
Reconsidering Read and Spontaneous Speech: Causal Perspectives on the Generation of Training Data for Automatic Speech Recognition




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Since the causal perspective requires a researcher to be explicit about the assumptions and relations of the data generation process, we rigorously analyse different scenarios of ASR, outline their influencing factors, and introduce a classification scheme, thus providing insight into how read speech and spontaneous speech do not conform to the same data generation process, and hence, differ in their sources of noise (Section 2). Notably, there is no real ground truth for annotations in the case of spontaneous speech data. Learning from it therefore constitutes a noisy-label problem, and must be qualitatively analysed and interpreted differently from read speech.
- We present consequences of the causal mechanisms involved in the generation of speech data to allow for better interpretation and explain failures and successes in learning from it (with a focus on spontaneous speech and its transcription), and ultimately provide directions for future model architectures (Section 3). Concrete aspects of this involve theoretical considerations resulting from speech recognition in causal and anti-causal prediction settings, such as the effectiveness of semi-supervised learning, and a discussion of possible distribution shifts occurring in ASR.
- The perspective of causal reasoning offers a foundation for the judgement of performance, robustness, and transferability of estimates—in short, the generalization behaviour of prediction models when the assumptions of inference diverge from the actual data generation. Through this, we hope to facilitate scientific interpretation and advance the analysis of learning behaviour, and reconcile the two viewpoints of engineering and modelling.
2. Some Characteristics of ASR Data
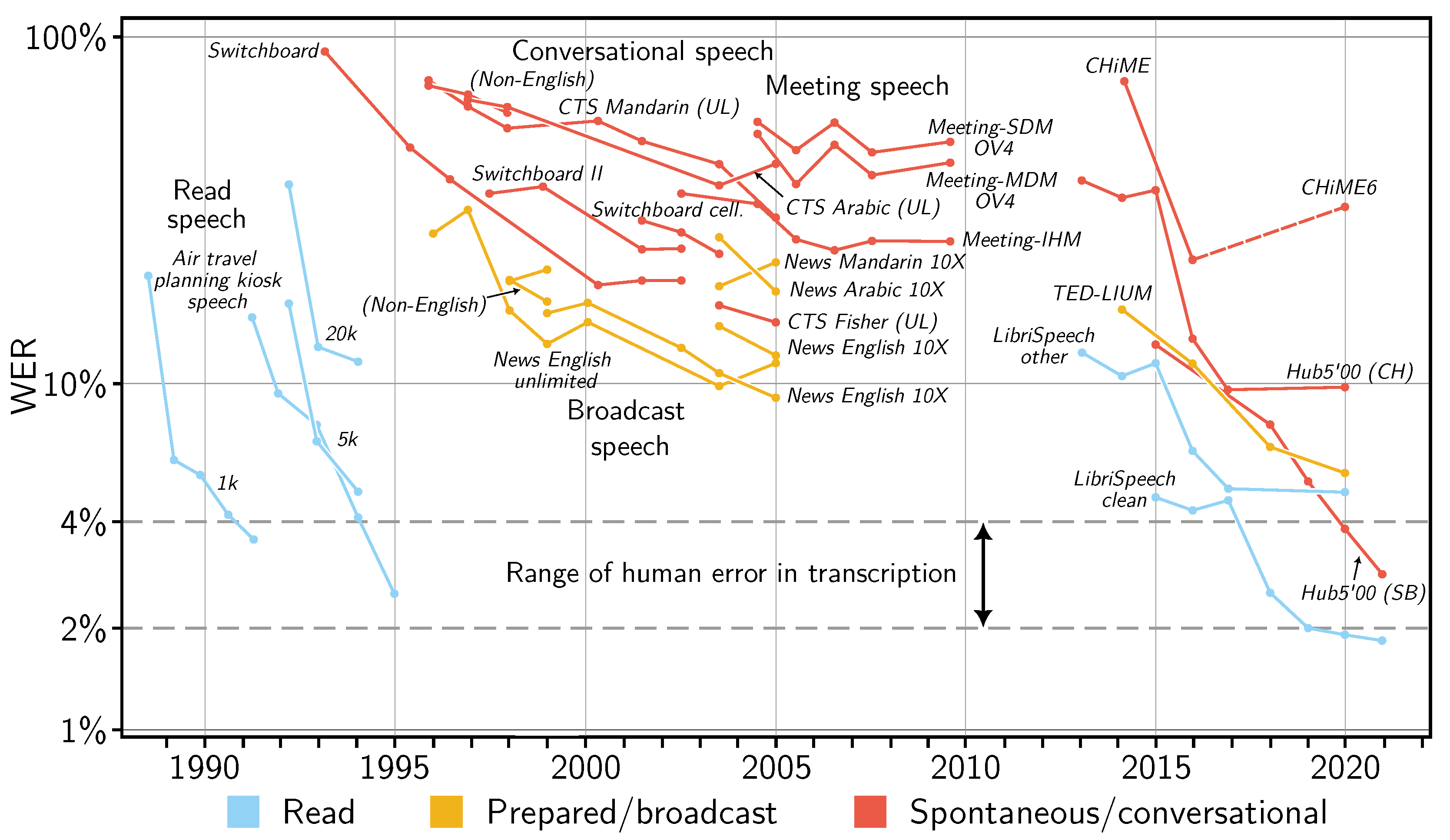
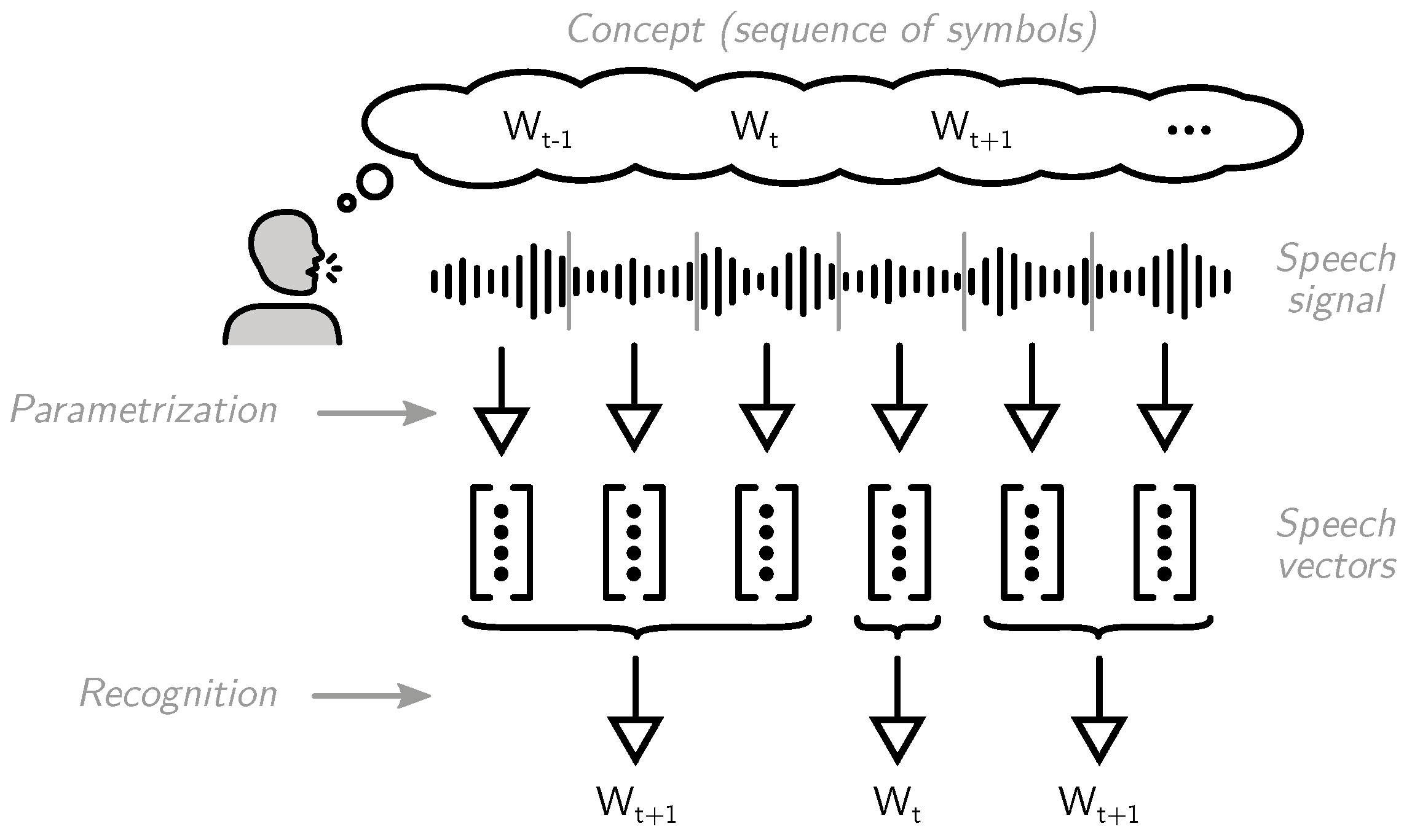
2.1. The Case of Spontaneous Speech
- musst einen <?>Ofen bauen “[you] must build a <?> oven”
- hast einen <*ENG>reflow offen “[do you] have a reflow open”
3. Modelling beyond Prediction: The Relevance of Causal Reasoning
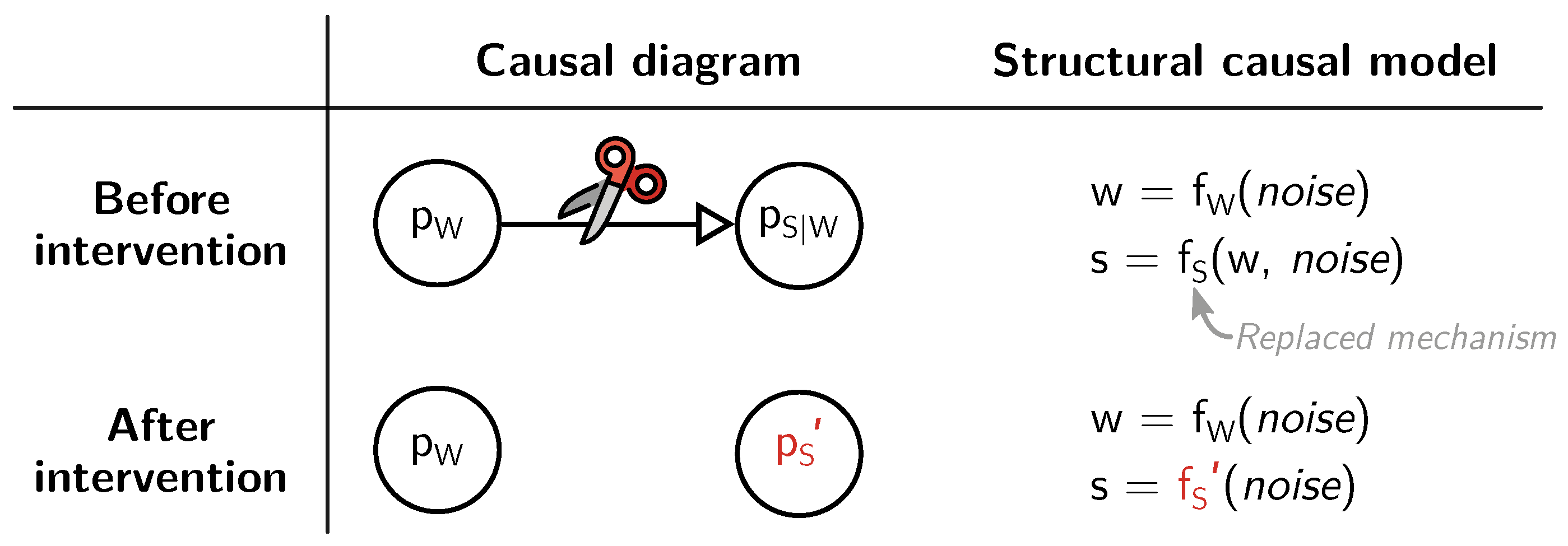
3.1. Formalization of Causal Models
[C]ausal relationships are more “stable” than probabilistic relationships. We expect such difference in stability because causal relationships are ontological, describing objective physical constraints in our world, whereas probabilistic relationships are epistemic, reflecting what we know or believe about the world. Therefore, causal relationships should remain unaltered as long as no change has taken place in the environment, even when our knowledge about the environment undergoes changes.[51] (p. 25)
3.2. A Causal Analysis of ASR Data Generation
3.2.1. Inference in Causal and Anti-Causal Settings
3.2.2. Causal and Anti-Causal Inference under Shifts
3.3. A Causal Perspective on Learning in ASR Models
Notwithstanding the significant progress that can be made by removing errors and improving the consistency of the treebank, there are interesting foundational linguistic issues as to which decisions are linguistically well-justified, and which turn into arbitrary conventions of treebank annotation.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. A Note on Model Misspecification
References
- Pierce, J.R. Whither Speech Recognition? J. Acoust. Soc. Am. 1969, 46, 1049–1051. [Google Scholar] [CrossRef]
- Roe, D.; Wilpon, J. Whither Speech Recognition: The next 25 Years. IEEE Commun. Mag. 1993, 31, 54–62. [Google Scholar] [CrossRef]
- Hannun, A. The History of Speech Recognition to the Year 2030. arXiv 2021, arXiv:2108.00084. [Google Scholar]
- Furui, S. History and Development of Speech Recognition. In Speech Technology: Theory and Applications; Chen, F., Jokinen, K., Eds.; Springer: New York, NY, USA, 2010; pp. 1–18. [Google Scholar] [CrossRef]
- Galitsky, B. Developing Enterprise Chatbots: Learning Linguistic Structures; Springer International Publishing: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Corbett, E.; Weber, A. What Can I Say? Addressing User Experience Challenges of a Mobile Voice User Interface for Accessibility. In Proceedings of the 18th International Conference on Human–Computer Interaction with Mobile Devices and Services, Florence, Italy, 6–9 September 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 72–82. [Google Scholar] [CrossRef] [Green Version]
- Messaoudi, M.D.; Menelas, B.A.J.; Mcheick, H. Review of Navigation Assistive Tools and Technologies for the Visually Impaired. Sensors 2022, 22, 7888. [Google Scholar] [CrossRef] [PubMed]
- Furui, S. Future Directions in Speech Information Processing. J. Acoust. Soc. Am. 1998, 103, 2747. [Google Scholar] [CrossRef]
- King, S.; Frankel, J.; Livescu, K.; McDermott, E.; Richmond, K.; Wester, M. Speech Production Knowledge in Automatic Speech Recognition. J. Acoust. Soc. Am. 2007, 121, 723–742. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Geiger, R.S.; Yu, K.; Yang, Y.; Dai, M.; Qiu, J.; Tang, R.; Huang, J. Garbage in, Garbage out? Do Machine Learning Application Papers in Social Computing Report Where Human-Labeled Training Data Comes From? In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 325–336. [Google Scholar] [CrossRef]
- Jin, Z.; von Kügelgen, J.; Ni, J.; Vaidhya, T.; Kaushal, A.; Sachan, M.; Schölkopf, B. Causal Direction of Data Collection Matters: Implications of Causal and Anticausal Learning for NLP. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2021; pp. 9499–9513. [Google Scholar] [CrossRef]
- Feder, A.; Keith, K.A.; Manzoor, E.; Pryzant, R.; Sridhar, D.; Wood-Doughty, Z.; Eisenstein, J.; Grimmer, J.; Reichart, R.; Roberts, M.E.; et al. Causal Inference in Natural Language Processing: Estimation, Prediction, Interpretation and Beyond. Trans. Assoc. Comput. Linguist. 2022, 10, 1138–1158. [Google Scholar] [CrossRef]
- Glass, J. Towards Unsupervised Speech Processing. In Proceedings of the 2012 11th International Conference on Information Science, Signal Processing and Their Applications (ISSPA), Montreal, QC, Canada, 2–5 July 2012; pp. 1–4. [Google Scholar] [CrossRef]
- Baevski, A.; Hsu, W.N.; Conneau, A.; Auli, M. Unsupervised Speech Recognition. Adv. Neural Inf. Process. Syst. 2021, 34, 27826–27839. [Google Scholar]
- Malik, M.; Malik, M.K.; Mehmood, K.; Makhdoom, I. Automatic Speech Recognition: A Survey. Multimed. Tools Appl. 2021, 80, 9411–9457. [Google Scholar] [CrossRef]
- Zue, V.W.; Seneff, S. Transcription and Alignment of the TIMIT Database. In Recent Research Towards Advanced Man–Machine Interface Through Spoken Language; Fujisaki, H., Ed.; Elsevier: Amsterdam, The Netherlands, 1996; pp. 515–525. [Google Scholar] [CrossRef]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR Corpus Based on Public Domain Audio Books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar] [CrossRef]
- Godfrey, J.J.; Holliman, E.C.; McDaniel, J. SWITCHBOARD: Telephone Speech Corpus for Research and Development. In Proceedings of the Acoustics, Speech, and Signal Processing, IEEE International Conference On IEEE Computer Society, San Francisco, CA, USA, 23–26 March 1992; pp. 517–520. [Google Scholar] [CrossRef]
- Schweitzer, A.; Lewandowski, N. Convergence of Articulation Rate in Spontaneous Speech. In Proceedings of the INTERSPEECH 2013, Lyon, France, 25-29 August 2013; pp. 525–529. [Google Scholar]
- Simpson, A.P.; Kohler, K.J.; Rettstadt, T. The Kiel Corpus of Read/Spontaneous Speech: Acoustic Data Base, Processing Tools and Analysis Results; Technical Report 1997; Universtität Kiel: Kiel, Germany, 1997. [Google Scholar]
- Weninger, F.; Schuller, B.; Eyben, F.; Wöllmer, M.; Rigoll, G. A Broadcast News Corpus for Evaluation and Tuning of German LVCSR Systems. arXiv 2014, arXiv:1412.4616. [Google Scholar]
- Radová, V.; Psutka, J.; Müller, L.; Byrne, W.; Psutka, J.V.; Ircing, P.; Matoušek, J. Czech Broadcast News Speech LDC2004S01; Linguistic Data Consortium: Philadelphia, PA, USA, 2004. [Google Scholar] [CrossRef]
- Schuppler, B.; Hagmüller, M.; Zahrer, A. A Corpus of Read and Conversational Austrian German. Speech Commun. 2017, 94, 62–74. [Google Scholar] [CrossRef]
- Ernestus, M.; Kočková-Amortová, L.; Pollak, P. The Nijmegen Corpus of Casual Czech. In Proceedings of the LREC 2014: 9th International Conference on Language Resources and Evaluation, Reykjavik, Iceland, 26–31 May 2014; pp. 365–370. [Google Scholar]
- Torreira, F.; Ernestus, M. The Nijmegen Corpus of Casual Spanish. In Proceedings of the Seventh Conference on International Language Resources and Evaluation (LREC’10), Valletta, Malta, 17–23 May 2010; European Language Resources Association (ELRA): Paris, France, 2010; pp. 2981–2985. [Google Scholar]
- Auer, P. On-Line Syntax: Thoughts on the Temporality of Spoken Language. Lang. Sci. 2009, 31, 1–13. [Google Scholar] [CrossRef]
- Furui, S.; Nakamura, M.; Ichiba, T.; Iwano, K. Why Is the Recognition of Spontaneous Speech so Hard? In Proceedings of the Text, Speech and Dialogue; Matoušek, V., Mautner, P., Pavelka, T., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; pp. 9–22. [Google Scholar] [CrossRef] [Green Version]
- Valenta, T.; Šmídl, L. Word Confusions in the Transcription and Recognition of Spontaneous Czech. In Tackling the Complexity in Speech; Niebuhr, O., Skarnitzl, R., Eds.; Opera Facultatis Philosophicae Universitatis Carolinae Pragensis; Faculty of Arts, Charles University: Prague, Czech Republic, 2015; Volume XIV. [Google Scholar]
- Linke, J.; Garner, P.N.; Kubin, G.; Schuppler, B. Conversational Speech Recognition Needs Data? Experiments with Austrian German. In Proceedings of the 13th Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; pp. 4684–4691. [Google Scholar]
- Szymański, P.; Żelasko, P.; Morzy, M.; Szymczak, A.; Żyła-Hoppe, M.; Banaszczak, J.; Augustyniak, L.; Mizgajski, J.; Carmiel, Y. WER We Are and WER We Think We Are. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 3290–3295. [Google Scholar] [CrossRef]
- Likhomanenko, T.; Xu, Q.; Pratap, V.; Tomasello, P.; Kahn, J.; Avidov, G.; Collobert, R.; Synnaeve, G. Rethinking Evaluation in ASR: Are Our Models Robust Enough? arXiv 2021, arXiv:2010.11745. [Google Scholar]
- Zhang, Y.; Park, D.S.; Han, W.; Qin, J.; Gulati, A.; Shor, J.; Jansen, A.; Xu, Y.; Huang, Y.; Wang, S.; et al. BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition. IEEE J. Sel. Top. Signal Process. 2022, 1–14. [Google Scholar] [CrossRef]
- Nakamura, M.; Iwano, K.; Furui, S. Differences between Acoustic Characteristics of Spontaneous and Read Speech and Their Effects on Speech Recognition Performance. Comput. Speech Lang. 2008, 22, 171–184. [Google Scholar] [CrossRef]
- Schuppler, B. Rethinking Classification Results Based on Read Speech, or: Why Improvements Do Not Always Transfer to Other Speaking Styles. Int. J. Speech Technol. 2017, 20, 699–713. [Google Scholar] [CrossRef] [Green Version]
- Ajot, J.; Fiscus, J. Speech-To-Text (STT) and Speaker Attributed STT (SASTT) Results. In Proceedings of the NIST Rich Transcription Evaluation Workshop, Gaithersburg, MD, USA, 2009; Available online: https://www.nist.gov/itl/iad/mig/rich-transcription-evaluation (accessed on 12 October 2022).
- Synnaeve, G. wer_are_we. Available online: https://github.com/syhw/wer_are_we/tree/a5d4a30100340c6c8773f329b438017403d606ad#readme (accessed on 6 February 2023).
- Natarajan, N.; Dhillon, I.S.; Ravikumar, P.K.; Tewari, A. Learning with Noisy Labels. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar]
- Beigman, E.; Beigman Klebanov, B. Learning with Annotation Noise. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; Association for Computational Linguistics: Singapore, 2009; pp. 280–287. [Google Scholar]
- Kohler, K.J. The Disappearance of Words in Connected Speech. ZAS Pap. Linguist. 1998, 11, 21–33. [Google Scholar]
- Zayats, V.; Tran, T.; Wright, R.; Mansfield, C.; Ostendorf, M. Disfluencies and Human Speech Transcription Errors. In Proceedings of the Interspeech 2019, ISCA, Graz, Austria, 15–19 September 2019; pp. 3088–3092. [Google Scholar] [CrossRef] [Green Version]
- Raymond, W.D. An Analysis of Coding Consistency in the Transcription of Spontaneous Speech from the Buckeye Corpus. In Proceedings of the Workshop on Spontaneous Speech: Data and Analysis, 2003; The National Institute for Japanese Language: Tokyo, Japan, 2003; pp. 55–71. Available online: https://buckeyecorpus.osu.edu/pubs/SSDA.proof.pdf (accessed on 12 October 2022).
- Stefanowitsch, A. Corpus Linguistics: A Guide to the Methodology; Number 7 in Textbooks in Language Sciences; Language Science Press: Berlin, Gemany, 2020. [Google Scholar] [CrossRef]
- Hovy, E.; Lavid, J. Towards a ’Science’ of Corpus Annotation: A New Methodological Challenge for Corpus Linguistics. Int. J. Transl. 2010, 22, 13–36. [Google Scholar]
- Artstein, R.; Poesio, M. Inter-Coder Agreement for Computational Linguistics. Comput. Linguist. 2008, 34, 555–596. [Google Scholar] [CrossRef] [Green Version]
- Passonneau, R.J.; Carpenter, B. The Benefits of a Model of Annotation. Trans. Assoc. Comput. Linguist. 2014, 2, 311–326. [Google Scholar] [CrossRef]
- Paun, S.; Carpenter, B.; Chamberlain, J.; Hovy, D.; Kruschwitz, U.; Poesio, M. Comparing Bayesian Models of Annotation. Trans. Assoc. Comput. Linguist. 2018, 6, 571–585. [Google Scholar] [CrossRef] [Green Version]
- Tarantola, A. Inverse Problem Theory and Methods for Model Parameter Estimation; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2005. [Google Scholar] [CrossRef] [Green Version]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational Inference: A Review for Statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef] [Green Version]
- Pearl, J. Understanding Simpson’s Paradox. SSRN J. 2013. [Google Scholar] [CrossRef] [Green Version]
- Yao, L.; Chu, Z.; Li, S.; Li, Y.; Gao, J.; Zhang, A. A Survey on Causal Inference. ACM Trans. Knowl. Discov. Data 2021, 15, 1–46. [Google Scholar] [CrossRef]
- Pearl, J. Causality: Models, Reasoning, and Inference, 2nd ed.; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Healy, E.W.; Tan, K.; Johnson, E.M.; Wang, D. An Effectively Causal Deep Learning Algorithm to Increase Intelligibility in Untrained Noises for Hearing-Impaired Listeners. J. Acoust. Soc. Am. 2021, 149, 3943–3953. [Google Scholar] [CrossRef]
- Granger, C.W.J. Investigating Causal Relations by Econometric Models and Cross-spectral Methods. Econometrica 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Peters, J.; Bühlmann, P.; Meinshausen, N. Causal Inference by Using Invariant Prediction: Identification and Confidence Intervals. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2016, 78, 947–1012. [Google Scholar] [CrossRef] [Green Version]
- Bühlmann, P. Invariance, Causality and Robustness. Stat. Sci. 2020, 35, 1–36. [Google Scholar] [CrossRef]
- Schölkopf, B. Causality for Machine Learning. arXiv 2019, arXiv:1911.10500. [Google Scholar]
- Lewis, D. Causation. J. Philos. 1974, 70, 556–567. [Google Scholar] [CrossRef]
- Pearl, J.; Mackenzie, D. The Book of Why: The New Science of Cause and Effect; Basic Books: New York, NY, USA, 2018. [Google Scholar]
- Molnar, C.; Casalicchio, G.; Bischl, B. Interpretable Machine Learning – A Brief History, State-of-the-Art and Challenges. In Proceedings of the ECML PKDD 2020 Workshops; Koprinska, I., Kamp, M., Appice, A., Loglisci, C., Antonie, L., Zimmermann, A., Guidotti, R., Özgöbek, Ö., Ribeiro, R.P., Gavaldà, R., et al., Eds.; Communications in Computer and Information Science; Springer International Publishing: Cham, Switzerland, 2020; pp. 417–431. [Google Scholar] [CrossRef]
- Burkart, N.; Huber, M.F. A Survey on the Explainability of Supervised Machine Learning. J. Artif. Intell. Res. 2021, 70, 245–317. [Google Scholar] [CrossRef]
- Vowels, M.J.; Camgoz, N.C.; Bowden, R. D’ya like DAGs? A Survey on Structure Learning and Causal Discovery. arXiv 2021, arXiv:2103.02582. [Google Scholar] [CrossRef]
- Pearl, J. Causal Inference in Statistics: An Overview. Statist. Surv. 2009, 3, 96–146. [Google Scholar] [CrossRef]
- Bareinboim, E.; Correa, J.D.; Ibeling, D.; Icard, T. On Pearl’s Hierarchy and the Foundations of Causal Inference. In Probabilistic and Causal Inference: The Works of Judea Pearl, 1st ed.; Association for Computing Machinery: New York, NY, USA, 2022; pp. 507–556. [Google Scholar]
- Peters, J.; Janzing, D.; Schölkopf, B. Elements of Causal Inference: Foundations and Learning Algorithms; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Schölkopf, B.; Janzing, D.; Peters, J.; Sgouritsa, E.; Zhang, K.; Mooij, J. On Causal and Anticausal Learning. arXiv 2012, arXiv:1206.6471. [Google Scholar]
- Gresele, L.; von Kügelgen, J.; Stimper, V.; Schölkopf, B.; Besserve, M. Independent Mechanism Analysis, a New Concept? arXiv 2022, arXiv:2106.05200. [Google Scholar]
- Greenland, S.; Brumback, B. An Overview of Relations among Causal Modelling Methods. Int. J. Epidemiol. 2002, 31, 1030–1037. [Google Scholar] [CrossRef] [Green Version]
- Suzuki, E.; Shinozaki, T.; Yamamoto, E. Causal Diagrams: Pitfalls and Tips. J. Epidemiol. 2020, 30, 153–162. [Google Scholar] [CrossRef] [Green Version]
- Pearl, J. The Do-Calculus Revisited. In Proceedings of the Twenty-Eighth Conference on Uncertainty in Artificial Intelligence, Catalina Island, CA, USA, 14–18 August 2012; pp. 4–11. [Google Scholar]
- Rubin, D.B. Causal Inference Using Potential Outcomes: Design, Modeling, Decisions. J. Am. Stat. Assoc. 2005, 100, 322–331. [Google Scholar] [CrossRef]
- Cinelli, C.; Forney, A.; Pearl, J. A Crash Course in Good and Bad Controls. SSRN J. 2020. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley Series in Telecommunications; Wiley: New York, NY, USA, 1991. [Google Scholar]
- Chen, Y.; Wang, W.; Wang, C. Semi-Supervised ASR by End-to-End Self-Training. In Proceedings of the Interspeech 2020, ISCA, Shanghai, China, 25–29 October 2020; pp. 2787–2791. [Google Scholar] [CrossRef]
- Karita, S.; Watanabe, S.; Iwata, T.; Ogawa, A.; Delcroix, M. Semi-Supervised End-to-End Speech Recognition. In Proceedings of the Interspeech 2018, ISCA, Hyderabad, India, 2–6 September 2018; pp. 2–6. [Google Scholar]
- Synnaeve, G.; Xu, Q.; Kahn, J.; Likhomanenko, T.; Grave, E.; Pratap, V.; Sriram, A.; Liptchinsky, V.; Collobert, R. End-to-End ASR: From Supervised to Semi-Supervised Learning with Modern Architectures. arXiv 2020, arXiv:1911.08460. [Google Scholar]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. Wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. arXiv 2020, arXiv:2006.11477. [Google Scholar]
- Blöbaum, P.; Shimizu, S.; Washio, T. Discriminative and Generative Models in Causal and Anticausal Settings. In Proceedings of the Advanced Methodologies for Bayesian Networks; Suzuki, J., Ueno, M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; Volume 9505, pp. 209–221. [Google Scholar] [CrossRef]
- Kilbertus, N.; Parascandolo, G.; Schölkopf, B. Generalization in Anti-Causal Learning. In Proceedings of the NeurIPS 2018 Workshop on Critiquing and Correcting Trends in Machine Learning, Montreal, QC, Canada, 7 December 2018. [Google Scholar]
- Castro, D.C.; Walker, I.; Glocker, B. Causality Matters in Medical Imaging. Nat. Commun. 2020, 11, 3673. [Google Scholar] [CrossRef] [PubMed]
- Hoyer, P.; Janzing, D.; Mooij, J.M.; Peters, J.; Schölkopf, B. Nonlinear Causal Discovery with Additive Noise Models. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–11 December 2008; Curran Associates, Inc.: Red Hook, NY, USA, 2008; Volume 21. [Google Scholar]
- Furui, S. 50 Years of Progress in Speech and Speaker Recognition Research. ECTI Trans. Comput. Inf. Technol. (ECTI-CIT) 2005, 1, 64–74. [Google Scholar] [CrossRef]
- Levinson, S.E.; Rabiner, L.R.; Sondhi, M.M. An Introduction to the Application of the Theory of Probabilistic Functions of a Markov Process to Automatic Speech Recognition. Bell Syst. Tech. J. 1983, 62, 1035–1074. [Google Scholar] [CrossRef]
- Young, S.; Evermann, G.; Gales, M.; Hain, T.; Kershaw, D.; Liu, X.; Moore, G.; Odell, J.; Ollason, D.; Povey, D.; et al. The HTK Book; Technical Report; Cambridge University Engineering Department: Cambridge, UK, 2009. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi Speech Recognition Toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, Waikoloa, HI, USA, 11–15 December 2011; IEEE Signal Processing Society: Piscataway, NJ, USA, 2011. Number CONF. [Google Scholar]
- Bilmes, J.A. What HMMs Can Do. IEICE Trans. Inf. Syst. 2006, E89-D, 869–891. [Google Scholar] [CrossRef]
- Beigman Klebanov, B.; Beigman, E. From Annotator Agreement to Noise Models. Comput. Linguist. 2009, 35, 495–503. [Google Scholar] [CrossRef]
- Varga, A.; Moore, R. Hidden Markov Model Decomposition of Speech and Noise. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Albuquerque, NM, USA, 3–6 April 1990; Volume 2, pp. 845–848. [Google Scholar] [CrossRef]
- Ghahramani, Z.; Jordan, M. Factorial Hidden Markov Models. In Proceedings of the Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1995; Volume 8. [Google Scholar]
- Wellekens, C. Explicit Time Correlation in Hidden Markov Models for Speech Recognition. In Proceedings of the ICASSP ’87. IEEE International Conference on Acoustics, Speech, and Signal Processing, Dallas, TX, USA, 6–9 April 1987; Volume 12, pp. 384–386. [Google Scholar] [CrossRef]
- Bridle, J.S. Towards Better Understanding of the Model Implied by the Use of Dynamic Features in HMMs. In Proceedings of the Interspeech 2004, ISCA, Jeju Island, Republic of Korea, 4–8 October 2004; pp. 725–728. [Google Scholar] [CrossRef]
- Bilmes, J.A. Graphical Models and Automatic Speech Recognition. J. Acoust. Soc. Am. 2002, 112, 2278. [Google Scholar] [CrossRef]
- Deng, L. Deep Learning: From Speech Recognition to Language and Multimodal Processing. APSIPA Trans. Signal Inf. Process. 2016, 5, E1. [Google Scholar] [CrossRef]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech Recognition Using Deep Neural Networks: A Systematic Review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 369–376. [Google Scholar] [CrossRef]
- Vyas, A.; Madikeri, S.; Bourlard, H. Comparing CTC and LFMMI for Out-of-Domain Adaptation of Wav2vec 2.0 Acoustic Model. arXiv 2021, arXiv:2104.02558. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep Speech 2: End-to-End Speech Recognition in English and Mandarin. In Proceedings of the 33rd International Conference on Machine Learning; Balcan, M.F., Weinberger, K.Q., Eds.; PMLR: New York, NY, USA, 2016; Volume 48, pp. 173–182. [Google Scholar]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. Wav2vec: Unsupervised Pre-training for Speech Recognition. arXiv 2019, arXiv:1904.05862. [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision; Technical Report; OpenAI: San Francisco, CA, USA, 2022. [Google Scholar]
- Mackenzie, A. The Production of Prediction: What Does Machine Learning Want? Eur. J. Cult. Stud. 2015, 18, 429–445. [Google Scholar] [CrossRef] [Green Version]
- Bzdok, D.; Altman, N.; Krzywinski, M. Statistics versus Machine Learning. Nat. Methods 2018, 15, 233. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.H.; Asch, S.M. Machine Learning and Prediction in Medicine—Beyond the Peak of Inflated Expectations. N. Engl. J. Med. 2017, 376, 2507–2509. [Google Scholar] [CrossRef] [Green Version]
- Ma, D.; Ryant, N.; Liberman, M. Probing Acoustic Representations for Phonetic Properties. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 311–315. [Google Scholar] [CrossRef]
- Padmanabhan, J.; Johnson Premkumar, M.J. Machine Learning in Automatic Speech Recognition: A Survey. IETE Tech. Rev. 2015, 32, 240–251. [Google Scholar] [CrossRef]
- Ostendorf, M. Moving beyond the “Beads-on-a-String” Model of Speech. In Proceedings of the IEEE ASRU Workshop, Merano, Italy, 13–17 December 1999; pp. 79–84. [Google Scholar]
- Scharenborg, O. Reaching over the Gap: A Review of Efforts to Link Human and Automatic Speech Recognition Research. Speech Commun. 2007, 49, 336–347. [Google Scholar] [CrossRef] [Green Version]
- Deng, L.; Jaitly, N. Deep Discriminative and Generative Models for Speech Pattern Recognition. In Handbook of Pattern Recognition and Computer Vision; World Scientific: Singapore, 2015; pp. 27–52. [Google Scholar] [CrossRef]
- Manning, C.D. Part-of-Speech Tagging from 97% to 100%: Is It Time for Some Linguistics? In Proceedings of the Computational Linguistics and Intelligent Text Processing; Gelbukh, A.F., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 171–189. [Google Scholar] [CrossRef] [Green Version]
- Reidsma, D.; Carletta, J. Reliability Measurement without Limits. Comput. Linguist. 2008, 34, 319–326. [Google Scholar] [CrossRef]
- Toth, C.; Lorch, L.; Knoll, C.; Krause, A.; Pernkopf, F.; Peharz, R.; von Kügelgen, J. Active Bayesian Causal Inference. arXiv 2022, arXiv:2206.02063. [Google Scholar]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gabler, P.; Geiger, B.C.; Schuppler, B.; Kern, R. Reconsidering Read and Spontaneous Speech: Causal Perspectives on the Generation of Training Data for Automatic Speech Recognition. Information 2023, 14, 137. https://doi.org/10.3390/info14020137
Gabler P, Geiger BC, Schuppler B, Kern R. Reconsidering Read and Spontaneous Speech: Causal Perspectives on the Generation of Training Data for Automatic Speech Recognition. Information. 2023; 14(2):137. https://doi.org/10.3390/info14020137
Chicago/Turabian StyleGabler, Philipp, Bernhard C. Geiger, Barbara Schuppler, and Roman Kern. 2023. "Reconsidering Read and Spontaneous Speech: Causal Perspectives on the Generation of Training Data for Automatic Speech Recognition" Information 14, no. 2: 137. https://doi.org/10.3390/info14020137
APA StyleGabler, P., Geiger, B. C., Schuppler, B., & Kern, R. (2023). Reconsidering Read and Spontaneous Speech: Causal Perspectives on the Generation of Training Data for Automatic Speech Recognition. Information, 14(2), 137. https://doi.org/10.3390/info14020137