
Deep Learning Approaches for Big Data-Driven Metadata Extraction in Online Job Postings


 and
and
Abstract
:1. Introduction
2. Previous Work
3. Methodology
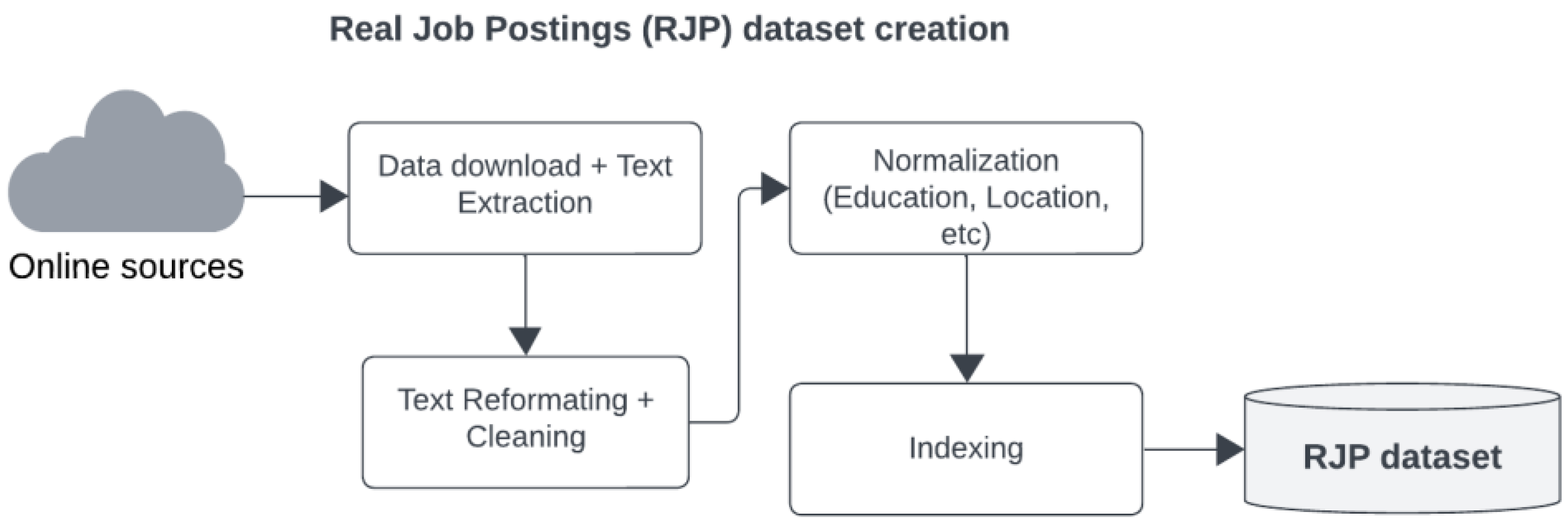
3.1. Overview
3.2. Data Collection from Online Sources and Preprocessing
- ○
- Correcting typographical errors.
- ○
- Removing duplicate records.
- ○
- Stripping special characters like &NBSP (HTML element), \r, and _.
- ○
- Managing empty lines within a text block.
- ○
- Using regular expressions to identify and exclude URLs embedded in job descriptions.
- ○
- Deleting site-specific prefix keywords (e.g., ‘Job Description’).
- ○
- Constructing detailed inventories for geographical names linked to companies and ensuring unified location representations.
- ○
- Creating mappings for educational titles, recognizing that the same qualifications might be described differently across job boards.
3.3. Utilization of LLMs for Job Postings Generation
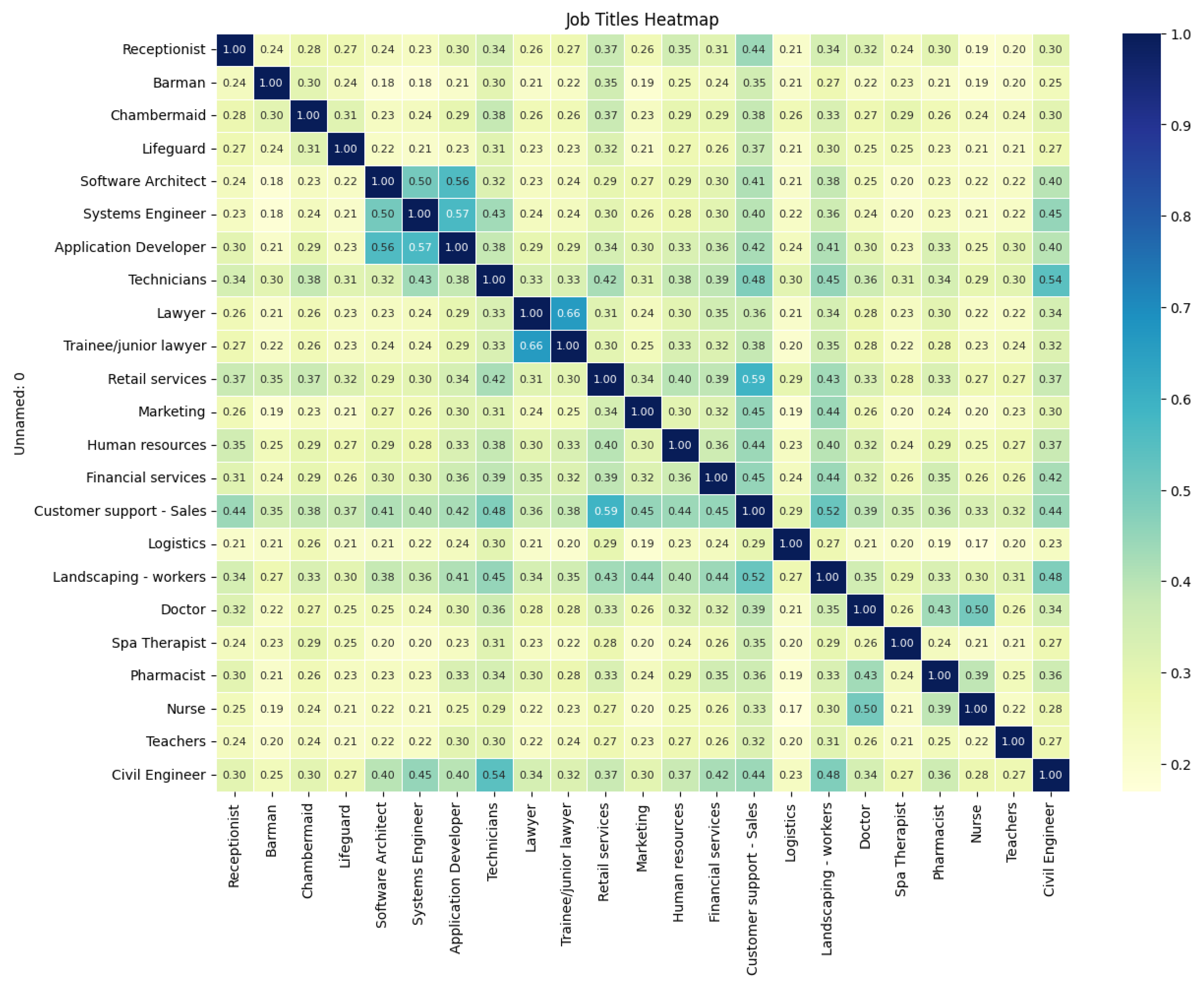
Measuring Similarity of Job Postings
3.4. Training Dataset Creation and Use Cases
- ○
- one dataset with real-world data from online sources (RJP),
- ○
- two synthetic datasets from the OpenAI API (davinci-003) and the GPT4All framework models Falcon, Vicuna, and Wizardlm (FVW),
- ○
- an augmented dataset (augmented), which is a composition of instances from davinci-003 for augmenting underrepresented classes, and 60% of the RJP dataset (‘davinci-003’ was selected due to its diverse and linguistically rich responses, resulting in a higher quality of augmentation). This augmented dataset was then combined with the RJP_train (60% of the original RJP dataset),
- ○
- RJP_evaluation dataset (evaluation) derived from the remaining data of the RJP dataset (approximately 40%). To ensure both a substantial training set and a robust evaluation, we allocated 60% of the data for training and 40% for evaluation. The selection of instances for each subset was conducted randomly, ensuring against a biased distribution or the exclusion of difficult-to-learn/classify instances.
3.5. Models Architecture and Training
3.6. Metrics
4. Results
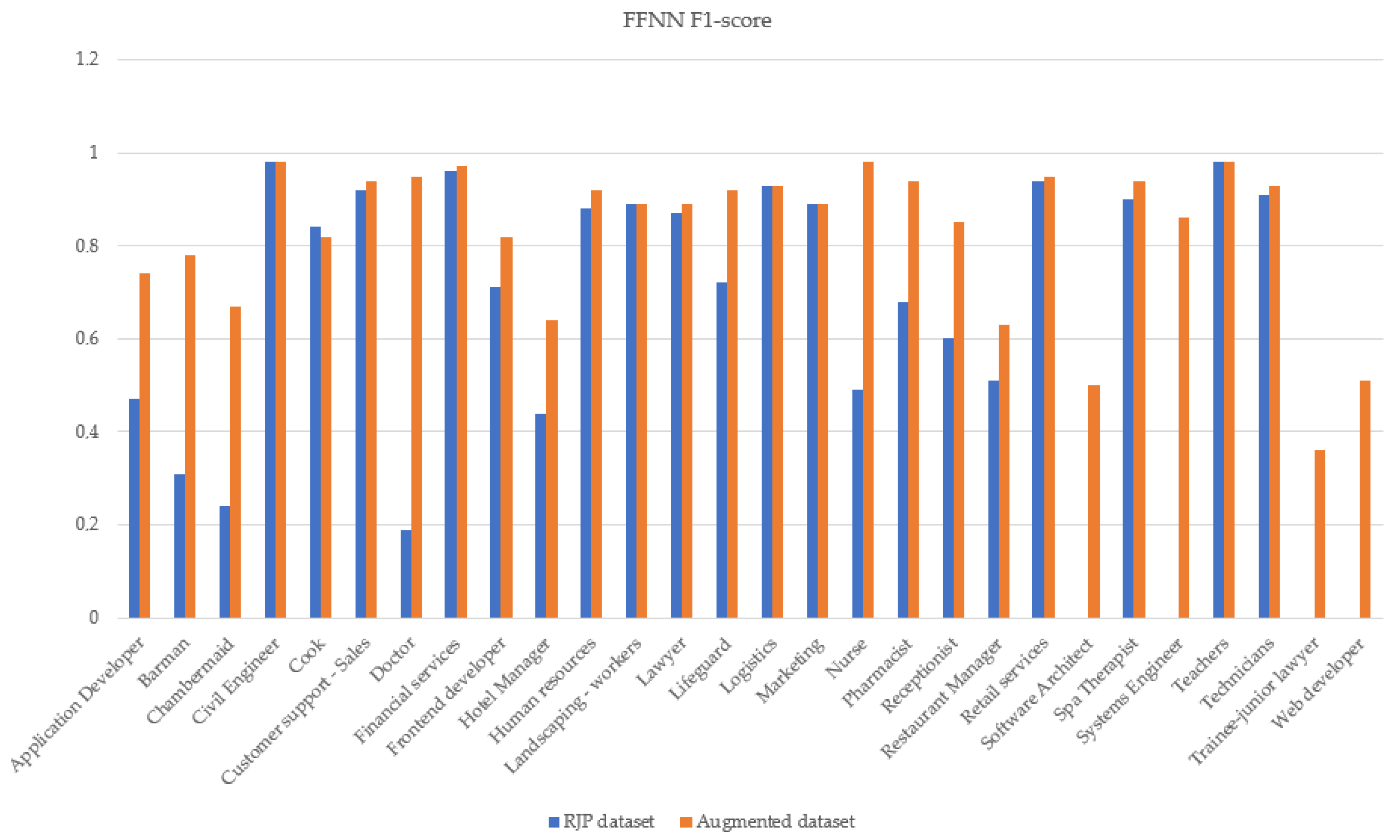
4.1. Use Case 1 per Class Results
4.2. Use Case 2 per Class Results
5. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- OpenAI API. Available online: https://bit.ly/3UOELSX (accessed on 15 October 2023).
- GPT4All API. Available online: https://docs.gpt4all.io/index.html (accessed on 15 October 2023).
- Ye, J.; Chen, X.; Xu, N.; Zu, C.; Shao, Z.; Liu, S.; Cui, Y.; Zhou, Z.; Gong, C.; Shen, Y.; et al. A Comprehensive Capability Analysis of GPT-3 and GPT-3.5 Series Models. arXiv 2023, arXiv:2303.10420. [Google Scholar]
- Anand, Y.; Nussbaum, Z.; Duderstadt, B.; Schmidt, B.; Mulyar, A. GPT4All: Training an Assistant-style Chatbot with Large Scale Data Distillation from GPT-3.5-Turbo. 2023. Available online: https://github.com/nomic-ai/gpt4all (accessed on 16 September 2023).
- The Rise of Open-Source LLMs in 2023: A Game Changer in AI. Available online: https://www.ankursnewsletter.com/p/the-rise-of-open-source-llms-in-2023 (accessed on 15 October 2023).
- 12 Best Large Language Models (LLMs) in 2023. Available online: https://beebom.com/best-large-language-models-llms/ (accessed on 15 October 2023).
- Penedo, G.; Malartic, Q.; Hesslow, D.; Cojocaru, R.; Cappelli, A.; Alobeidli, H.; Pannier, B.; Almazrouei, E.; Launay, J. The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only. arXiv 2023, arXiv:2306.01116. [Google Scholar]
- Chiang, W.; Li, Z.; Lin, Z.; Sheng, Y.; Wu, Z.; Zhang, H.; Zheng, L.; Zhuang, S.; Zhuang, Y.; Gonzalez, J.E.; et al. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality. Available online: https://lmsys.org/blog/2023-03-30-vicuna/ (accessed on 15 October 2023).
- Xu, C.; Sun, Q.; Zheng, K.; Geng, X.; Zhao, P.; Feng, J.; Tao, C.; Jiang, D. WizardLM: Empowering Large Language Models to Follow Complex Instructions. arXiv 2023, arXiv:2304.12244. [Google Scholar]
- White, J.; Fu, Q.; Hays, S.; Sandborn, M.; Olea, C.; Gilbert, H.; Elnashar, A.; Spencer-Smith, J.; Schmidt, D. A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT. arXiv 2023, arXiv:2302.11382. [Google Scholar]
- Strobelt, H.; Webson, A.; Sanh, V.; Hoover, B.; Beyer, J.; Pfister, H.; Rush, A.M. Interactive and Visual Prompt Engineering for Ad-hoc Task Adaptation with Large Language Models. IEEE Trans. Vis. Comput. Graph. 2023, 29, 1146–1156. [Google Scholar] [CrossRef]
- Liu, Y.; Deng, G.; Xu, Z.; Li, Y.; Zheng, Y.; Zhang, Y.; Zhao, L.; Zhang, T.; Liu, Y. Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study. arXiv 2023, arXiv:2305.13860. [Google Scholar]
- Gao, A. Prompt Engineering for Large Language Models. 2023. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4504303 (accessed on 24 October 2023).
- Liu, V.; Chilton, L.B. Design Guidelines for Prompt Engineering Text-to-Image Generative Models. In Proceedings of the CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022; pp. 1–23. [Google Scholar] [CrossRef]
- Sabit, E. Prompt Engineering for ChatGPT: A Quick Guide to Techniques, Tips, And Best Practices. TechRxiv 2023. techrXiv:22683919.v2. [Google Scholar]
- Bayer, M.; Kaufhold, M.A.; Reuter, C. 2022. A Survey on Data Augmentation for Text Classification. ACM Comput. Surv. 2023, 55, 146. [Google Scholar] [CrossRef]
- Shi, Z.; Lipani, A. Rethink the Effectiveness of Text Data Augmentation: An Empirical Analysis. arXiv 2023, arXiv:2306.07664. [Google Scholar]
- Kumar, V.; Choudhary, A.; Cho, E. Data Augmentation using Pre-trained Transformer Models. arXiv 2021, arXiv:2003.02245. [Google Scholar]
- Li, Y.; Wang, X.; Miao, Z.; Tan, W.C. Data augmentation for ML-driven data preparation and integration. Proc. VLDB Endow. 2021, 14, 3182–3185. [Google Scholar] [CrossRef]
- Whitehouse, C.; Choudhury, M.; Aji, A.F. LLM-powered Data Augmentation for Enhanced Crosslingual Performance. arXiv 2023, arXiv:2305.14288v1. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.; Hua, N.; Limtiaco, N.; St. John, R.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal Sentence Encoder for English. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 31 October–4 November 2018; pp. 169–174. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Nasser, I.; Alzaanin, A.H. Machine Learning and Job Posting Classification: A Comparative Study. Int. J. Eng. Inf. Syst. 2020, 4, 6–14. [Google Scholar]
- Zaroor, A.; Maree, M.; Sabha, M. JRC: A Job Post and Resume Classification System for Online Recruitment. In Proceedings of the 2017 IEEE 29th International Conference on Tools with Artificial Intelligence (ICTAI), Boston, MA, USA, 6–8 November 2017; pp. 780–787. [Google Scholar] [CrossRef]
- De Mauro, A.; Greco, M.; Grimaldi, M.; Ritala, P. Human resources for Big Data professions: A systematic classification of job roles and required skill sets. Inf. Process. Manag. 2018, 54, 807–817. [Google Scholar] [CrossRef]
- Zhang, M.; Jensen, K.N.; Plank, B. Kompetencer: Fine-grained Skill Classification in Danish Job Postings via Distant Supervision and Transfer Learning. arXiv 2022, arXiv:2205.01381. [Google Scholar]
- Goindani, M.; Liu, Q.; Chao, J.; Jijkoun, V. Employer Industry Classification Using Job Postings. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 183–188. [Google Scholar] [CrossRef]
- Varelas, G.; Lagios, D.; Ntouroukis, S.; Zervas, P.; Parsons, K.; Tzimas, G. Employing Natural Language Processing Techniques for Online Job Vacancies Classification; IFIP Advances in Information and Communication Technology; Springer: Cham, Switzerland, 2022; pp. 333–344. [Google Scholar] [CrossRef]
- Hugging Face Libraries. Available online: https://huggingface.co/docs/hub/models-libraries (accessed on 15 October 2023).
- Scrappy. Available online: https://scrapy.org/ (accessed on 13 October 2023).
- Requests. Available online: https://python.langchain.com/docs/integrations/tools/requests (accessed on 15 October 2023).
- Beautiful Soup. Available online: https://www.crummy.com/software/BeautifulSoup/bs4/doc/ (accessed on 15 October 2023).
- MariaDB. Available online: https://mariadb.org (accessed on 13 October 2023).
- ChatGPT—Python Parameters Tuning. Available online: https://platform.openai.com/docs/api-reference/completions/create (accessed on 15 October 2023).
- GPT4All—Python Parameters Tuning. Available online: https://docs.gpt4all.io/gpt4all_python.html#the-generate-method-api (accessed on 15 October 2023).
- Sparck, J.K. A Statistical Interpretation of Term Specificity and Its Application in Retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Cosine Similarity. Available online: https://www.sciencedirect.com/topics/computer-science/cosine-similarity (accessed on 15 October 2023).
- Josifoski, M.; Sakota, M.; Peyrard, M.; West, R. Exploiting Asymmetry for Synthetic Training Data Generation: SynthIE and the Case of Information Extraction. arXiv 2023, arXiv:2303.04132v1. [Google Scholar]
- Xu, B.; Wang, Q.; Lyu, Y.; Dai, D.; Zhang, Y.; Mao, Z. S2ynRE: Two-Stage Self-Training with Synthetic Data for Low-resource Relation Extraction. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Association for Computational Linguistics: Kerrville, TX, USA; Volume 1, pp. 8186–8207. [Google Scholar] [CrossRef]
- Jeronymo, V.; Bonifacio, L.; Abonizio, H.; Fadaee, M.; Lotufo, R.; Zavrel, J.; Nogueira, R. InPars-v2: Large Language Models as Efficient Dataset Generators for Information Retrieval. arXiv 2023, arXiv:2301.01820v4. [Google Scholar]
- Veselovsky, V.; Ribeiro, M.H.; Arora, A.; Josifoski, M.; Anderson, A.; West, R. Generating Faithful Synthetic Data with Large Language Models: A Case Study in Computational Social Science. arXiv 2023, arXiv:2305.15041v1. [Google Scholar]
- Abonizio, H.; Bonifacio, L.; Jeronymo, V.; Lotufo, R.; Zavrel, J.; Nogueira, R. InPars Toolkit: A Unified and Reproducible Synthetic Data Generation Pipeline for Neural Information Retrieval. arXiv 2023, arXiv:2307.04601v1. [Google Scholar]
- Skondras, P.; Psaroudakis, G.; Zervas, P.; Tzimas, G. Efficient Resume Classification through Rapid Dataset Creation Using ChatGPT. In Proceedings of the 14th International Conference on Information, Intelligence, Systems and Applications (IISA 2023), Volos, Greece, 10–12 July 2023. [Google Scholar]
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient Transformers: A Survey. 2022. ACM Comput. Surv. 2023, 55, 1–34. [Google Scholar] [CrossRef]
- Safeguarding LLMs with Guardrails. Available online: https://towardsdatascience.com/safeguarding-llms-with-guardrails-4f5d9f57cff2 (accessed on 15 October 2023).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Job Category | RJP | FVW | Davinci-003 | Augmented | RJP_ Evaluation |
|---|---|---|---|---|---|
| Lawyers | 367 | 153 | 250 | 275 | 147 |
| Trainee lawyers | 42 | 150 | 150 | 175 | 32 |
| Teachers | 499 | 155 | 150 | 299 | 200 |
| Human resources | 498 | 155 | 150 | 299 | 199 |
| Marketing | 497 | 255 | 250 | 298 | 199 |
| Customer support—sales | 495 | 268 | 250 | 297 | 198 |
| Retail services | 495 | 155 | 150 | 297 | 198 |
| Cook | 500 | 205 | 200 | 300 | 200 |
| Logistics | 494 | 154 | 150 | 296 | 198 |
| Financial services | 492 | 219 | 200 | 295 | 197 |
| Civil engineers | 484 | 160 | 150 | 290 | 194 |
| Receptionist | 65 | 170 | 232 | 271 | 44 |
| Hotel manager | 68 | 170 | 232 | 272 | 58 |
| Barman | 67 | 170 | 232 | 271 | 28 |
| Lifeguard | 64 | 160 | 160 | 198 | 26 |
| Restaurant manager | 67 | 180 | 232 | 272 | 25 |
| Chambermaid | 67 | 180 | 232 | 270 | 63 |
| Landscaping—workers | 471 | 189 | 150 | 283 | 188 |
| Technicians | 469 | 255 | 250 | 281 | 188 |
| Systems engineer | 47 | 170 | 252 | 280 | 19 |
| Web developer | 27 | 170 | 250 | 266 | 21 |
| Software architect | 31 | 170 | 262 | 280 | 13 |
| Front end developer | 163 | 180 | 179 | 280 | 62 |
| Application aeveloper | 122 | 182 | 210 | 280 | 52 |
| Pharmacist | 64 | 169 | 242 | 280 | 26 |
| Doctor | 47 | 186 | 252 | 280 | 19 |
| Nurse | 65 | 183 | 180 | 219 | 26 |
| Spa Therapist | 84 | 191 | 230 | 280 | 34 |
| Total | 6851 | 5104 | 5827 | 7684 | 2854 |
| Job Category/Class | Similar/Specialized Type of Job |
|---|---|
| Human resources | HR Generalist, HR Assistant, HR Specialist, HR Payroll Officer, Junior HR Assistant, and HR Business Partner |
| Civil Engineer | Civil Engineer, Building Architect, Mechanical Technician, Natural Resources Engineer |
| Cooks | A’ Cook, B’ Cook, Chef, Baker, Sous Chef, Buffet/Bar, and Pastry Chef |
| Customer support—sales | Customer Support, Customer Service Supporter, Sales Executive, Commercial Representative, Customer Experience Specialist, E-commerce Site Specialist, Customer Service Supporter, and Customer Service Agent |
| Financial services | Economist, Accounting Officer, Accountant, Financial Advisor, Investment Advisor, Portfolio Manager, Financial Services Risk Management Advisor, Financial Services Consultant, Financial Analyst, Auditor, Credit Manager, and Financial Manager |
| Landscaping—workers | Agro Coordinator, Agronomist, Gardener, Market Development Agronomist, Landscape Environmental Manager, and Landscape Engineer |
| Logistics | Warehouse Worker, Warehouse Driver, Warehouse Officer, Warehouse Assistant, and Warehouse Staff |
| Marketing | Sales and Marketing, Marketing Executive, Marketing Officer, Digital Marketing, Marketing Manager, Performance Marketing Specialist, and Marketing Associate |
| Retail Services | Cashier, Store Manager, Food Delivery Driver, and Store Administrator |
| Software Engineer | Systems Engineer, Web Developer, Software Architect, Front end Developer, and Application Developer |
| Teachers | English Teacher, Italian Teacher, Spanish Teacher, German Teacher, French Teacher, Russian Teacher, and Arabic Teacher |
| Technicians | Plumber, Electrician, Refrigeration engineer, Ironworker, Bicycle technician, Bodyworker Car painter, and Cabinet maker |
| Experiments | Use Cases | Model | Training Dataset | Evaluation Dataset | Accuracy | Macro Avg |
|---|---|---|---|---|---|---|
| 1 | Ref | FFNN | RJP_train | RJP_evaluation | 0.84 | 0.62 |
| 2 | Ref | BERT | RJP_train | RJP_evaluation | 0.96 | 0.91 |
| 3 | 1 | FFNN | davinci-003 | RJP_evaluation | 0.73 | 0.66 |
| 4 | 1 | FFNN | FVW | RJP_evaluation | 0.73 | 0.65 |
| 5 | 1 | BERT | davinci-003 | RJP_evaluation | 0.86 | 0.79 |
| 6 | 1 | BERT | FVW | RJP_evaluation | 0.84 | 0.77 |
| 7 | 2 | FFNN | Augmented | RJP_evaluation | 0.89 | 0.83 |
| 8 | 2 | BERT | Augmented | RJP_evaluation | 0.97 | 0.94 |
| Dataset | Approach | Precision | Recall | F1-Score |
|---|---|---|---|---|
| RJP | FFNN | 0.6546 | 0.6329 | 0.6161 |
| RJP | BERT | 0.9050 | 0.9111 | 0.9068 |
| davinci-003 | FFNN | 0.6832 | 0.6889 | 0.6621 |
| davinci-003 | BERT | 0.8861 | 0.7771 | 0.7886 |
| FVW | FFNN | 0.6886 | 0.6607 | 0.6546 |
| FVW | BERT | 0.8179 | 0.7700 | 0.7725 |
| Dataset | Approach | Precision | Recall | F1-Score |
|---|---|---|---|---|
| RJP | FFNN | 0.6546 | 0.633 | 0.6160 |
| RJP | BERT | 0.9050 | 0.9111 | 0.9068 |
| Augmented | FFNN | 0.8625 | 0.8207 | 0.8279 |
| Augmented | BERT | 0.9411 | 0.9504 | 0.9432 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Skondras, P.; Zotos, N.; Lagios, D.; Zervas, P.; Giotopoulos, K.C.; Tzimas, G. Deep Learning Approaches for Big Data-Driven Metadata Extraction in Online Job Postings. Information 2023, 14, 585. https://doi.org/10.3390/info14110585
Skondras P, Zotos N, Lagios D, Zervas P, Giotopoulos KC, Tzimas G. Deep Learning Approaches for Big Data-Driven Metadata Extraction in Online Job Postings. Information. 2023; 14(11):585. https://doi.org/10.3390/info14110585
Chicago/Turabian StyleSkondras, Panagiotis, Nikos Zotos, Dimitris Lagios, Panagiotis Zervas, Konstantinos C. Giotopoulos, and Giannis Tzimas. 2023. "Deep Learning Approaches for Big Data-Driven Metadata Extraction in Online Job Postings" Information 14, no. 11: 585. https://doi.org/10.3390/info14110585
APA StyleSkondras, P., Zotos, N., Lagios, D., Zervas, P., Giotopoulos, K. C., & Tzimas, G. (2023). Deep Learning Approaches for Big Data-Driven Metadata Extraction in Online Job Postings. Information, 14(11), 585. https://doi.org/10.3390/info14110585