
Editing Compression Dictionaries toward Refined Compression-Based Feature-Space

Abstract
:1. Introduction
2. Literature Review: Compression-Based Pattern Recognition
2.1. Compression Distance
2.2. PRDC
3. Methods
3.1. Removal of Common Words
3.2. Word Reassignment
3.2.1. REVIVAL Method
- Step 1:
- The dictionary with the fewest words is selected from U.Let d be the dictionary chosen here.
- Step 2:
- Some words that were removed from d in the past are probabilistically revived and added to d. To prohibit a revived word w from existing in multiple dictionaries simultaneously, we delete w from the dictionary which was holding it just before.
- Step 3:
- REVIVAL removes d from U. This removal of d from U means that d is fixed. Therefore, any word in d never vanishes from d anymore. If after d is removed, REVIVAL stops because all of the base dictionaries have already been processed. Otherwise, REVIVAL goes back to Step 1.
3.2.2. VOCAB Method
3.3. Implementation Details
4. Results
- The UC Merced land use dataset [29]: This dataset consists of 21 classes corresponding to various land cover and land use types. We choose five classes { (a) forest, (b) river, (c) intersection, (d) denseresidential, (e) building}, and randomly select 100 images for each class. Thus, the experimental dataset consists of 5 × 100 = 500 images. Figure 3 shows the instance images for these five classes.
- The Wang database [30]: This image database collects 1000 images from the Corel photo stock database and consists of 100 images for 10 object classes {africa people, beaches, buildings, buses, dinosaurs, elephants, roses, horses, mountains, foods}. Figure 4 shows the four images out of this database.
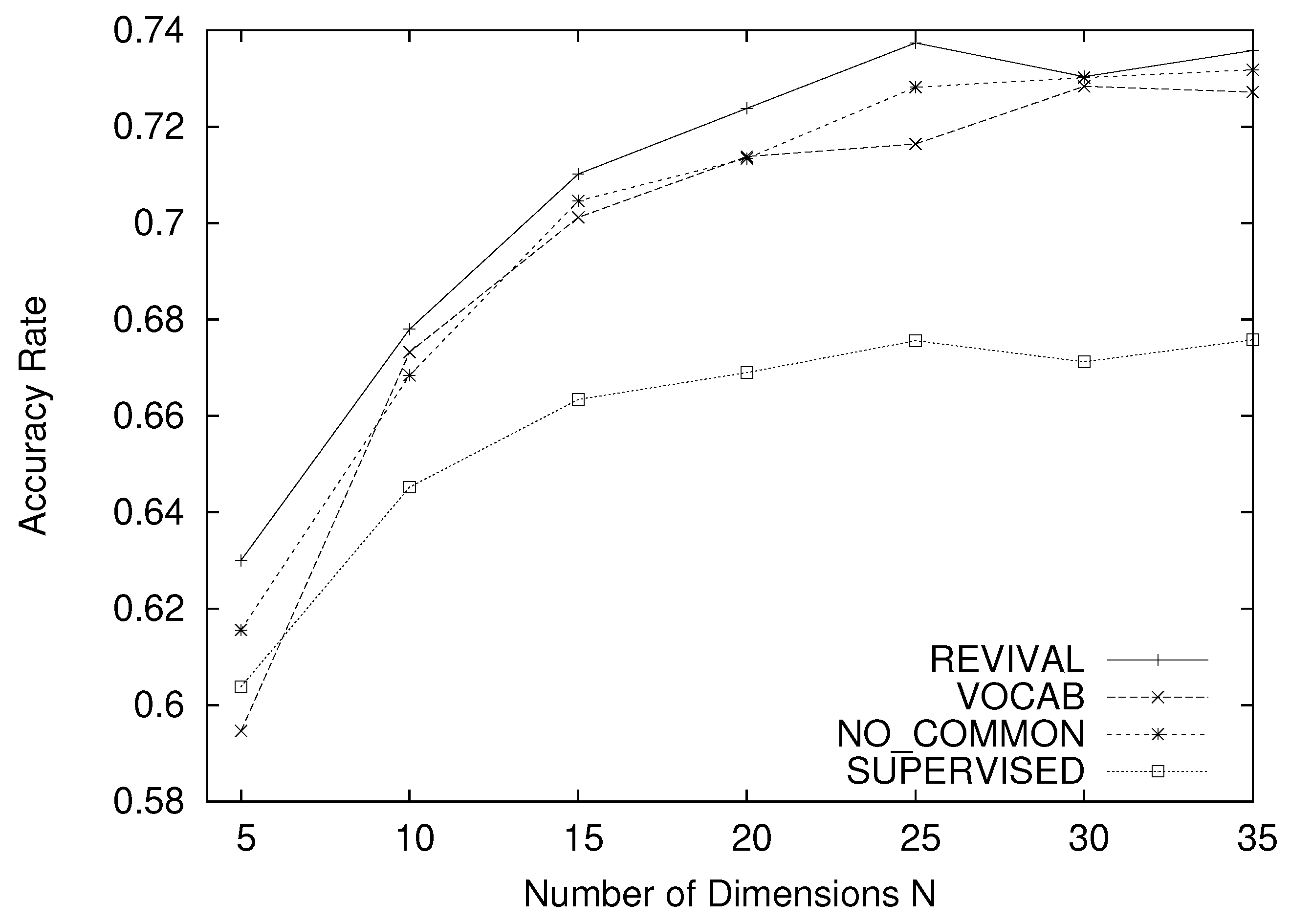
4.1. Comparison of Accuracy Rate
- REVIVAL, VOCAB and NO_COMMON evidently achieve higher accuracy rates for any N than the raw base dictionaries.
- REVIVAL outperforms NO_COMMON regardless of the dictionary selection algorithm.
4.2. Independence among Feature Dimensions
4.3. Execution Time
- (Procedure 1) PRDC chooses the N base dictionaries at the beginning.
- (Procedure 2) modifies the N dictionaries in D.
- (Procedure 3) After the N dictionaries are determined, the CVs are generated for all the objects in the UC Merced Dataset.
- (Procedure 4) classifies every object in the dataset with the K-NN classifier in the leave-one-out manner.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, M.; Chen, X.; Li, X.; Ma, B.; Vitanyi, P. The Similarity Metric. IEEE Trans. Inf. Theory 2004, 50, 3250–3264. [Google Scholar] [CrossRef]
- Luxburg, U. A Tutorial on Spectral Clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Cilibrasi, R.L.; Vitányi, P.M. A Fast Quartet tree heuristic for hierarchical clustering. Pattern Recognit. 2011, 44, 662–677. [Google Scholar] [CrossRef] [Green Version]
- Cristianini, N.; Ricci, E. Support Vector Machines. In Encyclopedia of Algorithms; Kao, M.Y., Ed.; Springer: Boston, MA, USA, 2008; pp. 928–932. [Google Scholar] [CrossRef]
- Cilibrasi, R.; Vitanyi, P. Clustering by compression. IEEE Trans. Inf. Theory 2005, 51, 1523–1545. [Google Scholar] [CrossRef] [Green Version]
- Watanabe, T.; Sugawara, K.; Sugihara, H. A new pattern representation scheme using data compression. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 579–590. [Google Scholar] [CrossRef]
- Koga, H.; Nakajima, Y.; Toda, T. Effective construction of compression-based feature space. In Proceedings of the 2016 International Symposium on Information Theory and Its Applications (ISITA), Monterey, CA, USA, 30 October–2 November 2016; pp. 116–120. [Google Scholar]
- Nishida, K.; Banno, R.; Fujimura, K.; Hoshide, T. Tweet Classification by Data Compression. In Proceedings of the 2011 International Workshop on DETecting and Exploiting Cultural diversity on the Social Web, Glasgow, UK, 24 October 2011; pp. 29–34. [Google Scholar] [CrossRef]
- Cilibrasi, R.; Vitányi, P.; De Wolf, R. Algorithmic Clustering of Music Based on String Compression. Comput. Music J. 2004, 28, 49–67. [Google Scholar] [CrossRef]
- Li, M.; Zhu, Y. Image Classification via LZ78 Based String Kernel: A Comparative Study. In Proceedings of the 10th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining, Singapore, 9–12 April 2006; pp. 704–712. [Google Scholar] [CrossRef]
- Cerra, D.; Datcu, M. Expanding the Algorithmic Information Theory Frame for Applications to Earth Observation. Entropy 2013, 15, 407–415. [Google Scholar] [CrossRef]
- Borbely, R.S. On normalized compression distance and large malware. J. Comput. Virol. Hacking Tech. 2015, 12, 235–242. [Google Scholar] [CrossRef] [Green Version]
- Hagenauer, J.; Mueller, J. Genomic analysis using methods from information theory. Proceedings of IEEE Information Theory Workshop, San Antonio, TX, USA, 24–29 October 2004; pp. 55–59. [Google Scholar]
- Sculley, D.; Brodley, C.E. Compression and Machine Learning: A New Perspective on Feature Space Vectors. In Proceedings of the Data Compression Conference, Snowbird, UT, USA, 28–30 March 2006; p. 332. [Google Scholar] [CrossRef] [Green Version]
- Macedonas, A.; Besiris, D.; Economou, G.; Fotopoulos, S. Dictionary Based Color Image Retrieval. J. Vis. Commun. Image Represent. 2008, 19, 464–470. [Google Scholar] [CrossRef]
- Cerra, D.; Datcu, M. A fast compression-based similarity measure with applications to content-based image retrieval. J. Vis. Commun. Image Represent. 2012, 23, 293–302. [Google Scholar] [CrossRef] [Green Version]
- Welch, T. A Technique for High-Performance Data Compression. Computer 1984, 17, 8–19. [Google Scholar] [CrossRef]
- Besiris, D.; Zigouris, E. Dictionary-based color image retrieval using multiset theory. J. Vis. Commun. Image Represent. 2013, 24, 1155–1167. [Google Scholar] [CrossRef]
- Uchino, T.; Koga, H.; Toda, T. Improved Compression-Based Pattern Recognition Exploiting New Useful Features. In Pattern Recognition and Image Analysis; Springer International Publishing: Cham, Switzerland, 2017; pp. 363–371. [Google Scholar]
- Field, R.; Quach, T.T.; Ting, C. Efficient Generalized Boundary Detection Using a Sliding Information Distance. IEEE Trans. Signal Process. 2020, 68, 6394–6401. [Google Scholar] [CrossRef]
- Zhang, N.; Watanabe, T. Topic Extraction for Documents Based on Compressibility Vector. IEICE Trans. 2012, 95-D, 2438–2446. [Google Scholar] [CrossRef] [Green Version]
- Cilibrasi, R. Statistical Inference Through Data Compression. Ph.D. Thesis, Institute for Logic, language and Computation, Universiteit van Amsterdam, Amsterdam, The Netherlands, 2007. [Google Scholar]
- Ting, C.; Field, R.; Fisher, A.; Bauer, T. Compression Analytics for Classification and Anomaly Detection Within Network Communication. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1366–1376. [Google Scholar] [CrossRef]
- Casella, G.; Berger, R. Statistical Inference; Duxbury Resource Center: Duxbury, MA, USA, 2001. [Google Scholar]
- Coltuc, D.; Datcu, M.; Coltuc, D. On the Use of Normalized Compression Distances for Image Similarity Detection. Entropy 2018, 20, 99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ting, C.; Johnson, N.; Onunkwo, U.; Tucker, J.D. Faster classification using compression analytics. In Proceedings of the 2021 International Conference on Data Mining Workshops (ICDMW), Auckland, New Zealand, 7–10 December 2021; pp. 813–822. [Google Scholar] [CrossRef]
- Contreras, I.; Arnaldo, I.; Krasnogor, N.; Hidalgo, J.I. Blind optimisation problem instance classification via enhanced universal similarity metric. Memetic Comput. 2014, 6, 263–276. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal Component Analysis; Springer: Berlin, Germany; New York, NY, USA, 1986. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and Spatial Extensions for Land-use Classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar] [CrossRef]
- Wang, J.; Li, J.; Wiederhold, G. SIMPLIcity: Semantics-Sensitive Integrated Matching for Picture LIbraries. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 947–963. [Google Scholar] [CrossRef] [Green Version]
- Mortensen, J.; Wu, J.; Furst, J.; Rogers, J.; Raicu, D. Effect of Image Linearization on Normalized Compression Distance. In Signal Processing, Image Processing and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2009; Volume 61, pp. 106–116. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | UC Merced Land Use | Wang |
|---|---|---|
| Number of images | 500 | 1000 |
| Number of classes | 5 | 10 |
| Class Name | ||
| 1 | forest | africa people |
| 2 | river | beaches |
| 3 | intersection | buildings |
| 4 | denseresidential | buses |
| 5 | building | dinosaurs |
| 6 | elephants | |
| 7 | roses | |
| 8 | horses | |
| 9 | mountains | |
| 10 | foods | |
| 0.340 | 0.508 | 0.160 | 0.581 | 0.598 | 0.530 | 0.496 | 0.463 | 0.173 | ||
| 0.011 | 0.509 | 0.536 | 0.824 | 0.114 | 0.218 | 0.045 | 0.275 | 0.213 | ||
| 0.285 | 0.714 | 0.016 | 0.516 | 0.455 | 0.187 | 0.359 | 0.218 | 0.484 | ||
| 0.199 | 0.387 | 0.118 | 0.539 | 0.242 | 0.234 | 0.148 | 0.142 | 0.120 | ||
| 0.214 | 0.878 | 0.843 | 0.238 | 0.288 | 0.453 | 0.046 | 0.322 | 0.175 | ||
| 0.540 | 0.074 | 0.143 | 0.476 | 0.168 | 0.664 | 0.133 | 0.675 | 0.252 | ||
| 0.081 | 0.649 | 0.832 | 0.006 | 0.810 | 0.217 | 0.170 | 0.740 | 0.061 | ||
| 0.650 | 0.268 | 0.160 | 0.116 | 0.114 | 0.718 | 0.166 | 0.217 | 0.045 | ||
| 0.357 | 0.374 | 0.314 | 0.174 | 0.272 | 0.815 | 0.146 | 0.831 | 0.001 | ||
| 0.386 | 0.650 | 0.585 | 0.160 | 0.648 | 0.361 | 0.725 | 0.591 | 0.563 |
| REVIVAL | PRDC | |
|---|---|---|
| (1) Selection of Initial Base Dictionaries [ms] | 23,551 | 23,516 |
| (2) Dictionary Modification [ms] | 342 | 0 |
| (3) Generation of CVs [ms] | 25,734 | 24,358 |
| (4) Object Classification [ms] | 57 | 56 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koga, H.; Ouchi, S.; Nakajima, Y. Editing Compression Dictionaries toward Refined Compression-Based Feature-Space. Information 2022, 13, 301. https://doi.org/10.3390/info13060301
Koga H, Ouchi S, Nakajima Y. Editing Compression Dictionaries toward Refined Compression-Based Feature-Space. Information. 2022; 13(6):301. https://doi.org/10.3390/info13060301
Chicago/Turabian StyleKoga, Hisashi, Shota Ouchi, and Yuji Nakajima. 2022. "Editing Compression Dictionaries toward Refined Compression-Based Feature-Space" Information 13, no. 6: 301. https://doi.org/10.3390/info13060301
APA StyleKoga, H., Ouchi, S., & Nakajima, Y. (2022). Editing Compression Dictionaries toward Refined Compression-Based Feature-Space. Information, 13(6), 301. https://doi.org/10.3390/info13060301