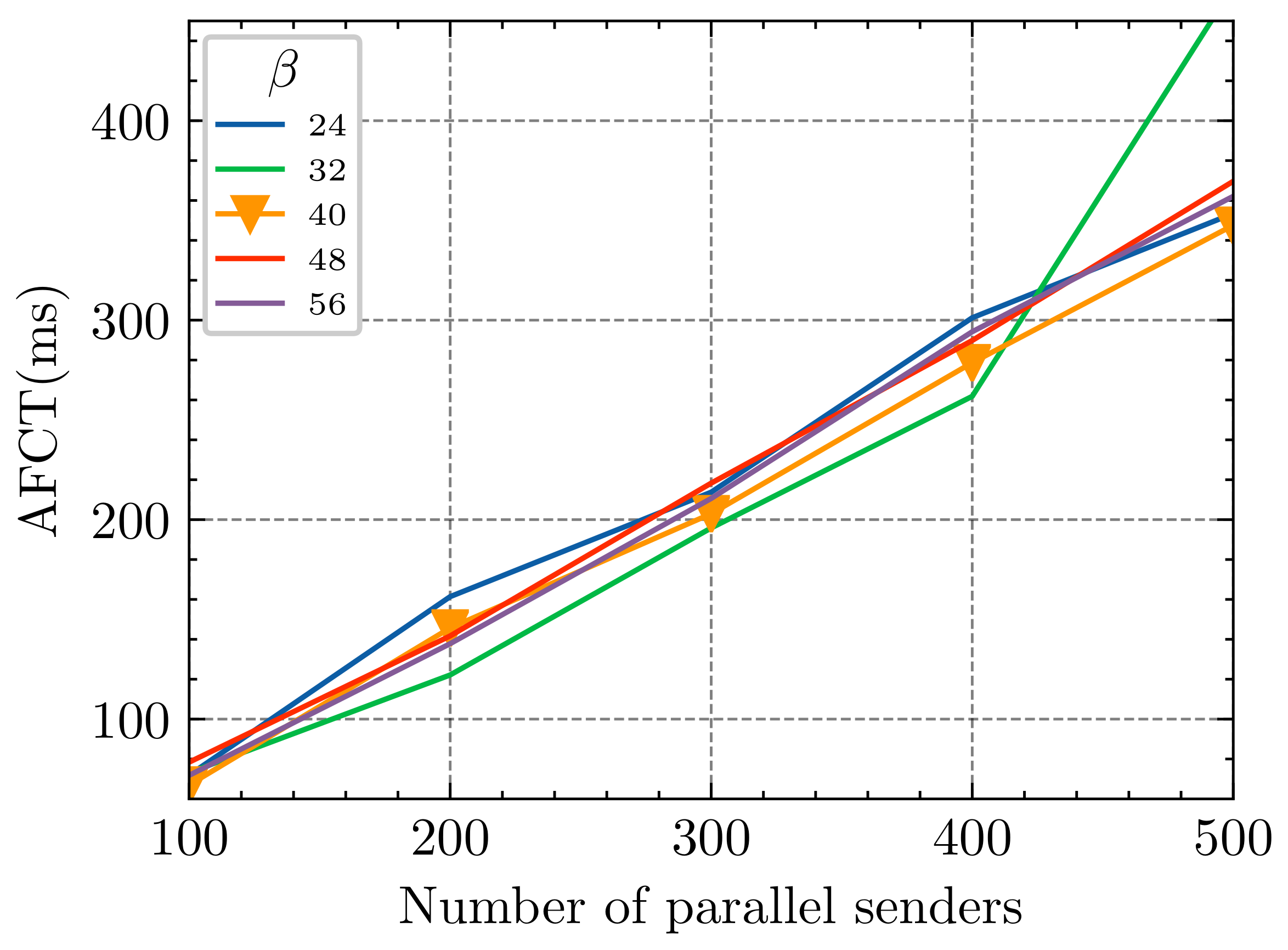
4.2.2.
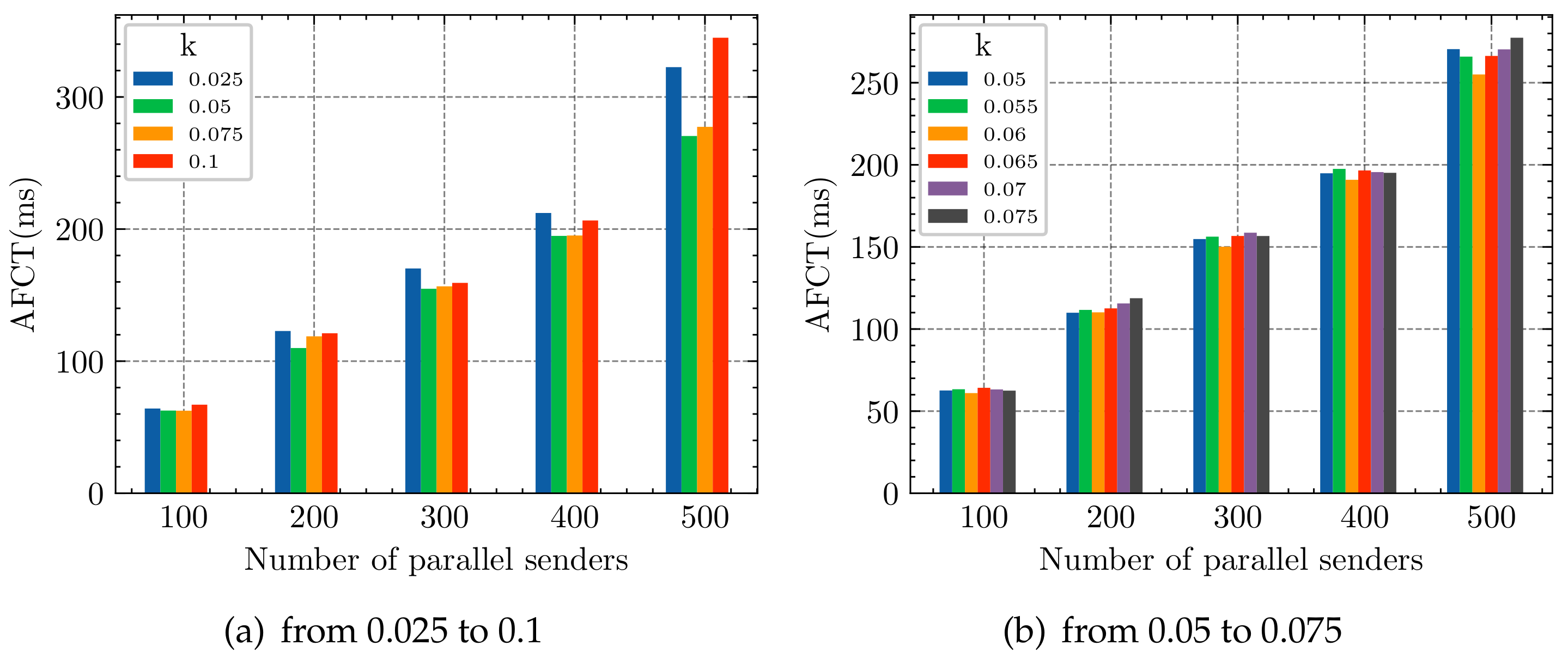
4.2.3. k
5. Experiment Results
5.1. Incast Experiment
5.2. Realistic Traffic Model
6. Conclusions
7. Patents
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Yu, F.R.; Wang, S. Load balancing in data center networks: A survey. IEEE Commun. Surv. Tutor. 2018, 20, 2324–2352. [Google Scholar] [CrossRef]
- Zeng, G.X.; Hu, S.H.; Zhang, J.X.; Chen, K. Transport Protocols for Data Center Networks: A Survey. J. Comput. Res. Dev. 2020, 57, 74. [Google Scholar]
- Rezaei, H.; Vamanan, B. ResQueue: A Smarter Datacenter Flow Scheduler. In Proceedings of the Web Conference 2020 (WWW’20), Taiwan, China, 20–24 April 2020; pp. 2599–2605. [Google Scholar]
- Alizadeh, M.; Yang, S.; Sharif, M.; Katti, S.; McKeown, N.; Prabhakar, B.; Shenker, S. pFabric: Minimal near-optimal datacenter transport. In Proceedings of the Special Interest Group on Data Communication (SIGCOMM), Hong Kong, China, 12–16 August 2013; pp. 435–446. [Google Scholar]
- Bai, W.; Chen, L.; Chen, K.; Han, D.S.; Tian, C.; Wang, H. PIAS: Practical information-agnostic flow scheduling for commodity data centers. IEEE/ACM Trans. Netw. 2017, 25, 1954–1967. [Google Scholar] [CrossRef]
- Wilson, C.; Ballani, H.; Karagiannis, T.; Rowtron, A. Better never than late: Meeting deadlines in datacenter networks. In Proceedings of the Special Interest Group on Data Communication (SIGCOMM), Toronto, ON, Canada, 15–19 August 2011; pp. 50–56. [Google Scholar]
- Vamanan, B.; Hasan, J.; Vijaykumar, T.N. Deadline-aware datacenter tcp (d2tcp). In Proceedings of the Special Interest Group on Data Communication (SIGCOMM), Helsinki, Finland, 13–17 August 2012; pp. 115–126. [Google Scholar]
- Hong, C.Y.; Caesar, M.; Godfrey, P.B. Finishing flows quickly with preemptive scheduling. In Proceedings of the Special Interest Group on Data Communication (SIGCOMM), Helsinki, Finland, 13–17 August 2012; pp. 127–138. [Google Scholar]
- Rezaei, H.; Malekpourshahraki, M.; Vamanan, B. Slytherin: Dynamic, network-assisted prioritization of tail packets in datacenter networks. In Proceedings of the 2018 27th International Conference on Computer Communication and Networks (ICCCN), Hang Zhou, China, 30 July–2 August 2018; pp. 1–9. [Google Scholar]
- Shan, D.; Ren, F.; Cheng, P.; Shu, R.; Guo, C.X. Micro-burst in data centers: Observations, analysis, and mitigations. In Proceedings of the 2018 IEEE 26th International Conference on Network Protocols (ICNP), Cambridge, UK, 24–27 September 2018; pp. 88–98. [Google Scholar]
- Kang, K.; Zhang, J.H.; Jin, J.H.; Shen, D.; Luo, J.Z.; Li, W.X.; Wu, Z.A. MBECN: Enabling ECN with micro-burst traffic in multi-queue data center. In Proceedings of the IEEE International Conference on Cluster Computing, Albuquerque, NM, USA, 23–26 September 2019; pp. 1–12. [Google Scholar]
- Alizadeh, M.; Greenberg, A.; Maltz, D.A.; Padhye, J.; Patel, P.; Prabhakar, B.; Sengupta, S.; Sridharan, M. Data center tcp (dctcp). In Proceedings of the ACM SIGCOMM 2010 Conference, New Delhi, India, 30 August–3 September 2010; pp. 63–74. [Google Scholar]
- Munir, A.; Qazi, I.A.; Uzmi, Z.A.; Mushtaq, A.; Ismail, S.N.; Iqbal, M.S.; Khan, B. Minimizing flow completion times in data centers. In Proceedings of the 32nd IEEE International Conference on Computer Communications, Turin, Spain, 14–19 April 2013; pp. 2157–2165. [Google Scholar]
- Giannakas, F.; Troussas, C.; Voyiatzis, I.; Sgouropoulou, C. A deep learning classification framework for early prediction of team-based academic performance. Appl. Soft Comput. 2021, 106, 107355. [Google Scholar] [CrossRef]
- Giannakas, F.; Troussas, C.; Krouska, A.; Sgouropoulou, C.; Voyiatzis, I. XGBoost and Deep Neural Network Comparison: The Case of Teams’ Performance. In Proceedings of the 2021 International Conference on Intelligent Tutoring Systems, Cambridge, UK, 7–11 June 2021; pp. 343–349. [Google Scholar]
- Liu, Z.F.; Sun, J.S.; Hu, S.Q.; Hu, X.L. An Adaptive AQM Algorithm Based on a Novel Information Compression Model. IEEE Access 2018, 6, 31180–31190. [Google Scholar] [CrossRef]
- Alizadeh, M.; Kabbani, A.; Edsall, T.; Prabhakar, B.; Vahdat, A.; Yasuda, M. Less is more: Trading a little bandwidth for ultra-low latency in the data center. In Proceedings of the Usenix Conference on Networked Systems Design and Implementation (NSDI), San Jose, CA, USA, 25–27 April 2012; pp. 253–266. [Google Scholar]
- Zhang, T.; Wang, J.X.; Huang, J.W.; Huang, Y.; Chen, J.; Pan, Y. Adaptive marking threshold method for delay-sensitive TCP in data center network. J. Netw. Comput. Appl. 2016, 61, 222–234. [Google Scholar] [CrossRef]
- Yan, S.Y.; Wang, X.L.; Zheng, X.L.; Xia, Y.B.; Liu, D.R.; Deng, W.S. ACC: Automatic ECN tuning for high-speed datacenter networks. In Proceedings of the 2021 ACM SIGCOMM 2021 Conference, Online, 23–27 August 2021; pp. 384–397. [Google Scholar]
- Shan, D.; Ren, F. Improving ECN marking scheme with micro-burst traffic in data center networks. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- Shan, D.; Ren, F. ECN Marking With Micro-Burst Traffic: Problem, Analysis, and Improvement. IEEE/ACM Trans. Netw. 2018, 26, 1533–1546. [Google Scholar] [CrossRef]
- Kim, G.; Lee, W. Absorbing microbursts without headroom for data center networks. IEEE Commun. Lett. 2019, 23, 806–809. [Google Scholar] [CrossRef]
- Peng, Y.; Chen, K.; Wang, G.H.; Bai, W.; Ma, Z.Q.; Gu, L. Hadoopwatch: A first step towards comprehensive traffic forecasting in cloud computing. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Toronto, ON, Canada, 27 April–2 May 2014; pp. 19–27. [Google Scholar]
- Bai, W.; Chen, K.; Chen, L.; Kim, C.H.; Wu, H.T. Enabling ECN over generic packet scheduling. In Proceedings of the 12th International on Conference on emerging Networking Experiments and Technologies, Irvine, CA, USA, 12–15 December 2016; pp. 191–204. [Google Scholar]
- Noormohammadpour, M.; Raghavendra, C. Comparison of flow scheduling policies for mix of regular and deadline traffic in datacenter environments. arXiv 2017, arXiv:1707.02024. [Google Scholar]
- The Network Simulator NS-2. Available online: http://www.isi.edu/nsnam/ns/ (accessed on 4 November 2011).
- Almasi, H.; Rezaei, H.; Chaudhry, M.U.; Vamanan, B. Pulser: Fast Congestion Response using Explicit Incast Notifications for Datacenter Networks. In Proceedings of the 2019 IEEE International Symposium on Local and Metropolitan Area Networks (LANMAN), Paris, France, 1–3 July 2019; pp. 1–6. [Google Scholar]
- Floyd, S.; Jacobson, V. Random early detection gateways for congestion avoidance. IEEE/ACM Trans. Netw. 1993, 1, 397–413. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Description | Value |
|---|---|---|
| C | Bottleneck link bandwidth | 1000 Mbps |
| B | The size of the buffer that the switch contains | 240 pkts |
| L | Number of long flows | 1 |
| S | Number of short flows | 100∼500 |
| The time when the short flows starts to be sent | s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Y.; Jiang, X.; Jin, G.; Gao, Z.; Li, P. A Buffer Management Algorithm Based on Dynamic Marking Threshold to Restrain MicroBurst in Data Center Network. Information 2021, 12, 369. https://doi.org/10.3390/info12090369
Yu Y, Jiang X, Jin G, Gao Z, Li P. A Buffer Management Algorithm Based on Dynamic Marking Threshold to Restrain MicroBurst in Data Center Network. Information. 2021; 12(9):369. https://doi.org/10.3390/info12090369
Chicago/Turabian StyleYu, Yan, Xianliang Jiang, Guang Jin, Zihang Gao, and Penghui Li. 2021. "A Buffer Management Algorithm Based on Dynamic Marking Threshold to Restrain MicroBurst in Data Center Network" Information 12, no. 9: 369. https://doi.org/10.3390/info12090369
APA StyleYu, Y., Jiang, X., Jin, G., Gao, Z., & Li, P. (2021). A Buffer Management Algorithm Based on Dynamic Marking Threshold to Restrain MicroBurst in Data Center Network. Information, 12(9), 369. https://doi.org/10.3390/info12090369