
Inferring Spatial Distance Rankings with Partial Knowledge on Routing Networks


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
2.1. Our Contribution
- A weighted directed graph with vertices V, arcs , and a cost function , and
- A set of target vertices ,
- Input: Query vertex ;
- Output: List L of all target vertices sorted with respect to the shortest distances from s, i.e.,
- ,
- , and
- for all ,
- where is the quasimetric induced by the cost function c.
2.2. Structure of the Paper
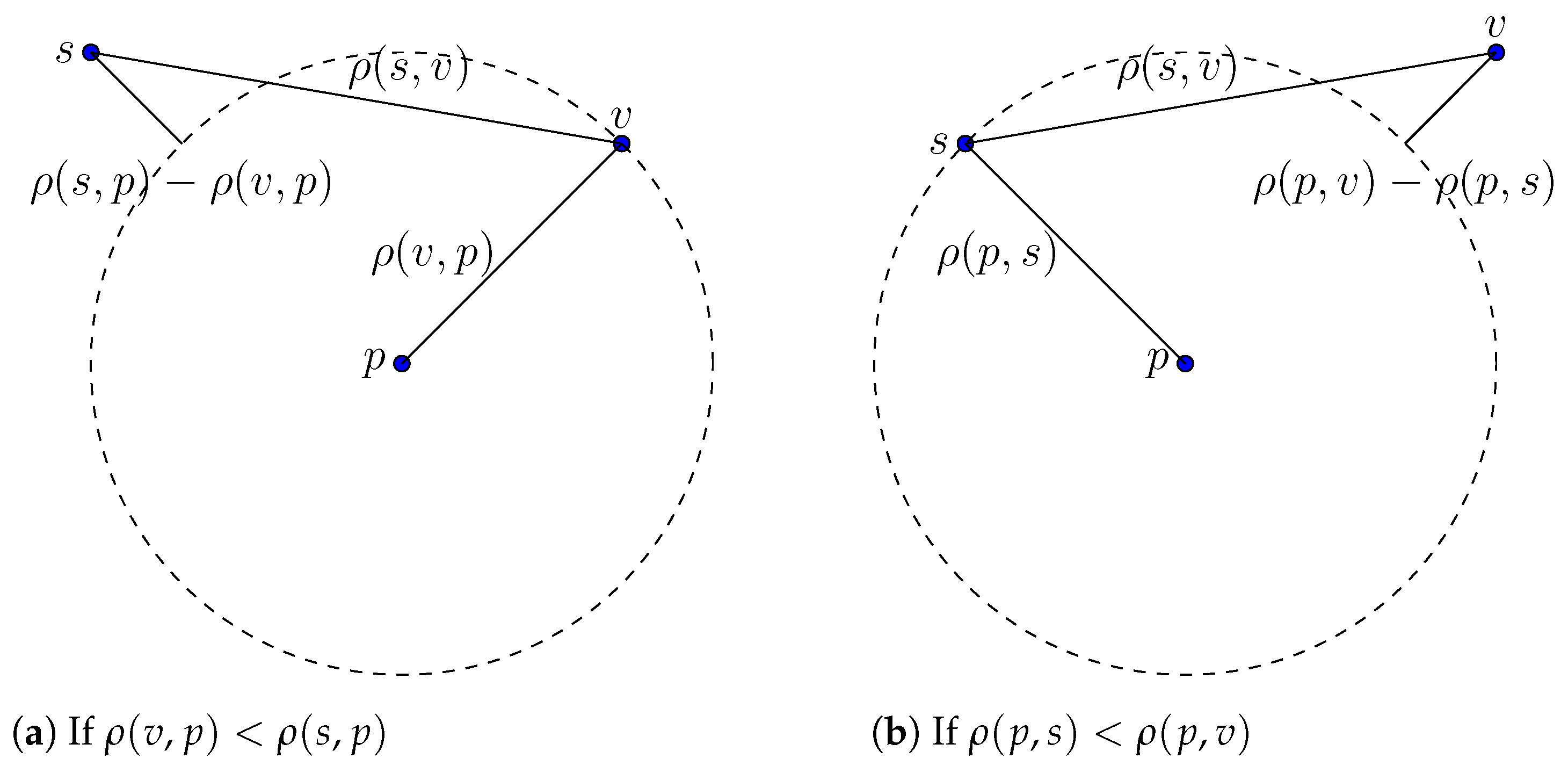
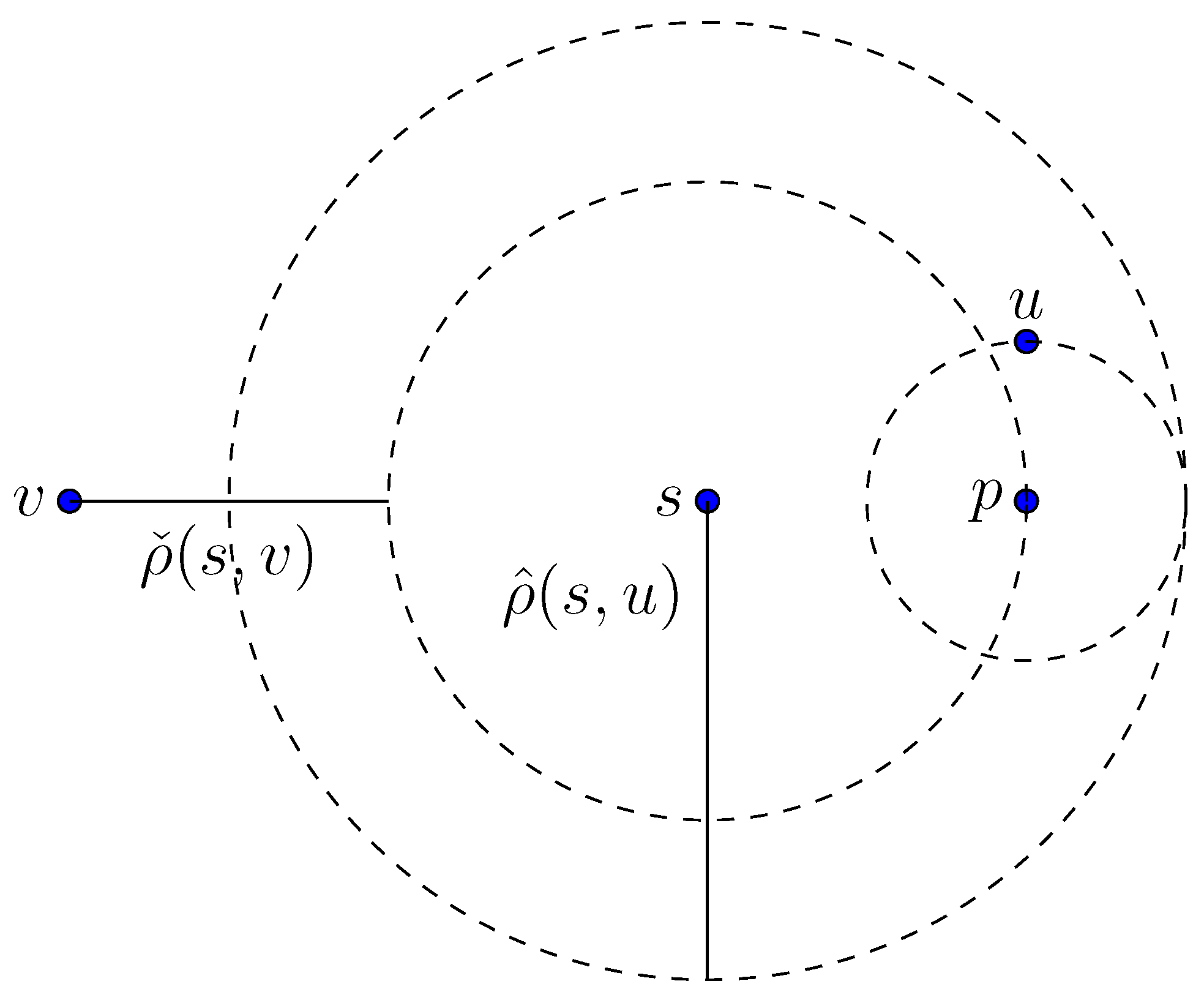
3. Properties of Quasimetric Spaces
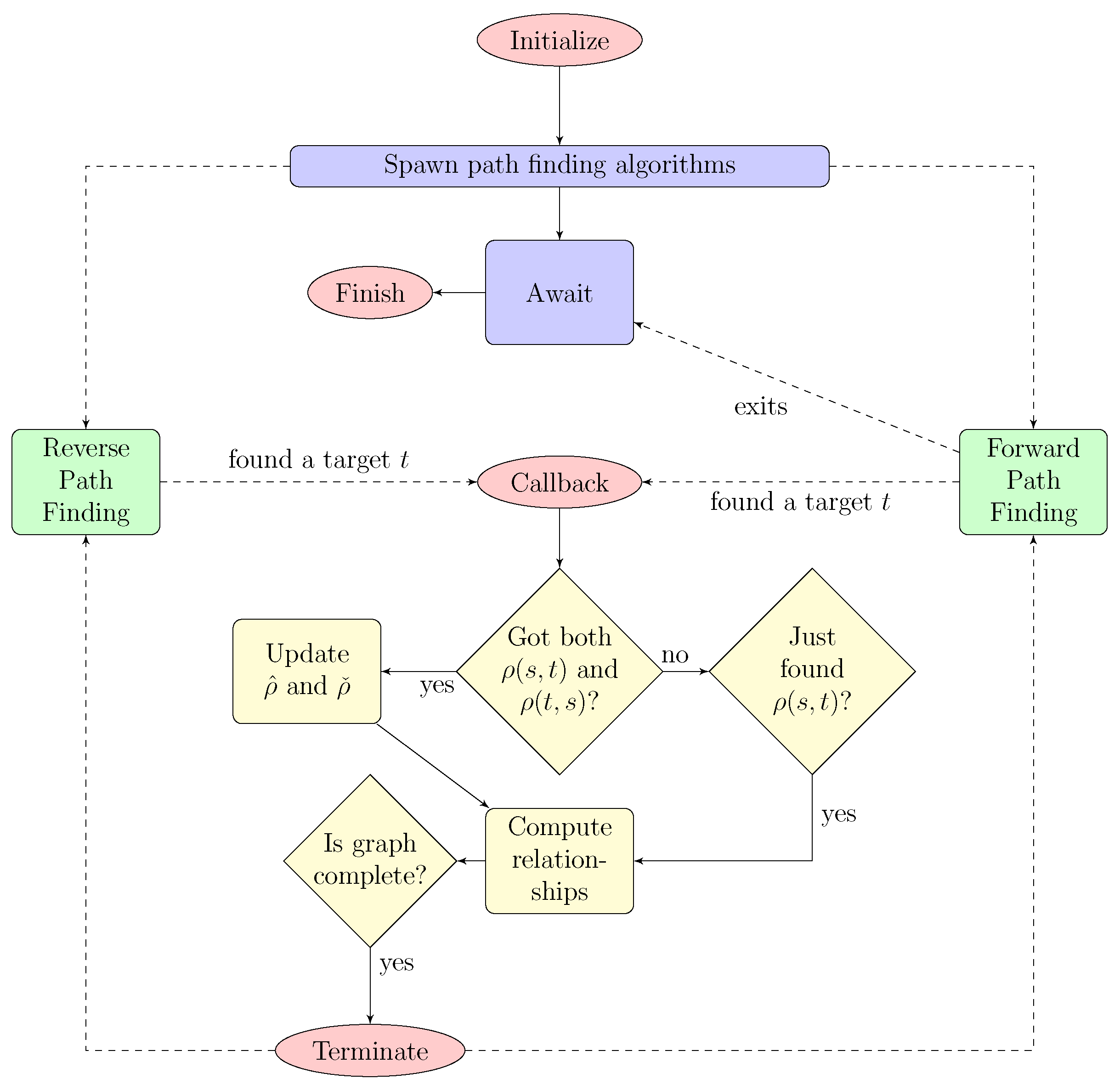
4. Routing Networks
- From , we get the non-negativity of .
- As for all walks from u to , we yield by definition for all . As for each , we can conclude that for each . Thus, we yield the positive definiteness of .
- If we define the concatenation of walks bytriangle inequality is simple to show: For arbitrary , let be a simple path from u to v, and be a simple path from v to w. Then, we can generate a walk by combining both paths, so we have . Applying the infimum over all walks from u to w yields the triangle inequality.
| Algorithm 1 An implementation on quasimetric networks |
 |
| Algorithm 2 Complete the ranking that is represented by both graphs |
 |
Possible Extensions
5. Time-Dependent Routing Networks
- If we can pre-compute and store values of routing distances, we can create the quasimetric network with a new function . Then, the induced quasimetric is a lower bound of for all .
- If measures the time it takes for an object o to get from to when starting at time t, then there exists some mapping with so that measures the distance from u to w. If we know the maximum speed of o while moving from u to w, we can take as a time-independent lower bounding metric.
- for every where is a class of functions for which is closed under composition and the evaluation of a function of is reasonably fast.
- It is possible to divide I into disjoint intervals
- For all exist some functions such that for every , we have for all .
- The values of c are discrete, i.e., is a step function for all . Then, is a step function for all (as V is finite). We can conclude that we can find a partition such that for every , we have for all . Hence, we can define as constant functions for all .
- The class of polynomial splines is closed under composition and can be factorized after composition for optimized evaluations.
6. Evaluation
6.1. Statistics
6.2. Design and Overview
- 1.
- Choose a fixed function at the beginning of A*; or
- 2.
- Update the heuristic whenever another specific target vertex is found. Updating means reevaluating the heuristic estimate for each vertex that is currently in the open front. This takes time and shows that Dijkstra is faster in situations where the target vertices are arbitrarily distributed on the network.
6.3. Implementation
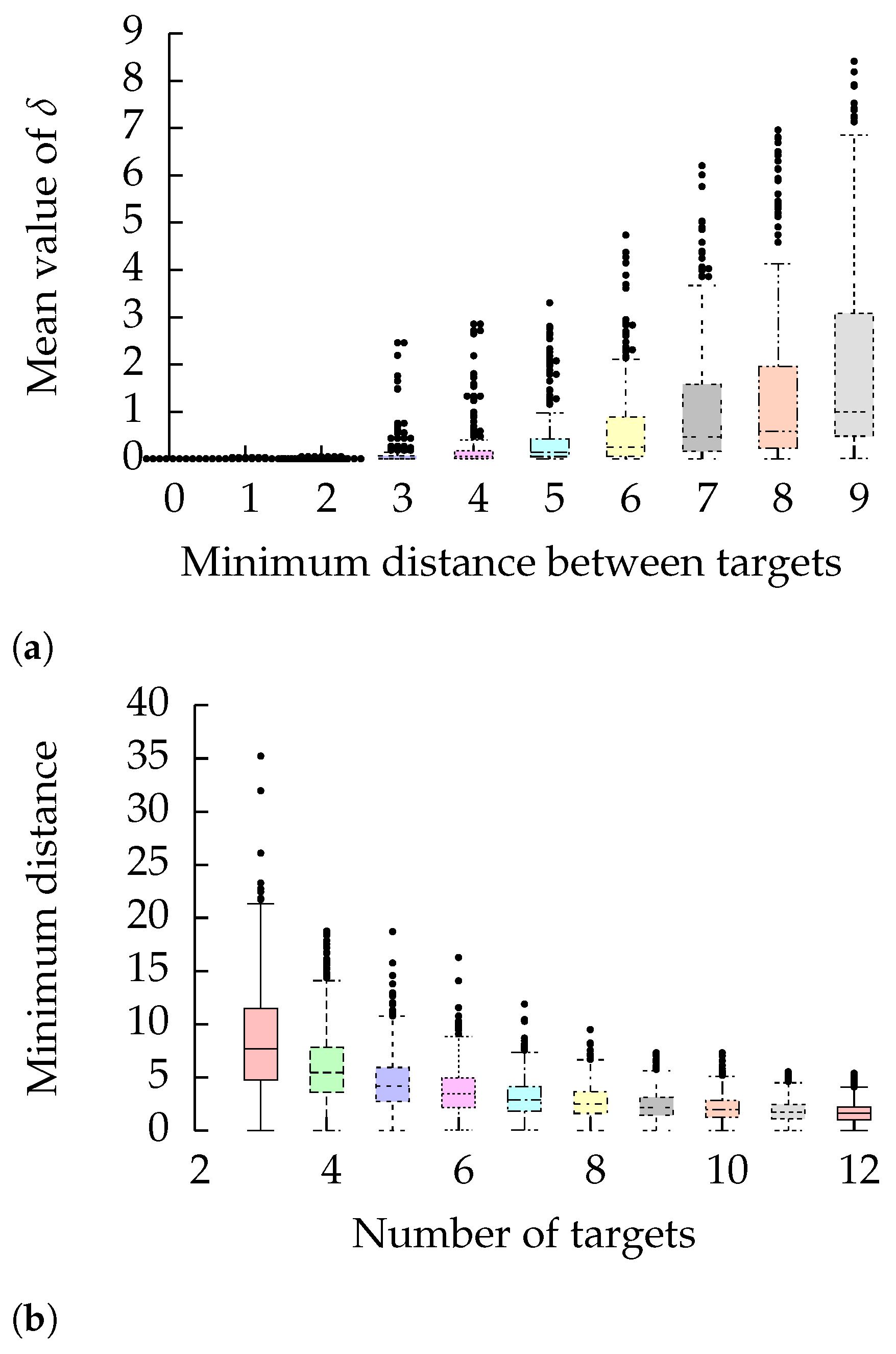
6.4. Experimental Results
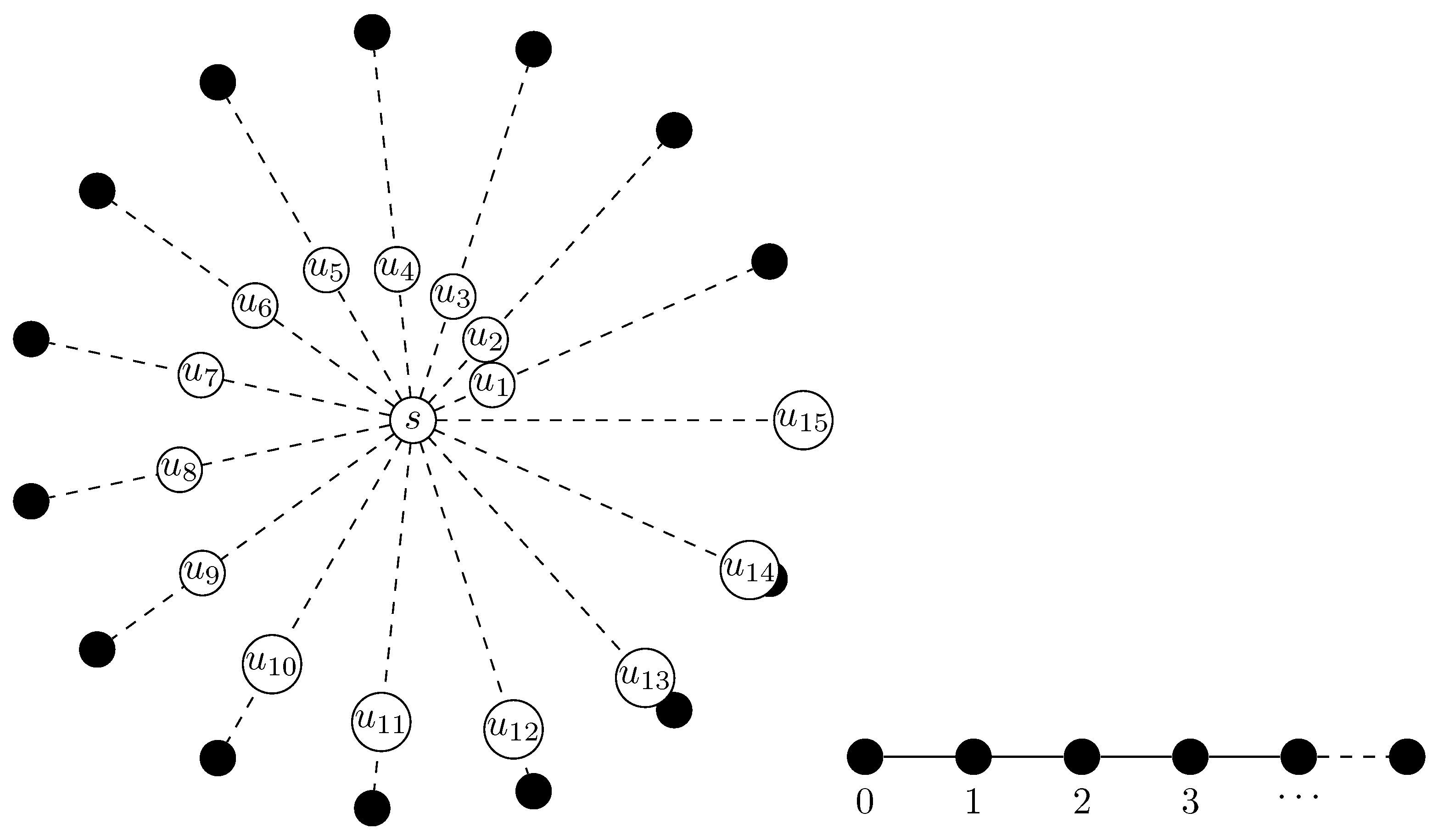
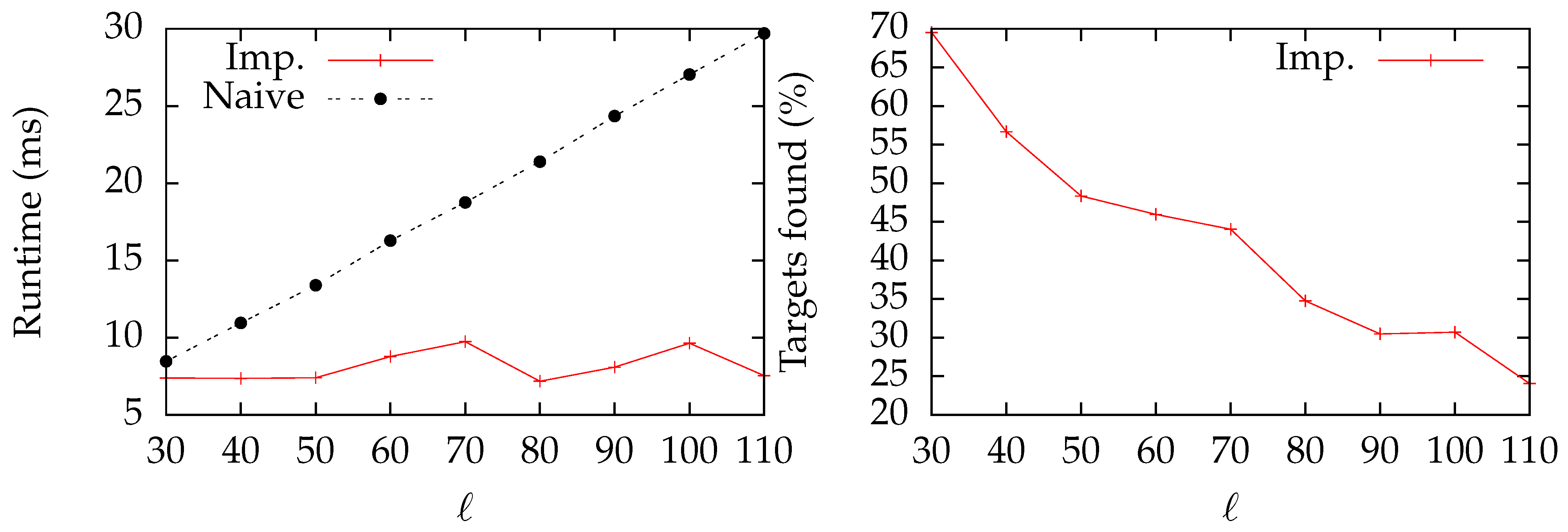
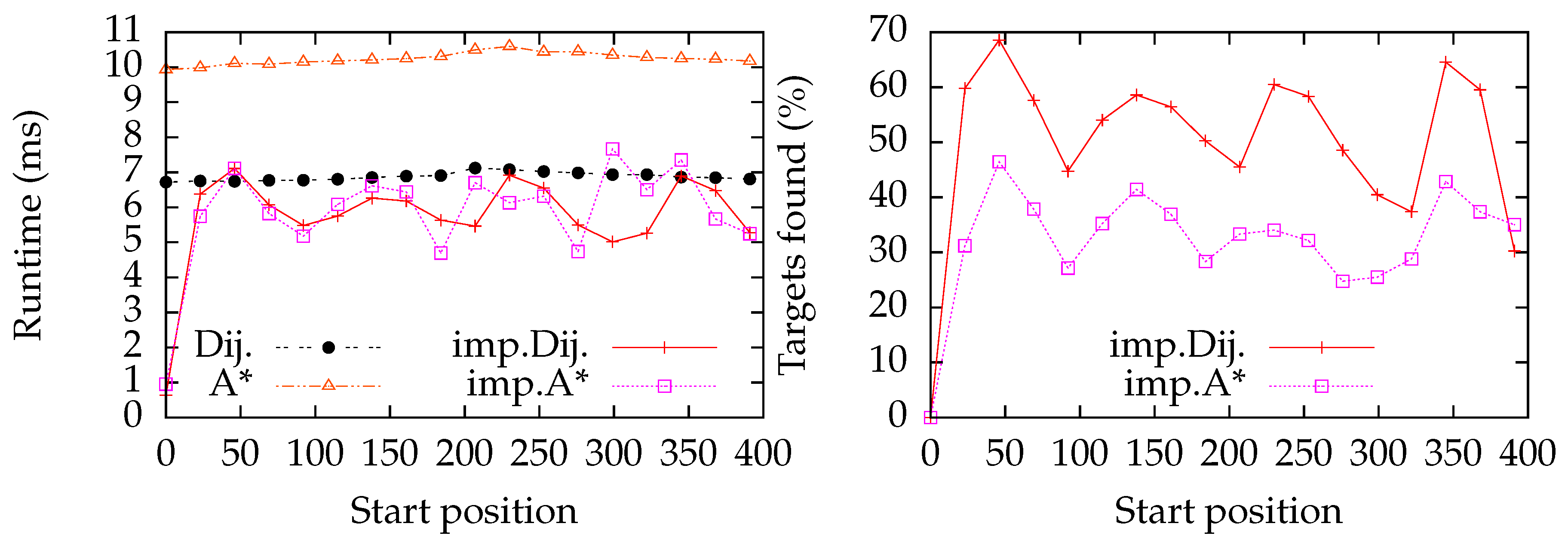
6.4.1. Star Graph
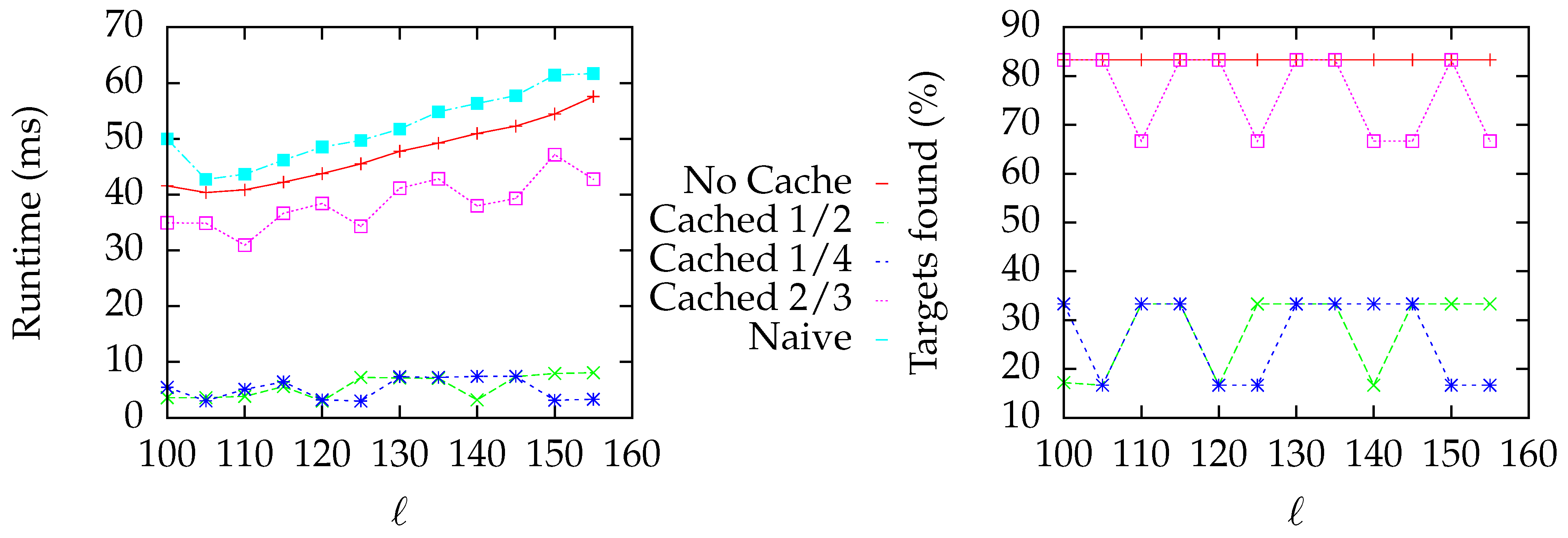
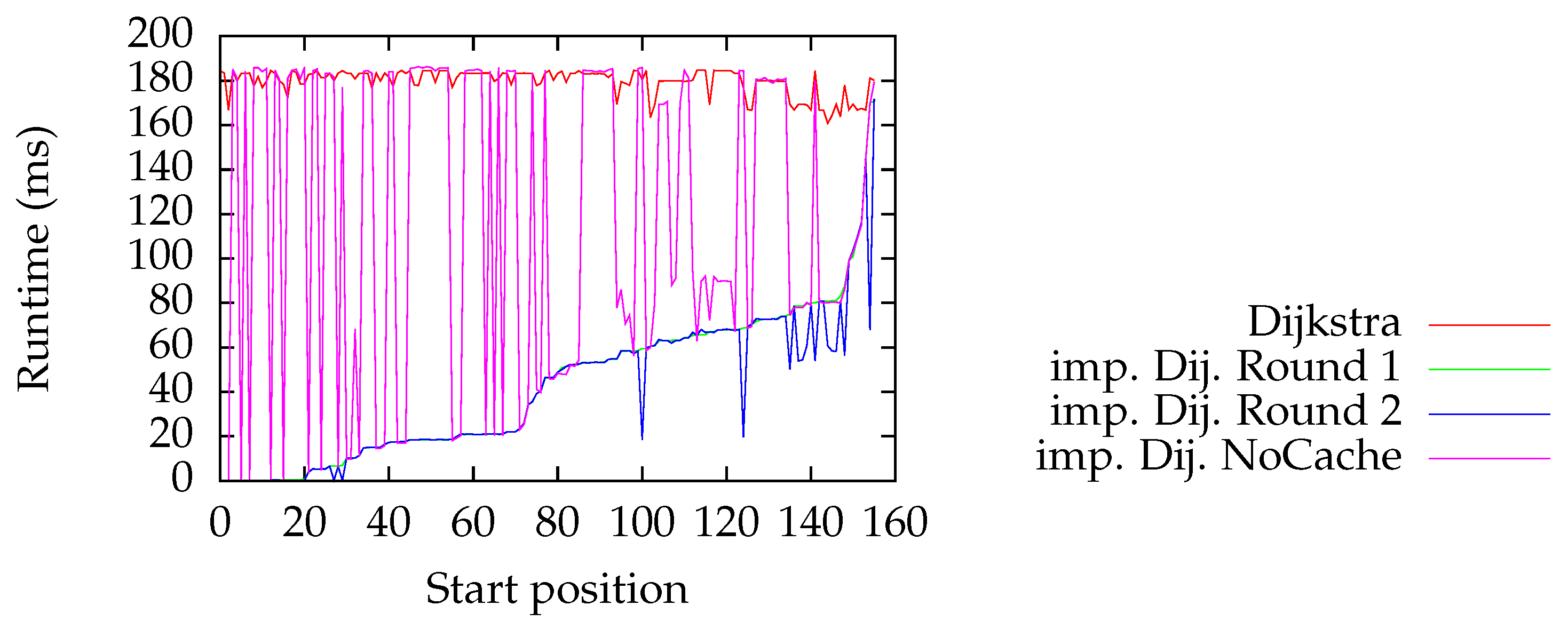
6.4.2. Line Graph
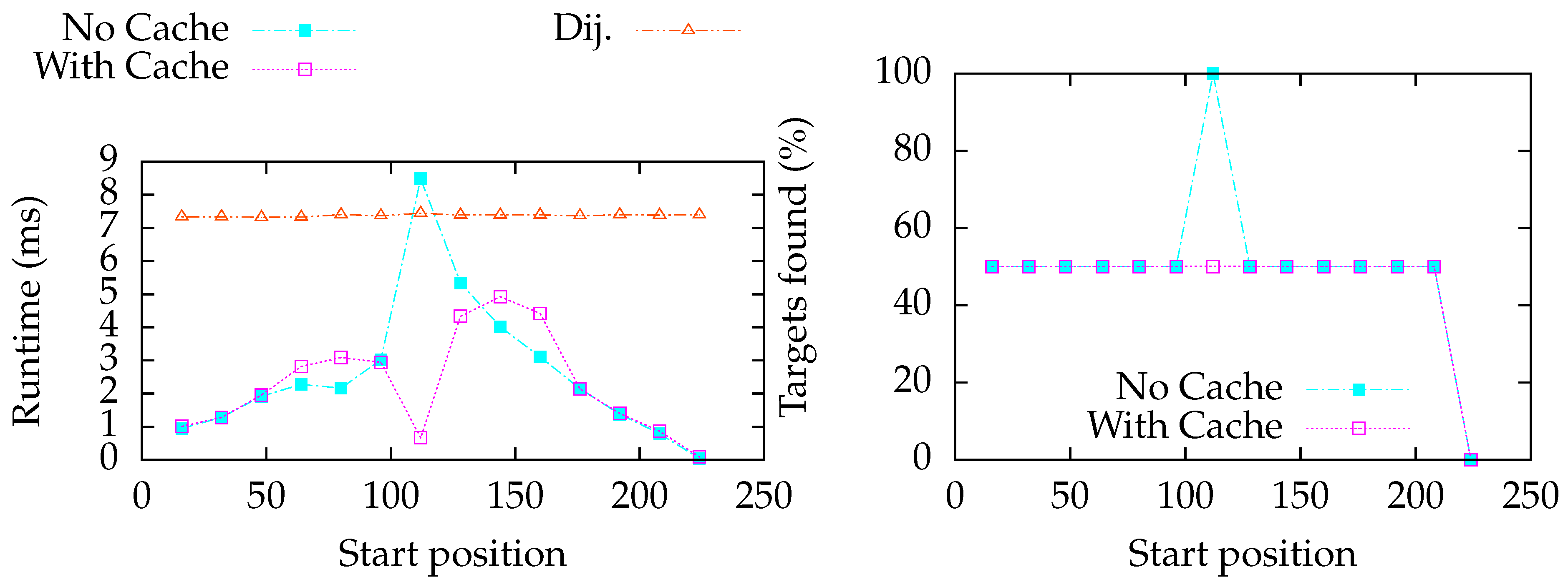
6.4.3. Show Case: City of Munich
7. Discussion
7.1. Star Graph
7.2. Line Graph
7.3. Show Case
8. Conclusions and Future Work
8.1. Theoretical Conclusions
8.2. Practical Conclusions
8.3. Future Work
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wenzel, F.; Köppl, D.; Kießling, W. Interactive Toolbox for Spatial-Textual Preference Queries. In Proceedings of the Spatial and Temporal Databases (SSTD), Munich, Germany, 21–23 August 2013; pp. 462–466. [Google Scholar]
- Mukai, T.; Ikeda, Y. Optimizing travel routes using temporal networks constructed from GPS data. arXiv 2021, arXiv:2106.00328. [Google Scholar]
- Huynh, N.; Barthelemy, J. A comparative study of topological analysis and temporal network analysis of a public transport system. Int. J. Transp. Sci. Technol. 2021. [Google Scholar] [CrossRef]
- Baum, M.; Dibbelt, J.; Gemsa, A.; Wagner, D. Towards route planning algorithms for electric vehicles with realistic constraints. Comput. Sci. Res. Dev. 2016, 31, 105–109. [Google Scholar] [CrossRef]
- Zheng, B.; Lee, K.C.K.; Lee, W.C. Location-Dependent Skyline Query. In Proceedings of the Ninth International Conference on Mobile Data Management (MDM 2008), Beijing, China, 27–30 April 2008; Meng, X., Lei, H., Grumbach, S., Leong, H.V., Eds.; IEEE: Piscataway, NJ, USA, 2008; pp. 148–155. [Google Scholar]
- Sharifzadeh, M.; Shahabi, C. The Spatial Skyline Queries. In Proceedings of the 32nd international conference on Very large data bases, Seoul, Korea, 12–15 September 2006. [Google Scholar]
- Graf, F.; Kriegel, H.P.; Renz, M.; Schubert, M. MARiO: Multi-Attribute Routing in Open Street Map. In Proceedings of the 12th International Symposium on Spatial and Temporal Databases, Minneapolis, MN, USA, 24–26 August 2011; pp. 486–490. [Google Scholar]
- Köppl, D. Breaking Skyline Computation down to the Metal - the Skyline Breaker Algorithm. In Proceedings of the 17th International Database Engineering & Applications Symposium, New York, NY, USA, 9–13 October 2013. [Google Scholar] [CrossRef]
- Börzsönyi, S.; Kossmann, D.; Stocker, K. The Skyline Operator. In Proceedings of the 17th International Conference on Data Engineering, Heidelberg, Germany, 2–6 April 2001; IEEE Computer Society: Washington, DC, USA, 2001; pp. 421–430. [Google Scholar]
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef] [Green Version]
- Fredman, M.L.; Tarjan, R.E. Fibonacci Heaps and Their Uses in Improved Network Optimization Algorithms. J. Acm (JACM) 1987, 34, 596–615. [Google Scholar] [CrossRef]
- Akiba, T.; Iwata, Y.; Yoshida, Y. Fast Exact Shortest-Path Distance Queries on Large Networks by Pruned Landmark Labeling. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013. [Google Scholar]
- Goldberg, A.V. Point-to-Point Shortest Path Algorithms with Preprocessing. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.84.8179&rep=rep1&type=pdf (accessed on 19 December 2021).
- Delling, D.; Sanders, P.; Schultes, D.; Wagner, D. Engineering Route Planning Algorithms. Available online: nozdr.ru/data/media/biblio/kolxoz/Cs/CsLn/Algorithmics%20of%20Large%20and%20Complex%20Networks%20(LNCS5515,%2440Springer,%202009)(ISBN%209783642020933)(410s).pdf#page=126 (accessed on 19 December 2021).
- Delling, D.; Werneck, R.F. Faster Customization of Road Networks. In Experimental Algorithms; Bonifaci, V., Demetrescu, C., Marchetti-Spaccamela, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7933, pp. 30–42. [Google Scholar] [CrossRef]
- Abraham, I.; Delling, D.; Fiat, A.; Goldberg, A.V.; Werneck, R.F. Highway Dimension and Provably Efficient Shortest Path Algorithms. J. ACM 2016, 63, 1–26. [Google Scholar] [CrossRef]
- Gutman, R.J. Reach-Based Routing: A New Approach to Shortest Path Algorithms Optimized for Road Networks. In Proceedings of the Sixth Workshop on Algorithm Engineering and Experiments and the First Workshop on Analytic Algorithmics and Combinatorics (ALENEX/ANALC), New Orleans, LA, USA, 10 January 2004. [Google Scholar]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Geisberger, R.; Sanders, P.; Schultes, D.; Delling, D. Contraction Hierarchies: Faster and Simpler Hierarchical Routing in Road Networks. In Proceedings of the 7th International Workshop (WEA 2008), Provincetown, MA, USA, 30 May–1 June 2008; pp. 319–333. [Google Scholar]
- Dibbelt, J.; Strasser, B.; Wagner, D. Customizable Contraction Hierarchies. ACM J. Exp. Algorithmics 2016, 21, 1.5:1–1.5:49. [Google Scholar] [CrossRef] [Green Version]
- Gottesbüren, L.; Hamann, M.; Uhl, T.N.; Wagner, D. Faster and Better Nested Dissection Orders for Customizable Contraction Hierarchies. Algorithms 2019, 12, 196. [Google Scholar] [CrossRef] [Green Version]
- Strasser, B.; Wagner, D.; Zeitz, T. Space-Efficient, Fast and Exact Routing in Time-Dependent Road Networks. Algorithms 2021, 14, 90. [Google Scholar] [CrossRef]
- Abraham, I.; Delling, D.; Goldberg, A.V.; Werneck, R.F.F. Hierarchical Hub Labelings for Shortest Paths. In Proceedings of the 20th Annual European Symposium, Ljubljana, Slovenia, 10–12 September 2012; pp. 24–35. [Google Scholar] [CrossRef]
- Kosowski, A.; Uznanski, P.; Viennot, L. Hardness of Exact Distance Queries in Sparse Graphs Through Hub Labeling. In Proceedings of the 2019 ACM Symposium on Principles of Distributed Computing, Toronto, ON, Canada, 29 July–2 August 2019; pp. 272–279. [Google Scholar] [CrossRef] [Green Version]
- Delling, D.; Goldberg, A.V.; Werneck, R.F. Hub Label Compression. Available online: citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.800.3597&rep=rep1&type=pdf#page=29 (accessed on 19 December 2021). [CrossRef]
- Funke, S. Seamless Interpolation Between Contraction Hierarchies and Hub Labels for Fast and Space-Efficient Shortest Path Queries in Road Networks. In Proceedings of the 14th International Conference, COCOON 2008, Dalian, China, 27–29 June 2008; pp. 123–135. [Google Scholar] [CrossRef]
- Rupp, T.; Funke, S. A Lower Bound for the Query Phase of Contraction Hierarchies and Hub Labels and a Provably Optimal Instance-Based Schema. Algorithms 2021, 14, 164. [Google Scholar] [CrossRef]
- Bast, H.; Delling, D.; Goldberg, A.V.; Müller-Hannemann, M.; Pajor, T.; Sanders, P.; Wagner, D.; Werneck, R.F. Route Planning in Transportation Networks. Available online: https://arxiv.org/pdf/1504.05140.pdf?ref=https://githubhelp.com (accessed on 19 December 2021). [CrossRef] [Green Version]
- Thorup, M.; Zwick, U. Approximate Distance Oracles. Available online: https://dl.acm.org/doi/pdf/10.1145/1044731.1044732?casa_token=xXJDcgBRiycAAAAA:77gPtAkmH0uB42ePXmFUicFz54yRHN1EccNgTa3hyrtPUUYIRBSsgP7RvPhJDwzwQHOXhmHeFIm7Fw (accessed on 19 December 2021).
- Charalampopoulos, P.; Gawrychowski, P.; Mozes, S.; Weimann, O. Almost optimal distance oracles for planar graphs. In Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, Phoenix, AZ, USA, 23–26 June 2019; pp. 138–151. [Google Scholar] [CrossRef] [Green Version]
- Long, Y.; Pettie, S. Planar Distance Oracles with Better Time-Space Tradeoffs. In Proceedings of the 2021 ACM-SIAM Symposium on Discrete Algorithms (SODA), Virtual Conference, 10–13 January 2021; pp. 2517–2537. [Google Scholar] [CrossRef]
- Deng, K.; Zhou, X.; Shen, H.T. Multi-source Skyline Query Processing in Road Networks. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007; IEEE Computer Society: Piscataway, NJ, USA, 2007; pp. 796–805. [Google Scholar]
- Dibbelt, J.M. Engineering Algorithms for Route Planning in Multimodal Transportation Networks. Ph.D. Thesis, Karlsruhe Institute of Technology, Karlsruhe, Germany, 2016. [Google Scholar]
- Skopal, T. Unified framework for fast exact and approximate search in dissimilarity spaces. ACM Trans. Database Syst. 2007, 32, 29. [Google Scholar] [CrossRef] [Green Version]
- Mennucci, A.C.G. On Asymmetric Distances; Technical Report; Scuola Normale Superiore: Pisa, Italy, 2004. [Google Scholar]
- Hetland, M.L. The Basic Principles of Metric Indexing. In Swarm Intelligence for Multi-Objective Problems in Data Mining; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar] [CrossRef] [Green Version]
- Samet, H. Foundations of Multidimensional and Metric Data Structures (The Morgan Kaufmann Series in Computer Graphics and Geometric Modeling); Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2005. [Google Scholar]
- Bondy, J.A.; Murty, U.S.R. Graph Theory with Applications; Elsevier: New York, NY, USA, 1976. [Google Scholar]
- Goldberg, A.V.; Harrelson, C. Computing the shortest path: A search meets graph theory. In Proceedings of the sixteenth annual ACM-SIAM symposium on Discrete algorithms, Vancouver, BC, Canada, 23–25 January 2005; pp. 156–165. [Google Scholar]
- Zhang, J.; Zhu, M.; Papadias, D.; Tao, Y.; Lee, D.L. Location-based Spatial Queries. In Proceedings of the 2003 ACM SIGMOD international conference on Management of data, San Diego, CA, USA, 9–12 June 2003; pp. 443–454. [Google Scholar]
- Shekhar, S.; Huang, Y. Discovering Spatial Co-location Patterns: A Summary of Results. In Proceedings of the 7th International Symposium on Spatial and Temporal Databases (SSTD01), Redondo Beach, CA, USA, 12–15 July 2001. [Google Scholar]
- Demiryurek, U.; Kashani, F.B.; Shahabi, C. A case for time-dependent shortest path computation in spatial networks. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 474–477. [Google Scholar]
- Dreyfus, S.E. An Appraisal of Some Shortest-Path Algorithms. Oper. Res. 1969, 17, 395–412. [Google Scholar] [CrossRef]
- Chabini, I.; Lan, S. Adaptations of the A* algorithm for the computation of fastest paths in deterministic discrete-time dynamic networks. IEEE Trans. Intell. Transp. Syst. 2002, 3, 60–74. [Google Scholar] [CrossRef] [Green Version]
- Nannicini, G.; Delling, D.; Liberti, L.; Schultes, D. Bidirectional A* Search for Time-Dependent Fast Paths. In Proceedings of the 7th International Workshop (WEA 2008), Provincetown, MA, USA, 30 May–1 June 2008. [Google Scholar]
- Delling, D.; Nannicini, G. Bidirectional Core-Based Routing in Dynamic Time-Dependent Road Networks. In Proceedings of the Algorithms and Computation, 19th International Symposium, ISAAC 2008, Gold Coast, Australia, 15–17 December 2008. [Google Scholar]
- Strasser, B. Dynamic Time-Dependent Routing in Road Networks through Sampling. Available online: https://drops.dagstuhl.de/opus/volltexte/2017/7897/pdf/OASIcs-ATMOS-2017-3.pdf (accessed on 19 December 2021).
- Strasser, B.; Zeitz, T. A Fast and Tight Heuristic for A* in Road Networks. arXiv 2019, arXiv:1910.12526. [Google Scholar]
- George, B.; Kim, S.; Shekhar, S. Spatio-temporal Network Databases and Routing Algorithms: A Summary of Results. In Proceedings of the 10th International Symposium, SSTD 2007, Boston, MA, USA, 16–18 July 2007. [Google Scholar]
- Zhao, L.; Li, Z.; Li, J.; Al-Dubai, A.Y.; Min, G.; Zomaya, A.Y. A Temporal-Information-Based Adaptive Routing Algorithm for Software Defined Vehicular Networks. In Proceedings of the ICC 2019–2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Tang, Y.; Zhang, Y.; Chen, H. A parallel shortest path algorithm based on graph-partitioning and iterative correcting. Comput. Syst. Sci. Eng. 2009, 24, 155–161. [Google Scholar]
- Rios, L.H.O.; Chaimowicz, L. PNBA*: A Parallel Bidirectional Heuristic Search Algorithm. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.278.6241&rep=rep1&type=pdf (accessed on 19 December 2021).
- Rodriguez, M.A.; Neubauer, P. The Graph Traversal Pattern. arXiv 2010, arXiv:1004.1001. [Google Scholar]
- Vicknair, C.; Macias, M.; Zhao, Z.; Nan, X.; Chen, Y.; Wilkins, D. A Comparison of a Graph Database and a Relational Database: A Data Provenance Perspective. In Proceedings of the 48th Annual Southeast Regional Conference (ACM SE’10), Oxford, MI, USA, 15–17 April 2010. [Google Scholar] [CrossRef]
- Macko, P.; Margo, D.; Seltzer, M. Performance Introspection of Graph Databases. In Proceedings of the 6th International Systems and Storage Conference (SYSTOR’13), Haifa, Israel, 30 June–2 July 2013. [Google Scholar] [CrossRef] [Green Version]
- Welc, A.; Raman, R.; Wu, Z.; Hong, S.; Chafi, H.; Banerjee, J. Graph Analysis: Do We Have to Reinvent the Wheel? In Proceedings of the First International Workshop on Graph Data Management Experiences and Systems (GRADES’13), New York, NY, USA, 23 June 2013. [Google Scholar] [CrossRef]
- Martínez-Bazan, N.; Aguila-Lorente, M.A.; Muntés-Mulero, V.; Dominguez-Sal, D.; Gómez-Villamor, S.; Larriba-Pey, J.L. Efficient Graph Management Based on Bitmap Indices. Available online: https://dl.acm.org/doi/pdf/10.1145/2351476.2351489?casa_token=F08ObS4XpRYAAAAA:QZRy1DRxUWfXQmQVjTsUXSNoDeDz9lVwRVd3He-doDp4xImiNLDuAaacX8vw78NkX1wkqU_jnTAohQ (accessed on 19 December 2021).
- Hickey, R. The Clojure Programming Language. In Proceedings of the 2008 Symposium on Dynamic Languages (DLS’08), Paphos, Cyprus, 8 July 2008. [Google Scholar] [CrossRef]
- Machkasova, E.; Adams, S.J.; Einertson, J. Steps towards teaching the Clojure programming language in an introductory CS class. In Proceedings of the Second Workshop on Trends in Functional Programming In Education (TFPIE 2013), Provo, UT, USA, 13 May 2013. [Google Scholar]
- Kraus, J.M.; Kestler, H.A. Multi-core Parallelization in Clojure: A Case Study. In Proceedings of the 6th European Lisp Workshop (ELW’09), Genova, Italy, 6–10 July 2009; pp. 8–17. [Google Scholar] [CrossRef]
- Shavit, N.; Touitou, D. Software Transactional Memory. Distrib. Comput. 1997, 10, 99–116. [Google Scholar] [CrossRef]
- Härder, T.; Reuter, A. Principles of Transaction-Oriented Database Recovery. ACM Comput. Surv. 1983, 15, 287–317. [Google Scholar] [CrossRef]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Köppl, D. Inferring Spatial Distance Rankings with Partial Knowledge on Routing Networks. Information 2022, 13, 168. https://doi.org/10.3390/info13040168
Köppl D. Inferring Spatial Distance Rankings with Partial Knowledge on Routing Networks. Information. 2022; 13(4):168. https://doi.org/10.3390/info13040168
Chicago/Turabian StyleKöppl, Dominik. 2022. "Inferring Spatial Distance Rankings with Partial Knowledge on Routing Networks" Information 13, no. 4: 168. https://doi.org/10.3390/info13040168
APA StyleKöppl, D. (2022). Inferring Spatial Distance Rankings with Partial Knowledge on Routing Networks. Information, 13(4), 168. https://doi.org/10.3390/info13040168