
Image Retrieval via Canonical Correlation Analysis and Binary Hypothesis Testing †

 , , , and
, , , and 
Abstract
:1. Introduction
2. Proposed Method
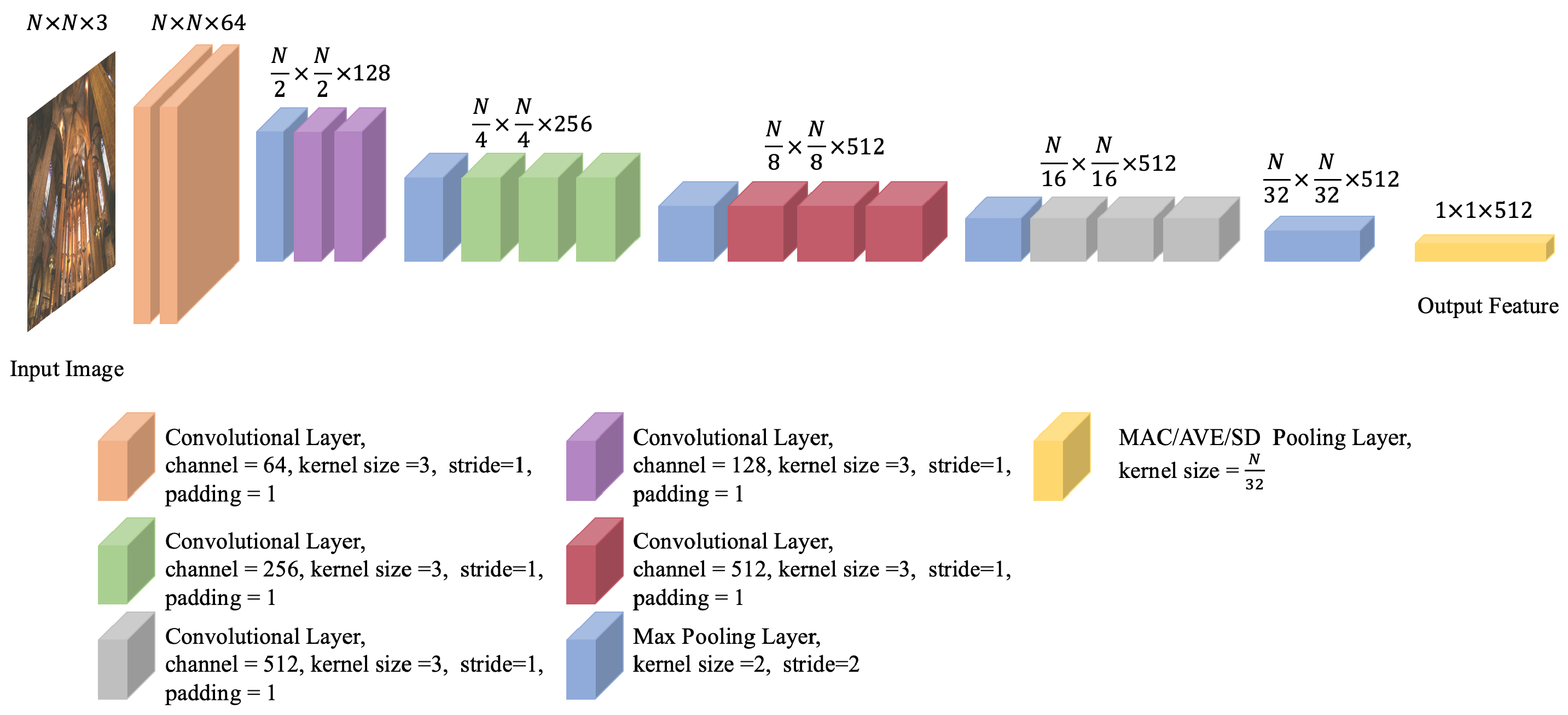
2.1. Image Pre-Processing and Feature Extraction
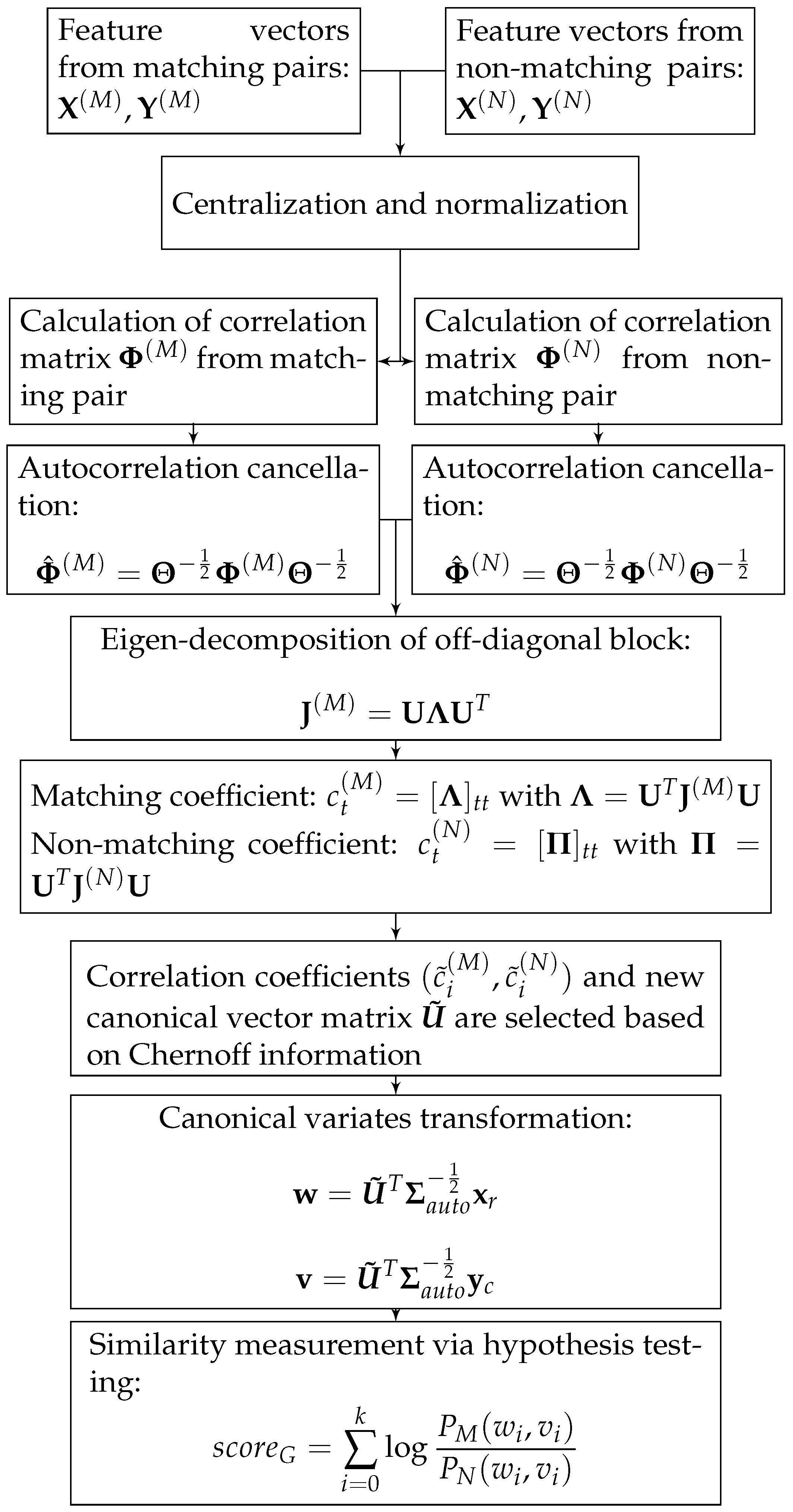
2.2. Correlation Analysis and Canonical Vectors
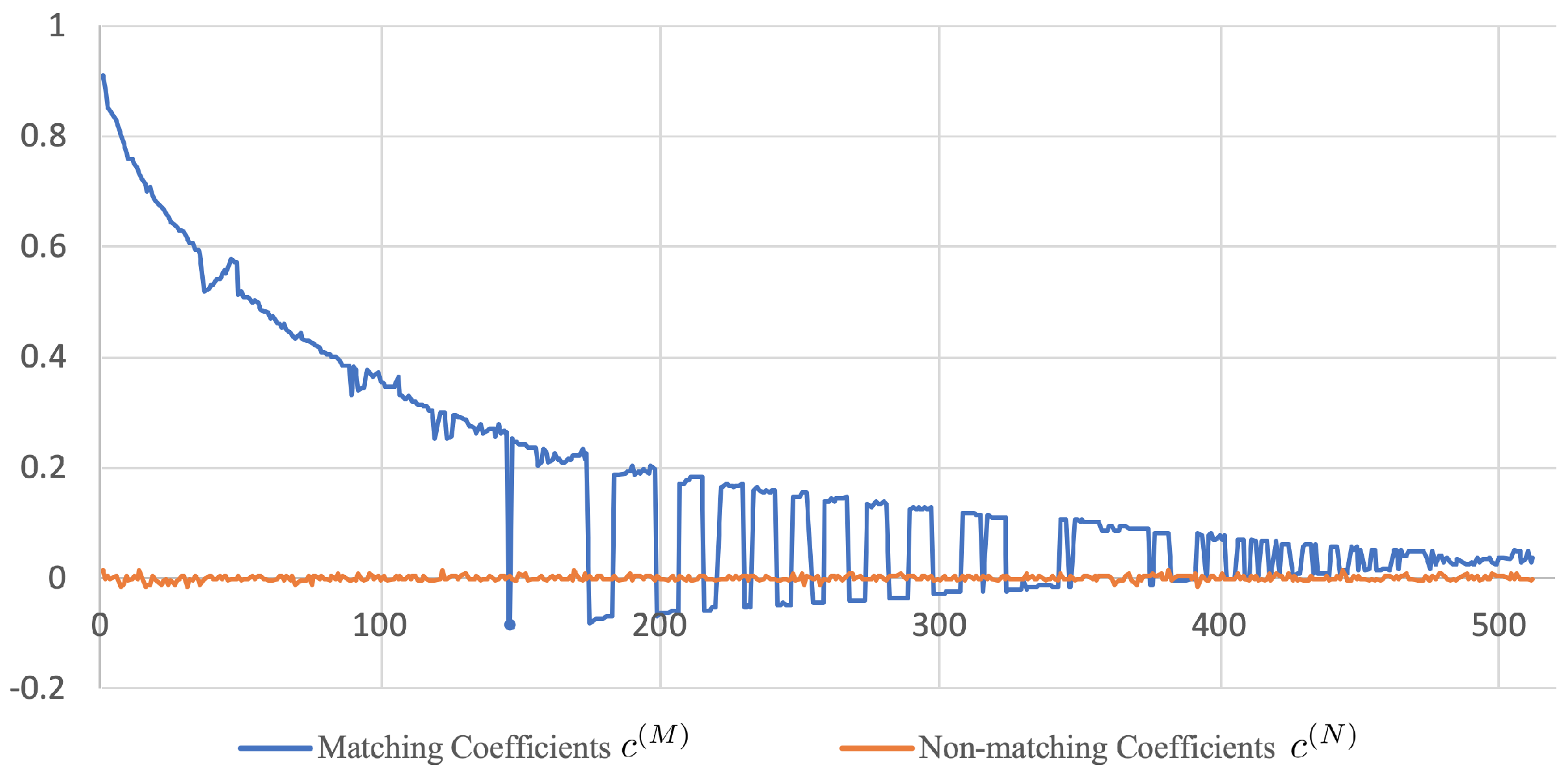
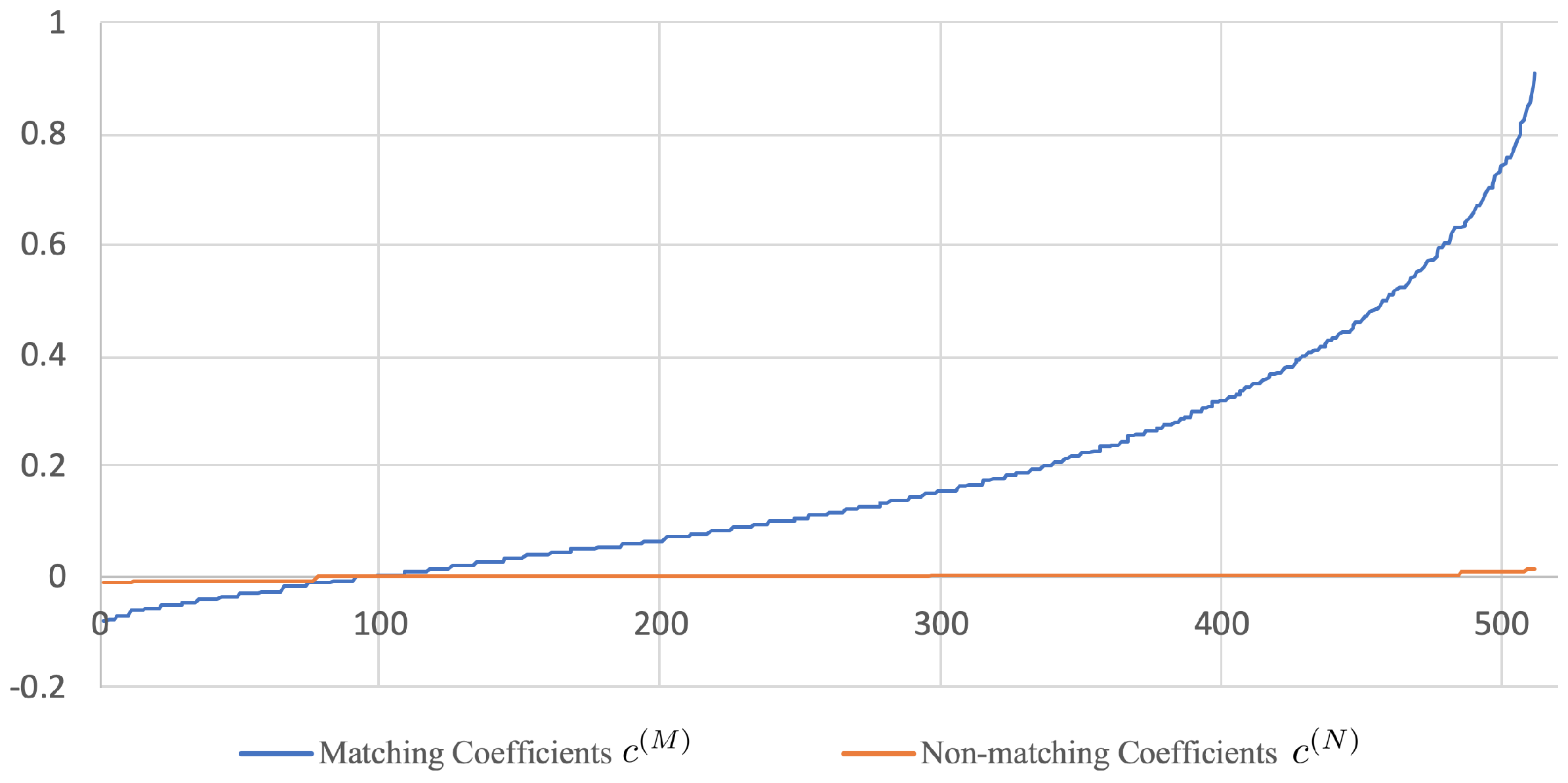
2.3. Chernoff Information for Canonical Vector Selection
2.4. Similarity Measurement
3. Experimental Results
3.1. Training Datasets
3.1.1. 120k-Structure from Motion
3.1.2. 30k-Structure from Motion
3.2. Training Details
3.3. Implementation Details
3.4. Evaluation Datasets and Details
3.4.1. Oxford5k
3.4.2. Oxford
3.4.3. Paris6k
3.4.4. Paris
3.5. Performance Evaluation and Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Chernoff Information between Two 2-Dimensional Gaussian Distributions
References
- Wengang, Z.; Houqiang, L.; Qi, T. Recent advance in content-based image retrieval: A literature survey. arXiv 2017, arXiv:1706.06064. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Tan, X.; Triggs, B. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans. Image Process. 2010, 19, 1635–1650. [Google Scholar] [PubMed] [Green Version]
- Ojansivu, V.; Heikkilä, J. Blur insensitive texture classification using local phase quantization. In International Conference on Image and Signal Processing; Springer: Berlin/Heidelberg, Germany, 2008; pp. 236–243. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. IEEE Conf. Comput. Vis. Pattern Recognit. 2005, 1, 886–893. [Google Scholar]
- Batool, A.; Nisar, M.W.; Shah, J.H.; Khan, M.A.; El-Latif, A.A.A. iELMNet: Integrating novel improved extreme learning machine and convolutional neural network model for traffic sign detection. Big Data, 2022; ahead of print. [Google Scholar] [CrossRef]
- Nawaz, M.; Nazir, T.; Javed, A.; Tariq, U.; Yong, H.-S.; Khan, M.A.; Cha, J. An efficient deep learning approach to automatic glaucoma detection using optic disc and optic cup localization. Sensors 2022, 22, 434. [Google Scholar] [CrossRef]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; Institute of Electrical and Electronics Engineers: Columbus, OH, USA, 2014; pp. 806–813. [Google Scholar]
- Khan, M.A.; Muhammad, K.; Sharif, M.; Akram, T.; Kadry, S. Intelligent fusion-assisted skin lesion localization and classification for smart healthcare. Neural Comput. Appl. 2021, 1–16. [Google Scholar] [CrossRef]
- Tolias, G.; Sicre, R.; Jégou, H. Particular object retrieval with integral max-pooling of CNN activations. arXiv 2015, arXiv:1511.05879. [Google Scholar]
- Babenko, A.; Lempitsky, V. Aggregating local deep features for image retrieval. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1269–1277. [Google Scholar]
- Lin, J.; Duan, L.-Y.; Wang, S.; Bai, Y.; Lou, Y.; Chandrasekhar, V.; Huang, T.; Kot, A.; Gao, W. Hnip: Compact deep invariant representations for video matching, localization, and retrieval. IEEE Trans. Multimed. 2017, 19, 1968–1983. [Google Scholar] [CrossRef]
- Kalantidis, Y.; Mellina, C.; Osindero, S. Cross-dimensional weighting for aggregated deep convolutional features. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 685–701. [Google Scholar]
- Azhar, I.; Sharif, M.; Raza, M.; Khan, M.A.; Yong, H.-S. A decision support system for face sketch synthesis using deep learning and artificial intelligence. Sensors 2021, 21, 8178. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.; Khan, M.A.; Alhaisoni, M.; Tariq, U.; Yong, H.-S.; Armghan, A.; Alenezi, F. Human action recognition: A paradigm of best deep learning features selection and serial based extended fusion. Sensors 2021, 21, 7941. [Google Scholar] [CrossRef]
- Noh, H.; Araujo, A.; Sim, J.; Weyand, T.; Han, B. Largescale image retrieval with attentive deep local features. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3456–3465. [Google Scholar]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN architecture for weakly supervised place recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 5297–5307. [Google Scholar]
- Radenović, F.; Tolias, G.; Chum, O. CNN image retrieval learns from bow: Unsupervised fine-tuning with hard examples. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 3–20. [Google Scholar]
- Gordo, A.; Almazan, J.; Revaud, J.; Larlus, D. End-to-end learning of deep visual representations for image retrieval. Int. J. Comput. Vis. 2017, 124, 237–254. [Google Scholar] [CrossRef] [Green Version]
- Hyvärinen, A.; Hurri, J.; Hoyer, P.O. Principal components and whitening. In Natural Image Statistics; Springer: Berlin/Heidelberg, Germany, 2009; pp. 93–130. [Google Scholar]
- Izenman, A.J. Linear discriminant analysis. In Modern Multivariate Statistical Techniques; Springer: Berlin/Heidelberg, Germany, 2013; pp. 237–280. [Google Scholar]
- Johnson, R.A.; Wichern, D.W. Canonical correlation analysis. In Applied Multivariate Statistical Analysis, 6th ed.; Pearson: Upper Saddle River, NJ, USA, 2018; pp. 539–574. [Google Scholar]
- Gong, Y.; Ke, Q.; Isard, M.; Lazebnik, S. A multi-view embedding space for modeling internet images, tags, and their semantics. Int. J. Comput. Vis. 2014, 106, 210–233. [Google Scholar] [CrossRef] [Green Version]
- Yan, F.; Mikolajczyk, K. Deep correlation for matching images and text. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3441–3450. [Google Scholar]
- Dorfer, M.; Schlüter, J.; Vall, A.; Korzeniowski, F.; Widmer, G. End-to-end cross-modality retrieval with cca projections and pairwise ranking loss. Int. J. Multimed. Inf. Retr. 2018, 7, 117–128. [Google Scholar] [CrossRef] [Green Version]
- Yu, Y.; Tang, S.; Aizawa, K.; Aizawa, A. Category-based deep cca for fine-grained venue discovery from multimodal data. arXiv 2018, arXiv:1805.02997. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, Z.; Peltonen, J. An information retrieval approach for finding dependent subspaces of multiple views. In International Conference on Machine Learning and Data Mining in Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1–16. [Google Scholar]
- Yair, O.; Talmon, R. Local canonical correlation analysis for nonlinear common variables discovery. IEEE Trans. Signal Process. 2017, 65, 1101–1115. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Abdi, H. The eigen-decomposition: Eigenvalues and eigenvectors. In Encyclopedia of Measurement and Statistics; SAGE Publications, Inc.: Thousand Oaks, CA, USA, 2007; pp. 304–308. [Google Scholar]
- Nielsen, F. An information-geometric characterization of chernoff information. IEEE Signal Process. Lett. 2013, 20, 269–272. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F. Chernoff information of exponential families. arXiv 2011, arXiv:1102.2684. [Google Scholar]
- Prince, S.J. Common probability distribution. In Computer Vision: Models, Learning and Inference; Cambridge University Press: Cambridge, England, 2012; pp. 35–42. [Google Scholar]
- Radenović, F.; Tolias, G.; Chum, O. Fine-tuning CNN image retrieval with no human annotation. In IEEE Transactions on Pattern Analysis and Machine Intelligence; Institute of Electrical and Electronics Engineers: Manhattan, NY, USA, 2018. [Google Scholar]
- Schonberger, J.L.; Radenovic, F.; Chum, O.; Frahm, J.-M. From single image query to detailed 3d reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5126–5134. [Google Scholar]
- Koren, Y.; Carmel, L. Robust linear dimensionality reduction. IEEE Trans. Vis. Comput. Graph. 2004, 10, 459–470. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Zhu, S.; Ogihara, M. Using discriminant analysis for multi-class classification. In Third IEEE International Conference on Data Mining; IEEE Computer Society: Los Alamitos, CA, USA, 2003; p. 589. [Google Scholar]
- Mirkes, E.M.; Gorban, A.N.; Zinoviev, A. A Supervised PCA. 2016. Available online: https://github.com/Mirkes/SupervisedPCA (accessed on 10 September 2021).
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Swets, D.L.; Weng, J.J. Using discriminant eigenfeatures for image retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 8, 831–836. [Google Scholar] [CrossRef] [Green Version]
- Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Object retrieval with large vocabularies and fast spatial matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Lost in quantization: Improving particular object retrieval in large scale image databases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Radenovic, F.; Iscen, A.; Tolias, G.; Avrithis, Y.; Chum, O. Revisiting oxford and paris: Large-scale image retrieval benchmarking. In Proceedings of the IEEE Computer Vision and Pattern Recognition Conference, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Matching Pair |  |  |  |  |  |  |
 |  |  |  |  |  | |
| Non-Matching Pair |  |  |  |  |  |  |
 |  |  |  |  |  |
| Method | Oxford5k | Oxford | Paris6k | Paris |
|---|---|---|---|---|
| MAC | 0.5296 | 0.3295 | 0.7455 | 0.5122 |
| S-CCA + MAC | 0.5800 | 0.3575 | 0.7726 | 0.5408 |
| G-CCA + MAC | 0.6275 | 0.3996 | 0.7455 | 0.5939 |
| AVE | 0.5312 | 0.2884 | 0.6467 | 0.4653 |
| S-CCA + AVE | 0.6845 | 0.4303 | 0.7845 | 0.5936 |
| G-CCA + AVE | 0.7146 | 0.4444 | 0.7507 | 0.5812 |
| SD | 0.6095 | 0.3834 | 0.7355 | 0.5311 |
| S-CCA + SD | 0.6943 | 0.4503 | 0.8191 | 0.6199 |
| G-CCA + SD | 0.7419 | 0.4806 | 0.8164 | 0.6403 |
| Oxford5k | Dim | MAC | AVE | SD | |||||||||
| SPCA | PCAw | S-CCA | G-CCA | SPCA | PCAw | S-CCA | G-CCA | SPCA | PCAw | S-CCA | G-CCA | ||
| 25 | 0.3589 | 0.3555 | 0.2431 | 0.3873 | 0.4474 | 0.4443 | 0.3091 | 0.4873 | 0.4757 | 0.4838 | 0.3439 | 0.4979 | |
| 50 | 0.4412 | 0.4258 | 0.3174 | 0.4487 | 0.4930 | 0.4933 | 0.3782 | 0.5127 | 0.5086 | 0.5074 | 0.4403 | 0.5690 | |
| 100 | 0.5016 | 0.5027 | 0.4122 | 0.5043 | 0.5599 | 0.5697 | 0.5447 | 0.6034 | 0.6002 | 0.6041 | 0.5191 | 0.6164 | |
| 200 | 0.5628 | 0.5583 | 0.4818 | 0.5501 | 0.6083 | 0.6086 | 0.6157 | 0.6445 | 0.6635 | 0.6619 | 0.6280 | 0.6772 | |
| 300 | 0.5723 | 0.5672 | 0.5280 | 0.5379 | 0.6416 | 0.6307 | 0.6428 | 0.6552 | 0.6753 | 0.6736 | 0.6513 | 0.6830 | |
| 400 | 0.5728 | 0.5715 | 0.5505 | 0.5405 | 0.6517 | 0.6385 | 0.6373 | 0.6525 | 0.6811 | 0.6811 | 0.6703 | 0.6745 | |
| 450 | 0.5670 | 0.5654 | 0.5609 | 0.5364 | 0.6544 | 0.6422 | 0.6393 | 0.6538 | 0.6839 | 0.6849 | 0.6740 | 0.6746 | |
| 512 | 0.5615 | 0.5601 | 0.5580 | 0.5363 | 0.6506 | 0.6388 | 0.6493 | 0.6537 | 0.6766 | 0.6763 | 0.6764 | 0.6743 | |
| Oxford | Dim | MAC | AVE | SD | |||||||||
| SPCA | PCAw | S-CCA | G-CCA | SPCA | PCAw | S-CCA | G-CCA | SPCA | PCAw | S-CCA | G-CCA | ||
| 25 | 0.2070 | 0.2226 | 0.1495 | 0.2276 | 0.2702 | 0.2709 | 0.1939 | 0.2590 | 0.2883 | 0.2856 | 0.2116 | 0.3031 | |
| 50 | 0.2823 | 0.2771 | 0.1886 | 0.2914 | 0.2731 | 0.2757 | 0.2206 | 0.2876 | 0.3117 | 0.3123 | 0.2590 | 0.3485 | |
| 100 | 0.3259 | 0.3281 | 0.2484 | 0.3282 | 0.3304 | 0.3197 | 0.3083 | 0.3372 | 0.3885 | 0.3795 | 0.3007 | 0.3848 | |
| 200 | 0.3462 | 0.3545 | 0.3071 | 0.3569 | 0.3569 | 0.3531 | 0.3759 | 0.4002 | 0.4399 | 0.4368 | 0.4021 | 0.4417 | |
| 300 | 0.3595 | 0.3593 | 0.3290 | 0.3413 | 0.3901 | 0.3771 | 0.3911 | 0.4057 | 0.4507 | 0.4420 | 0.4173 | 0.4484 | |
| 400 | 0.3576 | 0.3568 | 0.3424 | 0.3400 | 0.3905 | 0.3796 | 0.3798 | 0.4065 | 0.4526 | 0.4381 | 0.4454 | 0.4538 | |
| 450 | 0.3551 | 0.3544 | 0.3466 | 0.3398 | 0.4002 | 0.3772 | 0.3876 | 0.4052 | 0.4498 | 0.4382 | 0.4435 | 0.4499 | |
| 512 | 0.3442 | 0.3469 | 0.3444 | 0.3396 | 0.4042 | 0.3767 | 0.3963 | 0.4077 | 0.4417 | 0.4383 | 0.4412 | 0.4419 | |
| Paris | Dim | MAC | AVE | SD | |||||||||
| SPCA | PCAw | S-CCA | G-CCA | SPCA | PCAw | S-CCA | G-CCA | SPCA | PCAw | S-CCA | G-CCA | ||
| 25 | 0.4878 | 0.5084 | 0.4133 | 0.5464 | 0.4944 | 0.4330 | 0.4182 | 0.4990 | 0.5633 | 0.5858 | 0.4758 | 0.5969 | |
| 50 | 0.6027 | 0.6208 | 0.5391 | 0.6347 | 0.5692 | 0.5893 | 0.5898 | 0.6153 | 0.6415 | 0.6555 | 0.6084 | 0.6746 | |
| 100 | 0.6691 | 0.6750 | 0.5848 | 0.6808 | 0.6441 | 0.6736 | 0.6559 | 0.6790 | 0.7290 | 0.7267 | 0.6988 | 0.7426 | |
| 200 | 0.7035 | 0.6942 | 0.6384 | 0.7166 | 0.6931 | 0.6994 | 0.7049 | 0.7106 | 0.7719 | 0.7620 | 0.7501 | 0.7811 | |
| 300 | 0.7004 | 0.6980 | 0.6701 | 0.7067 | 0.7109 | 0.7328 | 0.7297 | 0.7118 | 0.7834 | 0.7819 | 0.7739 | 0.7892 | |
| 400 | 0.7076 | 0.7057 | 0.6893 | 0.7052 | 0.7375 | 0.7586 | 0.7418 | 0.7120 | 0.8010 | 0.7970 | 0.7885 | 0.7867 | |
| 450 | 0.7091 | 0.7073 | 0.6964 | 0.7027 | 0.7482 | 0.7679 | 0.7472 | 0.7130 | 0.8067 | 0.8066 | 0.7969 | 0.7871 | |
| 512 | 0.7032 | 0.7060 | 0.7039 | 0.7029 | 0.7508 | 0.7732 | 0.7520 | 0.7133 | 0.8020 | 0.8031 | 0.8036 | 0.7874 | |
| Paris | Dim | MAC | AVE | SD | |||||||||
| SPCA | PCAw | S-CCA | G-CCA | SPCA | PCAw | S-CCA | G-CCA | SPCA | PCAw | S-CCA | G-CCA | ||
| 25 | 0.3966 | 0.3944 | 0.3225 | 0.4212 | 0.3877 | 0.3981 | 0.3085 | 0.4212 | 0.4361 | 0.4410 | 0.3602 | 0.4433 | |
| 50 | 0.4725 | 0.4738 | 0.4063 | 0.4781 | 0.4354 | 0.4442 | 0.4385 | 0.4538 | 0.5006 | 0.5015 | 0.4524 | 0.5056 | |
| 100 | 0.5007 | 0.5021 | 0.4311 | 0.5106 | 0.4820 | 0.4886 | 0.4946 | 0.5082 | 0.5457 | 0.5501 | 0.5258 | 0.5653 | |
| 200 | 0.5183 | 0.5182 | 0.4668 | 0.5370 | 0.5118 | 0.5129 | 0.5302 | 0.5355 | 0.5822 | 0.5827 | 0.5635 | 0.5985 | |
| 300 | 0.5206 | 0.5200 | 0.4894 | 0.5285 | 0.5281 | 0.5306 | 0.5507 | 0.5377 | 0.5966 | 0.5964 | 0.5829 | 0.6045 | |
| 400 | 0.5224 | 0.5219 | 0.5040 | 0.5272 | 0.5504 | 0.5507 | 0.5577 | 0.5379 | 0.6064 | 0.6070 | 0.5958 | 0.6024 | |
| 450 | 0.5222 | 0.5200 | 0.5109 | 0.5255 | 0.5587 | 0.5590 | 0.5620 | 0.5383 | 0.6119 | 0.6121 | 0.6013 | 0.6027 | |
| 512 | 0.5169 | 0.5168 | 0.5154 | 0.5256 | 0.5579 | 0.5588 | 0.5646 | 0.5384 | 0.6051 | 0.6067 | 0.6048 | 0.6028 | |
| Oxford5k | Dim | MAC | AVE | SD | |||||||||
| MLDA | PCAw | S-CCA | G-CCA | MLDA | PCAw | S-CCA | G-CCA | MLDA | PCAw | S-CCA | G-CCA | ||
| 25 | 0.3603 | 0.3906 | 0.2677 | 0.4019 | 0.4758 | 0.4266 | 0.2644 | 0.4821 | 0.4759 | 0.4790 | 0.3400 | 0.5212 | |
| 50 | 0.4760 | 0.4319 | 0.3802 | 0.4987 | 0.5612 | 0.5033 | 0.4293 | 0.5572 | 0.5375 | 0.5355 | 0.4667 | 0.5956 | |
| 100 | 0.5157 | 0.5275 | 0.4537 | 0.5481 | 0.6017 | 0.5756 | 0.5529 | 0.6402 | 0.6429 | 0.6240 | 0.5593 | 0.6688 | |
| 200 | 0.5887 | 0.5453 | 0.5562 | 0.6231 | 0.6571 | 0.6437 | 0.6498 | 0.6964 | 0.6861 | 0.6410 | 0.6620 | 0.7244 | |
| 300 | 0.6028 | 0.5669 | 0.5697 | 0.6306 | 0.6643 | 0.6474 | 0.6658 | 0.7102 | 0.7030 | 0.6711 | 0.6754 | 0.7382 | |
| 400 | 0.5974 | 0.5810 | 0.5768 | 0.6275 | 0.6688 | 0.6681 | 0.6758 | 0.7139 | 0.7020 | 0.6970 | 0.6864 | 0.7422 | |
| 450 | 0.5939 | 0.5840 | 0.5820 | 0.6279 | 0.6678 | 0.6728 | 0.6781 | 0.7144 | 0.6972 | 0.6986 | 0.6939 | 0.7412 | |
| 512 | 0.5868 | 0.5799 | 0.5800 | 0.6275 | 0.6613 | 0.6711 | 0.6845 | 0.7146 | 0.6958 | 0.6946 | 0.6943 | 0.7419 | |
| Oxford | Dim | MAC | AVE | SD | |||||||||
| MLDA | PCAw | S-CCA | G-CCA | MLDA | PCAw | S-CCA | G-CCA | MLDA | PCAw | S-CCA | G-CCA | ||
| 25 | 0.2330 | 0.2503 | 0.1543 | 0.2459 | 0.2712 | 0.2533 | 0.1422 | 0.2441 | 0.2666 | 0.3037 | 0.1782 | 0.2853 | |
| 50 | 0.2989 | 0.2664 | 0.2366 | 0.3025 | 0.3522 | 0.2802 | 0.2337 | 0.3366 | 0.3418 | 0.3357 | 0.2636 | 0.3254 | |
| 100 | 0.3470 | 0.3521 | 0.2724 | 0.3437 | 0.3981 | 0.3318 | 0.3412 | 0.4290 | 0.4002 | 0.4075 | 0.3269 | 0.4073 | |
| 200 | 0.3924 | 0.3510 | 0.3482 | 0.3991 | 0.4324 | 0.3911 | 0.3913 | 0.4411 | 0.4497 | 0.4192 | 0.4085 | 0.4622 | |
| 300 | 0.4006 | 0.3557 | 0.3497 | 0.3986 | 0.4404 | 0.3920 | 0.4056 | 0.4430 | 0.4645 | 0.4454 | 0.4335 | 0.4796 | |
| 400 | 0.3964 | 0.3625 | 0.3526 | 0.4001 | 0.4412 | 0.4106 | 0.4215 | 0.4462 | 0.4673 | 0.4609 | 0.4429 | 0.4812 | |
| 450 | 0.3941 | 0.3613 | 0.3587 | 0.3998 | 0.4363 | 0.4159 | 0.4215 | 0.4443 | 0.4624 | 0.4604 | 0.4394 | 0.4807 | |
| 512 | 0.3881 | 0.3570 | 0.3575 | 0.3996 | 0.4267 | 0.4136 | 0.4303 | 0.4444 | 0.4597 | 0.4501 | 0.4503 | 0.4806 | |
| Paris6k | Dim | MAC | AVE | SD | |||||||||
| MLDA | PCAw | S-CCA | G-CCA | MLDA | PCAw | S-CCA | G-CCA | MLDA | PCAw | S-CCA | G-CCA | ||
| 25 | 0.5781 | 0.4878 | 0.5109 | 0.6270 | 0.5553 | 0.5013 | 0.4442 | 0.5693 | 0.6204 | 0.5543 | 0.5269 | 0.6611 | |
| 50 | 0.6384 | 0.6153 | 0.5416 | 0.6679 | 0.6362 | 0.5893 | 0.5467 | 0.6314 | 0.6900 | 0.6575 | 0.5935 | 0.6968 | |
| 100 | 0.6916 | 0.6788 | 0.6226 | 0.7339 | 0.6994 | 0.6736 | 0.6657 | 0.6910 | 0.7502 | 0.7313 | 0.7105 | 0.7641 | |
| 200 | 0.7244 | 0.7124 | 0.6765 | 0.7674 | 0.7162 | 0.6994 | 0.7220 | 0.7491 | 0.7845 | 0.7842 | 0.7760 | 0.8043 | |
| 300 | 0.7493 | 0.7214 | 0.6900 | 0.7719 | 0.7299 | 0.7328 | 0.7538 | 0.7491 | 0.8030 | 00.8046 | 0.7973 | 0.8160 | |
| 400 | 0.7548 | 0.7230 | 0.7146 | 0.7729 | 0.7247 | 0.7586 | 0.7729 | 0.7507 | 0.8042 | 0.8143 | 0.8067 | 0.8164 | |
| 450 | 0.7540 | 0.7222 | 0.7729 | 0.7455 | 0.7197 | 0.7679 | 0.7775 | 0.7508 | 0.8003 | 0.8144 | 0.8096 | 0.8161 | |
| 512 | 0.7549 | 0.7288 | 0.7726 | 0.7455 | 0.7111 | 0.7732 | 0.7845 | 0.7507 | 0.7971 | 0.8159 | 0.8164 | 0.8191 | |
| Paris | Dim | MAC | AVE | SD | |||||||||
| MLDA | PCAw | S-CCA | G-CCA | MLDA | PCAw | S-CCA | G-CCA | MLDA | PCAw | S-CCA | G-CCA | ||
| 25 | 0.4321 | 0.3728 | 0.3956 | 0.4787 | 0.4524 | 0.3745 | 0.3607 | 0.4455 | 0.4817 | 0.4136 | 0.4075 | 0.5032 | |
| 50 | 0.4910 | 0.4685 | 0.4214 | 0.5156 | 0.4944 | 0.4495 | 0.4229 | 0.4877 | 0.5373 | 0.4998 | 0.4611 | 0.5415 | |
| 100 | 0.5339 | 0.5096 | 0.4681 | 0.5631 | 0.5003 | 0.5101 | 0.5052 | 0.5340 | 0.5796 | 0.5596 | 0.5472 | 0.5970 | |
| 200 | 0.5526 | 0.5346 | 0.5066 | 0.5910 | 0.5656 | 0.5310 | 0.5437 | 0.5678 | 0.6066 | 0.6002 | 0.5928 | 0.6317 | |
| 300 | 0.5520 | 0.5425 | 0.5124 | 0.5942 | 0.5809 | 0.5566 | 0.5639 | 0.5799 | 0.6195 | 0.6156 | 0.6021 | 0.6408 | |
| 400 | 0.5437 | 0.5406 | 0.5282 | 0.5941 | 0.5843 | 0.5738 | 0.5824 | 0.5857 | 0.6165 | 0.6228 | 0.6072 | 0.6401 | |
| 450 | 0.5399 | 0.5369 | 0.5313 | 0.5941 | 0.5829 | 0.5796 | 0.5844 | 0.5813 | 0.6136 | 0.6187 | 0.6118 | 0.6401 | |
| 512 | 0.5333 | 0.5387 | 0.5408 | 0.5939 | 0.5830 | 0.5828 | 0.5936 | 0.5812 | 0.6093 | 0.6178 | 0.6199 | 0.6403 | |
| Query | TOP 10 Retrieved Images | |
|---|---|---|
| A |  |           |
| B |  |           |
| C |  |           |
| Query | TOP 10 Retrieved Images | |
|---|---|---|
| A |  |           |
| B |  |           |
| C |  |           |
| Query | TOP 10 Retrieval Images | |
|---|---|---|
| A |  |           |
| B |  |           |
| C |  |           |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, K.; Liu, X.; Alrabeiah, M.; Guo, X.; Lin, J.; Liu, H.; Chen, J. Image Retrieval via Canonical Correlation Analysis and Binary Hypothesis Testing. Information 2022, 13, 106. https://doi.org/10.3390/info13030106
Shi K, Liu X, Alrabeiah M, Guo X, Lin J, Liu H, Chen J. Image Retrieval via Canonical Correlation Analysis and Binary Hypothesis Testing. Information. 2022; 13(3):106. https://doi.org/10.3390/info13030106
Chicago/Turabian StyleShi, Kangdi, Xiaohong Liu, Muhammad Alrabeiah, Xintong Guo, Jie Lin, Huan Liu, and Jun Chen. 2022. "Image Retrieval via Canonical Correlation Analysis and Binary Hypothesis Testing" Information 13, no. 3: 106. https://doi.org/10.3390/info13030106
APA StyleShi, K., Liu, X., Alrabeiah, M., Guo, X., Lin, J., Liu, H., & Chen, J. (2022). Image Retrieval via Canonical Correlation Analysis and Binary Hypothesis Testing. Information, 13(3), 106. https://doi.org/10.3390/info13030106