
Finding Optimal Moving Target Defense Strategies: A Resilience Booster for Connected Cars


Abstract
:1. Introduction
- A game theoretic model for the defense of CRESs;
- A resolution method based on the transformation to an MILP problem;
- A complete methodology to define the input parameters of the presented model;
- An experimental case study for a typical connected car architecture,
2. Background
2.1. Moving Target Defense
- Runtime environment (e.g., modify the operating system’s address space layout);
- Data (e.g., modify data representation in memory);
- Software (e.g., switching between multiple implementations of the same services);
- Network (e.g., switching between multiple active IP addresses and open ports and modifying the network topology).
2.2. Game-Theoretic Concepts
- Simultaneous games in which the players choose their respective actions at the same time without knowing in advance the choices of the other players.
- Sequential games in which the players are playing in a (fixed) order, such that all other players can observe the first player’s action before making a decision.
2.3. Complementary Slackness
2.4. Security Risk Analysis
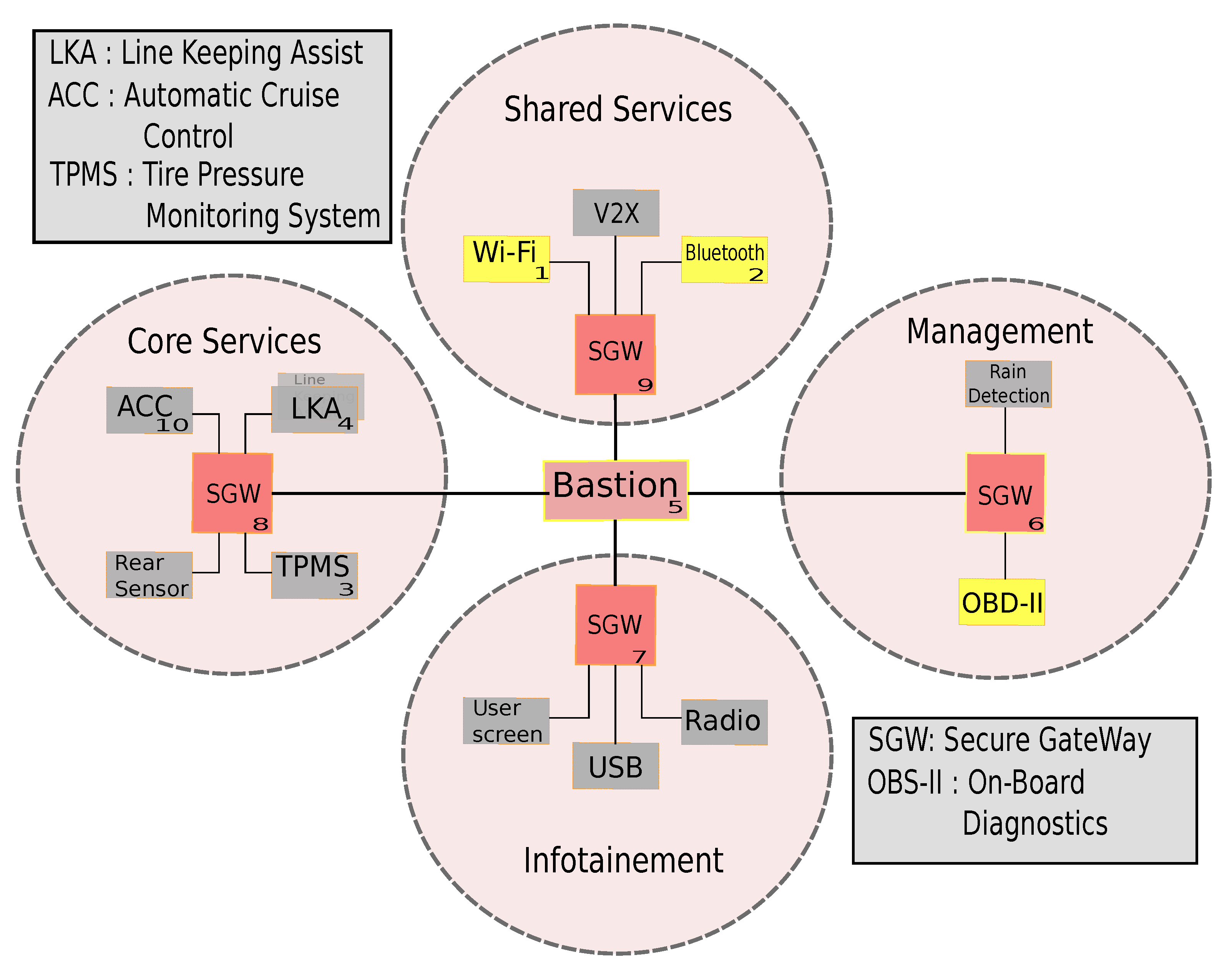
3. Motivating Example
- Infotainment: services related to the user experience such as the radio, the on-board screen, and various applications accessible to the user.
- Core Services: critical services for the operation of the vehicle such as cruise control, brake controls, or lane-keeping assistant.
- Management: services dedicated to diagnostics and updates of the vehicle, such as the On-Board Diagnostic (OBD-II) plug.
- Shared Services: regroups services allowing communication with the outside world (V2X), as well as some services shared among several domains.
4. Model
4.1. Model Structure
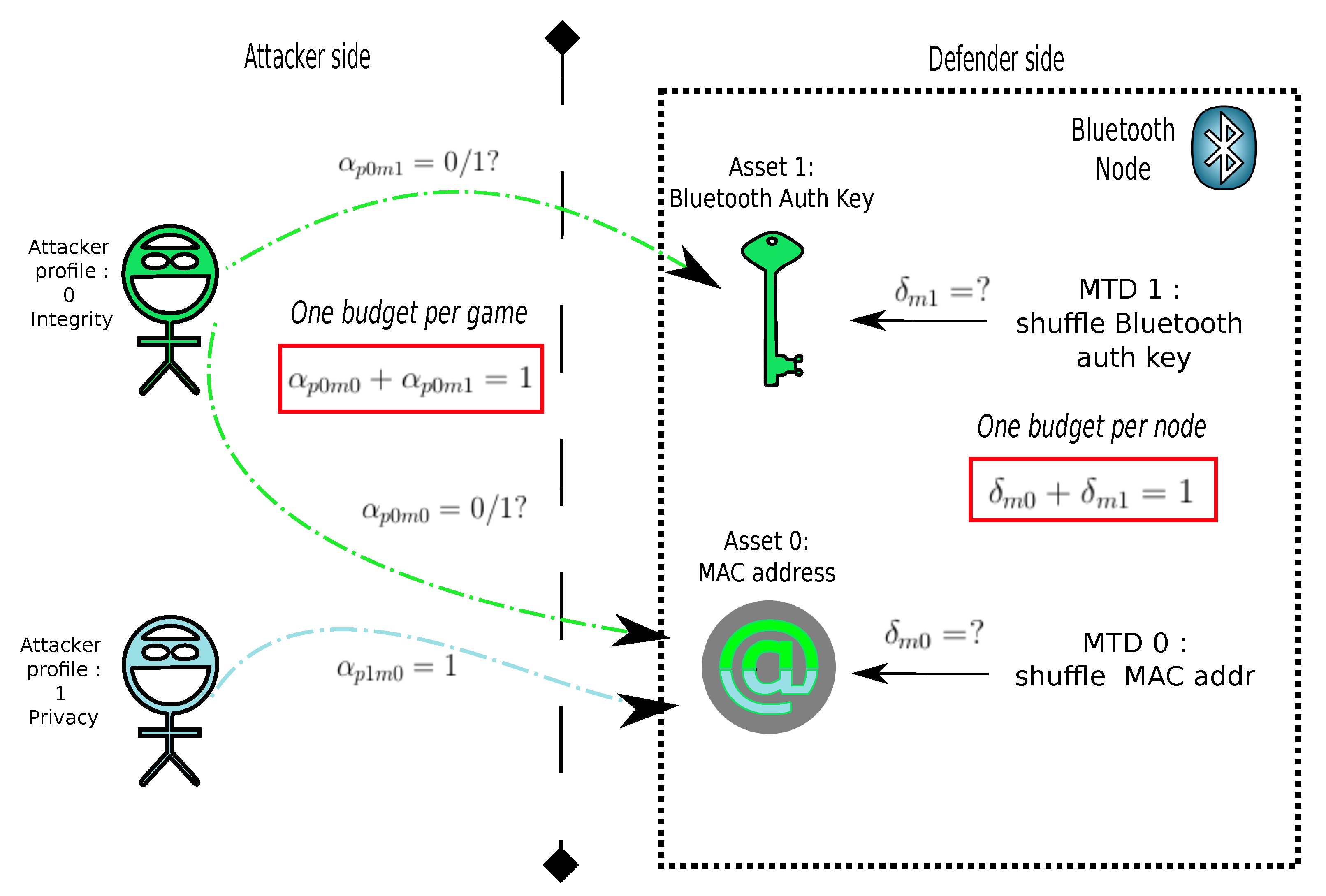
- : the set of nodes of the system under attack.
- : the set of MTDs present on node i.
- : the set of attacker profiles.
- : reward obtained by the defender when he/she chooses to use the MTD m on node n while the attacker p targets the MTD on node .
- : reward obtained by the attacker p when she/he chooses to target the MTD on the node while the defender will defend the node n with the MTD m.
- : the strategy of the defender on the node n and its MTD m.
- : the strategy of the attacker of profile p on the MTD of node .
4.2. Input Parameters
| Success probability of attacker profile p on node n when MTD m is used. | |
| Attacker profile p interested in node n. | |
| Cost for the attacker of type p to attack MTD m on node n. | |
| Probability of encountering attacker profile p. |
| Defender interest in node n when the attacker profile p targets it. | |
| Defender cost to use the MTD m on node n. |
4.3. How to Determine the Parameters
- The entropy value associated with each element that we want to protect by an MTD. This corresponds, e.g., to the number of valid IP addresses that can be used or the number of MAC addresses available for an element.
- The CVSS score associated with each asset of the system we are considering in the game. This will allow us to know the interest that one of the players may have in this node: the more vulnerable it is, the more it may interest an attacker. This score is computed by taking into account the difficulty of accessing a specific resource and the requirements to launch an attack.
- For each MTD, the time during which the corresponding service is not accessible if the defense is used.
- For each attacker profile and information to protect, the time needed for an attacker to scan an occurrence of the information.
- For each node, the associated reconfiguration period.
4.3.1. Success Probability:
- When the MTD m used is of type shuffle, we apply the urn statistical model [29], to solve the problem of drawing with replacement. In our case, the number of attempts is equal to the node period divided by the time needed to scan one configuration. The formulation of this problem is given by Equation (3), where x is the number of attempts, h is the number of instances of the asset, and a is the number of available values. The probability of finding the information can then be calculated as
- When the MTD m is not of shuffle type and a method to bypass this MTD exists, the attacker’s success probability is equal to the duration of the reconfiguration period of the node n divided by the time to bypass the MTD. If the duration of a period is greater, the attacker’s success probability is equal to 1.
- When the MTD m used is neither of type shuffle nor has a method to bypass, we will need to resort to an ad hoc method to estimate the success probability.
4.3.2. Attacker Gain:
4.3.3. Attack Cost:
4.3.4. Attacker Appearance Probability:
4.3.5. Defender Node Gain:
4.3.6. MTD Usage Cost:
5. Game Formalization
5.1. Game Form
5.2. Reward
- If the attacker p and the defender target the same nodes n and and MTDs m and at the same time, the associated gain for the attacker is 0.
- If the attacker p and the defender do not target the same nodes n and and MTDs m and , the associated gain for the attacker p is equal to his/her success probability multiplied by his/her interest in the node .
- If the attacker p and the defender target the same nodes n and and MTDs m and at the same time, the associated gain for the defender is equal to the probability of success of the attacker p multiplied by the interest of the defender in the node.
- If the attacker p and the defender do not target the same nodes n and and MTDs m and , the associated gain for the defender is equal to 0.
5.3. Payoff Function
5.4. Optimal Attack Strategy
5.5. Mixed-Integer Quadratic Program
6. Game Resolution
6.1. MIQP to MILP Transformation
6.2. Correspondence between the MIQP and the MILP
7. Experimental Results
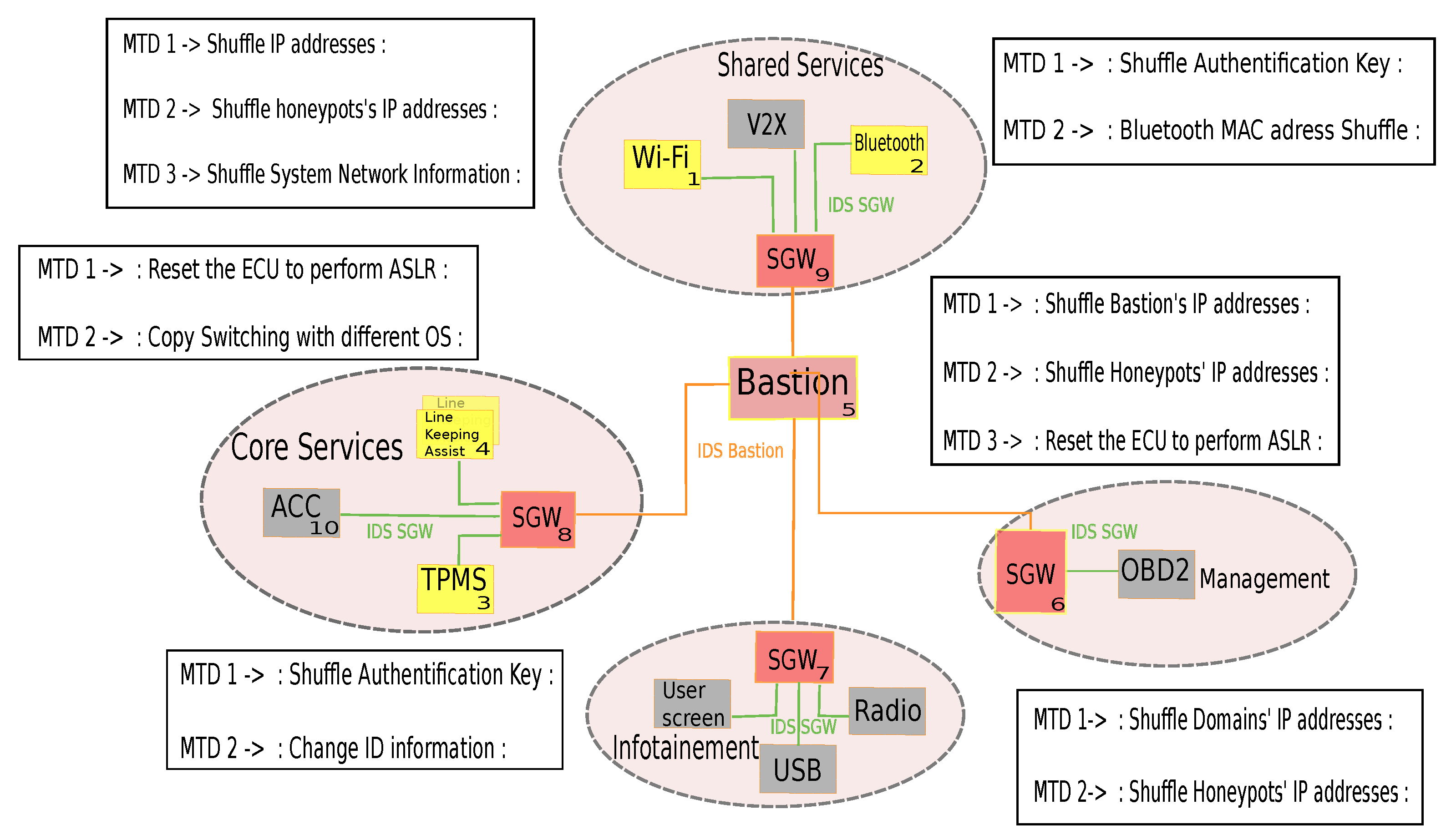
7.1. Automotive Use Case
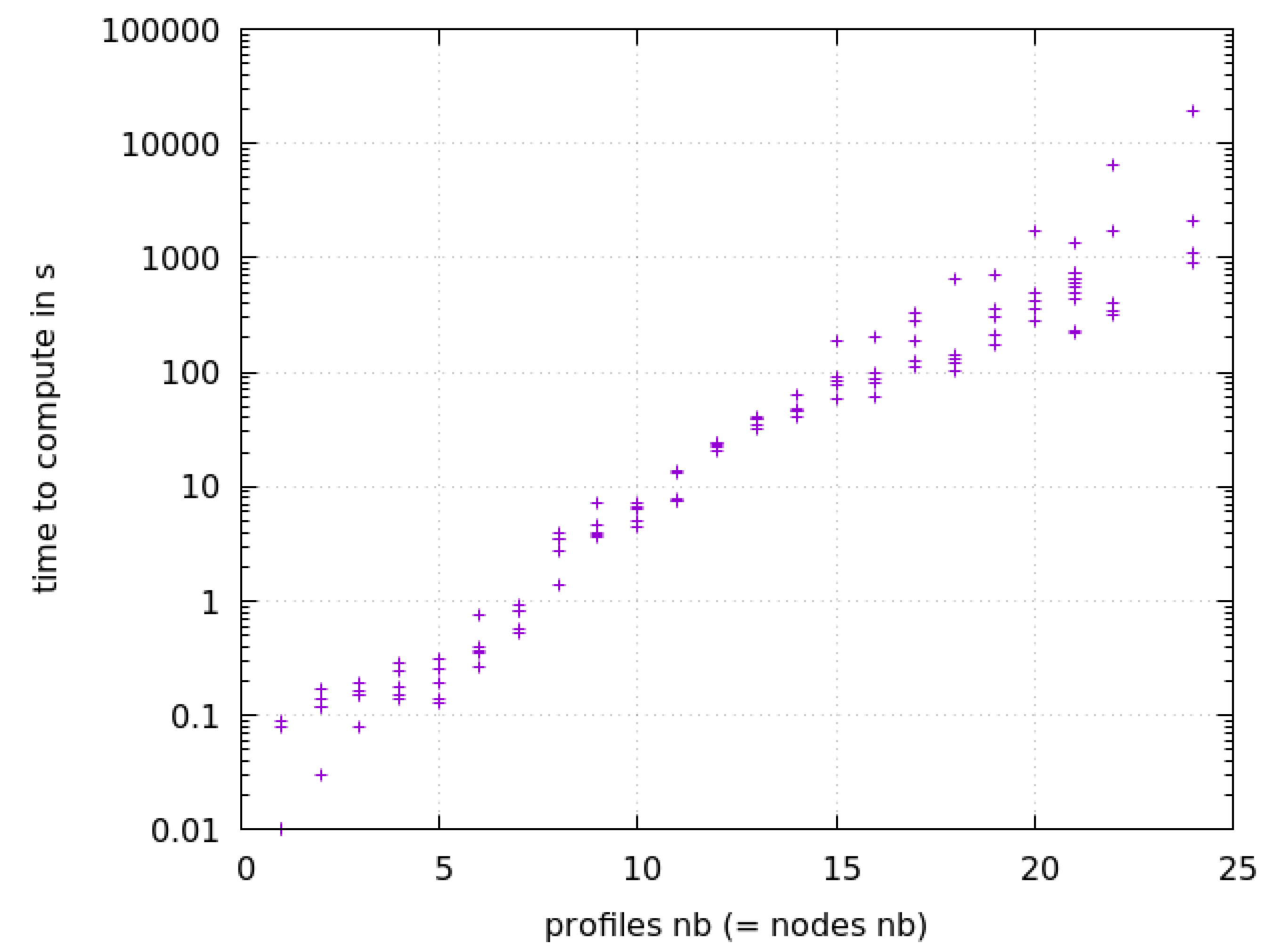
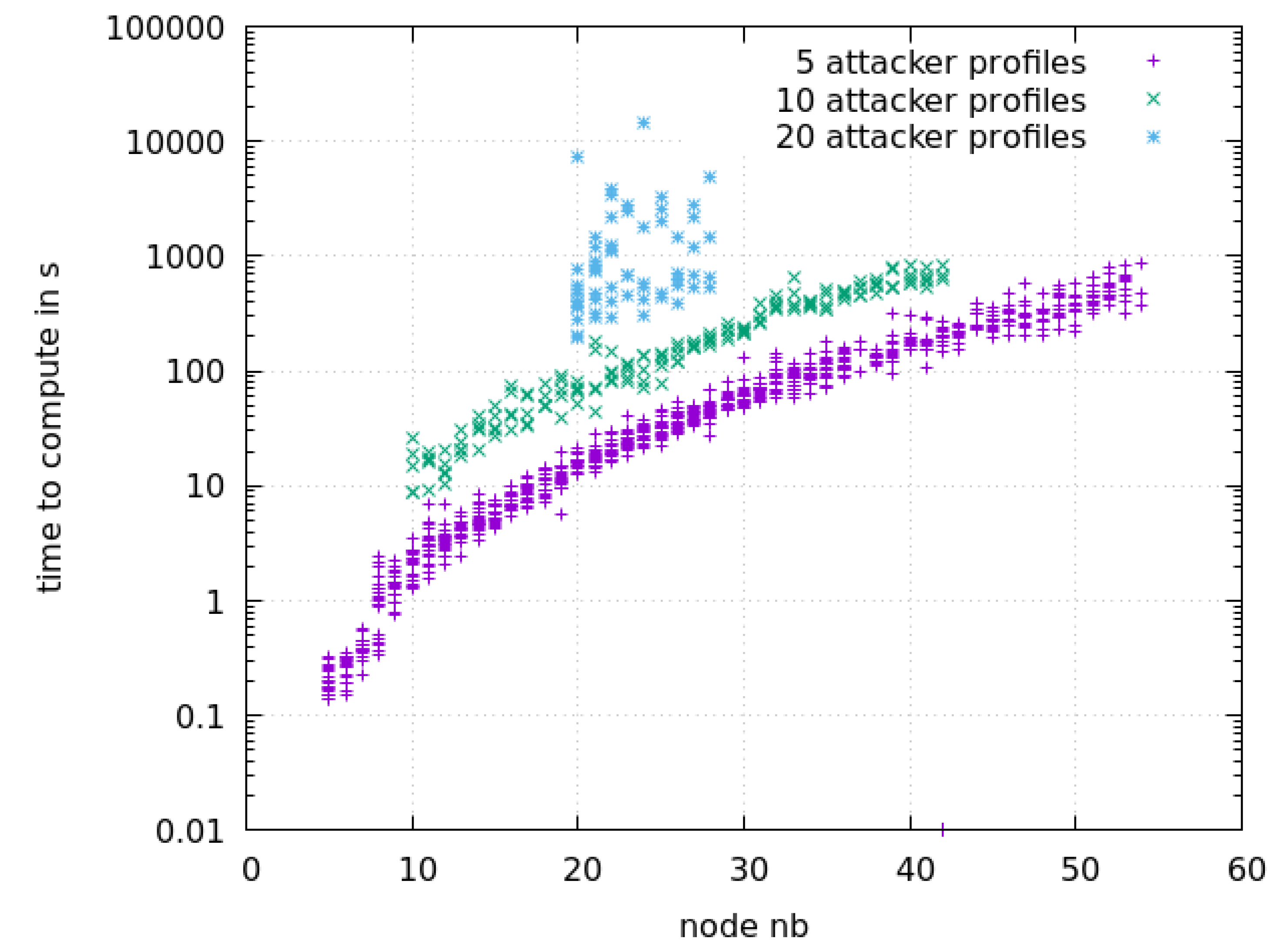
7.2. Scalability
7.2.1. Random Scenarios
7.2.2. Fixed Attacker Profiles
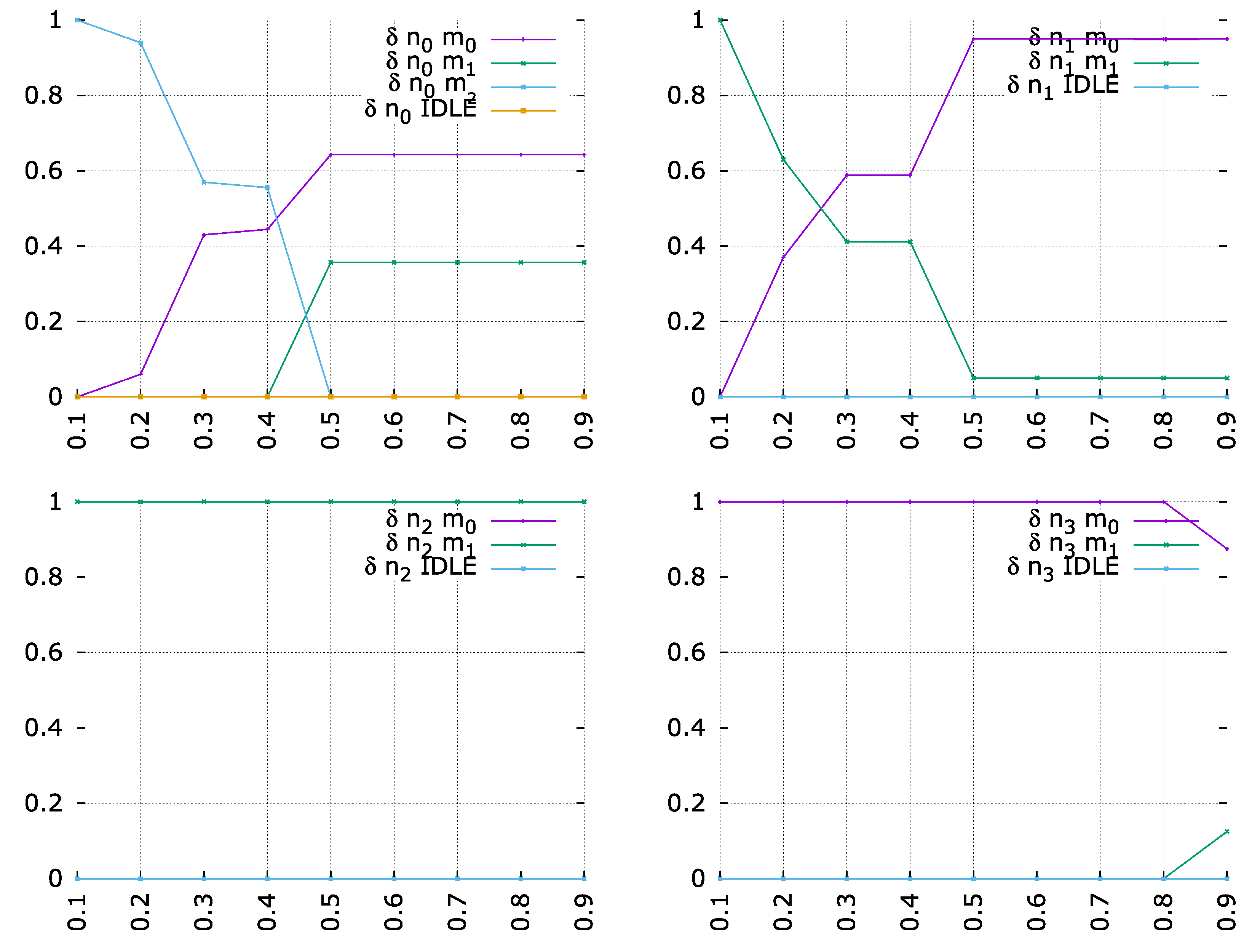
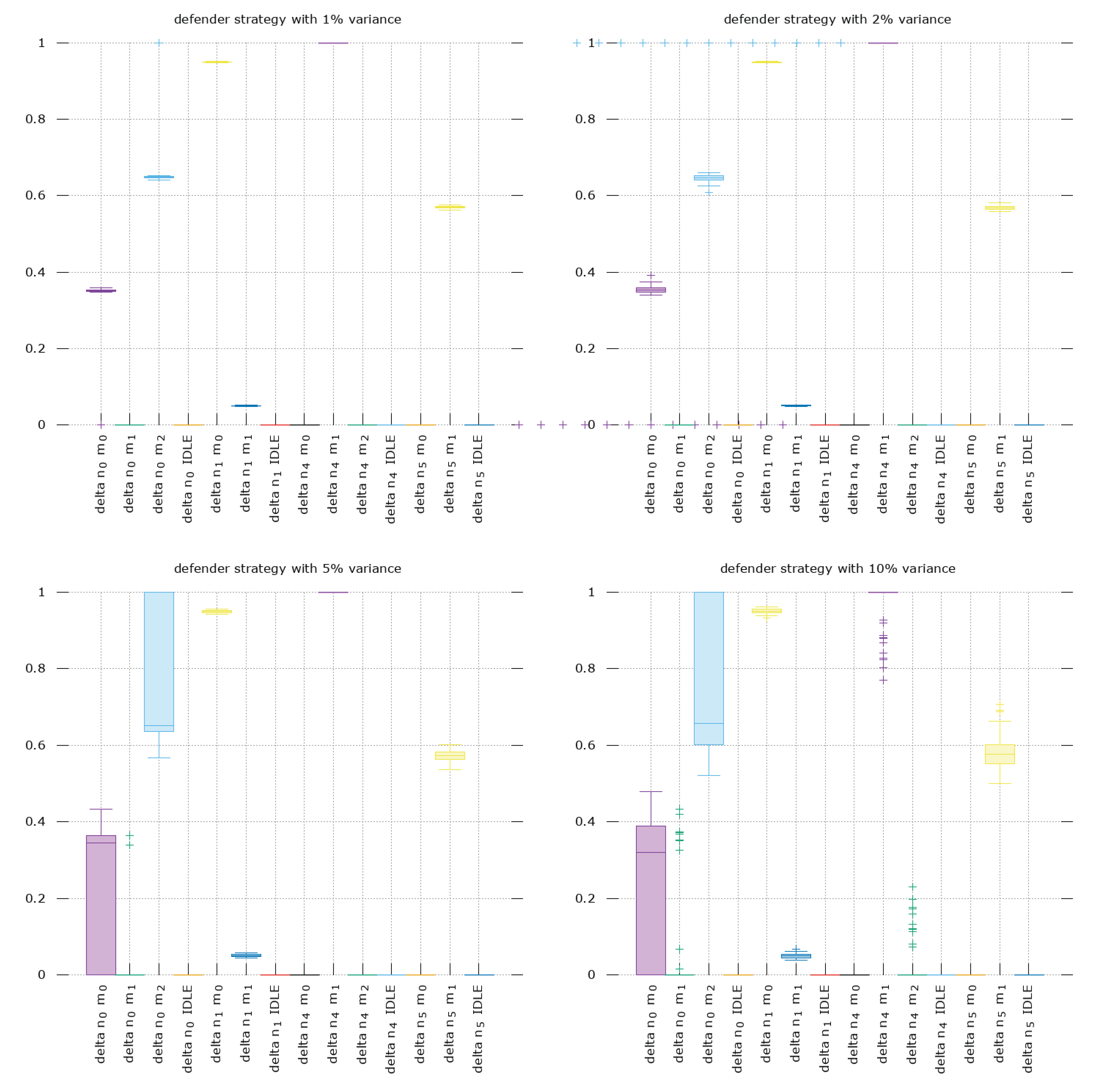
7.3. Stability Analysis
8. Discussion and Limitations
9. Related Work
10. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Smith, C. The Car Hacker’s Handbook: A Guide for the Penetration Tester; No Starch Press: San Francisco, CA, USA, 2016; 278p, ISBN 978-1-59327-703-1. [Google Scholar]
- Xu, J.; Guo, P.; Zhao, M.; Erbacher, R.F.; Zhu, M.; Liu, P. Comparing Different Moving Target Defense Techniques. Proc. ACM Conf. Comput. Commun. Secur. 2014, 2014, 97–107. [Google Scholar] [CrossRef]
- Taylor, J.; Zaffarano, K.; Koller, B.; Bancroft, C.; Syversen, J. Automated Effectiveness Evaluation of Moving Target Defenses: Metrics for Missions and Attacks. In Proceedings of the 2016 ACM Workshop on Moving Target Defense—MTD’16, Vienna, Austria, 24 October 2016. [Google Scholar]
- Burow, N.; Burrow, R.; Khazan, R.; Shrobe, H.; Ward, B.C. Moving Target Defense Considerations in Real-Time Safety- and Mission-Critical Systems. In Proceedings of the 7th ACM Workshop on Moving Target Defense, Online, 9–13 November 2020; pp. 81–89. [Google Scholar]
- Lei, C.; Ma, D.; Zhang, H. Optimal Strategy Selection for Moving Target Defense Based on Markov Game. IEEE Access 2017, 5, 156–169. [Google Scholar] [CrossRef]
- Sengupta, S.; Vadlamudi, S.G.; Kambhampati, S.; Doupé, A.; Zhao, Z.; Taguinod, M.; Ahn, G.J. A Game Theoretic Approach to Strategy Generation for Moving Target Defense in Web Applications. In Proceedings of the 16th International Conference on Autonomous Agents and Multiagent Systems, Rhodes, Greece, 20–22 June 2017; p. 9. [Google Scholar]
- Feng, X.; Zheng, Z.; Mohapatra, P.; Cansever, D. A Stackelberg Game and Markov Modeling of Moving Target Defense. In Decision and Game Theory for Security; Rass, S., An, B., Kiekintveld, C., Fang, F., Schauer, S., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 315–335. [Google Scholar]
- Li, H.; Zheng, Z. Optimal Timing of Moving Target Defense: A Stackelberg Game Model. arXiv 2019, arXiv:1905.13293. [Google Scholar]
- Zhang, H.; Zheng, K.; Wang, X.; Luo, S.; Wu, B. Strategy Selection for Moving Target Defense in Incomplete Information Game. Comput. Mater. Contin. 2019, 61, 763–786. [Google Scholar] [CrossRef]
- Hong, J.B.; Kim, D.S. Assessing the Effectiveness of Moving Target Defenses Using Security Models. IEEE Trans. Dependable Secur. Comput. 2015, 13, 163–177. [Google Scholar] [CrossRef]
- Paruchuri, P.; Pearce, J.P.; Marecki, J.; Tambe, M.; Ordonez, F.; Kraus, S. Playing Games for Security: An Efficient Exact Algorithm for Solving Bayesian Stackelberg Games. In Proceedings of the 7th International Joint Conference on Autonomous Agents and Multiagent Systems (AAMAS ’08), Estoril, Portugal, 14–16 May 2008; International Foundation for Autonomous Agents and Multiagent Systems: Richland, SC, USA, 2008; Volume 2, pp. 895–902. [Google Scholar]
- Ayrault, M.; Borde, E.; Kühne, U.; Leneutre, J. Moving Target Defense Strategy in Critical Embedded Systems: A Game-theoretic Approach. In Proceedings of the 2021 IEEE 26th Pacific Rim International Symposium on Dependable Computing (PRDC), Perth, Australia, 1–4 December 2021; pp. 27–36. [Google Scholar] [CrossRef]
- Lei, C.; Zhang, H.Q.; Tan, J.L.; Zhang, Y.C.; Liu, X.H. Moving Target Defense Techniques: A Survey. Secur. Commun. Netw. 2018, 2018, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Cai, G.L.; Wang, B.S.; Hu, W.; Wang, T.Z. Moving target defense: State of the art and characteristics. Front. Inf. Technol. Electron. Eng. 2016, 17, 1122–1153. [Google Scholar] [CrossRef] [Green Version]
- Okhravi, H.; Rabe, M.A.; Mayberry, T.J.; Leonard, W.G.; Hobson, T.R.; Bigelow, D.; Streilein, W.W. Survey of Cyber Moving Target Techniques; Technical Report; Defense Technical Information Center: Fort Belvoir, VA, USA, 2013. [Google Scholar]
- Okhravi, H.; Hobson, T.; Bigelow, D.; Streilein, W. Finding Focus in the Blur of Moving-Target Techniques. IEEE Secur. Priv. 2014, 12, 16–26. [Google Scholar] [CrossRef]
- ’KARL—Kernel Address Randomized Link’—MARC. Available online: https://undeadly.org/cgi?action=article;sid=20170613041706 (accessed on 12 April 2022).
- Hund, R.; Holz, T.; Freiling, F.C. Return-Oriented Rootkits: Bypassing Kernel Code Integrity Protection Mechanisms. In Proceedings of the USENIX Security Symposium, Montreal, QC, Canada, 12–14 August 2009; p. 16. [Google Scholar]
- Ayrault, M.; Borde, E.; Kühne, U. Run or Hide? Both! A Method Based on IPv6 Address Switching to Escape While Being Hidden. In Proceedings of the 6th ACM Workshop on Moving Target Defense. Association for Computing Machinery, MTD′19, London, UK, 11 November 2019; pp. 47–56. [Google Scholar] [CrossRef]
- Prisner, E. Game Theory through Examples; MAA, The Mathematical Association of America: Washington, DC, USA, 2014; OCLC: 986787860. [Google Scholar]
- Brown, G.; Carlyle, M.; Salmerón, J.; Wood, K. Defending Critical Infrastructure. INFORMS J. Appl. Anal. 2006, 36, 530–544. [Google Scholar] [CrossRef] [Green Version]
- Harsanyi, J.C. Games with Incomplete Information Played by “Bayesian” Players, I–III Part I. The Basic Model. Manag. Sci. 1967, 14, 159–182. [Google Scholar] [CrossRef]
- Paruchuri, P.; Pearce, J.P.; Tambe, M.; Ordonez, F.; Kraus, S. An Efficient Heuristic Approach for Security Against Multiple Adversaries. In Proceedings of the 6th International Joint Conference on Autonomous Agents and Multiagent Systems, Honolulu, HI, USA, 14–18 May 2007; p. 8. [Google Scholar] [CrossRef]
- Harsanyi, J.C.; Selten, R. A Generalized Nash Solution for Two-Person Bargaining Games with Incomplete Information. Manag. Sci. 1972, 18, 80–106. [Google Scholar] [CrossRef]
- Agence Nationale de la Sécurité des Systèmes d’Information (ANSSI). EBIOS Risk Manager; Technical Report; ANSSI: Paris, France, 2019.
- Gadyatskaya, O.; Hansen, R.R.; Larsen, K.G.; Legay, A.; Olesen, M.C.; Poulsen, D.B. Modelling Attack-defense Trees Using Timed Automata. In Formal Modeling and Analysis of Timed Systems; Lecture Notes in Computer Science, Series; Fränzle, M., Markey, N., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; Volume 9884, pp. 35–50. [Google Scholar] [CrossRef] [Green Version]
- Common Vulnerability Scoring System version 3.1. 2021. Available online: https://www.first.org/cvss/v3-1/cvss-v31-specification_r1.pdf (accessed on 12 April 2022).
- Maghrabi, L.; Pfluegel, E.; Al-Fagih, L.; Graf, R.; Settanni, G.; Skopik, F. Improved software vulnerability patching techniques using CVSS and game theory. In Proceedings of the 2017 International Conference on Cyber Security And Protection of Digital Services (Cyber Security), London, UK, 19–20 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Carroll, T.E.; Crouse, M.; Fulp, E.W.; Berenhaut, K.S. Analysis of network address shuffling as a moving target defense. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, Australia, 10–14 June 2014; pp. 701–706. [Google Scholar]
- Lyon, G.F. Nmap Network Scanning: The Official Nmap Project Guide to Network Discovery and Security Scanning; Insecure.com LLC: Seattle, WA, USA, 2009. [Google Scholar]
- Conitzer, V.; Sandholm, T. Computing the optimal strategy to commit to. In Proceedings of the 7th ACM Conference on Electronic Commerce (EC ’06), Ann Arbor, MI, USA, 11–15 June 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 82–90. [Google Scholar]
- IBM. Overview of Mathematical Programming—IBM® Decision Optimization CPLEX® Modeling for Python (DOcplex) V2.23 Documentation. Available online: https://ibmdecisionoptimization.github.io/docplex-doc/mp.html (accessed on 12 April 2022).
- Connell, W.; Menasce, D.A.; Albanese, M. Performance Modeling of Moving Target Defenses with Reconfiguration Limits. IEEE Trans. Dependable Secur. Comput. 2021, 18, 205–219. [Google Scholar] [CrossRef] [Green Version]
- Thomas, M.U. Queueing Systems. Volume 1: Theory (Leonard Kleinrock). SIAM Rev. 1976, 18, 512–514. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Defend | Not Defend | |
|---|---|---|
| Attack | , | , |
| Not Attack | , | , |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ayrault, M.; Kühne, U.; Borde, É. Finding Optimal Moving Target Defense Strategies: A Resilience Booster for Connected Cars. Information 2022, 13, 242. https://doi.org/10.3390/info13050242
Ayrault M, Kühne U, Borde É. Finding Optimal Moving Target Defense Strategies: A Resilience Booster for Connected Cars. Information. 2022; 13(5):242. https://doi.org/10.3390/info13050242
Chicago/Turabian StyleAyrault, Maxime, Ulrich Kühne, and Étienne Borde. 2022. "Finding Optimal Moving Target Defense Strategies: A Resilience Booster for Connected Cars" Information 13, no. 5: 242. https://doi.org/10.3390/info13050242
APA StyleAyrault, M., Kühne, U., & Borde, É. (2022). Finding Optimal Moving Target Defense Strategies: A Resilience Booster for Connected Cars. Information, 13(5), 242. https://doi.org/10.3390/info13050242