
Enhanced Feature Pyramid Vision Transformer for Semantic Segmentation on Thailand Landsat-8 Corpus



Abstract
:1. Introduction
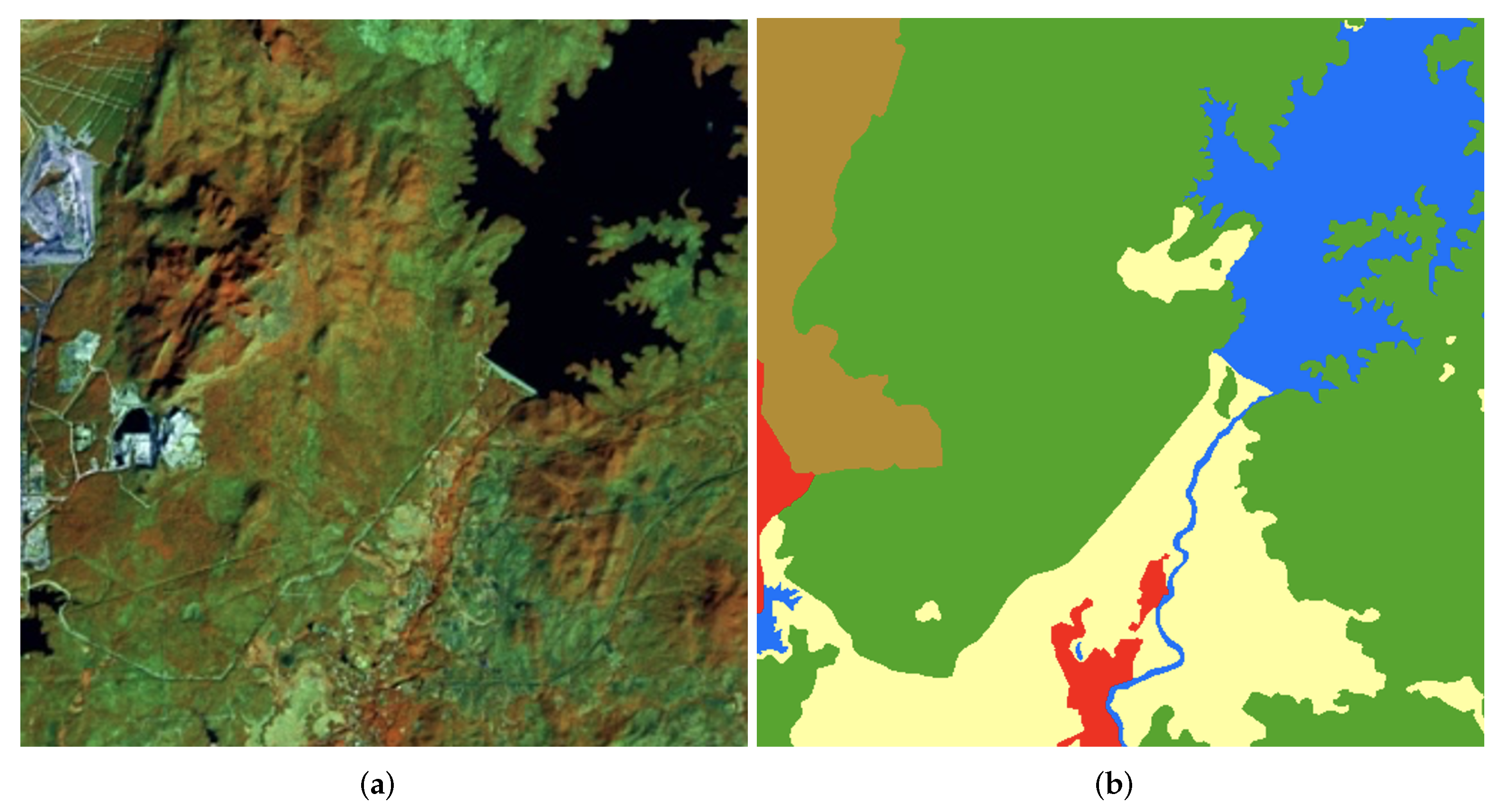
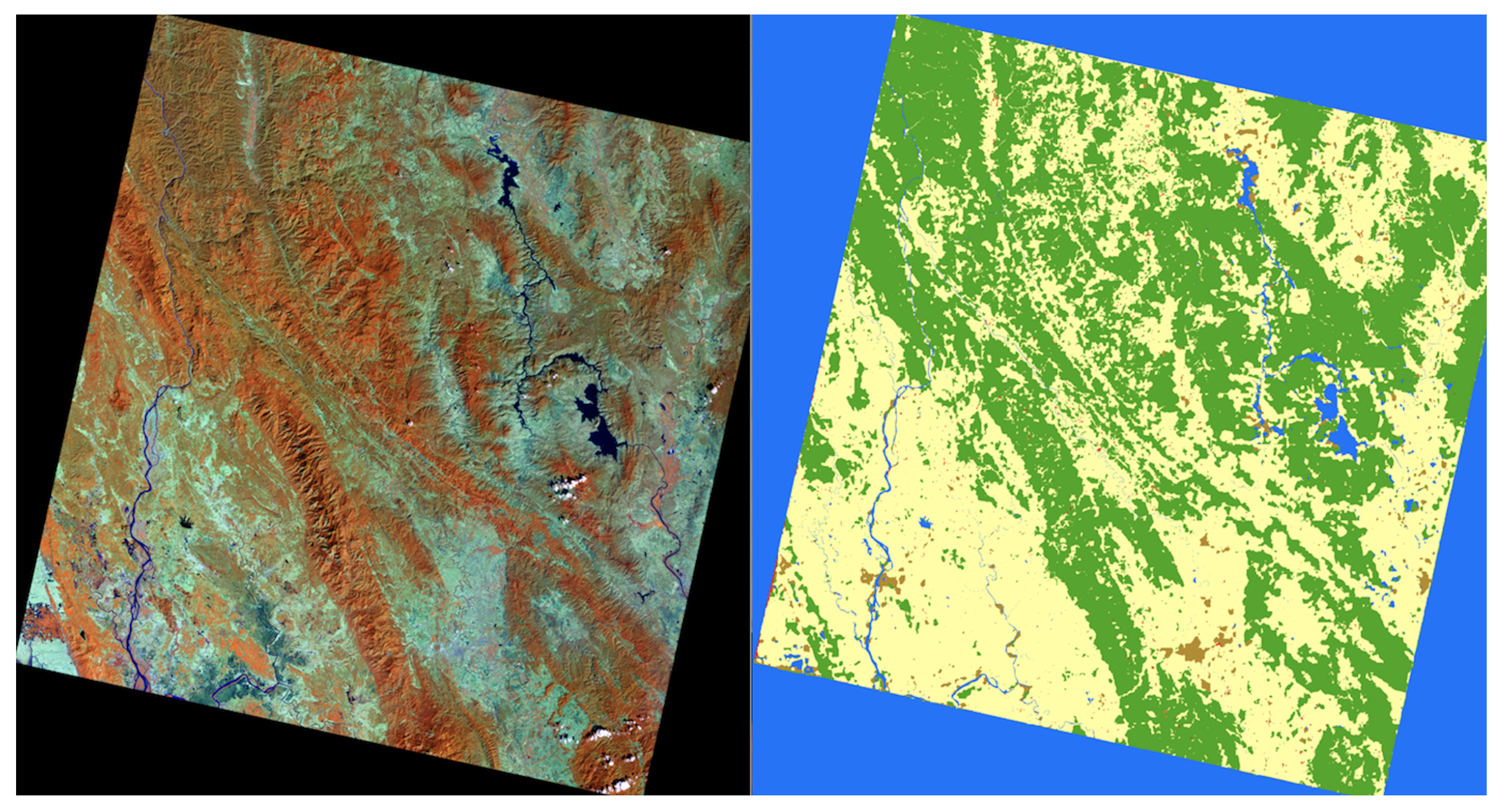
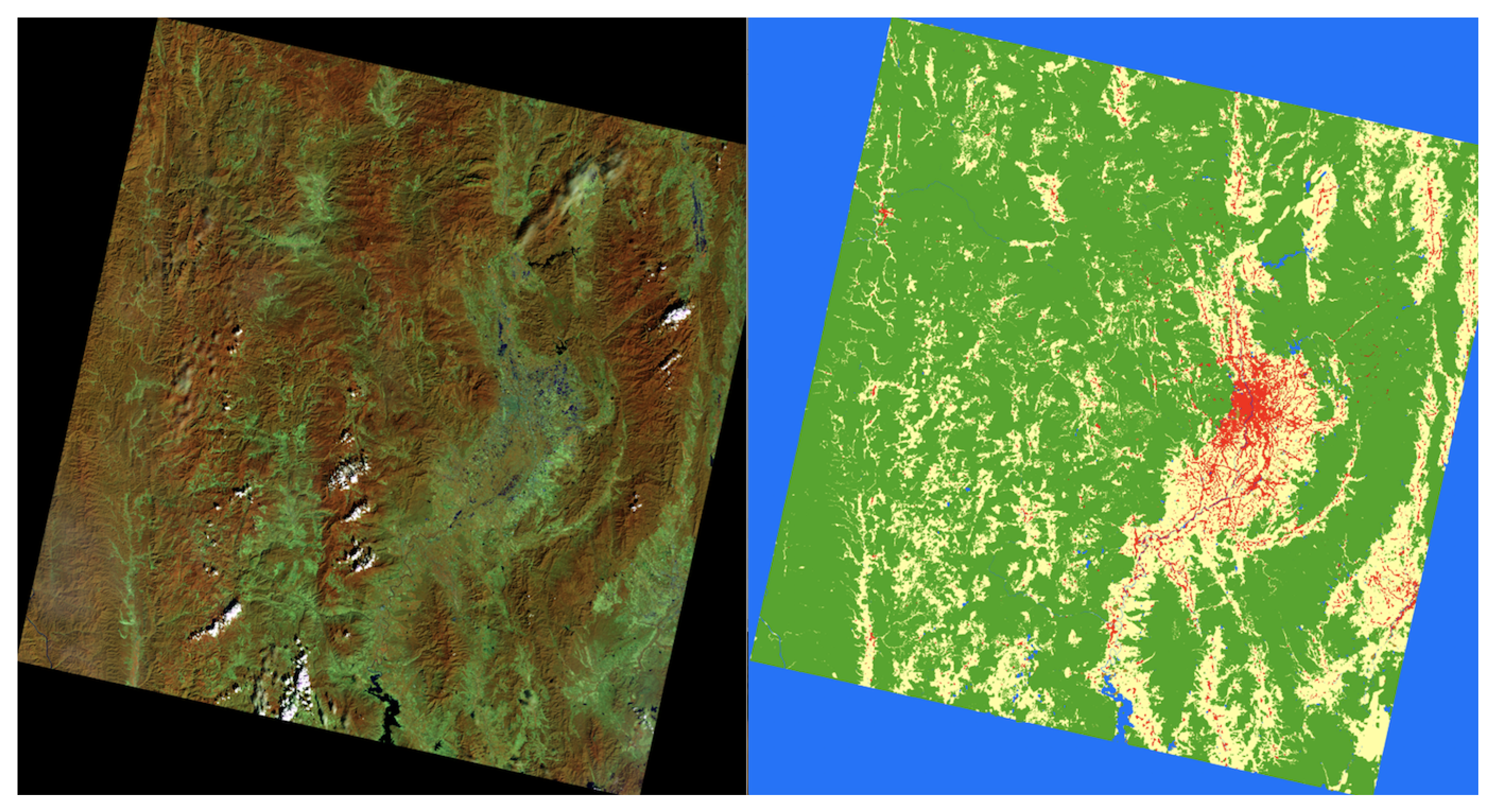
2. Data Collection
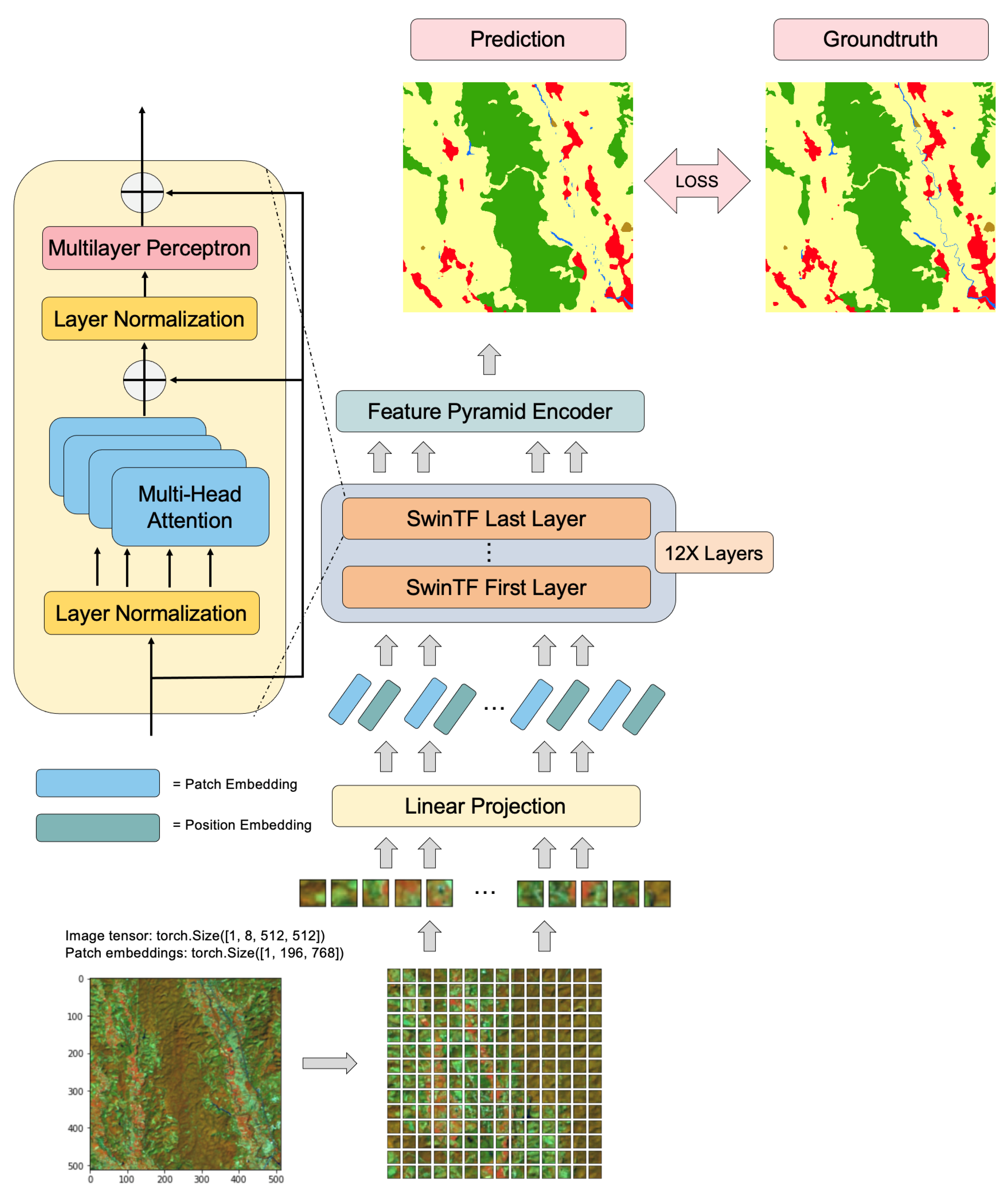
3. Proposed Method
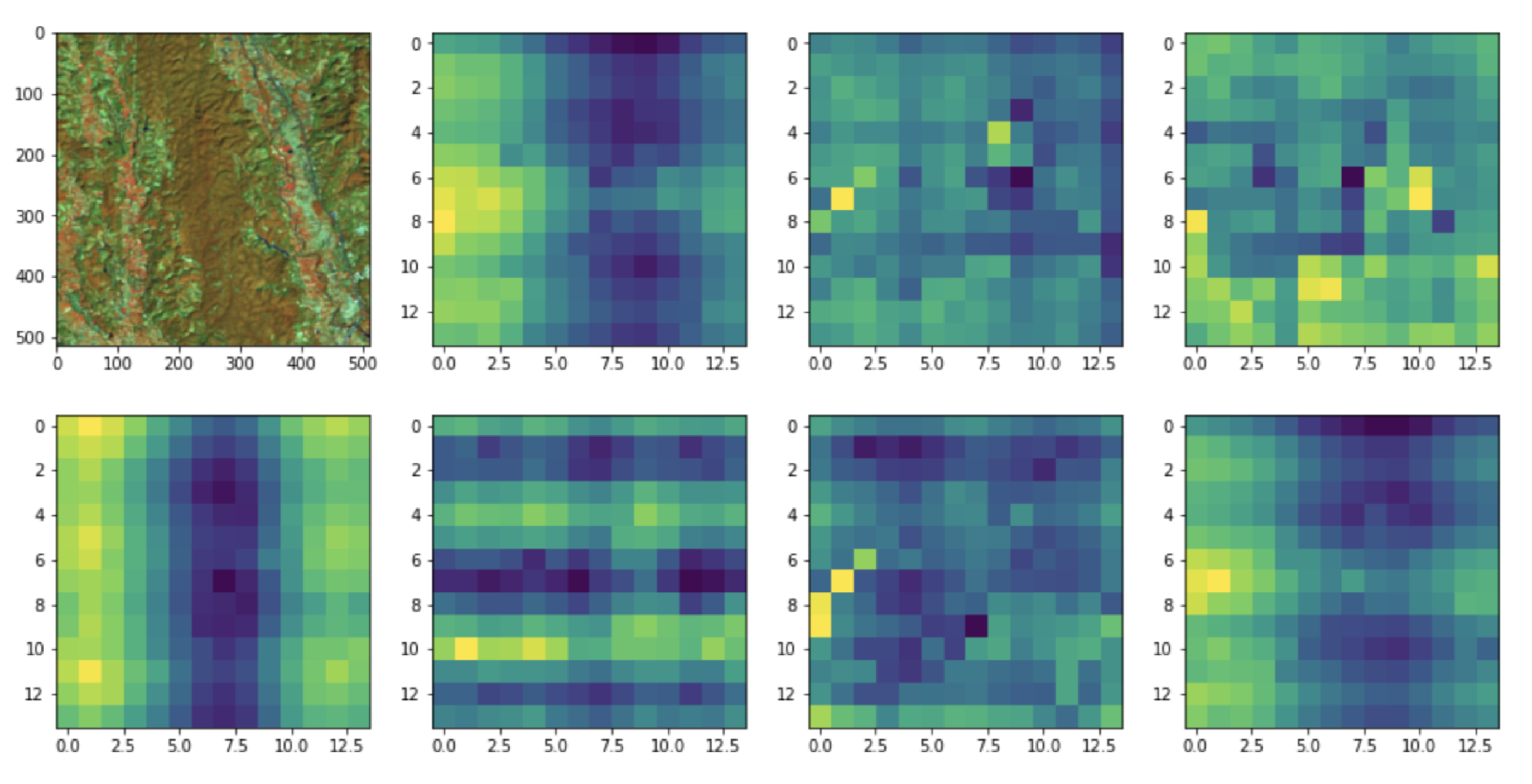
Pyramid Vision Transformer-Based Semantic Segmentation
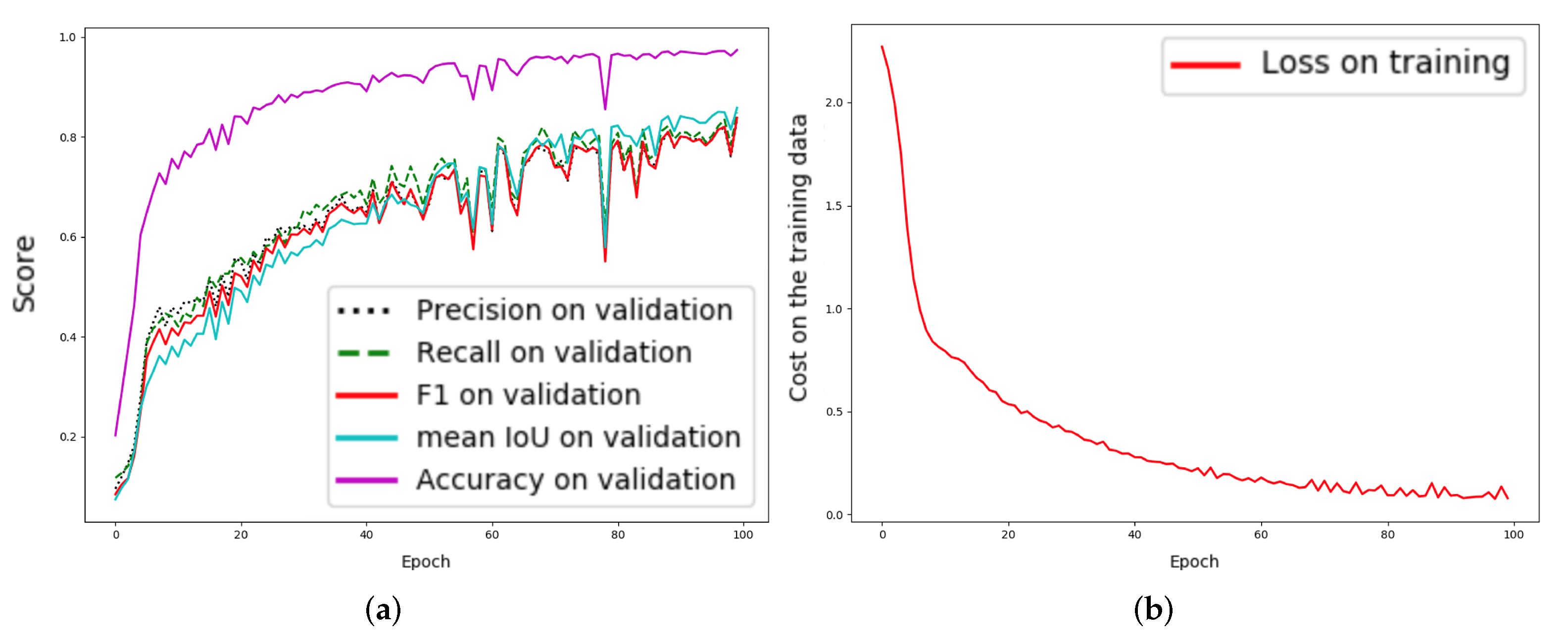
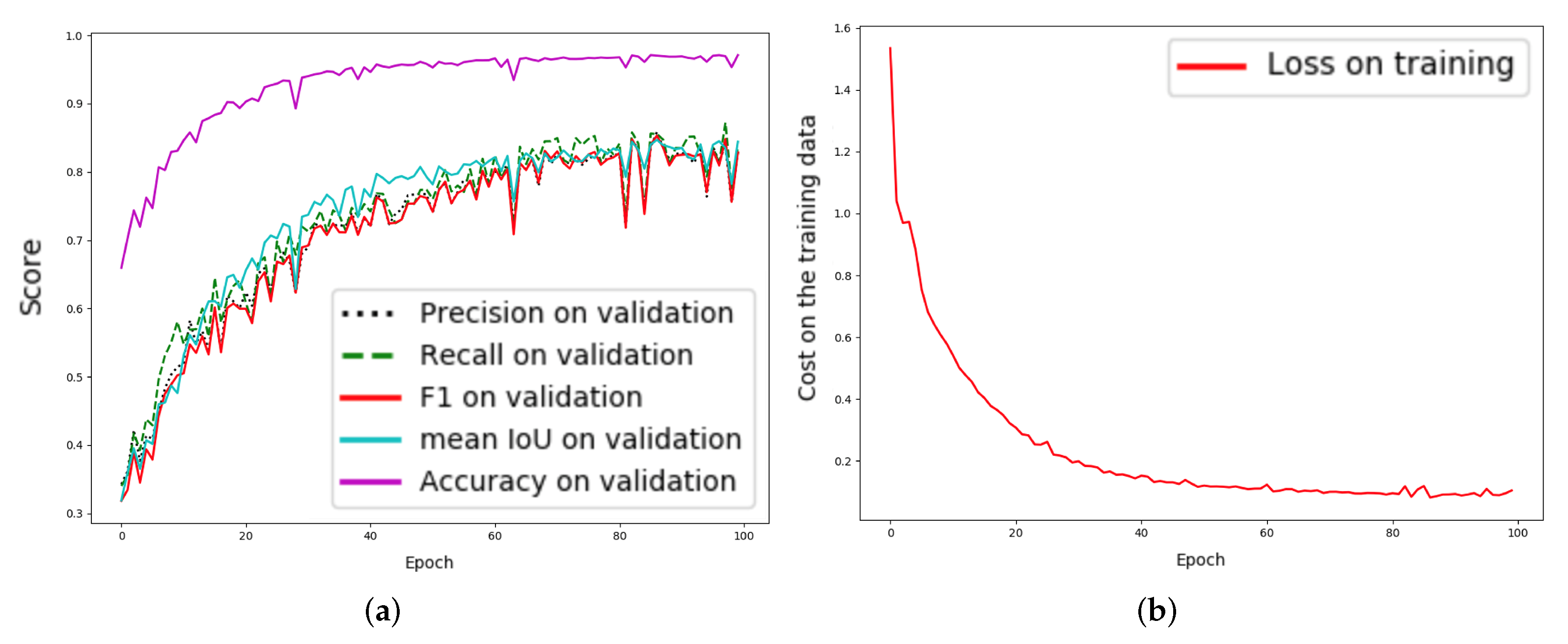
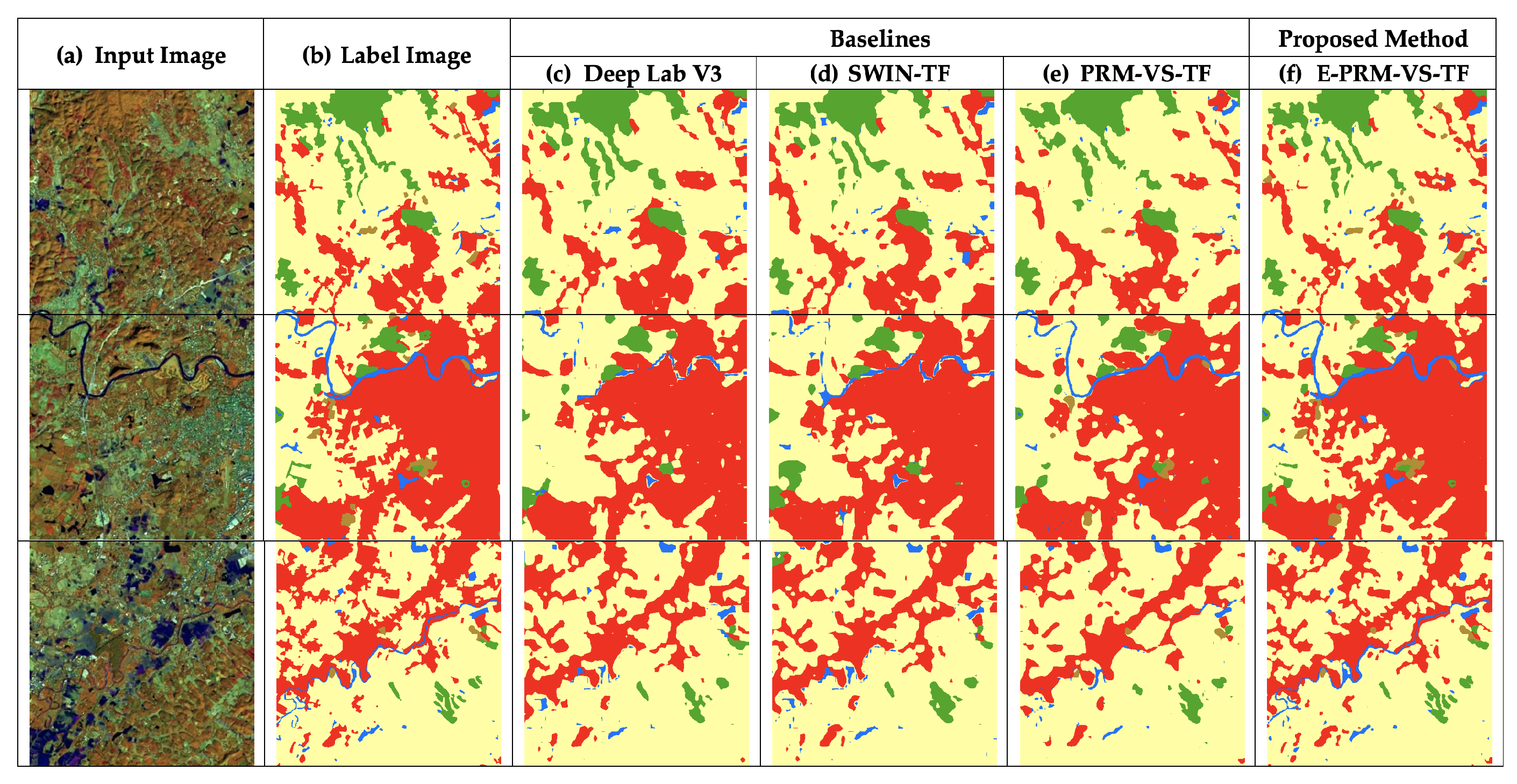
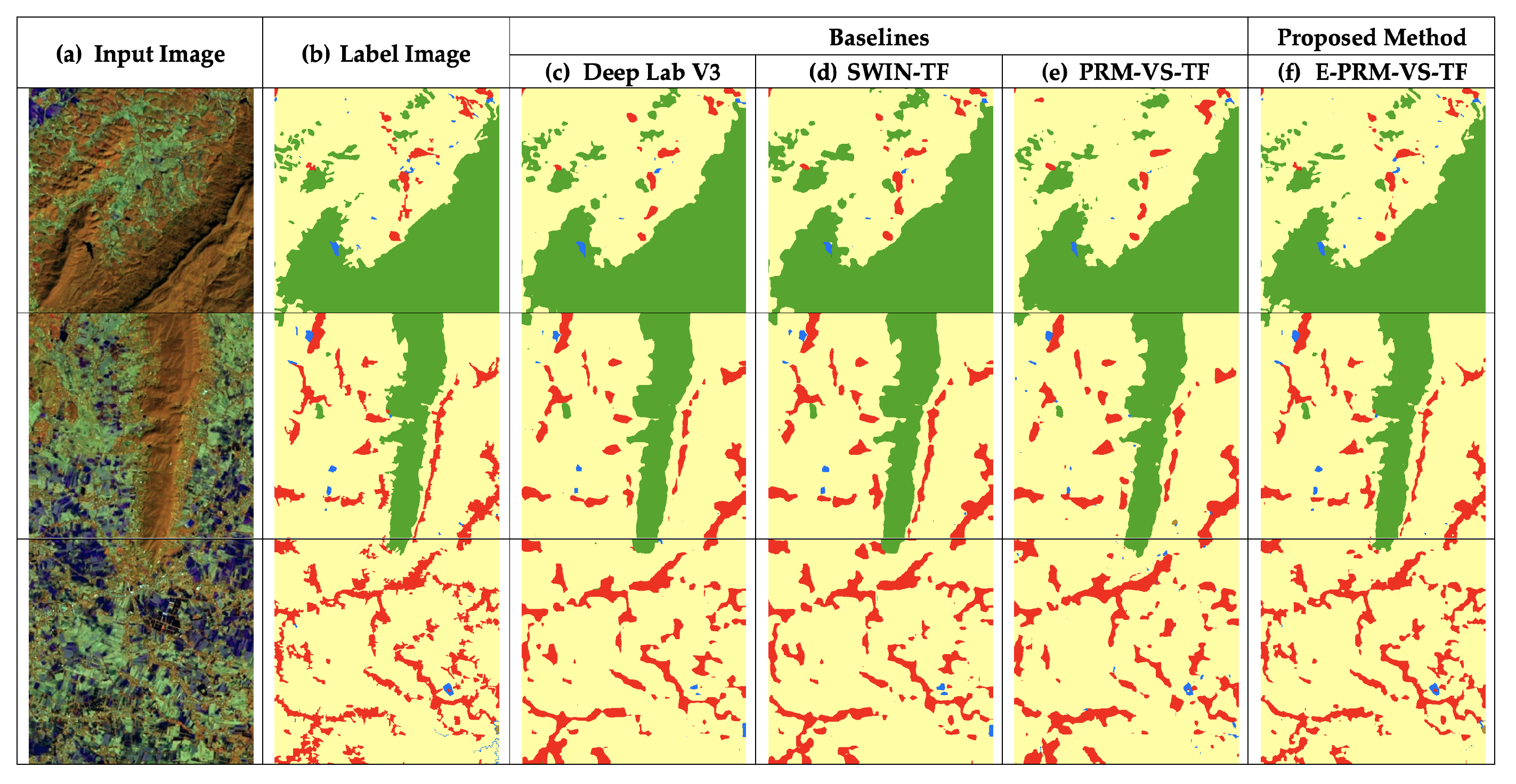
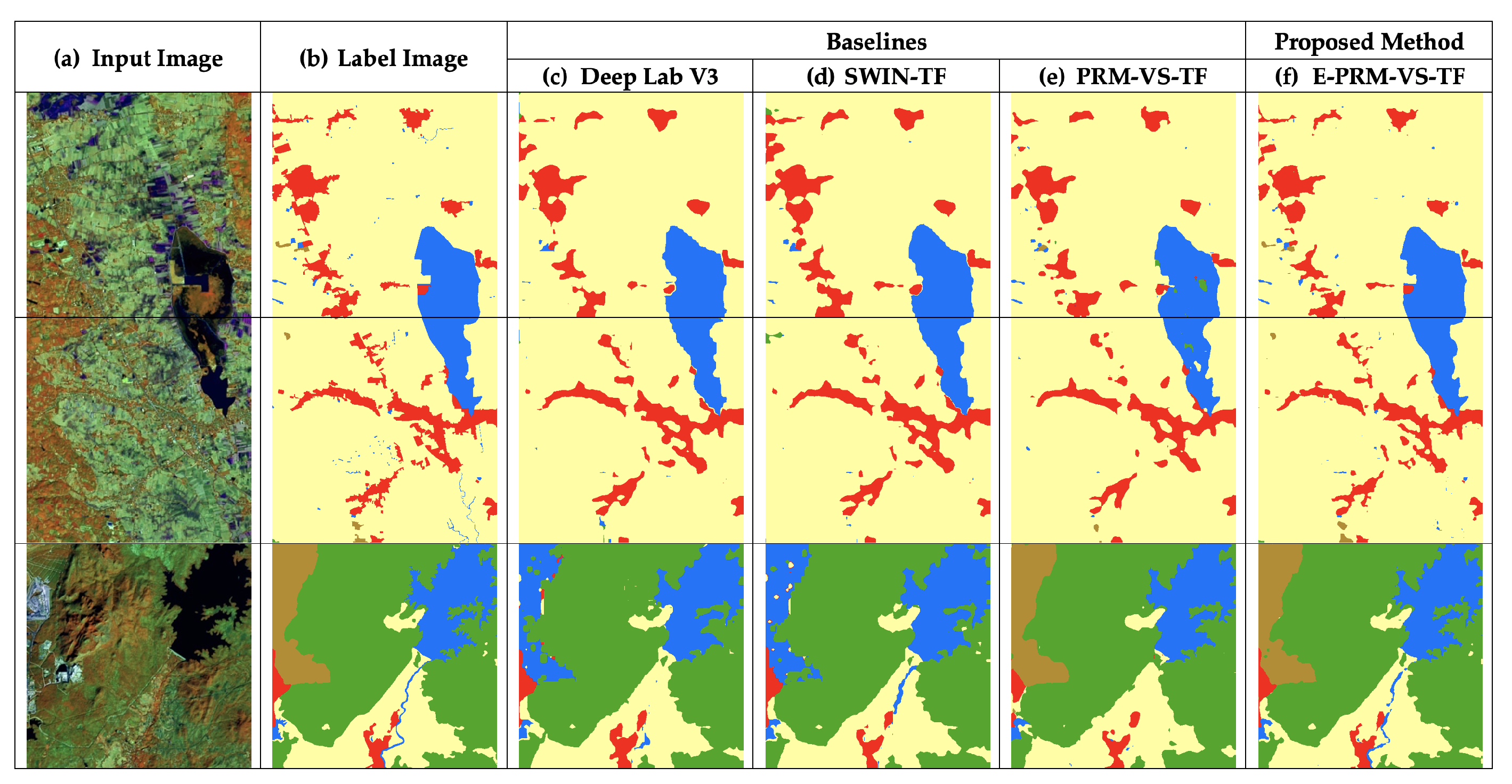
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNNs | Convolutional Neural Networks |
| DeiT | Data-efficient Image Transformers |
| DL | Deep Learning |
| E | Enhanced |
| Param | Parameters |
| PRM | Pyramid |
| PRM-VS-TF | Pyramid Vision Transformer |
| R-CNN | Region-based Convolutional Neural Networks |
| SwinTF | Swin Transformer |
| TU | Transitions Up |
| TD | Transitions Down |
| ViT | Vision Transformer |
References
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention network for semantic segmentation of fine-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Yang, N.; Tang, H. Semantic Segmentation of Satellite Images: A Deep Learning Approach Integrated with Geospatial Hash Codes. Remote Sens. 2021, 13, 2723. [Google Scholar] [CrossRef]
- Li, H.; Qiu, K.; Chen, L.; Mei, X.; Hong, L.; Tao, C. SCAttNet: Semantic Segmentation Network with Spatial and Channel Attention Mechanism for High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 905–909. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Lyu, X.; Gao, H.; Tong, Y.; Cai, S.; Li, S.; Liu, D. Dual attention deep fusion semantic segmentation networks of large-scale satellite remote-sensing images. Int. J. Remote Sens. 2021, 42, 3583–3610. [Google Scholar] [CrossRef]
- Chen, Z.; Li, D.; Fan, W.; Guan, H.; Wang, C.; Li, J. Self-attention in reconstruction bias U-Net for semantic segmentation of building rooftops in optical remote sensing images. Remote Sens. 2021, 13, 2524. [Google Scholar] [CrossRef]
- Tasar, O.; Giros, A.; Tarabalka, Y.; Alliez, P.; Clerc, S. Daugnet: Unsupervised, multisource, multitarget, and life-long domain adaptation for semantic segmentation of satellite images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1067–1081. [Google Scholar] [CrossRef]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters–improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 603–612. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12299–12310. [Google Scholar]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 12179–12188. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16519–16529. [Google Scholar]
- Kim, K.; Wu, B.; Dai, X.; Zhang, P.; Yan, Z.; Vajda, P.; Kim, S.J. Rethinking the Self-Attention in Vision Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3071–3075. [Google Scholar]
- Salvador, A.; Gundogdu, E.; Bazzani, L.; Donoser, M. Revamping Cross-Modal Recipe Retrieval with Hierarchical Transformers and Self-supervised Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15475–15484. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Pasadena, CA, USA, 13–15 December 2021; pp. 10347–10357. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Lin, A.; Chen, B.; Xu, J.; Zhang, Z.; Lu, G. DS-TransUNet: Dual Swin Transformer U-Net for Medical Image Segmentation. arXiv 2021, arXiv:2106.06716. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. arXiv 2021, arXiv:2102.12122. [Google Scholar]
- Chen, K.; Fu, K.; Yan, M.; Gao, X.; Sun, X.; Wei, X. Semantic segmentation of aerial images with shuffling convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 173–177. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Wang, Y.; Ho, C.; Xu, W.; Xuan, Z.; Liu, X.; Qi, G.J. Dual-Flattening Transformers through Decomposed Row and Column Queries for Semantic Segmentation. arXiv 2022, arXiv:2201.09139. [Google Scholar]
- Kim, S.W.; Kook, H.K.; Sun, J.Y.; Kang, M.C.; Ko, S.J. Parallel feature pyramid network for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 234–250. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frontend | Model | Precision | Recall | F1 | |
|---|---|---|---|---|---|
| Baseline | DenseNet-201 | DeepLabV3 [8] | 79.27% | 76.38% | 77.66% |
| ViT | SwinTF [12,19,23] | 78.49% | 77.71% | 78.08% | |
| ViT | PRM-VS-TF [21] | 82.75% | 78.87% | 79.82% | |
| Proposed | ViT | E-PRM-VS-TF | 81.79% | 81.11% | 81.44% |
| Model | Agri | Forest | Misc | Urban | Water | |
|---|---|---|---|---|---|---|
| Baseline | DeepLabV3 [8] | 86.78% | 89.67% | 66.48% | 82.64% | 66.90% |
| SwinTF [12,19,23] | 86.76% | 88.94% | 73.39% | 91.98% | 72.70% | |
| PRM-VS-TF [21] | 87.89% | 88.91% | 76.65% | 93.31% | 74.48% | |
| Proposed Method | E-PRM-VS-TF | 89.83% | 89.28% | 79.68% | 94.50% | 75.50% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Intarat, K.; Rakwatin, P.; Panboonyuen, T. Enhanced Feature Pyramid Vision Transformer for Semantic Segmentation on Thailand Landsat-8 Corpus. Information 2022, 13, 259. https://doi.org/10.3390/info13050259
Intarat K, Rakwatin P, Panboonyuen T. Enhanced Feature Pyramid Vision Transformer for Semantic Segmentation on Thailand Landsat-8 Corpus. Information. 2022; 13(5):259. https://doi.org/10.3390/info13050259
Chicago/Turabian StyleIntarat, Kritchayan, Preesan Rakwatin, and Teerapong Panboonyuen. 2022. "Enhanced Feature Pyramid Vision Transformer for Semantic Segmentation on Thailand Landsat-8 Corpus" Information 13, no. 5: 259. https://doi.org/10.3390/info13050259
APA StyleIntarat, K., Rakwatin, P., & Panboonyuen, T. (2022). Enhanced Feature Pyramid Vision Transformer for Semantic Segmentation on Thailand Landsat-8 Corpus. Information, 13(5), 259. https://doi.org/10.3390/info13050259