
Identifying Adverse Drug Reaction-Related Text from Social Media: A Multi-View Active Learning Approach with Various Document Representations

Abstract
:1. Introduction
2. Related Work
2.1. Identifying Adverse Drug Reactions from Social Media
2.2. Multi-View Active Learning
2.3. Research Gap
3. The Multi-View Active Learning Approach for ADR-Related Social Media Text Identification
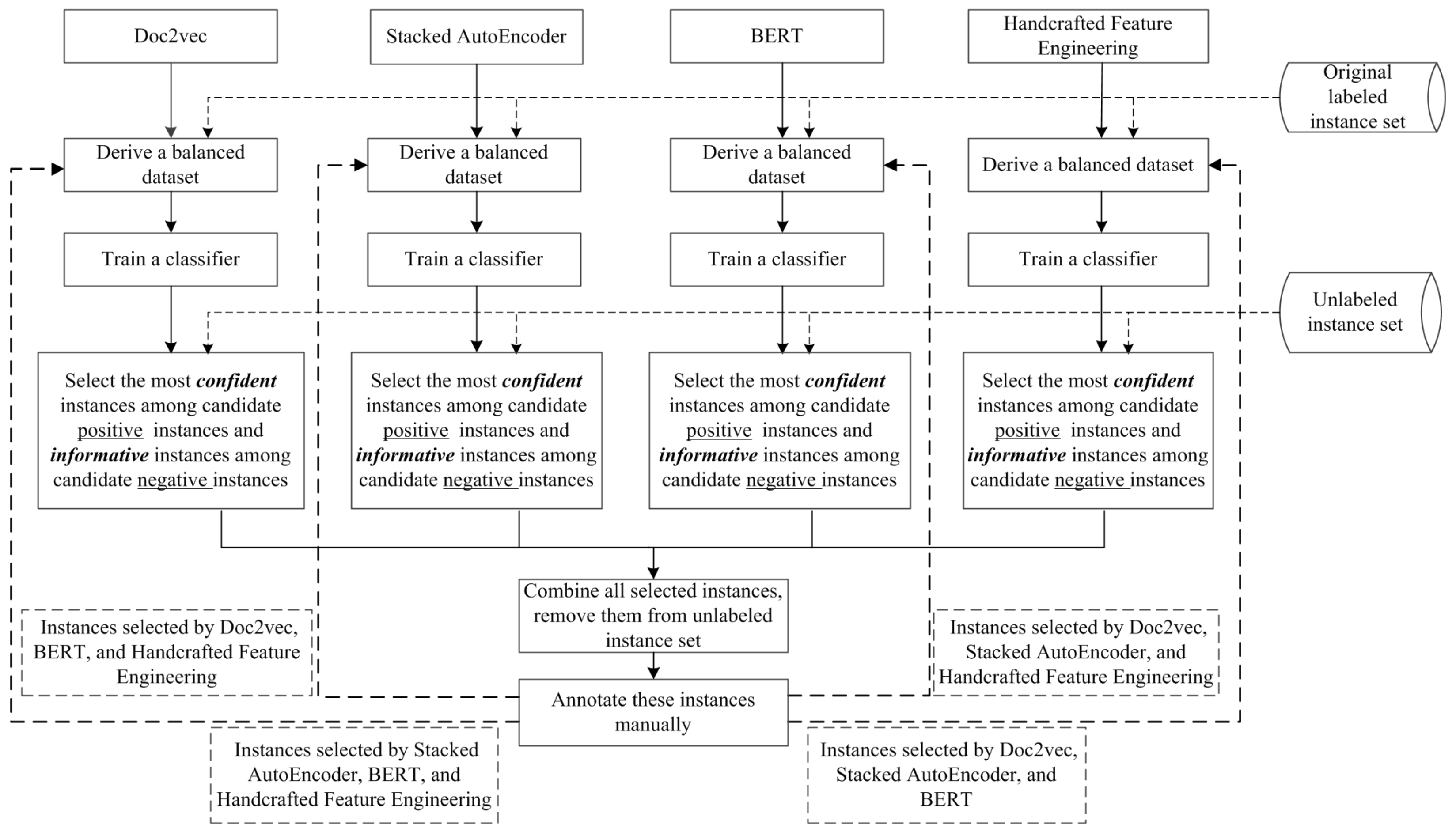
3.1. Framework of the Proposed Approach
3.1.1. Document Representation
3.1.2. Selection Strategy in the Proposed Approach
3.1.3. Augmentation Strategy in the Proposed Approach
3.2. View-Generation Mechanism Using Various Document Representations
3.2.1. Stacked Autoencoder
3.2.2. Doc2vec
3.2.3. BERT
3.2.4. Handcrafted Feature Engineering
3.2.5. Advantages of the Proposed View-Generation Mechanism
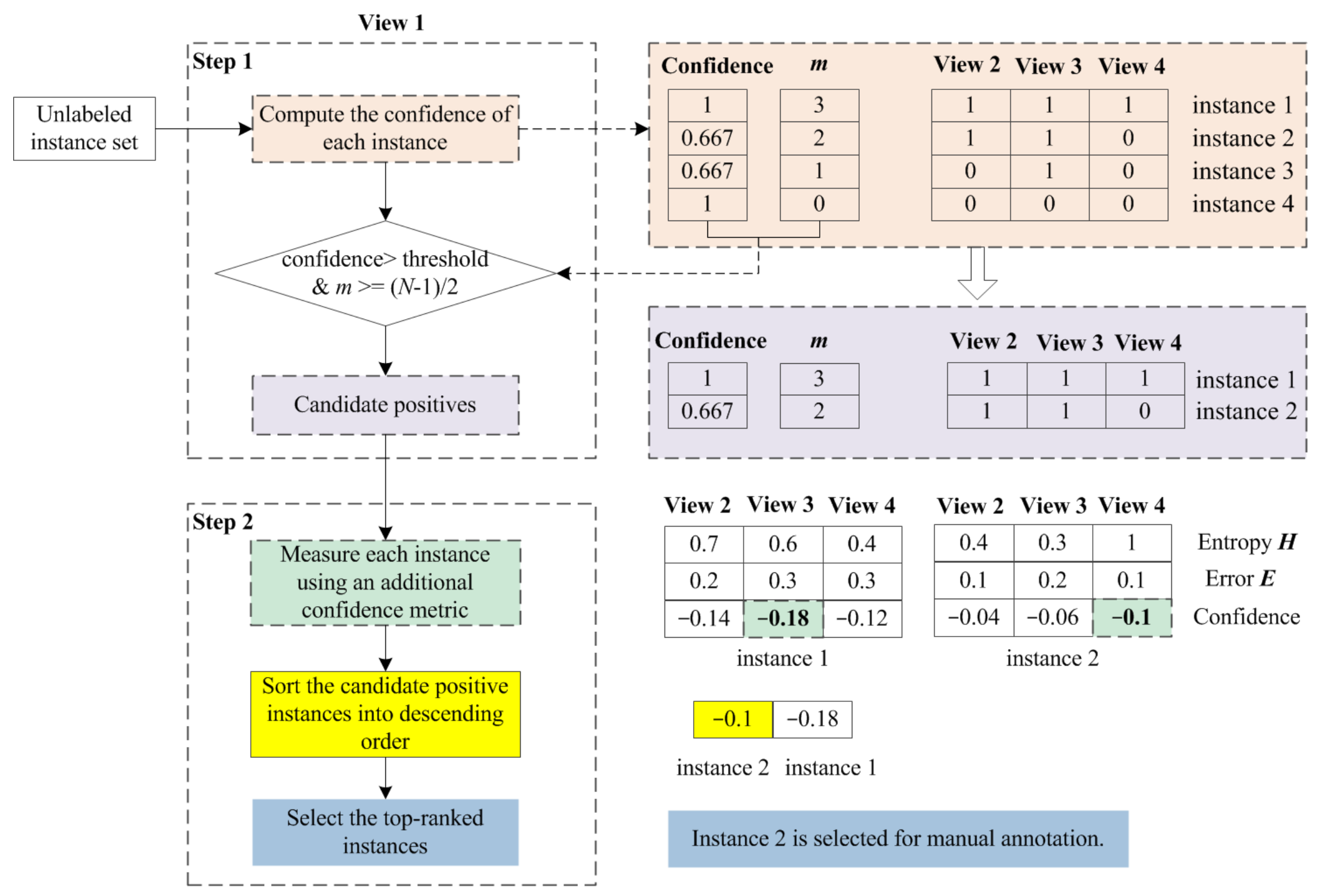
3.3. Selection Strategy in the Proposed Approach
3.3.1. Motivation of the Selection Strategy
3.3.2. Finding Candidate Positive and Negative Instances
- Finding candidate positive instances
- 2.
- Finding candidate negative instances
3.3.3. Determining Selected Positives and Negatives for Manual Annotation
- Determining selected positive instances
- 2.
- Determining selected negative instances
3.4. Pseudocode for the Proposed Approach
| Algorithm 1. MVAL4D |
| Input: |
| L: initial labeled instance set |
| U: unlabeled instance set |
| N: number of views |
| Li: labeled instance set for the ith classifier (i = 1,2,…,N) |
| h: classification learning algorithm |
| T: maximum number of iterations |
| L′i: set of instances that the ith classifier selects in each iteration (i = 1,2,…,N) |
| K: predefined total number of instances to label in each iteration |
| φ: confidence threshold |
| q: the number of selected negative instances divided by the number of selected positive instances in each iteration (0 ≤ q ≤ 1) |
| Process: |
| 1. Generate N views using different methods (e.g., Doc2vec, average Word2vec, stacked autoencoder, and handcrafted feature engineering) |
| 2. Use the under-sampling strategy to address imbalance problem on the original labeled instance set Li ← undersample (L) (i = 1,2,...,N) |
| 3. Train a classifier for each view: |
| 4. For each view i (i = 1,2,..., N), select instances to constitute the Li′: |
| 4.1. To find potentially positive instances, select the most confident instances from U to constitute POS′i, as described in Section 3.3.2 |
| 4.2. For potentially negative instances, select the most informative instances from U to constitute NEG′i, as described in Section 3.3.3 |
| 4.3. |
| 5. Obtain the union of selected instance sets and manually label these instances |
| 6. For each view, combine with the union of selected instance sets derived by all other classifiers (with ground-truth labels) Li←Li ∪ undersample (L′i) ( j = 1,2,…, N & j ≠ i) |
| 7. Remove the union of selected instance sets |
| 8. Repeat Steps 3 through 7 T times or until |
| Output: % Majority voting scheme is adopted |
4. Experimental Datasets and Settings
4.1. Experimental Dataset
4.2. Evaluation Metrics
4.3. Experimental Procedure
4.4. Experimental Settings
5. Results and Discussion
5.1. Experiment A: Effectiveness of Different View Configurations
5.2. Experiment B: Effectiveness of Different Selection Strategies
5.3. Experiment C: Performance Comparison with Different Numbers of Initial Labeled Instances
5.4. Experiment D: Comparison between the Proposed Approach and Other Methods
5.5. Discussions
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sarker, A.; Ginn, R.; Nikfarjam, A.; O’Connor, K.; Smith, K.; Jayaraman, S.; Upadhaya, T.; Gonzalez, G. Utilizing social media data for pharmacovigilance: A review. J. Biomed. Inform. 2015, 54, 202–212. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.; Cui, S.; Gao, H. Adverse drug reaction detection on social media with deep linguistic features. J. Biomed. Inform. 2020, 106, 103437. [Google Scholar] [CrossRef] [PubMed]
- Hazell, L.; Shakir, S.A. Under-reporting of adverse drug reactions. Drug Saf. 2006, 29, 385–396. [Google Scholar] [CrossRef] [PubMed]
- Amante, D.J.; Hogan, T.P.; Pagoto, S.L.; English, T.M.; Lapane, K.L. Access to care and use of the Internet to search for health information: Results from the US National Health Interview Survey. J. Med. Internet Res. 2015, 17, e106. [Google Scholar] [CrossRef] [PubMed]
- Freifeld, C.C.; Brownstein, J.S.; Menone, C.M.; Bao, W.; Filice, R.; Kass-Hout, T.; Dasgupta, N. Digital drug safety surveillance: Monitoring pharmaceutical products in Twitter. Drug Saf. 2014, 37, 343–350. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, C.; Wu, F.; Liu, J.; Wu, S.; Huang, Y.; Xie, X. Detecting Tweets Mentioning Drug Name and Adverse Drug Reaction with Hierarchical Tweet Representation and Multi-Head Self-Attention. In Proceedings of the Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–1 November 2018. [Google Scholar]
- Fan, B.; Fan, W.; Smith, C.; Garner, H. Adverse drug event detection and extraction from open data: A deep learning approach. Inf. Process. Manag. 2020, 57, 102131. [Google Scholar] [CrossRef]
- Dai, H.; Wang, C. Classifying adverse drug reactions from imbalanced twitter data. Int. J. Med. Inform. 2019, 129, 122–132. [Google Scholar] [CrossRef]
- Kim, D.; Seo, D.; Cho, S.; Kang, P. Multi-co-training for document classification using various document representations: TF–IDF, LDA, and Doc2Vec. Inf. Sci. 2019, 477, 15–29. [Google Scholar] [CrossRef]
- Liu, J.; Huang, L.; Zhang, C. An Active Learning Approach for Identifying Adverse Drug Reaction-Related Text from Social Media Using Various Document Representations. In International Conference on Web Information Systems and Applications; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Henriksson, A.; Kvist, M.; Dalianis, H.; Duneld, M. Identifying Adverse Drug Event Information in Clinical Notes with Distributional Semantic Representations of Context. J. Biomed. Inform. 2015, 57, 333–349. [Google Scholar] [CrossRef] [Green Version]
- Gurulingappa, H.; Mateen-Rajput, A.; Toldo, L. Extraction of potential adverse drug events from medical case reports. J. Biomed. Semant. 2012, 3, 15. [Google Scholar] [CrossRef] [Green Version]
- Van Mulligen, E.M.; Fourrier-Reglat, A.; Gurwitz, D.; Molokhia, M.; Nieto, A.; Trifiro, G.; Kors, J.A.; Furlong, L.I. The EU-ADR corpus: Annotated drugs, diseases, targets, and their relationships. J. Biomed. Inform. 2012, 45, 879–884. [Google Scholar] [CrossRef] [Green Version]
- Sarker, A.; Gonzalez, G. Portable automatic text classification for adverse drug reaction detection via multi-corpus training. J. Biomed. Inform. 2015, 53, 196–207. [Google Scholar] [CrossRef] [Green Version]
- Sarker, A.; Belousov, M.; Friedrichs, J.; Hakala, K.; Kiritchenko, S.; Mehryary, F.; Han, S.; Tran, T.; Rios, A.; Kavuluru, R.; et al. Data and systems for medication-related text classification and concept normalization from Twitter: Insights from the Social Media Mining for Health (SMM4H)-2017 shared task. J. Am. Med. Inform. Assoc. 2018, 25, 1274–1283. [Google Scholar] [CrossRef] [Green Version]
- Weissenbacher, D.; Sarker, A.; Paul, M.; Gonzalez, G. Overview of the third social media mining for health (SMM4H) shared tasks at EMNLP 2018. In Proceedings of the 2018 EMNLP Workshop SMM4H: The 3rd Social Media Mining for Health Applications Workshop & Shared Task, Brussels, Belgium, 31 October–1 November 2018. [Google Scholar]
- Weissenbacher, D.; Sarker, A.; Magge, A.; Daughton, A.; O’Connor, K.; Paul, M.; Gonzalez, G. Overview of the Fourth Social Media Mining for Health (#SMM4H) Shared Task at ACL 2019. In Proceedings of the 4th Social Media Mining for Health Applications (#SMM4H) Workshop & Shared Task, Florence, Italy, 2 August 2019. [Google Scholar]
- Yang, M.; Kiang, M.; Shang, W. Filtering big data from social media–Building an early warning system for adverse drug reactions. J. Biomed. Inform. 2015, 54, 230–240. [Google Scholar] [CrossRef] [Green Version]
- Nikfarjam, A.; Sarker, A.; O’Connor, K.; Ginn, R.; Gonzalez, G. Pharmacovigilance from social media: Mining adverse drug reaction mentions using sequence labeling with word embedding cluster features. J. Am. Med. Inform. Assoc. 2015, 22, 671–681. [Google Scholar] [CrossRef] [Green Version]
- Cocos, A.; Fiks, A.G.; Masino, A.J. Deep learning for pharmacovigilance: Recurrent neural network architectures for labeling adverse drug reactions in Twitter posts. J. Am. Med. Inform. Assoc. 2017, 24, 813–821. [Google Scholar] [CrossRef]
- Tang, B.; Hu, J.; Wang, X.; Chen, Q. Recognizing Continuous and Discontinuous Adverse Drug Reaction Mentions from Social Media Using LSTM-CRF. Wirel. Commun. Mob. Comput. 2018, 2379208. [Google Scholar] [CrossRef]
- Liu, J.; Wang, G.; Chen, G. Identifying Adverse Drug Events from Social Media using an Improved Semi-Supervised Method. IEEE Intell. Syst. 2019, 34, 66–74. [Google Scholar] [CrossRef]
- Liu, X.; Chen, H. A research framework for pharmacovigilance in health social media: Identification and evaluation of patient adverse drug event reports. J. Biomed. Inform. 2015, 58, 268–279. [Google Scholar] [CrossRef] [Green Version]
- Emadzadeh, E.; Sarker, A.; Nikfarjam, A.; Gonzalez, G. Hybrid Semantic Analysis for Mapping Adverse Drug Reaction Mentions in Tweets to Medical Terminology. Am. Med. Inform. Assoc. 2017, 2017, 679–688. [Google Scholar]
- Chowdhury, S.; Zhang, C.; Yu, P.S. Multi-task pharmacovigilance mining from social media posts. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23 April 2018. [Google Scholar]
- Patki, A.; Sarker, A.; Pimpalkhute, P.; Nikfarjam, A.; Ginn, R.; O’Connor, K.; Smith, K.; Gonzalez, G. Mining Adverse Drug Reaction Signals from Social Media: Going beyond Extraction. In BioLink-SIG; Oxford University Press: Oxford, UK, 2014. [Google Scholar]
- Cai, J.J.; Tang, J.; Chen, Q.G.; Hu, Y.; Wang, X.; Huang, S.J. Multi-view active learning for video recommendation. In Proceedings of the IJCAI-19, Macao, China, 10–16 August 2019; Available online: https://www.ijcai.org/proceedings/2019/0284.pdf (accessed on 30 December 2019).
- Yan, Y.; Nie, F.; Li, W.; Gao, C.; Yang, Y.; Xu, D. Image classification by cross-media active learning with privileged information. IEEE Trans. Multimed. 2016, 18, 2494–2502. [Google Scholar] [CrossRef]
- Bhattacharjee, S.D.; Tolone, W.J.; Paranjape, V.S. Identifying malicious social media contents using multi-view context-aware active learning. Future Gener. Comput. Syst. 2019, 100, 365–379. [Google Scholar] [CrossRef]
- Chen, L.; Fan, A.; Shi, H.; Chen, G. Search task success evaluation by exploiting multi-view active semi-supervised learning. Inf. Process. Manag. 2020, 57, 102180. [Google Scholar] [CrossRef]
- Nigam, K.; Ghani, R. Analyzing the effectiveness and applicability of co-training. In Proceedings of the Ninth International Conference on Information and Knowledge Management, McLean, VA, USA, 6–11 November 2000. [Google Scholar]
- Zhao, Y.; Shi, Z.; Zhang, J.; Chen, D.; Gu, L. A novel active learning framework for classification: Using weighted rank aggregation to achieve multiple query criteria. Pattern Recognit. 2019, 93, 581–602. [Google Scholar] [CrossRef] [Green Version]
- Muslea, I.; Minton, S.; Knoblock, C.A. Active learning with multiple views. J. Artif. Intell. Res. 2006, 27, 203–233. [Google Scholar] [CrossRef]
- Schwenker, F.; Trentin, E. Pattern classification and clustering: A review of partially supervised learning approaches. Pattern Recognit. Lett. 2014, 37, 4–14. [Google Scholar] [CrossRef]
- Salton, G.; Wong, A.; Yang, C.S. A vector space model for automatic indexing. Commun. ACM 1974, 18, 613–620. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Guo, H.; Zhang, Q.; Gu, M.; Yang, J. Imbalanced text sentiment classification using universal and domain-specific knowledge. Knowl.-Based Syst. 2018, 160, 1–15. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 31 May 2013. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Lizarralde, I.; Mateos, C.; Zunino, A.; Majchrzak, T.A.; Grønli, T.-M. Discovering web services in social web service repositories using deep variational autoencoders. Inf. Processing Manag. 2020, 57, 102231. [Google Scholar] [CrossRef]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24 July 1998. [Google Scholar]
- Windeatt, T.; Ardeshir, G. Decision Tree Simplification for Classifier Ensembles. Int. J. Pattern Recognit. Artif. Intell. 2004, 18, 749–776. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. In Advances in Neural Information Processing Systems; Curran Associates: Vancouver, BC, Canada, 2007. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:arXiv:1810.04805. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Proccedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhou, Z.-H.; Li, M. Tri-training: Exploiting unlabeled data using three classifiers. IEEE Trans. Knowl. Data Eng. 2005, 17, 1529–1541. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Zhou, Z.-H. Improve computer-aided diagnosis with machine learning techniques using undiagnosed samples. Syst. Man Cybern. Part A Syst. Hum. IEEE Trans. 2007, 37, 1088–1098. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Type | Feature | Description | Knowledge Base/Tool |
|---|---|---|---|
| Shallow linguistic features | N-grams with tf-idf | = 1, 2, 3) tokens in the text | / |
| Domain knowledge-based features | Medical semantic features | Concept IDs and semantic types that represent fine and broad categories of medical concepts | Unified Medical Language System (UMLS) 1/MetaMap 2 |
| The ADR lexicon match-based features | A flag of whether ADR mentions in a constructed lexicon are contained in the instance | COSTART 3, MedEffect 4, SIDER 5, and Consumer Health Vocabulary (CHV) 6 | |
| The number of ADR mentions | |||
| The negation features | Negated concepts | NegEx 7 incorporated in MetaMap | |
| Other discriminative features | Synonym expansion features | Synonyms for each noun, verb, and adjective in an instance | WordNet 8 |
| Change phrase features | less-good, more-good, more-bad, and less-bad | / | |
| Sentiword score feature | The overall sentiment score divided by the length of the instance | SentiWordNet 9 | |
| Topic-based features | Topic terms | Mallet 10 |
| Document Representation | # Features | C | Window | Min_Count | Max_Seq_Length |
|---|---|---|---|---|---|
| Doc2vec | 128 | 16 | 5 | 60 | / |
| BERT | 768 | 4 | / | / | 35 |
| Stacked autoencoder | 300 | 16 | / | / | / |
| Feature engineering | 15,657 | 256 | / | / | / |
| Abbreviation | Description |
|---|---|
| D2V_BERT_SAE_FE | DRs fusing doc2vec, pre-trained BERT, stacked autoencoder, and feature engineering |
| D2V_FE | DRs fusing doc2vec and feature engineering |
| BERT_FE | DRs fusing pre-trained BERT and feature engineering |
| SAE_FE | DRs fusing stacked autoencoder and feature engineering |
| D2V_ BERT_SAE | DRs fusing doc2vec, pre-trained BERT, and stacked autoencoder |
| MVAL4D_Same | Separately selecting potentially positive and negative instances with the informativeness-based selection criterion |
| MVAL4D_ WithoutPosNeg | Using the informativeness-based criterion to select instances, without concerning their pseudo labels |
| View Configurations | MVAL4D Recall | MV_SL F1_Score | AA↑ | AUC↑ | ||
|---|---|---|---|---|---|---|
| AA | AUC | AA | AUC | |||
| D2V_BERT_SAE_FE | 82.04% | 0.8816 | 76.57% | 0.8705 | 7.14% | 1.27% |
| D2V_FE | 82.51% | 0.8823 | 77.69% | 0.8675 | 6.20% | 1.71% |
| BERT_FE | 81.90% | 0.8734 | 77.12% | 0.8697 | 6.19% | 0.42% |
| SAE_FE | 81.95% | 0.8751 | 77.32% | 0.8691 | 5.98% | 0.70% |
| D2V_BERT_SAE | 81.73% | 0.8748 | 75.40% | 0.8633 | 8.40% | 1.33% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Wang, Y.; Huang, L.; Zhang, C.; Zhao, S. Identifying Adverse Drug Reaction-Related Text from Social Media: A Multi-View Active Learning Approach with Various Document Representations. Information 2022, 13, 189. https://doi.org/10.3390/info13040189
Liu J, Wang Y, Huang L, Zhang C, Zhao S. Identifying Adverse Drug Reaction-Related Text from Social Media: A Multi-View Active Learning Approach with Various Document Representations. Information. 2022; 13(4):189. https://doi.org/10.3390/info13040189
Chicago/Turabian StyleLiu, Jing, Yue Wang, Lihua Huang, Chenghong Zhang, and Songzheng Zhao. 2022. "Identifying Adverse Drug Reaction-Related Text from Social Media: A Multi-View Active Learning Approach with Various Document Representations" Information 13, no. 4: 189. https://doi.org/10.3390/info13040189
APA StyleLiu, J., Wang, Y., Huang, L., Zhang, C., & Zhao, S. (2022). Identifying Adverse Drug Reaction-Related Text from Social Media: A Multi-View Active Learning Approach with Various Document Representations. Information, 13(4), 189. https://doi.org/10.3390/info13040189