
Accurate Air-Quality Prediction Using Genetic-Optimized Gated-Recurrent-Unit Architecture

 , , ,
, , ,
Abstract
:1. Introduction
2. Related Works
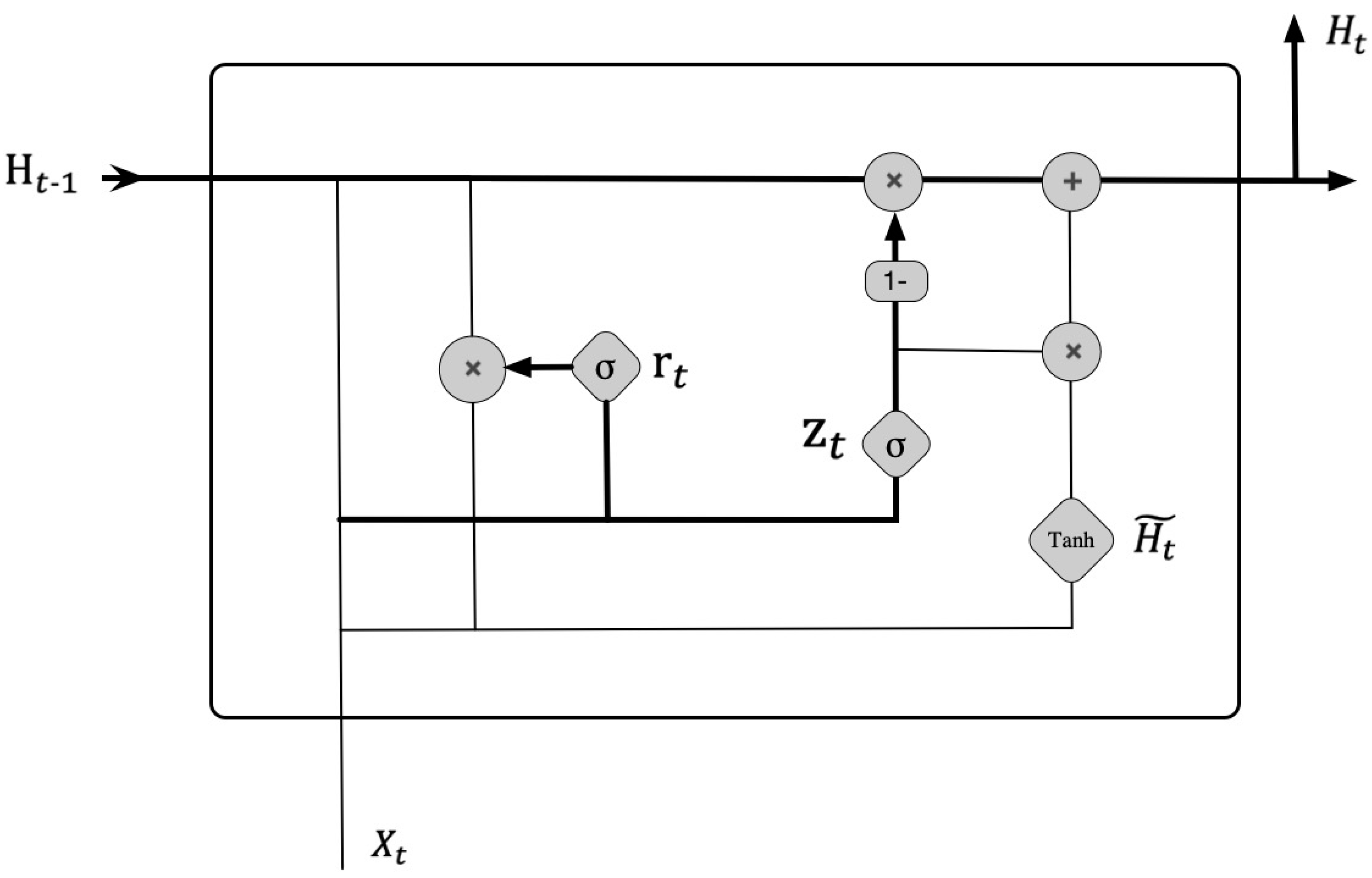
2.1. Gated Recurrent Unit
2.2. Genetic Algorithm
3. The Proposed Method
3.1. Data Preprocessing
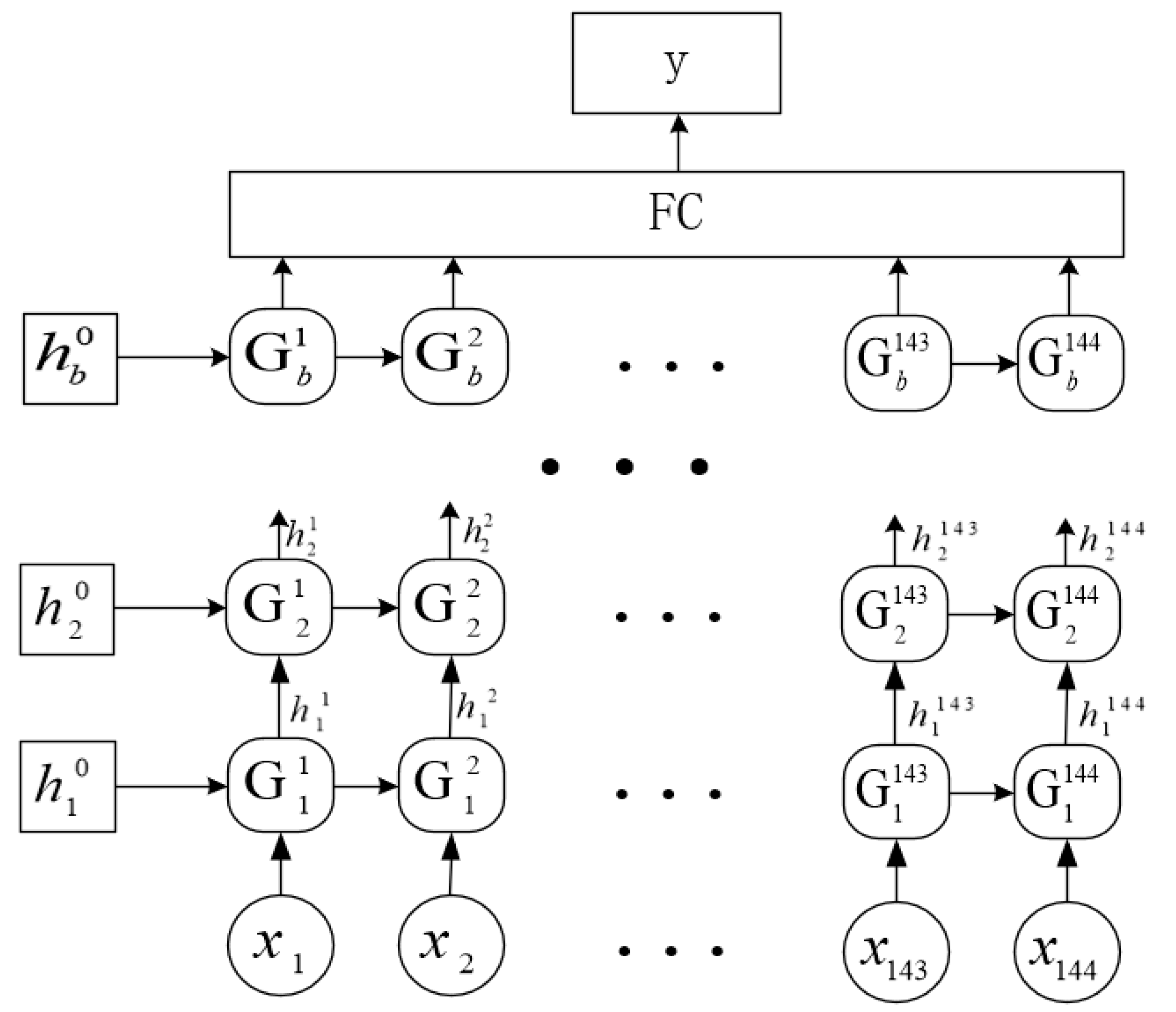
3.2. The Network Structure of GRU
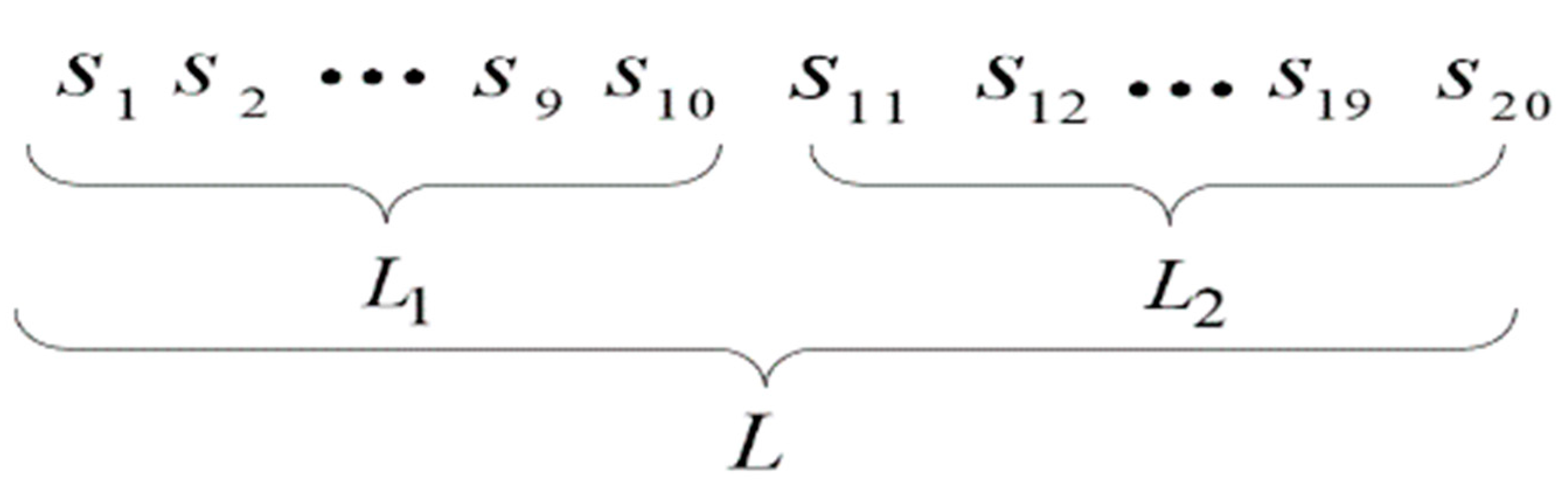
3.3. Binary-Network Representation
3.4. Genetic Operation
3.4.1. Initialization
3.4.2. Selection
3.4.3. Mutation
3.4.4. Crossover
| Algorithm 1 The Genetic Process for Network |
| 1: Input: the reference dataset D, the number of generations T, the number of individuals in each generation N, the mutation probability , the crossover probabilities , the mutation parameter , and the crossover parameter . 2: Initialization: randomly generating a group of models and computing their fitness; 3: for t = 1, 2, 3,…, T do 4: Selection: generating a new generation using rank selection; 5: Crossover: performing crossover with probability and parameter ; 6: Mutation: performing mutation on each individual with probability and parameter ; 7: Evaluation: computing the fitness for each individual ; 8: end for 9: Output: the final generation . |
3.5. Training and Evaluation
4. Experiments and Analysis
4.1. Datasets
4.2. The Experimental Environment
4.3. The Experimental Evaluation Index
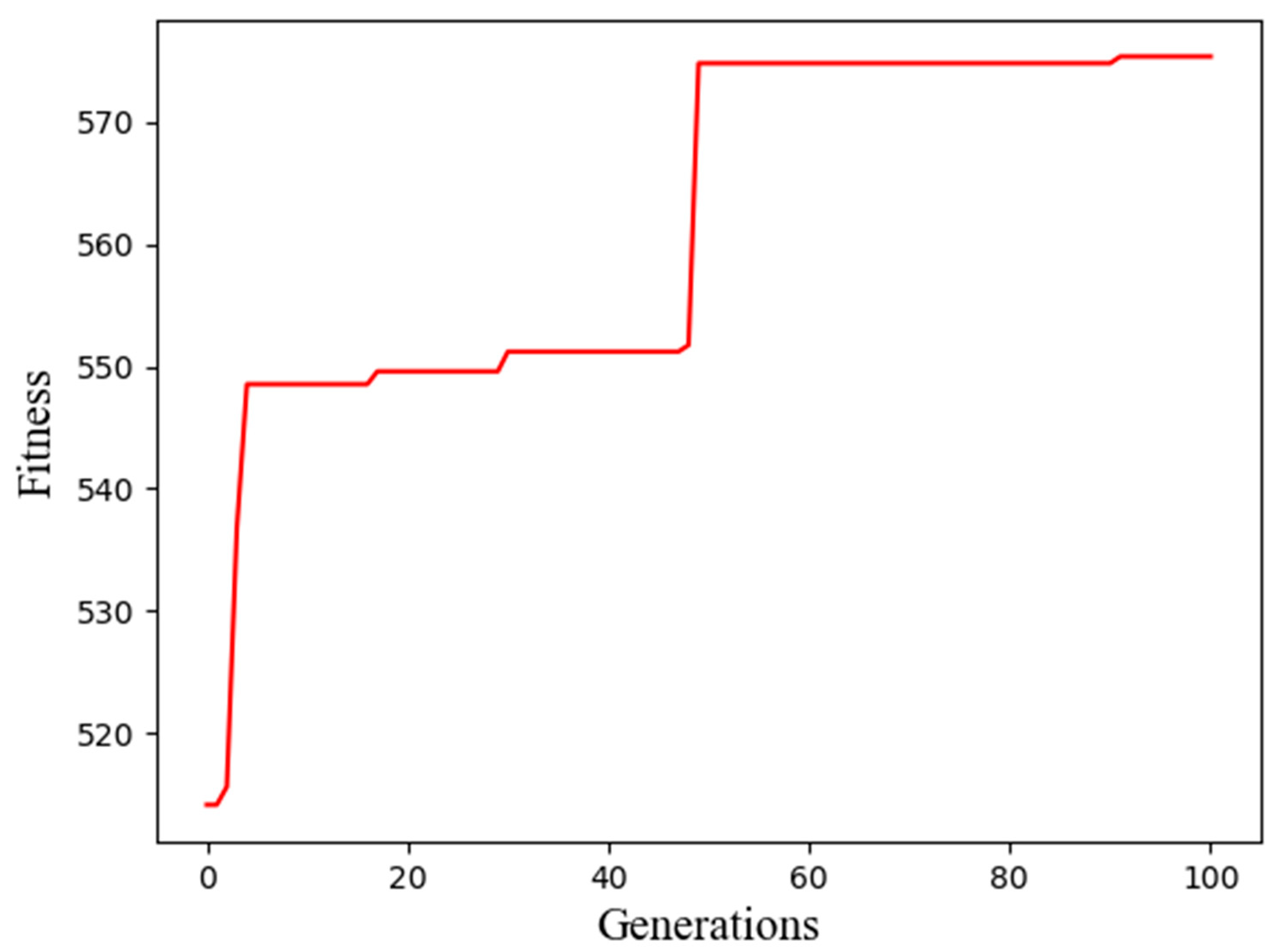
4.4. The Adaptive GRU Structure Using Genetic Algorithm
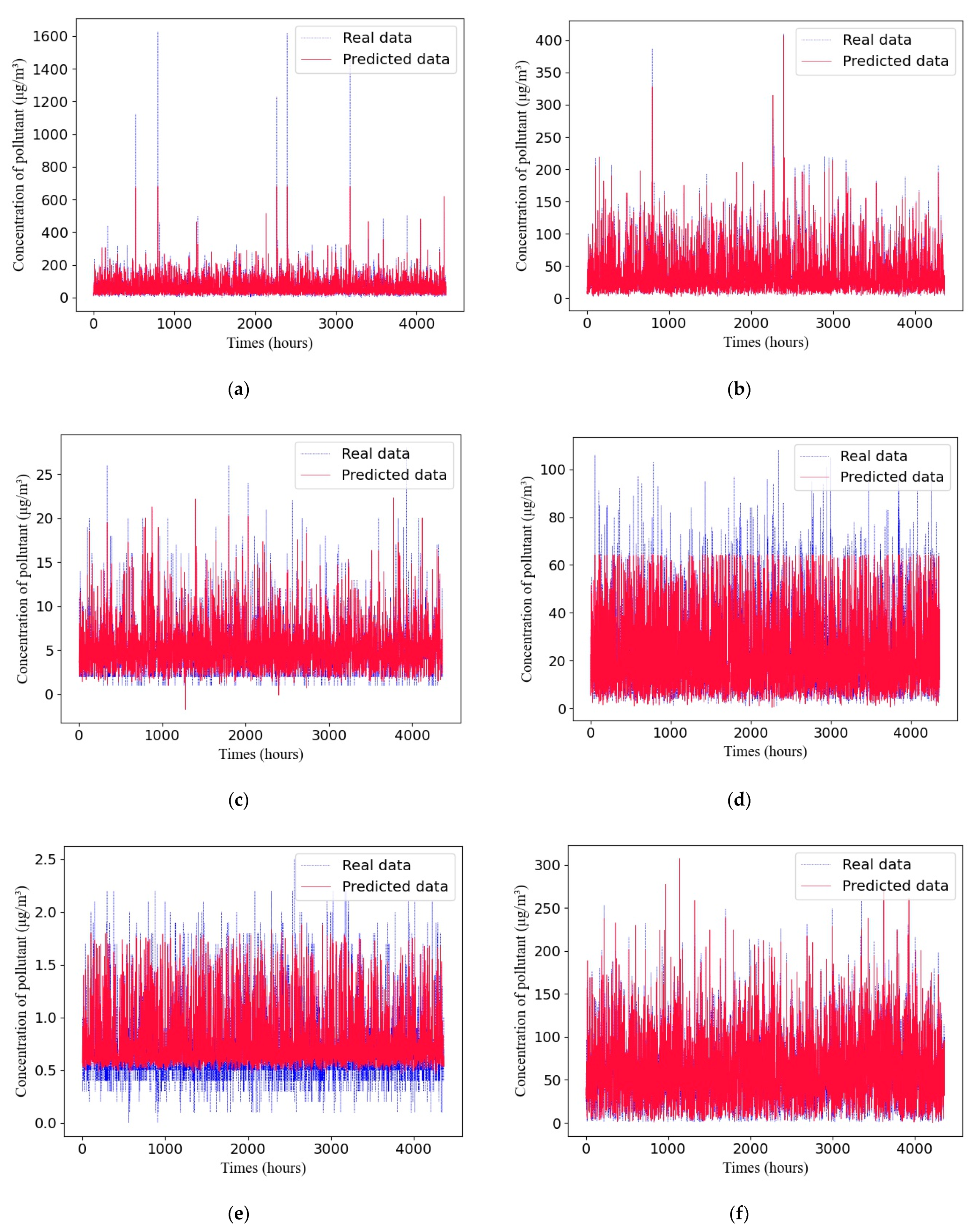
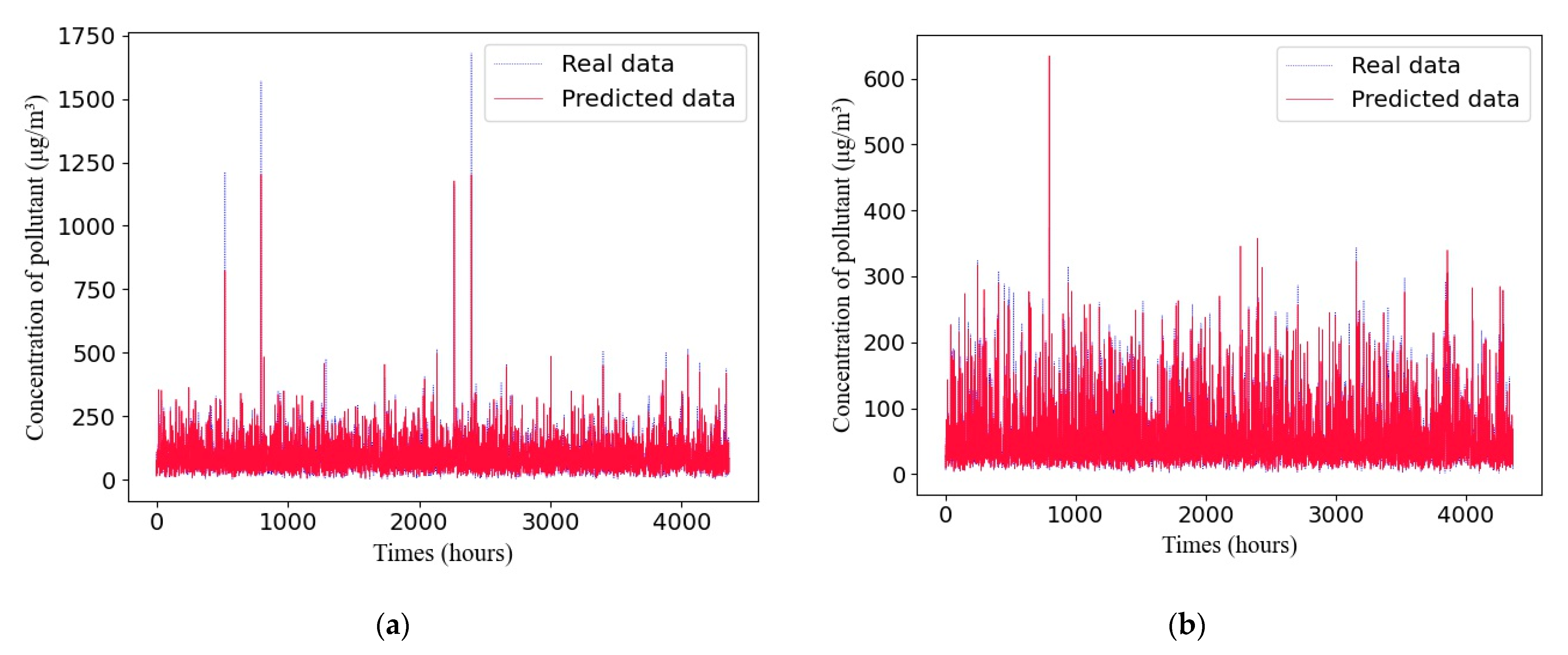
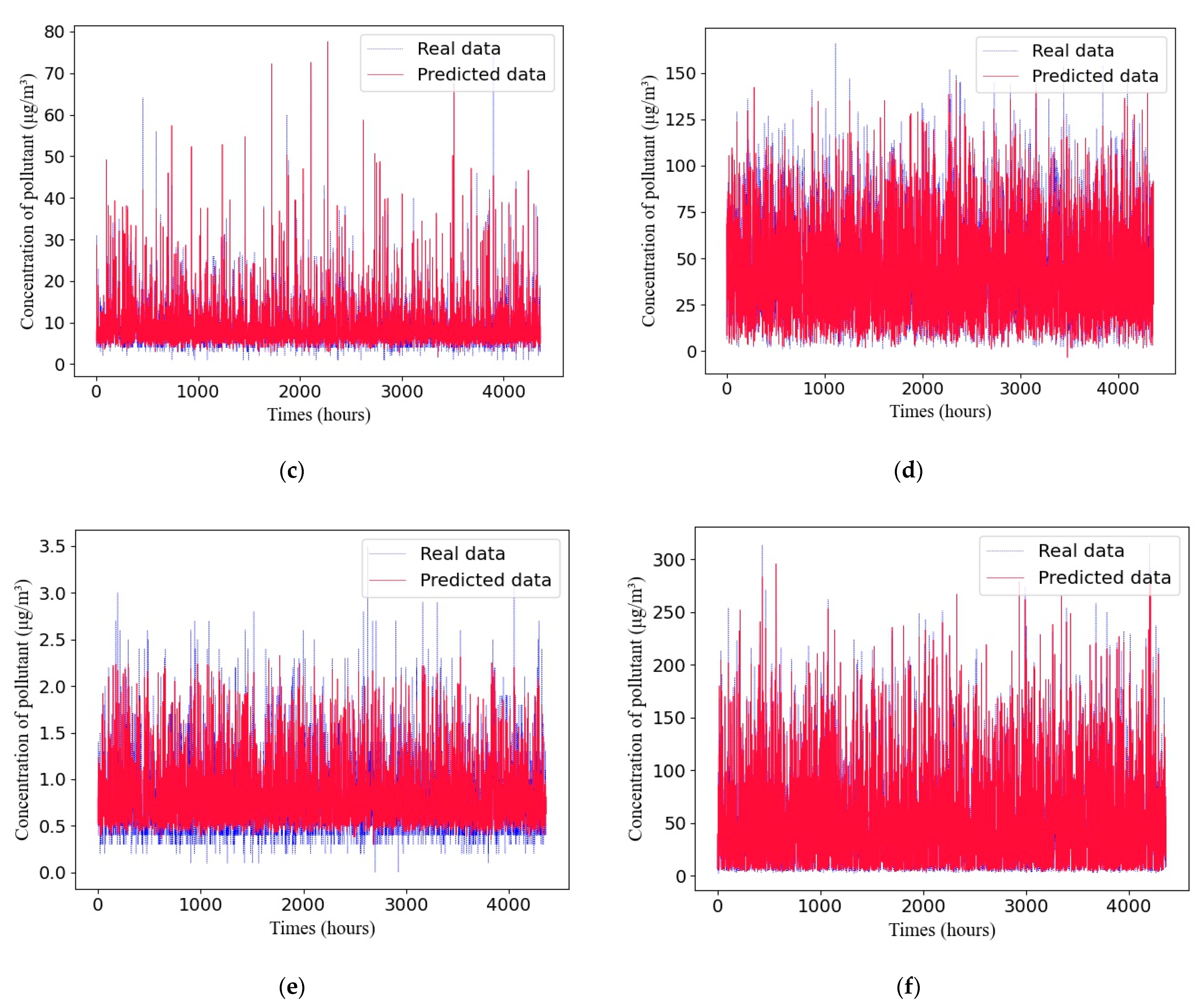
4.5. The Adaptive GRU Structure Compared with the Manually Designed GRU Structure
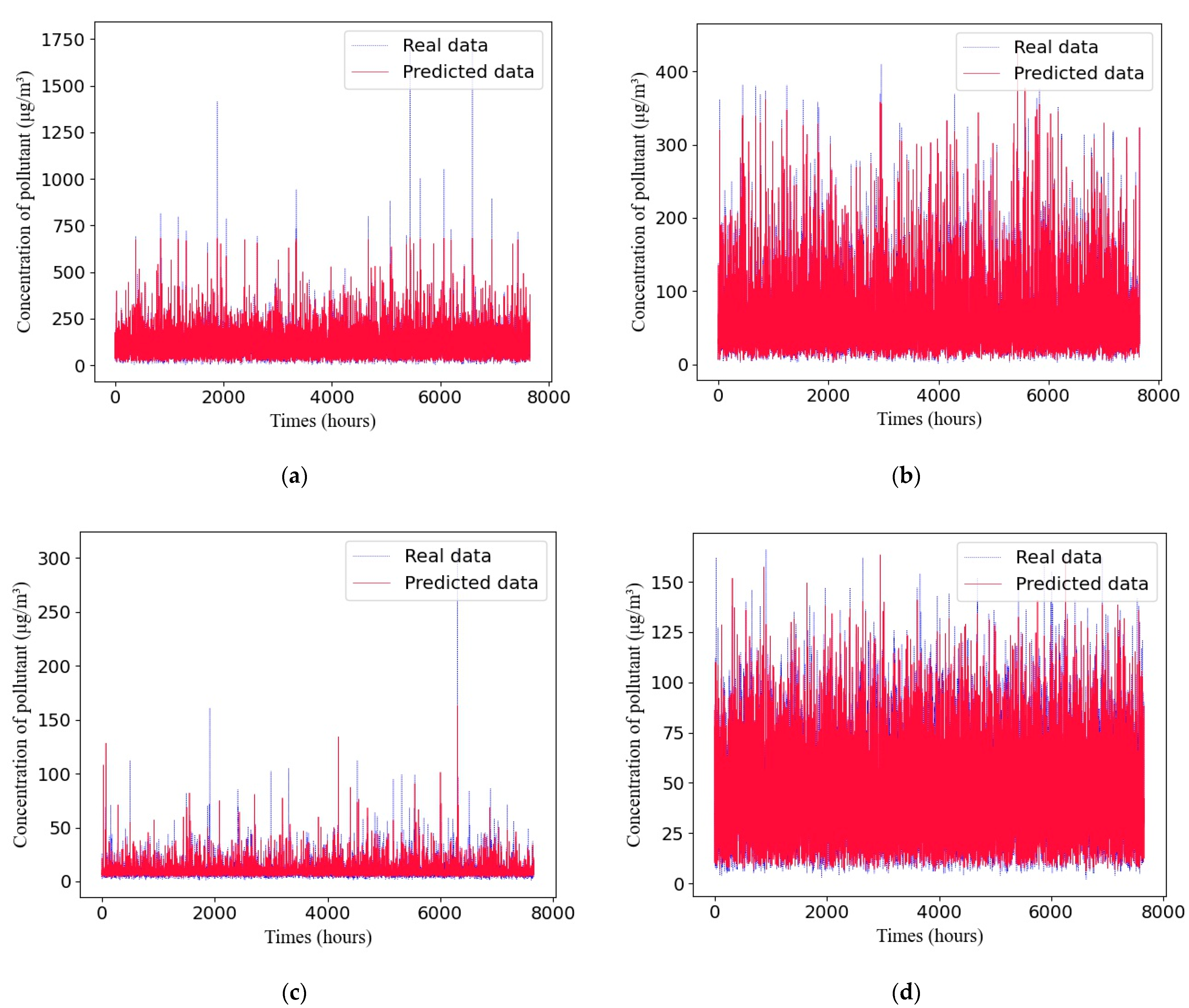
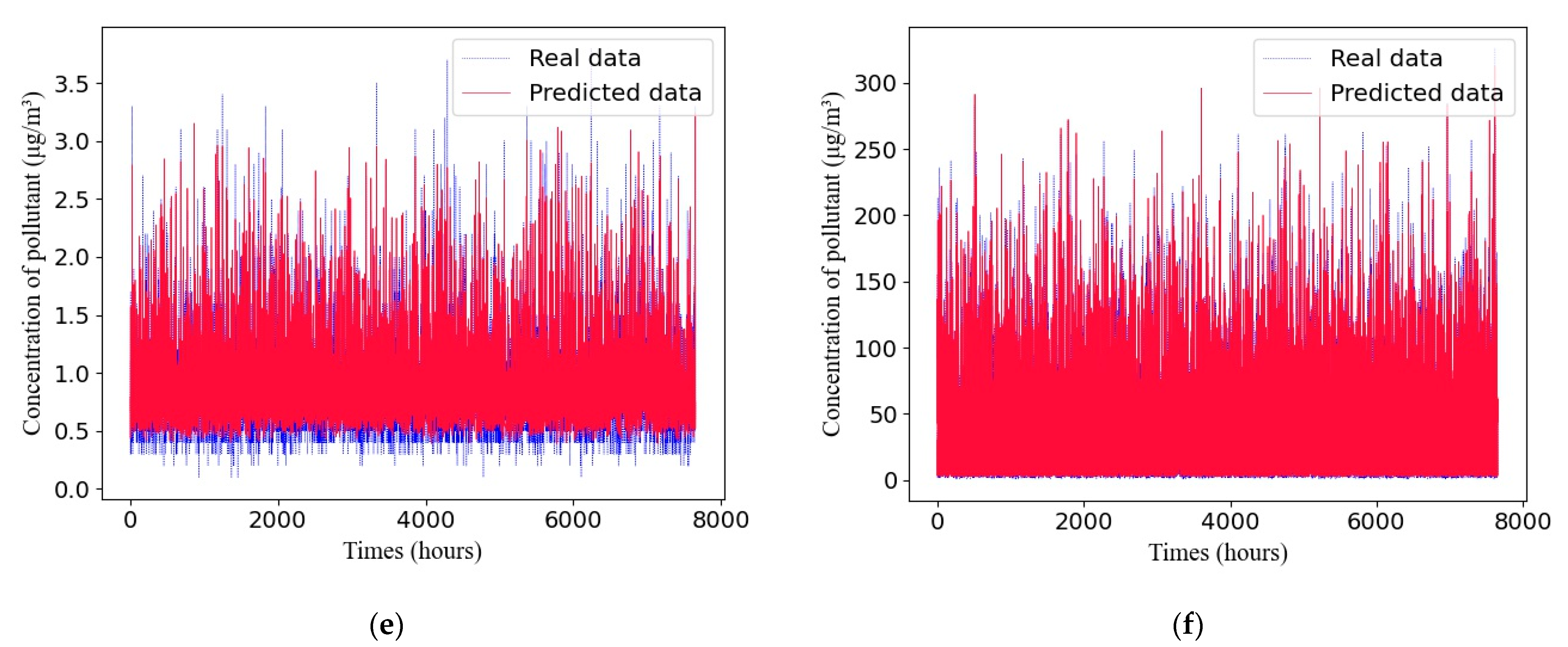
4.6. The Adaptive GRU Compared with Other Air-Quality-Prediction Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aliyu, Y.A.; Botai, J.O. Reviewing the local and global implications of air pollution trends in Zaria, northern Nigeria-ScienceDirect. Urban Clim. 2018, 26, 51–59. [Google Scholar] [CrossRef] [Green Version]
- Aliyu, Y.A.; Musa, I.J.; Jeb, D.N. Geostatistics of pollutant gases along high traffic points in Urban Zaria, Nigeria. Int. J. Geomat. Geosci. 2014, 5, 19–31. [Google Scholar]
- Alegria, A.; Barbera, R.; Boluda, R.; Errecalde, F.; Farré, R.; Lagarda, M.J. Environmental cadmium, lead and nickel contamination: Possible relationship between soil and vegetable content. Fresenius J. Anal. Chem. 1991, 339, 654–657. [Google Scholar] [CrossRef]
- Ercilla-Montserrat, M.; Muoz, P.; Montero, J.I.; Gabarrell, X.; Rieradevall, J. A study on air quality and heavy metals content of urban food produced in a Mediterranean city (Barcelona). J. Clean. Prod. 2018, 195, 385–395. [Google Scholar] [CrossRef]
- Wang, B.; Hong, G.; Qin, T.; Fan, W.R.; Yuan, X.C. Factors governing the willingness to pay for air pollution treatment: A case study in the Beijing-Tianjin-Hebei region. J. Clean. Prod. 2019, 235, 1304–1314. [Google Scholar] [CrossRef]
- Cohen, A.J.; Brauer, M.; Burnett, R.; Anderson, H.R.; Frostad, J.; Estep, K.; Balakrishnan, K.; Brunekreef, B.; Dandona, L.; Dandona, R.; et al. Estimates and 25-year trends of the global burden of disease attributable to ambient air pollution: An analysis of data from the Global Burden of Diseases Study 2015. Lancet 2017, 389, 1907–1918. [Google Scholar] [CrossRef] [Green Version]
- Yin, P.; He, G.; Fan, M.; Chiu, K.Y.; Fan, M.; Liu, C.; Xue, A.; Liu, T.; Pan, Y.; Mu, Q.; et al. Particulate air pollution and mortality in 38 of China’s largest cities: Time series analysis. BMJ Clin. Res. 2017, 356, j667. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- United Nations. The World’s Cities in 2018 Data Booklet, 1009 Economics & Social Affairs. 2018. Available online: https://www.un.org/development/desa/pd/content/worlds-cities-2018-data-booklet (accessed on 13 April 2020).
- Afzali, A.; Rashid, M.; Afzali, M.; Younesi, V. Prediction of Air Pollutants Concentrations from Multiple Sources Using AERMOD Coupled with WRF Prognostic Model. J. Clean. Prod. 2017, 166, 1216–1225. [Google Scholar] [CrossRef]
- Todorov, V.; Dimov, I.; Ostromsky, T.; Apostolov, S.; Georgieva, R.; Dimitrov, Y.; Zlatev, Z. Advanced stochastic approaches for Sobol’ sensitivity indices evaluation. Neural Comput. Appl. 2021, 33, 1999–2014. [Google Scholar] [CrossRef]
- Dimov, I.; Todorov, V.; Sabelfeld, K. A study of highly efficient stochastic sequences for multidimensional sensitivity analysis. Monte Carlo Methods Appl. 2022, 28, 1–12. [Google Scholar] [CrossRef]
- Roeva, O.; Fidanova, S.; Paprzycki, M. Population Size Influence on the Genetic and Ant Algorithms Performance in Case of Cultivation Process Modeling. In Recent Advances in Computational Optimization. Studies in Computational Intelligence; Fidanova, S., Ed.; Springer: Cham, Switzerland, 2015; Volume 580. [Google Scholar]
- Zhou, X.; Xu, J.; Zeng, P.; Meng, X. Air pollutant concentration prediction based on GRU method. J. Phys. Conf. Ser. 2019, 1168, 032058. [Google Scholar] [CrossRef]
- Christensen, J.H. The Danish eulerian hemispheric model—A three-dimensional air pollution model used for the arctic. Atmos. Environ. 1997, 31, 4169–4191. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Sun, C. Data Classification for Air Quality on Wireless Sensor Network Monitoring System Using Decision Tree Algorithm. In Proceedings of the 2016 2nd International Conference on Science and Technology-Computer (ICST), Yogyakarta, Indonesia, 27–28 October 2016. [Google Scholar]
- Kujaroentavon, K.; Kiattisin, S.; Leelasantitham, A.; Thammaboosadee, S. Air quality classification in Thailand based on decision tree. In Proceedings of the 7th 2014 Biomedical Engineering International Conference, Fukuoka, Japan, 26–28 November 2014. [Google Scholar]
- Zhang, C.; Yuan, D. Fast Fine-Grained Air Quality Index Level Prediction Using Random Forest Algorithm on Cluster Computing of Spark. In Proceedings of the 2015 IEEE 12th International Conference on Ubiquitous Intelligence and Computing and 2015 IEEE 12th International Conference on Autonomic and Trusted Computing and 2015 IEEE 15th International Conference on Scalable Computing and Communications and Its Associated Workshops (UIC-ATC-ScalCom), Beijing, China, 10–14 August 2015. [Google Scholar]
- Ghaemi, Z.; Farnaghi, M.; Alimohammadi, A. Hadoop-Based Distributed System for Online Prediction of Air Pollution Based on Support Vector Machine, The International Archives of the Photogrammetry. Remote Sens. Spat. Inf. Sci. 2015, 40, 215–219. [Google Scholar]
- Gao, S.; Hu, H.; Li, Y.; Bai, Y. Prediction of Ait Quality Index Based on MFO-SVM. J. North Univ. China Nat. Sci. Ed. 2018, 39, 373–379. [Google Scholar]
- Kingsy, R.; Grace, R.; Manimegalai, M.S.; Geetha Devasena, S.; Rajathi, K.; Usha, N.; Raabiathul, B. Air Pollution Analysis using Enhanced K-Means Clustering Algorithm for Real Time Sensor Data. In Proceedings of the IEEE Region 10 Conference, Singapore, 22–25 November 2016. [Google Scholar] [CrossRef]
- Taghavifar, H.; Mardani, A.; Mohebbi, A.; Khalilarya, S.; Jafarmadar, S. Appraisal of artificial neural networks to the emission analysis and prediction of CO2, soot, and NOx of n-heptane fueled engine. J. Clean. Prod. 2016, 112, 1729–1739. [Google Scholar] [CrossRef]
- Taylan, O. Modelling and analysis of ozone concentration by artificial intelligent techniques for estimating air quality. Atmos. Environ. 2017, 150, 356–365. [Google Scholar] [CrossRef]
- Gao, M.; Yin, L.; Ning, J. Artificial neural network model for ozone concentration estimation and Monte Carlo analysis. Atmos. Environ. 2018, 184, 129–139. [Google Scholar] [CrossRef]
- Nieto, P.; García-Gonzalo, E.; Sánchez, A.B.; Rodríguez Miranda, A.A. Air Quality Modeling Using the PSO-SVM-Based Approach, MLP Neural Network, and M5 Model Tree in the Metropolitan Area of Oviedo (Northern Spain). Environ. Model. Assess. 2018, 23, 229–247. [Google Scholar] [CrossRef]
- Gholizadeh, M.H.; Darand, M. Forecasting the Air Pollution with using Artificial Neural Networks: The Case Study; Tehran City. J. Appl. Sci. 2009, 9, 3882–3887. [Google Scholar] [CrossRef]
- Ai, H.; Shi, Y. Study on Prediction of Haze Based on BP Neural Network. Comput. Simul. 2015, 32, 402–405. [Google Scholar]
- Zhao, W.Y.; Xia, L.S.; Gao, G.K.; Cheng, L. PM2.5 prediction model based on weighted KNN-BP neural network. J. Environ. Eng. Technol. 2019, 9, 14–18. [Google Scholar]
- Ma, C.; Zu, J.; Fu, Q.; Luo, L. Air visibility forecast based on genetic neural network model. Chin. J. Environ. Eng. 2015, 9, 1905–1910. [Google Scholar]
- Li, K.; Zhou, R.; Xu, H. Based on Hopfield neural network to determine the air quality levels. In Proceedings of the 2011 International Conference on Business Management and Electronic Information, Guangzhou, China, 13–15 May 2011. [Google Scholar]
- Wang, X.; Zhang, Y.; Zhao, S.; Zhang, L. Air quality forecasting based on dynamic granular wavelet neural network. Comput. Eng. Appl. 2013, 49, 221–224. [Google Scholar]
- Fan, J.; Li, Q.; Zhu, Y.; Hou, J.; Feng, X. Aspatio-temporal prediction framework for air polution based on dep RNN. Sci. Surv. Mapp. 2017, 4, 15. [Google Scholar]
- Yang, C.; Wang, Y.; Shu, Z.; Liu, J.; Xie, N. Application of LSTM Model Based on TensorFlow in Air Quality Index Prediction. Digit. Technol. Appl. 2021, 39, 203–206. [Google Scholar]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long short-term memory neural network for air pollutant concentration predictions: Method development and evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef]
- Zhao, J.; Deng, F.; Cai, Y.; Chen, J. Long short-term memory-fully connected (LSTM-FC) neural network for PM2.5concentration prediction. Chemosphere 2019, 220, 486–492. [Google Scholar] [CrossRef]
- Lu, H.; Xie, M.; Wu, Z.; Liu, B.; Gao, Y.; Chen, G.; Li, Z. Chengyu region machine learning WRF-CMAQ PM2.5 concentration numerical air quality forecast. Acta Sci. Circumstantiae 2020, 40, 4419–4431. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.H.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Houck, C.; Joines, J.; Kay, M. A Genetic Algorithm for Function Optimization: A Matlab Implementation; Technical Report; North Carolina State University: Raleigh, NC, USA, 2009. [Google Scholar]
- Reeves, C. A Genetic Algorithm for Flowshop Sequencing. Comput. Oper. Res. 1995, 22, 5–13. [Google Scholar] [CrossRef]
- Beasley, J.; Chu, P. A Genetic Algorithm for the Set Covering Problem. Eur. J. Oper. Res. 1996, 94, 392–404. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: Nsga-ii. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Grefenstette, J.; Gopal, R.; Rosmaita, B.; van Gucht, D. Genetic Algorithms for the Traveling Salesman Problem. In Proceedings of the International Conference on Genetic Algorithms and Their Applications, Pittsburg, PA, USA, 24–26 July 1985. [Google Scholar]
- Yao, X. Evolving Artificial Neural Networks. Proc. IEEE 1999, 87, 423–1447. [Google Scholar]
- Snyder, L.; Daskin, M. A Random-Key Genetic Algorithm for the Generalized Traveling Salesman Problem. Eur. J. Oper. Res. 2006, 174, 38–53. [Google Scholar] [CrossRef]
- Bayer, J.; Wierstra, D.; Togelius, J.; Schmidhuber, J. Evolving Memory Cell Structures for Sequence Learning. In Proceedings of the International Conference on Artificial Neural Networks, Limassol, Cypros, 14–17 September 2009. [Google Scholar]
- Ding, S.; Li, H.; Su, C.; Yu, J.; Jin, F. Evolutionary Artificial Neural Networks: A Review. Artif. Intell. Rev. 2013, 39, 251–260. [Google Scholar] [CrossRef]
- Xie, L.; Yuille, A. Genetic CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), IEEE Computer Society, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Baker, J.E. Adaptive selection methods for genetic algorithms. In Proceedings of the International Conference on Genetic Algorithms and Their Applications, Pittsburg, PA, USA, 24–26 July 1985; pp. 101–111. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | PM10 (μg/m3) | PM2.5 (μg/m3) | SO2 (μg/m3) | NO2 (μg/m3) | CO (mg/m3) | O3 (μg/m3) |
|---|---|---|---|---|---|---|
| 2018-01-01 01:00 | 436 | 201 | 27 | 85 | 2.2 | 5 |
| … | … | … | … | … | … | … |
| 2020-12-31 23:00 | 267 | 218 | 21 | 82 | 2.4 | 7 |
| Order | Time | PM10 | PM2.5 | SO2 | NO2 | CO | O3 |
|---|---|---|---|---|---|---|---|
| 0 | 2018-01-01 01:00 | 5.6161 | 2.1780 | −0.3676 | 0.4809 | −0.7304 | −0.6894 |
| 1 | 2018-01-01 02:00 | 5.1333 | 3.0558 | −0.4115 | 0.3639 | −0.7260 | −0.6748 |
| … | … | … | … | … | … | … | … |
| 26,276 | 2020-12-31 23:00 | 3.1436 | 2.4267 | −0.4553 | 0.4370 | −0.7275 | −0.6602 |
| Order | Time | PM10 | PM2.5 | SO2 | NO2 | CO | O3 |
|---|---|---|---|---|---|---|---|
| 0 | 2018-01-01 01:00 | 5.6161 | 2.1780 | −0.3676 | 0.4809 | −0.7304 | −0.6894 |
| 1 | 2018-01-01 02:00 | 5.1333 | 3.0558 | −0.4115 | 0.3639 | −0.7260 | −0.6748 |
| … | … | … | … | … | … | … | … |
| 23 | 2018-01-02 00:00 | 6.1428 | 3.3777 | −0.0457 | 0.8613 | −0.7158 | −0.6894 |
| 24 | 2018-01-02 01:00 | 6.7573 | 5.3528 | −0.1774 | 0.7589 | −0.7099 | −0.6309 |
| Dataset Name | Xi‘an Xincheng Center Square Station | Xi‘an Caotang Base | Xi‘an Gaoxin West Station |
|---|---|---|---|
| Dataset Number | Dataset 1 | Dataset 2 | Dataset 3 |
| Data Quantity | 25,569 | 14,567 | 14,568 |
| Dataset Name | Xi‘an Xincheng Center Square Station | Xi‘an Caotang Base | Xi‘an Gaoxin West Station |
|---|---|---|---|
| Dataset Number | Dataset 1 | Dataset 2 | Dataset 3 |
| Sample Quantity | 25,545 | 14,543 | 14,544 |
| Dataset | Number of Samples | ||
|---|---|---|---|
| Training Set | Validation Set | Testing Set | |
| Dataset 1 | 16,093 | 1788 | 7664 |
| Dataset 2 | 9157 | 1017 | 4360 |
| Dataset 3 | 9157 | 1018 | 4360 |
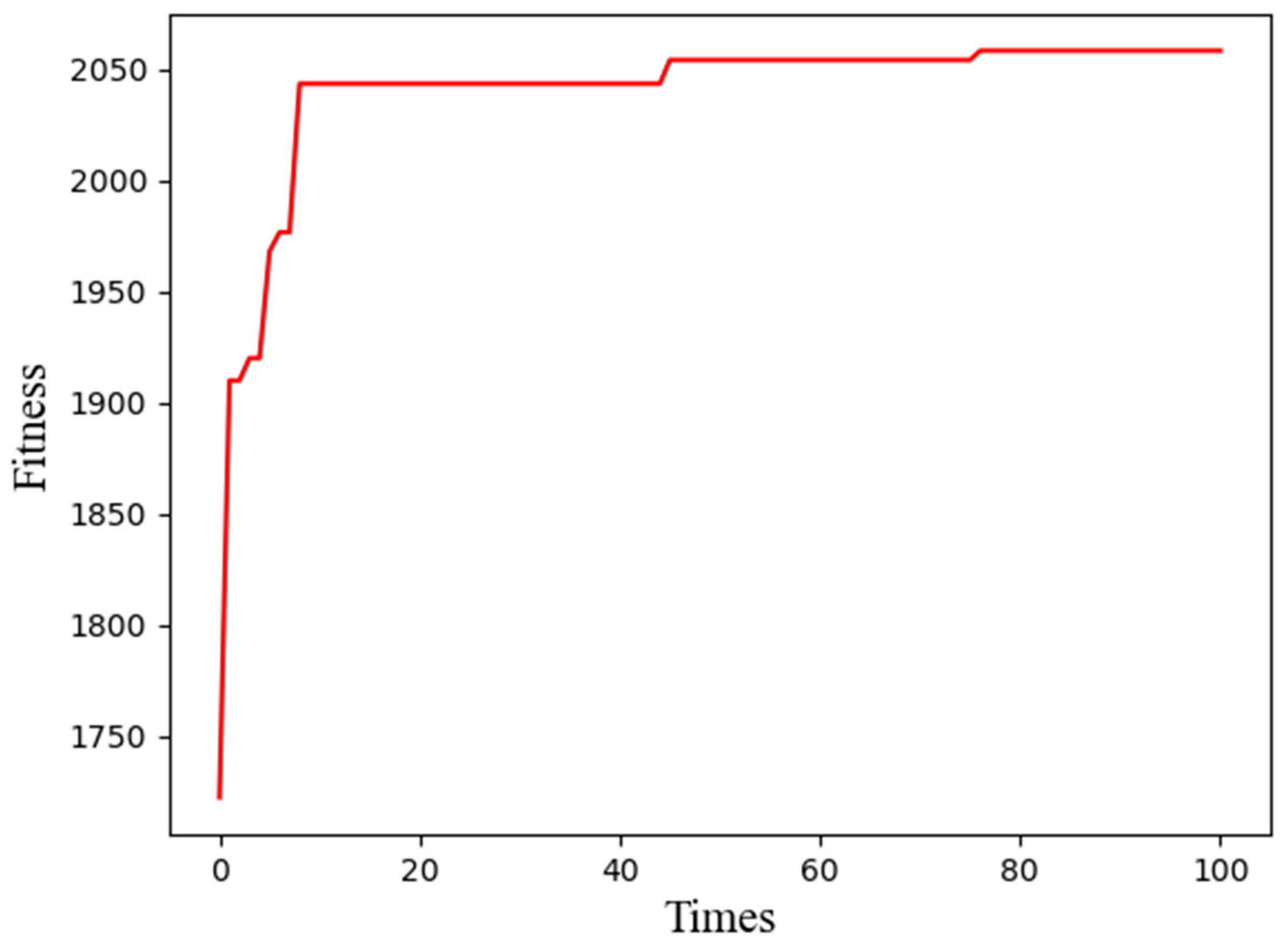
| Generations | Best Fitness | Network Structure |
|---|---|---|
| 00 | 514.13 | 0110011000|0001001001 |
| 01 | 514.13 | 0110011000|0001001001 |
| 03 | 536.76 | 0110011100|0001001001 |
| 05 | 548.55 | 0110011101|0000101001 |
| 08 | 548.55 | 0110011101|0000101001 |
| 10 | 548.55 | 0110011101|0000101001 |
| 30 | 551.22 | 0111011101|0000101011 |
| 50 | 574.82 | 0111100010|0000101010 |
| 80 | 574.82 | 0111100010|0000101010 |
| 100 | 575.37 | 0110110010|0000101111 |
| Generations | Best Fitness | Network Structure |
|---|---|---|
| 00 | 1722.22 | 0010111110|0000001101 |
| 01 | 1909.79 | 0101111000|0000010101 |
| 03 | 1919.86 | 0010111101|0001011110 |
| 05 | 1967.90 | 0111000111|0001011101 |
| 08 | 2043.25 | 0111110011|0000010110 |
| 10 | 2043.25 | 0111110011|0000010110 |
| 30 | 2043.25 | 0111110011|0000010110 |
| 50 | 2053.95 | 0111110111|0000010110 |
| 80 | 2058.13 | 0110110111|0000010100 |
| 100 | 2058.13 | 0110110111|0000010100 |
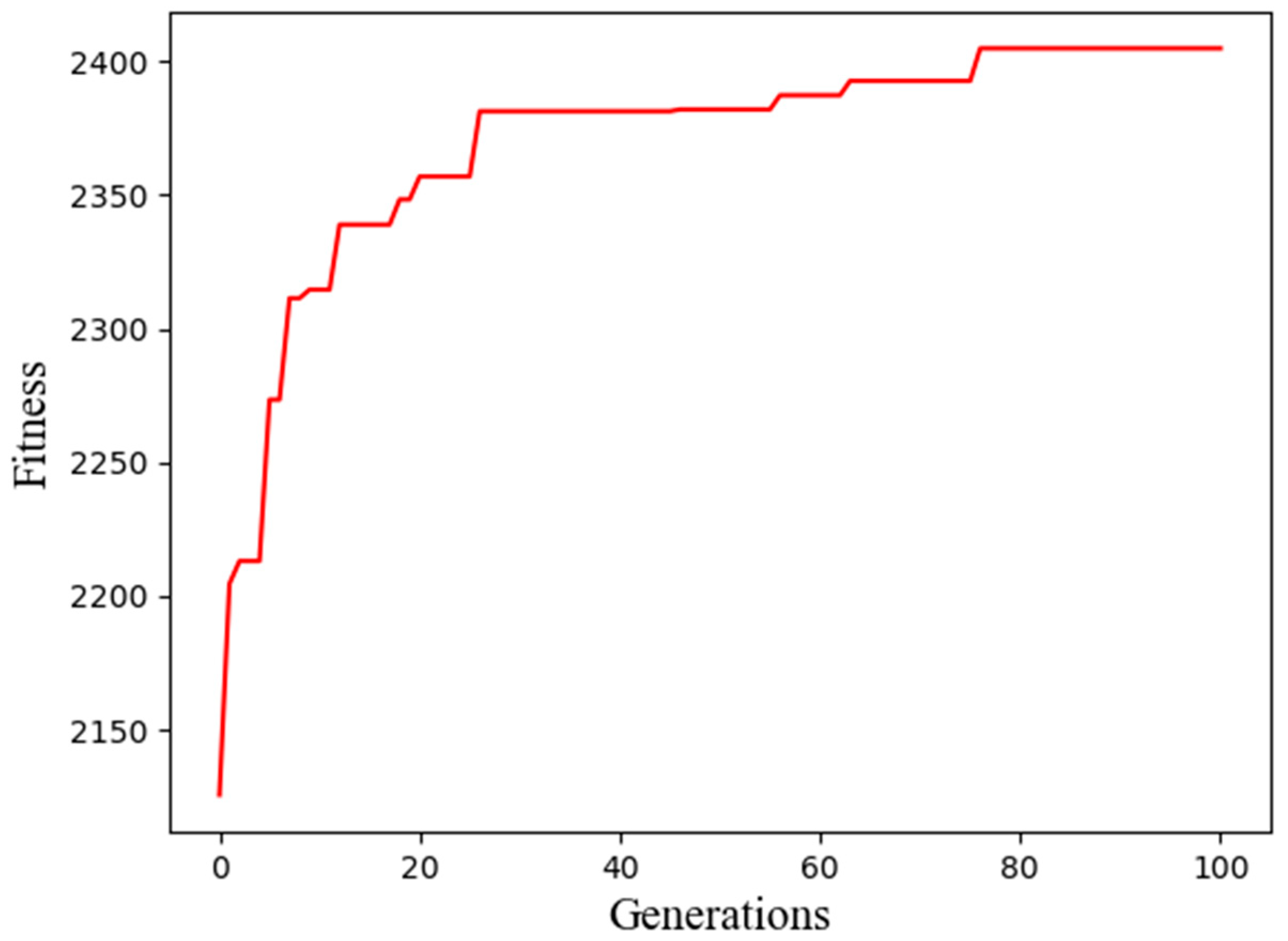
| Generations | Best Fitness | Network Structure |
|---|---|---|
| 00 | 2125.73 | 0010111000|0001000010 |
| 01 | 2204.67 | 0011101111|0000101111 |
| 03 | 2213.15 | 0010010110|0000110010 |
| 05 | 2273.15 | 0011101011|0000101011 |
| 08 | 2311.43 | 0011101011|0000100001 |
| 10 | 2311.43 | 0110010110|0000101001 |
| 30 | 2381.33 | 0111011101|0000100010 |
| 50 | 2382.01 | 0111110011|0000011010 |
| 80 | 2404.84 | 0111100111|0000011011 |
| 100 | 2404.84 | 0111100111|0000011011 |
| Air Pollutant | RMSE | SMAPE | ||||
|---|---|---|---|---|---|---|
| GRU1 | GRU2 | GRU_GA | GRU1 | GRU2 | GRU_GA | |
| PM10 | 0.0264 | 0.0647 | 0.0224 | 0.0870 | 0.1937 | 0.0855 |
| PM2.5 | 0.0136 | 0.0392 | 0.0078 | 0.0699 | 0.3041 | 0.0678 |
| SO2 | 0.0067 | 0.0065 | 0.0035 | 0.0154 | 0.2734 | 0.0143 |
| NO2 | 0.0076 | 0.0202 | 0.0068 | 0.0974 | 0.3835 | 0.0959 |
| CO | 0.0088 | 0.0003 | 0.0001 | 0.0007 | 0.0014 | 0.0007 |
| O3 | 0.0087 | 0.0359 | 0.0088 | 0.0759 | 0.3608 | 0.0761 |
| Air Pollutant | RMSE | SMAPE | ||||
|---|---|---|---|---|---|---|
| GRU1 | GRU2 | GRU_GA | GRU1 | GRU2 | GRU_GA | |
| PM10 | 0.0388 | 0.0722 | 0.0339 | 0.1286 | 0.2307 | 0.1297 |
| PM2.5 | 0.0066 | 0.0330 | 0.0057 | 0.0777 | 0.3650 | 0.0692 |
| SO2 | 0.0025 | 0.0029 | 0.0023 | 0.0136 | 0.0150 | 0.0127 |
| NO2 | 0.0078 | 0.0186 | 0.0075 | 0.1045 | 0.2195 | 0.1035 |
| CO | 0.0004 | 0.0003 | 0.0004 | 0.0020 | 0.0016 | 0.0022 |
| O3 | 0.0119 | 0.0441 | 0.0115 | 0.1003 | 0.2164 | 0.0978 |
| Air Pollutant | RMSE | SMAPE | ||||
|---|---|---|---|---|---|---|
| GRU1 | GRU2 | GRU_GA | GRU1 | GRU2 | GRU_GA | |
| PM10 | 0.0273 | 0.0652 | 0.0208 | 0.0865 | 0.2136 | 0.0854 |
| PM2.5 | 0.0085 | 0.0425 | 0.0078 | 0.0740 | 0.3270 | 0.0701 |
| SO2 | 0.0045 | 0.0054 | 0.0028 | 0.0195 | 0.0285 | 0.0160 |
| NO2 | 0.0082 | 0.0246 | 0.0084 | 0.1035 | 0.3859 | 0.0971 |
| CO | 0.0003 | 0.0003 | 0.0022 | 0.0014 | 0.0016 | 0.0015 |
| O3 | 0.0099 | 0.0430 | 0.0100 | 0.0874 | 0.3124 | 0.0895 |
| Air Pollutant | RMSE | SMAPE | ||||||
|---|---|---|---|---|---|---|---|---|
| SVM | RNN | LSTM | GRU_GA | SVM | RNN | LSTM | GRU_GA | |
| PM10 | 0.6732 | 0.6471 | 0.6470 | 0.0224 | 0.1936 | 0.1937 | 0.1837 | 0.0855 |
| PM2.5 | 0.4031 | 0.3923 | 0.3921 | 0.0078 | 0.3031 | 0.3063 | 0.3041 | 0.0678 |
| SO2 | 0.0078 | 0.0066 | 0.0065 | 0.0035 | 0.0290 | 0.0285 | 0.0285 | 0.0143 |
| NO2 | 0.0215 | 0.0203 | 0.0202 | 0.0068 | 0.3711 | 0.3725 | 0.3617 | 0.0959 |
| CO | 0.0003 | 0.0003 | 0.0003 | 0.0001 | 0.0015 | 0.0012 | 0.0014 | 0.0007 |
| O3 | 0.0355 | 0.0358 | 0.0359 | 0.0088 | 0.3727 | 0.3601 | 0.3403 | 0.0761 |
| Air Pollutant | RMSE | SMAPE | ||||||
|---|---|---|---|---|---|---|---|---|
| SVM | RNN | LSTM | GRU_GA | SVM | RNN | LSTM | GRU_GA | |
| PM10 | 0.0722 | 0.0722 | 0.0722 | 0.0339 | 0.2306 | 0.2306 | 0.2307 | 0.0854 |
| PM2.5 | 0.0331 | 0.0330 | 0.0330 | 0.0057 | 0.3589 | 0.3659 | 0.3650 | 0.0701 |
| SO2 | 0.0030 | 0.0029 | 0.0031 | 0.0023 | 0.0151 | 0.0150 | 0.0150 | 0.0160 |
| NO2 | 0.0186 | 0.0187 | 0.0186 | 0.0075 | 0.2192 | 0.2341 | 0.2195 | 0.0971 |
| CO | 0.0003 | 0.0004 | 0.0007 | 0.0004 | 0.0016 | 0.0033 | 0.0016 | 0.0015 |
| O3 | 0.0440 | 0.0441 | 0.0441 | 0.0115 | 0.2167 | 0.2173 | 0.2164 | 0.0895 |
| Air Pollutant | RMSE | SMAPE | ||||||
|---|---|---|---|---|---|---|---|---|
| SVM | RNN | LSTM | GRU_GA | SVM | RNN | LSTM | GRU_GA | |
| PM10 | 0.0651 | 0.0651 | 0.0652 | 0.0208 | 0.2130 | 0.2128 | 0.2133 | 0.0854 |
| PM2.5 | 0.0425 | 0.0425 | 0.0425 | 0.0078 | 0.3260 | 0.3270 | 0.3277 | 0.0701 |
| SO2 | 0.0054 | 0.0054 | 0.0055 | 0.0028 | 0.0284 | 0.0284 | 0.0291 | 0.0160 |
| NO2 | 0.0246 | 0.0246 | 0.0247 | 0.0084 | 0.1673 | 0.1681 | 0.2837 | 0.0955 |
| CO | 0.0003 | 0.0003 | 0.0006 | 0.0022 | 0.0016 | 0.0016 | 0.0028 | 0.0015 |
| O3 | 0.0430 | 0.0430 | 0.0431 | 0.0100 | 0.3132 | 0.3139 | 0.3150 | 0.0895 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, C.; Zheng, Z.; Zheng, S.; Wang, X.; Xie, X.; Wen, D.; Zhang, L.; Zhang, Y. Accurate Air-Quality Prediction Using Genetic-Optimized Gated-Recurrent-Unit Architecture. Information 2022, 13, 223. https://doi.org/10.3390/info13050223
Ding C, Zheng Z, Zheng S, Wang X, Xie X, Wen D, Zhang L, Zhang Y. Accurate Air-Quality Prediction Using Genetic-Optimized Gated-Recurrent-Unit Architecture. Information. 2022; 13(5):223. https://doi.org/10.3390/info13050223
Chicago/Turabian StyleDing, Chen, Zhouyi Zheng, Sirui Zheng, Xuke Wang, Xiaoyan Xie, Dushi Wen, Lei Zhang, and Yanning Zhang. 2022. "Accurate Air-Quality Prediction Using Genetic-Optimized Gated-Recurrent-Unit Architecture" Information 13, no. 5: 223. https://doi.org/10.3390/info13050223
APA StyleDing, C., Zheng, Z., Zheng, S., Wang, X., Xie, X., Wen, D., Zhang, L., & Zhang, Y. (2022). Accurate Air-Quality Prediction Using Genetic-Optimized Gated-Recurrent-Unit Architecture. Information, 13(5), 223. https://doi.org/10.3390/info13050223