
A Spark-Based Artificial Bee Colony Algorithm for Unbalanced Large Data Classification



Abstract
:1. Introduction
- We propose a new minimum fitness function to handle unbalanced data by minimizing the weight of the miss-classification rate.
- We design and implement a parallel version of the ABC-based data classification algorithm using Apache Spark to carry out the classification task on a massive amount of data while maintaining the quality level of the classification outcomes.
- We investigate the scalability and effectiveness of the parallel design of the ABC-based data classification algorithm using real-world massive unbalanced datasets.
2. Related Works
3. The Background Knowledge
3.1. Artificial Bee Colony Algorithm (ABC)
3.2. Artificial Bee Colony Algorithm for Data Classification
4. Spark-Based Artificial Bee Colony Algorithm for Large Data Classification
4.1. New Fitness Function
- Step 1:
- Each sample in the training dataset is assigned to the closest centroid (class label) according to the Euclidean distance.
- Step 2:
- Sum the misclassification weight of all misclassified samples.
4.2. Adopting Spark-Based ABC for Big Data Classification
5. Dataset and Environment
6. Evaluation Measures
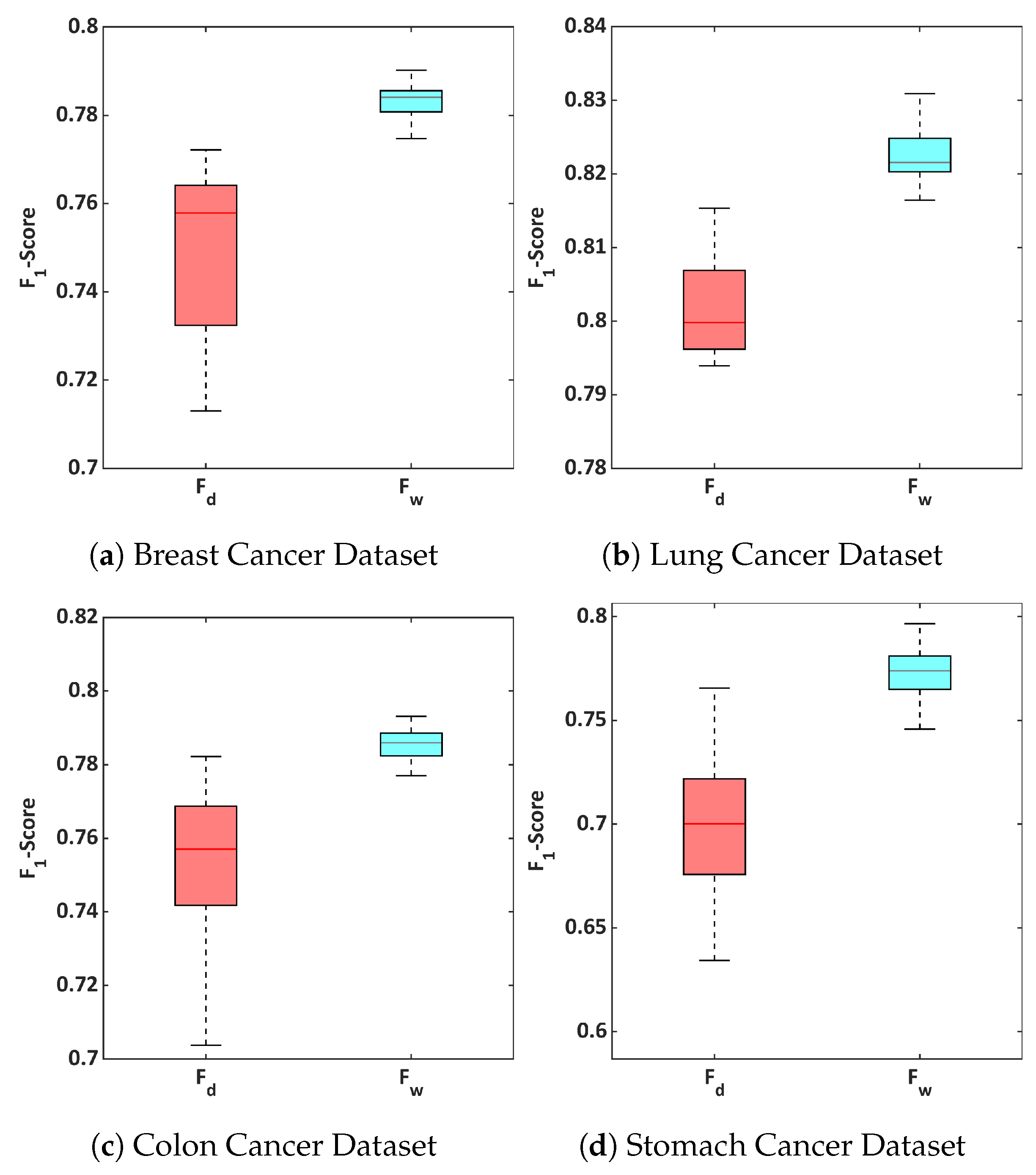
7. Experiments and Results
- Colony size = 150
- Maximum Cycles (MCN) = 200
- Limit = 20
7.1. Performance Analysis of ABCCS
7.2. Scalability Analysis of ABCCS
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sayad, S. Real Time Data Mining; Self-Help Publishers: Newcastle, UK, 2011. [Google Scholar]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef] [Green Version]
- Spark 2.1.0 Documentation. Available online: https://spark.apache.org/docs/2.1.0/ (accessed on 24 December 2021).
- Zaharia, M.; Chowdhury, M.; Das, T.; Dave, A.; Ma, J.; McCauly, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In Proceedings of the 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI 12), San Jose, CA, USA, 25–27 April 2012; pp. 15–28. [Google Scholar]
- Apache Hadoop- MapReduce. Available online: https://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html (accessed on 4 December 2021).
- Karau, H.; Konwinski, A.; Wendell, P.; Zaharia, M. Learning Spark: Lightning-Fast Big Data Analysis; OReilly: Newton, MA, USA, 2015. [Google Scholar]
- Apache Spark About. Available online: https://databricks.com/spark/about (accessed on 24 December 2021).
- Karaboga, D. An Idea Based on Honey Bee Swarm for Numerical Optimization; Technical Report, Technical Report-tr06; Erciyes University, Engineering Faculty, Computer Engineering Department: Kayseri, Turkey, 2005. [Google Scholar]
- Karaboga, D.; Gorkemli, B.; Ozturk, C.; Karaboga, N. A comprehensive survey: Artificial bee colony (ABC) algorithm and applications. Artif. Intell. Rev. 2014, 42, 21–57. [Google Scholar] [CrossRef]
- Karaboga, D.; Ozturk, C. A novel clustering approach: Artificial Bee Colony (ABC) algorithm. Appl. Soft Comput. 2011, 11, 652–657. [Google Scholar] [CrossRef]
- Banharnsakun, A. A MapReduce-based artificial bee colony for large-scale data clustering. Pattern Recognit. Lett. 2017, 93, 78–84. [Google Scholar] [CrossRef]
- Wang, Y.; Qian, Q. A Spark-Based Artificial Bee Colony Algorithm for Large-Scale Data Clustering. In Proceedings of the 2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Exeter, UK, 28–30 June 2018; pp. 1213–1218. [Google Scholar] [CrossRef]
- Tripathi, A.K.; Sharma, K.; Bala, M. A Novel Clustering Method Using Enhanced Grey Wolf Optimizer and MapReduce. Big Data Res. 2018, 14, 93–100. [Google Scholar] [CrossRef]
- Al-Sawwa, J.; Ludwig, S.A. Parallel particle swarm optimization classification algorithm variant implemented with Apache Spark. Concurr. Comput. Pract. Exp. 2020, 32, e5451. [Google Scholar] [CrossRef]
- Daoudi, M.; Hamena, S.; Benmounah, Z.; Batouche, M. Parallel diffrential evolution clustering algorithm based on mapreduce. In Proceedings of the 2014 6th International Conference of Soft Computing and Pattern Recognition (SoCPaR), Tunis, Tunisia, 11–14 August 2014; pp. 337–341. [Google Scholar]
- Wang, J.; Yuan, D.; Jiang, M. Parallel k-pso based on mapreduce. In Proceedings of the 2012 IEEE 14th International Conference on Communication Technology, Chengdu, China, 9–11 November 2012; pp. 1203–1208. [Google Scholar]
- Yang, J.; Li, X. MapReduce based method for big data semantic clustering. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 2814–2819. [Google Scholar]
- Aljarah, I.; Ludwig, S.A. Parallel particle swarm optimization clustering algorithm based on mapreduce methodology. In Proceedings of the 2012 fourth world congress on Nature and biologically inspired computing (NaBIC), Mexico City, Mexico, 5–9 November 2012; pp. 104–111. [Google Scholar]
- Ashish, T.; Kapil, S.; Manju, B. Parallel bat algorithm-based clustering using mapreduce. In Networking Communication and Data Knowledge Engineering; Springer: Singapore, 2018; pp. 73–82. [Google Scholar]
- Al-Madi, N.; Aljarah, I.; Ludwig, S.A. Parallel glowworm swarm optimization clustering algorithm based on MapReduce. In Proceedings of the 2014 IEEE Symposium on Swarm Intelligence, Orlando, FL, USA, 9–12 November 2014; pp. 1–8. [Google Scholar]
- Shanthi, S.; Lakshmi, K. MapReduce-Based Crow Search-Adopted Partitional Clustering Algorithms for Handling Large-Scale Data. Int. J. Cogn. Inform. Nat. Intell. (IJCINI) 2021, 15, 1–23. [Google Scholar]
- Surveillance, Epidemiology, and End Results (SEER) Program Research Data (1973–2015), National Cancer Institute, DCCPS, Surveillance Research Program, Released April 2018. Available online: www.seer.cancer.gov (accessed on 24 December 2021).
- Pour, E.S.H. Stage-Specific Predictive Models for Cancer Survivability. Ph.D. Thesis, The University of Wisconsin-Milwaukee, Milwaukee, WI, USA, 2016. [Google Scholar]
- Agrawal, A.; Misra, S.; Narayanan, R.; Polepeddi, L.; Choudhary, A. Lung cancer survival prediction using ensemble data mining on SEER data. Sci. Program. 2012, 20, 29–42. [Google Scholar] [CrossRef] [Green Version]
- Delen, D.; Walker, G.; Kadam, A. Predicting breast cancer survivability: A comparison of three data mining methods. Artif. Intell. Med. 2005, 34, 113–127. [Google Scholar] [CrossRef] [PubMed]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2018, 17, 168–192. [Google Scholar] [CrossRef]
- Al-Sawwa, J.; Ludwig, S.A. A Cost-Sensitive Centroid-based Differential Evolution Classification Algorithm applied to Cancer Data Sets. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 2514–2521. [Google Scholar] [CrossRef]
- Puri, A.; Gupta, M.K. Comparative Analysis of Resampling Techniques under Noisy Imbalanced Datasets. In Proceedings of the 2019 International Conference on Issues and Challenges in Intelligent Computing Techniques (ICICT), Ghaziabad, India, 27–28 September 2019; Volume 1, pp. 1–5. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Class Label | Number of Attributes | Total | |
|---|---|---|---|---|
| Survive | Not Survive | |||
| Breast Cancer | 280,592 (90.80%) | 28,414 (9.20%) | 15 | 309,006 |
| Lung Cancer | 24,513 (26.49%) | 68,041 (73,51%) | 17 | 92,554 |
| Colon Cancer | 56,263 (63.14%) | 32,840 (36.86%) | 17 | 89,103 |
| Stomach Cancer | 4177 (36.25%) | 7345 (63.75%) | 16 | 11,522 |
| Dataset Name | Duplication Rate | Size |
|---|---|---|
| 5R Dataset | 5 times | 1,545,030 |
| 15R Dataset | 15 times | 4,635,090 |
| 30R Dataset | 30 times | 9,270,180 |
| Class Label | ||
|---|---|---|
| Survived | Not Survived | |
| Breast Cancer | 1.0 | 10.0 |
| Lung Cancer | 2.7 | 1.0 |
| Colon Cancer | 1.0 | 1.8 |
| Stomach Cancer | 1.8 | 1.0 |
| Breast | Average | 68.99 % | 77.99% |
| Standard Deviation | [±0.0313] | [±0.003] | |
| Lung | Average | 79.04% | 81.23% |
| Standard Deviation | [±0.004] | [±0.0025] | |
| Colon | Average | 69.76% | 77.58% |
| Standard Deviation | [±0.0385] | [±0.0042] | |
| Stomach | Average | 68.90% | 77.33% |
| Standard Deviation | [±0.0272] | [±0.0112] | |
| Average | 71.67% | 78.53% | |
| Breast | Average | 75.11% | 78.28% |
| Standard Deviation | [±0.0178] | [±0.0044] | |
| Lung | Average | 80.15% | 82.2% |
| Standard Deviation | [±0.0065] | [±0.0042 ] | |
| Colon | Average | 74.6% | 78.57% |
| Standard Deviation | [±0.0437] | [±0.0044] | |
| Stomach | Average | 69.36% | 77.41% |
| Standard Deviation | [±0.0393] | [±0.0127] | |
| Average | 74.81% | 79.12% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Sawwa, J.; Almseidin, M. A Spark-Based Artificial Bee Colony Algorithm for Unbalanced Large Data Classification. Information 2022, 13, 530. https://doi.org/10.3390/info13110530
Al-Sawwa J, Almseidin M. A Spark-Based Artificial Bee Colony Algorithm for Unbalanced Large Data Classification. Information. 2022; 13(11):530. https://doi.org/10.3390/info13110530
Chicago/Turabian StyleAl-Sawwa, Jamil, and Mohammad Almseidin. 2022. "A Spark-Based Artificial Bee Colony Algorithm for Unbalanced Large Data Classification" Information 13, no. 11: 530. https://doi.org/10.3390/info13110530
APA StyleAl-Sawwa, J., & Almseidin, M. (2022). A Spark-Based Artificial Bee Colony Algorithm for Unbalanced Large Data Classification. Information, 13(11), 530. https://doi.org/10.3390/info13110530