1. Introduction
Recommender Systems (RSs) function as a specialist for people who cannot decide on the conceivably overwhelming number of choices accessible on the World Wide Web. Neighborhood-based calculations are conventional methodologies for synergistic proposals and are mainstream because of their straightforwardness and proficiency.
Nowadays, people of different age groups prefer online purchasing. The instant availability of various alternatives, feedback of common people on items, and easy accessibility from home, is the major reason for such popularity. As a result, the inconsistencies during offline purchasing have been resolved substantially. However, host sites often face “information overload” problems to keep up the enriched services. Neighborhood-based recommender frameworks utilize various sorts of likeness measures between clients or things to accomplish assorted objectives for planning an RS, for example, exactness, curiosity, and variety.
Despite that, the current likeness measures can’t oversee the information sparsity issues well, which brings about either not many co-appraised things or positively no co-evaluated things. Moreover, there are additional circumstances where just the relationship among clients and things, such as purchasing practices, exist in the type of unary evaluations, a unique instance of appraisals. Neighborhood-based recommendations are essential, as it is very likely to have the same interests as any user on the same platform. However, the current definition of similar users is purely based on the ratings of the items neglecting other essential factors in it. A new model is proposed to recommend new items based on similar user selection, which uses the Simple Matching Coefficient (SMC) technique and Jaccard Index as similarity measures [
1]. To further enhance this approach, Collaborative Filtering for Java (CF4J) and Jaccard Index was used. CF4J is used to accommodate similarities between two users using different frameworks together [
2]. These days, the recommendation system assumes a pivotal function in the online business stage. The recommender framework has its function in conveying more exact and solid information to specific clients. The recommender framework accumulates the client’s pertinent information and feeling or the set of the gathering [
3,
4].
Big Data has been utilized in different businesses around the globe and the movement business has been one of them. The movement business is the one that intensely relies on the information it gathers and now has gotten more proficient withBig Data utilization. It has changed the movement business and is presently a vital part of their everyday activities. Big Data is taking the movement business the correct way. It deals with all that a voyager anticipates from the voyaging organization he is managing. From customized offers to giving recommendations about the spots you should visit; it is the ideal partner that an explorer needs. Tourism industries deploy Big Data to enhance their customer service model more realistically. Based on the tourists’ profile data, the travel industries decide to serve and recommend the clients better based on clients’ preferences. Travel industries also adapt Artificial Intelligent-based RSs to serve the clients in a better way. Generally, RSs are considered as a major area related to information retrieval. Since the last decade, there has been tremendous demand for RSs among common people around the world. It has been widely used in various fields related to human life, e.g., E-Commerce, Entertainment, Social Networking, Education, Tourism, etc. Recommenders are proven to be advantageous to buyers as well as sellers. From the sellers’ perspective, online selling has minimized business costs, that is, transportation, inventory, and maintenance substantially. The buyers have benefited in terms of the reliability of services and high-quality recommendations. Recommender Systems (RSs) are fundamental instruments of a web-based business in creating keen choices for a person to get item proposals. Neighborhood-based methodologies are conventional strategies for community suggestions and are well known because of their effortlessness and proficiency.
RSs can be looked at as the sub-branch of the whole dynamic filtering algorithms working in the market today. The movie recommendation systems’ maximum is based on K-Means and K-NN Means algorithms as studied and observed. However, with the increasing amount of movie content and users on a specific platform, this combination isn’t considered efficient. Katarya et al. [
5,
6] have used FCM (fuzzy C-means), a soft clustering technique, to increase its efficiency. Recommendation Systems are used for filtering the required information from a large bucket of information for every individual. However, while filtering the information, it is also very important that the retrieved information is relevant and useful for end-use. Gray wolf optimization and fuzzy c-means techniques are used on MovieLens data clusters to achieve high precision and accuracy. Some of the popular RSs are Movie recommendation on
Netflix, Music recommendation on
Pandora, Product recommendation on
Amazon, Tourism recommendation on
Trip-advisor, the Jokes recommendation in
Jester, and Social recommendation on
Facebook.
Primarily, RSs utilize intelligent algorithms, that is, Collaborative Filtering, Content-based Filtering, Demographic Filtering, Social-based Filtering, Knowledge-based Filtering, and Hybrid Filtering. Nowadays, all these algorithms are deployed in some commercial recommenders used by consumers in everyday life. Collaborative filtering considers user ratings to perform filtering and as such, the recommendations are based on users’ ratings who have a similar preference level as that of the target user. On the other hand, Content-based Filtering is made with the item information (features) and user’s preference (ratings) to those items. The recommended items are similar to the ones the user has already purchased. Demographic filtering is quite similar to collaborative filtering.
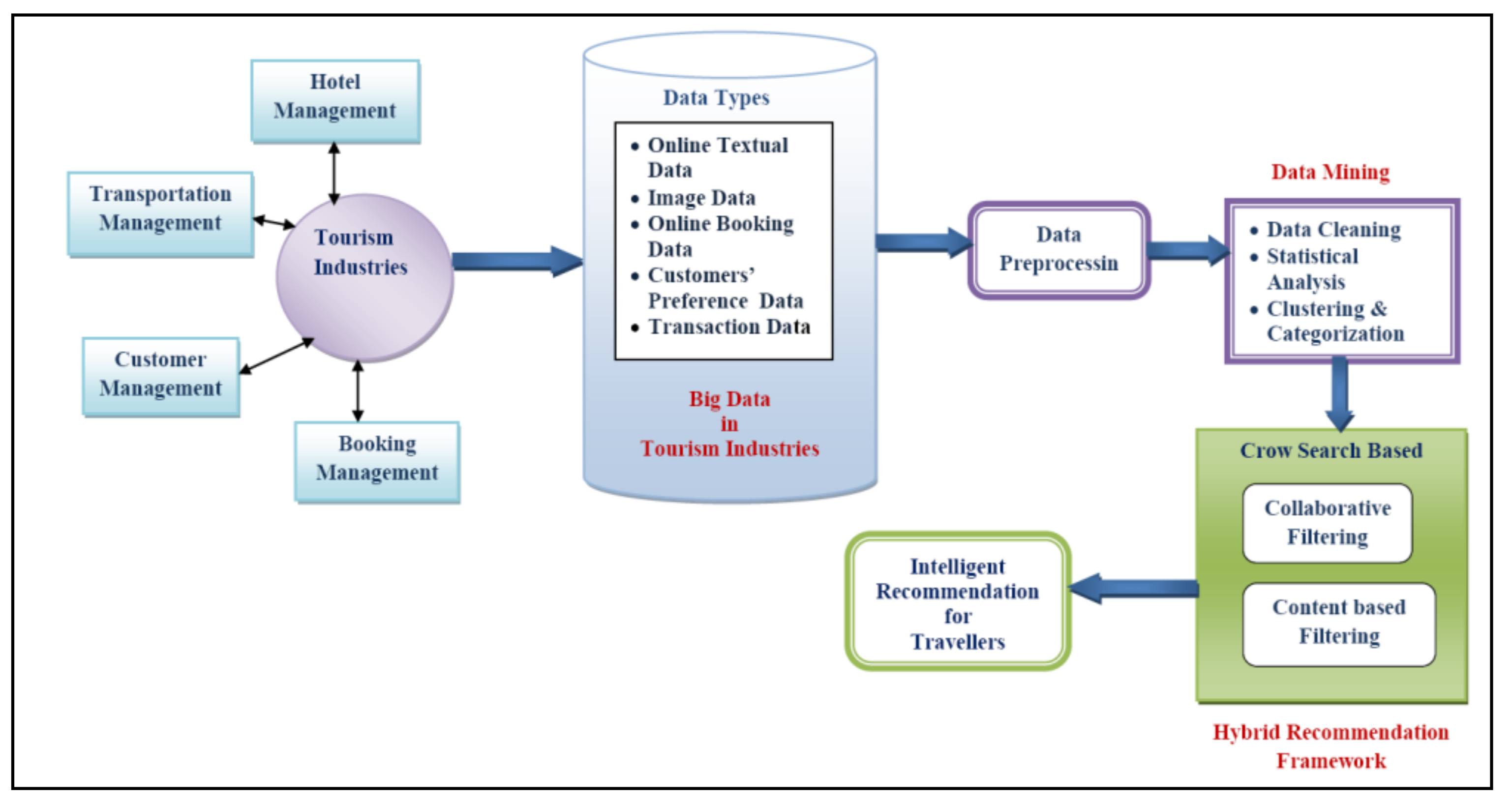
All the recommendation techniques can be deployed based on the previous data. Today, all tourism industries deploy recommendation techniques based on the concept of the Big Data model. In this paper, the concept of Big Data in the domain of tourism industries is considered. The tourism data set is analyzed first, and a structured form is made for further prediction. Crow search-based, hybrid recommendation techniques are applied to implement the proposed model. The proposed model combines collaborative and content-based filtering techniques to achieve more effective recommendations for clients in a real scenario. Finally, a comparison is performed with two different existing related works. The performance of the proposed model is also evaluated. The remaining parts of the article are organized as follows. Related Works are described in
Section 2.
Section 3 illustrates the relation of Big Data with Tourism Industries.
Section 4 explores the proposed model and algorithm followed by data preparation in
Section 5.
Section 6 explores results and simulations. Furthermore, a complete discussion is given in
Section 7. Finally,
Section 8 depicts the conclusions of the research.
2. Related Works
Recommendation Systems (RSs) area software application that minimizes the information overload problem, filters the required information, and automatically suggests ideal items to the user. Moreover, the recommendations are displayed according to the priority. This is also known as the “Top-N” recommendation. In other words, RS deals with the prediction of users’ preferences. Isinkaye et al. [
7], in their research, described the basic concepts of the recommendation system. As their paper indicates, the Internet is known as the greatest source of information for all users. However, with the regular increase in the amount of information, the number of options is also increasing. Thus, to handle this much volume it becomes necessary to filter out the required information for every user. Katarya et al. [
8] described the recommendation systems work based on rating predictions on several items. It becomes equally important to focus on sequential information. To test this novel approach, an MNSBC data set was used, which contained 5000 entries per user. On the same line, to enhance the existing systems, another research was implemented on movie recommendations using K-Means and the Cukoo Search Optimization algorithm by Katarya et al. [
9]. The final result was compared with the existing approaches and was found to be more precise. However, to enhance its quality, bio-inspired algae algorithms have also been used. To find the similarities between any two users’ multilevel, the Pearson Correlation Coefficient (PCC) was used [
10]. Meanwhile, most music recommendation systems focus more on contextual information, such asmusic ratings and user–user interaction dynamics. A new recommendation system was proposed based on Depth First Search (DFS) and Bellmon Ford is used to recommend new suggestions based on all the factors mentioned above [
11]. Another proposed movie recommendation model worked on the based similarities of two users on the same online platform. K-Means clustering was applied with bio-inspired artificial bee colony (ABC) techniques, known as the ABC-KM recommendation model [
12]. The current recommendation system suffers from sparsity, coldstart, and scalability issues. Post understanding all these issues, a new model was proposed based on matrix factorization and topical-based collaborative filtering. This model was observed to be more accurate, and due to the hybrid use of techniques, it was termed the HYBRTyco model [
13]. Martı’nez et al. [
14] introduced a matrix factorization-based hybrid recommendation algorithm consisting of collaborative filtering and content-based filtering. Shamri et al. [
15] proposed a hybrid filtering technique using the the Fuzzy-Genetic algorithm. The algorithm provides less Mean Absolute Error and more Coverage. Lee et al. [
16] proposed a neural network-based optimized hybrid recommendation algorithm on the MovieLens dataset to improvise Mean Absolute Error and Scalability. Campos et al. [
17] introduced a hybrid recommendation algorithm with the help of the Bayesian Network using MovieLens and IMDB datasets, providing few Mean Absolute Error. Shinde et al. [
18] proposed a hybrid recommendation framework, applying the Centering–Bunching-based Clustering algorithm using the Jester dataset, resulting in less Mean Absolute Error and higher Precision, Recall, and F-Measure. Jung et al. [
19] performed user behavior analysis to accomplish a hybrid recommendation. The framework was successfully validated with the EachMovie dataset’s help, providing top-n recommendations and less Mean Absolute Error. Christakou et al. [
20] introduced a neural network-based two-way hybrid filtering technique. The proposed algorithm was validated using the MovieLens dataset, resulting in higher Precision and Recall. Geetha et al. [
21] developed a K-Means clustering-based hybrid filtering technique. The experimental results show an accurate and personalized recommendation. Yang et al. [
22] proposed a job recommendation system based on hybrid filtering. The system is validated using User-Skill, User-City, Most Recent Company, and Most Recent Job Title features. Iaquinta et al. [
23] proposed a word net-based hybrid recommendation technique to optimize the electronic support system’s performance by using Each Movie dataset. The results reveal the proposed algorithm results in low Mean Absolute Error compared to the popular Pearson coefficient. Recent research by Ashami et al. [
24] introduced a clustering-based approach to finding the best neighbor of the target user. The clustering is accomplished using the hybridization of the Crow Search and Uniform Crossover Algorithm and the Jester dataset is used as a test-bed for providing significantly less Mean Absolute Error. Recently, Tesfaye et al. [
25] proposed a hybrid algorithm to accomplish intelligent Collaborative Filtering. The hybridization is achieved using the Crow Search Algorithm and K-Means Clustering. The MovieLens dataset is used as a test-bed and the results are promising (small Mean Absolute Error) compared to similar techniques. A new proposed model was read that used Newton’s third law of gravitation and was applied to the data set taken from the user-item matrix [
26].
4. Proposed Model
Today, big data is useful in the domain of tourism industries to better serve the clients in a more realistic way. In this research paper, an Intelligent Tourist Recommender System (ITRS) is proposed to guide tourists based on their preferences. The tourism industries can deploy the model to recommend the tourists regarding their entire plans. This proposed ITRS is beneficial for both tourists as well as tourism industries. To implement the ITRS model, a Big Data tourism database is used. The tourism dataset supports the ‘3V’ properties of Big Data [
27,
28], i.e., volume, variety, and veracity. A tourism dataset is statistically analyzed [
29,
30] and a balanced, structured matrix is formed to perform the prediction and recommendation. Sequential analysis is performed as a pilot survey to generate sub-matrices where all the sub-matrices are orthogonal.
4.1. Statistical Analysis
To validate the proposed model, data analysis is required. Real-time data is used as a test-bed for this model. The data is analyzed by statistical approach. Using the tourism data set as a test-bed, it is analyzed based on the user’s choice. The dataset is extremely large, with unstructured data patterns and integrity issues to deal with.
Assuming that all the records of the dataset have n number of features with their different parameters’ value as , the dataset is continuous then determines the density function for selecting the data sample randomly. A small sample of data, , belongs around the data points . In the dataset, the values of users’ choices are categorized and near each other.
To get the whole dataset to equilibrium, the users with a high frequency of traveling are distributed with possible equidistribution over the whole dataset with kinematic restriction. The users with a high frequency of traveling will influence their co-centric neighbors. The first target is to distinguish the users who travel very frequently through any third-party travel agencies and determine the users with similar choices. The proposed model is validated using the tourism dataset as a test-bed. The tourism dataset is unstructured and contains noisy data. Thus, the first thing is to filter the dataset and structure through an analysis. The data sample of frequent users of position
have
. The mean of frequent users per sample is determined as
where,
dv indicates the unit volume of the sample dataset and
d denotes the entire dataset.
is determined and evaluates the degree of similarities for each sample distribution using a uniform distribution. Since the pattern of a dataset of tourism industries is Big Data, a high degree of similarities is required to find more similar users. To determine the entropy of the sample, Equation (2) is used.
Then, the solution of Equation (2) is maximized using Equation (1).
The optimum selection of data sample
U, for which
is maximized and subjected to
, is determined using Equation (3).
where
is selected such that
.
Using the inequality
the sample data,
, are selected randomly from the whole dataset for every iteration. For any two alternative densities, the inequality in Equation (4) will be defined as
where
U denotes the data samples.
The variable U will have unity if incident of Equation (5) is applied for Equation (1).
The data samples of frequent users are considered for the tourism industries. The degree of travel frequency is different for the different data samples. The sampling distribution is deployed to transform the degree of travel frequency for different samples, as per linear transformation .
If
B is considered a non-singular matrix, then
As per the relational equation, the relation between the users is defined as Equation (7):
Y = BU which transforms into a quadratic form
The dissimilarity between frequent users and rear users is firmly determined and a threshold value is evaluated by using a partitioning matrix.
The partitioning matrix in Equation (10) is partitioned into
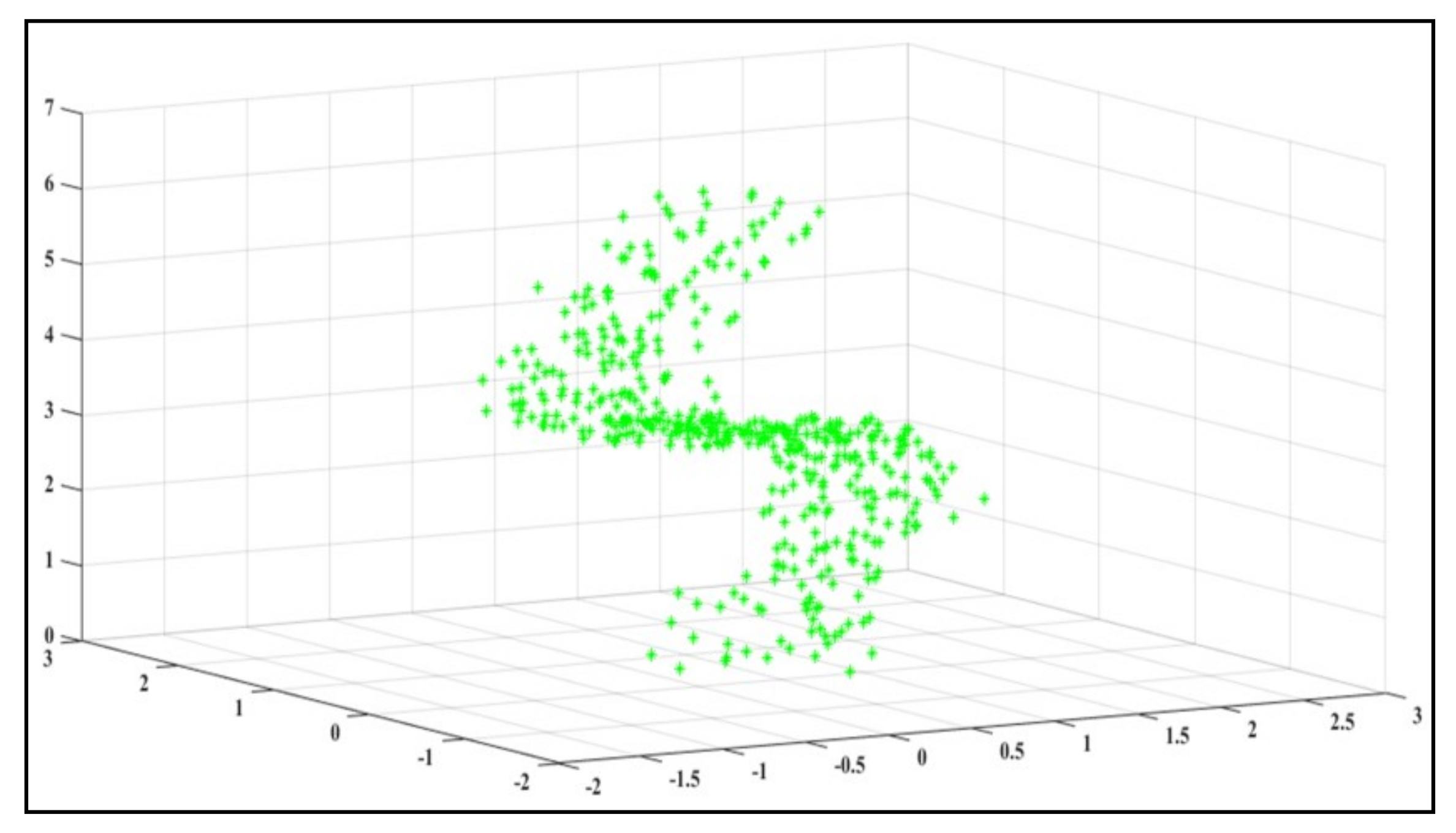
kth sub-matrices where all the sub-matrices are orthogonal to each other but are not orthogonal by themselves. This is a pilot statistical analysis for the data. After statistical analysis, the dataset is visualized in
Figure 2. The visualization of the dataset in
Figure 2 represents the distributions of the data points. Data analysis is performed by using Algorithm 1.
| Algorithm 1: Data analysis for grouping similar data |
| Begin |
| Step 1:, and |
| , which belongs around the n number of features |
| Step 2: |
| Step 3: |
| Step 4: |
| Step 5: |
Step 6: Randomly select the data sample to determine any two alternative densities by applying
|
| Step 7: Sampling distribution is deployed to transform the degree of travel frequency for different samples |
Step 8: The interrelated differential elements are defined as
|
Step 9: Determine dissimilarity between frequent users and rear users as
,
|
| End |
6. Results and Simulations
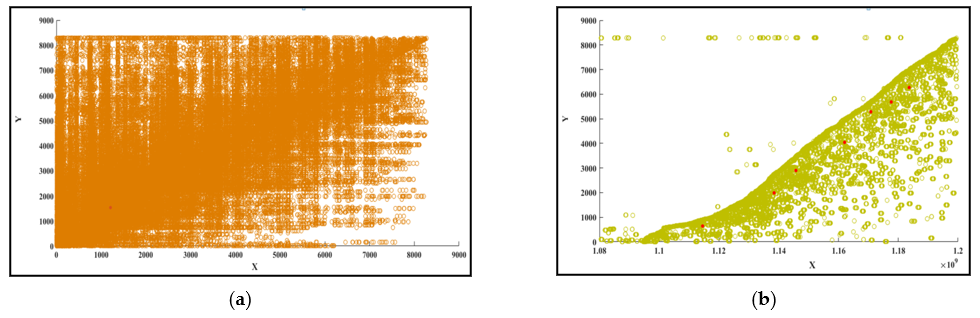
The tourism dataset is used as a test-bed to validate the proposed model. The data set is very large and has an imbalanced structure. As such, statistical analysis is performed to fit the dataset of the proposed model, and the simulation results are shown in
Figure 2.
The original data set, before the statistical analysis shown in
Figure 2a, has data patterns that are unstructured and have some missing data fields. After the statistical analysis, the dataset is filtered and freed from noise data. As per the requirement, the data is filtered by the analysis. The filtered and structured dataset is shown in
Figure 2b. The required data values are all in a single group other than noise data. In
Figure 2b, the required data points are shown in the high-density section. After data analysis, a collaborative filtering technique is applied to find out the users’ similarities based on their preferences.
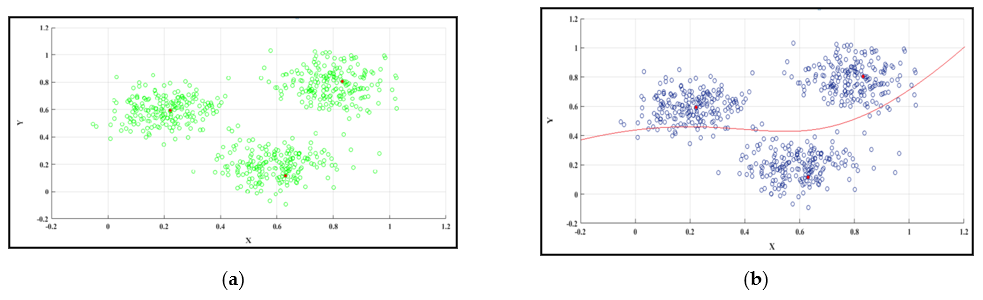
Figure 3 shows the grouping of the users as per their preferences. In this research, the applied data set is divided into three different subgroups by the collaborative filtering technique. Every user has a similarity index concerning other remaining users in a group.
Figure 3a shows three different groups derived from the applied structured test-bed data set. A threshold value is derived from selecting the group whose similarity index is very near to the threshold value. The threshold value is shown in
Figure 3b. Every group has its similarity index value, which is the mean of the group members’ all similarity index.
Based on the similarity index, the item will be recommended to the neighbors of the same group.
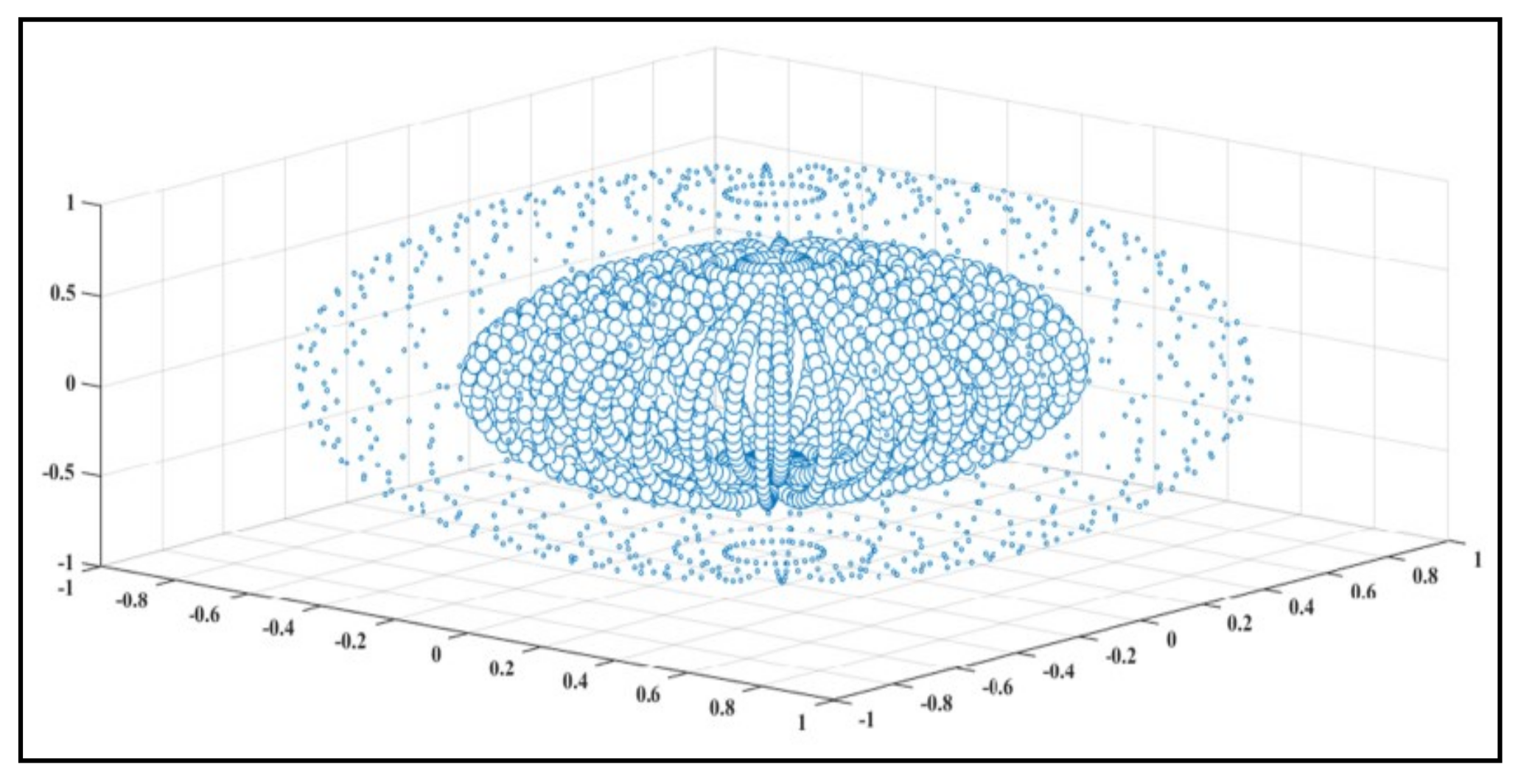
Figure 4 shows that the similarity index value is gradually decreased outward from the center value. The users who belong near the center have similar preferences. After each iteration, the error is determined. The Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE) are determined from the dataset after deploying the proposed methodology.
Table 2 and
Table 3 show the MAE and RMSE respectively, based on the rating of the users.
Table 3 depicts MAE’s related to the proposed model. To begin with, 500, 1000, 2000, 3000, 4000, and 5000 user ratings are considered for validation purposes. Consecutively, the target user’s rating on unseen items is predicted. The experimental result demonstrates that the proposed model provides small MAE on large data samples. Moreover, after a few iterations, MAE becomes unchanged.
Table 4 exhibits the RMSE’s obtained from the proposed model. At first, 500, 1000, 2000, 3000, 4000, and 5000 user ratings were considered for experimentation. Successively, target user preference is predicted on unrated items. The experimental results reveal that the proposed model provides less RMSE for the large data samples. On the other hand, RMSE rapidly decreased as the number of user ratings increased. Therefore, the proposed model is practically deployable whenever numerous ratings are involved. After the minimization of errors, a similarity index of all users in a group is evaluated and shown in
Figure 4.
The simulation in
Figure 4 describes the distribution of the similarity index for a particular group. Based on this similarity index, a new item will be recommended in the future for users in the same group. But, in a real scenario, collaborative filtering is not always sufficient for recommendations to users. The proposed model is designed based on hybrid recommendation systems. Collaborative filtering is visualized in
Figure 4. To achieve a higher level of accuracy, content-based filtering is also applied. After deploying content-based filtering, an effective result is achieved for a recommendation.
Figure 5 describes the effective result of a recommendation. A new item will not be recommended for all the same groups of users with the same similarity index. The new item is only recommended for the users who have the same similarity index and have prior similar content choices. After determining the effective optimized recommendation, performance metrics of the model are measured with various sampling data. The result of the performance metrics [
46] is shown in
Figure 5.
Table 5 demonstrates a comparison of precision between the proposed model, HCSUC, Tesfaye et al., collaborative filtering, content-based filtering, collaborative-content hybrid filtering, and particle swarm optimization (PSO)-based collaborative-content hybrid filtering considering different top
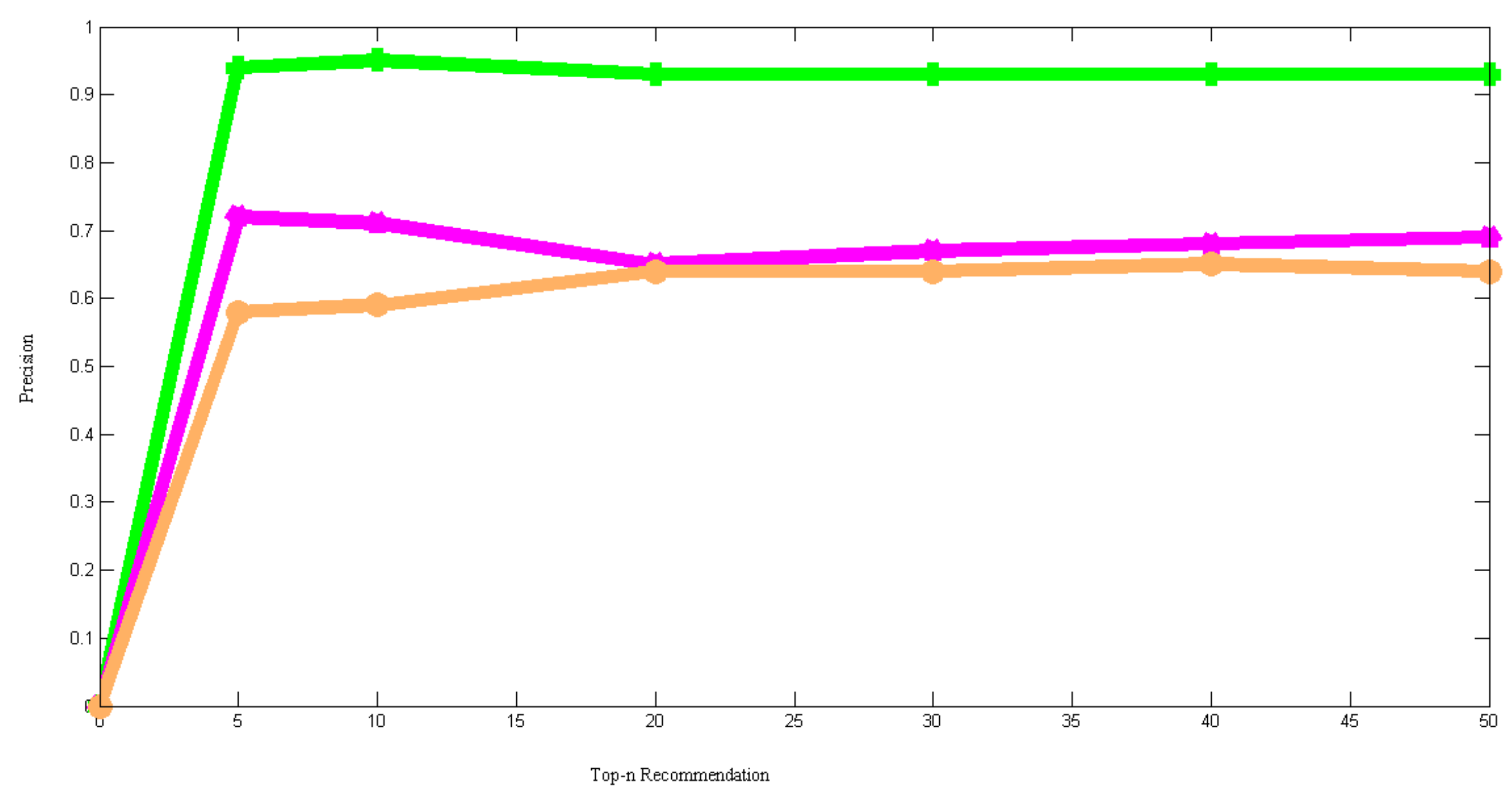
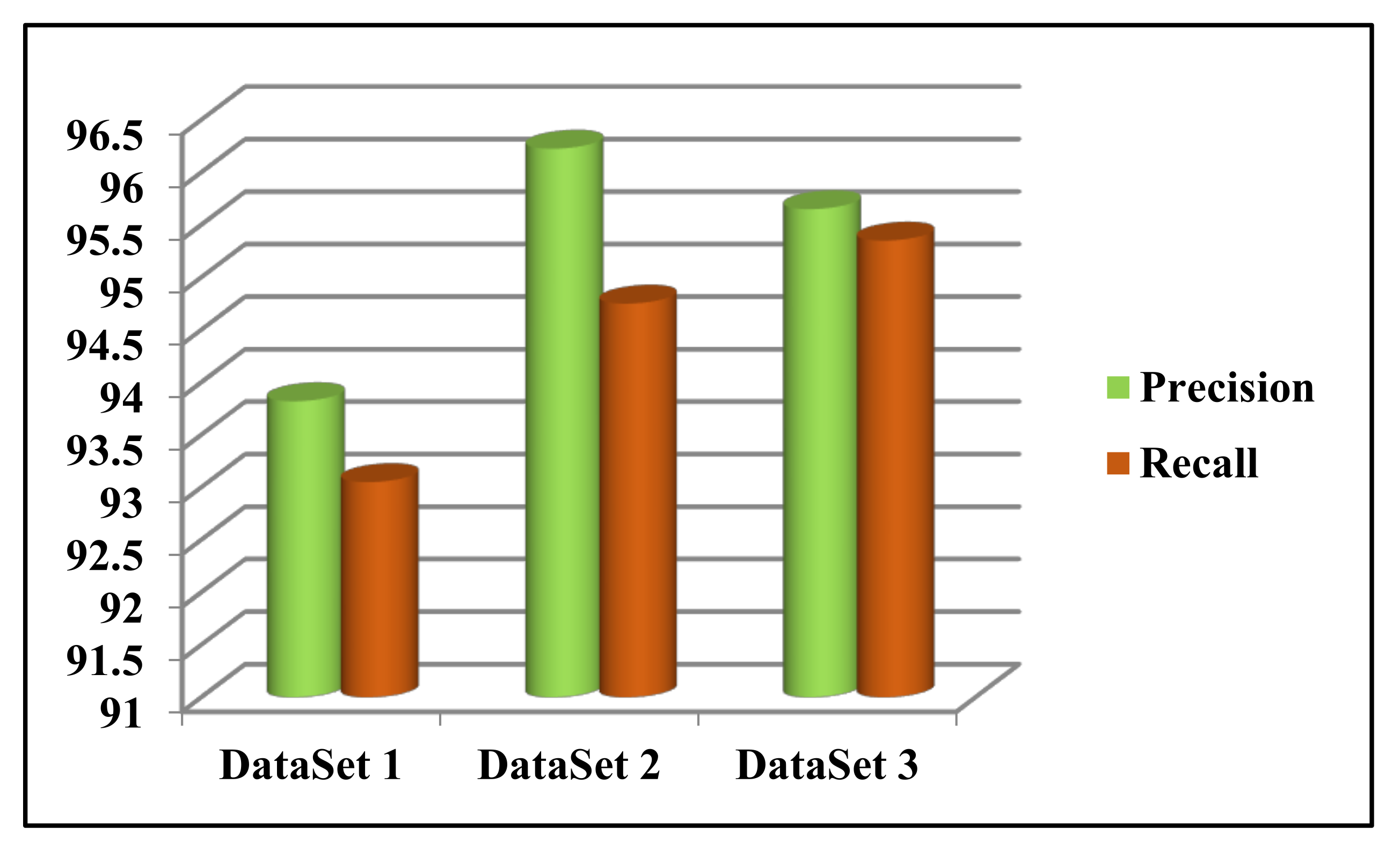
n recommendation sets. The effectiveness of the models is devised with the help of true positive and false positive recommendations. The experimental results reveal that the proposed model provides an average precision of 93.5%. Meanwhile, HCSUC results have an average precision of 68.6%. On the other hand, the recommendation model of Tesfaye et al., collaborative filtering, content-based filtering, collaborative-content hybrid, and PSO-based hybrid filtering provides an average precision of 62.3%, 62.5%, 62%, 63.5%, and 69%, respectively. Therefore, the experimental results reveal that the proposed model is better than other models in terms of precision.
Figure 6 shows a comparison between the proposed model, HCSUC, and Tesfaye et al. considering the precision values. The X-axis and Y-axis in the graph represent the size of the topn set and precision. The proposed model, HCSUC, and Tesfaye et al. are indicated by the greenline, violet line, and brown line in the graph. The figure describes that the proposed model outperforms the existing algorithms.
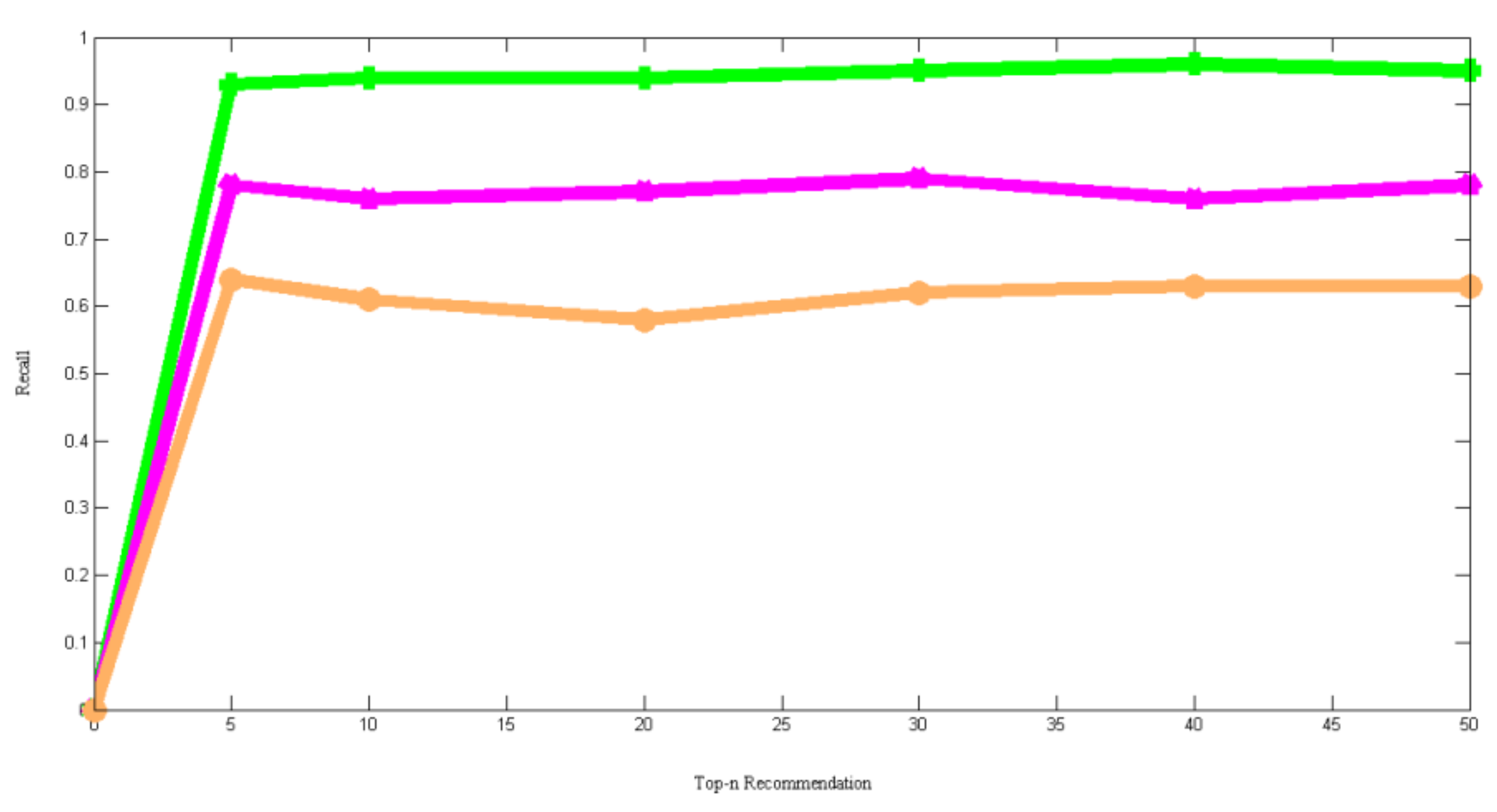
Table 6 shows a comparison of recall values between the proposed model and popular recommendation models. The size of recommendation sets is varied up to 50 recommendations in order to make a correct decision. Subsequently, the true positive, and false negative recommendations in those models have been identified. The experimental results presented in the table shows that the proposed model provides an average recall of 94.5%. On the other hand, recent recommendation models, such as HCSUC and Tesfaye et al. provides an average recall of 77.3% and 62.3%. Traditional recommendation models, such as collaborative filtering, content-based filtering, collaborative-content hybrid, and PSO-based hybrid filtering provides an average recall of 62.3%, 63.8%, 65.6%, and 63.6%. Therefore, it is evident from the experimental results that the proposed model is very accurate in providing personalized recommendation.
Figure 7 shows a comparison between the proposed model, HCSUC, and Tesfaye et al., considering the recall. The X-axis and Y-axis in the graph represent the size of the top-n set and recall. On the other hand, the proposed model, HCSUC, and Tesfaye et al. are indicated by the green line, violet line, and brown line in the graph. The figure shows that the proposed model is better than existing algorithms.
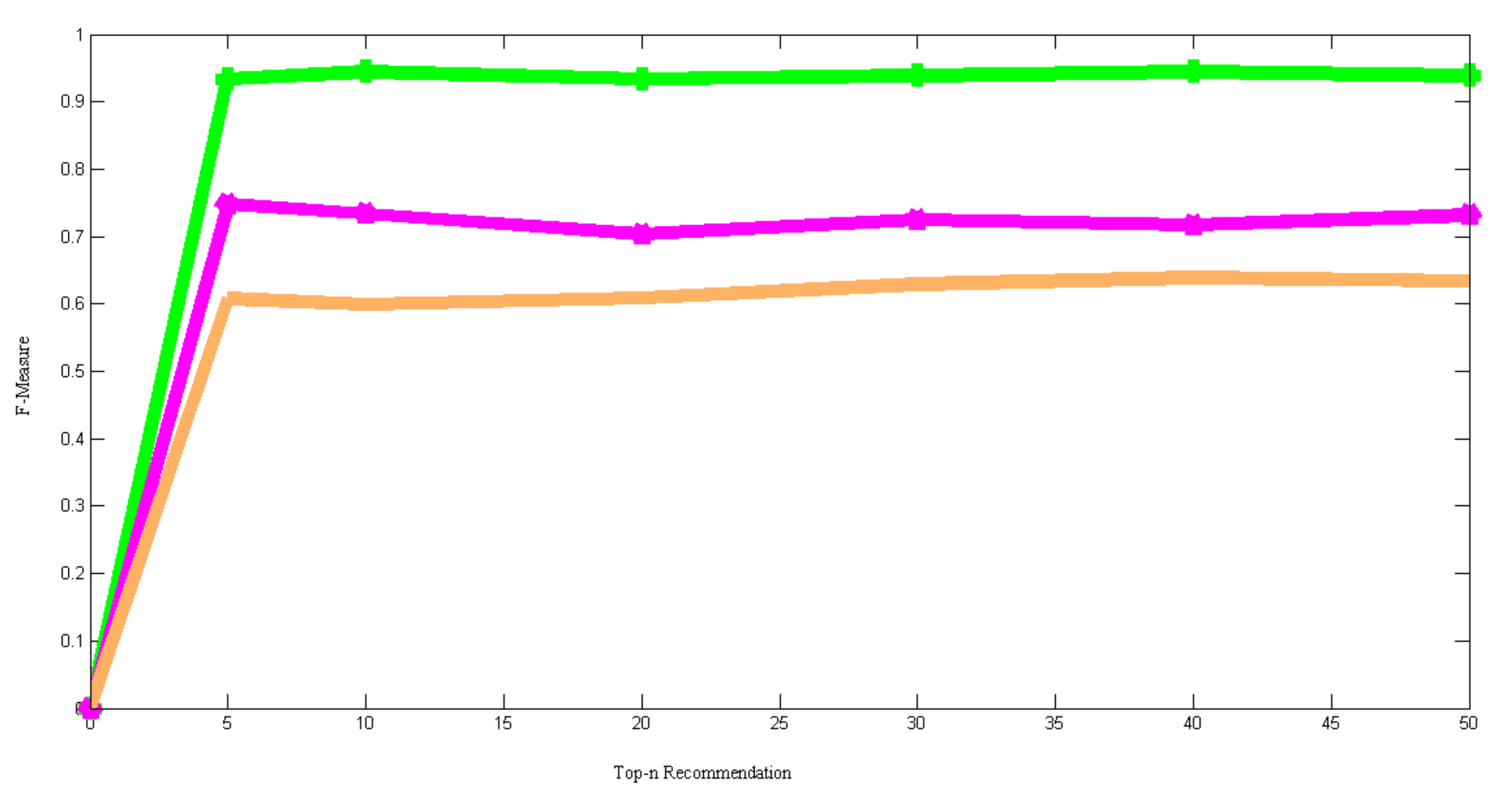
Table 7 demonstrates a comparison of F-Measure values between the proposed model and other similar models. The precision and recall of the models are considered for the computation of F-Measure. The results reveal that the proposed model provides an average F-Measure of 93.3%. Meanwhile, the F-Measure of the recently proposed identical models, such as HCSUC and Tesfaye et al., drastically decreases in each iteration of testing. On the other hand, traditional recommendation models like collaborative filtering, content-based filtering, collaborative-content hybrid, and PSO-based hybrid filtering results average F-Measure of up to 68.1%. Therefore, it is clear from the experimental results that the proposed model performs well while providing personalized recommendations according to their user profile.
Figure 8 demonstrates a comparison of F-measure between the proposed model, HCSUC, and Tesfaye et al. The X-axis and Y-axis in the graph represent the size of the topn set and F-measure. On the other hand, the proposed model, HCSUC, and Tesfaye et al. are indicated by the green line, violet line, and brown color line, respectively. The figure represents that the proposed model performs better than the existing algorithms
Table 8 shows a comparison of precision between the proposed model and other related models. The experimental results demonstrate the proposed model provides a precision of 93.5%. Meanwhile, recent research works on HCSUC and Tesfaye et al. achieve a precision of 60.3% and 57.8%. On the other hand, popular recommendation models, such as collaborative filtering, content-based filtering, collaborative-content hybrid, and PSO-based hybrid filtering, provide precision levels of 60.8%, 61.3%, 66%, and 71% respectively. Therefore, results show that the proposed model is more accurate in identifying true positive and false positive recommendations compared to the other models.
Table 9 represents a comparison of recall between the proposed model, recent recommendation models, and traditional recommendation models. The experimental results reveal the proposed model provides a recall of 96.6%. Meanwhile, HCSUC and Tesfaye et al., provide an average recall of 60% and 71% respectively. On the other hand, collaborative filtering, content-based filtering, collaborative-content hybrid, and PSO-based hybrid filtering provides an average recall of 61.6%, 67.6%, 74.1%, and 76.6%, respectively. Therefore, it is evident from the results that the proposed model is more correct in identifying true positive and false negative recommendations.
Table 10 represents a comparison of F-Measure values between the proposed model, and different recommendation models considering the testing sets. The experimental results reveal that the proposed model provides an F-Measure of 94.3%. Meanwhile, recommendation models, namely HCSUC and Tesfaye et al., provide an average F-Measure of 59.5% and 61.1%, respectively. Traditional recommendation models, such as collaborative filtering, content-based filtering, collaborative-content hybrid, and PSO-based hybrid filtering provide F-Measures of 60%, 63.6%, 69.3%, and 73.1%, respectively. Therefore, the experimental results demonstrate that the proposed model provides better recommendations compared to other models.
Table 11 compares the precision of the proposed models, HCSUC and Tesfaye et al., collaborative filtering, content-based filtering, collaborative-content hybrid filtering, and particle swarm optimization (PSO)-based collaborative-content hybrid filtering when the recommendation set has various sizes. The experiment is carried out with a recommendation set size of 5, 10, 20, 30, 40, and 50, respectively. The testing sets are used to verify seven recommendation models at first. Following that, suggestions for genuine positives and false positives are calculated. Finally, the models’ accuracy is determined by counting the number of true positive and false positive suggestions. The suggested model has an average accuracy of 96.3%, according to the experimental findings. HCSUC, on the other hand, achieves an average accuracy of 76.1%. The Tesfaye et al. recommendation model, collaborative filtering, content-based filtering, collaborative-content hybrid, and PSO-based hybrid filtering, on the other hand, has an average precision of 72.3%, 61.1%, 67.3%, 80.3%, and 64.1%. As a consequence of the experimental data, it is obvious that the suggested model outperforms similar models in terms of precision.
Table 12 compares recall values for the proposed models, HCSUC, Tesfaye et al., collaborative filtering, content-based filtering, collaborative-content hybrid filtering, and particle swarm optimization (PSO)-based collaborative-content hybrid filtering with different recommendation set sizes. The experiment is performed with the recommended size set of 5, 10, 20, 30, 40, and 50, correspondingly. To begin, the testing sets are used to validate seven recommendation models. The real positive and false negative suggestions are reviewed in order. Finally, the recall of models is assessed by considering true positive and false negative suggestions. According to the testing results, the suggested model has an average recall of 94.5%. HCSUC, on the other hand, has an average recall of 69.6%. Similarly, on the other hand, the recommendation model of Tesfaye et al., collaborative filtering, content-based filtering, collaborative-content hybrid, and PSO-based hybrid filtering results an average recall of 73.5%, 66.3%, 69.5%, 83.1%, and 71%, respectively. Therefore, it is evident from the experiment that the proposed model outperforms other models in terms of recall.
Table 13 compares F-Measure values for collaborative filtering, content-based filtering, collaborative-content hybrid filtering, and particle swarm optimization (PSO)-based collaborative-content hybrid filtering with respect to different sizes of the recommendation set between the proposed model, HCSUC, and Tesfaye et al., collaborative filtering, content-based filtering, collaborative-content hybrid filtering, and particle swarm optimization (PSO)-based collaborative-content hybrid filter. The experiment is performed with the size of the suggestion set to 5, 10, 20, 30, 40, and 50. To begin, the testing sets are used to verify seven recommendation models. Then the models’ accuracy and recall are determined. Finally, the models’ F-Measure is calculated by combining accuracy and recall. The suggested model has an average F-Measure of 94.5 percent, according to the experimental findings. The average F-Measure for the HCSUC recommendation model is 72.1%. The Tesfaye et al. recommendation model, collaborative filtering, content-based filtering, collaborative-content hybrid, and PSO-based hybrid filtering, on the other hand, achieves an average F-Measure of 72.5%, 63.0%, 67.8%, 81.1%, and 65%, respectively. As a consequence of the experimental findings, it is clear that the suggested model outperforms current methods in terms of F-Measure.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}