
Link Prediction in Time Varying Social Networks

 ,
, 
 ,
,  and
and
Abstract
:1. Introduction
2. Temporal Graph Networks
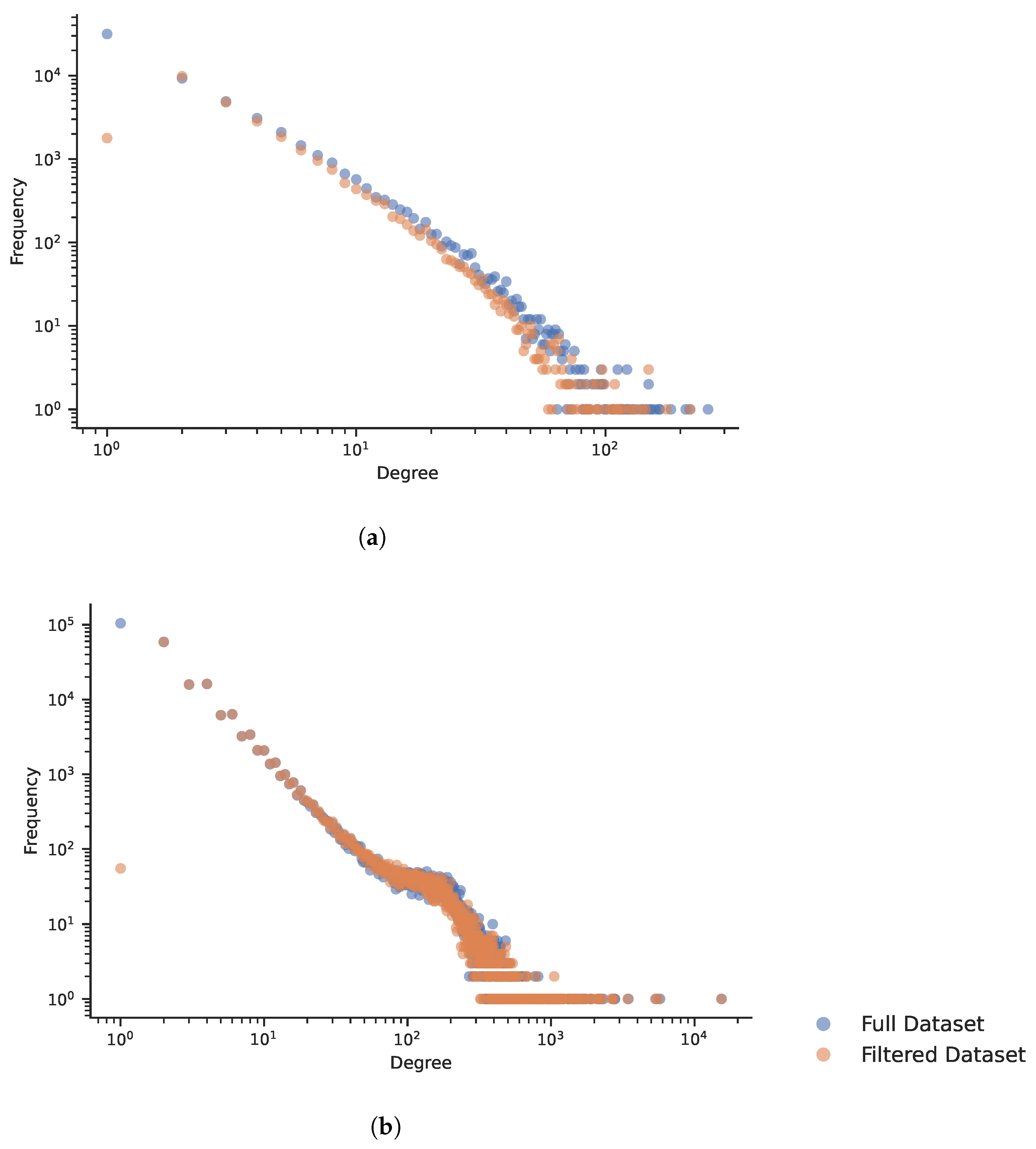
3. Dataset
4. Simulations and Results
4.1. Experiments Settings
4.2. Results
4.2.1. Experiments on Aggregation Functions
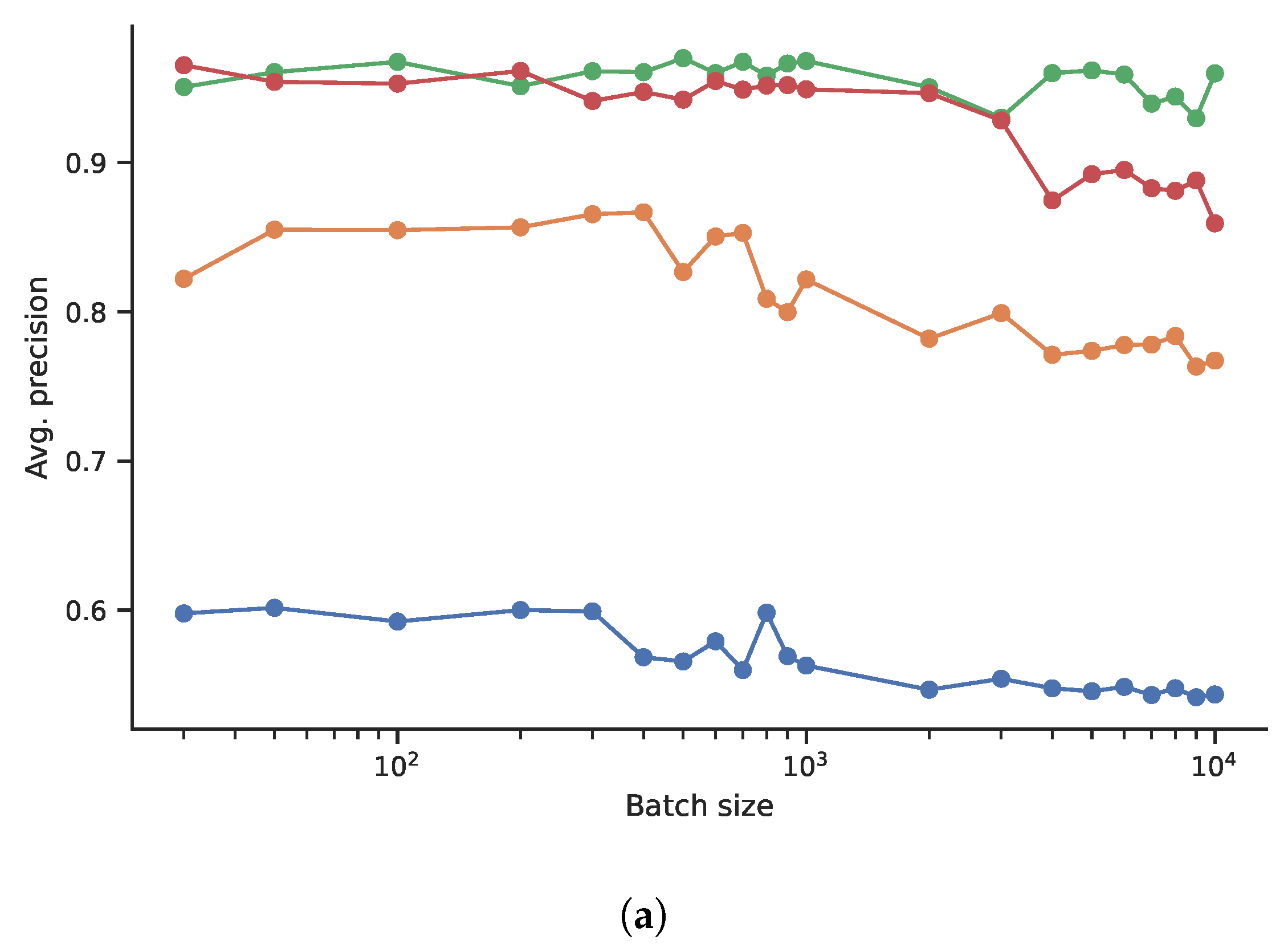
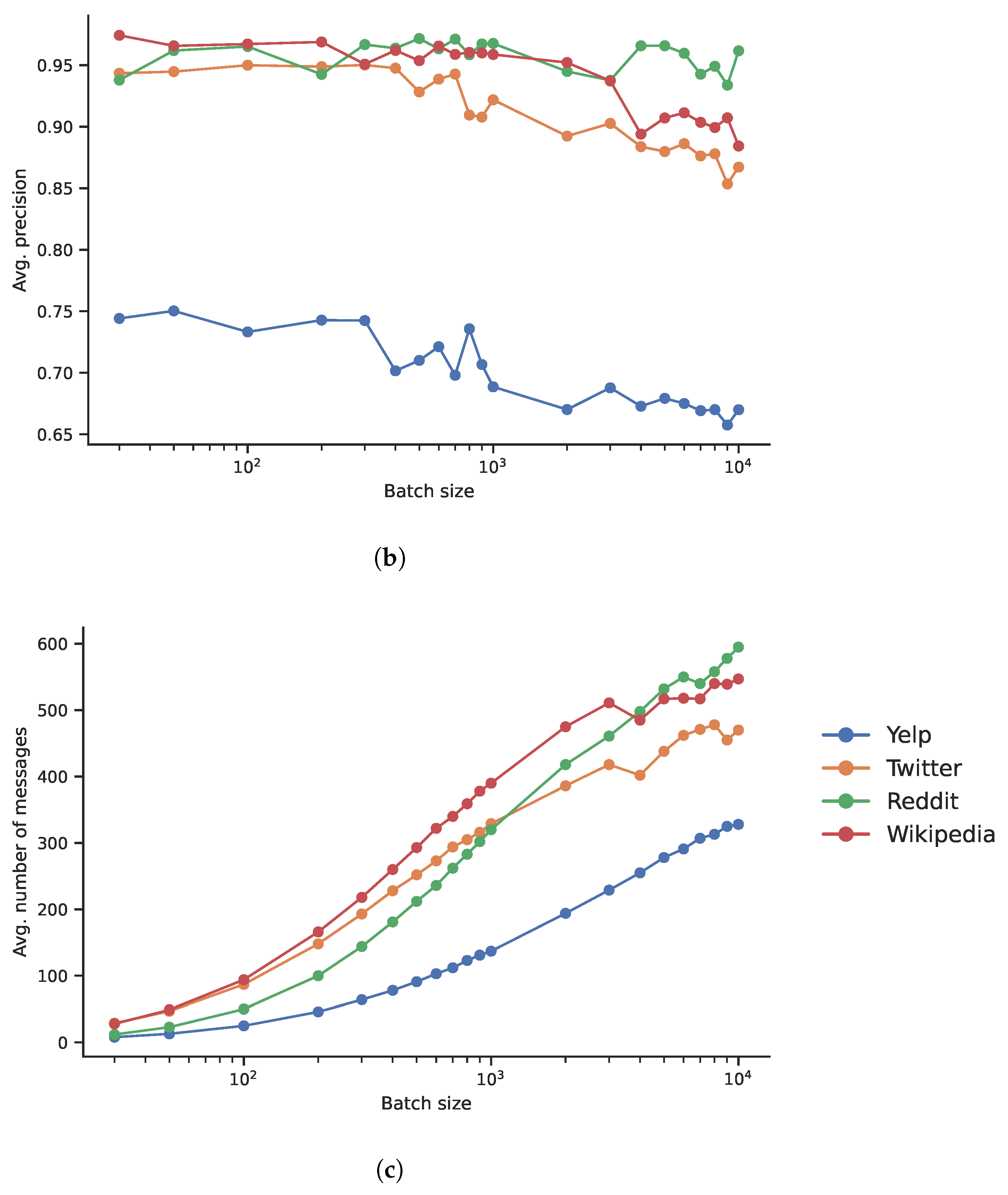
4.2.2. Experiments on Batch Size
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Linyuan, L.L.; Zhou, T. Link prediction in complex networks: A survey. Phys. A Stat. Mech. Its Appl. 2011, 390, 1150–1170. [Google Scholar]
- Biondi, G.; Franzoni, V. Discovering Correlation Indices for Link Prediction Using Differential Evolution. Mathematics 2020, 8, 2097. [Google Scholar] [CrossRef]
- Martínez, V.; Berzal, F.; Cubero, J.C. A Survey of Link Prediction in Complex Networks. ACM Comput. Surv. 2016, 49, 1–33. [Google Scholar] [CrossRef]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online Learning of Social Representations. In KDD ’14, Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 701–710. [Google Scholar] [CrossRef] [Green Version]
- Liben-Nowell, D.; Kleinberg, J. The Link Prediction Problem for Social Networks. In CIKM ’03, Proceedings of the Twelfth International Conference on Information and Knowledge Management, New Orleans, LA, USA, 3–8 November 2003; Association for Computing Machinery: New York, NY, USA, 2003; pp. 556–559. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Li, X.; Huang, Z. Link prediction approach to collaborative filtering. In Proceedings of the 5th ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL ’05), Denver, CO, USA, 7–11 June 2005; pp. 141–142. [Google Scholar] [CrossRef]
- Leskovec, J.; Mcauley, J. Learning to Discover Social Circles in Ego Networks. In Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Nice, France, 2012; Volume 25. [Google Scholar]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric Deep Learning: Going beyond Euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef] [Green Version]
- Deng, L.; Yu, D. Deep Learning: Methods and Applications. Deep Learning: Methods and Applications; Foundations and Trends in Signal Processing. Now Publishers. 2014. Available online: https://www.nowpublishers.com/ (accessed on 3 January 2022).
- Mikolov, T.; Deoras, A.; Povey, D.; Burget, L.; Černocký, J. Strategies for training large scale neural network language models. In Proceedings of the 2011 IEEE Workshop on Automatic Speech Recognition Understanding, Waikoloa, HI, USA, 11–15 December 2011; pp. 196–201. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Advances in Neural Information Processing Systems; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Nice, France, 2014; Volume 27. [Google Scholar]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; pp. 253–256. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Conneau, A.; Schwenk, H.; Barrault, L.; Lecun, Y. Very Deep Convolutional Networks for Text Classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, Valencia, Spain, 3–7 April 2017; Association for Computational Linguistics: Valencia, Spain, 2017; pp. 1107–1116. [Google Scholar]
- Wu, Y.; Lian, D.; Jin, S.; Chen, E. Graph Convolutional Networks on User Mobility Heterogeneous Graphs for Social Relationship Inference. In IJCAI’19, Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; AAAI Press: Menlo Park, CA, USA, 2019; pp. 3898–3904. [Google Scholar]
- Jin, D.; Liu, Z.; Li, W.; He, D.; Zhang, W. Graph Convolutional Networks Meet Markov Random Fields: Semi-Supervised Community Detection in Attribute Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 152–159. [Google Scholar] [CrossRef]
- Wu, Y.; Lian, D.; Xu, Y.; Wu, L.; Chen, E. Graph Convolutional Networks with Markov Random Field Reasoning for Social Spammer Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1054–1061. [Google Scholar] [CrossRef]
- Fout, A.; Byrd, J.; Shariat, B.; Ben-Hur, A. Protein Interface Prediction Using Graph Convolutional Networks. In NIPS’17, Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6533–6542. [Google Scholar]
- Xu, C.; Nayyeri, M.; Chen, Y.Y.; Lehmann, J. Knowledge Graph Embeddings in Geometric Algebras. arXiv 2021, arXiv:2010.00989. [Google Scholar]
- Hamilton, W.L. Graph Representation Learning. Synth. Lect. Artif. Intell. Mach. Learn. 2020, 14, 1–159. [Google Scholar] [CrossRef]
- Xu, D.; Ruan, C.; Korpeoglu, E.; Kumar, S.; Achan, K. Inductive representation learning on temporal graphs. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Rossi, E.; Chamberlain, B.; Frasca, F.; Eynard, D.; Monti, F.; Bronstein, M. Temporal Graph Networks for Deep Learning on Dynamic Graphs. arXiv 2020, arXiv:2006.10637. [Google Scholar]
- Monti, F.; Otness, K.; Bronstein, M.M. Motifnet: A Motif-Based Graph Convolutional Network for Directed Graphs. In Proceedings of the 2018 IEEE Data Science Workshop (DSW), Lausanne, Switzerland, 4–6 June 2018; pp. 225–228. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Cui, P.; Zhu, W. Deep Learning on Graphs: A Survey. IEEE Trans. Knowl. Data Eng. 2020, 34, 249–270. [Google Scholar] [CrossRef] [Green Version]
- Grassia, M.; De Domenico, M.; Mangioni, G. Machine learning dismantling and early-warning signals of disintegration in complex systems. Nat. Commun. 2021, 12, 5190. [Google Scholar] [CrossRef] [PubMed]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. arXiv 2018, arXiv:1710.10903. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Nice, France, 2017; Volume 30. [Google Scholar]
- Halevy, A.Y.; Canton-Ferrer, C.; Ma, H.; Ozertem, U.; Pantel, P.; Saeidi, M.; Silvestri, F.; Stoyanov, V. Preserving Integrity in Online Social Networks. arXiv 2020, arXiv:2009.10311. [Google Scholar] [CrossRef]
- Monti, F.; Frasca, F.; Eynard, D.; Mannion, D.; Bronstein, M.M. Fake News Detection on Social Media using Geometric Deep Learning. arXiv 2019, arXiv:1902.06673. [Google Scholar]
- Zhou, X.; Zafarani, R. A Survey of Fake News: Fundamental Theories, Detection Methods, and Opportunities. ACM Comput. Surv. 2020, 53, 1–40. [Google Scholar] [CrossRef]
- Carchiolo, V.; Longheu, A.; Malgeri, M.; Mangioni, G.; Previti, M. A Trust-Based News Spreading Model. In Complex Networks IX; Cornelius, S., Coronges, K., Gonçalves, B., Sinatra, R., Vespignani, A., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 303–310. [Google Scholar]
- Carchiolo, V.; Longheu, A.; Malgeri, M.; Mangioni, G.; Previti, M. Mutual influence of users credibility and news spreading in online social networks. Future Internet 2021, 13, 107. [Google Scholar] [CrossRef]
- Previti, M.; Rodriguez-Fernandez, V.; Camacho, D.; Carchiolo, V.; Malgeri, M. Fake news detection using time series and user features classification. In International Conference on the Applications of Evolutionary Computation (Part of EvoStar); Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin, Germany, 2020; Volume 12104 LNCS, pp. 339–353. [Google Scholar]
- Sano, Y.; Zhao, Z.; Zhao, J.; Levy, O.; Takayasu, H.; Takayasu, M.; Li, D.; Wu, J.; Havlin, S. Fake news propagates differently from real news even at early stages of spreading. EPJ Data Sci. 2020, 9, 7. [Google Scholar]
- Bessi, A.; Coletto, M.; Davidescu, G.A.; Scala, A.; Caldarelli, G.; Quattrociocchi, W. Science vs. Conspiracy: Collective Narratives in the Age of Misinformation. PLoS ONE 2015, 10, e0118093. [Google Scholar] [CrossRef] [Green Version]
- Baronchelli, A. The emergence of consensus: A primer. R. Soc. Open Sci. 2018, 5, 172189. [Google Scholar] [CrossRef] [Green Version]
- Vicario, M.D.; Quattrociocchi, W.; Scala, A.; Zollo, F. Polarization and Fake News: Early Warning of Potential Misinformation Targets. ACM Trans. Web 2019, 13, 1–22. [Google Scholar] [CrossRef]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef] [PubMed]
- Villalba-Diez, J.; Molina, M.; Schmidt, D. Geometric Deep Lean Learning: Evaluation Using a Twitter Social Network. Appl. Sci. 2021, 11, 6777. [Google Scholar] [CrossRef]
- Leng, Y.; Ruiz, R.; Dong, X.; Pentland, A.S. Interpretable Recommender System with Heterogeneous Information: A Geometric Deep Learning Perspective. SSRN Electron. J. 2020. [Google Scholar] [CrossRef]
- Rossi, E.; Frasca, F.; Chamberlain, B.; Eynard, D.; Bronstein, M.M.; Monti, F. SIGN: Scalable Inception Graph Neural Networks. arXiv 2020, arXiv:2004.11198. [Google Scholar]
- Kumar, S.; Zhang, X.; Leskovec, J. Predicting Dynamic Embedding Trajectory in Temporal Interaction Networks. In KDD ’19, Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1269–1278. [Google Scholar] [CrossRef]
- Pennebaker, J.W.; Francis, M.E.; Booth, R.J. Linguistic inquiry and word count: LIWC 2001. Mahway Lawrence Erlbaum Assoc. 2001, 71, 2001. [Google Scholar]
- Crossley, S.A.; Kyle, K.; McNamara, D.S. Sentiment Analysis and Social Cognition Engine (SEANCE): An automatic tool for sentiment, social cognition, and social-order analysis. Behav. Res. Methods 2017, 49, 803–821. [Google Scholar] [CrossRef] [Green Version]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Edge Features | ||||||
|---|---|---|---|---|---|---|
| Network | Type | # | Type | Timespan | ||
| Bipartite (users and posts) | 11.000 | 672.447 | 172 | LIWC | 30 days | |
| Monoplex (users) | 38.458 | 715.030 | 768 | BERT | 15 days | |
| Wikipedia | Bipartite (users and pages) | 9.227 | 157.474 | 172 | LIWC | 30 days |
| Yelp | Bipartite (users and reviews) | 29.608 | 61.522 | 21 | SEANCE | 1 year |
| Network | Last m. | Mean | Weighted Mean | MLP |
|---|---|---|---|---|
| 86.76 | 96.62 | 95.56 | 97.45 | |
| 87.16 | 87.32 | 85.69 | 86.14 | |
| Yelp | 63.43 | 63.87 | 63.51 | 62.83 |
| Wikipedia | 96.05 | 96.21 | 95.88 | 96.02 |
| Network | Last m. | Mean | Weighted Mean | MLP |
|---|---|---|---|---|
| 85.34 | 96.78 | 95.14 | 97.58 | |
| 95.62 | 95.19 | 94.70 | 94.52 | |
| Yelp | 75.34 | 75.47 | 75.82 | 74.35 |
| Wikipedia | 96.80 | 96.78 | 96.89 | 96.98 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carchiolo, V.; Cavallo, C.; Grassia, M.; Malgeri, M.; Mangioni, G. Link Prediction in Time Varying Social Networks. Information 2022, 13, 123. https://doi.org/10.3390/info13030123
Carchiolo V, Cavallo C, Grassia M, Malgeri M, Mangioni G. Link Prediction in Time Varying Social Networks. Information. 2022; 13(3):123. https://doi.org/10.3390/info13030123
Chicago/Turabian StyleCarchiolo, Vincenza, Christian Cavallo, Marco Grassia, Michele Malgeri, and Giuseppe Mangioni. 2022. "Link Prediction in Time Varying Social Networks" Information 13, no. 3: 123. https://doi.org/10.3390/info13030123
APA StyleCarchiolo, V., Cavallo, C., Grassia, M., Malgeri, M., & Mangioni, G. (2022). Link Prediction in Time Varying Social Networks. Information, 13(3), 123. https://doi.org/10.3390/info13030123