
Interactive Search on the Web: The Story So Far

 ,
,  ,
,
Abstract
:1. Introduction
2. Survey Methodology
3. Keyword Search Engine
3.1. Current State of the Art and Related Works
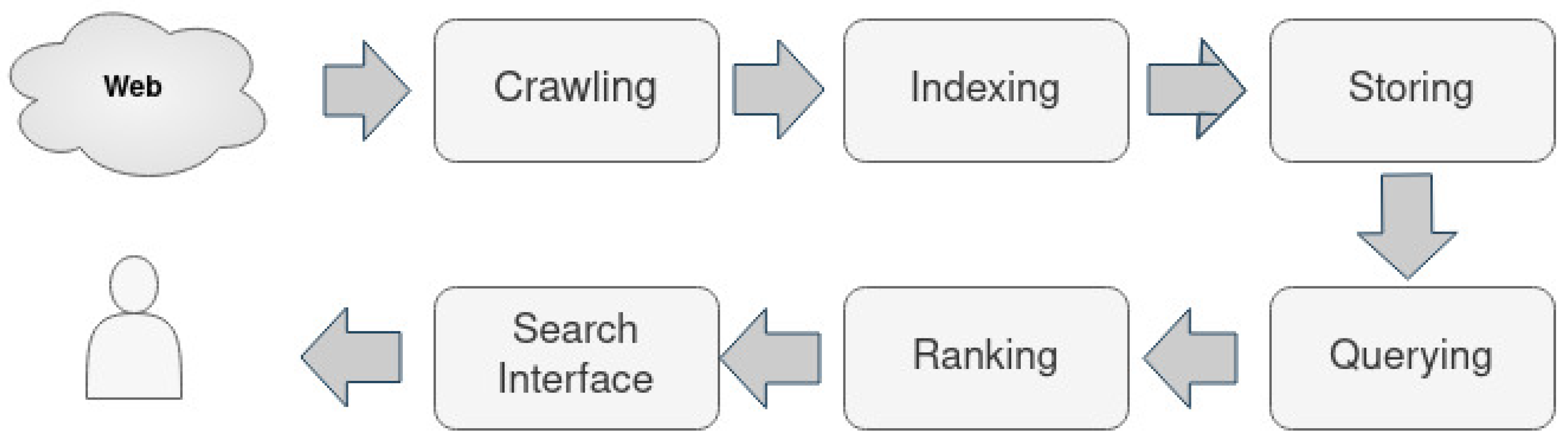
3.2. Process Model
- Information Collection Component: web crawlers are responsible for collecting information. A crawler (also called spider or bot) can be assumed as a program that continually browses the web to collect new pages. The collected pages are used in the indexing in the next component.
- Indexing Component: the collected web pages are stored, organized, and indexed in this component to improve the speed of retrieval. When a page is in the index, it is in the running to be displayed as a result of relevant queries.
- Ranking Component: this component provides the pieces of content that evaluate the desired pages for the query, which means that results are ordered by most relevant to least relevant. The ranking algorithms which can be applied in the ranking component are described in Section 3.4.
3.3. Data Preparation and Representation
3.4. Common Methodologies
- Content-based ranking: these approaches rank the relevant pages based on pages’ content and keywords. Firstly, the words from the user query are stripped down to the root. The root words and their synonyms are considered for the construction of a dictionary. Then the keywords of each page are compared against the dictionary. Accordingly to the matches found, the relevancy of each particular page against the user query is computed as the ranking score.
- Usage-based ranking: these approaches aim to rank web pages based on users’ past navigation and retrieval patterns. A ranking score is assigned to each page which indicates how often they are viewed on the web. Thus, it determines the page’s relevancy by its selection frequency. Ranking based on usage only can not guarantee precise results due to the other indications such as time spent on reading the page, the number of times the page was saved/printed or added to the bookmarks, and the actions of following the links of the page are neglected.
- Link-based ranking: these approaches compute the ranking scores based on the links between the pages. For example, from the fact that a page has many links and references, it is derived that it must have something interesting to express. The link-analysis-based algorithms are generally computed offline, even before receiving any query from the user. Here, the popularity of pages is calculated by building a graph using a set of nodes and analyzing the existing links in it. The PR algorithm and the HITS algorithm are the most common examples of linked-based ranking algorithms.
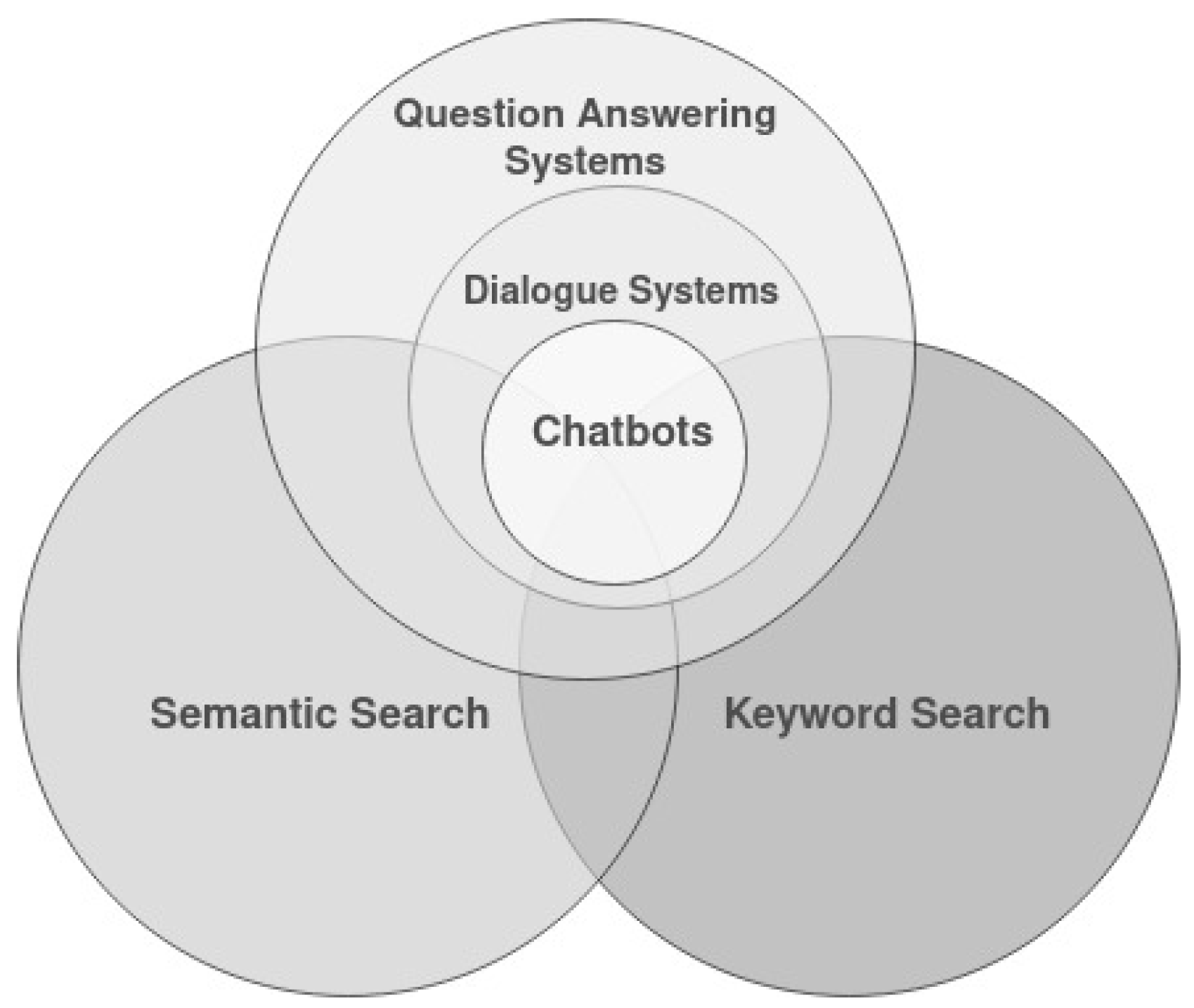
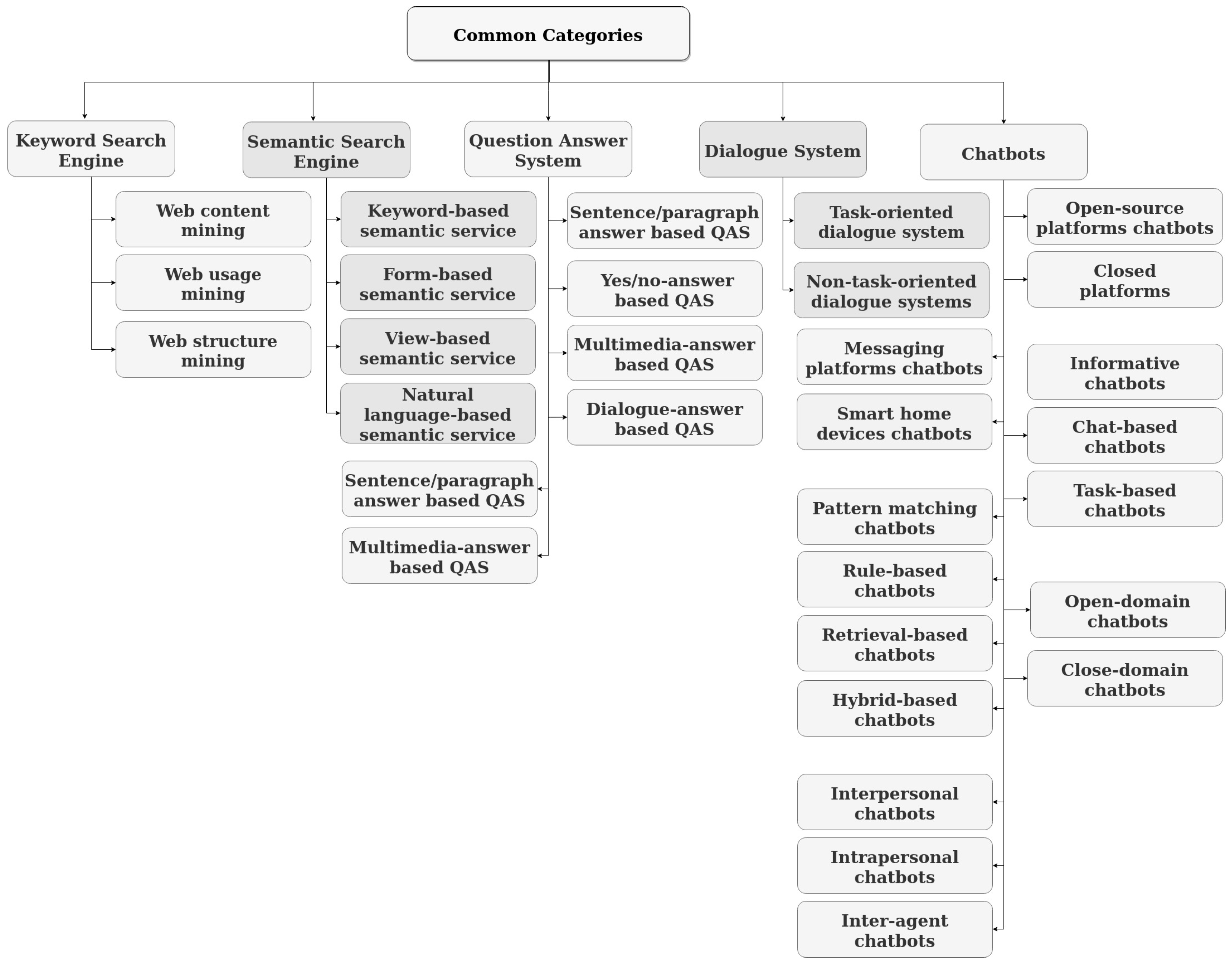
3.5. Categories
- Web content mining: these search engines mine the content of web pages to extract the result by performing different mining techniques and shrink the search data, which become easy to find required user information [41].
- Web usage mining: according to the log information stored during user interactions while surfing the web, user navigation patterns are discovered. Then the discovered patterns are applied to rank and fetch the desired pages against user queries [42].
3.6. Summary
4. Semantic Search Engine
4.1. Current State of the Art and Related Works
4.2. Process Model
- Crawling: a crawler aims to discover documents and collect them. Like classic search engines, semantic search engines collect data using crawlers, for instance, crawling RDF documents embedded on websites. For that, more specialized crawlers have been developed [56], which provide various methods for crawling data; (1) direct URL (Uniform Resource Locator) crawling that bootstraps the crawling process, (2) Google-based crawling, which retrieves hyperlinks directly from Google search engine, (3) extracting and following hyperlinks limited to a certain depth and threshold, (4) RDF crawling that fetches semantic annotations embedded on webpages [45], furthermore, (5) crawlers that combine previous approaches, for example, using Google-based crawling to retrieve hyperlinks for most common words used in a specific language (e.g., English language).
- Indexing: the indexing process analyses the retrieved documents from the crawling process. For instance, the vocabulary used and the relationship between resources and metadata about the retrieved documents (e.g., last modified) are analyzed. For instance, Swoogle uses a rational surfer model to rank retrieved documents [49].
- Storing: the indexed documents are later on stored in a knowledge base in the form of graphs, which contain triples (subject, predicate, object). The goal of storing the data using semantic technologies is to facilitate the answer of complex queries [49]. For instance, there are several graph database systems, such as GraphDB (https://www.ontotext.com/products/graphdb, accessed on 1 July 2022) and Neo4J (https://neo4j.com/, accessed on 1 July 2022), which support semantic queries.
- Querying: after the indexing and storing processes have been done, the knowledge can be queried, while querying to traditional search engines return documents, the result of a semantic web search query is richer than just simple documents. Semantic search engines return a representation of an entity (note that an entity or a resource includes web pages, parts of a web page, devices, people and more) (i.e., classes, properties, and literal values). For this reason, the query system provided by a semantic search engine should be able to perform complex search queries, e.g., a user can express the context for a term that he or she is looking for, and the semantic search engine can disambiguate the term [45].
- Ranking: the ranking process runs semantic analysis and concept match between the user’s query and the output produced by the semantic search engine [49]. The ranking process evaluates several semantic and statistical metrics, e.g., context and popularity, which improve semantic search engines’ algorithm [57]. For instance, Anyanwu et al. [57] propose SemRank that applies several techniques (e.g., semantic association) for analyzing and ranking relationships between two instances in a knowledge base.
- Search Interface: “the proof of the pudding is in the eating”, providing means to access the knowledge base is a crucial part of a semantic search engine. For instance, it is essential to provide means that facilitate access to knowledge for humans and machines. Services like REST (Representational State Transfer) service API (Application Programming Interface) [54], keyword-based, form-based, view-based, or natural language-based semantic search systems must be supported [16].
4.3. Data Preparation and Representation
4.4. Common Methodologies
- Knowledge acquisition: To effectively harvest structured and unstructured knowledge from the web, hybrid crawlers were used. For instance, crawling semantic annotations from websites, following links from the crawled semantic annotations, harvesting RDF/XML documents, and URLs using traditional search engines. Furthermore, several methods for transforming unstructured and semistructured data into structured knowledge are needed, e.g., converting comma-separated values (CSV) data into RDF.
- Knowledge base construction: It summarizes methods, such as schema alignment, entity matching, and entity fusion, for integrating knowledge into a knowledge base. For instance, to detect duplicates (i.e., entity matching), it is necessary to compare every entity with each other, which is not recommendable for large knowledge bases [61,62]. In this case, indexing techniques might help to reduce the number of comparison, e.g., some indexing approaches are: an ontology-based index [63] that stores the ontology graph, an entity-based index that takes into account the relationships between entities, and a textual-based index that considers triples (subject, predicate, object). Additionally, more index techniques are listed in the paper presented by Lashkari et al. [64].
- Semantic search services: Approaches to capture and process search queries based on various techniques, such as entity ranking algorithms, e.g., ranking approaches can be classified into three categories [65]: entity, relationship, and document ranking. Furthermore, semantic search services comprises the coupling between the stored knowledge base and an ontology to support the generation of queries, e.g., traversing the knowledge base (or a part of it) and using query templates are common approaches used for refining/creation of queries.
- Semantic search presentation: Common ways of interacting with semantic search engines involve a) services for machines like REST service APIs and b) user-friendly interfaces such as keyword-based, form-based, view-based, and natural language-based semantic search systems.
4.5. Categories
- Keyword-based semantic service: These search engines try to boost the performance of conventional keyword search engines by considering semantic entities that match query keywords. They translate query terms into semantic entities through typed links among entities on the data web to find more accurate and relevant information.
- Form-based semantic service: Form-based semantic search services aim to guide users to make queries based on the information needed. They facilitate formulating semantic queries by translating ontologies’ parts into forms, menus, and drop-down lists.
- View-based semantic service: The services intend to help users construct queries and explore domains by ontology presentation and navigation. The considerable benefit of web-based semantic services is that users can easily understand the domain. The query vocabulary and content classification scheme can be presented in intuitive formats.
- Natural language-based semantic service: the main idea is to employ semantic markup and natural language processing techniques in question-answer systems. The service takes a query expressed in natural language and a given ontology as input and finds the answer from one or more knowledge bases that subscribe to the ontology. Therefore, they are more flexible than form-based and view-based semantic services and do not require users to learn the vocabulary or structure of the ontology to be queried.
4.6. Summary
5. Question Answering System
5.1. Current State of the Art and Related Works
5.2. Process Model
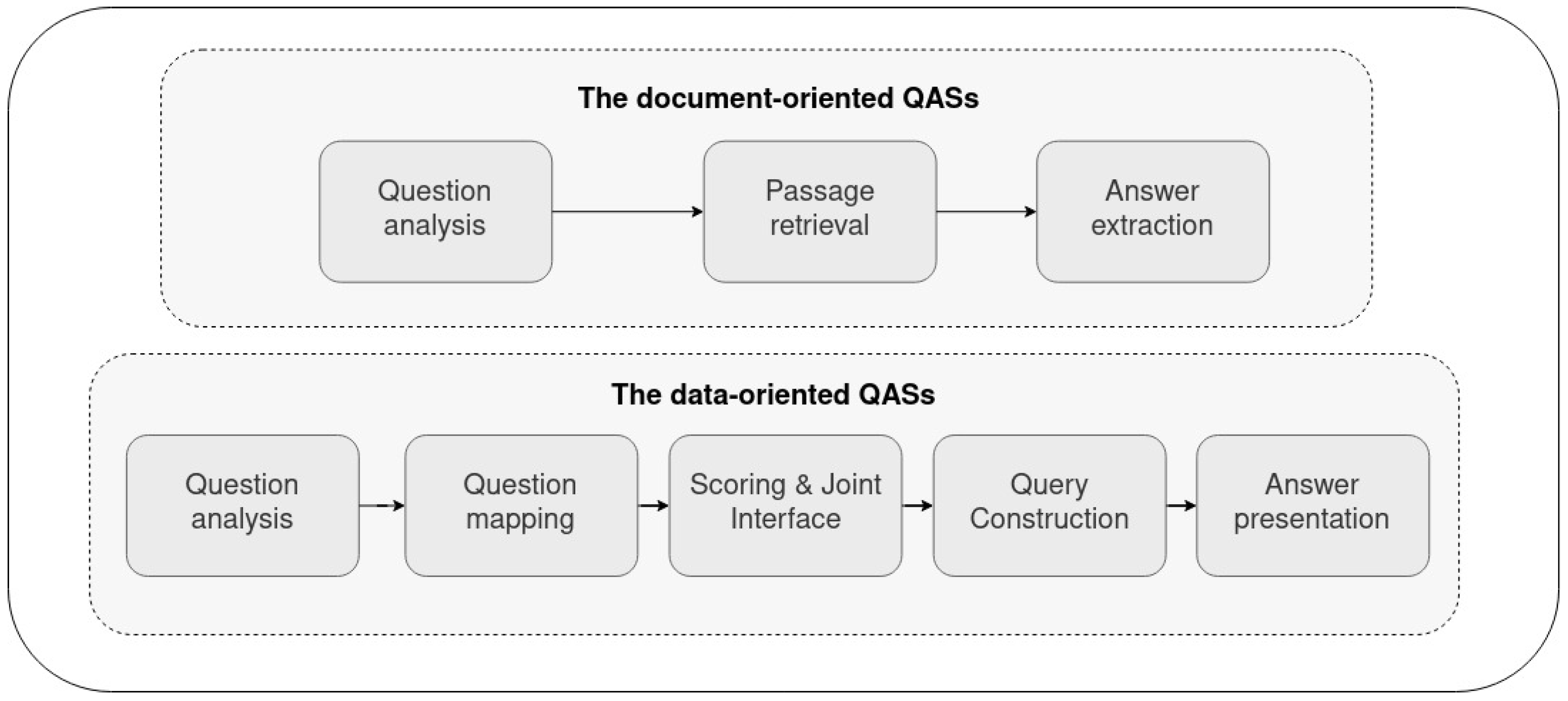
- Question analysis: as the first activity, questions are classified based on their type, leading to recognizing the expected answer types. Then named entities of input questions are identified, and their relations are detected. The last activity of this module aims at enhancing question phrasing through adding more descriptive information to increase the accuracy of the system, for example, using WordNet as a lexicon in order to retrieve semantically equivalent information [14,71].
- Passage retrieval: to find relevant information in the underlying documents as source knowledge, this module employs information retrieval techniques for returning a ranked subset of the most relevant documents. Then the relevant documents are segmented into shorter units, namely, passages. Finally, the candidate passages are ranked according to features such as the number of question words in the passage and the number of named entities having the answer type in the passage. These features should determine the probability of containing the precise answer [14,71].
- Answer extraction: this module targets identifying the answer candidates from the ranked list of passages. Then the candidate answers are ranked according to features that reflect the probability of being the precise answer. To deal with the partial answers between passages or documents, it is responsible for generating the final answers and computing a confidence score that reflects the confidence of its accuracy.
- Question analysis: it aims at analyzing the input question linguistically and syntactically. The linguistic analysis of the question leverages part-of-speech taggers and parsers to capture the syntactic structure of the question, e.g., Named Entity Recognition. The semantic analysis targets identifying the question type and the focus question.
- Question mapping: this component’s main goal is to match question words or phrases to their counterparts in the underlying knowledge source, e.g., RDF knowledge graphs. Due to the lexical gap and the ambiguity between user questions and the underlying knowledge graph vocabulary, synonymy, hypernym and hyponym should be considered in computing similarities.
- Scoring and joint interface: to select only one candidate among the candidate components, a scoring mechanism is required to score the candidates. The semantic similarity between the candidates and the question can be applied to achieve a scoring mechanism to define a matching score. Moreover, string matching combined with linear programming can be used.
- Query construction: in order to transfer the question to an executable query such as SPARQL Protocol and RDF Query Language (SPARQL) (https://www.w3.org/TR/rdf-sparql-query/, accessed on 1 July 2022), the approaches can be summarized into two groups: (a) template-based approaches which map input questions to generated SPARQL query templates, (b) template-free approaches which aim at creating SPARQL queries according to the given syntactic structure of the input question.
- Answer presentation: since the structured representation of answers is not intelligible for users, the answer presentation component follows some processing activities to transfer the RDF answers to a natural language form.
5.3. Data Preparation and Representation
5.4. Common Methodologies
- Traditional techniques. Frequently asked question and answer (FAQs) and rule-based methods can be assumed as the major traditional and straightforward approaches. In FAQs, a set of question and answer pairs are collected and stored as the dataset. Then answers are generated by searching the given question from the stored dataset. When the required query is found, the relevant answer is given back to the user [85]. The rule-based methods primarily used in QASs over knowledge graphs rely on predefined rules or templates to parse questions and provide logical forms [7]. The definition of rules or templates leads to limited scalability and the need for researchers to become familiar with linguistic knowledge.
- Information retrieval-based techniques. Machine learning, more specifically deep learning, plays a key role in many aspects of information retrieval systems [86]. A QAS over documents generally involves question and document representation steps, followed by a matching step to estimate the mutual relevance of the query and the document representations. A neural approach can affect one or more of these steps. In the case of QA over knowledge graphs, for a given natural language question, the named entities that reflect the main focus of the question are identified. Then the link between the extracted entities and the knowledge graph are specified. In the next step, a subset of the knowledge graph around the identified entities are extracted what its nodes are assumed as candidate answers. Based on the features extracted from the questions and candidate answers, the matching scores between the encoded answers and questions are calculated, and the final answer is selected. From the feature representation’s perspective, the information retrieval-based techniques are divided into two groups including feature engineering and representation learning. In feature engineering, features are manually defined according to the questions’ syntax information which basically fail to capture the semantic information of questions. In representation learning, questions and candidates are transformed to embeddings and then the embeddings are leveraged to compute the semantic matching and find the answer. The state-of-the-art QASs employ neural deep networks (e.g., memory networks, Convolutional Neural Network (CNN), Long Short-Term Memory (LSTM)) to generate better distributed embeddings for questions and candidate.
- Semantic parsing-based techniques. Knowledge graphs based QASs can leverage semantic parsing-based techniques in order to answer user questions. These methods usually transform natural language questions into executable queries such as SPARQL queries or intermediate query forms such as query graphs based on neural semantic parsing with high scalability and capability. Recent QASs take advantage of graphs to represent questions, namely query graphs. Basically, the query graphs can be generated based on predefined natural language processing rules or neural networks. Then, the query graph which basically have topology commonalities with knowledge graphs are mapped to the knowledge graphs to find the answers. Additionally, trees or high-level programming languages can be used to represent questions through sequence-to-sequence models and attention mechanisms [87].
5.5. Categories
- Sentence/paragraph-answer based QAS: To answer some types of questions such as factoid or hypothetical ones, QASs return a single fact or a small piece of text as sentence/paragraph as the relevant answer.
- Yes/no-answer based QAS: User questions are generally answered in the form of yes or no through verification and justification.
- Multimedia-answer-based QAS: Answers are generated in different types of multimedia such as audio or video.
- Opinionated-answer-based QAS: This system gives a star rating to an object as the answer.
- Dialogue-answer-based QAS: These QASs are also known as dialogue systems that make efforts to answer users’ questions in the form of a dialogue.
5.6. Summary
6. Dialogue System
6.1. Current State of the Art and Related Works
6.2. Process Model
- User experience layer: this layer is the user’s input and the dialogue system’s output layers. As mentioned previously, the input and output can be in the form of voice, text, images, video clips, and or sign language. The user experience layer can be connected to many platforms such as Facebook Messenger, WhatsApp, WeChat, Sina Weibo, Tencent QQ, Telegram, and Skype.
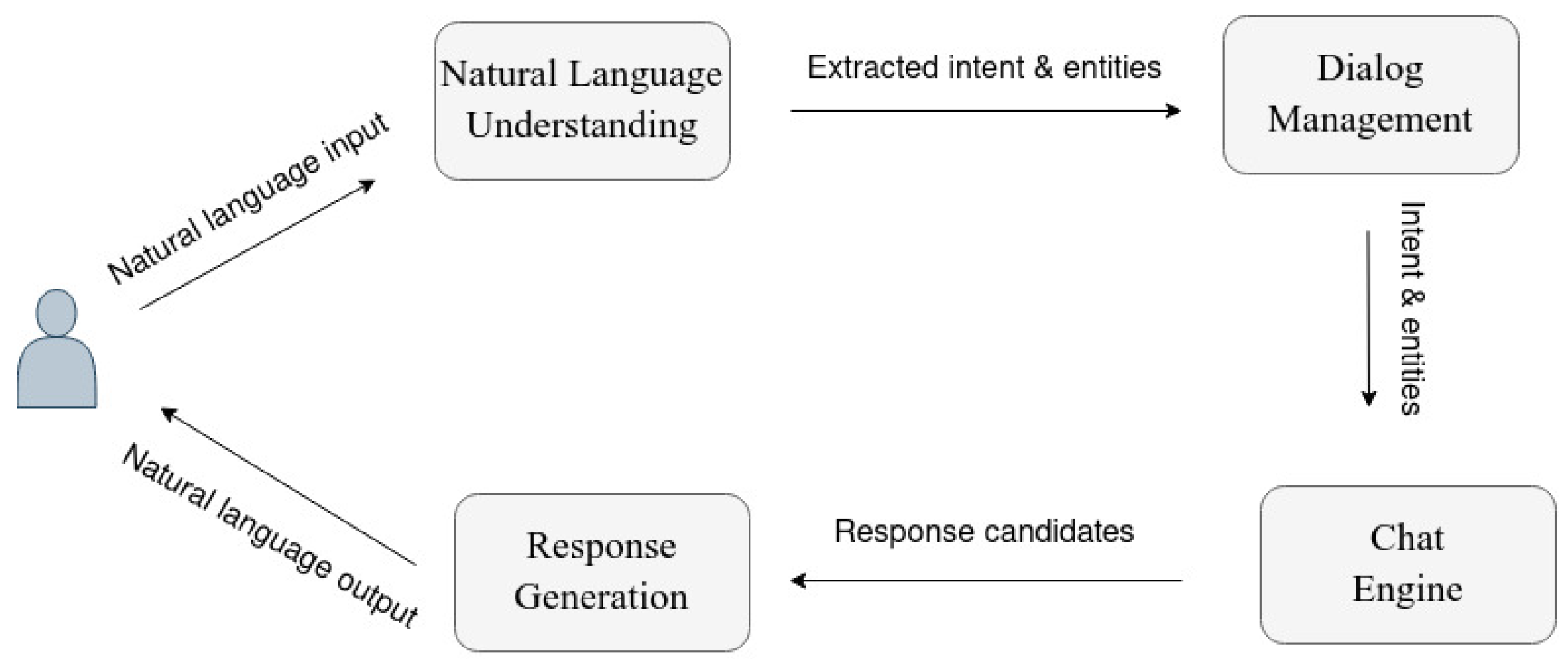
- Conversation engine layer: the second layer is connected to the other layers, including the user experience and data layers. It analyses the user input and preserves the data in a useful manner in the data layer. Depending on the task of the dialogue system, the data is used to give the desired answer. For speech-based dialogue systems, a Text To Speech module is added at the end. The conversation engine layer consists of three main modules as shown in Figure 6 [19].
- (a)
- Natural Language Understanding Module: it takes a user query in a natural language manner and translates it into a semantic representation. If the input is not a text, it is converted to a string of words, then stored in the Data Layer.
- (b)
- Dialogue Manager Module: the semantic representation of the user’s text is taken, and a schematic representation of response is generated. Indeed, the module keeps track of the dialogue state and a dialogue policy learner, which decides what to answer to the user.
- (c)
- Natural Language Generation Module: the semantic representation of the answer is translated to a natural language answer. Thus, it makes decisions regarding the information to be included, how information should be structured, choice of words, and syntactic structure for the message.
- Data layer: all data, including collected conversational data, non-conversational data, and knowledge resources, is stored in the data layer as a set of data sources.
6.3. Data Preparation and Representation
- Unstructured data: this kind of data is not organized in a predefined manner. Text documents are the most well-understood instance of unstructured data which do not have any predefined data model.
- Structured data: due to addressable elements in structured data, it is easy to be analyzed. It can be effectively organized in a formatted repository such as databases. The relational databases are the most well-known model for holding tabular data as an example of structured data.
- Semi-structured data: it lies between unstructured and structured data. However, the semi-structured data does not reside in a relational database, but it has some organizational features that make it easier to analyze. The XML data resources can be considered semi-structured data.
6.4. Common Methodologies
- Pipeline methods: the main idea behind the pipeline methods is to define a pipeline structure including natural language understanding, dialogue state tracker, dialogue parser learning, and natural language generation. Natural language understanding is responsible for detecting the intent of users through classifying the intent into predefined intents or employing some techniques such as deep learning. The dialogue state tracker handles the input of each turn along with the dialogue history and returns the current dialogue state. Then the dialogue parser learning learns the following action based on the output of the dialogue state tracker. Finally, the response is returned based on the action [8].
- End-to-end methods: the task-oriented dialogue systems can apply an encoder-decoder model to train the whole system. The model only adopts a single module and interacts with structured external databases. In end-to-end methods, dialogue system learning can be viewed as the problem of learning a mapping from dialogue histories to system responses [8].
- Retrieval-based methods: the major focus of retrieval-based methods is message- response matching by employing matching algorithms to bridge semantic gaps between messages and responses. So based on the matching, a response from candidate responses is selected [99]. The early retrieval-based dialogue systems apply single-turn response matching. In these systems, only the message is used to select a proper response in each single-turn conversation, while multi-turn response matching has been mainly used in recent years, current messages and previous utterances are taken to select the response. Thus, the selected response is natural and relevant to the whole context [8,100].
- Hybrid methods: recently, the neural generative and retrieval-based models have been combined to increase performance. Since the retrieval-based systems generally return accurate but straight responses, while generation-based systems often return fluent but meaningless responses, the combined approaches can have significant effects on performance [8,102,103].
6.5. Categories
- Task-oriented dialogue system: Furthermore, known as goal-oriented dialogue system, it targets to assist users in completing tasks in one or multiple domains by the end of the dialog. Some goal-oriented dialogue systems include restaurant reservation, flight ticket booking, and course selection advising, finding products. The major methods to develop task-oriented dialogue systems include the pipeline or end-to-end methods.
- Non-task-oriented dialogue systems: It also called chatbot can be defined as software to provide extended conversations and mimic the unstructured conversations or ‘chats’ characteristic of human-human interaction [10]. Chatbots aim to maximize user engagement and interact with a human to provide reasonable responses and entertainment. Typically they focus on conversing on open domains. However, the none-task-oriented systems have been basically designed for entertainment. They also intend to gain practical targets over time like task-oriented chatbots [8,10]. The widely applied method to none-task-oriented dialogue systems are the retrieval-based, neural generative-based, and hybrid methods.
6.6. Summary
7. Chatbot
7.1. Current State of the Art and Related Works
7.2. Process Model
7.3. Data Preparation and Representation
7.4. Common Methodologies
- Parsing—This category extracts meaningful information from the textual input of the user. The grammatical structure of a sentence is used to extract keywords that are then matched against the stored data to find the appropriate response. Semantic parsing is a more advanced technique for converting the input sentence into a representation that machines can process. For example, Dialogflow recognizes relevant information based on a predefined set of training phrases containing placeholders for parts of the sentences containing relevant information. Those placeholders identify a specific type of information (e.g., location information or name information) that can be used to generate queries to the underlying database by using templates. This approach allows an explicit definition of what happens with the relevant information. However, it requires a lot of manual work to set up the chatbot properly [9].
- Pattern Matching—This approach is most commonly used. It defines a set of handcrafted pattern-template pairs. Whenever a pattern matches the input, the template is used to return a response to the user. This approach is mainly used in QA chatbots and is very flexible for creating conversations. However, all possible patterns are built manually, which is not scaling. Due to the scaling issues, the responses are predictable and are not manifold, more repetitive [9].
- Ontologies—Ontologies are used to represent domain knowledge and make it explorable by the chatbot itself. An advantage of this approach is that the chatbot can use reasoning to detect relationships between concept nodes used in the conversation [9].
- Markov Chain Model—The Markov chain model is a probabilistic model modeling probabilities of state transitions over time. There is a fixed probability for the following states based on a given state. A chatbot using this model produces outputs based on those state transitions. The chatbot constructs probabilistically more suitable responses. This model is mainly used for chatbots that entertain users by imitating simple human conversations. Markov chain models however do not work well on complex conversations [9].
- Neural Networks Models—These models allow more intelligent chatbots. The research trend for using artificial neural networks for chatbots is a generative-based approach where chatbots dynamically generate the response to the given user input. Neural network models are learning algorithms used in machine learning and can be supervised and unsupervised. Subclasses of artificial neural networks models used for chatbots are RNNs, sequence to sequence neural model, or LSTMs. A major problem with these artificial neural networks is that they are not accurate yet. Therefore, prominent virtual assistants like Alexa, Siri, and Cortana rely on a semi-rule-based approach [115].
7.5. Categories
7.6. Summary
8. Future of Search on the Web
- Keyword search engines fail to (1) disambiguate words and return irrelevant results (false positives), and (2) turn up related materials that do not specifically use the search keywords (false negatives).
- The stability of the semantic web languages and continuous development of ontologies are key challenges in semantic web search engines. Furthermore, the performance of semantic web search engines relies on knowledge sources, which might contain errors and missing values.
- Despite a lot of progress in QASs, lexical gap and ambiguity are still main challenges in these systems either documents-based, data-based, or mixture of document and data based knowledge sources.
- In addition to lexical gap and ambiguity, dialogue systems need to tackle with incremental processing due to these systems are naturally interactive.
- Additionally to the above challenges, remembering the context of a conversation (or even understanding in some cases) needs to be improved in chatbots.
9. Discussion
10. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Summary of 2019 Gartner IIoT Platform Report. Available online: https://medium.com/world-of-iot/96-summary-of-2019-gartner-iiot-platform-report-9d7f41f53a4e (accessed on 20 June 2022).
- Internet of Things: Key Stats for 2022. Available online: https://techinformed.com/internet-of-things-key-stats-for-2022/ (accessed on 20 June 2022).
- Sheela, S.; kumar, J. Comparative study of syntactic search engine and semantic search engine: A survey. In Proceedings of the 2019 Fifth International Conference on Science Technology Engineering and Mathematics, Chennai, India, 14–15 March 2019; Volume 1, pp. 1–4. [Google Scholar]
- Strzelecki, A. Eye-tracking studies of web search engines: A systematic literature review. Information 2020, 11, 300. [Google Scholar] [CrossRef]
- Mariné-Roig, E. Measuring destination image through travel reviews in search engines. Sustainability 2017, 9, 1425. [Google Scholar] [CrossRef] [Green Version]
- Broder, A. A taxonomy of web search. In Proceedings of the ACM Sigir Forum, September 2002; ACM: New York, NY, USA, 2002; Volume 36, pp. 3–10. Available online: https://www.cis.upenn.edu/~nenkova/Courses/cis430/p3-broder.pdf (accessed on 1 May 2022).
- Fu, B.; Qiu, Y.; Tang, C.; Li, Y.; Yu, H.; Sun, J. A Survey on Complex Question Answering over Knowledge Base: Recent Advances and Challenges. arXiv 2020, arXiv:2007.13069. [Google Scholar]
- Chen, H.; Liu, X.; Yin, D.; Tang, J. A Survey on Dialogue Systems: Recent Advances and New Frontiers. arXiv 2017, arXiv:1711.01731. [Google Scholar] [CrossRef]
- Hussain, S.; Sianaki, O.A.; Ababneh, N. A survey on conversational agents/chatbots classification and design techniques. In Proceedings of the Workshops of the International Conference on Advanced Information Networking and Applications, Matsue, Japan, 27–29 March 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 946–956. [Google Scholar]
- Jurafsky, D.; Martin, J. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition; Prentice Hall: Hoboken, NJ, USA, 2008; Volume 2. [Google Scholar]
- Gupta, V. A keyword searching algorithm for search engines. In Proceedings of the 2007 Innovations in Information Technologies, Dubai, United Arab Emirates, 18–20 November 2007; pp. 203–207. [Google Scholar]
- Stokoe, C. Differentiating homonymy and polysemy in information retrieval. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 403–410. [Google Scholar]
- Aghaei, S.; Nematbakhsh, M.A.; Farsani, H.K. Evolution of the world wide web: From web 1.0 to web 4.0. Int. J. Web Semant. Technol. 2012, 3, 1–10. [Google Scholar] [CrossRef]
- Ojokoh, B.; Adebisi, E. A Review of Question Answering Systems. J. Web Eng. 2019, 17, 717–758. [Google Scholar] [CrossRef] [Green Version]
- Ceravolo, P.; Liu, C.; Jarrar, M.; Sattler, K.U. Special issue on querying the data web. World Wide Web 2011, 14, 461–463. [Google Scholar] [CrossRef] [Green Version]
- Uren, V.S.; Lei, Y.; Lopez, V.; Liu, H.; Motta, E.; Giordanino, M. The usability of semantic search tools: A review. Knowl. Eng. Rev. 2007, 22, 361–377. [Google Scholar] [CrossRef]
- Allam, A.M.N.; Haggag, M.H. The question answering systems: A survey. Int. J. Res. Rev. Inf. Sci. 2012, 2, 3. [Google Scholar]
- Diefenbach, D.; Both, A.; Singh, K.; Maret, P. Towards a question answering system over the semantic web. Semant. Web 2020, 11, 421–439. [Google Scholar] [CrossRef] [Green Version]
- Arora, S.; Batra, K.; Singh, S. Dialogue System: A Brief Review. arXiv 2013, arXiv:1306.4134. [Google Scholar]
- Chiba, Y.; Nose, T.; Kase, T.; Yamanaka, M.; Ito, A. An analysis of the effect of emotional speech synthesis on non-task-oriented dialogue system. In Proceedings of the 19th Annual SIGdial Meeting on Discourse and Dialogue, Melbourne, Australia, 12–14 July 2018; pp. 371–375. [Google Scholar]
- Simsek, U.; Umbrich, J.; Fensel, D. Towards a Knowledge Graph Lifecycle: A pipeline for the population of a commercial Knowledge Graph. In Proceedings of the Qurator, Berlin, Germany, 20–21 January 2020. [Google Scholar]
- Seymour, T.; Frantsvog, D.; Kumar, S. History of search engines. Int. J. Manag. Inf. Syst. 2011, 15, 47–58. [Google Scholar] [CrossRef]
- Sampath Kumar, B.T.; Pavithra, S. Evaluating the searching capabilities of search engines and metasearch engines: A comparative study. Ann. Libr. Inf. Stud. 2010, 57, 87–97. [Google Scholar]
- Meng, W.; Yu, C.; Liu, K.L. Building efficient and effective metasearch engines. ACM Comput. Surv. 2002, 34, 48–89. [Google Scholar] [CrossRef]
- Peters, R.; Sikorski, R. Metacrawler. Science 1997, 277, 977. [Google Scholar]
- Sadeh, T. Google Scholar versus metasearch systems. High Energy Phys. Libr. Webzine 2006, 12, 2006. [Google Scholar]
- Shokouhi, M.; Si, L. Federated search. Found. Trends Inf. Retr. 2011, 5, 1–102. [Google Scholar] [CrossRef]
- Vaughan, L.; Chen, Y. Data mining from web search queries: A comparison of google trends and baidu index. J. Assoc. Inf. Sci. Technol. 2015, 66, 13–22. [Google Scholar] [CrossRef]
- Rahman, M. Search Engines Going beyond Keyword Search: A Survey. Int. J. Comput. Appl. 2013, 75, 1–8. [Google Scholar] [CrossRef]
- Selvan, M.P.; Sekar, C.; Dharshin, P. Survey on Web Page Ranking Algorithms. Int. J. Comput. Appl. 2012, 41, 1–7. [Google Scholar]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Technical Report; Stanford InfoLab: Standford, CA, USA, 1999. [Google Scholar]
- Kleinberg, J.M. Authoritative sources in a hyperlinked environment. Citeseer 1998, 98, 668–677. [Google Scholar]
- Abou-Assaleh, T.; Das, T.; Gao, W.; Miao, Y.; O’Brien, P.; Zhen, Z. A link-based ranking scheme for focused search. In Proceedings of the 16th international Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 1125–1126. [Google Scholar]
- Tokgoz, B.; Ozcilnak, Z.; Cinar, C.; Yalun, M.T.; Bitirim, Y. An evaluation of Turkish retrieval performance of popular search engines for Internet and image search by using common lists. In Proceedings of the The Third International Conference on Digital Information and Communication Technology and its Applications, Bangkok, Thailand, 1–15 October 2013; pp. 148–153. [Google Scholar]
- Hussain, A.; Gul, S.; Shah, T.A.; Shueb, S. Retrieval effectiveness of image search engines. Electron. Libr. 2019, 37, 173–184. [Google Scholar] [CrossRef]
- CheshmehSohrabi, M.; Sadati, E.A. Performance evaluation of web search engines in image retrieval: An experimental study. Inf. Dev. 2021, 02666669211010211. [Google Scholar] [CrossRef]
- Uluc, F.; Emirzade, E.; Bitirim, Y. The impact of number of query words on image search engines. In Proceedings of the Second International Conference on Internet and Web Applications and Services (ICIW’07), Morne, Mauritius, 13–19 May 2007; p. 50. [Google Scholar]
- Çakir, E.; Bahceci, H.; Bitirim, Y. An evaluation of major image search engines on various query topics. In Proceedings of the 2008 The Third International Conference on Internet Monitoring and Protection, Bucharest, Romania, 29 June–5 July 2008; pp. 161–165. [Google Scholar]
- Adrakatti, A.; Wodeyar, R.; Mulla, K. Search by image: A novel approach to content based image retrieval system. Int. J. Libr. Sci. 2016, 14, 41–47. [Google Scholar]
- Arora, N.; Govilkar, S. Survey on different ranking algorithms along with their approaches. Int. J. Comput. Appl. 2016, 975, 8887. [Google Scholar] [CrossRef]
- Mughal, M.J.H. Data Mining: Web Data Mining Techniques, Tools and Algorithms: An Overview. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 6. [Google Scholar] [CrossRef] [Green Version]
- Duhan, N.; Sharma, A.K.; Bhatia, K.K. Page Ranking Algorithms: A Survey. In Proceedings of the 2009 IEEE International Advance Computing Conference, San Diego, CA, USA, 2–5 November 2009; pp. 1530–1537. [Google Scholar]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The semantic web. Sci. Am. 2001, 284, 34–43. [Google Scholar] [CrossRef]
- Guha, R.; McCool, R.; Miller, E. Semantic search. In Proceedings of the 12th international conference on World Wide Web, Budapest, Hungary, 20–24 May 2003; pp. 700–709. [Google Scholar]
- Ilyas, Q.M.; Kai, Y.Z.; Talib, A. A conceptual architecture for semantic search engine. In Proceedings of the 8th International Multitopic Conference, Lahore, Pakistan, 24–26 December 2004; pp. 605–610. [Google Scholar]
- Sánchez-Cervantes, J.L.; Colombo-Mendoza, L.O.; Alor-Hernández, G.; García-Alcaráz, J.L.; Álvarez-Rodríguez, J.M.; Rodríguez-González, A. LINDASearch: A faceted search system for linked open datasets. Wirel. Net. 2020, 26, 5645–5663. [Google Scholar] [CrossRef]
- Sahu, S.K.; Mahapatra, D.; Balabantaray, R. Comparative study of search engines in context of features and semantics. J. Theor. Appl. Inf. Technol. 2016, 88, 210–218. [Google Scholar]
- Hussan, B.K. Comparative study of semantic and keyword based search engines. Adv. Sci. Technol. Eng. Syst. J. 2020, 5, 106–111. [Google Scholar] [CrossRef]
- Jain, R.; Duhan, N.; Sharma, A. Comparative study on semantic search engines. Int. J. Comput. Appl. 2015, 131, 4–11. [Google Scholar] [CrossRef]
- Heflin, J.; Hendler, J. Searching the Web with SHOE. In Proceedings of the AAAI-2000 Workshop on AI for Web Search, Austin, TX, USA, 30–31 July 2000; pp. 35–40. [Google Scholar]
- Huaman, E.; Tauqeer, A.; Fensel, A. Towards Knowledge Graphs Validation Through Weighted Knowledge Sources. In Proceedings of the Iberoamerican Knowledge Graphs and Semantic Web Conference, Kingsville, TX, USA, 22–24 November 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 47–60. [Google Scholar]
- Roy, S.; Modak, A.; Barik, D.; Goon, S. An overview of semantic search engines. Int. J. Res. Rev. 2019, 6, 73–85. [Google Scholar]
- Sudeepthi, G.; Anuradha, G.; Babu, M.S.P. A survey on semantic web search engine. Int. J. Comput. Sci. Issues (IJCSI) 2012, 9, 241. [Google Scholar]
- Ding, L.; Finin, T.; Joshi, A.; Pan, R.; Cost, R.S.; Peng, Y.; Reddivari, P.; Doshi, V.; Sachs, J. Swoogle: A search and metadata engine for the semantic web. In Proceedings of the thirteenth ACM International Conference on Information and Knowledge Management, Washington, DC, USA, 8–13 November 2004; pp. 652–659. [Google Scholar]
- Cheng, G.; Ge, W.; Wu, H.; Qu, Y. Searching Semantic Web objects based on class hierarchies. In Proceedings of the LDOW2008, Beijing, China, 22 April 2008. [Google Scholar]
- d’Aquin, M.; Ding, L.; Motta, E. Semantic web search engines. In Handbook of Semantic Web Technologies; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Anyanwu, K.; Maduko, A.; Sheth, A. Semrank: Ranking complex relationship search results on the semantic web. In Proceedings of the 14th International Conference on World Wide Web, Chiba, Japan, 10–14 May 2005; pp. 117–127. [Google Scholar]
- McBride, B. The resource description framework (RDF) and its vocabulary description language RDFS. In Handbook on Ontologies; Springer: Berlin/Heidelberg, Germany, 2004; pp. 51–65. [Google Scholar]
- Fensel, D.; Simsek, U.; Angele, K.; Huaman, E.; Kärle, E.; Panasiuk, O.; Toma, I.; Umbrich, J.; Wahler, A. Knowledge Graphs: Methodology, Tools and Selected Use Cases. In Knowledge Graphs; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Pan, J.; Vetere, G.; Gomez-Perez, J.M.; Wu, H. Exploiting Linked Data and Knowledge Graphs in Large Organisations; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar] [CrossRef]
- Aghaei, S.; Fensel, A. Finding Similar Entities across Knowledge Graphs. In Proceedings of the 7th International Conference on Advances in Computer Science and Information Technology, Vienna, Austria, 20–21 March 2021; pp. 1–11. [Google Scholar] [CrossRef]
- Huaman, E.; Fensel, D. Knowledge Graph Curation: A Practical Framework. In Proceedings of the 10th International Joint Conference on Knowledge Graphs, virtual event, Thailand, 6–8 December 2021; pp. 166–171. [Google Scholar] [CrossRef]
- Sitthisarn, S.; Lau, L.; Dew, P.M. A survey of semantic keyword search approaches. Int. J. Appl. Comput. Technol. Inf. Syst. 2013, 2, 29–37. [Google Scholar]
- Lashkari, F.; Ensan, F.; Bagheri, E.; Ghorbani, A.A. Efficient indexing for semantic search. Expert Syst. Appl. 2017, 73, 92–114. [Google Scholar] [CrossRef]
- Jindal, V.; Bawa, S.; Batra, S. A review of ranking approaches for semantic search on Web. Inf. Process. Manag. 2014, 50, 416–425. [Google Scholar] [CrossRef]
- Wei, W.; Barnaghi, P.M.; Bargiela, A. Search with meanings: An overview of semantic search systems. Int. J. Commun. 2008, 3, 76–82. [Google Scholar]
- da Silva, J.W.F.; Venceslau, A.D.P.; Sales, J.E.; Maia, J.G.R.; Pinheiro, V.C.M.; Vidal, V.M.P. A short survey on end-to-end simple question answering systems. Artif. Intell. Rev. 2020, 53, 1–25. [Google Scholar] [CrossRef]
- Höffner, K.; Walter, S.; Marx, E.; Usbeck, R.; Lehmann, J.; Ngonga Ngomo, A.C. Survey on challenges of question answering in the semantic web. Semant. Web 2017, 8, 895–920. [Google Scholar] [CrossRef] [Green Version]
- Yani, M.; Krisnadhi, A.A. Challenges, Techniques, and Trends of Simple Knowledge Graph Question Answering: A Survey. Information 2021, 12, 271. [Google Scholar] [CrossRef]
- Diefenbach, D.; Lopez, V.; Singh, K.; Maret, P. Core techniques of question answering systems over knowledge bases: A survey. Knowl. Inf. Syst. 2017, 55, 529–569. [Google Scholar] [CrossRef]
- Dimitrakis, E.; Sgontzos, K.; Tzitzikas, Y. A survey on question answering systems over linked data and documents. J. Intell. Inf. Syst. 2019, 55, 233–259. [Google Scholar] [CrossRef]
- Mishra, A.; Jain, S.K. A survey on question answering systems with classification. J. King Saud Univ. Comput. Inf. 2016, 28, 345–361. [Google Scholar] [CrossRef] [Green Version]
- Rodrigo, Á.; Peñas, A. A study about the future evaluation of Question-Answering systems. Knowl. Based Syst. 2017, 137, 83–93. [Google Scholar] [CrossRef]
- Wu, P.; Zhang, X.; Feng, Z. A Survey of Question Answering over Knowledge Base. In Knowledge Graph and Semantic Computing: Knowledge Computing and Language Understanding. CCKS 2019; Springer: Singapore, 2019; pp. 86–97. [Google Scholar]
- Aghaei, S.; Fensel, A. Building knowledge subgraphs in question answering over knowledge graphs. In Proceedings of the 22nd International Conference on Web Engineering, Bari, Italy, 5–8 July 2022; p. 13362. [Google Scholar]
- Abbasiyantaeb, Z.; Momtazi, S. Text-based Question Answering from Information Retrieval and Deep Neural Network Perspectives: A Survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 11, e1412. [Google Scholar] [CrossRef]
- Arenas, M.; Grau, B.C.; Kharlamov, E.; Marciuska, S.; Zheleznyakov, D. Faceted search over RDF-based knowledge graphs. J. Web Semant. 2016, 37, 55–74. [Google Scholar] [CrossRef]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; Van Kleef, P.; Auer, S. Dbpedia—A large-scale, multilingual knowledge base extracted from wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef] [Green Version]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge unifying wordnet and wikipedia. In Proceedings of the 16th International World Wide Web Conference, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; pp. 1247–1250. [Google Scholar]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Ehrlinger, L.; Wöß, W. Towards a Definition of Knowledge Graphs. Semantics 2016, 48, 2. [Google Scholar]
- Sun, H.; Bedrax-Weiss, T.; Cohen, W.W. PullNet: Open Domain Question Answering with Iterative Retrieval on Knowledge Bases and Text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 2380–2390. [Google Scholar]
- Sun, H.; Dhingra, B.; Zaheer, M.; Mazaitis, K.; Salakhutdinov, R.; Cohen, W. Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4231–4242. [Google Scholar]
- Sultana, T.; Badugu, S. A review on different question answering system approaches. In Advances in Decision Sciences, Image Processing, Security and Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 579–586. [Google Scholar]
- Kenter, T.; Borisov, A.; Van Gysel, C.; Dehghani, M.; de Rijke, M.; Mitra, B. Neural networks for information retrieval. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 1403–1406. [Google Scholar]
- Dong, L.; Lapata, M. Language to logical form with neural attention. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 33–43. [Google Scholar]
- Reddy, C.O.; Latha, M. A Survey on types of question answering system. IOSR J. Comput. Eng. 2017, 19, 19–23. [Google Scholar]
- Arbaaeen, A.; Shah, A. Ontology-Based Approach to Semantically Enhanced Question Answering for Closed Domain: A Review. Information 2021, 12, 200. [Google Scholar] [CrossRef]
- Menie, M.A.W.O.; te Nijenhuis, J.; Murphy, R. The Victorians were still faster than us. Commentary: Factors influencing the latency of simple reaction time. Front. Hum. Neurosci. 2015, 9, 452. [Google Scholar]
- Hrúz, M.; Campr, P.; Krňoul, Z.; Železnỳ, M.; Aran, O.; Santemiz, P. Multi-modal dialogue system with sign language capabilities. In Proceedings of the 13th International ACM SIGACCESS Conference on Computers and Accessibility, Dundee, UK, 24–26 October 2011; pp. 265–266. [Google Scholar]
- Skantze, G.; Schlangen, D. Incremental dialogue processing in a micro-domain. In Proceedings of the 12th Conference of the European Chapter of the ACL, Athens, Greece, 30 March–3 April 2009; pp. 745–753. [Google Scholar]
- Addlesee, A.; Eshghi, A.; Konstas, I. Current challenges in spoken dialogue systems and why they are critical for those living with dementia. arXiv 2019, arXiv:1909.06644. [Google Scholar]
- Deriu, J.; Rodrigo, Á.; Otegi, A.; Echegoyen, G.; Rosset, S.; Agirre, E.; Cieliebak, M. Survey on evaluation methods for dialogue systems. Artif. Intell. Rev. 2020, 54, 755–810. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Gao, J.; Li, D.; Shum, H.Y. The design and implementation of xiaoice, an empathetic social chatbot. Comput. Linguist. 2020, 46, 53–93. [Google Scholar] [CrossRef]
- Mallios, S.; Bourbakis, N. A survey on human machine dialogue systems. In Proceedings of the 2016 7th International Conference on Information, Intelligence, Systems & Applications (IISA), Chalkidiki, Greece, 13–15 July 2016; pp. 1–7. [Google Scholar]
- Chaves, A.P.; Gerosa, M.A. The Impact of Chatbot Linguistic Register on User Perceptions: A Replication Study. In Chatbot Research and Design. CONVERSATIONS 2021; Springer: Cham, Switzerland, 2021; pp. 143–159. [Google Scholar]
- Liebrecht, C.; Sander, L.; Hooijdonk, C.V. Too informal? How a chatbot’s communication style affects brand attitude and quality of interaction. In Chatbot Research and Design. CONVERSATIONS 2020; Springer: Cham, Switzerland, 2020; pp. 16–31. [Google Scholar]
- Hu, B.; Lu, Z.; Li, H.; Chen, Q. Convolutional Neural Network Architectures for Matching Natural Language Sentences. In Proceedings of the 27th International Conference on Neural Information Processing Systems-Volume 2, Montreal, QC, Canada, 8–13 December 2014; MIT Press: Cambridge, MA, USA, 2014; pp. 2042–2050. [Google Scholar]
- Lowe, R.; Pow, N.; Serban, I.; Pineau, J. The Ubuntu Dialogue Corpus: A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems. In Proceedings of the 16th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Singapore and Online, 29–31 July 2015; pp. 285–294. [Google Scholar] [CrossRef]
- Ritter, A.; Cherry, C.; Dolan, W.B. Data-driven response generation in social media. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 583–593. [Google Scholar]
- Song, Y.; Yan, R.; Li, X.; Zhao, D.; Zhang, M. Two are Better than One: An Ensemble of Retrieval- and Generation-Based Dialog Systems. arXiv 2016, arXiv:1610.07149. [Google Scholar]
- Qiu, M.; Li, F.L.; Wang, S.; Gao, X.; Chen, Y.; Zhao, W.; Chen, H.; Huang, J.; Chu, W. Alime chat: A sequence to sequence and rerank based chatbot engine. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 498–503. [Google Scholar]
- Ni, J.; Young, T.; Pandelea, V.; Xue, F.; Adiga, V.; Cambria, E. Recent advances in deep learning based dialogue systems: A systematic survey. arXiv 2021, arXiv:2105.04387. [Google Scholar]
- Coope, S.; Farghly, T.; Gerz, D.; Vulić, I.; Henderson, M. Span-ConveRT: Few-shot Span Extraction for Dialog with Pretrained Conversational Representations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics, Online, 5–10 July 2020; pp. 107–121. [Google Scholar] [CrossRef]
- Qiu, L.; Li, J.; Bi, W.; Zhao, D.; Yan, R. Are training samples correlated? Learning to generate dialogue responses with multiple references. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3826–3835. [Google Scholar]
- Moon, S.; Shah, P.; Kumar, A.; Subba, R. Opendialkg: Explainable conversational reasoning with attention-based walks over knowledge graphs. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 845–854. [Google Scholar]
- Zhang, H.; Lan, Y.; Pang, L.; Guo, J.; Cheng, X. Recosa: Detecting the relevant contexts with self-attention for multi-turn dialogue generation. arXiv 2019, arXiv:1907.05339. [Google Scholar]
- Henderson, M.; Vulić, I.; Gerz, D.; Casanueva, I.; Budzianowski, P.; Coope, S.; Spithourakis, G.; Wen, T.H.; Mrkšić, N.; Su, P.H. Training Neural Response Selection for Task-Oriented Dialogue Systems. arXiv 2019, arXiv:1906.01543. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Jung, J.; Son, B.; Lyu, S. Attnio: Knowledge graph exploration with in-and-out attention flow for knowledge-grounded dialogue. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Punta Cana, Dominican Republic, 8–12 November 2020; pp. 3484–3497. [Google Scholar]
- Weizenbaum, J. ELIZA—A computer program for the study of natural language communication between man and machine. Commun. ACM 1983, 26, 23–28. [Google Scholar] [CrossRef]
- ZEMČÍK, M.T. A brief history of chatbots. DEStech Trans. Comput. Sci. Eng. 2019, 10. [Google Scholar] [CrossRef]
- Caldarini, G.; Jaf, S.; McGarry, K. A Literature Survey of Recent Advances in Chatbots. Information 2022, 13, 41. [Google Scholar] [CrossRef]
- Nimavat, K.; Champaneria, T. Chatbots: An overview. Types, architecture, tools and future possibilities. Int. J. Sci. Res. Dev. 2017, 5, 1019–1024. [Google Scholar]
- Miner, A.S.; Laranjo, L.; Kocaballi, A.B. Chatbots in the fight against the COVID-19 pandemic. NPJ Digit. Med. 2020, 3, 65. [Google Scholar] [CrossRef] [PubMed]
- Adamopoulou, E.; Moussiades, L. An Overview of Chatbot Technology. Artif. Intell. Appl. Innov. 2020, 584, 373–383. [Google Scholar]
- Deshpande, A.; Shahane, A.; Gadre, D.; Deshpande, M.; Joshi, P.M. A survey of various chatbot implementation techniques. Int. J. Comput. Eng. Appl. 2017, 11. [Google Scholar]
- Suta, P.; Lan, X.; Wu, B.; Mongkolnam, P.; Chan, J. An overview of machine learning in chatbots. Int. J. Mech. Eng. Robot. Res. 2020, 9, 502–510. [Google Scholar] [CrossRef]
- Kim, J.; Forsythe, S. Adoption of virtual try-on technology for online apparel shopping. J. Interact. Mark. 2008, 22, 45–59. [Google Scholar] [CrossRef]
- Lee, H.J.; Yang, K. Interpersonal service quality, self-service technology (SST) service quality, and retail patronage. J. Retail. Consum. Serv. 2013, 20, 51–57. [Google Scholar] [CrossRef]
- Yang, K.; Forney, J.C. The moderating role of consumer technology anxiety in mobile shopping adoption: Differential effects of facilitating conditions and social influences. J. Electron. Commer. Res. 2013, 14, 334. [Google Scholar]
- Chin, W.W.; Marcolin, B.L.; Newsted, P.R. A partial least squares latent variable modeling approach for measuring interaction effects: Results from a Monte Carlo simulation study and an electronic-mail emotion/adoption study. Inf. Syst. Res. 2003, 14, 189–217. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Lee, K.Y.; Emokpae, E.; Yang, S.B. What makes you continuously use chatbot services? Evidence from chinese online travel agencies. Electron. Mark. 2021, 31, 575–599. [Google Scholar] [CrossRef] [PubMed]
- Jain, M.; Kumar, P.; Kota, R.; Patel, S.N. Evaluating and informing the design of chatbots. In Proceedings of the 2018 Designing Interactive Systems Conference, San Diego, CA, USA, 23–28 June 2018; pp. 895–906. [Google Scholar]
- Sankar, R.; Balakrishnan, K. Empowering chatbots with business intelligence by big data integration. Int. J. Adv. Res. Comput. Sci. 2018, 9, 627–631. [Google Scholar]
- Breitfuss, A.; Errou, K.; Kurteva, A.; Fensel, A. Representing emotions with knowledge graphs for movie recommendations. Future Gener. Comput. Syst. 2021, 125, 715–725. [Google Scholar] [CrossRef]
- Ait-Mlouk, A.; Jiang, L. KBot: A Knowledge Graph Based ChatBot for Natural Language Understanding Over Linked Data. IEEE Access 2020, 8, 149220–149230. [Google Scholar] [CrossRef]
- Yan, R.; Wu, W. Empowering conversational AI is a trip to Mars: Progress and future of open domain human–computer dialogues. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; Volume 35, pp. 15078–15086. [Google Scholar]
- The Rise of Multimodal and Multilingual Search. Available online: https://www.oncrawl.com/technical-seo/rise-multimodal-multilingual-search/ (accessed on 23 January 2022).
- ReadWrite What Does the Future of Online Search Look Like? Available online: https://readwrite.com/2020/12/28/future-of-seo/ (accessed on 30 July 2021).
- The Future of Search. Available online: https://www.iprospect.com/en/gb/news-and-insights/news/the-future-of-search/ (accessed on 30 July 2021).
- Sanderson, M.; Croft, W.B. The history of information retrieval research. Proc. IEEE 2012, 100, 1444–1451. [Google Scholar] [CrossRef]
- Cuquet, M.; Fensel, A. The societal impact of big data: A research roadmap for Europe. Technol. Soc. 2018, 54, 74–86. [Google Scholar] [CrossRef] [Green Version]
- Reid, P.; Laffey, D. Search Engines: Past, Present, and Future. In Encyclopedia of E-Commerce Development, Implementation, and Management; IGI Global: Hershey, PA, USA, 2016; pp. 1102–1115. [Google Scholar]
- Caballero, M. A Brief Survey of Question Answering Systems. Int. J. Artif. Intell. Appl. (IJAIA) 2021, 12, 5. [Google Scholar] [CrossRef]
- Jacques, R.; Følstad, A.; Gerber, E.; Grudin, J.; Luger, E.; Monroy-Hernández, A.; Wang, D. Conversational agents: Acting on the wave of research and development. In Proceedings of the Extended abstracts of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–8. [Google Scholar]
- Masche, J.; Le, N.T. A review of technologies for conversational systems. In Advanced Computational Methods for Knowledge Engineering. ICCSAMA 2017; Springer: Cham, Switzerland, 2017; pp. 212–225. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| From | To | Description |
|---|---|---|
| Keyword search engine | Semantic Search Engine | Keyword search engines look for literal matches of the query words, while semantic search engines not only return results based on keywords but also consider the contextual meaning and the user’s intent when fetching the relevant results. |
| Semantic search engine | Question answering | Semantic search engines fetch relevant results based on the user’s query, while QASs allow the user to submit a question and derive the pertinent and exact answers. |
| Question answering | Dialogue system | The objective of a QAS is to focus on producing the exact answer for a single-user question, while unintentionally ignoring the reasons that motivated that user to pose this question. So, dialogue systems as conversational agents are developed to extend conversations between the user and agent. |
| Dialogue system | Chatbot | Chatbots are a sub-type of dialogue systems that perform chit-chat with the user or serve as an assistant via conversations. |
| Keyword Search | Semantic Search | Question Answering | Dialogue System | Chatbots |
|---|---|---|---|---|
| The first keyword search engine called “Archie” was launched in 1990 [22]. For almost two decades, it was the most common approach that supported browsing services on the web [22]. Keyword search engines were gradually replaced by semantic search engines in the early 10’s [135]. | Semantic search has emerged with the semantic web in the early 00’s [43]. However, the major breakthrough of the semantic search engines as a service was in 2013, when Google presented the “Hummingbird” update [135]. As of today, browsing services supported by semantic search engines play a crucial role in the big picture of the web as a service. | The first QAS was built in 1961 to answer simple questions relating to American League baseball games [136]. With emerging knowledge graphs in 2012, QASs across knowledge graphs have been introduced. Since the early stage, QASs have advanced significantly, particularly about a decade ago, due to progress in natural language understanding and deep neural networks | The concept of conversing in language shifted from fiction to scientific pursuit when Alan Turing forecast machines that could converse like humans in 1949 [137]. Dialogue systems took significant steps in 1966 and 2011 with the emerging ELIZA and Siri, respectively [94]. Work on dialogue systems has been of broad significance in the recent decade. | In 1966, ELIZA, the first chatbot, appeared intending to imitate a psychologist [138]. PARRY in 1972 was another famous chatbot 16 years later [113]. The first chatbots were relatively simple, and nowadays, they are much more intelligent. Examples of intelligent digital assistants (as they are called nowadays) are Amazon Alexa, Apple Siri, Google Assistant, and Microsoft Cortana [114]. |
| Keyword Search | Semantic Search | Question Answering | Dialogue System | Chatbots |
|---|---|---|---|---|
|
|
|
|
|
| Keyword Search | Semantic Search | Question Answering | Dialogue System | Chatbots |
|---|---|---|---|---|
| For users typing (e.g., “Restaurants” and “Innsbruck”), Keyword Search Engines return web pages containing these keywords. The users have to check the returned pages one by one to find relevant information for them. | For the case of “Pizza, a semantic search engine might return a Pizza description, which details its definition, name, nutritional facts, and local where one can order it. | For users’ questions (e.g., “Which restaurants in Innsbruck serve Austrian cuisine on Sundays for between €30 and €60?”), QASs provide precise answers. | Users’ intents are identified through a dialogue (e.g., to book a restaurant’s table, a dialogue is shaped to understand the user’s information needs such as kind of food, location, price range, etc.). | For the case of booking a table in a restaurant, users’ personal information is used to return a restaurant that matches the user’s preferences and there is no need for the users to leave the chatbot and call the restaurant. |
| Keyword Search | Semantic Search | Question Answering | Dialogue System | Chatbots |
|---|---|---|---|---|
|
|
|
|
|
| Keyword Search | Semantic Search | Question Answering | Dialogue System | Chatbots |
|---|---|---|---|---|
|
|
|
|
|
| Keyword Search | Semantic Search | Question Answering | Dialogue System | Chatbots |
|---|---|---|---|---|
|
|
|
|
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aghaei, S.; Angele, K.; Huaman, E.; Bushati, G.; Schiestl, M.; Fensel, A. Interactive Search on the Web: The Story So Far. Information 2022, 13, 324. https://doi.org/10.3390/info13070324
Aghaei S, Angele K, Huaman E, Bushati G, Schiestl M, Fensel A. Interactive Search on the Web: The Story So Far. Information. 2022; 13(7):324. https://doi.org/10.3390/info13070324
Chicago/Turabian StyleAghaei, Sareh, Kevin Angele, Elwin Huaman, Geni Bushati, Mathias Schiestl, and Anna Fensel. 2022. "Interactive Search on the Web: The Story So Far" Information 13, no. 7: 324. https://doi.org/10.3390/info13070324
APA StyleAghaei, S., Angele, K., Huaman, E., Bushati, G., Schiestl, M., & Fensel, A. (2022). Interactive Search on the Web: The Story So Far. Information, 13(7), 324. https://doi.org/10.3390/info13070324