
SOCRAT: A Dynamic Web Toolbox for Interactive Data Processing, Analysis and Visualization

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background and Related Work
2.1. Integrative Web Toolkits for Visual Analytics
2.2. SOCR Tools for Visual Analytics
3. SOCRAT Design and Key Features
3.1. Design Considerations
- data management, including data input and preprocessing, storage, representation, and querying;
- interactive visualizations for various data types, including univariate, multivariate, high-dimensional, hierarchical, longitudinal, and geospatial;
- data analytics, including inferential and descriptive statistics, with applications of machine learning and other modeling and computational techniques, supported by interactive visual interpretation of the analytical results, method properties, and algorithm visualizations.
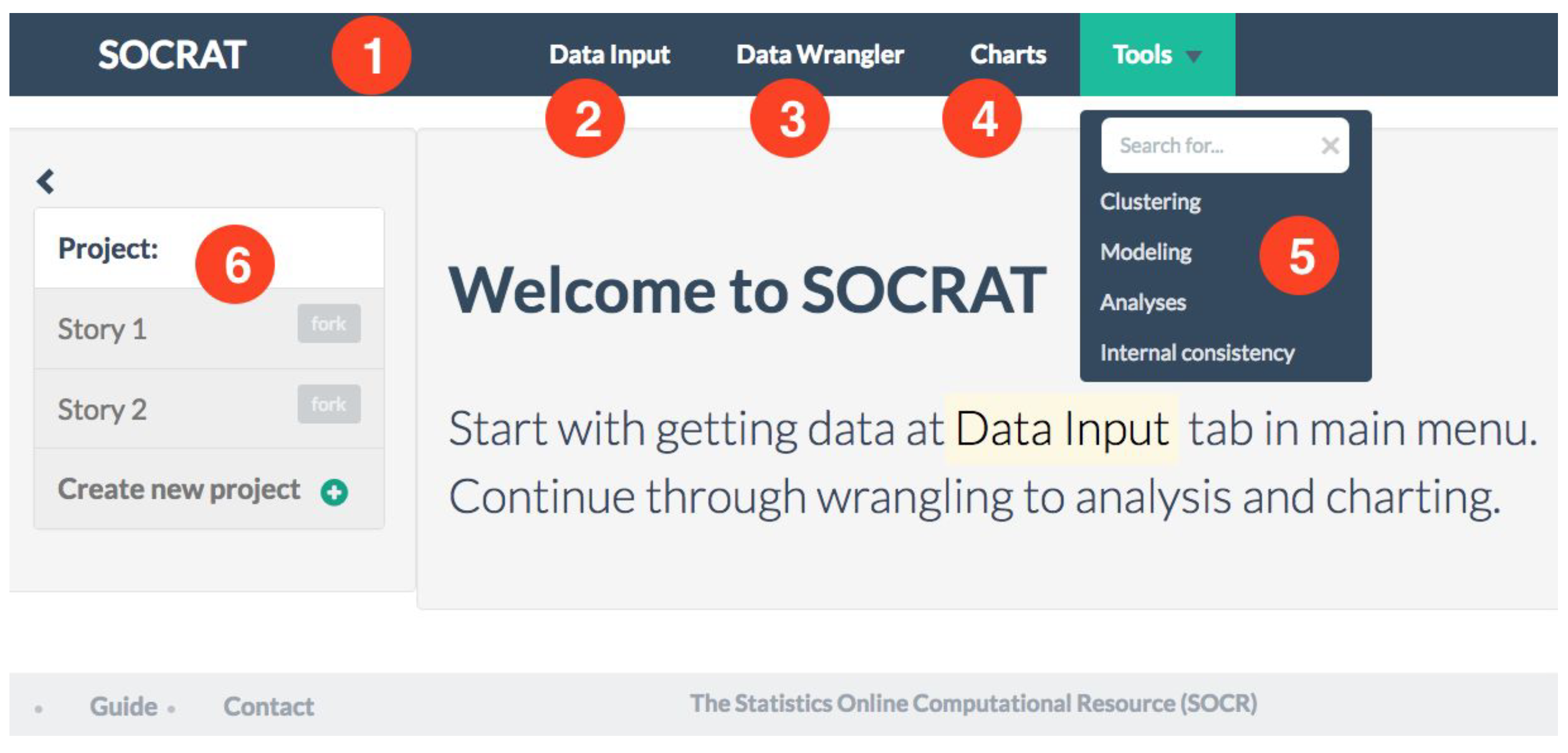
3.2. User Interface
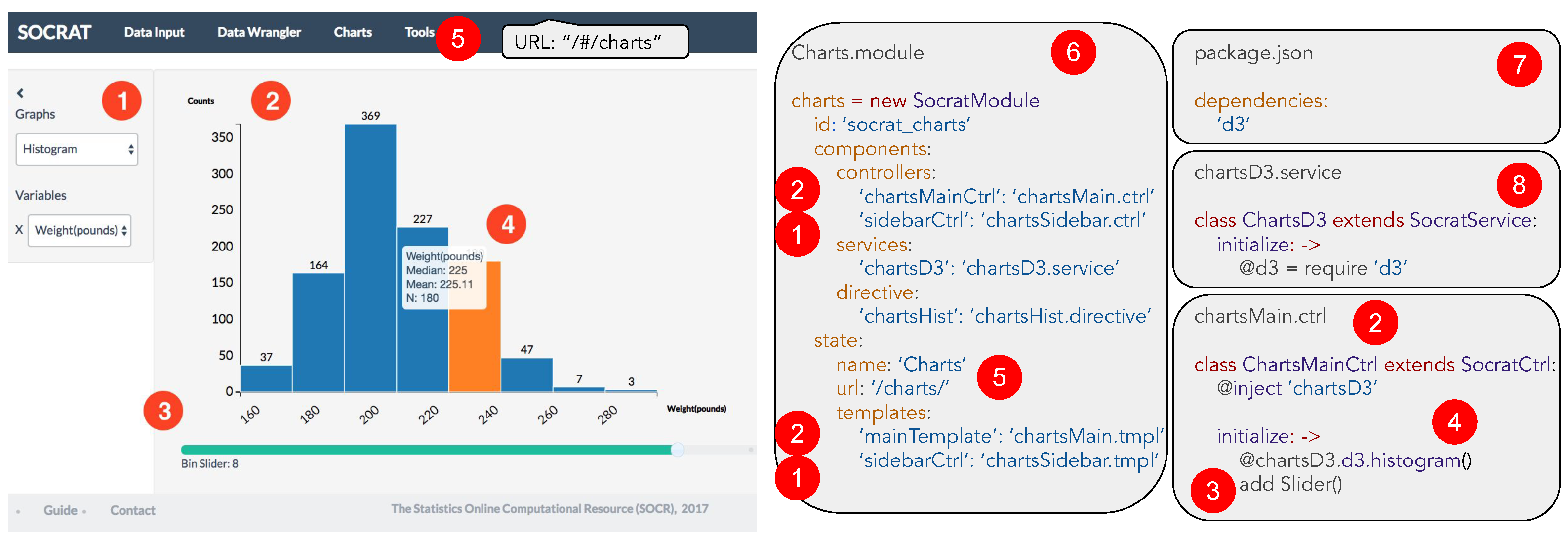
3.3. Modular Architecture
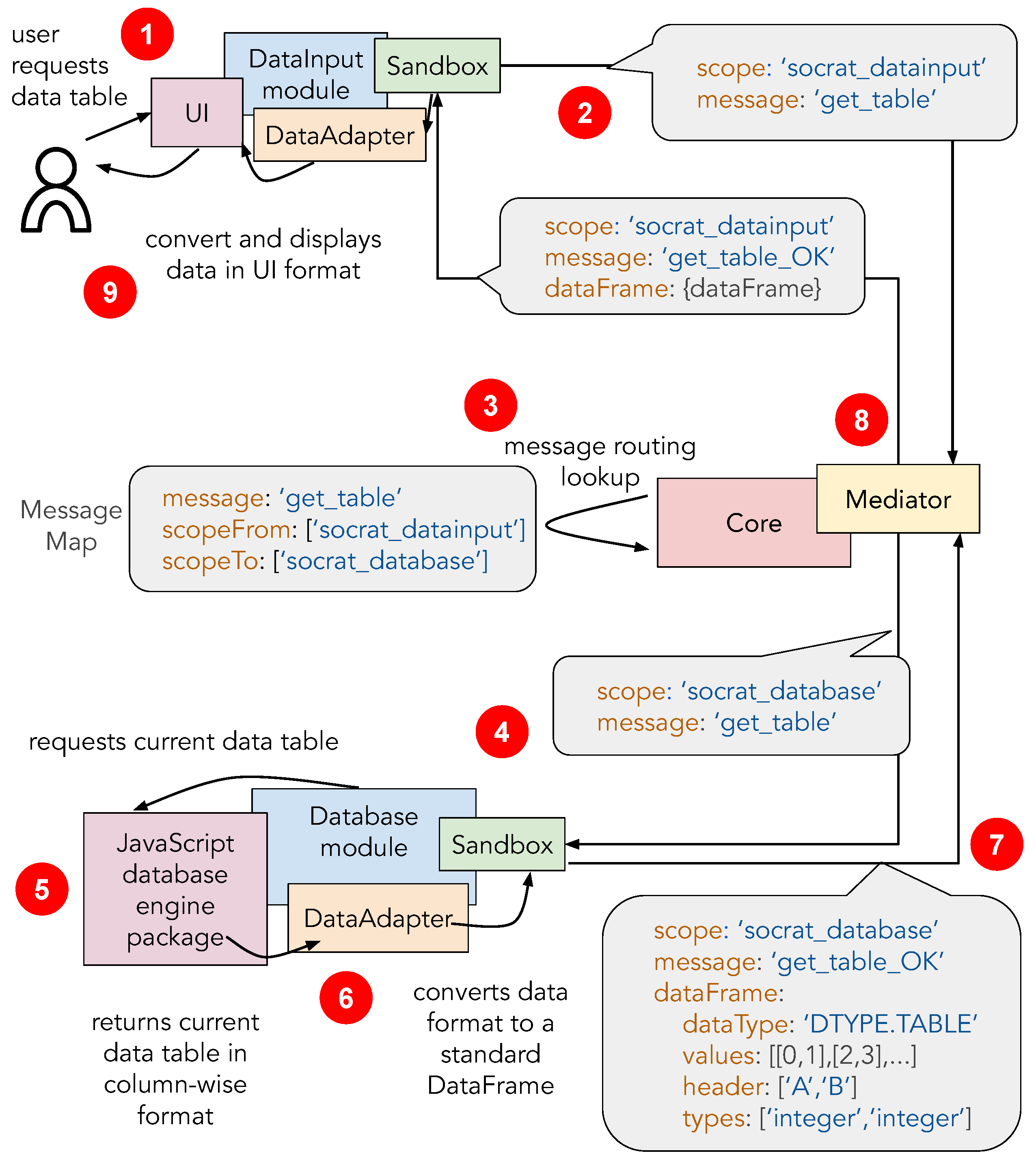
3.4. Basic Module Definition
3.5. Module Interaction
3.6. Module Specification with the User Interface
3.7. Third-Party Module Integration
4. Example Visual Analytics Capabilities
4.1. Data Management Tools
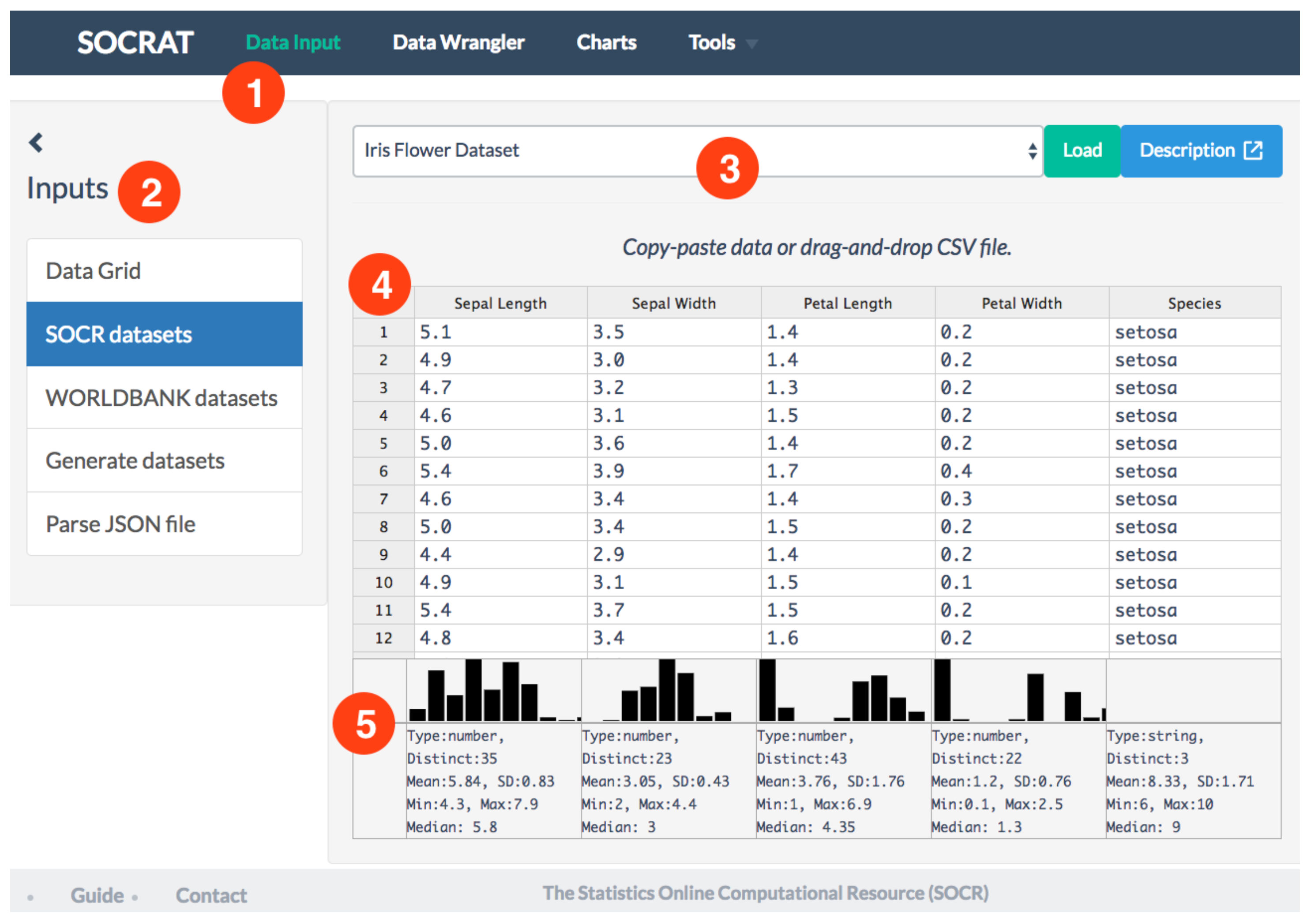
4.1.1. Data input and display
- Handsontable [50], a dynamic Excel-like data grid editor for raw data display and input via copy-and-paste;
- options to upload or drag-n-drop delimiter separated files such as CSV/TSV or JSON files, which SOCRAT will attempt to convert to tabular format;
- requests to various application program interfaces (APIs), e.g., World Bank APIs [51];
- over 50 predefined datasets are available from the SOCR Data resource [52], including climate, economic, business, and census datasets along with scientific data derived from multiple biomedical and healthcare studies.
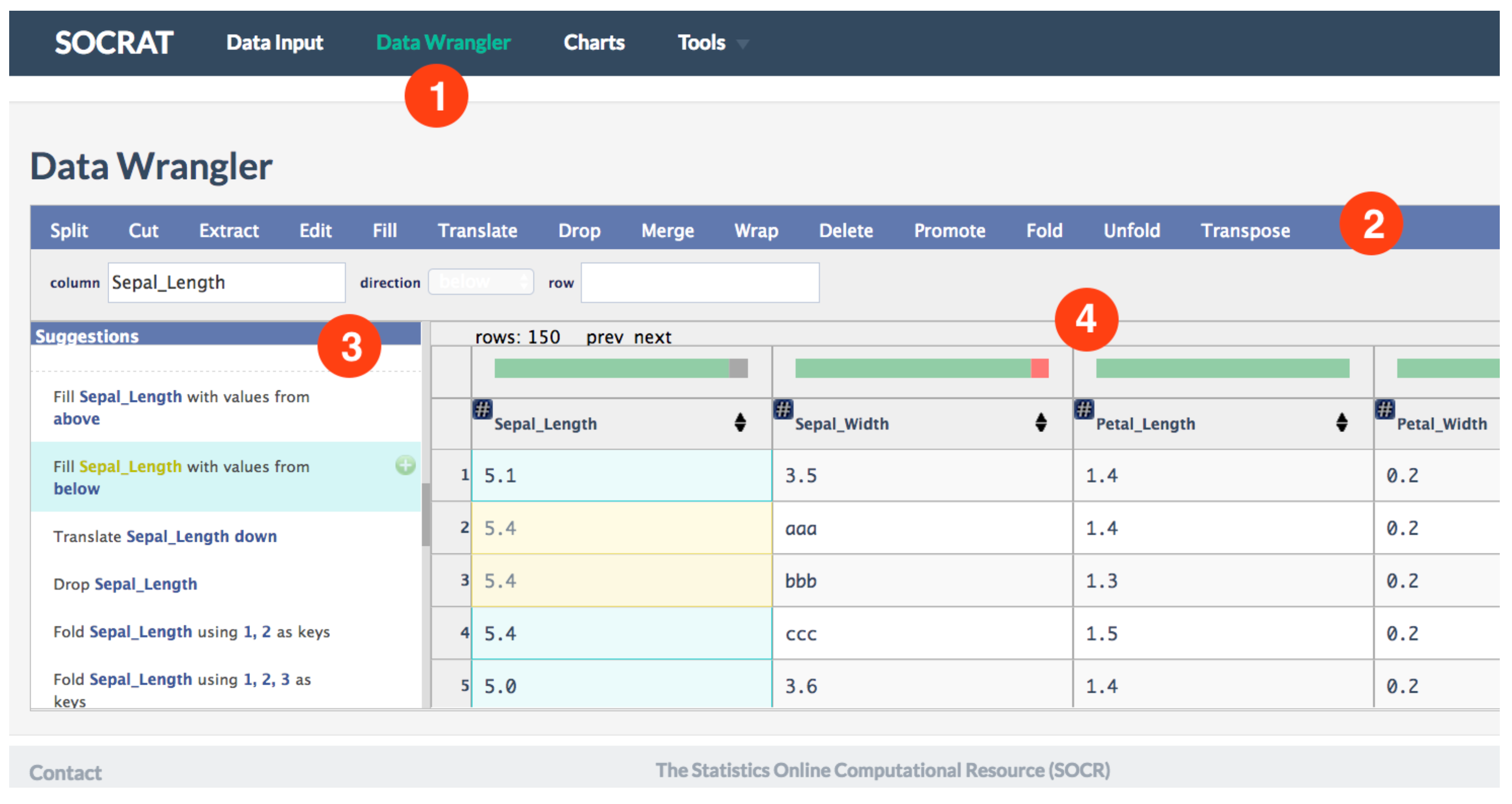
4.1.2. Data Storage, Querying, and Wrangling
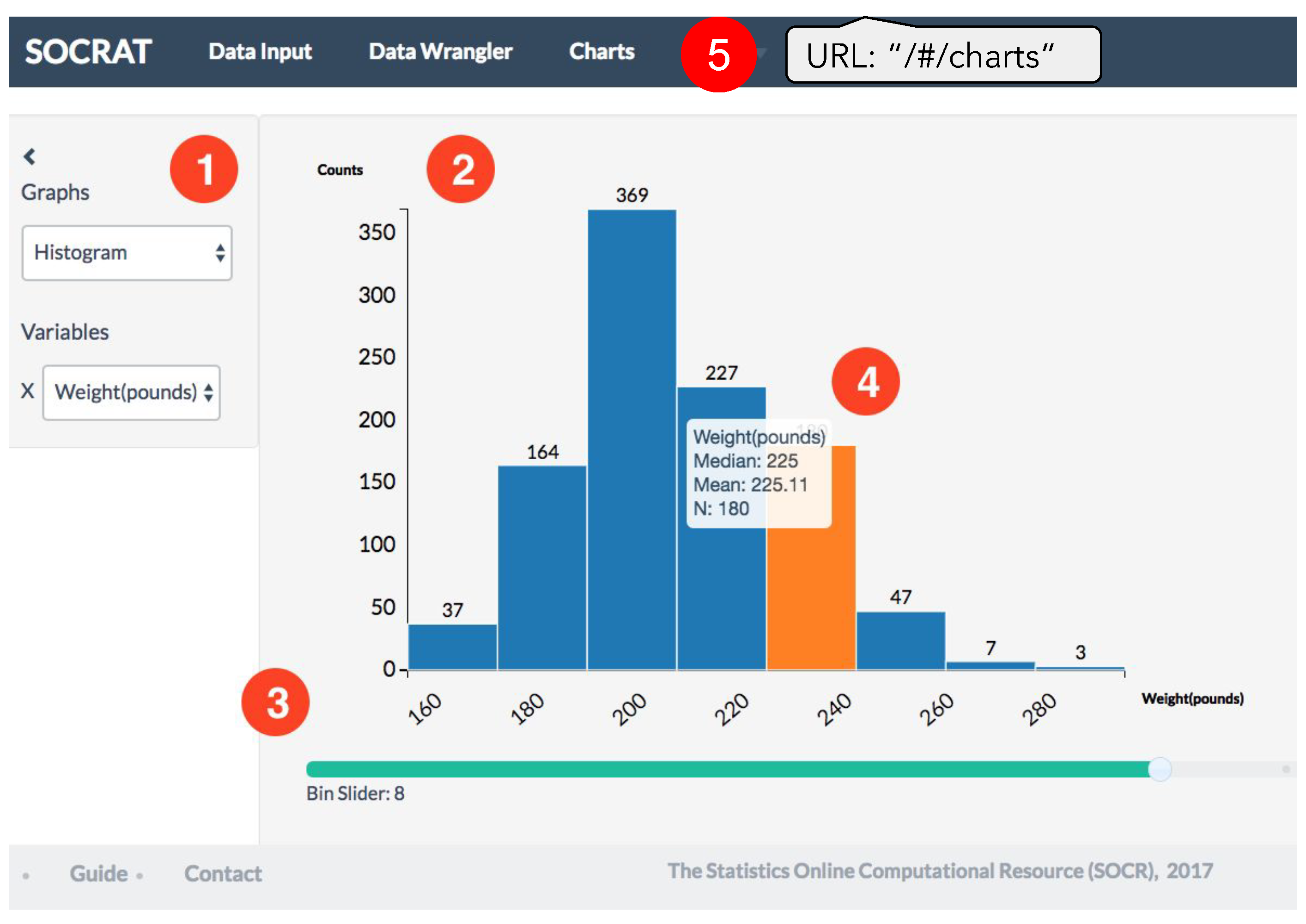
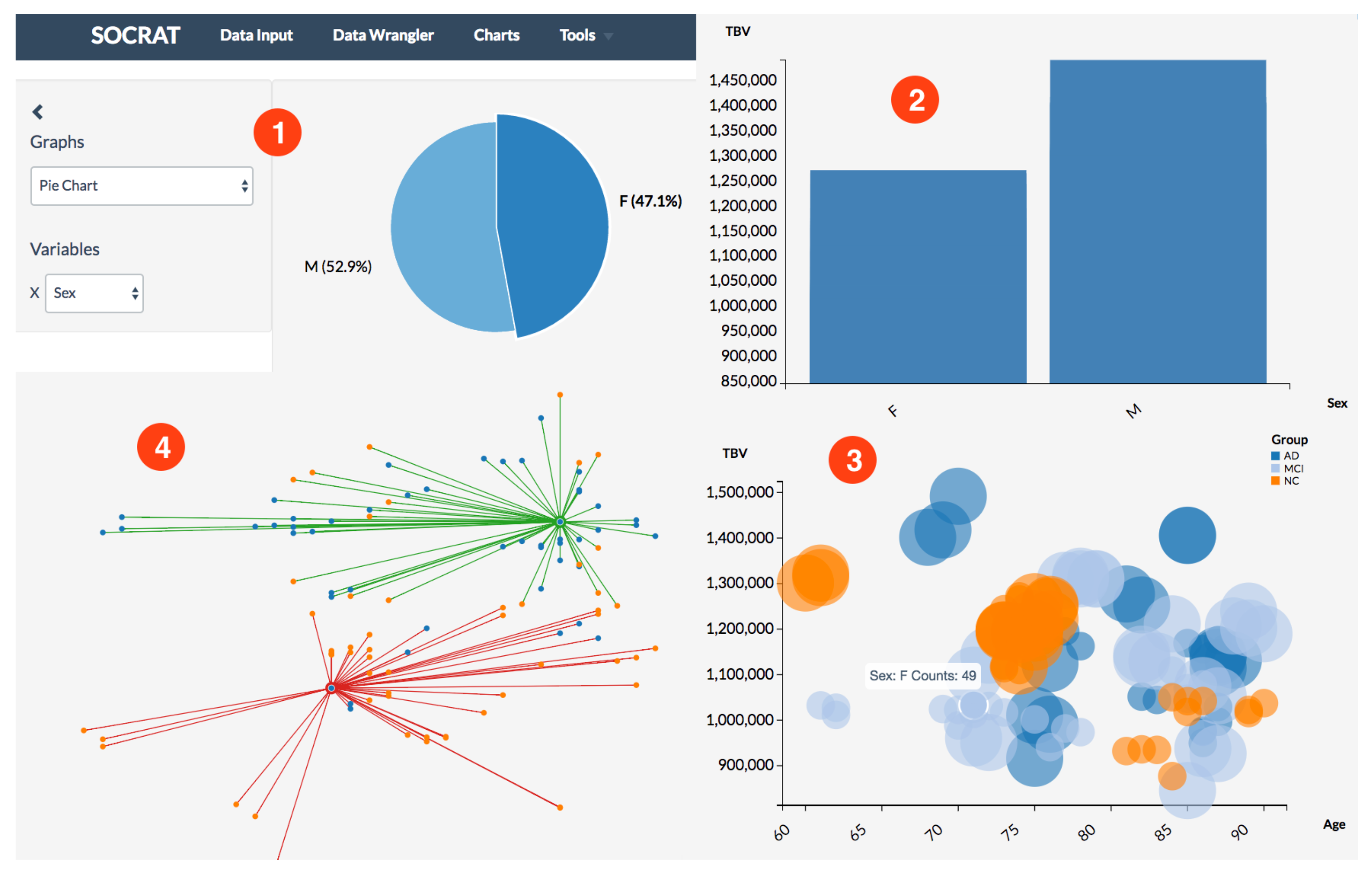
4.2. Interactive Visualizations
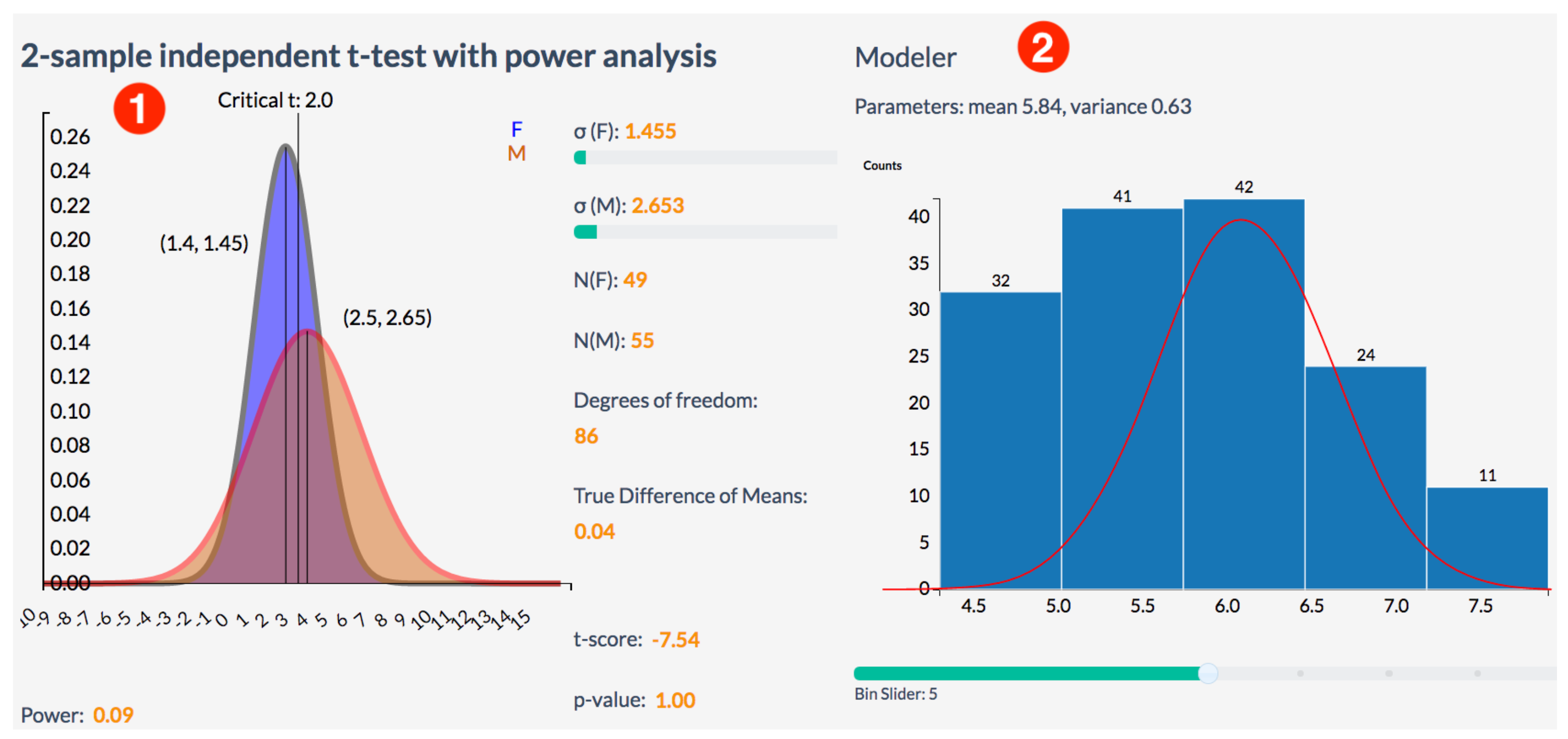
4.3. Data Modeling and Analytics
- statistical tests, such as t-test, ANOVA, etc.;
- power and sample size analysis;
- interactive clustering, including k-Means;
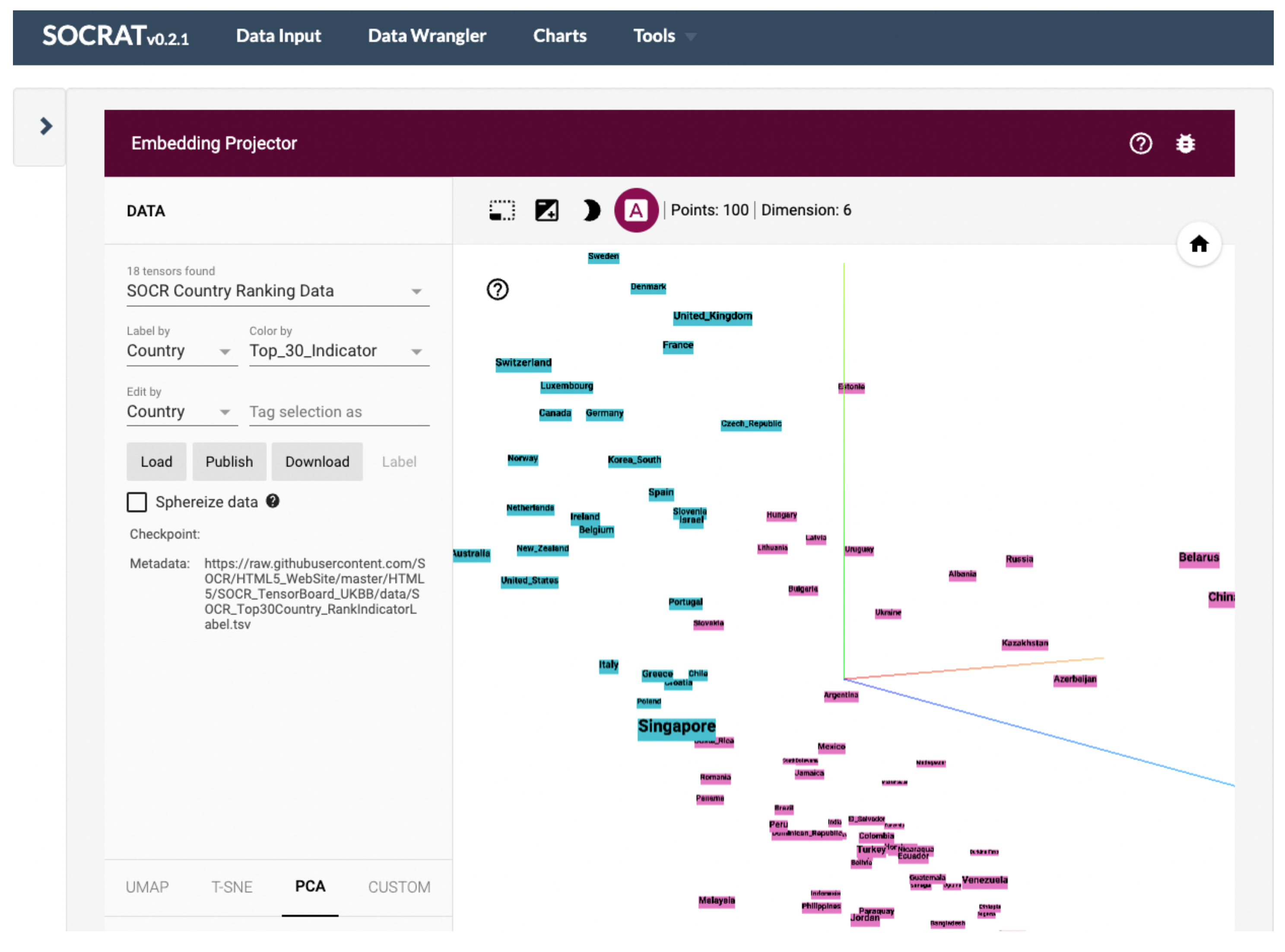
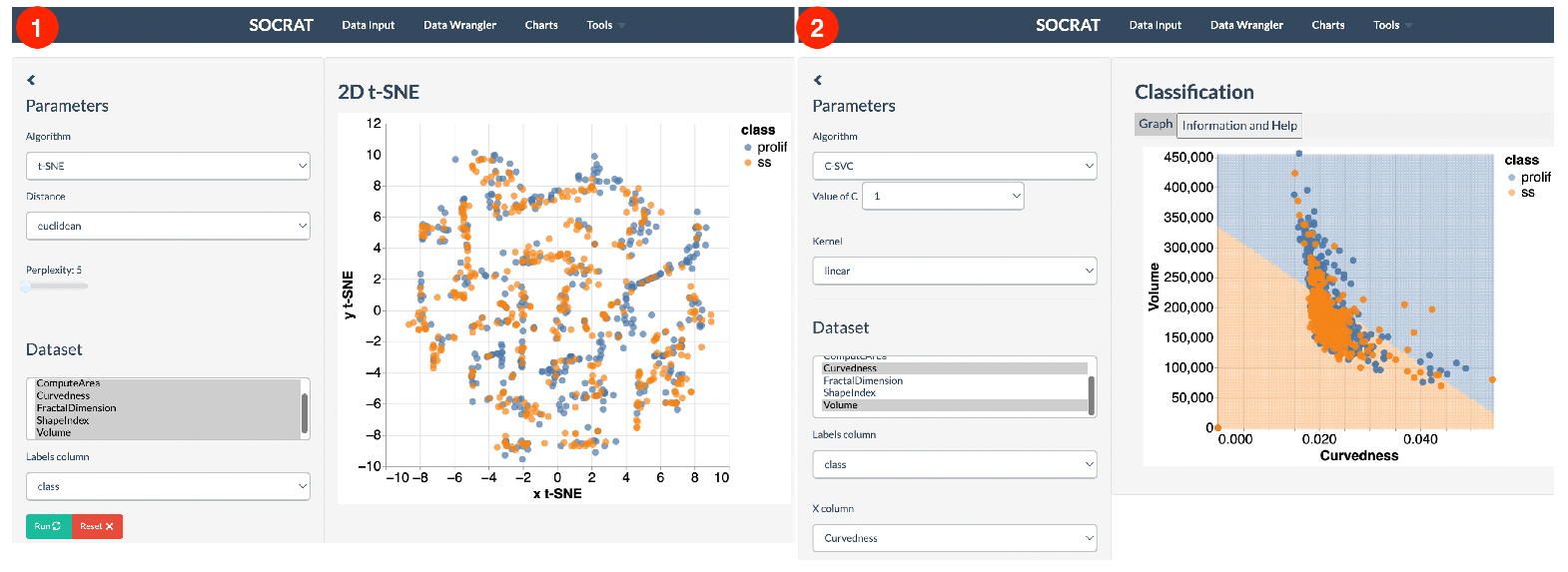
- dimensionality reduction with PCA, t-SNE, and other algorithms ( Figure 7).
5. Example Case Studies
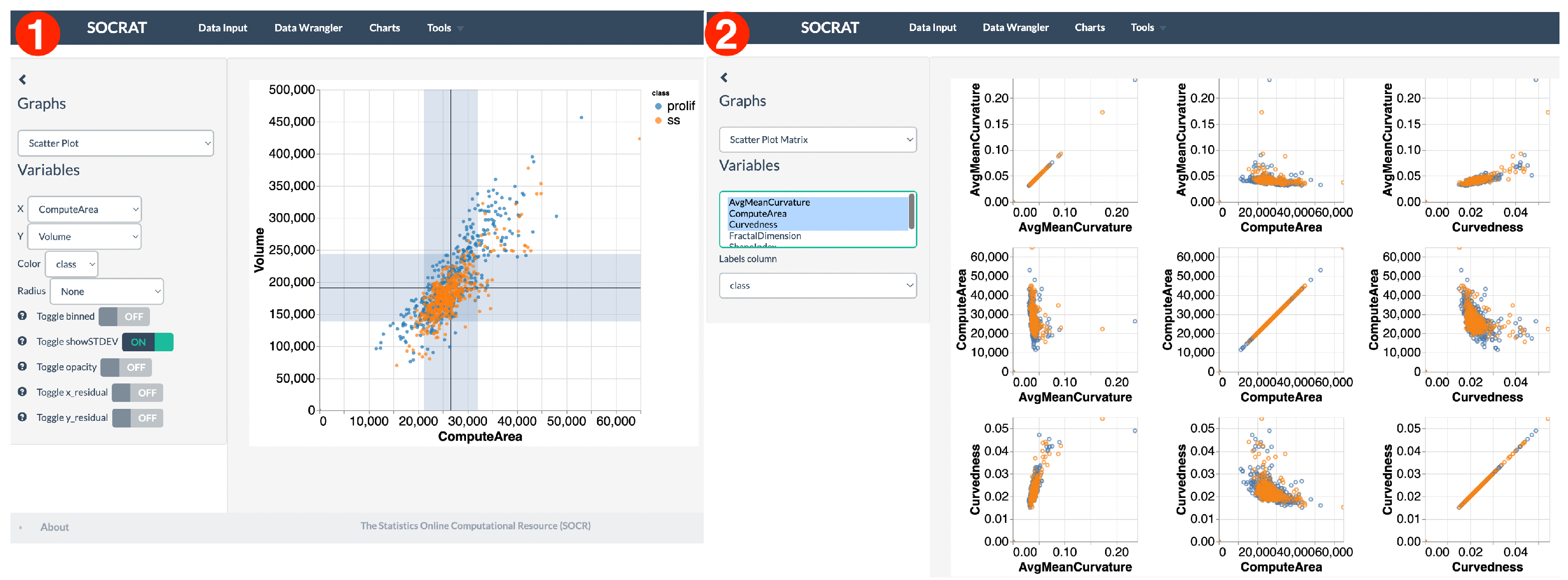
5.1. 3D Cell Morphological Analysis
- class: phenotypic state of the cell (PROLIF or SS);
- Average Mean Curvature: extrinsic measure of the surface curvature of the cell nucleus;
- Compute Area: surface area of the cell nucleus;
- Curvedness: magnitude of the local curvedness of the cell nucleus;
- Fractal Dimension: measure of the geometric complexity of the cell nucleus border;
- Shape Index: intrinsic measure of the relative curvature of the cell nucleus;
- Volume: volume of the cell nucleus.
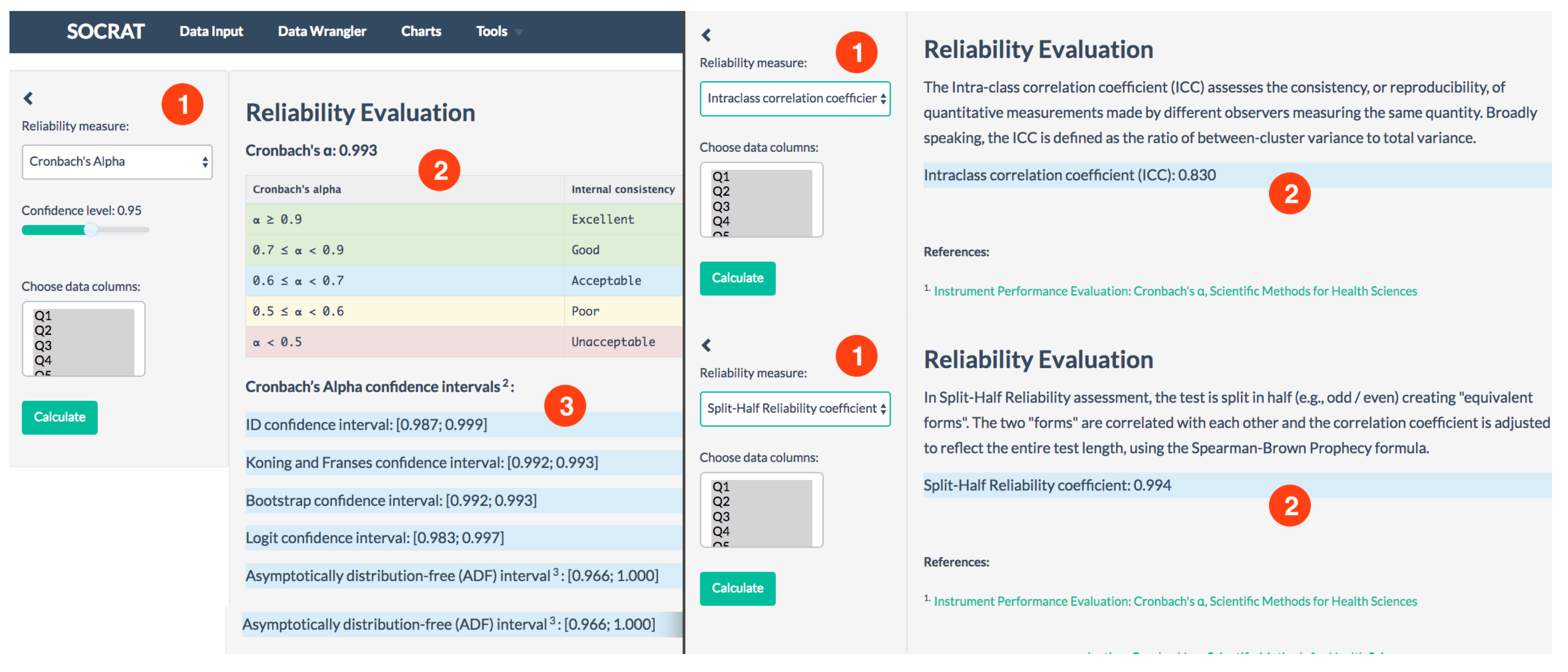
5.2. Internal Consistency Evaluation: Türkiye Student Evaluation Data
- Cronbach’s alpha is a coefficient of internal consistency that is commonly used as an estimate of the reliability;
- Intra-class correlation coefficient (ICC) assesses the consistency, or reproducibility, of quantitative measurements made by different observers measuring the same quantity. The ICC is defined as the ratio of between-cluster variance to total variance;
- Split-Half Reliability assessment, the test is split in half (e.g., odd/even) creating “equivalent forms”. The two “forms” are correlated with each other and the correlation coefficient is adjusted to reflect the entire test length, using the Spearman-Brown Prophecy formula.
- Instr: Instructor’s identifier with values taken from 1, 2, 3;
- Class: Course code (descriptor) with values taken from 1–13;
- Repeat: Number of times the student is taking this course with values taken from 0, 1, 2, 3,…;
- Attendance: Code of the level of attendance with values from 0, 1, 2, 3, 4;
- Difficulty: Level of difficulty of the course as perceived by the student with values taken from 1, 2, 3, 4, 5;
- Q1–Q28: course specific questions measured in Likert scale 1, 2, 3, 4, 5.
6. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 3D | Three-dimensional |
| AD | Alzheimer’s disease |
| ANOVA | Analysis of Variance |
| API | Application Programming Interface |
| CSV | Comma-separated Values |
| D³ | Data-Driven Documents |
| EDA | Exploratory Data Analysis |
| HTML | HyperText Markup Language |
| ICC | Intra-class Correlation Coefficient |
| JSON | JavaScript Object Notation |
| MCI | mild cognitive impairment |
| MVC | Model-view-controller |
| NC | Normal controls |
| npm | Node Package Manager |
| PCA | Principal Component Analysis |
| PROLIF | Proliferating (cells) |
| SOCR | Statistics Online Computational Resource |
| SOCRAT | Statistics Online Computational Resource Analytical Toolbox |
| SS | Serum-starved (cells) |
| SVM | Support Vector Machine |
| t-SNE | t-distributed Stochastic Neighbor Embedding |
| TSV | Tab-separated Values |
| VA | Visual Analytics |
| UI | User Interface |
| URL | Uniform Resource Locator |
Appendix A


References
- McAfee, A.; Brynjolfsson, E. Big data: The management revolution. Harv. Bus. Rev. 2012, 90, 60–68, 68, 128. [Google Scholar] [PubMed]
- Dinov, I.D. Data Science and Predictive Analytics: Biomedical and Health Applications Using R; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar] [CrossRef]
- Dinov, I.D.; Velev, M.V. Data Science: Time Complexity, Inferential Uncertainty, and Spacekime Analytics; De Gruyter: Berlin, Germany, 2021. [Google Scholar] [CrossRef]
- Keim, D.; Andrienko, G.; Fekete, J.D.; Görg, C.; Kohlhammer, J.; Melançon, G. Visual Analytics: Definition, Process, and Challenges. In Information Visualization; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2008; pp. 154–175. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Cui, W.; Wu, Y.; Liu, M. A survey on information visualization: Recent advances and challenges. Vis. Comput. 2014, 30, 1373–1393. [Google Scholar] [CrossRef]
- Herrera, D.; Chen, H.; Lavoie, E.; Hendren, L. Numerical computing on the web: Benchmarking for the future. In Proceedings of the 14th ACM SIGPLAN International Symposium on Dynamic Languages, Boston, MA, USA, 6 November 2018; pp. 88–100. [Google Scholar] [CrossRef] [Green Version]
- Steed, C.A.; Evans, K.J.; Harney, J.F.; Jewell, B.C.; Shipman, G.; Smith, B.E.; Thornton, P.E.; Williams, D.N. Web-based visual analytics for extreme scale climate science. In Proceedings of the 2014 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 27–30 October 2014. [Google Scholar] [CrossRef]
- Tukey, J.W. Exploratory Data Analysis; Pearson College Division: London, UK, 1977. [Google Scholar]
- Khan, F.; Foley-Bourgon, V.; Kathrotia, S.; Lavoie, E.; Hendren, L. Using JavaScript and WebCL for numerical computations. ACM SIGPLAN Not. 2014, 50, 91–102. [Google Scholar] [CrossRef]
- Heer, J.; Agrawala, M. Software design patterns for information visualization. IEEE Trans. Vis. Comput. Graph. 2006, 12, 853–860. [Google Scholar] [CrossRef] [PubMed]
- VanderPlas, J.; Granger, B.; Heer, J.; Moritz, D.; Wongsuphasawat, K.; Satyanarayan, A.; Lees, E.; Timofeev, I.; Welsh, B.; Sievert, S. Altair: Interactive Statistical Visualizations for Python. J. Open Source Softw. 2018, 3, 1057. [Google Scholar] [CrossRef]
- Booth, P.; Hall, W.; Gibbins, N.; Galanis, S. Visualising data in web observatories. In Proceedings of the 23rd International Conference on World Wide Web—WWW ’14 Companion, Seoul, Republic of Korea, 7–11 April 2014. [Google Scholar] [CrossRef]
- Dinov, I.D. SOCR: Statistics Online Computational Resource. J. Stat. Softw. 2006, 16, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Ince, D.C.; Hatton, L.; Graham-Cumming, J. The case for open computer programs. Nature 2012, 482, 485–488. [Google Scholar] [CrossRef] [Green Version]
- Bostock, M.; Ogievetsky, V.; Heer, J. D³ Data-Driven Documents. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2301–2309. [Google Scholar] [CrossRef]
- Fisher, D.; Drucker, S.M.; Fernandez, R.; Ruble, S. Visualizations everywhere: A multiplatform infrastructure for linked visualizations. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1157–1163. [Google Scholar] [CrossRef]
- Heimler, S. Development of a Modular JavaScript Data Display Framework. In Applied Research Conference 2014: 5th July 2014, Ingolstadt; Shaker Verlag GmbH: Düren, Germany, 2014. [Google Scholar] [CrossRef]
- Stolte, C.; Tang, D.; Hanrahan, P. Polaris: A system for query, analysis, and visualization of multidimensional relational databases. IEEE Trans. Vis. Comput. Graph. 2002, 8, 52–65. [Google Scholar] [CrossRef] [Green Version]
- Kandel, S.; Paepcke, A.; Hellerstein, J.; Heer, J. Wrangler: Interactive Visual Specification of Data Transformation Scripts. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; ACM: New York, NY, USA, 2011; pp. 3363–3372. [Google Scholar] [CrossRef]
- Guo, P.J.; Kandel, S.; Hellerstein, J.M.; Heer, J. Proactive wrangling. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology—UIST ’11, Santa Barbara, CA, USA, 16–19 October 2011. [Google Scholar] [CrossRef]
- Kandel, S.; Paepcke, A.; Hellerstein, J.M.; Heer, J. Enterprise Data Analysis and Visualization: An Interview Study. IEEE Trans. Vis. Comput. Graph. 2012, 18, 2917–2926. [Google Scholar] [CrossRef]
- Krishnan, S.; Haas, D.; Franklin, M.J.; Wu, E. Towards reliable interactive data cleaning. In Proceedings of the Workshop on Human-In-the-Loop Data Analytics—HILDA ’16, San Francisco, CA, USA, 26 June–1 July 2016. [Google Scholar] [CrossRef]
- Vega and Vega-Lite. Available online: https://vega.github.io/ (accessed on 17 September 2022).
- Rauschmayer, A. Exploring ES6: Upgrade to the Next Version of JavaScript. 2015. Available online: https://leanpub.com/exploring-es6 (accessed on 17 September 2022).
- Wongsuphasawat, K.; Moritz, D.; Anand, A.; Mackinlay, J.; Howe, B.; Heer, J. Voyager: Exploratory Analysis via Faceted Browsing of Visualization Recommendations. IEEE Trans. Vis. Comput. Graph. 2016, 22, 649–658. [Google Scholar] [CrossRef]
- Wongsuphasawat, K.; Qu, Z.; Moritz, D.; Chang, R.; Ouk, F.; Anand, A.; Mackinlay, J.; Howe, B.; Heer, J. Voyager 2: Augmenting Visual Analysis with Partial View Specifications. In Proceedings of the ACM CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017. [Google Scholar] [CrossRef]
- Satyanarayan, A.; Russell, R.; Hoffswell, J.; Heer, J. Reactive Vega: A Streaming Dataflow Architecture for Declarative Interactive Visualization. IEEE Trans. Vis. Comput. Graph. 2016, 22, 659–668. [Google Scholar] [CrossRef]
- Satyanarayan, A.; Moritz, D.; Wongsuphasawat, K.; Heer, J. Vega-Lite: A Grammar of Interactive Graphics. IEEE Trans. Vis. Comput. Graph. 2017, 23, 341–350. [Google Scholar] [CrossRef] [Green Version]
- Wongsuphasawat, K.; Moritz, D.; Anand, A.; Mackinlay, J.; Howe, B.; Heer, J. Towards a general-purpose query language for visualization recommendation. In Proceedings of the Workshop on Human-In-the-Loop Data Analytics—HILDA ’16, San Francisco, CA, USA, 26 June–1 July 2016. [Google Scholar] [CrossRef]
- Datalib. Available online: https://vega.github.io/datalib/ (accessed on 17 September 2022).
- Chu, A.; Cui, J.; Dinov, I.D. SOCR Analyses: Implementation and demonstration of a new graphical statistics educational toolkit. J. Stat. Softw. 2009, 30, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Chu, A.; Cui, J.; Dinov, I.D. SOCR Analyses—An Instructional Java Web-based Statistical Analysis Toolkit. J. Online Learn. Teach. 2009, 5, 1–18. [Google Scholar]
- Al-Aziz, J.; Christou, N.; Dinov, I.D. SOCR Motion Charts: An Efficient, Open-Source, Interactive and Dynamic Applet for Visualizing Longitudinal Multivariate Data. J. Stat. Educ. 2010, 18, 1–29. [Google Scholar] [CrossRef] [Green Version]
- JFreeChart. Available online: http://www.jfree.org/jfreechart (accessed on 17 September 2022).
- Dinov, I.D.; Siegrist, K.; Pearl, D.K.; Kalinin, A.; Christou, N. Probability Distributome: A Web Computational Infrastructure for Exploring the Properties, Interrelations, and Applications of Probability Distributions. Comput. Stat. 2016, 31, 559–577. [Google Scholar] [CrossRef] [Green Version]
- Bobrovnikov, M.; Chai, J.T.; Dinov, I.D. Interactive visualization and computation of 2D and 3D probability distributions. SN Comput. Sci. 2022, 3, 327. [Google Scholar] [CrossRef]
- Education: Statistics Starter Kit. Science 2003, 302, 1635. [CrossRef] [Green Version]
- Dinov, I.D.; Christou, N. Statistics Online Computational Resource for Education. Teach. Stat. 2009, 31, 49–51. [Google Scholar] [CrossRef] [Green Version]
- Dinov, I.D.; Sanchez, J.; Christou, N. Pedagogical Utilization and Assessment of the Statistic Online Computational Resource in Introductory Probability and Statistics Courses. Comput. Educ. 2008, 50, 284–300. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dinov, I.D.; Christou, N. Web-based tools for modelling and analysis of multivariate data: California ozone pollution activity. Int. J. Math. Educ. Sci. Technol. 2011, 42, 789–829. [Google Scholar] [CrossRef] [Green Version]
- Husain, S.S.; Kalinin, A.; Truong, A.; Dinov, I.D. SOCR data dashboard: An integrated big data archive mashing medicare, labor, census and econometric information. J. Big Data 2015, 2, 13. [Google Scholar] [CrossRef] [Green Version]
- US-CERT. Oracle Java Contains Multiple Vulnerabilities. Alert (TA13-064A). 2013. Available online: https://www.cisa.gov/uscert/ncas/alerts/TA13-064A (accessed on 17 September 2022).
- Smith, D. Even Further Updates to ‘Moving to a Plugin Free Web’. 2017. Available online: https://blogs.oracle.com/java/post/even-further-updates-to-moving-to-a-plugin-free-web (accessed on 17 September 2022).
- Kalinin, A.A.; Palanimalai, S.; Dinov, I.D. SOCRAT Platform Design: A Web Architecture for Interactive Visual Analytics Applications. In Proceedings of the Workshop on Human-In-the-Loop Data Analytics—HILDA’17, Chicago, IL, USA, 14–19 May 2017. [Google Scholar] [CrossRef] [Green Version]
- Node.js. Available online: https://nodejs.org/ (accessed on 16 September 2022).
- AngularJS. Available online: https://angularjs.org/ (accessed on 16 September 2022).
- CoffeeScript. Available online: https://coffeescript.org/ (accessed on 16 September 2022).
- npm. Available online: https://www.npmjs.com/ (accessed on 17 September 2022).
- Datavore. Available online: http://vis.stanford.edu/projects/datavore/ (accessed on 17 September 2022).
- Handsontable. Available online: https://handsontable.com/ (accessed on 17 September 2022).
- The World Bank Developer Information: Overview. Available online: https://datahelpdesk.worldbank.org/knowledgebase/articles/889386-developer-information-overview (accessed on 17 September 2022).
- SOCR Data. Available online: http://wiki.socr.umich.edu/index.php/SOCR_Data (accessed on 17 September 2022).
- Smilkov, D.; Thorat, N.; Nicholson, C.; Reif, E.; Viégas, F.B.; Wattenberg, M. Embedding Projector: Interactive Visualization and Interpretation of Embeddings. arXiv 2016, arXiv:1611.05469. [Google Scholar]
- Dinov, I.D.; Van Horn, J.D.; Lozev, K.M.; Magsipoc, R.; Petrosyan, P.; Liu, Z.; Mackenzie-Graham, A.; Eggert, P.; Parker, D.S.; Toga, A.W. Efficient, Distributed and Interactive Neuroimaging Data Analysis Using the LONI Pipeline. Front. Neuroinform. 2009, 3, 22. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kalinin, A.A.; Allyn-Feuer, A.; Ade, A.; Fon, G.V.; Meixner, W.; Dilworth, D.; de Wet, J.R.; Higgins, G.A.; Zheng, G.; Creekmore, A.; et al. 3D cell nuclear morphology: Microscopy imaging dataset and voxel-based morphometry classification results. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar] [CrossRef]
- Kalinin, A.A.; Allyn-Feuer, A.; Ade, A.; Fon, G.V.; Meixner, W.; Dilworth, D.; Husain, S.S.; de Wet, J.R.; Higgins, G.A.; Zheng, G.; et al. 3D Shape Modeling for Cell Nuclear Morphological Analysis and Classification. Sci. Rep. 2018, 8, 13658. [Google Scholar] [CrossRef] [Green Version]
- Kalinin, A.A.; Hou, X.; Ade, A.S.; Fon, G.V.; Meixner, W.; Higgins, G.A.; Sexton, J.Z.; Wan, X.; Dinov, I.D.; O’Meara, M.J.; et al. Valproic acid-induced changes of 4D nuclear morphology in astrocyte cells. Mol. Biol. Cell 2021, 32, 1624–1633. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory —COLT ’92, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar] [CrossRef]
- Scientific Methods for Health Sciences. Available online: http://wiki.socr.umich.edu/index.php/Scientific_Methods_for_Health_Sciences (accessed on 17 September 2022).
- Tsagris, M.; Frangos, C.C.; Frangos, C.C. Confidence intervals for Cronbach’s reliability coefficient. In Proceedings of the 1st International Conference on Computer Supported Education (COSUE ’13), Athens, Greece, 14–16 May 2013; Tavares Martins, A.M., Naaji, A., Fournier-Viger, P., Eds.; WSEAS Press: Athens, Greece, 2013; pp. 152–157. [Google Scholar]
- Maydeu-Olivares, A.; Coffman, D.L.; Hartmann, W.M. Asymptotically distribution-free (ADF) interval estimation of coefficient alpha. Psychol. Methods 2007, 12, 157–176. [Google Scholar] [CrossRef] [Green Version]
- Gunduz, N.; Fokoue, E. UCI Machine Learning Repository. 2013. Available online: http://archive.ics.uci.edu/ml (accessed on 25 October 2022).
- Li, G.; Li, R.; Wang, Z.; Liu, C.H.; Lu, M.; Wang, G. HiTailor: Interactive transformation and visualization for hierarchical tabular data. IEEE Trans. Vis. Comput. Graph. 2022, 1–10. [Google Scholar] [CrossRef]
- Wang, C.; Chen, M.H.; Schifano, E.; Wu, J.; Yan, J. Statistical methods and computing for big data. Stat. Interface 2016, 9, 399. [Google Scholar] [CrossRef] [Green Version]
- Haas, A.; Rossberg, A.; Schuff, D.L.; Titzer, B.L.; Holman, M.; Gohman, D.; Wagner, L.; Zakai, A.; Bastien, J. Bringing the web up to speed with WebAssembly. In Proceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation, Barcelona, Spain, 18–23 June 2017; pp. 185–200. [Google Scholar] [CrossRef]












Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kalinin, A.A.; Palanimalai, S.; Zhu, J.; Wu, W.; Devraj, N.; Ye, C.; Ponarul, N.; Husain, S.S.; Dinov, I.D. SOCRAT: A Dynamic Web Toolbox for Interactive Data Processing, Analysis and Visualization. Information 2022, 13, 547. https://doi.org/10.3390/info13110547
Kalinin AA, Palanimalai S, Zhu J, Wu W, Devraj N, Ye C, Ponarul N, Husain SS, Dinov ID. SOCRAT: A Dynamic Web Toolbox for Interactive Data Processing, Analysis and Visualization. Information. 2022; 13(11):547. https://doi.org/10.3390/info13110547
Chicago/Turabian StyleKalinin, Alexandr A., Selvam Palanimalai, Junqi Zhu, Wenyi Wu, Nikhil Devraj, Chunchun Ye, Nellie Ponarul, Syed S. Husain, and Ivo D. Dinov. 2022. "SOCRAT: A Dynamic Web Toolbox for Interactive Data Processing, Analysis and Visualization" Information 13, no. 11: 547. https://doi.org/10.3390/info13110547
APA StyleKalinin, A. A., Palanimalai, S., Zhu, J., Wu, W., Devraj, N., Ye, C., Ponarul, N., Husain, S. S., & Dinov, I. D. (2022). SOCRAT: A Dynamic Web Toolbox for Interactive Data Processing, Analysis and Visualization. Information, 13(11), 547. https://doi.org/10.3390/info13110547