
AR-Sanad 280K: A Novel 280K Artificial Sanads Dataset for Hadith Narrator Disambiguation

 , , and
, , and
Abstract
:1. Introduction
Contributions
- Introducing a new Arabic dataset of artificial sanads (AR-Sanad 280K) with identified narrators. This dataset could be used to train systems to disambiguate narrators’ names when their full names are not mentioned;
- Introducing a new dataset of real sanads that we use as a test set to evaluate models’ performance on real data;
- We also present a systematic benchmark evaluation using AraBERT, a BERT-based model trained on a very large Arabic corpus. We also evalauate other models on the lite version of the AR-Sanad 280K dataset. This evaluation can be used by other studies to improve the models designed for the narrator disambiguation task.
2. Related Work
2.1. Hadith Computation
2.2. Word Sense Disambiguation
2.3. Arabic Named Entity Disambiguation
3. AR-Sanad 280K Dataset
3.1. Creating Artificial Sanads
- We pick a random narrator ID that he/she narrated to and a random narrator ID that he/she narrated from;
- For the two narrators IDs we picked, we select two other narrators IDs they narrated to/from;
- For each narrator of the five narrators, we select a random name from their appearance forms;
- The term [فاصل] (Means separator) is used as a separator between the five names, and the final sanad is in the form:name1 [فاصل] name2 [فاصل] ... [فاصل] name5
- We repeat steps 1–4 a few times depending on the number of narrators they narrated to/form.
3.2. Special Appearance Forms
3.3. Dataset Refinement
- We removed duplicate sanads;
- We removed any name that was misspelled in appearance forms;
- After filtering the appearance forms, some narrators did not have appearance forms. We referred to them using their full names. If the name was too long we use only their first four names;
- We removed duplicate narrators who have identical information in the narrators’ list, i.e., same full name, kunia, death date, etc.
3.4. Dataset Statistics
3.5. Creating Lite Dataset
4. Experiments
4.1. Lite Dataset
4.1.1. Static Embeddings
4.1.2. AraBERT
4.1.3. Other Deep Learning Models
4.2. Full Dataset
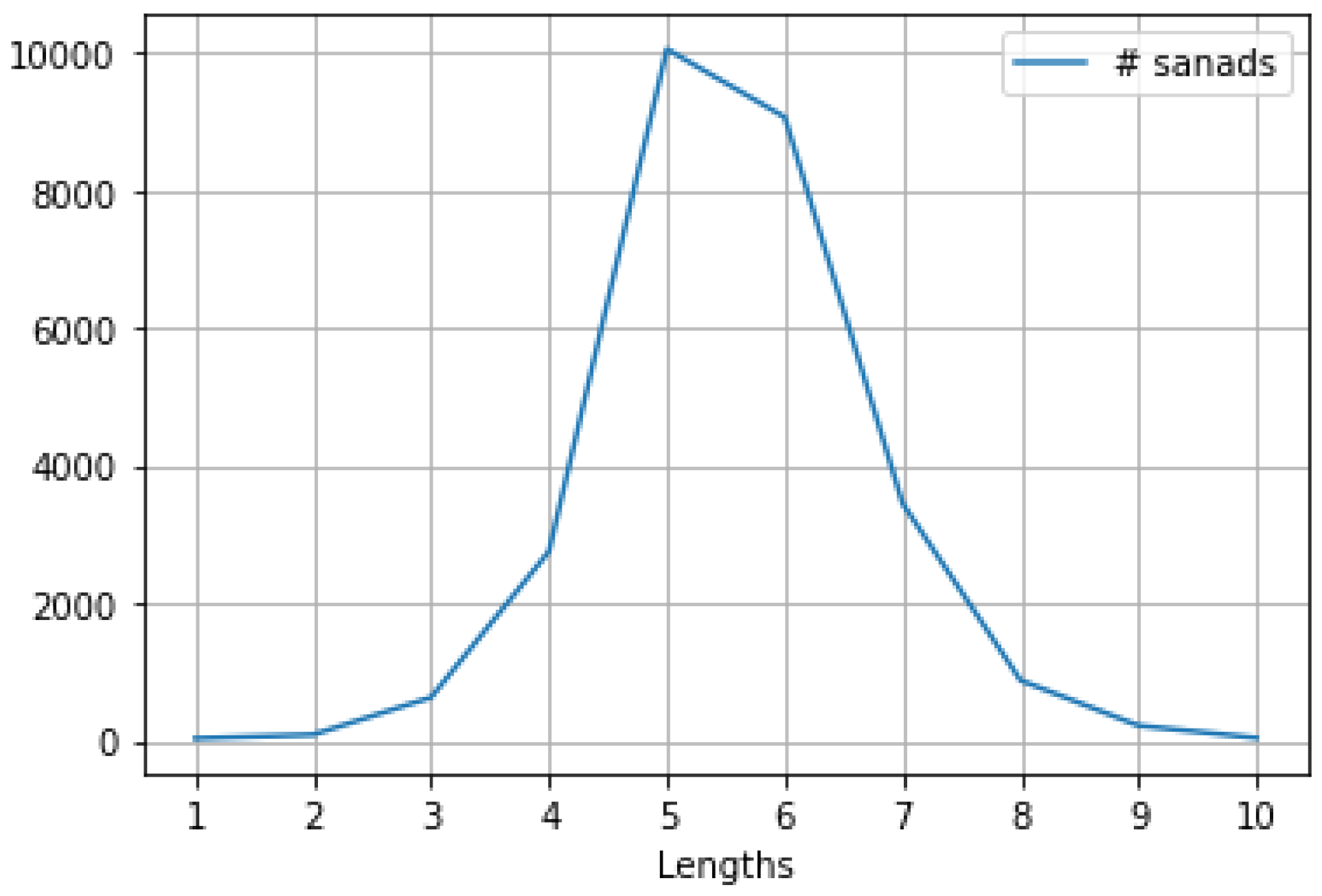
Effect of Sanad Length
4.3. Real Sanads Test Set
4.3.1. Effect of Farasa Segmenter
4.4. Implementation Details
5. Analysis
- First, we look at some of the predictions made by the model. In Figure 8 and Figure 9, we show a few examples of false and true predictions and the narrators’ true identities. We notice that in most cases the model’s confidence level is higher for true predictions than false ones. In total, 68.3% of all narrators were identified correctly with a confidence level of 90% or above. In total, 81.7% of the correct predictions have a confidence level of 90% or above. Only 12.9% of the false predictions have a confidence level of 90% or above;
- Special appearance forms could be a little confusing for models, since the narrator name is not stated. Only 71% of the narrators that appeared in a special form were classified correctly;
- Figure 10 shows examples of narrators that were not identified correctly, but their true identities were in the top five most probable ones. Most of them are called by common short names;
- As we shown in Table 2, there are many narrators who have similar appearance forms. There were 3669 instances of the names showed in the table; only 26% were correctly identified. We hope that our AR-Sanad 280K dataset could be used to build better systems that can manage to avoid such errors.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Esposito, J.L. The Future of Islam; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Khan, I.A. Authentication of Hadith: Redefining the Criteria; Iiit: Herndon, VA, USA, 2010. [Google Scholar]
- مقدمة النووي في علوم الحديث: وهي مقدمةعلى صحيح مسلم. 1996.
- Azmi, A.M.; Al-Qabbany, A.O.; Hussain, A. Computational and natural language processing based studies of hadith literature: A survey. Artif. Intell. Rev. 2019, 52, 1369–1414. [Google Scholar] [CrossRef]
- Astari, A.; Bijaksana, M.A.; Suryani, A.A. Analysis Name Entity Disambiguation Using Mining Evidence Method. Paradig. J. Inform. Komput. 2020, 22, 101–108. [Google Scholar] [CrossRef]
- Azmi, A.M.; AlOfaidly, A.M. A novel method to automatically pass hukm on hadith. In Proceedings of the 5th International Conference on Arabic Language Processing (CITALA’14), Oujda, Morocco, 26–27 November 2014; pp. 26–27. [Google Scholar]
- Al-Azami, M.M. A note on work in progress on computerization of hadith. J. Islam. Stud. 1991, 2, 86–91. [Google Scholar] [CrossRef]
- Alias, N.; Abd Rahman, N.; Nor, Z.; Alias, M. Searching algorithm of authentic chain of narrators’ in Shahih Bukhari book. In Proceedings of the International Conference on Applied Computing, Mathematical Sciences and Engineering (ACME 2016), Johor Bahru, Malaysia, 30–31 May 2016. [Google Scholar]
- Luthfi, E.T.; Suryana, N.; Basari, A.H. Digital hadith authentication: A literature review and analysis. J. Theor. Appl. Inf. Technol. 2018, 96, 5054–5068. [Google Scholar]
- Mahmood, A.; Khan, H.U.; Alarfaj, F.K.; Ramzan, M.; Ilyas, M. A multilingual datasets repository of the hadith content. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 165–172. [Google Scholar] [CrossRef]
- Altammami, S.; Atwell, E.; Alsalka, A. Constructing a Bilingual Hadith Corpus Using a Segmentation Tool. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; pp. 3390–3398. [Google Scholar]
- Hadiwinoto, C.; Ng, H.T.; Gan, W.C. Improved Word Sense Disambiguation Using Pre-Trained Contextualized Word Representations. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5297–5306. [Google Scholar]
- Loureiro, D.; Jorge, A. Language Modelling Makes Sense: Propagating Representations through WordNet for Full-Coverage Word Sense Disambiguation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5682–5691. [Google Scholar]
- Levine, Y.; Lenz, B.; Dagan, O.; Ram, O.; Padnos, D.; Sharir, O.; Shalev-Shwartz, S.; Shashua, A.; Shoham, Y. SenseBERT: Driving Some Sense into BERT. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual Online. 5–10 July 2020; pp. 4656–4667. [Google Scholar]
- Bevilacqua, M.; Navigli, R. Breaking through the 80% glass ceiling: Raising the state of the art in word sense disambiguation by incorporating knowledge graph information. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual Online. 5–10 July 2020; pp. 2854–2864. [Google Scholar]
- Huang, L.; Sun, C.; Qiu, X.; Huang, X.J. GlossBERT: BERT for Word Sense Disambiguation with Gloss Knowledge. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3509–3514. [Google Scholar]
- Blevins, T.; Zettlemoyer, L. Moving Down the Long Tail of Word Sense Disambiguation with Gloss Informed Bi-encoders. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual Online. 5–10 July 2020; pp. 1006–1017. [Google Scholar]
- Yosef, M.A.; Spaniol, M.; Weikum, G. AIDArabic A Named-Entity Disambiguation Framework for Arabic Text. In Proceedings of the EMNLP 2014 Workshop on Arabic Natural Language Processing (ANLP), Doha, Qatar, 25 October 2014; pp. 187–195. [Google Scholar]
- Hoffart, J.; Yosef, M.A.; Bordino, I.; Fürstenau, H.; Pinkal, M.; Spaniol, M.; Taneva, B.; Thater, S.; Weikum, G. Robust disambiguation of named entities in text. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 782–792. [Google Scholar]
- Al-Smadi, M.; Talafha, B.; Qawasmeh, O.; Alandoli, M.N.; Hussien, W.A.; Guetl, C. A hybrid approach for Arabic named entity disambiguation. In Proceedings of the 15th International Conference on Knowledge Technologies and Data-Driven Business, Graz, Austria, 21–22 October 2015; pp. 1–4. [Google Scholar]
- Gad-Elrab, M.H.; Yosef, M.A.; Weikum, G. Named entity disambiguation for resource-poor languages. In Proceedings of the Eighth Workshop on Exploiting Semantic Annotations in Information Retrieval, Melbourne, Australia, 23 October 2015; pp. 29–34. [Google Scholar]
- Mahdisoltani, F.; Biega, J.; Suchanek, F.M. A Knowledge Base from Multilingual Wikipedias–Yago3. Technical Report, Technical Report, Telecom ParisTech. Available online: https://suchanek.name/work/publications/cidr2015.pdf (accessed on 15 November 2021).
- Steinberger, R.; Pouliquen, B.; Kabadjov, M.; Belyaeva, J.; van der Goot, E. JRC-NAMES: A Freely Available, Highly Multilingual Named Entity Resource. In Proceedings of the International Conference Recent Advances in Natural Language Processing, Hissar, Bulgaria, 12–14 September 2011; pp. 104–110. [Google Scholar]
- Spitkovsky, V.I.; Chang, A.X. A cross-lingual dictionary for english wikipedia concepts. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 21–27 May 2012. [Google Scholar]
- Prasetio, A.; Bijaksana, M.A.; Suryani, A.A. Name Disambiguation Analysis Using the Word Sense Disambiguation Method in Hadith. Edumatic J. Pendidik. Inform. 2020, 4, 68–74. [Google Scholar] [CrossRef]
- Bin Ibrahim Saif, O. The Attention Given to Al-Muhmaluun (the Unspecified) Narrators in the Program of the Custodian of the Two Holy Mosques for the Prophetic Sunnah. Islam. Univ. J. 2020, 1, 379–429. [Google Scholar]
- Shukur, Z.; Fabil, N.; Salim, J.; Noah, S.A. Visualization of the hadith chain of narrators. In Proceedings of the International Visual Informatics Conference; Springer: Berlin/Heidelberg, Germany, 2011; pp. 340–347. [Google Scholar]
- Boella, M.; Romani, F.R.; Al-Raies, A.; Solimando, C.; Lancioni, G. The SALAH Project: Segmentation and linguistic analysis of Hadith Arabic texts. In Proceedings of the Asia Information Retrieval Symposium; Springer: Berlin/Heidelberg, Germany, 2011; pp. 538–549. [Google Scholar]
- Siddiqui, M.A.; Saleh, M.; Bagais, A.A. Extraction and visualization of the chain of narrators from hadiths using named entity recognition and classification. Int. J. Comput. Linguist. Res 2014, 5, 14–25. [Google Scholar]
- Alhawarat, M. A domain-based approach to extract Arabic person names using n-grams and simple rules. Asian J. Inf. Technol. 2015, 14, 287–293. [Google Scholar]
- Hamam, H.; Othman, M.T.B.; Kilani, A.; Ben, M. Data mining in Sciences of the prophet’s tradition in general and in impeachment and amendment in particular. Int. J. Islam. Appl. Comput. Sci. Technol. 2015, 3, 9–16. [Google Scholar]
- Najeeb, M.M. Multi-agent system for hadith processing. Int. J. Softw. Eng. Appl. 2015, 9, 153–166. [Google Scholar] [CrossRef]
- Kenton, J.D.M.W.C.; Toutanova, L.K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minnesota, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Antoun, W.; Baly, F.; Hajj, H. AraBERT: Transformer-based Model for Arabic Language Understanding. In Proceedings of the LREC 2020 Workshop Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; p. 9. [Google Scholar]
- Abdelali, A.; Darwish, K.; Durrani, N.; Mubarak, H. Farasa: A fast and furious segmenter for arabic. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations, San Diego, CA, USA, 12–16 June 2016; pp. 11–16. [Google Scholar]
- Antoun, W.; Baly, F.; Hajj, H. AraELECTRA: Pre-Training Text Discriminators for Arabic Language Understanding. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 19 April 2021; pp. 191–195. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 1909, arXiv:1909.11942. [Google Scholar]
- مجموعات العمل: المهمات والمناهج والضوابط العملية. 2014.
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- You, K.; Long, M.; Wang, J.; Jordan, M.I. How does learning rate decay help modern neural networks? arXiv 2019, arXiv:1908.01878. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Narrator | # Observations | # Connections |
|---|---|---|
| Sulayman bin Ahmad | 12,968 | 1053 |
| Omar bin Alkhattab | 9231 | 899 |
| Abu Muhammad Masud bin zayd | 2 | 2 |
| Daylam bin Abi Daylam | 1 | 1 |
| Appearance Forms | # Narrators |
|---|---|
| Muhammad | 167 |
| Abdullah | 128 |
| Ahmad | 97 |
| Abdurrahman | 95 |
| Ibrahim | 94 |
| Model | Accuracy |
|---|---|
| FastText600 + KNN | 54.1 |
| FastText600 + NB | 65.5 |
| FastText300 + KNN | 81.2 |
| FastText300 + NB | 67 |
| Model | Accuracy |
|---|---|
| AraBERT + KNN | 85.5 |
| AraBERT + NB | 69.7 |
| AraBERT + narrEmb + 1-NN | 65.6 |
| FrozenAraBERT + 1-layer NN | 90.5 |
| FrozenAraBERT + 2-layer NN | 90.4 |
| TunedAraBERT + 1-layer NN | 93.1 |
| Model | Accuracy |
|---|---|
| AraElectra [36] | 92.1 |
| AlBERT-Arabic [37] | 92.5 |
| AraBERT [34] | 93.1 |
| Dataset | Large | Real | ||||
|---|---|---|---|---|---|---|
| Model | MicroF1 | MacroF1 | SER | MicroF1 | MacroF1 | SER |
| Frozen | 90.1 | 88.4 | 39.9 | 77.5 | 68 | 73.4 |
| Tuned | 92.9 | 92.5 | 30.2 | 83.5 | 78.8 | 60.6 |
| k | Val | Test |
|---|---|---|
| 1 | 92.9% | 83.5% |
| 3 | 97.4% | 95.3% |
| 5 | 98.4% | 97.1% |
| # Wrong Predictions | Val | Test |
|---|---|---|
| 0 narrators | 69.8% | 39.4% |
| 1 narrator | 25.1% | 36.8% |
| 2 narrators | 4.6% | 17.6% |
| 3 narrators | 0.5% | 5.2% |
| >3 narrators | 0.1% | 1% |
| Length | MicroF1 | MacroF1 | SER |
|---|---|---|---|
| 3 | 91.2 | 88.5 | 23.5 |
| 4 | 92.6 | 90.8 | 25.6 |
| 5 | 92.7 | 91.8 | 30.8 |
| 6 | 93.5 | 92.1 | 32.3 |
| 7 | 93.6 | 91.8 | 36.4 |
| Book | # Sanads |
|---|---|
| Sahih Al-Bukhari | 5674 |
| Sahih Muslim | 5189 |
| Sunan Abi Dawud | 4084 |
| Al-Termizi | 3588 |
| Sunan Al-Nasai | 4903 |
| Sunan bin Majah | 3756 |
| Book | MicroF1 | MacroF1 | SER | Top-1 | Top-3 | Top-7 |
|---|---|---|---|---|---|---|
| Sahih Al-Bukhari | 78.5 | 59.5 | 68.9 | 78.5 | 93.3 | 95.7 |
| Sahih Muslim | 84.3 | 71.9 | 60.2 | 84.3 | 96.6 | 98.1 |
| Sunan Abi Dawud | 84.9 | 79.1 | 57.6 | 84.9 | 95.3 | 97.1 |
| Al-Termizi | 88.3 | 80.7 | 48.7 | 88.3 | 97.4 | 98.5 |
| Sunan Al-Nasai | 80.2 | 72 | 70.5 | 80.2 | 93.2 | 95.7 |
| Sunan bin Majah | 87.9 | 82.8 | 50.5 | 87.9 | 97.2 | 98.4 |
| Using Farasa | Micro F1 | Macro F1 | SER |
|---|---|---|---|
| Yes | 83.5 | 78.8 | 60.6 |
| No | 81 | 74 | 66.8 |
| Model-Dataset | Batch Size | lr |
|---|---|---|
| Frozen-lite | 32 | |
| Tuned-lite | 32 | |
| Frozen-large | 128 | |
| Tuned-large | 32 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahmoud, S.; Saif, O.; Nabil, E.; Abdeen, M.; ElNainay, M.; Torki, M. AR-Sanad 280K: A Novel 280K Artificial Sanads Dataset for Hadith Narrator Disambiguation. Information 2022, 13, 55. https://doi.org/10.3390/info13020055
Mahmoud S, Saif O, Nabil E, Abdeen M, ElNainay M, Torki M. AR-Sanad 280K: A Novel 280K Artificial Sanads Dataset for Hadith Narrator Disambiguation. Information. 2022; 13(2):55. https://doi.org/10.3390/info13020055
Chicago/Turabian StyleMahmoud, Somaia, Omar Saif, Emad Nabil, Mohammad Abdeen, Mustafa ElNainay, and Marwan Torki. 2022. "AR-Sanad 280K: A Novel 280K Artificial Sanads Dataset for Hadith Narrator Disambiguation" Information 13, no. 2: 55. https://doi.org/10.3390/info13020055
APA StyleMahmoud, S., Saif, O., Nabil, E., Abdeen, M., ElNainay, M., & Torki, M. (2022). AR-Sanad 280K: A Novel 280K Artificial Sanads Dataset for Hadith Narrator Disambiguation. Information, 13(2), 55. https://doi.org/10.3390/info13020055