1. Introduction
Multimedia data groups together different types of data such as sounds, videos, images and cartographic data. These types of data are characterized by large volumes and/or continuous flows of data. The processing of these types of data is generally carried out in the cloud out of convenience [
1]. However, with the concomitant development of the Internet of Things (IoT), virtual reality, augmented reality, big data, and social networks have led to network congestion and an increase in processing times and the limits of the Central Cloud Computing (CCC) paradigm. Moreover, applications needs and user demands for near real-time reaction time have motivate the development of solutions to address congestion and reduce processing times.
Recent technologies have disrupted CCC to move storage and processing resources close to end-users and use also processing capabilities present in the neighborhood. These ones have been motivated by the saturation of network and the need of response time to data queries in (quasi) real-time. Bringing processing closer to users at geographically distributed data centers (Cloudlets) and Micro Data Centers (MCD) have reduced latency for data transmission and querying. Subsequently, the increase in processing capacities at the level of routers and network equipment (Fog Computing) made it possible to offer new processing capacities closer to users. At the same time, the memory and processor capacities of the sensors have also evolved and it has been possible to offer processing capacities (Edge Computing) as close as possible to the sensors to verify, clean, encrypt, compress the data and lightly preprocess data in order to limit the amount of data that is sent to the cloud [
1]. Processing and storage capacities and latency decrease the closer you get to the end user. The underlying question is where and when to perform the treatment. Different approaches have been developed in the academic and industrial world to try to provide a satisfactory answer to this question.
Osmotic Computing (OC) uses micro virtual machines (MVM) that can be moved between the local level and the cloud depending on available resources. This paradigm is inspired by osmotic pressure to distribute tasks between Edge and Cloud level [
1,
2]. However, for the moment, security aspects in terms of privacy or data confidentiality are lowly or not managed.
Dew Computing (DC) is a concept that aims to store data locally on the end user’s device to enable them to have a local copy of data and allows them to consult them easily. However, this approach requires the implementation of a data synchronization protocol, and in the case of multimedia data generates significant traffic to store the data locally.
Mobile Edge Computing (MEC) is born with the rapid development of the processing and storage capacities of mobile devices (mainly smartphones and tablets) and the need to follow devices in their displacements. It then expanded to also allow access via WiFi and is sometimes called Multi-access Edge Computing. In parallel, the deployment of 5G on a large scale will offer high throughput and ultra-low latency that will allow nomadic users to dispose of processing capacities that follow them on their displacements. However, this approach remains conditional on the effective deployment of 5G, the degree of coverage, as well as the compatibility of devices with 5G. A mixed approach called
Jungle Computing (JC) seeks to federate the resources of all kinds available locally to carry out processing. The main difficulty with this approach is to federate widely heterogeneous resources in terms of processing capabilities, transmission without any guarantee on the availability in the time of these resources and processing of data on time. This way of operating based on opportunism does not ensure the Quality of Service (QoS).
Nevertheless, all these approaches suffer a lack of interoperability between future 5G-MEC new technologies and the wireless sensor networks (WSN) actually in place.
In this article, we propose to address the problem of data processing in situations where the access to the cloud is difficult or impossible. Few examples: An underground sensors network with a WSN that communicates in the ground [
3,
4], in the sewers [
5] or in mountain areas [
6,
7] where sensors implanted on cannot be easily connected to a Cloud Computing service. However, the use of 5G and local processing capabilities can provide an answer to this type of problem. However, to achieve this type of approach, it is necessary to have interoperability between the WSN and the 5G-MEC. In other words, this approach is particularly important for the so-called white areas where 3rd Generation Partnership Project (3GPP) networks are not present or where the Internet network does not exist or with a speed too low to allow data transfer to the cloud.
Our motivation in this work is to propose an interoperable architecture integrating actual and still functional wireless sensor network with the 5G-MEC new paradigms. This have been achieved to take advantage of the low latency and high speed between the MEC and the end users on one hand and to continue to use alternative transmission solutions where 5G will not be available (white areas) or particularly harsh conditions on the other hand.
The rest of this article is organized as follows: In
Section 2, we summarize alternatives to avoid to use Cloud Computing and processes data close to sensors. The
Section 3 explains our architectural proposition. Afterwards, the
Section 4, describe the implementation of the architecture. The
Section 5 presents the experimentation. Finally, in
Section 6, we conclude this article and outline future works.
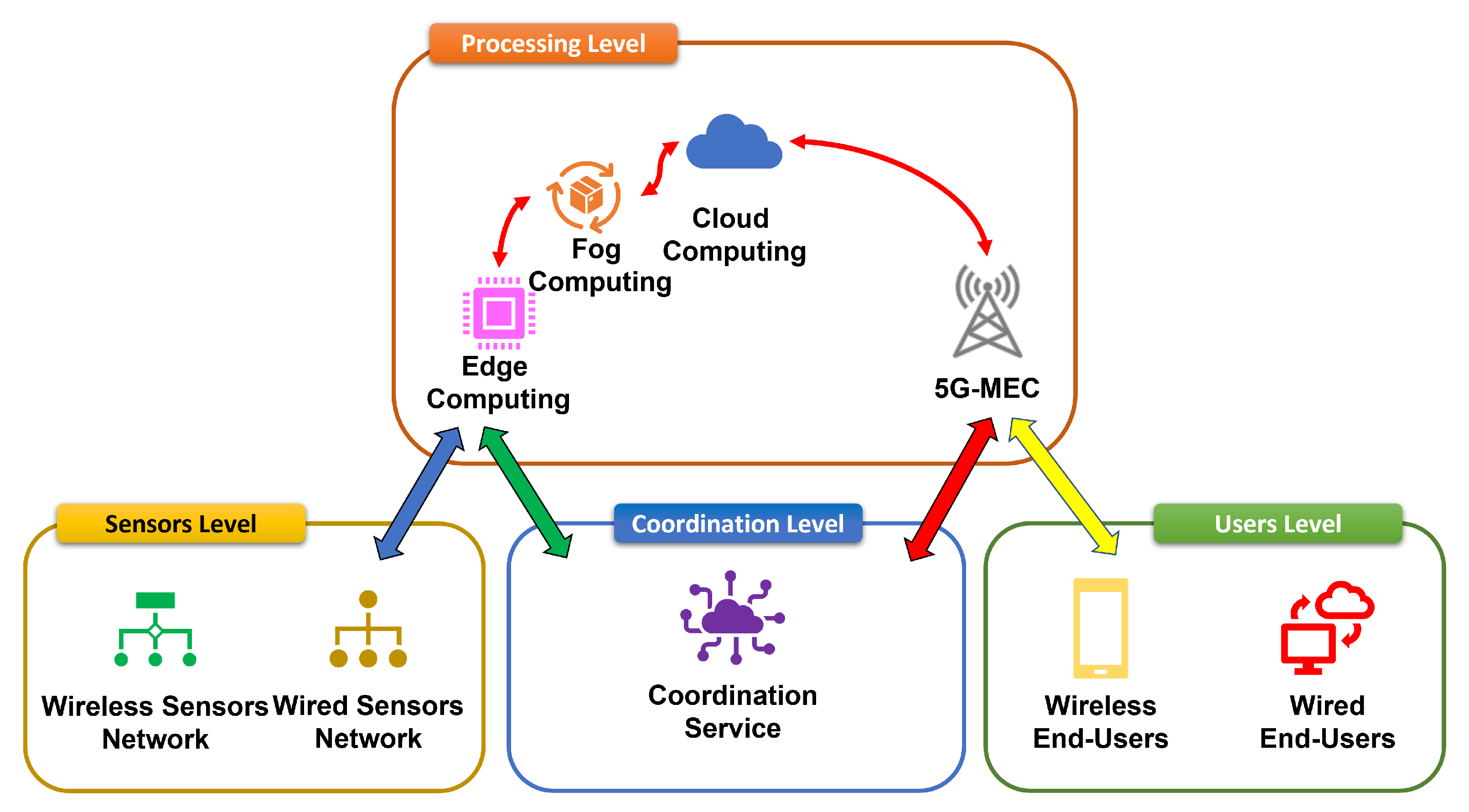
Our contribution is a new paradigm aiming to improve exploitation of local resources at the sensors, networks and end-users devices level for an efficient data processing. The association of 5G-MEC improve the quality of the user experience while the association between Edge-Fog Computing process data close sensors, video cameras, Unmanned Aerial Vehicles (UAVs), robots or vehicles [
1]. Our contribution is a coordination service which interconnects and makes MEC and Fog-Edge Computing interoperable.
2. Related Works
Different ways of local treatment have been developed to achieve the data processing closer to the sensors or users. It was therefore necessary to distinguish between the approaches achieving processing at user level such as the Mist Computing (MC), Social Internet of Things (SIoT) and those implemented on the user side such as the Jungle Computing (JC) or Dew Computing (DC).
The
Mist Computing (MC) is a lightweight and rudimentary form of Edge Computing (EC) [
8]. This paradigm extends elastic computation, storage and networking services from the edge to absolute edge/endpoints. Nowadays, smart end devices have evolved towards more efficient processors, more memory and a better networking stacks that allow them to run analysis and applications autonomously with real-time query and NoSQL like file-system support [
9]. The MC rigs the computing at sensors and actuators level and is only used in case of a communication failure between the cloud and the IoT device to reduce the device power consumption [
10]. When MC is insufficient Fog/Edge Computing will be of assistance [
9]. The advantage of this paradigm is that the sensor data is close to its source and avoid sharing across the network except if required unequivocally. Barik et al. [
11] have proposed a prototype development of SOA-Mist a Mist-based framework to provides an efficient and effective means of sharing geospatial health data resources. The framework integrates: (1) a security integration based on SSL which ensure integrity of service; (2) a database security, which ensures the availability of data for authenticated users.
The
Dew Computing (DC) [
12] allows to further improve response times by pushing from Central Cloud to End Users (EU), computing applications, data and low-level services. Client microcomputers are used to store a part of the data locally in background and to limit access to the cloud, reduce network dependency and drastically reduce processing cost [
12]. DC is the additional piece of Cloud Computing. It is mainly based on on-premises computers composed of a wide range of heterogeneous devices and various equipment from smartphone to intelligent sensors; for instance, micro-services [
13]. DC is highly and effectively capable in terms of scalability and ability to perform sophisticated operations and to process numerous applications and tools. Additionally, the equipment of DC is ad hoc programmable and self-adaptive [
12]. They have the qualifications to running process within another process in a distributed way without a focal communication network [
12]. Applications running in the on-premises computers provide services to users and/or devices independently of cloud, but collaborating with cloud services [
13]. DC can provide access web fraction without an Internet connection (WiD), storage in dew has a cloud copy (STiD), local database has a cloud backup (DBiD), software ownership and settings have a cloud copy (SiD), Software Development Kit (SDK) and projects have a cloud copy (PiD), on-premises computer settings and data have a cloud copy (IaD), and other services (DiD) [
13].
The
Jungle Computing (JC) enables available computing elements present in the vicinity of users to achieve data treatment while DC synchronizes locally user data to improve the user Quality of Experience (QoE). The aim of JC is to exploit all available resources, which are diverse in terms of CPU architecture, number of cores, amount of memory, operating cost, and performance available to process data [
14]. These heterogeneous, hierarchical, and distributed computing resources are, for example: Desktop Grids, Grids, isolated machines, mobile devices, clusters, and the cloud, but also specialized architectures such as GPUs and FPGAs [
15]. Nowadays, the only usable Jungle Computing platform is the Ibis/Constellation [
16,
17]. Ibis is a high-performance distributed programming system written in Java and composed of a distributed deployment system allowing us to deploy an application in the Jungle and a high-performance programming system allowing us to write an application especially designed to run in the Jungle. While Constellation is a lightweight software platform designed for distributed, heterogeneous and hierarchical computing environments in which each application consists of multiple distinct, loosely coupled activities that communicate using events. Each activity represents distinct action, targeting small and homogeneous environment [
16]. Zarrin et al. [
18] have developed under the framework Service-oriented Operating System (S[o]OS), a Hybrid Adaptive Resource Discovery for Jungle Computing (HARD), an efficient and highly scalable resource-discovery approach applicable to large heterogeneous and highly dynamic distributed environment. HARD is self-adaptable and self-configurable to processing resources in the system.
The
Social Internet of Things (SIoT) is a paradigm inspired by social networks, proposed by Atozi et al. [
19], in which the privacy and protection technologies are used to enhance the security of the IoT [
20]. Moreover, SIoT performs an effective discovery of things and services, services composition and improve the scalability [
20,
21]. The SIoT combines IoT and social networks. In this paradigm, each object establishes social relationships with other objects individually while respecting the heuristics set by the owner of the object [
21]. Objects can interact following four basic relationship type: parent–child, co-location/co-work based, object ownership, and social object. These relations are used to discover and provide on-demand services. SIoT also includes service composition and trust management [
22]. It is imperative for researchers to correctly identify from the outset where the data processing will take place because this has an impact on the choice of nodes, the amount of data to transfer and by consequence on communication protocols to use, but also on battery autonomy of devices. Kosmatos et al. [
23] have proposed a unified architectural model for the IoT, which integrates Radio Frequency Identification (RFID) tags and smart things by using of social features of them. Ortiz et al. [
24] have proposed an architecture combining humans, devices and services. Vouryras et al. [
25] proposed an architecture using Virtual Entities that are the equivalent of smart things in the virtual world. Vouryras et al. [
26] developed an architecture using the principles of relation model. Alam et al. [
27] have proposed cyber physical architecture for the Social Internet of Vehicles (SIoV). SIoV is a vehicular instance of the SIoT, where vehicles are the key social entities in the machine to machine vehicular social networks. The architecture adopts the IoT-A reference model to design the domain models of the SIoV subsystems.
4. Implementation
The coordination service is based on containerization that ensures the discovery of sensors, putting them in touch with end-users, coordinate processing between Fog computing/Cloud near sensors networks connected at low throughput with sensors and end-users connected with high bandwidth by means of 5G or xDSL.
Micro-services deployment can be done by using either virtual machines or containers. Virtual machines offer a better isolation thanks to the use of dedicated operating systems. On the other hand, containers are lighter because they only host the software layers necessary to run programs or services. Since containers are lighter than virtual machines, it is possible to deploy more of them with the same resource. Indeed, when the resources at network edge are limited, containerization technology is the preferred choice.
Among container orchestration systems, Kubernetes is the benchmark. Kubernetes was developed specifically for the deployment of clusters of several thousand nodes to form private, public or hybrid clouds. Micro Kubernetes (
micro k8s) is a lightweight open source container orchestration platform that manages workloads (
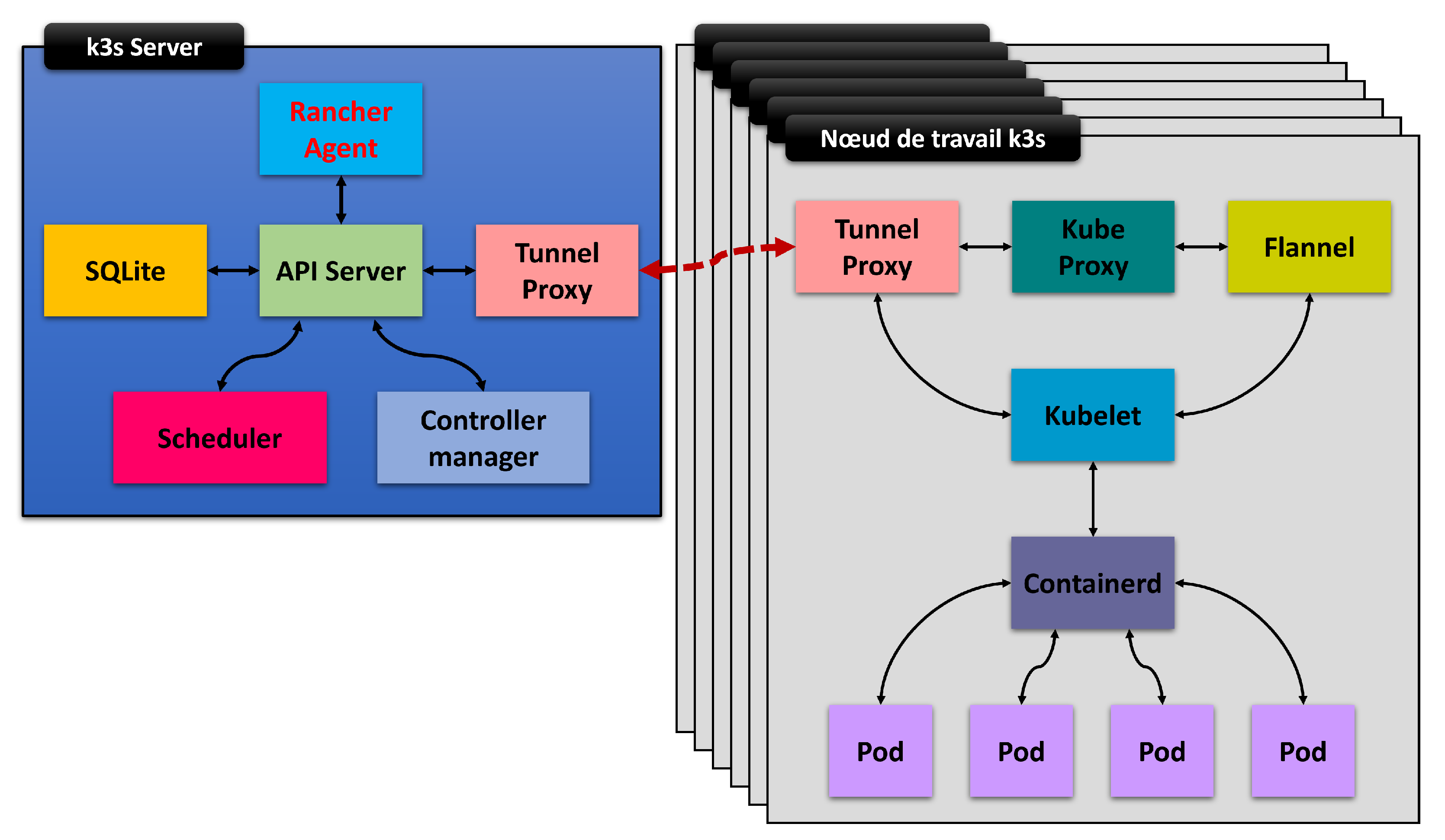
worflow) and containerized services at the edge with the ability to manage Nvidia GPU containers. Kubernetes and Micro Kubernetes are designed to work together and be deployed at the cloud and edge, respectively. Both use the notion of "pods" which are deployment units containing one or more containers. k3s is a lightweight version of k8s specifically designed for IoT as a project of the Cloud Native Computing Foundation. It takes the form of a 40 MB binary, requiring only 512 MB of memory and is adapted to run on ARMv7 and ARM64. k3s and micro k8s can run on Raspberry Pi, Nvidia Jetson Nx and Nano in theory. In practice, micro k8s has a large memory footprint for nodes with a small amount of memory, so we preferred k3s, which offers, in addition to its lightness, a sufficient level of security to implement an Edge-level cluster on constrained devices. Basically, k3s differs from k8s by replacing etcd (
https://etcd.io, accessed on 24 January 2022) database with SQLite at the master node, adding a tunnel proxy that secures the connection between the master node and each worker node, and replacing the Container Network Interface (CNI) with a lighter component called “flannel”. The
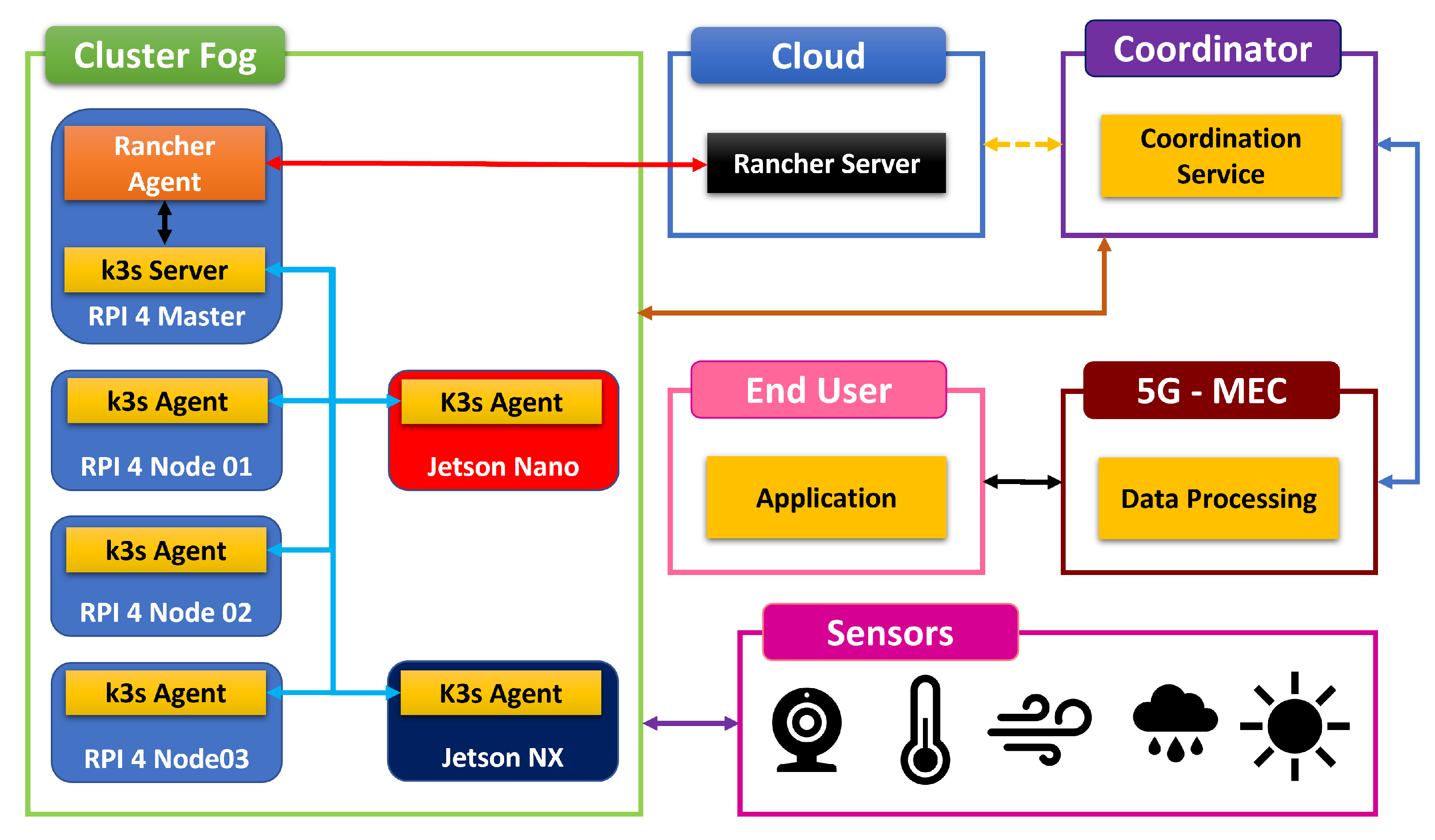
Figure 2 gives an overview of the interactions between software components.
Depending on the nature of the tasks to be performed, application cases and their constraints guide the choice and the number of computing nodes. For example, for image or video processing, we can be satisfied with computing nodes with many cores. If we want to use pre-trained AI algorithms, GPU-based nodes are preferred for this type of application.
A cluster with different types of nodes can address most of the needs at the Edge. In addition, if necessary, highly parallelized calculations can also be executed on the CPU nodes with an additional GPU and could be typically reserved for artificial intelligence algorithms. Similarly, artificial intelligence algorithms can also be executed on CPU-based nodes, but more slowly. The challenge is then to assign tasks according to their nature to the best suited resources according to their availability and load (CPU/GPU and memory resources used).
The Rancher orchestrator is used to deploy containers at the edge level. At the cloud level, the Rancher server is deployed in a docker container on Apache Mesos. The Rancher agent deployed at the Edge cluster provides communication with the Rancher server deployed in the cloud. The Edge cluster is managed by a k3s master node, which communicates with the Rancher agent and the k3s agent installed on each k3s worker node.
Figure 3 shows the arrangement of the different components of k3s within the micro-cluster.
The Master Node, a Raspberry Pi 4, is responsible for application workload distribution, scheduling, and detecting and managing changes in the state of deployed applications. The master node is also responsible for assigning the application to a node chosen according to its needs. There are two ways used to configure our node: the first is to use the pod configuration file to describe the node that will be responsible for scheduling the application. The second way, consists of using the command line and specifying the label of the specific node.
The services installed on the master node are: (1) SQLite, for persistence and maintenance of statistical information about the various components of the k3s cluster. SQLite is used instead of etcd (
https://etcd.io/, accessed on 24 January 2022) database, which is usually used by k8s, but is too memory-intensive to run in a memory constrained environment; (2) an API server exposes endpoints for all interactions with and within the k3s cluster; (3) a scheduler schedules based on application resource requirements and specific affinity constraints which application pod(s) should run on the selected working node(s) of the k3s cluster; (4) a controller manager; (5) a tunnel proxy that manages and maintains the connection tunnel between the master node and each of the worker nodes; and (6) the “Flannel” replaces the k8s Container Network Interface (CNI) and allows for the interconnection of worker nodes to each other.
The worker nodes mixing Raspberry Pi 4, Nvidia Jetson Nano and Nvidia Xavier NX are composed of: (1) Kubelet, an agent that runs on each worker (Worker) of k3s. It creates and starts an application module on the worker and monitors the health of the worker and all modules running on the master node via the API server; (2) Kube-proxy, a network proxy that is an entry point for accessing various application service endpoints and routes a request to the appropriate pods in the cluster; (3) Containerd manages the container lifecycle such as obtaining images, starting and stopping containers, etc.; and (4) the tunnel proxy maintains the connection between the master node and the worker node.
5. Experimentation
Our first use case is the analysis of cows’ behaviors in field by means of a Solar WiFi camera 1080 p connected to the mini-cluster previously partially described in [
30] by an external Wi-Fi network. (See
Figure 4).
The mini-cluster is composed of two Jetson NX equipped of 500 Gb SSD Samsung 980 Pro, and four Raspberry Pi 4 8GB equipped of 500 Gb Crucial MX500 SSDs interconnected by a 8 Port Gigabit Ethernet Network switch (See
Figure 5). Raspberry PI 4 runs an adapted release of Ubuntu while Jetson runs Jetpack SDK 4.6 (
https://developer.nvidia.com/embedded/jetpack, accessed on 25 January 2022). k3s has been used as lightweight container manager compatible with Kubernetes (k8s). It was preferred to other solutions such as micro k8s and k8s for its low memory footprint [
31], its security level using centralized Role Based Access Control (RBAC), and finally for its CUDA support. One Raspberry Pi plays the role of master node, while three others are worker nodes. Jetson nodes (NX & Nano) are also worker nodes. k3s has been deployed on the mini cluster by means of Rancher 2.5 (
https://rancher.com/, accessed on 25 January 2022), an open source software with zero vendor lock-in.
The cluster analyzes, on one hand, the camera video using a deep neural network, and on the other hand, collects and processes data from the environmental sensors.
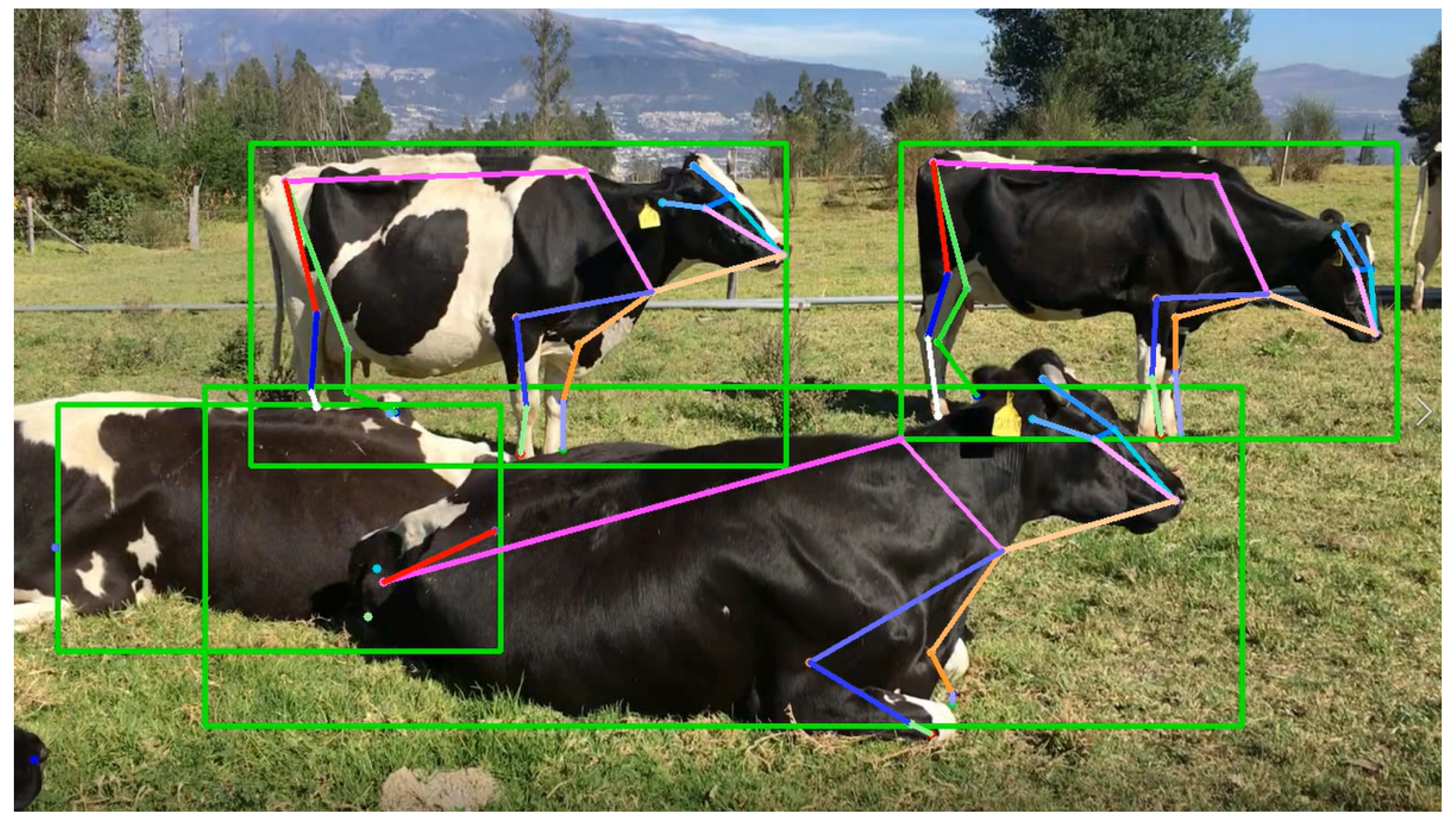
The model based on a top-down approach and using YOLOv3 (
https://pjreddie.com/darknet/yolo/, accessed on 23 January 2022) as object detection models to calculate a bounding box around each animal. Afterwards, the model computes for each one a digital twin based on a skeleton made of 20 key points by means of mmPose 0.21 [
32], an open-source toolbox for pose estimation. The model was trained with the Animal Pose Dataset proposed by Cao et al. [
33] providing animal pose annotations of 20 key points: Two eyes, Throat, Nose, Withers, Two Earbases, Tailbase, Four Elbows, Four Knees, and Four Paws for five categories: dog, cat, cow, horse, sheep. Finally, skeletons are classified animal behaviors: standing, rumination, grazing, walking, and lying [
34,
35]. Images are analyzed at a rate of 0.5 frame by second at Fog Level.
A processed frame of a video is illustrated at
Figure 6. The transmission of data coupling animal skeleton and environmental parameters is achieved by LoRa radio frequency protocol to the Coordinator (See
Figure 4).
Two kind of data packet are transmitted: The first packet of data contains the id of the cow (4 digits), and meteorological data: temperature (5 characters), relative humidity (4 characters), wind speed at 2 meter of the ground, expressed in meter per second (4 characters) transmitted once every 5 minutes. The second type of data packet contains a header with the batch index (4 digits), the id of the cow (4 digits) to witch relatives coordinates of the 10 of 20 key points (12 digits per point) of the skeleton are added. Hence, the 20 keypoints are transmitted in 2 packets each 2 s. Coordinator service merge environmental data and the two packages with data of skeleton keypoints are merged following the batch index before to be sent to MEC by 5G.
Data packets are forwarded by the coordinator to MEC by 5G where a model calculates the digital twin in the form of a skeleton as illustrated on the
Figure 6 and determine behaviors from skeleton movement and deformation detection.
Our second use case is the monitoring of landslides in the mountain region of Tetouan in the North of Morocco (See
Figure 7). The monitoring system previous described in [
6] uses sensors to follow soil moisture and soil movements.
The data is transmitted with LoRa protocol, but mountain harsh conditions limit the signal propagation to few hundreds meters. Then, we improved the system by using Edge Computing, but the facilities for data processing must be close to the data measurement locations which leads to high costs [
36]. The SSCIoT now allows us to centralize the information from the WSNs and process one or more measurement areas at the 5G-MEC server level, allowing us to deploy the premises of our monitoring and early warning system [
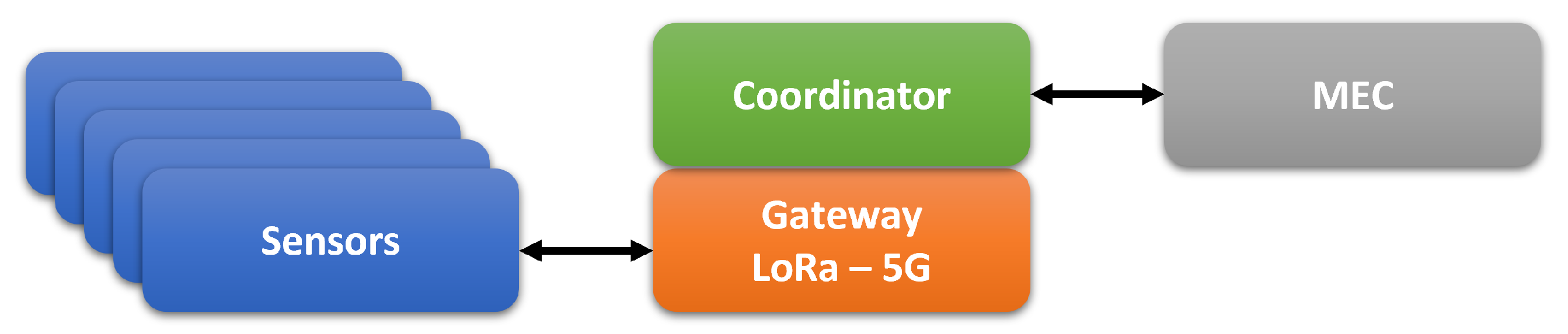
7]. As illustrated on the
Figure 8, the coordinator is hosted on the LoRa-5G gateway which performs the dual roles of network gateway and coordination between the WSN and the 5G-MEC for data processing. The network gateway can perform both roles given the small amounts of data that are transmitted at a frequency much lower than 1 Hz.
This implementation of SSCIoT allows the gateway to be used for light pre-processing and hosting of the coordination service. The MEC is used for heavier processing instead of the cloud and provides ultra-low latency access to the processing results to the end user.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







